论文阅读:TransFG
TransFG: A Transformer Architecture for Fine-grained Recognition
文章目录
- TransFG: A Transformer Architecture for Fine-grained Recognition
-
- 0 摘要
- 1 引言
- 2 相关研究
- 3 方法
-
- 3.1 transformer当作特征提取器
-
- 图片序列化
- patch embedding
- 3.2 TransFG 架构
-
- 部件选择模块PSM
- 对比特征学习
- 4 实验
-
- 4.3 消融研究
- 4.4 可视化
- 5 总结
0 摘要
本文提出了TransFG,将原始注意力权重整合到注意力图中,指导网络有效准确地选择判别图像块并计算它们的关系。用对比损失以进一步扩大相似子类的特征表示之间的距离。
1 引言
TransFG:一种基于ViT的简单而有效的框架:
- 通过利用multi-head self-attention机制,提出了一个部件选择模块来计算判别区域并去除冗余信息。
- 选定的token与全局分类token连接输入到最后一个transformer层。
- 为扩大不同类别样本的特征表示之间的距离,减少相同类别样本特征表示的距离,引入了对比损失
在5个数据集上做了相关实验。
本文贡献:
- 首次将Transformer应用到细粒度视觉分类,它提供了一种替代具有RPN模型设计的主导CNN主干的方法
- 提出了TransFG,取得了SOTA效果
- 可视化结果说明TransFG能捕获有区别的原生图像区域,更好地了解它如何做出正确的预测。
2 相关研究
3 方法
3.1 transformer当作特征提取器
图片序列化
传统的方法将图片分割成非重叠的patch,损害了块之间的结构,文本提出用滑动窗口产生重叠块。
图片大小: H ∗ W H*W H∗W
块大小: P ∗ P P*P P∗P
滑动步长: S S S
块的数量: N = N H ∗ N W = ⌊ H − P + S S ⌋ ∗ ⌊ W − P + S S ⌋ N=N_H*N_W=\lfloor\frac{H-P+S}{S}\rfloor*\lfloor\frac{W-P+S}{S}\rfloor N=NH∗NW=⌊SH−P+S⌋∗⌊SW−P+S⌋( ⌊ H − P S ⌋ + 1 \lfloor\frac{H-P}{S}\rfloor+1 ⌊SH−P⌋+1这样好理解点)
S S S越小,性能越好,但相应的,计算代价就大了。
patch embedding
将patch映射到D维嵌入空间上。加上一个可训练的位置嵌入:
z 0 = [ x p 1 E , x p 2 E , . . . , x p N E ] + E p o s z l ′ = M S A ( L N ( z l − 1 ) ) + z l − 1 , l ∈ 1 , 2 , . . . , L z l = M L P ( L N ( z l ′ ) ) + z l ′ , l ∈ 1 , 2 , . . . , L z_0=[x^1_pE,x^2_pE,...,x^N_pE]+E_{pos}\\ z'_l=MSA(LN(z_{l-1}))+z_{l-1}, l\in 1,2,...,L\\ z_l=MLP(LN(z'_{l}))+z'_l, l\in 1,2,...,L z0=[xp1E,xp2E,...,xpNE]+Eposzl′=MSA(LN(zl−1))+zl−1,l∈1,2,...,Lzl=MLP(LN(zl′))+zl′,l∈1,2,...,L
- N N N是token的个数
- E ∈ R ( P 2 ∗ C ) ∗ D E\in R^{(P^2*C)*D} E∈R(P2∗C)∗D。token大小是 P ∗ P ∗ C P*P*C P∗P∗C,每个token映射到 D D D维度。
- E p o s ∈ R N ∗ D E_{pos}\in R^{N*D} Epos∈RN∗D
- M S A MSA MSA:multi-head self-attention
- M L P MLP MLP:Linear-GELU-Dropout-Linear-Dropout
3.2 TransFG 架构
纯Vision Transformer可以直接应用于细粒度视觉分类并取得令人印象深刻的结果。它不能很好地捕获FGVC所需的本地信息。提出了部件选择模块(PSM),并应用对比特征学习来扩大相似子类别之间表示的距离。
整体结构:

部件选择模块PSM
准确定位区别性区域。Vision Transformer模型以其先天的multi-head self-attention非常适合。为了充分利用注意力信息,更改了最后一个 Transformer 层的输入。
假设模型有 K K K个self-attention head,最后一层的隐藏特征输入记为 z L − 1 = [ z L − 1 0 ; z L − 1 1 , . . . , z L − 1 N ] z_{L-1}=[z^0_{L-1};z^1_{L-1},...,z^N_{L-1}] zL−1=[zL−10;zL−11,...,zL−1N],前面各层的注意力权重可以写成:
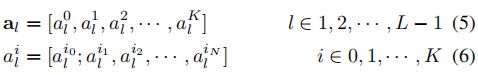
研究表明原始注意力权重不一定对应于输入标记的相对重要性,尤其是对于模型的较高层,由于嵌入的标记可识别性不足。为此,作者提出整合所有先前层的注意力权重,递归地将矩阵乘法应用于所有层中的原始注意力权重:
a f i n a l = ∏ l = 0 L − 1 a l \mathbf a_{final}=\prod^{L-1}_{l=0}\mathbf a_l afinal=l=0∏L−1al
由于 a f i n a l a_{final} afinal 捕获信息如何从输入层传播到更高层的嵌入,因此与单层原始注意力权重 a L − 1 a_{L-1} aL−1 相比,它是选择判别区域的更好选择。
针对 a f i n a l a_{final} afinal 中的 K K K 个不同的注意力头选择最大值 A 1 A_1 A1、 A 2 A_2 A2、···、 A K A_K AK 的索引,这些位置用作模型的索引,以提取 z L − 1 z_{L−1} zL−1中的相应token。最后将选定的标记与分类标记连接起来作为输入序列:
z l o c a l = [ z L − 1 0 ; z L − 1 A 1 , z L − 1 A 2 , . . . , z L − 1 A K ] z_{local}=[z^0_{L-1};z^{A_1}_{L-1},z^{A_2}_{L-1},...,z^{A_K}_{L-1}] zlocal=[zL−10;zL−1A1,zL−1A2,...,zL−1AK]
通过用对应于信息区域的标记替换原始的整个输入序列,并将分类标记作为输入连接到最后一个 Transformer 层,我们不仅保留全局信息,而且迫使最后一个 Transformer Layer 专注于不同子类别之间的细微差异,同时放弃诸如背景或超类之间的共同特征等辨别力较小的区域。
对比特征学习
L c o n = 1 N 2 ∑ i N [ ∑ j : y i = y j N ( 1 − s i m ( z i , z j ) + ∑ j : y i ≠ y j N max ( s i m ( z i , z j ) − α ) , 0 ) ] L_{con}=\frac{1}{N^2}\sum^N_i[\sum^N_{j:y_i=y_j}(1-sim(z_i,z_j)+\sum^N_{j:y_i\neq y_j }\max(sim(z_i,z_j)-\alpha),0)] Lcon=N21i∑N[j:yi=yj∑N(1−sim(zi,zj)+j:yi=yj∑Nmax(sim(zi,zj)−α),0)]
- sim是余弦相似度
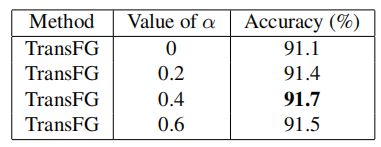
- α = 0.4 \alpha=0.4 α=0.4
- N N N是batch size
L = L c r o s s ( y , y ′ ) + L c o n ( z ) L=L_{cross}(y,y')+L_{con}(z) L=Lcross(y,y′)+Lcon(z)
4 实验
4.3 消融研究
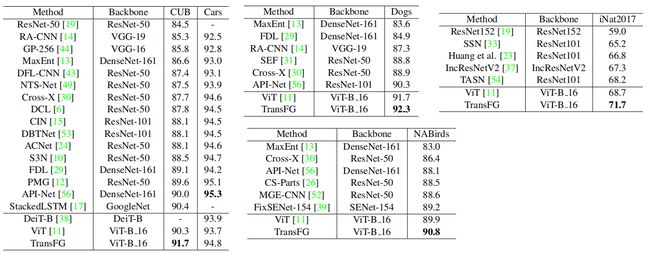
patch重叠的影响:
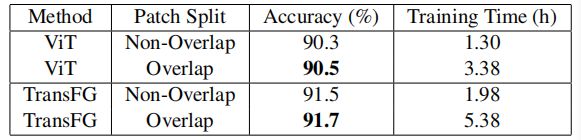
部分选择模块的影响:
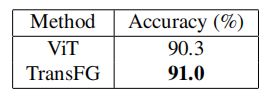
对比损失影响:

α \alpha α的影响:
4.4 可视化
结论:能够定位重要的部分。
5 总结
本文提出了一种细粒度视觉分类框架 TransFG,取得了最先进的结果。
利用self-attention来捕捉最具辨别力的区域。与其他方法产生的边界框相比,选择的图像块要小得多,因此通过显示哪些区域真正有助于细粒度分类而变得更有意义。
这种小图像块的有效性也来自于 Transformer Layer 来处理这些区域之间的内部关系,而不是依赖它们中的每一个来分别产生结果。
引入对比特征学习以提高分类标记的判别能力。
定性可视化进一步证明了方法的有效性和可解释性。