多模态商业应用
最近在研究多模态技术,发现这个领域确实是一片蓝海。所谓多模态,简单的理解就是不同于 CV,NLP 在单个领域的研究,它融合了音频、视频、文本、商品模态等信息,为不同下游任务提供强有力的技术支持。在这篇文章中,我将整理自己最近浏览的知识(也是作为自己回顾的资料)。
短视频多模态应用
代表应用:淘宝视频分类,阿里文娱多模态视频分类,抖音短视频分类
淘宝视频多模态AI算法
在淘宝,短视频业务一直非常重要,视频销售已经成为品牌方最爱的营销方式。如何对规模庞大的视频进行内容化理解并个性化推荐变得极为重要。
算法框架
淘宝短视频的信息是十分丰富的,有视频/封面图/文本/音频/商品等模态,分别刻画短视频不同维度的信息。为了建立高效准确的视频分类算法,淘宝团队提出了以下算法框架:
(1) 预训练模型的选择
(2) 模态融合方法的设计
(3) 多目标的分类器的设计
预训练模型的选择
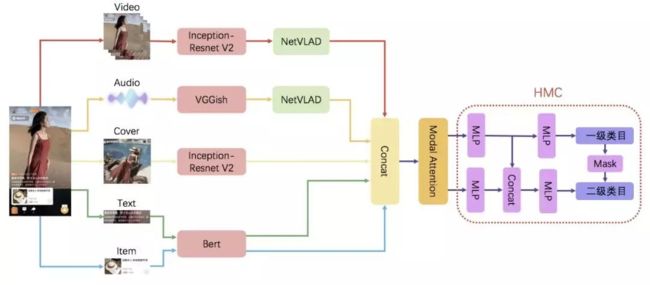
使用预训练模型进行迁移学习能够加速 loss 收敛并显著提升下游任务的准确率。
(1) 视频模态: 在淘宝应用中,视频模态具体指视频和封面图。淘宝团队选择了 Inception-Resnet v2 1 作为视频特征提取的模型,该模型既能通过堆叠不同的 Inception Block 增加网络的宽度提高算法准确度,又通过加入 ResNet 的残差学习单元缓解网格退化问题,有效提高了视频特征的泛化性。
视频特征序列相较于普通的图像特征包含了更加丰富的信息,不同特征之间具有时序相关性。淘宝团队 采用 NetVLAD 2 作为视频特征聚合网络,该网络以 CNN 结构为基础,通过聚类中心将视频序列特征转化为多个视频镜头特征,然后通过学习权重对多个视频镜头加权求和获得全局特征向量。
(2) 音频模态: 该部分首先从淘宝视频中分离音频信号,通过计算 MFCC 特征将音频信号转化为图像输入,然后使用 VGGish 3 提取音频特征序列。对于获取的音频特征序列,我们同样可以用 NetVLAD 提取不同镜头对应的音频特征,然后通过可学习的权重融合生成音频模态的全局特征向量。
(3) 文本模态: 视频内容中的文本主要包括视频标题和视频摘要。文本预处理当然得使用大力出奇迹的 Bert 模型了!Bert 在手,天下我有。它通过 12 层的 transformer encoder 极大的提高了 nlp 多项任务的指标。
(4) 商品模态: 商品模态是淘宝视频区别于其他视频的标志。这部分可以沿用 Bert 模型提取商品的标题和泪目名称的文本特征,作为商品模态的全局特征向量。
模态融合方法的设计
如何设计优秀的多模态特征融合方法,充分利用非结构化的多模态信息,将不同模态间的特征对齐到同一特征空间,使得不同信息模态信息取长补短可以说是该类任务中最关键的部分了。
淘宝团队应用了基于 Modal Attention 的多模态特征融合方法。Modal Attention 基于融合的特征向量预测一个模态个数维度的基于多模态联合特征的对于不同模态的重要性分布概率,这个模态分布概率与多模态融合特征做点积,得到对于不同模态特征重要性重新加权后的新的模态融合特征。
层次化分类器设计
淘宝视频的标签体系不同于以往单一的分类目标,它是一种结构化的分层任务,同时具有一级类目和二级类目且两级类目之间有依存关系。例如,二级类目的男士休闲、少女穿搭等都属于一级类目的服饰类。针对这种情况,淘宝团队提出了分层多标签分类器(HMC)。
(1) HMC 分类器同时构建了一二级类目各自的分类通道,能够同时预测一二级类目标签(如下图所示), 这种分类器能够隐形的学习一二级类目的依赖关系,能够互相促进,提高分类精度。
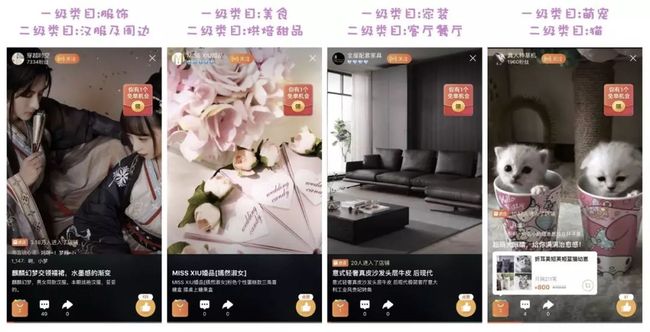
(2) 基于HMC分类器,淘宝添加了基于类别不匹配的多目标损失函数。损失函数L由三部分构成,分别是一级类目损失L1,二级类目损失L2,以及一二级类别不匹配损失LH。一级类目损失和二级类目损失是一二级类目的交叉熵损失,能够使得网络同时学习到多模态特征与一二级类目的条件概率分布,同时能够隐形的学习到一二级类目之间的依赖关系。然而,仅仅使用一二级类目损失无法保证一二级类目之间的依赖关系,为了缓解这个问题,淘宝加入了类别不匹配损失,用于惩罚一二级类目不匹配的情况。参数 λ 用来控制一级类目损失和二级类目损失之间的重要性相对程度,因为二级类目数量更多,学习更加困难,需要添加更大的权重去学习。参数 β 用来调节类别不匹配损失对于总体损失函数的重要性。添加类别不匹配损失之后,一二级类目不匹配的情况大幅度下降,同时分类准确率也获得了提升4。
阿里文娱多模态视频分类
1. 多模态视频分类算法网络结构
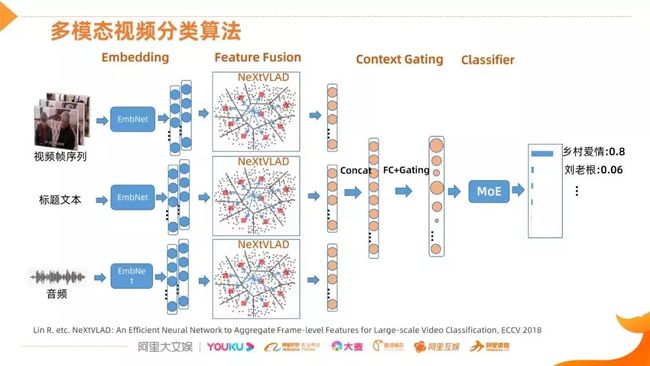
阿里文娱采用的多模态视频分类网络结构共分为四个阶段
- 视频信息的多模态 Embedding,形成多帧的特征
- 基于聚类和残差的 NeXtVLAD 融合网络融合出单帧的 feature
- 将多模态信息进行连接,通过 FC 做映射
- 使用 Gating 发掘各个维度之间的关联信息,选择性的增强或抑制部分维度,调整后的信息会送到一个分类网络(比如 MoE),最终得到一个预测结果
2. 多模态视频分类算法改进
2.1 特征改进
特征改进主要有这样几个目标:
- 细粒度的表征领域,特别是对节目分类
- 信息要涵盖全面
- 扩展性好:只有上述两项都做到,信息的扩展性才好,这里强调的扩展性也是针对节目分类的,因为每天都有新剧产生,要保证模型性能的基本稳定,这样就需要更精细全面的信息提取能力。
改进措施主要包括三个方面:
- 改进基础网络 backbone: 选择优秀高效的网络结构 (EfficientNet)
- 选择更优的数据增广策略: 包括半监督和无监督
- 训练方法:尝试分类监督、无监督的方法
2.1.1 backbone - EfficientNet

EfficientNet 在性能和效率方面做了比较好的权衡。它认为影响网络的三个维度 (网络深度、宽度和输入的分辨率)并不是独立的,而是相互影响的。如果图像的分辨率不变的话,将这个网络进行加深的话,对后面更高层的计算是比较冗余的。该网络通过暴力搜索得到这三个方面的最佳配置。
2.1.2 数据增广

这里的基本思路是通过一些措施使得网络能学习到更丰富、更细节的信息。具体措施可以查看原文
2.1.3 训练方法

基于分类的任务可能会学到一些非本质的信息,如 logo 或黑边,这样导致特征的扩展性较差,在大类别的分类上很快就能达到性能上限。因此阿里文娱团队参考了 Keiming He 团队的无监督特征学习方法,具体流程如下图:

经过优化后,模型在特征细粒度的区分能力上有了很大的增强

此类任务中常见的问题:

第一类,一个对文本、音频、视频多路特征间怎样进行融合,大家有一个困惑,不同模态的数据存在不同的 embedding 空间,可比性会不会影响特征的融合,其实有一些影响,但不会特别大。如果能保证不同模态的特征量纲差别不大,就可以用简单的方法来融合并提取出有用的信息。
第二类,把各模态的特征模型和分类模型分开训练还是统一训练。从工程的角度看,统一训练的方式是很难实施的,试想一下对上千万的视频片段做分类,它的视频帧就上亿,直接在图像帧上训练整个网络,训练成本是非常高的,再加上音频、文本,训练成本就更高。基于此,我们将各模态的 embedding 和 embedding 后的融合分开来做,简化了问题。
第三类,样本均衡问题。先考虑一下,做样本均衡是否带来真正的收益,前提是我们需要有一个辨析能力较强的网络下,做这个样本均衡才是有效的,比如,有各两类,从各个模态来说比较接近,比较难分,这两类,有一个特别多,有一类特别少,在网络的辨析能力没有提高下,对占比较少的类进行扩充势必会影响另一类,也就是说样本均衡在某种情况下带不来收益。
第四类,多层次的分类模型,也面临着工程方面的问题,比说新增加了一个分类,整个模型我们需要更新和评估。我们做法也是分开训练模型,减少各分类之间的影响。
第五类,小样本学习是目前比较棘手的问题,人工标注成本比较高,标注不及时,样本量增长过慢。我们也一直做一些尝试,如果对后面的网络进行半监督学习的话,需要找到一些方法在特征空间进行数据的增广,通过数据变换生成不同的 VIEW,这是一个非常核心的操作,基于图片的分类上有比较的结果,但是对于基于特征的网络来说,我们还在做更多的探索。
持续更新中
参考资料
- [1] Szegedy C, Ioffe S, Vanhoucke V, et al. Inception-v4, inception-resnet and the impact of residual connections on learning[C]//Thirty-First AAAI Conference on Artificial Intelligence. 2017.
- [2] Arandjelovic R, Gronat P, Torii A, et al. NetVLAD: CNN architecture for weakly supervised place recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 5297-5307.
- [3] Hershey S, Chaudhuri S, Ellis D P W, et al. CNN architectures for large-scale audio classification[C]//2017 ieee international conference on acoustics, speech and signal processing (icassp). IEEE, 2017: 131-135.