论文笔记之Learning Human-Object Interaction Detection using Interaction Points
直接预测人-物的交互点和交互向量(用于分组),再与人/物检测结果关联得到最终结果。
CVPR2020接收
论文地址:https://arxiv.org/abs/2003.14023
1. 摘要
理解人与物体之间的相互作用是视觉分类的基本问题之一,也是实现详细场景理解的重要步骤。人与物体之间的交互(HOI)检测力求既定位人与物体,又确定它们之间的复杂交互。 大多数现有的HOI检测方法都是以实例为中心的,其中基于外观特征和粗糙的空间信息来预测所有可能的人-物体之间的交互。 作者认为,仅外观特征不足以捕获复杂的人与物体的相互作用。因此,在本文中,作者提出了一种新颖的全卷积方法,该方法直接检测人与物体之间的相互作用。 网络会预测交互点,这些交互点可以直接对交互进行定位和分类。与密集预测的交互向量配对,这些交互与人类和物体检测相关联以获得最终预测。
2. 相关工作
在现有的人物交互(HOI)检测方法中,[Visual semantic role labeling]的工作是第一个探索视觉语义角色标记问题的方法。 该问题的目的是定位代理(人)和物体以及检测它们之间的交互。 [Detecting and recognizing human-object intaractions]的工作引入了一种以人为中心的方法,称为InteractNet,该方法扩展了Faster R-CNN框架,并带有一个附加分支,以了解目标位置上特定于交互作用的密度图。Qi等人[Learning human-object interactions by graph parsing neural networks]提出利用图卷积神经网络,并将HOI任务视为图结构优化问题。 Chao等人,[Learning to detect human-object interactions]建立了一个基于人对目标区域和成对交互分支的多流网络。 该多流架构的输入是来自预训练检测器(例如,FPN )和原始图像的预测边界框。 在这种多流体系结构中,人流和物体流基于从骨干网提取的外观特征,以生成关于检测到的人和物体边界框的置信度预测。另一方面,成对流通过将两个框(人和物体)结合起来,简单地编码人与物体之间的空间关系。以后的工作通过例如引入以实例为中心的注意力[iCAN:
Instance-centric attention network for human-object interaction detection],姿势信息[Transferable
interactiveness knowledge for human-object interaction detection]和基于上下文感知的外观特征的深层上下文注意力[Deep contextual attention for human-object interaction detection],扩展了上述多流体系结构。
传统方法计算昂贵,且仅根据外观特征和粗糙的空间信息不足以捕获复杂的交互作用。
3. 本文方法
3.1 总体结构
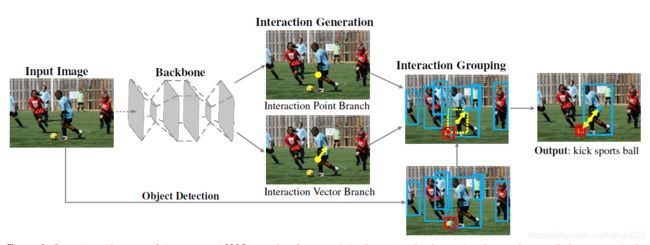
主要分为3个部分,特征提取部分、交互生成部分(生成交互点、交互向量)、交互分组部分(根据预测框,交互点,交互向量得到最终结果)。
Backone网络使用的是Hourglass网络,使用Faster RCNN + ResNet50-FPN获得预测框。
Hourglass网络输出的特征图大小为![]() ,其中H,W是输入图像的高度和宽度,S是步幅,D是输出通道(S设置为4)。
,其中H,W是输入图像的高度和宽度,S是步幅,D是输出通道(S设置为4)。
交互点定义为人-物对的中心点,且是交互向量的起点。
3.2 交互生成
3.2.1 交互点分支
输入提取的特征,用单个3*3卷积,生成大小为![]() 的交互点热图。C表示交互种类的数量。
的交互点热图。C表示交互种类的数量。
训练时,交互点由人和物中心点生成的GT高斯热图监督,推理时采用高斯热图的峰值的top-k个点(cornernet中的方式)。
不同于目标检测的一个点只能代表一个物体,本文一个点可以为多个交互类别(人同时与多个物体交互)。
3.2.2 交互向量分支

交互向量分支预测指向人类中心点的交互向量![]() 。
。
交互点的定义:![]()
交互向量的定义:![]()
输入提取的特征,使用单个3*3卷积生成无符号交互向量图V,大小为![]() ,两个值,一个作用于水平方向,一个作用于垂直方向。
,两个值,一个作用于水平方向,一个作用于垂直方向。
推理时,根据下式,生成4个人类中心的可能位置:
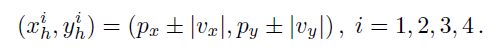
3.3 交互分组
满足![]() 条件的分为一组。
条件的分为一组。
分组策略:
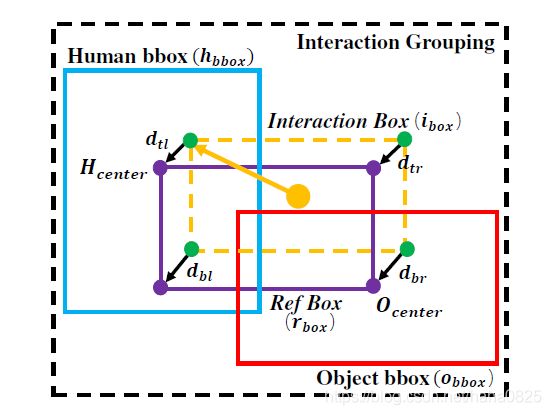
图中,四个绿色点由计算出;紫色的四个点由人/物框确定;然后基于这八个点计算向量长度
![]() 。
。
然后以上的值满足下式则为正例:

d_t为过滤时的阈值。
算法表示:

3.4 训练
预测交互点的loss采用和anchor-free检测器一样的改动的focal loss:
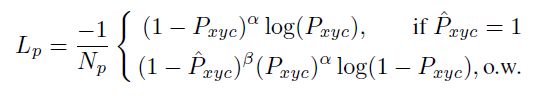
N_p 是图中的交互点数量。
对于交互向量预测,使用在交互点P_k上的无符号交互向量的值![]() 作为GT。这部分使用的是L1 loss:
作为GT。这部分使用的是L1 loss:

V_pk是在点P_k预测的交互向量。
总的损失函数:
![]()
λ_v设置为0.1.
4. 实验
检测分支在COCO上预训练,使用人的预测框置信度大于0.4,物体的预测框置信度大于0.1,设置的低是因为分组可以过滤掉大量的负例。
4.1 SOTA对比
V-COCO上
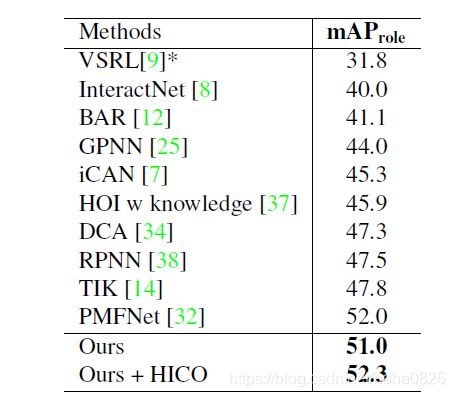
最后一行表示在HICO-DET上预训练,再在V-COCO上微调,测试。
HICO-DET上
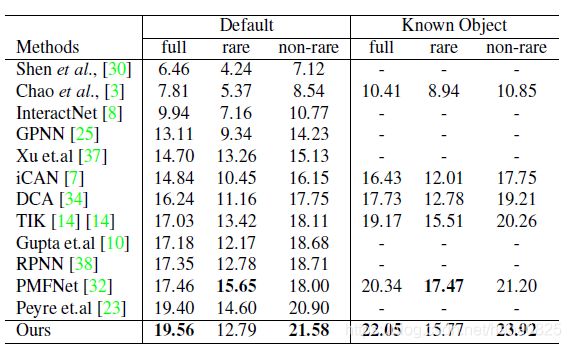
4.2 消融实验

Angle-filter: 交互点p与人体中心点H和物体中心点O具有固定结构。过滤掉在向量PH和PO之间的小于阈值的HOI对。
Dist-ratio-filter: 在训练时,PH和PO的比例设置为1,过滤掉比例在max(PH,PO)和min(PH,PO)之间的HOI对。
交互分组策略分为两部分,interaction-box和corner-dist,来验证三个软约束的效果。
interaction-box和corner-dist分别是前两个式子和最后一个式子。
发现仅仅interaction-box + interaction points就获得了巨大提升。再加上corner-dist也获得了挺大的提升。
Center pool
centernet中的中心池化,在交互点和交互向量之前使用,略有改善性能。

稀有类和非稀有类的交互合适的分数阈值应该是不同的,因为稀有类样本较少,所以分数一般较低。因此动态阈值获得了不错的效果。
4.3 局限
- 长尾类对于人物交互检测具有较大挑战。
- 多个HOI对不能共享相同的交互点,但这种情况很少见。