DPPO深度强化学习算法实现思路(分布式多进程加速)
为什么是多进程
众所周知,python的多线程是伪多线程,在全局GIL下某一时刻python只有一个线程在执行,这就意味着在计算密集型任务下多线程反而会更慢(上下文切换)。因此,想做关于强化学习加速的任务只能多进程(可以理解为手动运行多个程序)。但是多进程又很麻烦,麻烦在进程之间的数据联系(因为进程是不共享全局区的),本文采用pipe技术(管道)做数据传输。
代码
具体实现代码已上传github:https://github.com/ZYunfeii/DRL_algorithm_library/tree/master/PPO
实现思路1
- 多个子进程同步训练网络
- 在主进程将子进程网络的权重取平均更新到net
- 再将net传入子进程,回到1
这种思路是最容易想到的,实现这种思路有两个关键点:
- 进程同步(巧用pipe管道在接受数据时的阻塞原理可以实现,即主进程在每个episode都去接受每个子进程的数据,只有全接受到了才开始执行后面的语句)
- 主进程怎么实现对多个相同结构网络权重取平均然后赋给主进程网络。
针对第二个问题,给出如下代码(这里很坑的是不能直接对想要赋权重的网络通过字典键来赋值,而是先建一个相同的字典,对其赋值,再通过 load_state_dict()加载到目标网络):
""将子进程网络权重的平均值赋给net,下一个episode主进程再将net传给子进程"""
act_model_dict = net.act.state_dict()
cri_model_dict = net.cri.state_dict()
for k1,k2 in zip(act_model_dict.keys(),cri_model_dict.keys()):
result1 = torch.zeros_like(act_model_dict[k1])
result2 = torch.zeros_like(cri_model_dict[k2])
for j in range(process_num):
result1 += net_list[j][0].state_dict()[k1]
result2 += net_list[j][1].state_dict()[k2]
result1 /= process_num
result2 /= process_num
act_model_dict[k1] = result1
cri_model_dict[k2] = result2
net.act.load_state_dict(act_model_dict)
net.cri.load_state_dict(cri_model_dict)
这一思路的部分代码如下:
def main1():
"""
第一种实现多进程加速的思路:
1.多个子进程同步训练网络
2.在主进程将子进程网络的权重取平均更新到net
3.再将net传入子进程,回到1
"""
env = gym.make('LunarLanderContinuous-v2')
net = GlobalNet(env.observation_space.shape[0],env.action_space.shape[0])
process_num = 4
pipe_dict = dict((i,(pipe1,pipe2)) for i in range(process_num) for pipe1,pipe2 in (multiprocessing.Pipe(),))
child_process_list = []
for i in range(process_num):
pro = multiprocessing.Process(target=child_process1, args=(pipe_dict[i][1],))
child_process_list.append(pro)
[p.start() for p in child_process_list]
rewardList = list()
MAX_EPISODE = 30
for episode in range(MAX_EPISODE):
[pipe_dict[i][0].send(net) for i in range(process_num)]
net_list = list()
for i in range(process_num):
net_list.append(pipe_dict[i][0].recv())
"""将子进程网络权重的平均值赋给net,下一个episode主进程再将net传给子进程"""
act_model_dict = net.act.state_dict()
cri_model_dict = net.cri.state_dict()
for k1,k2 in zip(act_model_dict.keys(),cri_model_dict.keys()):
result1 = torch.zeros_like(act_model_dict[k1])
result2 = torch.zeros_like(cri_model_dict[k2])
for j in range(process_num):
result1 += net_list[j][0].state_dict()[k1]
result2 += net_list[j][1].state_dict()[k2]
result1 /= process_num
result2 /= process_num
act_model_dict[k1] = result1
cri_model_dict[k2] = result2
net.act.load_state_dict(act_model_dict)
net.cri.load_state_dict(cri_model_dict)
reward = 0
for i in range(process_num):
reward += net_list[i][2]
reward /= process_num
rewardList.append(reward)
print(f'episode:{episode} reward:{reward}')
[p.terminate() for p in child_process_list]
painter = Painter(load_csv=True,load_dir='../figure.csv')
painter.addData(rewardList,'MP-PPO')
painter.saveData('../figure.csv')
painter.drawFigure()
def child_process1(pipe):
env = gym.make('LunarLanderContinuous-v2')
batch_size = 128
while True:
net = pipe.recv()
ppo = AgentPPO(net)
rewards, steps = ppo.update_buffer(env, 5000, 1)
ppo.update_policy(batch_size, 8)
pipe.send((ppo.act.to("cpu"),ppo.cri.to("cpu"),rewards))
实现思路2
- 多个进程不训练网络,只是拿到主进程的网络后去探索环境,并将transition通过pipe传回主进程
- 主进程将所有子进程的transition打包为一个buffer后供网络训练
- 将更新后的net再传到子进程,回到1
这种实现思路是主流实现思路,即子进程是用来探索环境拿到数据的,而不是去训练网络的,训练网络放到主进程来做。唯一加速的地方就在于强化学习中replay buffer收集得很快。框图如下:
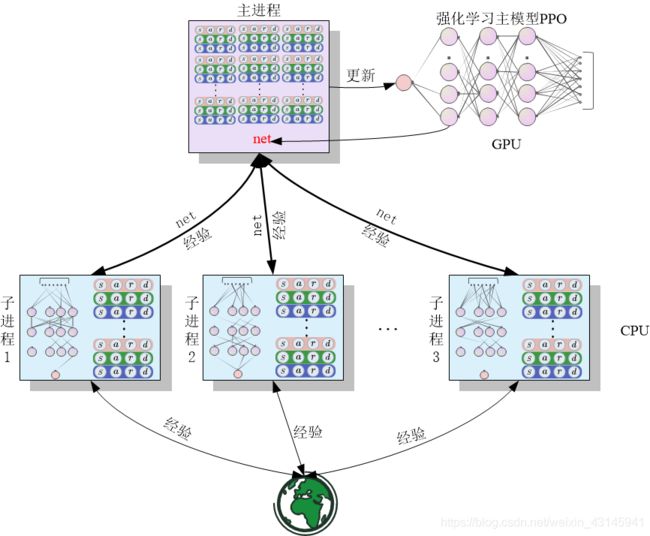
实现这一思路主要关键点在子进程通过pipe回传数据(r,a,s,mask),因为pipe不是什么类型都能传的,博主我就遇到不能直接将buffer回传,解决方案是将buffer中的数据解包通过元组(或者是数组)传递,到主进程再打包成一个大大的buffer给网络训练。
这一思路部分代码如下:
def main2():
"""
第二种实现多进程训练的思路:
1.多个进程不训练网络,只是拿到主进程的网络后去探索环境,并将transition通过pipe传回主进程
2.主进程将所有子进程的transition打包为一个buffer后供网络训练
3.将更新后的net再传到子进程,回到1
"""
env = gym.make('LunarLanderContinuous-v2')
net = GlobalNet(env.observation_space.shape[0], env.action_space.shape[0])
ppo = AgentPPO(deepcopy(net))
process_num = 4
pipe_dict = dict((i, (pipe1, pipe2)) for i in range(process_num) for pipe1, pipe2 in (multiprocessing.Pipe(),))
child_process_list = []
for i in range(process_num):
pro = multiprocessing.Process(target=child_process2, args=(pipe_dict[i][1],))
child_process_list.append(pro)
[p.start() for p in child_process_list]
rewardList = list()
MAX_EPISODE = 30
batch_size = 128
for episode in range(MAX_EPISODE):
[pipe_dict[i][0].send(net) for i in range(process_num)]
reward = 0
buffer_list = list()
for i in range(process_num):
receive = pipe_dict[i][0].recv() # 这句带同步子进程的功能,收不到子进程的数据就都不会走到for之后的语句
data = receive[0]
buffer_list.append(data)
reward += receive[1]
ppo.update_policy_mp(batch_size,8,buffer_list)
net.act.load_state_dict(ppo.act.state_dict())
net.cri.load_state_dict(ppo.cri.state_dict())
reward /= process_num
rewardList.append(reward)
print(f'episode:{episode} reward:{reward}')
[p.terminate() for p in child_process_list]
painter = Painter(load_csv=True, load_dir='../figure.csv')
painter.addData(rewardList, 'MP-PPO-Mod')
painter.saveData('../figure.csv')
painter.drawFigure()
def child_process2(pipe):
env = gym.make('LunarLanderContinuous-v2')
while True:
net = pipe.recv() # 收主线程的net参数,这句也有同步的功能
ppo = AgentPPO(net)
rewards, steps = ppo.update_buffer(env, 5000, 1)
transition = ppo.buffer.sample_all()
r = transition.reward
m = transition.mask
a = transition.action
s = transition.state
log = transition.log_prob
data = (r,m,s,a,log)
"""pipe不能直接传输buffer回主进程,可能是buffer内有transition,因此将数据取出来打包回传"""
pipe.send((data,rewards))
实验结果
选了个gym下稍微难点的环境:月球着陆器 env = gym.make('LunarLanderContinuous-v2')
参与实验的对象:
- PPO:单进程
- MP-PPO:第一种实现思路的多进程
- MP-PPO-Mod:第二种实现思路的多进程
MAX_EPISODE = 30
由于2,3都是多进程,因此buffer的容量都设置的一样的(这样3的总buffer会比1,2大子 进程数量 倍)
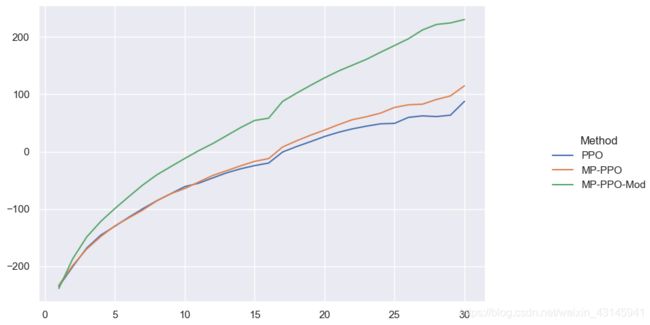
30个episode多进程的PPO已经把分跑上200了,得益于PPO以及多进程的加持。

这张图更加体现了多进程在ppo中的作用,相同的reward多进程可以节省一半时间。
细节
一个小细节:子进程探索环境时可以把模型全部放在cpu上跑,否则子进程一多显存容易溢出。主进程的模型是我们需要更新的,因此放在cuda上跑。