Affinity propagation 近邻传播算法
近邻传播算法是一种基于代表点的聚类方法,它会同时考虑所有数据点都是潜在的代表点,通过结点之间的信息传递,最后得到高质量的聚类。这个信息的传递,是基于sum-product或者说max-product的更新原则,在任意一个时刻,这个信息幅度都代表着近邻的程度,也就是一个数据点选择另一个数据点作为代表点有多靠谱。这也是近邻传播名字的由来。
近邻传播算法输入的信息是一个实值的集合,{s(i,k)}{s(i,k)},每个相似度s(i,k)s(i,k)都代表着一个数据k有多适合作为另一个数据i的代表点,可以看成是它们本身的相似度。每一个数据点都有一个对应的变量结点cici,其中,如果ci=kci=k而i≠ki≠k就代表着数据点i已经分配给了一个聚类,ckck是它的代表点。ck=kck=k就是说数据点k本身就是一个聚类代表点。我们可以构造一张图,用带约束的网相似度(net similarity)来作为图的函数。
图的结构如下: 
其中方格的代表函数结点,圆圈代表变量结点。我们定义网相似度如下: 
这是带有约束的,其中第一项是k-median 问题演化过来的(也比较好理解,每个点i都和它的代表点的相似度最高),只不过将它放在自然指数的位置,这是为了保证我们的F(c,s)F(c,s) 总是正数。第二项添加了一致性约束,就是说如果有非k的结点选了k作为代表点,那么k必须同时是本身的代表点。否则就会有惩罚。 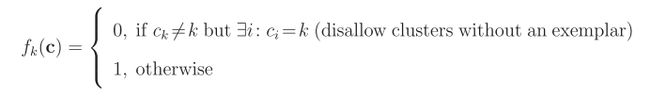
F(c,s)F(c,s)的两项都各自通过一个函数结点来表示,而标签值(聚类类别值)cici 用一个变量结点来表示。log F(c,s)log F(c,s)可以写成log函数的sum的形式。
1. Sum-Product Affinity Propagation
我们可以用sum-product 算法来得到变量的组合以完成对F(c;s)F(c;s) 的最大化,同时这也是对eS(c)eS(c)的最大化。S(c)S(c) 这里是带有约束的。对于这种特殊的图拓扑,使用sum-product 是非常直接的,通过变量结点到函数结点的信息传递,以及函数结点到变量结点的信息传递可以实现。
O(NN)O(NN)向量信息更新
从变量结点cici到函数结点fk(c)fk(c)包含了N个非负的实值——其中每一个的取值为j(cici中的一个取值,也就是说是从1到N中的一个数),我们可以用下图中的ρi→kρi→k 表示。

随后我们用技巧将它们简化为一个标量,使得算法的时间和空间和输入的相似对的数目成线性相关。
而从函数结点fk(c)fk(c)到变量结点cici也包含了N个实值,可以表示为αi←k(j)αi←k(j).在任意时刻,可以通过将所有的cici 的输入信息求乘积得到cici 的评估。 
我们先用公式来描述前者,所有的ρρ信息,也就是从变量到函数结点的信息,都是从变量结点出发的,它们可以所有输入信息逐个相乘: 
从函数结点到变量结点可以通过对所有输入信息的乘积,随后summing over掉所有的变量(除去我们发送信息过去的那个变量)。因为所有的函数结点都与N的变量结点相连接,这意味着我们需要对N个函数结点中的每一个求N-1次加法。
O(N3)O(N3) 向量信息更新
上面的时间复杂度明显是不适用的,所幸的是,所有的函数{fk(c)Nk=1}{fk(c)k=1N}都是二值的约束,所以它们是可以因子分解的: 
如果我们对ck=kck=k和ck≠kck≠k进行分开讨论,那么函数就可以写到加法里面去,输入信息就可以单独求加法(也就是说,把求和符号 和 乘号 的位置调换一下)。相应的,我们可以将从函数结点fkfk 到变量结点cici的信息整理如下: 
这个公式一眼看去非常让人头疼,为了容易理解,博主贡献一点个人的啃读领悟,在给定cici的情况下,比如说我们i=1, N=5,k=2,那么我们要求的从变量结点2到函数结点1的信息,而变量2其实不仅连接了函数结点1,还有函数结点2 3 4 5 ,要把从这些函数结点到它的信息乘起来。
1. 第一种情况,由于ck=k=ick=k=i
所以fk(j1,...,ji−1,ci,...,jN)≡1fk(j1,...,ji−1,ci,...,jN)≡1,所以可得原式第一个分式。
2. 第二种情况,由于ck≠k=ick≠k=i
根据定义,k不选自己,说明也没有别的数据点选它,只有j1,j2,...,ji−1,jj+1,...,jNj1,j2,...,ji−1,jj+1,...,jN都不等于k可以使得才能使得fkfk取值为1,否则为0求乘法后就是0这项可以忽略,所以可得原式第二个分式。注意乘法和加法交换了位置。
3. 第三种情况,由于有不是k的数据点选择了k作为代表点,所以应该k必须同时选择本身也作为代表点。所以写当i′==ki′==k,对应那项因子写成ρk→k(k)ρk→k(k)
4. 第四种情况,由于i≠ki≠k并且ci≠kci≠k,所以有两种情况,一种是ck=kck=k, 把这一项ρk→k(k)ρk→k(k)单独写出来如同第三种情况,当ck≠kck≠k时,必须要求j1,j2,...,ji−1,jj+1,...,jNj1,j2,...,ji−1,jj+1,...,jN都不等于k,可以写成第二种情况的形式,只不过这里为了后面的计算方便单独把∑j:j≠k ρk→k(j)∑j:j≠k ρk→k(j) 这一项写出来了。
如果我们把这些向量信息看成是相对于cici 的不变量和变量的乘积,那么问题会变得更加简单,也就是说
ρi→k(ci)=ρ¯i→k⋅ρ˜i′→k(ci)ρi→k(ci)=ρ¯i→k⋅ρ~i′→k(ci)
αi←k(ci)=α¯i←k⋅α˜i←k(ci)αi←k(ci)=α¯i←k⋅α~i←k(ci)
.
因此,我们上面的计算responsibilities的式子变换为:

相应的计算availabilities的式子 
为了方便,可以设定常量的部分为一个固定值,也就是:
ρ¯i→k=∑j:j≠kρi→k(j)ρ¯i→k=∑j:j≠kρi→k(j)
这样一来,变量的部分必须满足:
∑j:j≠kρ˜i→k(j)=1∑j:j≠kρ~i→k(j)=1
因为它们连乘要等于原来的数,而常量部分已经等于原来的数了,所以变量部分必须为1。因此我们又可以进一步得出
∑j=ρ˜i→k(j)=1+ρ˜i→k(k)∑j=ρ~i→k(j)=1+ρ~i→k(k)
另外,可以发现,在αi←k(ci)αi←k(ci)中没有表达式直接包含cici,而依赖于它的是表达式的选择。
对应的,N维向量αi←k(ci)αi←k(ci)只有两个不同的值:
一个是ci=kci=k,一个是ci≠kci≠k。
设定α¯i←k=αi←k(ci:ci≠k)α¯i←k=αi←k(ci:ci≠k),这会使得所有的α˜i←k(ci)=1α~i←k(ci)=1(ci≠kci≠k)
(理解这个式子,发出信息的函数结点 不等于 变量的标签)
从而,我们可以推导出在这两种情况下的变化:
(1)对于所有的ci≠kci≠k:
∏k′:k′≠kα˜i←k′(ci)=α˜i←ci(ci)∏k′:k′≠kα~i←k′(ci)=α~i←ci(ci)
这个式子容易理解,由于上面的设定,发出信息的函数结点(availability 信息传递是从函数结点到变量结点)的变量部分当k′≠cik′≠ci(当然也不等于k)时就会得到1,所以所有不是k也不是cici的函数结点发给变量结点i的乘积为1。
换言之,用更通俗的说法就是,发出结点如果和标签值cici是不同的,那么其值就是1,发出结点我们确定了不为k, 然而我们并不能肯定它是否为cici, 因为k≠cik≠ci, 所以,最后只剩下cici这个函数结点发出的部分了。
(2)对于ci=kci=k
需要满足
∏k′:k′≠kα˜i←k′(ci)=1∏k′:k′≠kα~i←k′(ci)=1
我们自然可以得出,只用排除一种情况,那就是发出结点k′k′不为k,由于k和cici相同,它自然也不等于函数的标签。因此各项都是1,相乘自然也是1。
公式的变形
得到上面的结论后,我们对之前的公式可以进一步的简化。 
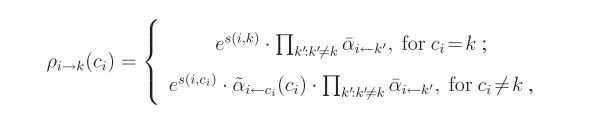
同样对于availabilities的变化。 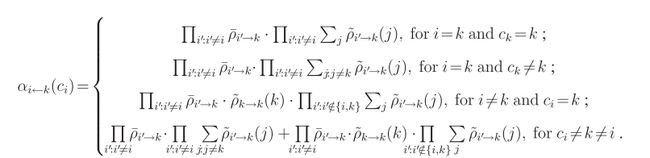

现在,我们可以将之前的表达式再换一种形式
ρi→k(ci)=ρ¯i→k⋅ρ˜i′→k(ci)ρi→k(ci)=ρ¯i→k⋅ρ~i′→k(ci)
返回来写:
ρ˜i→k(ci=k)=ρi→k(ci=k)ρ¯i→kρ~i→k(ci=k)=ρi→k(ci=k)ρ¯i→k
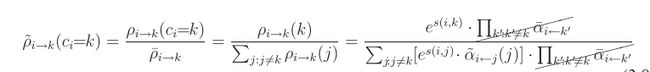
同理,对于α˜α~也可以重新改写其形式:

从上面式子中可以看出,由于常量的巧妙设置,在ci=kci=k 的变量部分,其实分别等于对应的上面的公式中第一种情况/第二种情况, 第三种情况/第四种情况。
进一步我们又可以消除其中的常量项。
O(N3)标量信息更新O(N3)标量信息更新
上面我们最后的计算部分,其实没有包含ci≠kci≠k的部分,那是因为我们已经计算了。
当ci≠kci≠k时,ρ˜i→k(ci)ρ~i→k(ci)和α˜i←k(ci)α~i←k(ci)在实际更新中都没有用到,具体说来,由于α˜i←k(ci≠k)=1α~i←k(ci≠k)=1,我们其实可以考虑用一个标量来表示信息,而不必要用到一个N维的矢量。考虑到数值范围的问题,在log domain来工作,我们将从变量结点到函数结点的标量定义为:er(i,k)=ρ˜i→k(k)er(i,k)=ρ~i→k(k),而从函数结点到变量结点的标量定义为:ea(i,k)=α˜i←k(k)ea(i,k)=α~i←k(k)。
代入上一节的公式,我们可以得到。 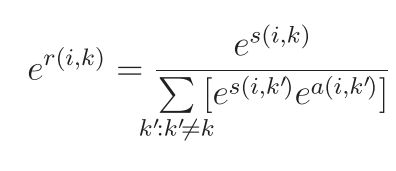

r(i,k)表示成responsibility,表示从数据点i到候选代表点k,代表着在同时考虑除去k的候选的代表点的evidence的和的情况下,k有多适合作为i的代表点。
a(i,k)表示成availability,综合考虑别的同样认为k适合作为代表点的数据点的信息,k有多适合作为i的代表点。
所有的数据点要不然就是一般的数据点,要不然就是代表点,取决于它们是在发送\接收 availability\responsibility 信息。
在若干轮的迭代后,我们要评估变量cici的值,通过将所有输入给变量结点cici 的信息的乘积,然后求使它最大值的j。 
另一种包含了availabilities 和responsibilities但是没有包括输入的相似度做法,可以通过在分子分母乘以一个常量获得,最终结果是不会改变的 
O(N2)O(N2)标量信息更新
在每一轮迭代中,包含了计算N2N2条availability以及responsibility信息的计算(就是N个点到N个点,所以是N^2),而在公式: 
中,每一条信息的更新都需要O(N)O(N)的计算量,所以整个网络一次迭代的计算量为O(N3)O(N3)。如果我们把表达式中一些中间值定义为:
R(i)=∑k′=1Nes(i,k′)+a(i,k′)R(i)=∑k′=1Nes(i,k′)+a(i,k′)
A(k)=∏i′=1N[1+er(i′,k)]A(k)=∏i′=1N[1+er(i′,k)]
这样之前的公式可以重新写成: 

而这些累加和累积的运算,我们在迭代的开始可以全部算出,时间复杂度为O(N2)O(N2),随后的信息更新就可以在O(1)O(1)的时间完成。这将使得整个算法的时间复杂度为O(N2)O(N2)
然而,在实际应用中,这种算法可能会导致数值上的不稳定。这是因为我们在计算∑k′≠kes(i,k′)+a(i,k′)∑k′≠kes(i,k′)+a(i,k′)时,用R(i)−es(i,k)+a(i,k)R(i)−es(i,k)+a(i,k), 计算机数值的精度有限。为了克服这个问题,我们需要存储和的累积值,同时修改相应的计算R(k)R(k)和A(k)A(k)的表达式。
2. Max-Product Affinity Propagation
引入Max-Product 算法,我们可以克服数值精度的问题,同时我们还能使得聚类结果对输入的similarities具有不变性,不会因为加入一个常数项而改变——
什么意思呢?对于sum-product affinity propagation,只有在responsibilities的计算公式中用到了 similarities,在指数的位置加入一个常数项,相当于分子坟墓各乘以一个常数项,对结果没有影响。
er(i,k)=es(i,k)/∑k′:k′≠k[es(i,k′)ea(i,k′)]=es(i,k)+constant/∑k′:k′≠k[es(i,k′)+constantea(i,k′)]er(i,k)=es(i,k)/∑k′:k′≠k[es(i,k′)ea(i,k′)]=es(i,k)+constant/∑k′:k′≠k[es(i,k′)+constantea(i,k′)]
在max-product 中,还增加了一个特点,对乘常数也是具有不变性的。(后文会解释)
相比sum-product的算法,变量结点到函数结点的信息在max-product中是不变的。
ρi→k(ci)=es(i,ci)⋅∏k′:k′≠kαi←k′(ci)ρi→k(ci)=es(i,ci)⋅∏k′:k′≠kαi←k′(ci)
但是,外面的求和符号替换为max运算符。 
这4种情况的讨论和上文大同小异,前三个公式都可以直接用max运算符替换求和运算符,所不同的最后一个公式,不再是把两种ck=kck=k和ck≠kck≠k两种情况加起来,而是求它们二者的较大值。为了方便读者阅读,我再把上文的公式,对应的贴一遍: 
和sum-product中算法相同,将它们表示成常量和变量的乘积。
ρi→k(ci)=es(i,ci)⋅∏k′:k′≠kα¯i←k′⋅∏k′:k′≠kα˜i←k(ci)ρi→k(ci)=es(i,ci)⋅∏k′:k′≠kα¯i←k′⋅∏k′:k′≠kα~i←k(ci)

随后设定ρ¯i→k=maxj:j≠kρi→k(j)ρ¯i→k=maxj:j≠kρi→k(j)
从而得到:maxj:j≠kρ˜i→k(j)=1maxj:j≠kρ~i→k(j)=1.
对于这一步博主的理解是:
ρi→k(ci)=ρ¯i→k⋅ρ˜i′→k(ci)ρi→k(ci)=ρ¯i→k⋅ρ~i′→k(ci)
maxρi→k(ci)=ρ¯i→k⋅maxρ˜i′→k(ci)maxρi→k(ci)=ρ¯i→k⋅maxρ~i′→k(ci)
所以可得
maxj:j≠kρ˜i→k(j)=1maxj:j≠kρ~i→k(j)=1
.
Dueck大牛博士论文这里是有错误的,写成了等于0;
就是说当j不为k时,从变量结点i发送到函数结点k的信息,在标签为j时,它等于0,所以再加上j=kj=k的情况就可以综合得到:
maxjρ˜i→k(j)=max[1,ρ˜i→k(k)]maxjρ~i→k(j)=max[1,ρ~i→k(k)]
对于availabilities的部分,可以设定α¯i←k=αi←k(ci:ci≠k)α¯i←k=αi←k(ci:ci≠k)。这会使得α˜i←k(ci)=1α~i←k(ci)=1对于ci≠kci≠k
和我们上节同样的推理过程,可以得到:
(1) 当ci≠kci≠k时
∏k′:k′≠kα˜i←k′(ci)=α˜i←ci(ci)∏k′:k′≠kα~i←k′(ci)=α~i←ci(ci)
(2) 当ci=kci=k时
∏k′:k′≠kα˜i←k′(k)=1∏k′:k′≠kα~i←k′(k)=1
所以可以得到和上文相同的化简形式: 
以及: 
同样为了方便读者对比,我把sum-product 对应的公式也得出来,可以发现改变的地方是微小的。
再接下来的步骤,想必大家也知道了,我们知道在ci≠kci≠k时的变量部分,现在要求出在ci=kci=k 时的变量部分,而这是一个so easy 的约分的过程,具体推导参考上节。
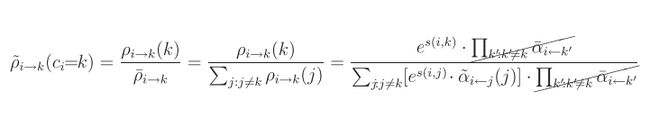

定义r(i,k)=logρ˜i→k(k)r(i,k)=logρ~i→k(k)
a(i,k)=logα˜i←k(k)a(i,k)=logα~i←k(k)
第一个公式变成
∀i,k:r(i,k)=s(i,k)−maxk′:k′≠k[s(i,k′)+a(i,k′)]∀i,k:r(i,k)=s(i,k)−maxk′:k′≠k[s(i,k′)+a(i,k′)]
我们再来看第二个公式,当k=i时
log(∏i′:i′≠imax[1,ρ˜i′→k(k)])=∏i′:i′≠imax[log(1),log(ρ˜i′→k(k))]=∑i′:i′≠imax[0,r(i′,k)]log(∏i′:i′≠imax[1,ρ~i′→k(k)])=∏i′:i′≠imax[log(1),log(ρ~i′→k(k))]=∑i′:i′≠imax[0,r(i′,k)]
当k≠ik≠i时,由于我们存在
logxmax(1,x)=min(0,log x)logxmax(1,x)=min(0,log x)
所以可以得到:
∀i,k:a(i,k)=min[0,r(k,k)+∑i′:i′∉{i,k}max(0,r(i′,k))]∀i,k:a(i,k)=min[0,r(k,k)+∑i′:i′∉{i,k}max(0,r(i′,k))]
Affinity propagation算法
我们可以总结,整个算法的流程如下: 
参考文献:
Affinity propagation: clustering data by passing messages(多伦多大学博士论文)