AP(affinity propagation)聚类算法
AP(affinity propagation)聚类算法
引言
- AP(affinity propagation)聚类算法是用来解决什么问题的
- AP(affinity propagation)聚类算法具体是怎么实现的
- AP(affinity propagation)聚类算法的问题与改进
AP(affinity propagation)聚类算法是用来解决什么问题的
聚类(Clustering)是按照某个特定标准(如距离)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。也即聚类后同一类的数据尽可能聚集到一起,不同类数据尽量分离。
AP算法名称算法名称:Affinity Propagation ,通常被翻译为近邻传播算法或者亲和力传播算法, 来自论文:Clustering by Passing Messages Between Data Points 著者:Brendan J. Frey and Delbert Dueck 大体思想:通过在点之间不断地传递信息,最终选出代表元以完成聚类。
AP聚类的优点:
- 不需要制定最终聚类族的个数
- 已有的数据点作为最终的聚类中心,而不是新生成一个簇中心。
- 模型对数据的初始值不敏感。
- 对初始相似度矩阵数据的对称性没有要求。
- 相比与k-centers聚类方法,其结果的平方差误差较小。
AP(affinity propagation)聚类算法具体是怎么实现的
基本思想
标准 AP 聚类算法是通过在所给定的数据集中的数据点之间迭代传送吸引度信息和归属度信息来达到高效、准确的数据聚类目的。
他基于数据点间的"信息传递"的一种聚类算法,把一对数据点之间的相似度作为输入,在数据点之间交换真实有价值的信息,直到一个最优的类代表点集合(称为聚类中心或者examplar)和聚类逐渐形成。此时所有的数据点到其最近的类代表点的相似度之和最大。
与k-均值算法或k中心点算法不同,AP算法不需要在运行算法之前确定聚类的个数,他所寻找的"examplars"就是聚类中心点,同时也是数据集合中实际存在的点,作为每类的代表。
AP聚类的一些相关名词介绍
-
Exemplar:指的是聚类中心,类似于K-Means中的质心。
-
Similarity:数据点i和点j的相似度记为s(i, j),是指点j作为点i的聚类中心的相似度。一般使用欧氏距离来计算,一般点与点的相似度值全部取为负值;因此,s(i, j)相似度值越大说明点i与点j的距离越近,AP算法中理解为数据点j作为数据点i的聚类中心的能力。
-
Preference:数据点i的参考度称为p(i)或s(i,i),是指点i作为聚类中心的参考度。若按欧氏距离计算其值应为0,但在AP聚类中其表示数据点i作为聚类中心的程度,因此不能为0。迭代开始前假设所有点成为聚类中心的能力相同,因此参考度一般设为相似度矩阵中所有值得最小值或者中位数,但是参考度越大则说明个数据点成为聚类中心的能力越强,则最终聚类中心的个数则越多;
-
Responsibility:r(i,k)用来描述点k适合作为数据点i的聚类中心的程度。从点i发送至候选聚类中心点k,反映了在考虑其他潜在聚类中心后,点k适合作为点i的聚类中心的程度。
-
Availability:a(i,k)用来描述点i选择点k作为其聚类中心的适合程度。从候选聚类中心点k发送至点i,反映了在考虑其他点对点k成为聚类中心的支持后,点i选择点k作为聚类中心的合适程度。
-
Damping factor(阻尼系数):为了避免振荡,AP算法更新信息时引入了衰减系数 λ。每条信息被设置为它前次迭代更新值的 λ 倍加上本次信息更新值的1-λ倍。其中,衰减系数 λ 是介于0到1之间的实数。
在实际计算应用中,最重要的两个参数(也是需要手动指定):
- Preference - 影响聚类数量的多少,值越大聚类数量越多
- Damping factor - 控制算法收敛效果
算法描述
假设 { x 1 , x 2 , ⋯ , x n } \{x_1,x_2,⋯,x_n\} {x1,x2,⋯,xn}数据样本集,数据间没有内在结构的假设。令 s s s是一个刻画点之间相似度的矩阵,使得 s ( i , j ) > s ( i , k ) s(i,j)>s(i,k) s(i,j)>s(i,k)当且仅当 x i x_i xi与 x j x_j xj的相似性程度要大于其与 x k x_k xk的相似性。
AP算法进行交替两个消息传递的步骤,以更新两个矩阵:
- 吸引信息(responsibility)矩阵R: r ( i , k ) r(i,k) r(i,k)描述了数据对象k适合作为数据对象i的聚类中心的程度,表示的是从i到k的消息
- 归属信息(availability)矩阵A: a ( i , k ) a(i,k) a(i,k)描述了数据对象i选择数据对象k作为其据聚类中心的适合程度,表示从k到i的消息
一开始将两个矩阵R ,A全部初始化为0。
接着我们通过以下步骤迭代进行更新:
-
首先,吸引信息(responsibility) r t + 1 ( i , k ) r_{t+1}(i,k) rt+1(i,k)按照
r t + 1 ( i , k ) ← s ( i , k ) − max k ′ s . t . k ′ ≠ k { a t ( i , k ′ ) + s ( i , k ′ ) } {r_{t + 1}}(i,k) \leftarrow s(i,k) - \mathop {\max }\limits_{k' s.t. k'\ne k} \{ {a_t}(i,k') + s(i,k')\} rt+1(i,k)←s(i,k)−k′s.t.k′=kmax{at(i,k′)+s(i,k′)}
的迭代。其中 a ( i , k ′ ) a(i,k') a(i,k′)表示除 k k k外其他点对 i i i点的归属度值,初始为0; s ( i , k ′ ) s(i,k') s(i,k′)表示除* k k k外其他点对 i i i的吸引度,即i外其他点都在争夺i点的所有权; r ( i , k ) r(i,k) r(i,k)表示数据点k成为数据点i*的聚类中心的累积证明, r ( i , k ) r(i,k) r(i,k)值大于0,则表示数据点 k k k成为聚类中心的能力强。说明:此时只考虑哪个点 k k k成为点i的聚类中心的可能性最大,但是没考虑这个吸引度最大的 k k k是否也经常成为其他点的聚类中心(即归属度),若点 k k k只是点 i i i的聚类中心,不是其他任何点的聚类中心,则会造成最终聚类中心个数大于实际的中心个数。 -
然后,归属信息(availability) a t + 1 ( i , k ) a_{t+1}(i,k) at+1(i,k)按照
a t + 1 ( i , k ) ← min { 0 , r t ( k , k ) + ∑ i ′ s . t . i ′ ∉ { i , k } max { 0 , r t ( i ′ , k ) } } , i ≠ k {a_{t + 1}}(i,k) \leftarrow {\min } \{ {0,{r_t}(k,k) + \sum\limits_{i' s.t.i' \notin \{ i,k\} } {\max \{ 0,{r_t}(i',k)\} } } \},i \ne k at+1(i,k)←min{0,rt(k,k)+i′s.t.i′∈/{i,k}∑max{0,rt(i′,k)}},i=k
和
a t + 1 ( k , k ) = ∑ i ′ s . t . i ′ ∉ { i , k } max { 0 , r t ( i ′ , k ) } , i = k {a_{t+1}}(k,k) = \sum\limits_{i' s.t.i' \notin \{ i,k\} } {\max \{ 0,{r_t}(i',k)\} },i=k at+1(k,k)=i′s.t.i′∈/{i,k}∑max{0,rt(i′,k)},i=k
迭代.其中 r ( i ′ , k ) r(i',k) r(i′,k)表示点 k k k作为除 i i i外其他点的聚类中心的相似度值,取所有大于等于0的吸引度值,加上 k k k作为聚类中心的可能程。即点 k k k在这些吸引度值大于0的数据点的支持下,数据点 i i i选择 k k k作为其聚类中心的累积证明。 -
对以上步骤进行迭代,如果这些决策经过若干次迭代之后保持不变或者算法执行超过设定的迭代次数,又或者一个小区域内的关于样本点的决策经过数次迭代后保持不变,则算法结束。
为了避免振荡,AP算法更新信息时引入了衰减系数 λ \lambda λ。每条信息被设置为它前次迭代更新值的 λ \lambda λ倍加上本次信息更新值的 1 − λ 1-\lambda 1−λ倍。其中,衰减系数 λ \lambda λ是介于0到1之间的实数,一般取0.5。即第 t + 1 t+1 t+1次 r ( i , k ) r(i,k) r(i,k), a ( i , k ) a(i,k) a(i,k)的迭代值:
r t + 1 ( i , k ) ← ( 1 − λ ) ∗ r t + 1 ( i , k ) + λ ∗ r t ( i , k ) r_{t+1}(i,k)\leftarrow(1-\lambda)*r_{t+1}(i,k)+\lambda*r_t(i,k) rt+1(i,k)←(1−λ)∗rt+1(i,k)+λ∗rt(i,k)
a t + 1 ( i , k ) ← ( 1 − λ ) ∗ a t + 1 ( i , k ) + λ ∗ a t ( i , k ) a_{t+1}(i,k)\leftarrow(1-\lambda)*a_{t+1}(i,k)+\lambda*a_t(i,k) at+1(i,k)←(1−λ)∗at+1(i,k)+λ∗at(i,k)
通俗解释
可以用一个比喻来理解这两个量和其之间交替过程:选举。
将聚类过程看成选举:
假设我们有n个数据,需要进行聚类,我们可以想象为有n个人,要投票投出几个leader来,那么怎么投票呢?
- 所有人都参加选举(大家都是选民也都是参选人),要选出几个作为代表
- s ( a , b ) s(a,b) s(a,b)就相当于a对选b这个人的一个熟悉程度,或者说是偏好程度
- r ( a , b ) r(a,b) r(a,b)表示用 s ( a , b ) s(a,b) s(a,b)减去最强竞争者的评分,可以理解为b在对a这个选民的竞争中的优势程度
- r ( a , b ) r(a,b) r(a,b)的更新过程对应选民a对各个参选人的挑选(越出众越有吸引力)
- a ( a , b ) a(a,b) a(a,b):从公式里可以看到,所有 r ( a ′ , b ) > 0 r(a',b)>0 r(a′,b)>0的值都对a有正的加成。对应到我们这个比喻中,就相当于选民a通过网上关于b的民意调查看到:有很多人(即 a ′ a' a′们)都觉得b不错( r ( a ′ , b ) > 0 r(a',b)>0 r(a′,b)>0),那么选民a也就会相应地觉得b不错,是个可以相信的选择
- a ( a , b ) a(a,b) a(a,b)的更新过程对应关于参选人b的民意调查对于选民i的影响(已经有了很多跟随者的人更有吸引力)
- 两者交替的过程也就可以理解为选民在各个参选人之间不断地比较和不断地参考各个参选人给出的民意调查。
- r ( a , b ) r(a,b) r(a,b)这个吸引度矩阵反映的是竞争, a ( a , b ) a(a,b) a(a,b)归属度矩阵则是为了让聚类更成功。
首先任何人之间有一个固定的映像了,比如a和b比较熟悉,或者a比较认可b,那么a投票投给b的可能性就大一点。那么我们用 s s s矩阵 s [ a , b ] s[a,b] s[a,b]表示a和b的,这个是已经存在的了。(那么对应到数据里面就是a和b的相似度)
现在开始投票:
第一个阶段(投票)( r r r矩阵的更新):
r t + 1 ( i , k ) ← s ( i , k ) − max k ′ s . t . k ′ ≠ k { a t ( i , k ′ ) + s ( i , k ′ ) } {r_{t + 1}}(i,k) \leftarrow s(i,k) - \mathop {\max }\limits_{k' s.t. k'\ne k} \{ {a_t}(i,k') + s(i,k')\} rt+1(i,k)←s(i,k)−k′s.t.k′=kmax{at(i,k′)+s(i,k′)}
甲在投票的时候,每一个人都会仔细考虑。在考虑要不要投给乙的时候,就会有其他人丙来告诉甲,“如果你投了我的话,我会给你什么什么好处,而且你看,有这么些个人有意向投给我(这时就向甲展示有谁谁谁有意向投给丙,这个值就是算法中的 a [ ] a[] a[])”
于是甲在经过考虑和听取了所有来向他介绍的人之后,就告诉乙,“我本来投给你的意向是什么什么,在经过考虑之后,现在我投给你的意向是什么什么”。
甲就轮流这样告诉所有人。

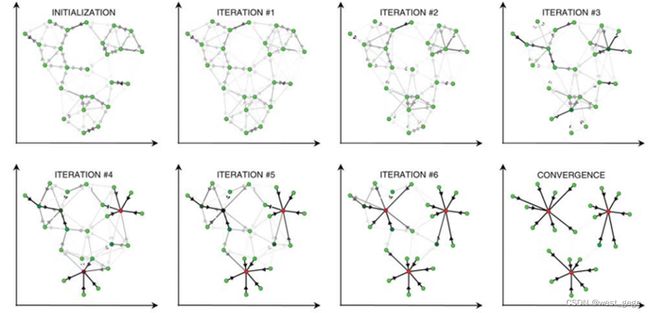
比如上面这张图,Data point i 的红色的线段就是告诉别人我投给你的意向是多少,黑色的线段就是听取了别人的游说。
第二个阶段(拉票)( a a a矩阵的更新):
KaTeX parse error: Limit controls must follow a math operator at position 38: …tarrow {\min }\̲l̲i̲m̲i̲t̲s̲_{} \{ {0,{r_t}…
这一个是每一个人拉票的阶段,他会统计上一次投票的时候有多少人有意愿投给我,统计完之后就会告诉选民们,你看,有这么多人选择支持我,说明我很厉害,你们投票投我吧~~~~~。

上面这幅图就是拉票的阶段,红色的线段是k向i拉票,黑色的线段是 k k k在收集民意。
结束
经过很多轮的投票和拉票的阶段之后,直到这个leader选出来了,大家都不再有意见了,或者超过一定的轮数了,就结束。
代码分析
N=size(S,1);A=zeros(N,N);R=zeros(N,N);% initialize messages
S=S+le-12*randn(N,N)*(max(S(:))-min(S(:)));% remove degeneracies
lambda=0.9;% set dampening factor
for iter=1:100,
Rold=R; % NOW COMPUTE RESPONSIBILITIES
AS=A+S;[Y, I]=max(AS,[],2);
for i=1:N,AS(i,I(i))=-inf;end;[Y2,I2]=max(AS,[],2);
R=S-repmat(Y,[1,N]);
for i=1:N,R(i,I(i))=S(i,I(i))-Y2(i); end;
R=(1-lambda)*R+lambda*Rold;% dampening responsibilities
Aold=A;% NOW COMPUTE AVAILABILITIES
Rp=max(R,0); for k=1:N,Rp(k,k)=R(k,k); end;
A=repmat(sum(Rp,1),[N,1])-Rp;
dA=diag(A);A=min(A,0);for k=1:N,A(k,k)=dA(k); end;
A=(1-lambda)*A+lambda*Aold;% dampening availabilities
end;
E=R+A;% pseudomarginals
I=find(diag(E)>0);K=length (I);% indices of exemplars
[tmp,c]=max(S(:,I),[],2);c(I)=1:K;idx=I(c);% assignments
S为一个N×N的相似度矩阵,N为数据点的数目,A和R都初始化为N×N的相似度矩阵。
第二行的作用是,主要为了防止振荡, 该情况的发生如S是一个对称矩阵,那么a点作为b点的代表点或是相反,二者计算出来的值是一样的,那么就会引起振荡。另外一种情况,假如我们的S是一个整数矩阵,算法可能会得到多个具有相同的网相似度的求解,算法也可能在这几个解之间振荡。通过在S上添加机器精度级的随机噪声有助于避免这种情况。
dampening的设置也是为了防止振荡。
算法设定的迭代次数为100次,没有early stop的步骤。但是这个显然是可以优化的。
r t + 1 ( i , k ) ← s ( i , k ) − max k ′ s . t . k ′ ≠ k { a t ( i , k ′ ) + s ( i , k ′ ) } {r_{t + 1}}(i,k) \leftarrow s(i,k) - \mathop {\max }\limits_{k' s.t. k' \ne k} \{ {a_t}(i,k') + s(i,k')\} rt+1(i,k)←s(i,k)−k′s.t.k′=kmax{at(i,k′)+s(i,k′)}
第6行~第7行,首先计算a+s,随后第一个max求出每一行的最大值,以及通过对最大值赋值为无穷小,同时得出次大值。把行看成对应i,把列看成对应为k’。之所以这么做是用到了一个trick,就是如果k对应的是最大值,那么我们在随后第9行的赋值,使得最终使用的次大值,也就是 k ′ ≠ k k'\neq k k′=k时的结果。而如果k对应的不是最大值,最终使用最大值的结果,仍然满足 k ′ ≠ k k'\neq k k′=k中最大值的要求。
举个例子 ,假设我们固定i=1,这一行的s(i,k)+a(i,k)依次为:
1 5 2 3 4 这时最大值为5,4是次大值,此时我们计算方法为:
| k=1 | k=2 | k=3 | k=4 | k=5 |
|---|---|---|---|---|
| s(1,1)-5 | s(1,2)-5 | s(1,3)-5 | s(1,4)-5 | s(1,3)-5 |
随后对最大项下标对应位置2重新赋值为:s(1,2)-4
| k=1 | k=2 | k=3 | k=4 | k=5 |
|---|---|---|---|---|
| s(1,1)-5 | s(1,2)-4 | s(1,3)-5 | s(1,4)-5 | s(1,3)-5 |
就是除去该列之外的最大值。
dampenling 是为了避免数值上的震荡,所以使用了一定的权值来进行平滑的过度。一般设定在[0.5,1)之间。
KaTeX parse error: Limit controls must follow a math operator at position 38: …tarrow {\min }\̲l̲i̲m̲i̲t̲s̲_{} \{ {0,{r_t}…
a t + 1 ( k , k ) = ∑ i ′ s . t . i ′ ∉ { i , k } max { 0 , r t ( i ′ , k ) } , i = k {a_{t+1}}(k,k) = \sum\limits_{i' s.t.i' \notin \{ i,k\} } {\max \{ 0,{r_t}(i',k)\} },i = k at+1(k,k)=i′s.t.i′∈/{i,k}∑max{0,rt(i′,k)},i=k
先理解公式,对于每一列,计算的是来自除去矩阵对角线的所有正值元素的和,如果不为对角线,再加上self-responsibility。
再来看第12~第14行,对角线的计算方法不同。所以矩阵中每个元素与0比较取较大值,得到仅是一个正值的矩阵,但是对角线的元素保持不变。随后对每一列求和。
假设k=1,a(i=1:5,1)= 1 2 3 4 5
(1)当i=1时,i=k 按公式10计算。
a(1,1)=ar1,1)+a(2,1)+a(3,1)+a(4,1)+a(5,1) - a(1,1) 而代码13行做的就是这件事。所以最终a矩阵对角线上的元素即为代码13行计算出的A矩阵的对角线上的元素,因此14行对其进行了存储。
(2)当i=2时, i ≠ k i \neq k i=k,此时按公式9计算。
其实Rp相当于 max { 0 , r t ( i ′ , k ) } {\max \{ 0,{r_t}(i',k)\} } max{0,rt(i′,k)} ,
代码sum(Rp,1) 相当于 ∑ i ′ ≠ k m a x [ 0 , r ( i ′ , k ) ] + r ( k , k ) \sum_{i'\neq k}max[0,r(i',k)]+r(k,k) ∑i′=kmax[0,r(i′,k)]+r(k,k),又等于
∑ i ′ ≠ k , i ′ ≠ i m a x [ 0 , r ( i ′ , k ) ] + r ( k , k ) + m a x [ r ( i , k ) , 0 ] \sum_{i'\neq k,i'\neq i}max[0,r(i',k)]+r(k,k)+max[r(i,k),0] ∑i′=k,i′=imax[0,r(i′,k)]+r(k,k)+max[r(i,k),0],
在第十三行减去Rp,即对应于 ∑ i ′ ≠ k , i ′ ≠ i m a x [ 0 , r ( i ′ , k ) ] + r ( k , k ) + m a x [ r ( i , k ) , 0 ] − m a x [ r ( i , k ) , 0 ] \sum_{i'\neq k,i'\neq i}max[0,r(i',k)]+r(k,k)+max[r(i,k),0]-max[r(i,k),0] ∑i′=k,i′=imax[0,r(i′,k)]+r(k,k)+max[r(i,k),0]−max[r(i,k),0],
所以非对角线的元素,可以直接用第14行代码计算得出。
最后两行,是划定每个数据点所属的代表点。首先获得代表点的下标,通过 a ( i , i ) + r ( i , i ) > 0 a(i,i)+r(i,i)>0 a(i,i)+r(i,i)>0来判断,然后比较每一个数据点距离哪一个代表点距离最近,对代表点的赋值为从1到k,对数据点的赋值为代表点的标签。
[tmp c]=max(S(:,I),[],2);% 注意c是相对于选出代表集的列之后的子集的坐标
c(I)=1:K; % 代表点的标签赋值为1到K
idx = I(c); % 对应回原始的列下标,也就是数据点的标签
以下以最简单的六个点进行聚类为例,分析AP算法实现的基本步骤和核心思想:
clear all;close all;clc; %清除所有变量,关闭所有窗口, 清除命令窗口的内容
x=[1,0; %定义一个矩阵
1,1;
0,1;
4,1;
4,0;
5,1];
N=size(x,1); %N为矩阵的列数,即聚类数据点的个数
M=N*N-N; %N个点间有M条来回连线,考虑到从i到k和从k到i的距离可能是不一样的
s=zeros(M,3); %定义一个M行3列的零矩阵,用于存放根据数据点计算出的相似度
j=1; %通过for循环给s赋值,第一列表示起点i,第二列为终点k,第三列为i到k的负欧式距离作为相似度。
for i=1:N
for k=[1:i-1,i+1:N]
s(j,1)=i;s(j,2)=k;
s(j,3)=-sum((x(i,:)-x(k,:)).^2);
j=j+1;
end;
end;
p=median(s(:,3)); %p为矩阵s第三列的中间值,即所有相似度值的中位数,用中位数作为preference,将获得数量合适的簇的个数
tmp=max(max(s(:,1)),max(s(:,2))); %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
S=-Inf*ones(N,N); %-Inf负无穷大,定义S为N*N的相似度矩阵,初始化每个值为负无穷大
for j=1:size(s,1) %用for循环将s转换为S,S(i,j)表示点i到点j的相似度值
S(s(j,1),s(j,2))=s(j,3);end;
nonoise=1; %此处仅选择分析无噪情况(即S(i,j)=S(j,i)),所以略去下面几行代码
%if ~nonoise %此处几行注释掉的代码是 在details,sparse等情况下时为了避免使用了无噪数据而使用的,用来给数据添加noise
%rns=randn('state');
%randn('state',0);
%S=S+(eps*S+realmin*100).*rand(N,N);
%randn('state',rns);
%end;
%Place preferences on the diagonal of S
if length(p)==1 %设置preference
for i=1:N
S(i,i)=p;
end;
else
for i=1:N
S(i,i)=p(i);
end;
end;
% Allocate space for messages ,etc
dS=diag(S); %%%%%%%%%%%%%%%%列向量,存放S中对角线元素信息
A=zeros(N,N);
R=zeros(N,N);
%Execute parallel affinity propagation updates
convits=50;maxits=500; %设置迭代最大次数为500次,迭代不变次数为50
e=zeros(N,convits);dn=0;i=0; %e循环地记录50次迭代信息,dn=1作为一个循环结束信号,i用来记录循环次数
while ~dn
i=i+1;
%Compute responsibilities
Rold=R; %用Rold记下更新前的R
AS=A+S %A(i,j)+S(i,j)
[Y,I]=max(AS,[],2) %获得AS中每行的最大值存放到列向量Y中,每个最大值在AS中的列数存放到列向量I中

for k=1:N
AS(k,I(k))=-realmax; %将AS中每行的最大值置为负的最大浮点数,以便于下面寻找每行的第二大值
end;
[Y2,I2]=max(AS,[],2); %存放原AS中每行的第二大值的信息
R=S-repmat(Y,[1,N]); %更新R,R(i,k)=S(i,k)-max{A(i,k')+S(i,k')} k'~=k 即计算出各点作为i点的簇中心的适合程度
for k=1:N %eg:第一行中AS(1,2)最大,AS(1,3)第二大,
R(k,I(k))=S(k,I(k))-Y2(k); %so R(1,1)=S(1,1)-AS(1,2); R(1,2)=S(1,2)-AS(1,3); R(1,3)=S(1,3)-AS(1,2).............
end; %这样更新R后,R的值便表示k多么适合作为i 的簇中心,若k是最适合i的点,则R(i,k)的值为正
lam=0.5;
R=(1-lam)*R+lam*Rold; %设置阻尼系数,防止某些情况下出现的数据振荡
%Compute availabilities
Aold=A;
Rp=max(R,0) %除R(k,k)外,将R中的负数变为0,忽略不适和的点的不适合程度信息
for k=1:N
Rp(k,k)=R(k,k);
end;
A=repmat(sum(Rp,1),[N,1])-Rp %更新A(i,k),先将每列大于零的都加起来,因为i~=k,所以要减去多加的Rp(i,k)

dA=diag(A);
A=min(A,0); %除A(k,k)以外,其他的大于0的A值都置为0
for k=1:N
A(k,k)=dA(k);
end;
A=(1-lam)*A+lam*Aold; %设置阻尼系数,防止某些情况下出现的数据振荡
%Check for convergence
E=((diag(A)+diag(R))>0);
e(:,mod(i-1,convits)+1)=E; %将循环计算结果列向量E放入矩阵e中,注意是循环存放结果,即第一次循环得出的E放到N*50的e矩阵的第一列,第51次的结果又放到第一列
K=sum(E); %每次只保留连续的convits条循环结果,以便后面判断是否连续迭代50次中心簇结果都不变。%%%%%%%%%%%%%%%%
if i>=convits || i>=maxits %判断循环是否终止
se=sum(e,2); %se为列向量,E的convits次迭代结果和
unconverged=(sum((se==convits)+(se==0))~=N);%所有的点要么迭代50次都满足A+R>0,要么一直都小于零,不可以作为簇中心
if (~unconverged&&(K>0))||(i==maxits) %迭代50次不变,且有簇中心产生或超过最大循环次数时循环终止。
dn=1;
end;
end;
end;
I=find(diag(A+R)>0); %经过上面的循环,便确定好了哪些点可以作为簇中心点,用find函数找出那些簇1中心点,这个简单demo中I=[2,4],
K=length(I); % Identify exemplars %即第二个点和第四个点为这六个点的簇中心
if K>0 %如果簇中心的个数大于0
[~,c]=max(S(:,I),[],2); %取出S中的第二,四列;求出2,4列的每行的最大值,如果第一行第二列的值大于第一行第四列的值,则说明第一个点是第二个点是归属点
c(I)=1:K; % Identify clusters %c(2)=1,c(4)=2(第2个点为第一个簇中心,第4个点为第2个簇中心)
% Refine the final set of exemplars and clusters and return results
for k=1:K
ii=find(c==k); %k=1时,发现第1,2,3个点为都属于第一个簇
[y,j]=max(sum(S(ii,ii),1)); %k=1时 提取出S中1,2,3行和1,2,3列组成的3*3的矩阵,分别算出3列之和取最大值,y记录最大值,j记录最大值所在的列
I(k)=ii(j(1)); %I=[2;4]
end;
[tmp,c]=max(S(:,I),[],2); %tmp为2,4列中每行最大数组成的列向量,c为每个最大数在S(:,I)中的位置,即表示各点到那个簇中心最近
c(I)=1:K; %c(2)=1;c(4)=2;
tmpidx=I(c) %I=[2;4],c中的1用2替换,2用4替换
%(tmpidx-1)*N+(1:N)' %一个列向量分别表示S(1,2),S(2,2),S(3,2),S(4,4),S(5,4),S(6,4)是S矩阵的第几个元素
%sum(S((tmpidx-1)*N+(1:N)')) %求S中S(1,2)+S(2,2)+S(3,2)+S(4,4)+S(5,4)+S(6,4)的和
tmpnetsim=sum(S((tmpidx-1)*N+(1:N)')); %将各点到簇中心的一个表示距离的负值的和来衡量这次聚类的适合度
tmpexpref=sum(dS(I)); %dS=diag(S); %表示所有被选为簇中心的点的适合度之和
else
tmpidx=nan*ones(N,1); %nan Not A Number 代表不是一个数据。数据处理时,在实际工程中经常数据的缺失或者不完整,此时我们可以将那些缺失设置为nan
tmpnetsim=nan;
tmpexpref=nan;
end;
netsim=tmpnetsim; %反应这次聚类的适合度
dpsim=tmpnetsim-tmpexpref; %
expref=tmpexpref; %
idx=tmpidx; %记录了每个点所属那个簇中心的列向量
unique(idx);
fprintf('Number of clusters: %d\n',length(unique(idx)));
fprintf('Fitness (net similarity): %g\n',netsim);
figure; %绘制结果
for i=unique(idx)'
ii=find(idx==i);
h=plot(x(ii,1),x(ii,2),'o');
hold on;
col=rand(1,3);
set(h,'Color',col,'MarkerFaceColor',col);
xi1=x(i,1)*ones(size(ii));
xi2=x(i,2)*ones(size(ii));
line([x(ii,1),xi1]',[x(ii,2),xi2]','Color',col);
end;
axis equal ;
AP(affinity propagation)聚类算法的问题与改进
问题:
AP算法中有两个重要参数:
-
置于相似度矩阵 S S S对角线的偏向参数P
-
迭代中针对R与A更新的阻尼因子 λ \lambda λ。
偏向参数 p ( k ) p(k) p(k)(通常是负数)表示数据点k被选作聚类中心的倾向性,并对哪些类代表会作为最终的聚类中心产生重要影响。根据吸引度R和归属度A的计算公式(1),(2)和(3),可知参数P出现在 R ( k , k ) = p ( k ) − m a x { A ( k , k ′ ) + S ( k , k ′ ) } R(k,k)=p(k)-max\{A(k,k')+S(k,k')\} R(k,k)=p(k)−max{A(k,k′)+S(k,k′)}中。这样,当 p ( k ) p(k) p(k)较大使得 R ( k , k ) R(k,k) R(k,k)较大时, A ( k , k ′ ) A(k,k') A(k,k′)也较大,从而类代表k作为最终聚类中心的可能性较大;同样,当越多的 p ( k ) p(k) p(k)较大时,越多的类代表倾向于成为最终的聚类中心。因此,增大或减小p可以增加或减小AP输出的聚类数目,且AP算法作者推荐在无先验知识时将所有的 p ( k ) p(k) p(k)设定为 p m p_m pm(S中元素的中值)。然而,在许多情况下 p m p_m pm不能使AP算法产生最优的聚类结果,这是由于 p m p_m pm的设定并不是依据数据集本身的聚类结构。此外,p与AP输出的聚类数目之间没有一一对应关系,这使得很难用聚类有效性方法来寻找最有聚类结果(最优类数)。因此,使用AP算法时如何找出最优的聚类结果是尚未解决的问题。
由于AP算法每次迭代都需要更新每个数据点的吸引度值和归属度值,算法复杂度较高,在大数据量下运行时间较长。
参考
- http://xiaqunfeng.cc/2018/04/08/affinity-propagation/
- https://www.dataivy.cn/blog/%E8%81%9A%E7%B1%BB%E7%AE%97%E6%B3%95affinity-propagation_ap/
- https://www.zhihu.com/question/25384514
- https://www.cnblogs.com/huadongw/p/4202492.html
- https://blog.csdn.net/qq_38195197/article/details/78136669
- https://blog.csdn.net/dudubird90/article/details/49948501