使用ENVI+eCognition面向对象分类(1)
1.两景影像分别融合
1.1ENVI用常见的图像融合方法
图像融合是将低空间分辨率的多光谱影像或高光谱影像与高空间分辨率影像重采样生成高空间分辨率多光谱的影像的过程。envi提供六种种图像融合方法。不同的融合方法具有不同融合优缺点,可根据实际情况进行选择。
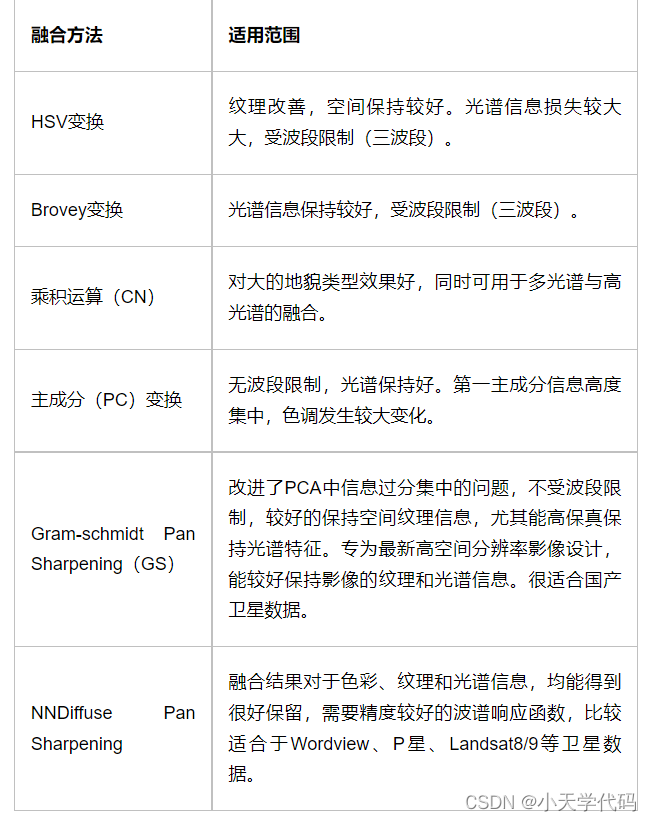
1.HSV变换
首先对RGB图像变换HSV颜色空间,用高分辨率的图像代替颜色亮度值波段,自动用最近邻或双线性或三次卷积技术将色度和饱和度重采样到高分辨率像元尺寸,然后再将图像变换回RGB颜色空间。
2.Brovey变换
对RGB图像和高分辨率数据进行数学合成,从而使图像融合,即RGB图像中的每一个波段都乘以高分辨率数据与RGB图像波段总和的比值。然后自动地用最近邻、双线性或三次卷积技术将3个RGB波段重采样到高分辨率像元尺寸。
3.color normalized (CN) 变换
也被称为能量分离变换(Energy Subdivision Transform),它使用来自融合图像的高空间分辨率(低波谱分辨率)波段对输入图像的低空间分辨率(高波谱分辨率)波段进行增强。该方法仅对包含在融合图像波段的波谱范围内对应的输入波段进行融合,其他输入波段被直接输出而不进行融合处理。融合图像波段的波谱范围由波段中心波长和FWHM(full width-half maximum)值限定,这两个参数都可以在融合图像的ENVI头文件中获得。
根据锐化图像波段的波谱范围,可以将输入图像的波段划分为各个波谱单元。系统按照如下方法对相应的波段单元同时进行处理。每个输入波段乘以融合波段,然后再除以波段单位中的输入波段总数,从而完成归一化:
![]()
该融合方法需要输入图像与融合图像的单位相同(即都为反射率、辐射率、DN值等)。如果融合图像与输入图像的单位相同不同,在融合输出面板中的Sharpening Image Multiplicative Scale Factor文本框中为融合图像键入一个比例系数,使之与输入图像相匹配。例如:如果输入图像是定标为单位(反射率*10000)的整型高光谱文件,但是融合图像是被定标为反射率(0到1)的浮点型多光谱文件,应该输入的比例系数为10,000。如果输入图像单位为辐射率[µW/(cm2 .nm.sr)],而融合图像单位为辐射率[µW/(cm2.m.sr)],应该输入的比例系数为0.001。
4.主成分(PC)变换
第一步,先对多光谱数据进行主成分变换。第二步,用高分辨率波段替换第一主成分波段,在此之前,高分辨率波段已被匹配到第一主成分波段,从而避免波谱信息失真。第三步,进行主成分反变换得到融合图像。

5.Gram-schmidt Pan Sharpening(GS)
第一步,从低分辨率的波段中复制出一个全色波段。第二步,对复制出的全色波段和多波段进行Gram-Schmidt变换,其中全色波段被作为第一个波段。第三步,用高空间分辨率的全色波段替换Gram-Schmidt 变换后的第一个波段。最后,应用Gram-Schmidt反变换得到融合图像。如下为GS融合方法的流程图:

6.NNDiffuse Pan Sharpening融合
NNDiffuse Pan Sharpening是由美国罗彻斯特理工学院(RIT)最新提出的一种融合算法。算法是Nearest Neighbor Diffusion (NNDiffuse) pan sharpening。该工具支持多线程计算,具有高性能处理的特点其。融合结果对于色彩、纹理和光谱信息,均能得到很好保留。
本次实验需要对植被进行分类以及NDVI的计算,所以介绍两种较为合适的方法。
1.2 Gram-Schmidt图像融合
第一步:将低分辨率多光谱数据和高分辨率全色数据载入ENVI软件。

第二步:打开“Gram-Schmidt图像融合”工具。

第三步:输入低分辨率的多光谱图像文件。

第四步:输入高分辨率的全色波段图像文件

第五步:图像的融合和输出参数设置

第六步:融合前后图像对比


以上是对5月份的图像进行的处理,对10月的图像进行相同处理。
1.3 NNDiffuse Pan Sharpening融合
第一步:打开“NNDiffuse Pan Sharpening融合”工具。

第二步:按照提示将融合图像输入进去。其他采用默认值

第三步:得到融合后的图像。

2.两个月份图像进行配准并裁剪
在进行完上一步的融合之后,下面需要将5月份的图像和10月份的图像进行配准为后面的植被分类做准备。这里使用的图像为Gram-Schmidt图像融合得到的图像。
2.1图像配准
通过观察图像发现虽然两份图像的坐标系统是一致的,但是在细节处存在错位的问题。


所以下面对两份图像进行配准工作。由于这两幅图像具有相同的坐标系且差异不大所以这里采用自动配准来进行。
第一步:打开图像配准工具

第二步:基准图像和配准图像可以自由选择。

第三步:自动生成连接点。

默认参数设置能满足大部分的图像配准需求,本练习选择默认参数设置,以下是对三个选项中的参数说明。
匹配算法(Matching Method):提供两种算法,Cross Correlation:一般用于相同形态的图像,如都是光学图像;Mutual Information:一般用于不同形态的图像,如光学-雷达图像,热红外-可见光等。
最小Tie点匹配度阈值(Minimum Matching Score):自动找点功能会给找到的点计算一个分值,分值越高精度越高。当找到的Tie点低于这个阈值,则会自动删除不参与校正。阈值范围0-1。
几何模型(Geometric Model):提供三种过滤Tie点的几何模型,不同模型适用不同类型的图像,以及需要设置不同的参数。
1.Fitting Global Transform:适合绝大部分的图像。还需要设置以下两个参数:
变换模型(Transform):包括一次多项式First-Order Polynomial和放射变化RST。
每个连接点最大允许误差(Maximum Allowable Error Per Tie Point):这个值越大,保留的Tie越多,当精度约差。
2、Frame Central Projection:适合于框幅式中心投影的航空影像数据。
3、Pushbroom Sensor:适合带有RPC文件的图像。
Seed Tie Points选项:
在这个面板中,可以实现对种子点(同名点)的读入、添加或者删除。以下两种情况需要手动选择Seed Tie:
如果待配准影像没有坐标信息,需要手动选择至少3个同名点,即这里的种子点。当基准影像或者待校正影像质量非常差,如地物变化很明显等情况,可以手动选择几个Seed Tie点,这样可以提高自动匹配的精度。

第四步:检查Tie点和待配准图像。对于自动生成Tie点,可以进行编辑。

单击Show Table,![]() 打开Tie点列表,可以对连接点进行编辑,最右列为误差值,右键选择Sort by selected column reverse安装误差排序,可以直接删除误差较大的点。
打开Tie点列表,可以对连接点进行编辑,最右列为误差值,右键选择Sort by selected column reverse安装误差排序,可以直接删除误差较大的点。

第五步:输出图像配准的结果


2.2图像裁剪
在envi中将配准好的两份图像另存为,注意在另存为较大区域的图像时,使用空间裁剪将其裁剪与区域小的图像一致。

3.五月影像单独监督分类
3.1创建工程
1.打开影像
点击![]() 创建一个新工程,选择处理好的影像。注意数据必须是在英文路径下,且工程名称也应为英文。
创建一个新工程,选择处理好的影像。注意数据必须是在英文路径下,且工程名称也应为英文。
2.编辑图层名称
影像导入之后,可以看到一共有五个图层。下面我们根据影像的命名给它们重命名,选中 Layer1,点击 Edit 按钮或双击 Layer1,弹出 Layer Properties 对话框,按照下图进行修改。

3.影像显示效果
勾选上Windows下的Split Horizontally和Side by Side View创建出上下两个视图,分别点击 ,编辑波段组合方式设置均衡化效果,使用 RGB 模式来组合波段进行显示。
3.2影像分割
1.创建进程目录
首先在 Process Tree 中创建一个“分割”目录,在该窗口中右键,从菜单中点击 Append New,创建一个新进程。在 Edit Process 中 Name 下一栏输入“分割”,然后点击 OK。

2.添加多尺度分割进程
在分割进程上右键,从菜单中点击 Insert Child,插入一个子进程。打开 Edit Process 窗口编辑进程。Algorithm 选择 multiresolution segmentation。Level Name 设置为 Level 1,Scale Parameter 设置为 30,将10月图像所有的波段权重设置为0,编辑完成后点击 Execute,执行多尺度分割。
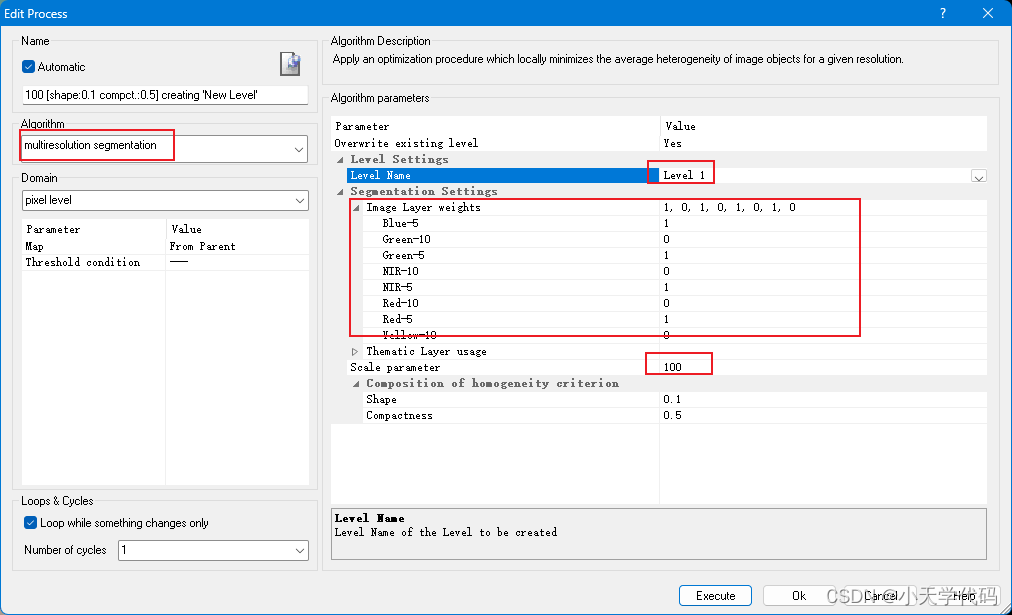
3.查看分割结果
分割完成后,可查看分割效果。

3.3阈值分类(提取植被区域)
1.创建进程目录
点击“分割”目录后右键,从菜单中点击 Append New,创建一个新进程。在 Edit Process中 Name 下一栏输入“阈值分类”,然后点击 OK。
点击阈值分类目录后右键,从菜单中点击 Insert Child,创建一个新进程。在 Edit Process中 Name 下一栏输入“区分植被非植被”,然后点击 OK。


2.创建自定义特征
在遥感中通常使用 NDVI 植被指数来区分植被和非植被。由于易康软件中没有这个特征,需要通过创建新特征这个工具来定义 NDVI。在 Feature View 窗口中双击 Create new ‘Arithmetic Feature’,弹出 Edit Customized Feature 窗口,输入 Feature name 为 NDVI,然后编辑公式([Mean NIR-5]-[Mean Red-5])\([Mean NIR-5]+[Mean Red-5]),为避免出错,所有的符号和波段名称最好都从下面的面板中点击输入,不要自己键入。如果发现没有自己需要的波段可以自己手动添加进来。



3.查看对象特征值
新创建的特征 NDVI 在 Feature View 窗口的 Object features > Customized 目录下,查看该特征值时,可在 NDVI 特征上右键,点击 Update Range,然后在窗口左下角的复选框中点击勾选,激活渲染特征值区间工具。
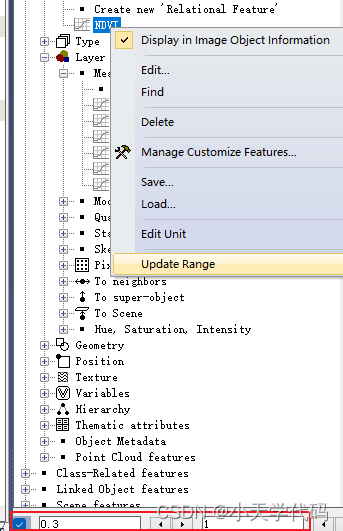
点击 显示轮廓线按钮,将轮廓线取消,显示影像的 NDVI 特征,在特征值区间内的对象用蓝色或绿色进行渲染,不在特征值区间的对象用白色、黑色或灰色进行渲染。
显示轮廓线按钮,将轮廓线取消,显示影像的 NDVI 特征,在特征值区间内的对象用蓝色或绿色进行渲染,不在特征值区间的对象用白色、黑色或灰色进行渲染。

为了确定植被的 NDVI 特征值区间,我们同样采用分窗的方式来查看,上窗显示原始影像,下窗显示 NDVI 特征值。通过特征显示窗口观察,我们发现属于植被的对象都是用绿色来渲染的,说明植被的 NDVI 值较高。于是我们在调节植被的 NDVI 特征值区间时,需要设定一个最低值,将其它类别的对象进行排除。通过调整、观察和对比,确定这个最低值为0.47。同时NDVI自身的范围为-1-1,所以将最高值设置为1。
4.创建类别
在 Class Hierarchy 窗口中新建一个类别植被。

![]()
5.添加植被分类进程
在进程目录中找到“区分植被和非植被”,在该进程上右键,点击 Insert Child,添加一个分类进程。Algorithm 选择 assign class,Class filter 选择none,Threshold condition 处设置 NDVI≥0.47,Use class 设置为植被并设置颜色。注意我这里使用了9.5版本的软件可以使用or来将两个月份的NDVI指数一起来进行阈值分类,只要有一个月份的NDVI指数大于0.47都算做植被区域。低于9.5版本的软件不支持这个功能,只需要考虑10月份的NDVI指数即可。


3.4创建样本文件
1.植被区域导出为shp文件
找到EXPORT下的Export Results将植被区域导出为shp文件。
将植被类添加到classes中。

将植被类的名字添加到features中
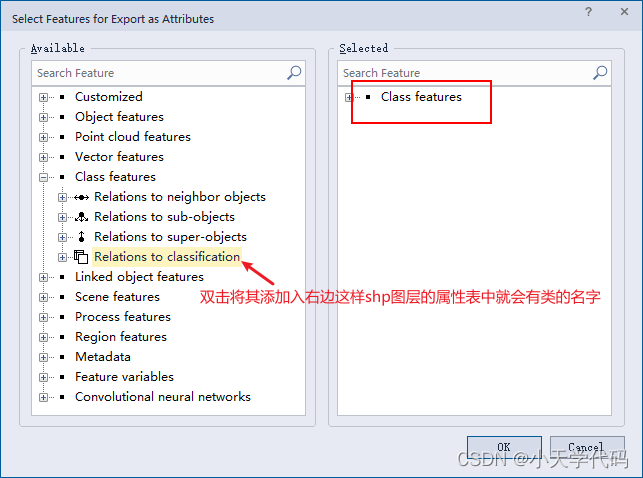
这样就可以将植被区域导出为shp文件。

2.在ArcGisPro中创建样本点
在ArcGisPro中打开导出的植被区域的shp文件,以及10月和5月的影像。将影像地图置于最底层,适当调整植被区域的透明度。达到下图中的效果。
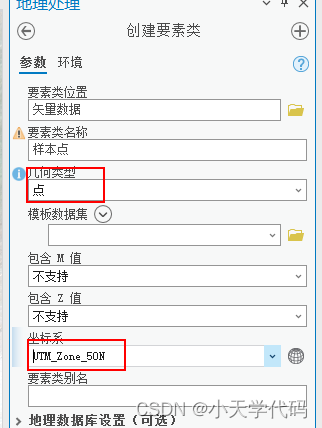
在合适的目录文件下,新建一个shp文件。这里注意将几何类型选择为点,坐标系要与原始影像相同。

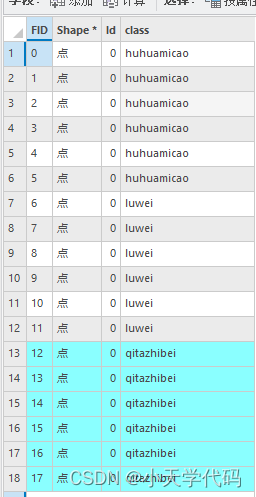
进入编辑页面,点击创建按钮选择样本点图层,开始在植被区域范围内,选择互花米草,芦苇以及其他植被。创建这些类别的矢量点,以便在后续在eCognition中创建样本。
打开样本点的属性表,添加一个字段用来记录这些点的类别,并对其赋值为各类别的名称。这里最好不用中文,不然在后续eCognition中查看属性表会出现中文乱码,应该是和编码格式有关。到此将创建好的样本点文件导出到合适的文件夹下便于后续加载。
3.5查看样本文件
1.加载矢量点文件
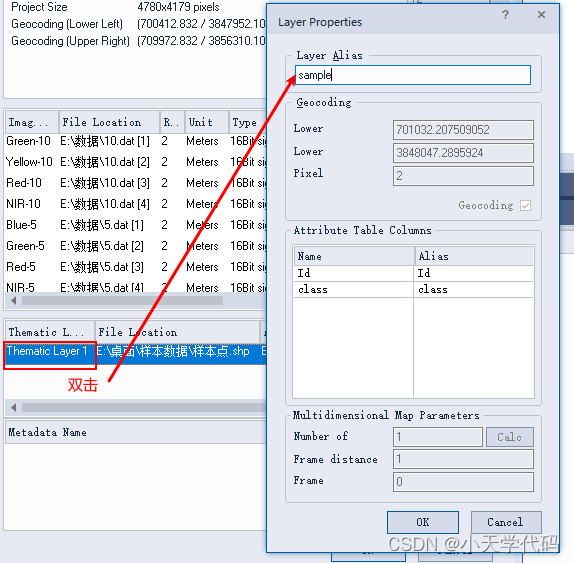
找到项目文件右击选择Modify,进入界面后载入之前创建好的样本点文件。

载入完毕后修改图层名称为sample。

载入完毕后修改图层名称为sample。
2.显示样本
在菜单空白处右键,在右键菜单中点击 Toolbars,再点击 ![]() Mannual Editting,调出Mannual Editting 工具条。
Mannual Editting,调出Mannual Editting 工具条。

在 Mannual Editing 工具条上,点击 Image object editting,下拉菜单中选择 Thematic editing。点击 New Layer,下拉菜单中选择 Sample。
![]()
在9.5版本中也可以使用view settings界面进行设置矢量的外边框、填充颜色以及透明度。
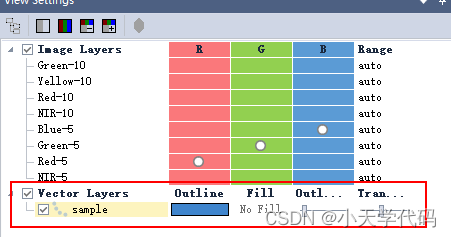
2.查看属性表
查看了矢量文件的显示效果之后,我们来查看一下矢量文件 Sample 的属性表。方法是在主菜单空白处右键,在弹出菜单中点击 Thematic Layer Attribute Table。


3.6矢量转化为样本
1.创建进程目录
在 Process Tree 中,右键点击”分割”,从菜单中点击 Append New,创建一个新进程。在Edit Process 中 Name 下一栏输入“矢量转化为样本”,然后点击 OK。


2.创建按照矢量分类的进程
在 Process Tree 中,右键点击” 矢量转化为样本”,从菜单中点击 Insert Child,创建一个分类进程。在 Edit Process 中,设置 Algorithm 为 assign class by thematic layer,Class Mode设置为 Create new class,然后点击 OK。

运行这个进程之前,要注意多尺度分割进程,不要使用 Sample 矢量进行分割。

然后再执行按照矢量分类的进程,就得到了新的类别。取消矢量文件的叠加显示效果,显示分类结果。
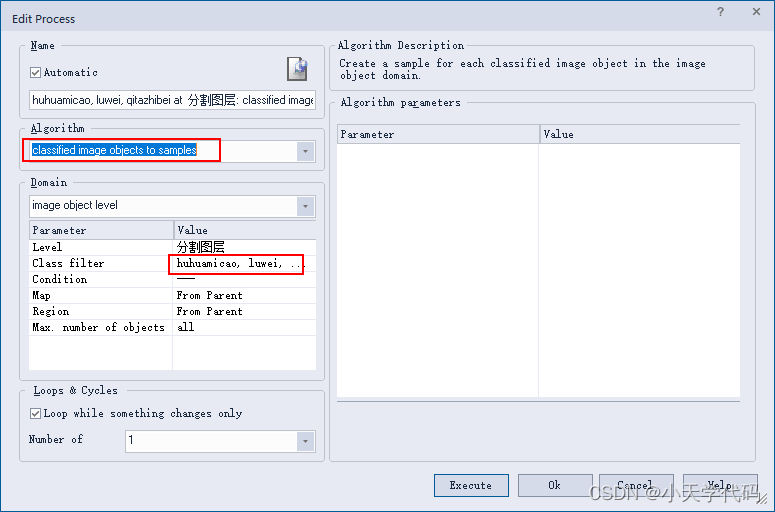
3.创建分类对象转化为样本的进程
在按照矢量分类的进程上右键点击 Append New,新建一个将分类对象转化为样本的进程。Edit Process 对话框中,设置 Algorithm 为 classified image object to samples,Class filters选择所有四个类别,然后点击 OK。

这样就可以对样本进行评价,点击 Sample 工具条上的 Sample Editor 工具![]() ,调出这个样本评价窗口,这个窗口可以评价所选类别的样本特征是否能够代表该类别。其中 Active class 为要评价的样本类别,它可以在下拉菜单中选择,也可以在 Class Hierachy 中选择。可以选择 Compare class,它是与该类别相对比的类别,只能从下拉菜单中选择。Sample Editor窗口中每个图表上的黑色柱状线段表示Active class的样本的特征值区间,而蓝色柱状线段表示 Compare class 的样本的特征值区间。当点击一个可能是 Active class 的对象的时候,在每个图表的横坐标下面会有一个红色指针,指出该对象的特征值所在的位置。当这个红色指针位于黑色柱状线段表示的区间内,说明这个对象很有可能被分为激活类别。如果不在这个特征区间,说明样本有可能选得还不够,或者样本选错了。
,调出这个样本评价窗口,这个窗口可以评价所选类别的样本特征是否能够代表该类别。其中 Active class 为要评价的样本类别,它可以在下拉菜单中选择,也可以在 Class Hierachy 中选择。可以选择 Compare class,它是与该类别相对比的类别,只能从下拉菜单中选择。Sample Editor窗口中每个图表上的黑色柱状线段表示Active class的样本的特征值区间,而蓝色柱状线段表示 Compare class 的样本的特征值区间。当点击一个可能是 Active class 的对象的时候,在每个图表的横坐标下面会有一个红色指针,指出该对象的特征值所在的位置。当这个红色指针位于黑色柱状线段表示的区间内,说明这个对象很有可能被分为激活类别。如果不在这个特征区间,说明样本有可能选得还不够,或者样本选错了。

3.7使用 SVM分类器分类
1.创建进程目录
在 Process Tree 中,右键点击菜单中点击 Append New,创建一个新进程。在 Edit Process 中 Name 下一栏输入“SVM分类”,然后点击 OK。


2.添加分类器训练进程
在 Process Tree 中,右键点击”SVM分类”,从菜单中点击 Insert child,创建一个新进程。在 Edit Process 中设置 Algorithm 为 classifier,Domin 选择 Image object level,Class filter之前生成的类别,Operation 选择 Train,Configuration 设置一个变量名 SVM(在 Creat Scene Variable 对话框中只需要设置变量名称,用于储存训练过程),Feature 处选择 Object features > Layer Values > Mean(在 Select Multiple Features 对话框中将Mean 组中5月的波段双击添加到右侧已选特征中),Classifier Type 设置为 SVM,然后点击OK。


执行分类器训练进程之后,可以在 Image Object Information 窗口中看到 Scene Variables一栏中有记录,这就是 SVM变量记录的训练过程。
![]()

3.添加分类器应用进程
在 Process Tree 窗口中,在分类器训练进程处右键点击 Append New,新建一个分类器应用进程。在 Edit Process 对话框中,设置 Algorithm 为 classifier,Domin 选择 Image Object level,Operation 选择 Apply,Configuration 选择 SVM(应用 SVM变量存储的训练结果)。

执行完分类器应用进程之后,查看分类效果。最后将结果导出为shp文件。


