Reinforcement Learning SARSA算法实现以及grid world模拟
- grid world
- SARSA算法实现
grid world
OpenAI Gym的Environment大部分是连续空间而不是离散空间的的Environment类,使用gridworld.py就可以模拟Environment的类【1】,【2】。使用这个类可以进行自定义格子的大小,水平和垂直格子数目。每个格子的奖励,初始状态。
gridworld.py的初始化函数:
def __init__(self, n_width:int=10,
n_height:int = 7,
u_size = 40,
default_reward:float = 0,
default_type = 0)在【3】里面对以下进行了实现:
env = LargeGridWorld() # 10*10的大格子
env = SimpleGridWorld() # 10*7简单无风格子
env = WindyGridWorld() # 10*7有风格子
env = RandomWalk() # 随机行走
env = CliffWalk() # 悬崖行走
env = SkullAndTreasure() # 骷髅和钱袋子示例可以将这个环境导入OpenAI Gym里面:
from gridworld import GridWorldEnv
env = GridWorldEnv(n_width=12, # 水平方向格子数量
n_height = 4, # 垂直方向格子数量
u_size = 60, # 可以根据喜好调整大小
default_reward = -1, # 默认格子的即时奖励值
default_type = 0) # 默认的格子都是可以进入的
from gym import spaces # 导入spaces
env.action_space = spaces.Discrete(4) # 设置行为空间支持的行为数量设置起始和终止状态:
env.start = (0,0)
env.ends = [(11,0)]对于特殊位置的reward进行改进:
for i in range(10):
env.rewards.append((i+1,0,-100))
env.ends.append((i+1,0))设置部分格子不可以进入:
env.types = [(5,1,1),(5,2,1)]最后进行更新:
env.refresh_setting()然后查看:
env.render()
input("press any key to continue...")运行代码看一下效果:
from gridworld import GridWorldEnv
from gym import spaces
env = GridWorldEnv(n_width=12, # 水平方向格子数量
n_height = 4, # 垂直方向格子数量
u_size = 60, # 可以根据喜好调整大小
default_reward = -1, # 默认格子的即时奖励值
default_type = 0) # 默认的格子都是可以进入的
env.action_space = spaces.Discrete(4) # 设置行为空间数量
# 格子世界环境类默认使用0表示左,1:右,2:上,3:下,4,5,6,7为斜向行走
# 具体可参考_step内的定义
# 格子世界的观测空间不需要额外设置,会自动根据传输的格子数量计算得到
env.start = (0,0)
env.ends = [(11,0)]
for i in range(10):
env.rewards.append((i+1,0,-100))
env.ends.append((i+1,0))
env.types = [(5,1,1),(5,2,1)]
env.refresh_setting()
env.reset()
env.render()
input("press any key to continue...")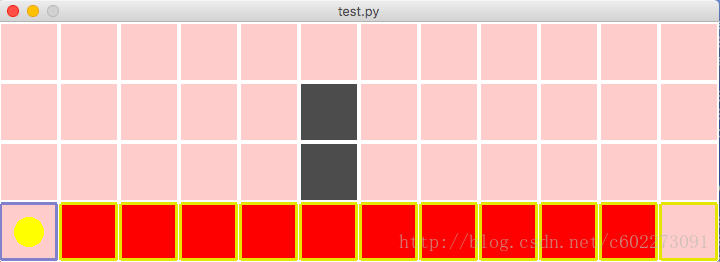
SARSA算法实现
SARSA算法是在TD中的一种,使用在control,获取最好的policy。
具体公式如下:

如果return reward加入 λ ,那么可以得到:

导入相关的包:
from random import random # 随机策略时用到
from gym import Env
import gym
from gridworld import * # 可以导入各种格子世界环境自定义一个Agent类,用来进行policy learning,greedy learning。
class Agent():
def __init__(self, env: Env):
self.env = env # 个体持有环境的引用
self.Q = {} # 个体维护一张行为价值表Q
self.state = None # 个体当前的观测,最好写成obs.
def performPolicy(self, state): pass # 执行一个策略
def act(self, a): # 执行一个行为
return self.env.step(a)
def learning(self): pass # 学习过程策略greedy policy:
def performPolicy(self, s, episode_num, use_epsilon):
epsilon = 1.00 / (episode_num+1)
Q_s = self.Q[s]
str_act = "unknown"
rand_value = random()
action = None
if use_epsilon and rand_value < epsilon:
action = self.env.action_space.sample()
else:
str_act = max(Q_s, key=Q_s.get)
action = int(str_act)
return action整个SARSA算法实现:
def learning(self, gamma, alpha, max_episode_num):
# self.Position_t_name, self.reward_t1 = self.observe(env)
total_time, time_in_episode, num_episode = 0, 0, 0
while num_episode < max_episode_num: # 设置终止条件
self.state = self.env.reset() # 环境初始化
s0 = self._get_state_name(self.state) # 获取个体对于观测的命名
self.env.render() # 显示UI界面
a0 = self.performPolicy(s0, num_episode, use_epsilon = True)
time_in_episode = 0
is_done = False
while not is_done: # 针对一个Episode内部
# a0 = self.performPolicy(s0, num_episode)
s1, r1, is_done, info = self.act(a0) # 执行行为
self.env.render() # 更新UI界面
s1 = self._get_state_name(s1)# 获取个体对于新状态的命名
self._assert_state_in_Q(s1, randomized = True)
# 获得A'
a1 = self.performPolicy(s1, num_episode, use_epsilon=True)
old_q = self._get_Q(s0, a0)
q_prime = self._get_Q(s1, a1)
td_target = r1 + gamma * q_prime
#alpha = alpha / num_episode
new_q = old_q + alpha * (td_target - old_q)
self._set_Q(s0, a0, new_q)
if num_episode == max_episode_num: # 终端显示最后Episode的信息
print("t:{0:>2}: s:{1}, a:{2:2}, s1:{3}".\
format(time_in_episode, s0, a0, s1))
s0, a0 = s1, a1
time_in_episode += 1
print("Episode {0} takes {1} steps.".format(
num_episode, time_in_episode)) # 显示每一个Episode花费了多少步
total_time += time_in_episode
num_episode += 1
return运行代码:
def main():
env = SimpleGridWorld()
agent = Agent(env)
print("Learning...")
agent.learning(gamma=0.9,
alpha=0.1,
max_episode_num=800)
if __name__ == "__main__":
main()Ref Links:
【1】grid file:https://inst.eecs.berkeley.edu/~cs188/fa11/projects/reinforcement/gridworld.py
【2】grid environment: https://inst.eecs.berkeley.edu/~cs188/fa11/projects/reinforcement/docs/gridworld.html
【3】grid env: https://github.com/qqiang00/reinforce/blob/master/reinforce/gridworld.py