mysql优化varchar索引_MySQL优化--概述以及索引优化分析
一、MySQL概述
1.1、MySQL文件含义
通过如下命令查看
show variables like '%dir%';

MySQL文件位置及含义
名称
值
备注
basedir
/usr/
安装路径
character_sets_dir
/usr/share/mysql-8.0/charsets/
保存字符集目录
datadir
/var/lib/mysql/
数据存放路径
lc_messages_dir
/usr/share/mysql-8.0/
plugin_dir
/usr/lib64/mysql/plugin/
插件
slave_load_tmpdir
/tmp
缓存文件
tmpdir
/tmp
缓存文件
配置文件位置
Linux:/etc/my.cnf
win:C:\ProgramData\MySQL\MySQL Server 8.0\my.ini
1.2、MySQL主要配置文件
二进制日志log-bin:用于主从复制
错误日志log-error:默认关闭,记录严重警告和错误信息,启动和关闭的详细信息等。
查询日志:默认关闭,可显式指定,记录慢查询日志
数据文件:
MyISAM中: 1. frm 存放表结构
2. myd 存放表数据
3. myd 存放表索引
InnoDB 中:ibd文件存放数据
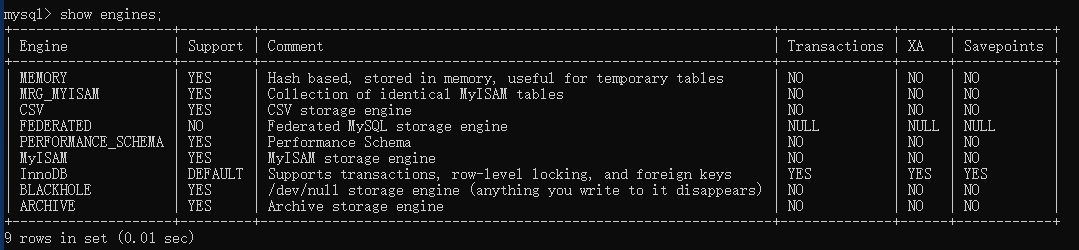
1.3、MySQL引擎
查询引擎
show engines;
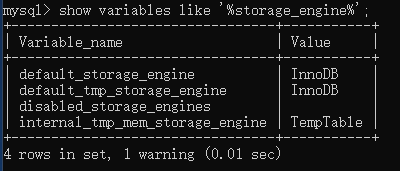
show variables like '%storage_engine%'
MyISAM
InnoDB
构成上的区别:
每个MyISAM在磁盘上存储成三个文件。第一个文件的名字以表的名字开始,扩展名指出文件类型。 .frm文件存储表定义。 数据文件的扩展名为.MYD (MYData)。 索引文件的扩展名是.MYI (MYIndex)。
基于磁盘的资源是InnoDB表空间数据文件和它的日志文件,InnoDB 表的大小只受限于操作系统文件的大小,一般为 2GB
事务处理上方面:
MyISAM类型的表强调的是性能,其执行数度比InnoDB类型更快,但是不提供事务支持
InnoDB提供事务支持事务,外部键(foreign key)等高级数据库功能
SELECT、UPDATE、INSERT、Delete操作
如果执行大量的SELECT,MyISAM是更好的选择
1.如果你的数据执行大量的INSERT或UPDATE,出于性能方面的考虑,应该使用InnoDB表 2.DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的删除。 3.LOAD TABLE FROM MASTER操作对InnoDB是不起作用的,解决方法是首先把InnoDB表改成MyISAM表,导入数据后再改成InnoDB表,但是对于使用的额外的InnoDB特性(例如外键)的表不适用
对AUTO_INCREMENT的操作
每表一个AUTO_INCREMEN列的内部处理。 MyISAM为INSERT和UPDATE操作自动更新这一列。这使得AUTO_INCREMENT列更快(至少10%)。在序列顶的值被删除之后就不能再利用。(当AUTO_INCREMENT列被定义为多列索引的最后一列,可以出现重使用从序列顶部删除的值的情况)。 AUTO_INCREMENT值可用ALTER TABLE或myisamch来重置 对于AUTO_INCREMENT类型的字段,InnoDB中必须包含只有该字段的索引,但是在MyISAM表中,可以和其他字段一起建立联合索引 更好和更快的auto_increment处理
如果你为一个表指定AUTO_INCREMENT列,在数据词典里的InnoDB表句柄包含一个名为自动增长计数器的计数器,它被用在为该列赋新值。 自动增长计数器仅被存储在主内存中,而不是存在磁盘上 关于该计算器的算法实现,请参考 AUTO_INCREMENT列在InnoDB里如何工作
表的具体行数
select count(*) from table,MyISAM只要简单的读出保存好的行数,注意的是,当count(*)语句包含 where条件时,两种表的操作是一样的
InnoDB 中不保存表的具体行数,也就是说,执行select count(*) from table时,InnoDB要扫描一遍整个表来计算有多少行
锁
表锁
提供行锁(locking on row level),提供与 Oracle 类型一致的不加锁读取(non-locking read in SELECTs),另外,InnoDB表的行锁也不是绝对的,如果在执行一个SQL语句时MySQL不能确定要扫描的范围,InnoDB表同样会锁全表, 例如update table set num=1 where name like "%aaa%"
二、索引优化分析
2.1、什么是索引
MySQL官方的定义为:
索引(Index)是帮助MySQL高效地获取数据的数据结构
索引的本质是数据结构
可简单的理解为“排好序的快速查找数据结构”
2.2、索引分类
索引类型
索引含义
单值索引
一个索引仅包含一个列
唯一索引
索引列的值必须唯一,可以有空值
复合索引
一个索引包含多个列
2.3、基本语法
2.3.1、创建
方法一:
CREATE [UNIQUE] INDEX indexName ON mytable(columnname(length));
方法二:
ALTER mytable ADD [UNIQUE] INDEX [indexname] on (columnname(length));
2.3.2、删除
DROP INDEX [indexName] ON mytable;
2.3.3、查看
SHOW INDEX FROM table_name;
2.4、explain
2.4.1、基本语法
EXPLAIN select语句;
2.4.2、字段解释
id:select查询的序列号,包含一组数字,表示select字句或操作表的顺序
id相同,执行顺序自上向下
id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
id相同不同,同时存在
select_type
id
select_type
含义
1
SIMPLE
简单select查询
2
PRIMARY
包含复杂查询的最外层查询
3
SUBQUERY
子查询
4
DERIVED
衍生,递归执行,结果保存至临时表
5
UNION
若第二个SELECT出现在UNION之后,标记为UNION
6
UNION RESULT
从UNION表获取结果的SELECT
table 这一行的数据关于哪张表
partitions
type
从最好到最差排序 system>const>eq_ref>ref>range>index>ALL
类型
含义
system
表中只有一行数据,等于系统表
const
通过索引一次就找到了,被视为常量
eq_ref
唯一性索引扫描,表中只有一个记录匹配
ref
非唯一性索引扫描,表中有多个记录匹配
range
范围
index
全索引扫描
ALL
全表扫描
possible_keys
可能会在该表上使用的索引,一个或者多个
查询字段上存在的索引将被列出,不一定实际使用
key 实际使用的索引,如果为NULL,未使用索引;若有覆盖索引(从索引就可以获得数据,不需要查表),则仅在key字段出现
key_len 索引字段的最大可能长度,并非实际长度
列类型
KEY_LEN
备注
id int
key_len = 4+1
int为4bytes,允许为NULL,加1byte
id bigint not null
key_len=8
bigint为8bytes
user char(30) utf8
key_len=30*3+1
utf8每个字符为3bytes,允许为NULL,加1byte
user varchar(30) not null utf8
key_len=30*3+2
utf8每个字符为3bytes,变长数据类型,加2bytes
user varchar(30) utf8
key_len=30*3+2+1
utf8每个字符为3bytes,允许为NULL,加1byte,变长数据类型,加2bytes
detail text(10) utf8
key_len=30*3+2+1
TEXT截取部分,被视为动态列类型。
ref 引用的字段,为NULL未引用
rows 根据表统计信息和索引选用情况,大致估算出所需要读取的行数
filtered
Extra 不适合包含在其他列但十分重要的信息
Using filesort 使用外部排序,不使用索引的排序;无法使用索引完成的排序成为“文件排序”
Using temporary 使用了临时表存储中间结果
Using index 覆盖索引
Using where 使用了where
Using join buffer 使用了连接缓存
Impossible where 不存在的条件
select tables optimized away 没有GROUP BY的情况下,优化MIN/MAX或者对于MyISAM存储引擎优化COUNT(*)操作,查询计划生成阶段即完成优化
distinct 使用了distinct
2.5、join语句的优化
尽可能减少Join语句中的NestedLoop的循环总次数;“ 永远用小结果集驱动大的结果集”。
优先优化NestedLoop的内层循环;
保证Join语句中被驱动表上Join条件字段已经被索引;
当无法保证被驱动表的Join条件字段被索引且内存资源充足的前提下,不要太吝惜JoinBuffer的设置;
2.6、索引失效的情况
全值匹配我最爱
最佳左前缀法则
不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描
存储引擎不能使用索引中范围条件右边的列
尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)),减少select*
mysql在使用不等于(!=或者<> )的时候无法使用索引会导致全表扫描图
is null ,is not null也无法使用索引
like以通配符开头('%ab...')mysq|索引失效会变成全表扫描的操作
字符串不加单引号索引失效
少用or,用它来连接时会索引失效