21年 46篇神经架构搜索(NAS) ICCV CVPR Survey 笔记 ( 更新至20)
目录
1. FBNetV3: Joint Architecture-Recipe Search using Predictor Pretraining
2. Activate or Not: Learning Customized Activation
3. Dynamic Slimmable Network
4. AttentiveNAS: Improving Neural Architecture Search via Attentive Sampling
5.HR-NAS: Searching Effificient High-Resolution Neural Architectures with Lightweight Transformers
6.ReNAS: Relativistic Evaluation of Neural Architecture Search
7.BN-NAS: Neural Architecture Search with Batch Normalization(ICCV)
8.BossNAS: Exploring Hybrid CNN-transformers with Block-wisely Self-supervised Neural Architecture Search (ICCV)
9.Contrastive Neural Architecture Search with Neural Architecture Comparators
10.DCNAS: Densely Connected Neural Architecture Search for Semantic Image Segmentation
11. BCNet: Searching for Network Width with Bilaterally Coupled Network
12. DOTS: Decoupling Operation and Topology in Differentiable Architecture Search
13. DSRNA: Differentiable Search of Robust Neural Architectures
14.Evolving Search Space for Neural Architecture Search
15 GLiT: Neural Architecture Search for Global and Local Image Transformer
16 HourNAS: Extremely Fast Neural Architecture Search Through an Hourglass Lens
17 LightTrack: Finding Lightweight Neural Networks for Object Tracking via One-Shot Architecture Search
18 Neural Architecture Search with Random Labels
19 Searching for Fast Model Families on Datacenter Accelerators
20 Zen-NAS: A Zero-Shot NAS for High-Performance Image Recognition
1. FBNetV3: Joint Architecture-Recipe Search using Predictor Pretraining
| Aim: |
NAS SOTA |
| Abstract: |
问题:之前的NAS是在一组训练超参数(训练配方)下搜索体系结构而忽略了优越的体系结构配方组合 |
| Conclusion: |
提出:NARS神经结构-配方搜索,同时搜索结构和相应的训练配方 |
| Methods: |
精度预测器(约束优化)、自由架构统计数据 |
| Keyresults: |
存在EA思想、CPU计算、减少参数、紧凑 |
| Code: |
未公布代码 |

2. Activate or Not: Learning Customized Activation
| Aim: |
提出简单、有效的激活函数 ACON ,学习是否激活神经元 |
| Abstract: |
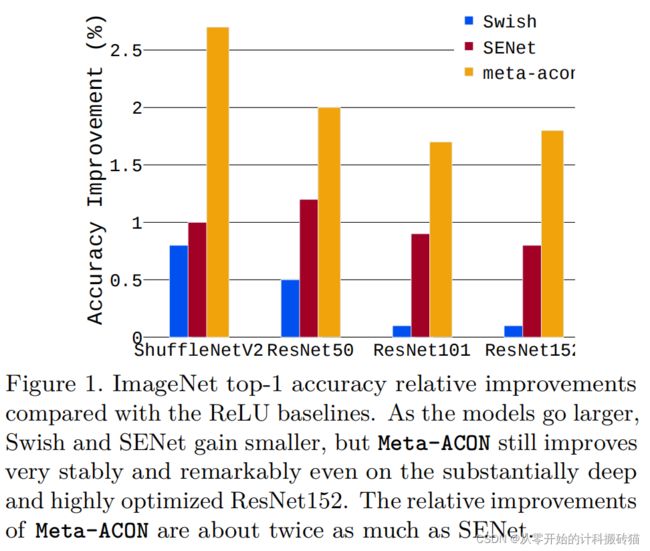
Maxout family 近似于Acon ,显著提升性能,使Swish成为ACON的特例
|
| Conclusion: |
提出:meta-ACON明确学习优化非线性激活和线性激活之间的参数切换,并提供了一个新的设计空间,通过简单的改变激活函数,在小模型的精准率上均得到提升 |
| Methods: |
激活函数、数学方面 |
| Keyresults: |
激活函数、目标检测、语义分割 |
| Code: |
GitHub - nmaac/acon: Official Repsoitory for "Activate or Not: Learning Customized Activation." [CVPR 2021] |
3. Dynamic Slimmable Network
| Aim: |
动态网络瘦身精简机制DS-Net,通过测量时动态调整不同输入的网络过滤器来实现良好的硬件效率,同时保持过滤器静态连接和连续存储在硬件中,防止额外的负担。 |
| Abstract: |
当前的动态+剪枝法减少网络的复杂度。但是存在问题,卷积滤波器上的动态稀疏模式在实际中无法实现真实的加速(由于索引、权重赋值或者零屏蔽的额外负担)。 |
| Conclusion: |
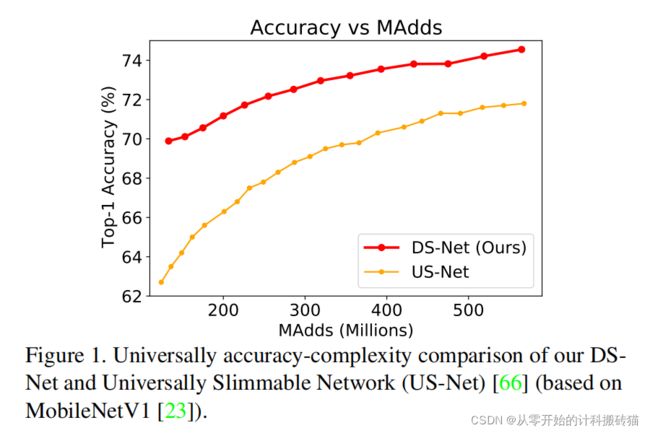
2-4倍的计算节约、1.62倍的真实加速,比最先进的压缩模型精度高 |
| Methods: |
动态网络、动态剪枝法、双头动态门attention+瘦身、受one-shot NAS启发的解纠缠两段训练方案、三明治门 |
| Keyresults: |
动态训练、动态瘦身、压缩模型 |
| Code: |
GitHub - changlin31/DS-Net: (CVPR 2021, Oral) Dynamic Slimmable Network |
4. AttentiveNAS: Improving Neural Architecture Search via Attentive Sampling
64个GPU做,没资源复现
| Aim: |
先前的Two-stage并未关注pareto,本文提出attention提高采样和有效识别pareto集的算法。 |
| Abstract: |
Two-stage NAS 需要在训练过程中,在搜索空间进行采样,影响模型准确性。虽然均匀采样简单高效,但不考虑模型的pareto前沿,这是搜索过程中的主要焦点。因此错过进一步提升的机会。 |
| Conclusion: |
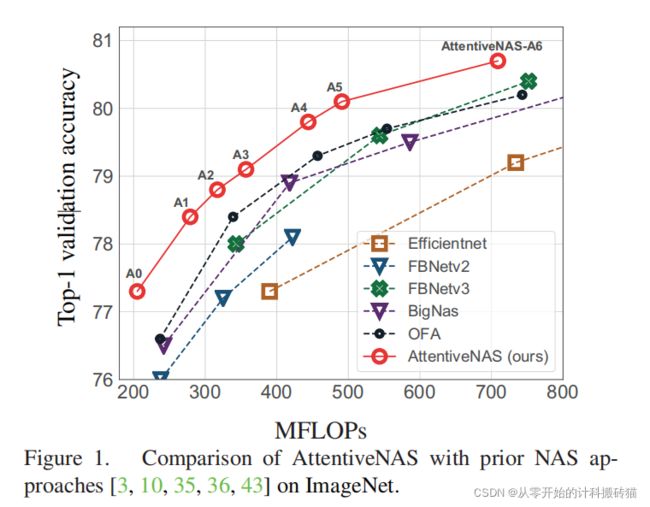
减少很多的计算量,491MFLOPs,比FBNetV3效果好,ImageNet 80.7%。(似乎使用的新技术这类很少,代码还有待参考) |
| Methods: |
两段搜索、attention、Flops约束 |
| Keyresults: |
attention、pareto |
| Code: |
GitHub - facebookresearch/AttentiveNAS: code for "AttentiveNAS Improving Neural Architecture Search via Attentive Sampling" |
5.HR-NAS: Searching Effificient High-Resolution Neural Architectures with Lightweight Transformers
| Aim: |
首次提出高分辨率NAS,在有限的计算量下,能够在多任务、多分支(预测+分类)中达到高精度。 |
| Abstract: |
高分辨率表示在先前的NAS工作中被忽略,本文提出一种全新的高分辨率NAS,能够有效编码多尺度上下文信息,同时保持高分辨率(在不同任务模块上)。 |
| Conclusion: |
HR-NAS在预测+分类等多任务中能够使用很小的计算量达到较高的精度。 |
| Methods: |
多尺度编码、轻量级transformer 动态调整计算函数与预算、多尺度卷积、细粒度搜索 |
| Keyresults: |
高分辨率表示、轻量级transformer、多特征卷积、细粒度搜索 |
| Code: |
https://github.com/dingmyu/HR-NAS |
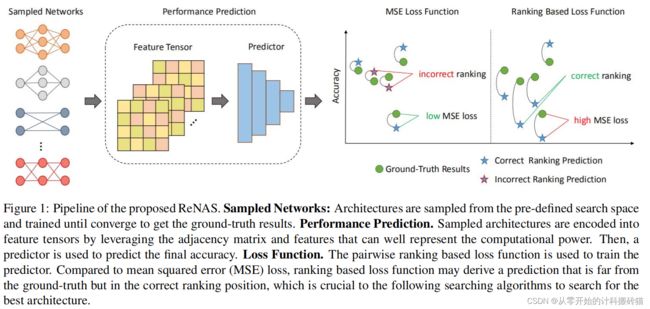
6.ReNAS: Relativistic Evaluation of Neural Architecture Search
| Aim: |
侧重于评估方案,目标确定哪种体系结构更好,而不是直接准确的预测绝对的体系结构性能 |
| Abstract: |
常规的评估这一步,一般采用预测器进行预测NA的精度。但是为了节约资源,一般采用小proxy数据集上训练和评估中间的神经架构。存在问题就是很难对真实结构精度进行预测。ReNAS采用新的预测思路,只是不断迭代选取当前最好的网络,在评估步骤上下功夫 |
| Conclusion: |
在NAS-Bench-101数据集上的实验结果表明,采样424个(占整个搜索空间的0.1%)神经结构及其相应的验证性能已经足以学习准确的结构性能预测器。在NAS-Bench-101和NAS-Bench-201数据集上搜索的神经结构的精度高于最先进的方法,并显示了所提出的方法的优先级。 |
| Methods: |
编码特征张量、预测器 |
| Keyresults: |
Bench-101、Bench-201 |
| Code: |
(这块没细看,该网站有很多模型,效果说很好,个人本地还没有测试过)https://www.mindspore.cn/resources/hub/
|
7.BN-NAS: Neural Architecture Search with Batch Normalization(ICCV)
这篇文章很有意思 ,Indicator指示器
| Aim: |
加速NAS |
| Abstract: |
提出一种基于BN的指示器,用于评估早期阶段训练阶段子网的表现 |
| Conclusion: |
在保证精度的同时,加速十倍的训练速度,缩短子网评估次数60万次。 |
| Methods: |
BN加速收敛、indicator |
| Keyresults: |
BN、supernet、预测器、指示器 |
| Code: |
https://github.com/bychen515/BNNAS |
8.BossNAS: Exploring Hybrid CNN-transformers with Block-wisely Self-supervised Neural Architecture Search (ICCV)
| Aim: |
1.搜索不同模型CNN trans的最佳结构 2.无监督模型NAS,解决由大权重共享空间和有偏倚的监督而导致的架构评级不准确的问题。 |
| Abstract: |
对搜索空间进行分解,自监督进行训练。 提出集成引导,每个搜索块作为整体进行搜索,在到达population center之前分别进行train |
| Conclusion: |
在ImageNet上达到了高达82.5%的准确率,在相同的计算时间下超过了EfficientNET 2.4%,SOTA. |
| Methods: |
混合结构CNN+Transformer 、分解space为块、集成引导ensemble bootstrapping |
| Keyresults: |
联合CNN trans 、自监督、block |
| Code: |
https://github.com/changlin31/BossNAS |
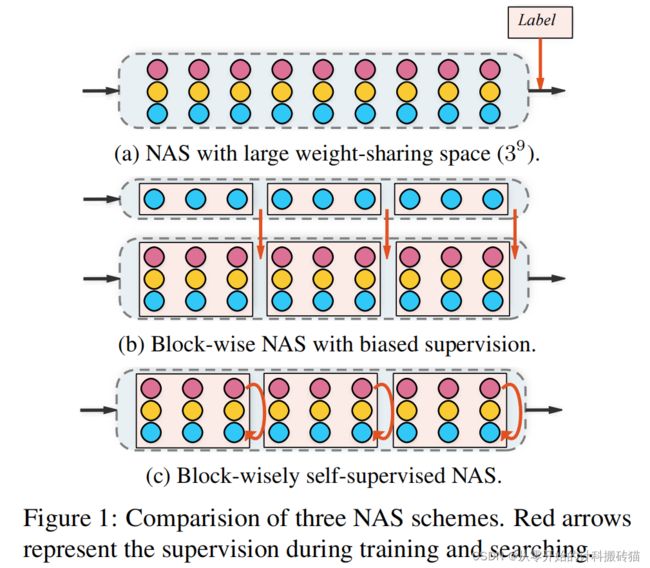
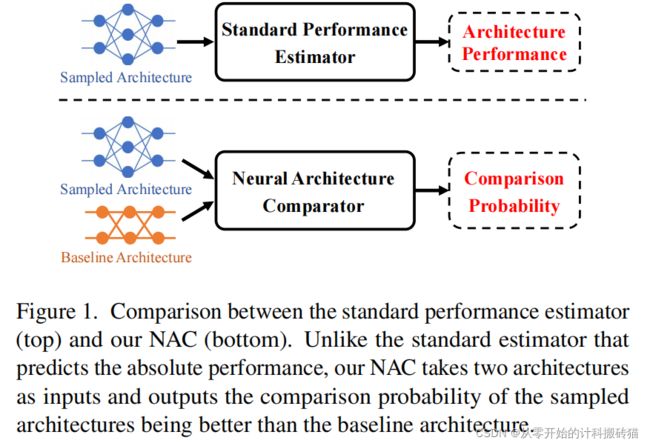
9.Contrastive Neural Architecture Search with Neural Architecture Comparators
| Aim: |
改进候网络的选择方式,不评估绝对性能,评估baseline |
| Abstract: |
本文中认为没有必要对网络的绝对性能进行评估,相反只需要了解体系结构是否比baseline的效果好就可以了。 困难: 1.如何比较体系与baseline 2.如何有效的利用标签数据
建立:比较器,比较每个结构之间的差距,对于基线,以curriculum learning的方式迭代的改进基线
|
| Conclusion: |
学习NAC(NA Comparator)等同于学习优化结构的排名,基于三个搜索空间显示了优越性 |
| Methods: |
CTNAS利用结构之间的比较结果为奖励进行结构搜索 |
| Keyresults: |
奖励、比较器、 |
| Code: |
没代码 |
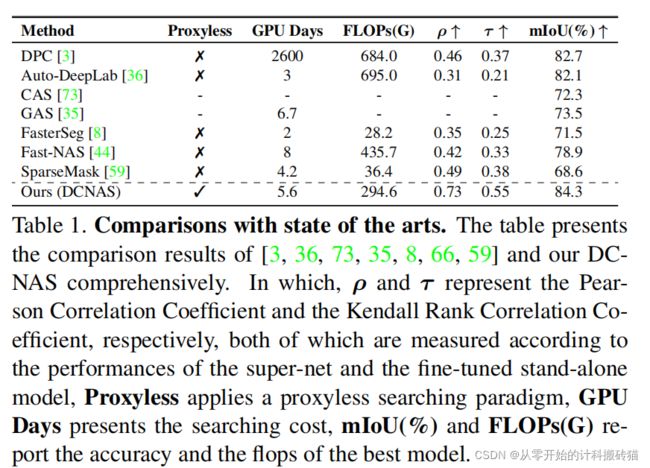
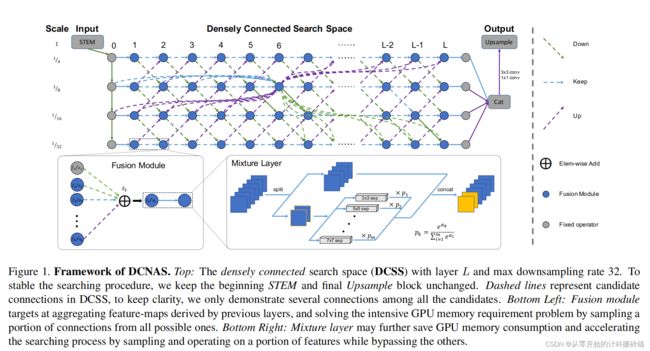
10.DCNAS: Densely Connected Neural Architecture Search for Semantic Image Segmentation
主要是做图像分割的,没有代码
| Aim: |
使得网络更宽,避免代理后与真实网络存在误差。不使用代理,在大规模目标数据集上直接搜索多尺度表示的最优架构。 |
| Abstract: |
通过使用可学习权值相互连接单元,引入一个密集连接的可搜索空间,覆盖大量主流网络的设计 |
| Conclusion: |
语义分割上达到SOTA |
| Methods: |
1.引入密集搜索空间,覆盖主流net 2.结合path和channel-level取样,减少计算内存消耗 |
| Keyresults: |
语义分割、proxy、multi-represeentations |
| Code: |
没代码 |
11. BCNet: Searching for Network Width with Bilaterally Coupled Network
| Aim: |
解决构建supernet的UA(unilaterally augmented)原则,即单方面增强网络的channel数量(加宽、加大)存在的每个channel训练不够充分的原则 |
| Abstract: |
双耦合的超网解决问题 每个channel训练不充分,提出两种解决方法: 1.提出一种训练BCNet时随机互补的策略 2.提出一种先验的初始化种群抽样方法来提高性能 |
| Conclusion: |
sota |
| Methods: |
进化算法、随机互补、更新抽样方法 |
| Keyresults: |
supernet 、EA |
| Code: |
没给 |
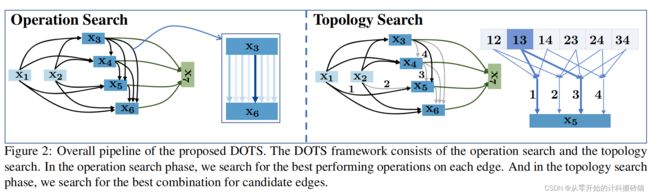
12. DOTS: Decoupling Operation and Topology in Differentiable Architecture Search
DARTS的改进型版本 ,这个可以纳入候选,没有test.py
| Aim: |
Darts算法主要集中解决操作搜索的问题,并从操作权值中推导出拓扑结构。但是操作权重往往并不能表示cell块的重要性。为了解决这个问题,提出一种解耦合+拓扑搜索(DOTS)的NAS算法。 |
| Abstract: |
DOTS由拓扑加解耦组成。该算法将拓扑和操作权值解耦,并进行一个显示的拓扑操作。引入包含候选边组合的拓扑空间实现。并且很容易扩张到搜索cell中。 |
| Conclusion: |
DOTS的算法可以很容易的应用于所有基于梯度下降的NAS算法中 |
| Methods: |
Decouple the Operation 、Topology Search、Darts
|
| Keyresults: |
Darts改进型、梯度下降搜索、拓扑搜索 |
| Code: |
https://github.com/guyuchao/DOTS |
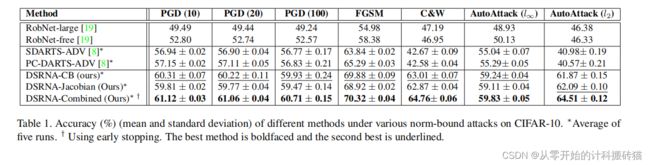
13. DSRNA: Differentiable Search of Robust Neural Architectures
从结构搜索的robust角度进行判断,但是没有给具体代码
| Aim: |
提高被搜索神经架构模型的robust性能,防止同时输入小bias引起精度预测器的明显偏差。 |
| Abstract: |
这些被搜索的架构很容易受到对抗性的攻击。对输入数据的一个小的扰动可以使体系结构显著地改变预测结果。为了解决这个问题,提出了对鲁棒神经结构进行可微搜索的方法。在我们的方法中,基于已认证的下界和雅可比范数界,定义了两个可微度量来度量架构的鲁棒性。然后,通过最大化鲁棒性度量来寻找健壮的架构。与以前旨在以隐式方式提高体系结构的鲁棒性的方法不同:执行对抗性训练和注入随机噪声,明确地和直接地最大化鲁棒性度量,以获取鲁棒的体系结构。 |
| Conclusion: |
搜索出来的神经结构roubus性能有一定的提升。 在不涉及attacks的情况下,精度比修改前效果好。 有更高的certified lower bounds |
| Methods: |
指标:两个metrics评判NAS的结构稳定性 1.具体的下界
2.Jacobian范数界
|
| Keyresults: |
对抗性攻击、神经架构搜索robust性能分析 |
| Code: |
没给 |
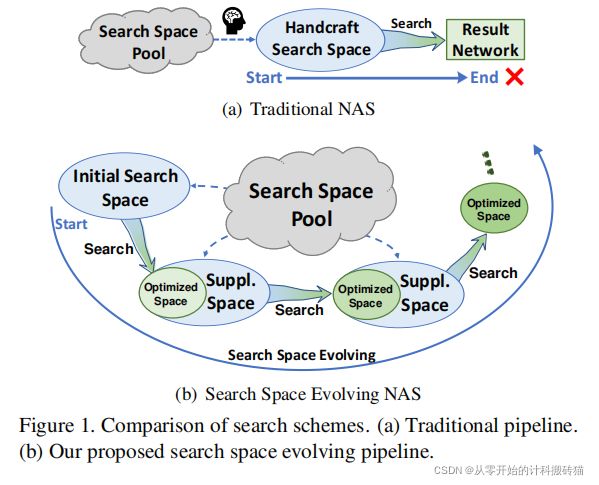
14.Evolving Search Space for Neural Architecture Search
| Aim: |
由于优秀的搜索空间子集是由人工干涉制作而成的,本文的目的就是减少这种干涉的必要性。 |
| Abstract: |
现有的NAS算法再增大搜索空间时,却发现网络的性能在下降,这一现象违反了常理。本文为了增强搜索空间的自由度,减少受干涉的必要性,提出神经搜索空间进化策略。 反复重复该计算过程 1.从搜索空间的子集中搜索一个优化后的空间 2.从未遍历过的大量操作池中重新填充此子集 |
| Conclusion: |
ImageNet的top1 精度为77.9% |
| Methods: |
进化算法、遍历、分支、推理延迟约束 |
| Keyresults: |
EA 多分支 |
| Code: |
GitHub - orashi/NSE_NAS: Official PyTorch implementation of "Evolving Search Space for Neural Architecture Search" |
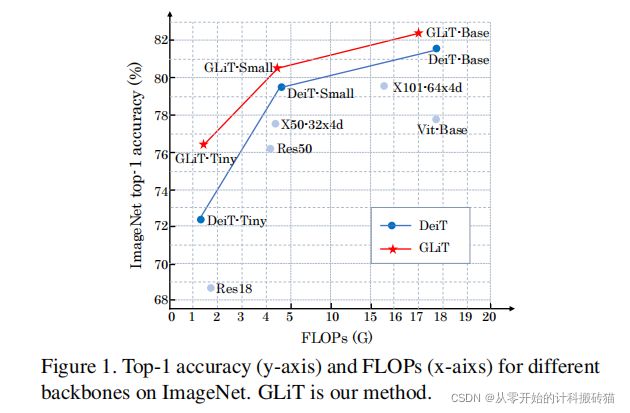
15 GLiT: Neural Architecture Search for Global and Local Image Transformer
| Aim: |
提高transform模型在计算机视觉上的感知能力,提出一种新的搜索空间和搜索算法。在ImageNet的分类效果达到82.3% SOTA |
| Abstract: |
GLiT是第一款图像分类的NAS transform 由于早期研究发现,不基于 CNN 的trans分类性能优异 ,但是transform早期是为 NLP定制,分类也许是次优的。为了提高transform在计算机视觉领域的感知能力,提 出一种新的搜 索空间和搜索 算法。
1. 引入一种局部 模型,更少的 计算成本明确 建模图像中的局部相关性。
利用模块的局部性,定义搜索空间,使搜索算法在全局和局部信息之间自由权衡,并优化每个模块的低级设计选择。
2. 为了解决巨大 的搜索空间问 题:提出一种 基于进化算法 的分层神经结 构搜索方法, 分别从两个层 次开始搜索最 优的神经视觉transform
|
| Conclusion: |
tiny model 的效果持平于 Darts 76.3%
small 80.5%
base 82.3% 和 zen-nas 的效果差不多
达到 SOTA
|
| Methods: |
EAs 、transform、 局部模型 |
| Keyresults: |
EAs 、transform |
| Code: |
GitHub - bychen515/GLiT |
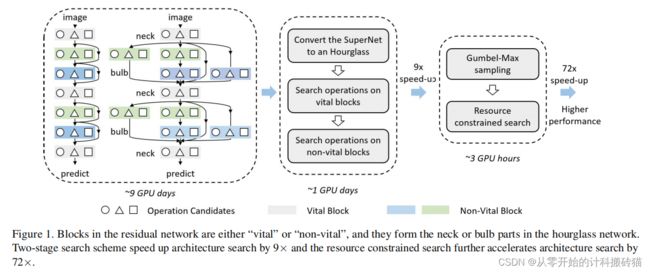
16 HourNAS: Extremely Fast Neural Architecture Search Through an Hourglass Lens
神经架构搜索(NAS)的目标是自动发现最优的架构。在本文中,提出了一种受沙漏启发的方法(HourNAS),用于极快的NAS。它的动机是,架构的影响通常来自于至关重要的几个块。像沙漏的窄颈,从深度神经网络的输入到输出的关键块限制了信息流,影响了网络的精度。其他的模块占据了网络的主要体积,并决定了网络的整体复杂性,对应于一个沙漏的底部。
这篇文章的代码链接貌似挂了
| Aim: |
由沙漏模型启发,有效的结构,往往从几个致命的模型模块出发 |
| Abstract: |
vital: 类似于沙漏的瓶颈,在模型路径中的几个关键模块,限制输入和输出的信息
流,影响精度。
other blocks: 其余的部分,占据网络的主体,对应于沙漏的底部。
1.鉴别关键模块,并使其作为架构搜索中的优先者
2.进一步缩小搜索空间中的非必要模块,仅覆盖候选、保证在可承担的计算量之内
|
| Conclusion: |
在ImageNet上的实验结果表明,仅使用一个GPU使用3小时(0.1天),HourNAS就可以搜索一个达到77.0%的Top-1精度的架构,这优于最先进的方法。 |
| Methods: |
类比 |
| Keyresults: |
Fast NAS |
| Code: |
https://gitee.com/%0D%0Aminds |
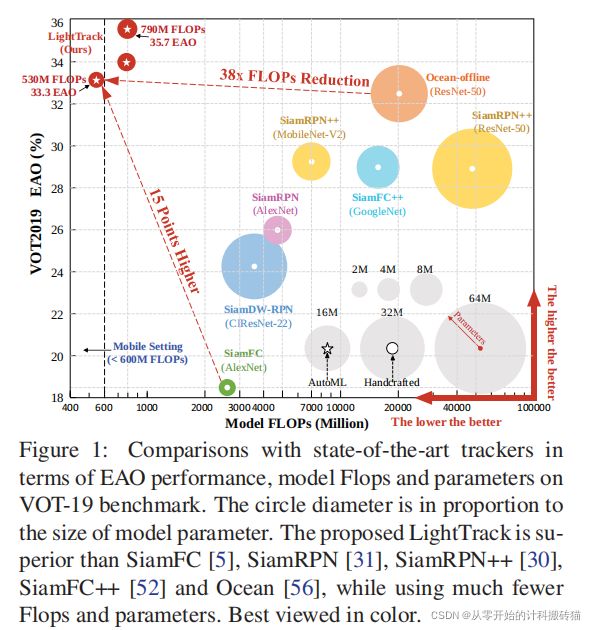
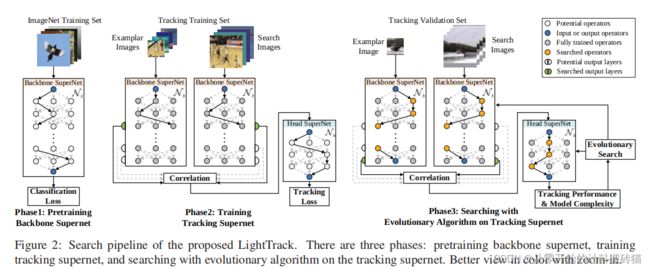
17 LightTrack: Finding Lightweight Neural Networks for Object Tracking via One-Shot Architecture Search
| Aim: |
目标跟踪模型越来越笨重与昂贵,采用NAS来设计更加轻量化和高效的物体跟踪器,缩小目标跟踪任务中的学术模型和工业部署之间的差距。 |
| Abstract: |
由于在资源受限的情况下,笨重昂贵的目标检测模型很难运行在移动芯片组之上。所以采用NAS来设计一个全新的物体跟踪器,综合实验表明,光轨LightTrack是有效的。 |
| Conclusion: |
它可以找到与手工制作的SOTA跟踪器相比,性能更好的跟踪器,如SiamRPN++[30]和Ocean[56],同时使用更少的模型Flops和参数。此外,当部署在资源有限的移动芯片组上时,发现的跟踪器运行速度要快得多。例如,在骁龙845AdrenoGPU上,光轨的运行速度比Ocean快12×,而使用的参数少13×,故障少38×。 |
| Methods: |
One-Shot NAS 应用 |
| Keyresults: |
目标跟踪、目标检测、One-shot |
| Code: |
https://github.com/researchmm/LightTrack |
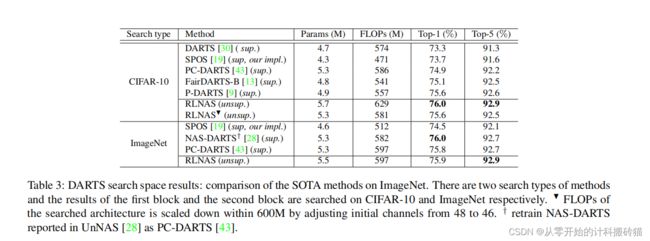
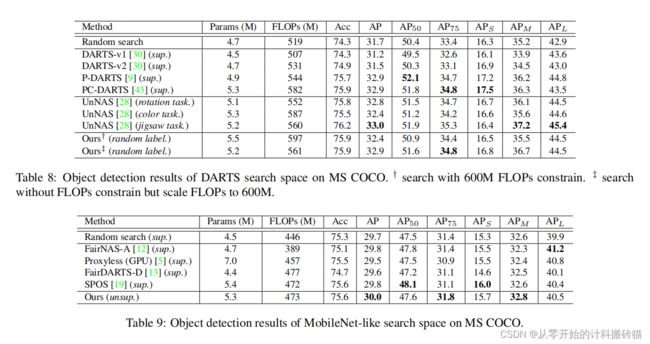
18 Neural Architecture Search with Random Labels
在本文中,我们研究了一种新的神经结构搜索(NAS)范式的随机标签搜索(RLNAS)。对于大多数现有的NAS算法来说,这个任务听起来违反直觉,因为随机标签提供的关于每个候选体系结构性能的信息很少。相反,我们提出了一个新的基于易收敛假设的NAS框架,它在搜索过程中只需要随机标签。
该算法包括两个步骤:首先,我们使用随机标签训练一个超级网络;其次,我们从超级网中提取出在训练过程中权值变化最显著的子网络。在多个数据集(如NAS-Bench-201和ImageNet)和多个搜索空间(如类飞镖和MobileNet)上进行了广泛的实验评估。非常令人惊讶的是,RLNAS取得了与最先进的NAS方法,如pc飞镖,单路径一飞球相比相当,甚至更好的结果,即使同行使用完整的地面真实标签进行搜索。我们希望我们的发现能够激发人们对NAS本质的新认识
| Aim: |
提出一种变种NAS,通过随机标签进行搜索。 |
| Abstract: |
提出一种随机标签搜索的NAS,很反常,因为随机标签可以供给的信息很少。 1.训练使用随机标签的超网 2.从超网中抽取训练期间权值变化显著的网络 |
| Conclusion: |
与一些20、21年的sota差不多,甚至和有真实标签的一致 |
| Methods: |
random labels
|
| Keyresults: |
NAS-Bench-201、ImageNet、 |
| Code: |
没给代码,很难判断他说的论文的重点在哪 |
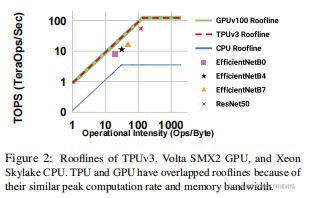
19 Searching for Fast Model Families on Datacenter Accelerators(Google)
有代码,但是没跑过这种类型代码
| Aim: |
神经架构搜索(NAS),结合模型缩放,在设计高精度和快速卷积架构家族方面取得了显著的进展。然而,由于NAS和模型缩放都没有考虑到足够的硬件架构细节,因此它们没有充分利用新兴的数据中心(DC)加速器。 |
| Abstract: |
1.在本文中,寻找快速和准确的CNN模型族,以有效的推断DC加速器。 首先分析了DC加速器,发现现有的cnn的操作强度、并行性和执行效率不足,并表现出flops延迟的非比例性。这些见解让我们创建了一个DC加速器优化的搜索空间,包括空间到深度、空间到批、混合融合卷积结构与香草和深度卷积,以及块级激活函数. 2.进一步提出了一种可感知延迟的复合缩放(LACS),这是第一个同时优化精度和延迟的多目标复合缩放方法。 LACS发现,网络深度应该比图像大小和网络宽度增长得快得多,这与以前的复合缩放的观测结果有很大的不同。有了新的搜索空间和LACS,我们在数据中心加速器上的搜索和缩放结果是一个名为EffcientNet-x的新模型系列。 |
| Conclusion: |
在TPuv3和GPUv100上,EffcientNet(一个在流量和精度上具有最先进的权衡的模型系列)快2倍以上,具有相当的精度。在tPUv3和GPUv100上,EffcientNet-x也比最近的RegNet和ResNeSt快7倍。 |
| Methods: |
模型缩放、快速卷积、数据中心加速器、延迟感知复合缩放 |
| Keyresults: |
模型缩放、数据中心加速器 |
| Code: |
tpu/models/official/efficientnet/tpu at master · tensorflow/tpu · GitHub |
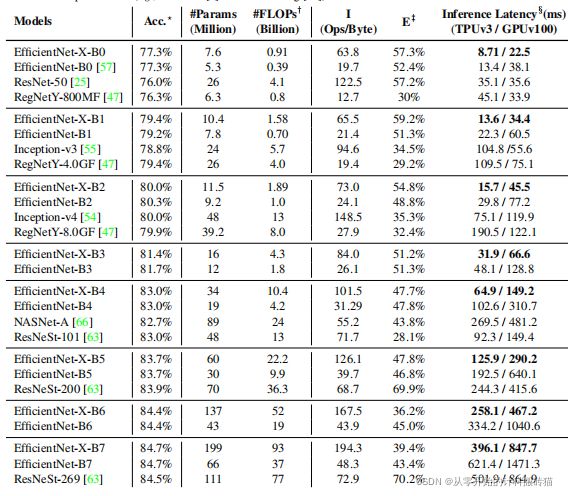
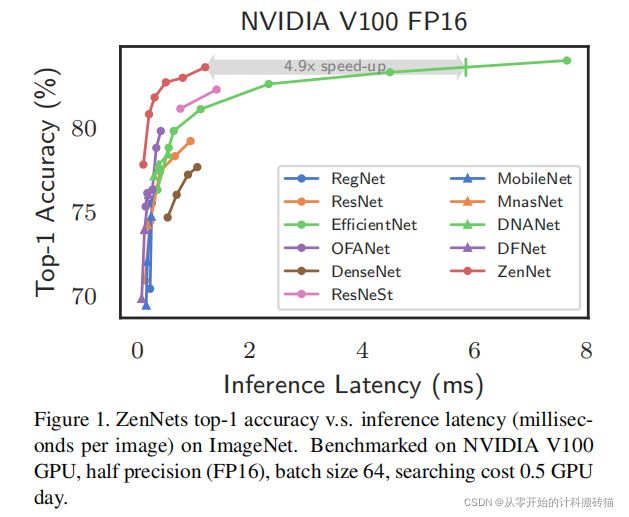
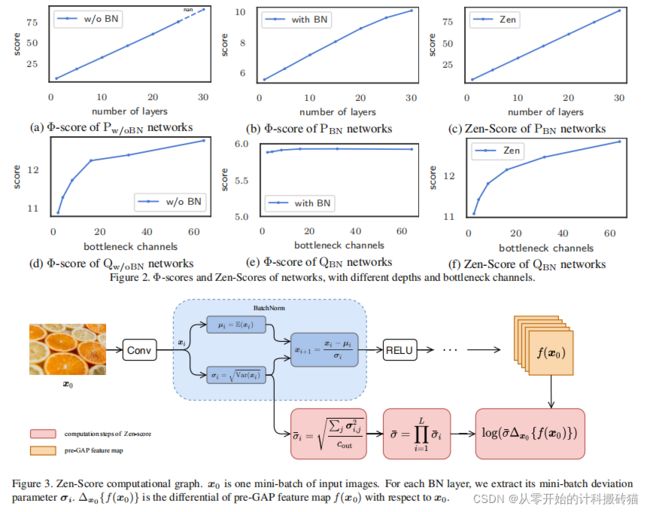
20 Zen-NAS: A Zero-Shot NAS for High-Performance Image Recognition
这篇论文的代码是阿里巴巴公司的研究者写的,但是并没有整理的比较干净, 作者在github上回复的非常及时,论文代码的调试运行非常的简单,半天就可以搜索出相应的cifar10架构。并且采用的是zero-score这个代理,也是一篇顶会,论文的参考文献都是比较新的,非常值得一看!
| Aim: |
采用一种zero-shot的代理方式,加速结构搜索,提高图片分类精度 |
| Abstract: |
zen-NAS采用的是一种零代理方式,称之zen-score来对架构进行排序(目的就是替代精度预测器,因为精度预测器的计算量是比较大的)zen-score便是网络的表达率,并与模型的精度正相关,并且其不需要训练网络参数。在有zenscore作为代理的情况下,提出一种zen-NAS的算法,在给定的推理预算下(1M大小)最大化目标网络的score。 |
| Conclusion: |
在0.5 GPU day的时间内,zenNAS可以以无数据的风格,直接搜索高性能架构,并且与之前的算法相比在ImageNet数据集上达到了83%的精度,远远高于Darts算法的精度。 |
| Methods: |
zero-shot、网络变异、零代理(取代精度预测器)、 |
| Keyresults: |
零代理、网络结构变异 |
| Code: |
https://github.com/idstcv/ZenNAS |
| Aim: |
|
| Abstract: |
|
| Conclusion: |
|
| Methods: |
|
| Keyresults: |
|
| Code: |
| Aim: |
|
| Abstract: |
|
| Conclusion: |
|
| Methods: |
|
| Keyresults: |
|
| Code: |
| Aim: |
|
| Abstract: |
|
| Conclusion: |
|
| Methods: |
|
| Keyresults: |
|
| Code: |
| Aim: |
|
| Abstract: |
|
| Conclusion: |
|
| Methods: |
|
| Keyresults: |
|
| Code: |
| Aim: |
|
| Abstract: |
|
| Conclusion: |
|
| Methods: |
|
| Keyresults: |
|
| Code: |
| Aim: |
|
| Abstract: |
|
| Conclusion: |
|
| Methods: |
|
| Keyresults: |
|
| Code: |
| Aim: |
|
| Abstract: |
|
| Conclusion: |
|
| Methods: |
|
| Keyresults: |
|
| Code: |
| Aim: |
|
| Abstract: |
|
| Conclusion: |
|
| Methods: |
|
| Keyresults: |
|
| Code: |
| Aim: |
|
| Abstract: |
|
| Conclusion: |
|
| Methods: |
|
| Keyresults: |
|
| Code: |
| Aim: |
|
| Abstract: |
|
| Conclusion: |
|
| Methods: |
|
| Keyresults: |
|
| Code: |
| Aim: |
|
| Abstract: |
|
| Conclusion: |
|
| Methods: |
|
| Keyresults: |
|
| Code: |
| Aim: |
|
| Abstract: |
|
| Conclusion: |
|
| Methods: |
|
| Keyresults: |
|
| Code: |
| Aim: |
|
| Abstract: |
|
| Conclusion: |
|
| Methods: |
|
| Keyresults: |
|
| Code: |
| Aim: |
|
| Abstract: |
|
| Conclusion: |
|
| Methods: |
|
| Keyresults: |
|
| Code: |