Chapter 1 The Machine Learning landscape (GDP per capita 与Life satification)
设置
from __feature__import division,print_function,unicode_literals
import numpy as np
np.random.seed(42)
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['xtick.labelsize'] = 12
import os
PROJECT_ROOT_DIR = "."
CHAPTER_ID = "fundamentals"
def save_fig(fig_id,tight_layout = True):
path = os.path.join(PROJECT_ROOT_DIR,"images",CHAPTER_ID,fig_id + '.png')
print("saving figure",fig_id)
if tight_layout:
plt.tight_layout()
plt.savefig(path,format = 'png',dpi = 300)
import warnings
warnings.filterwarnings(action = "ignore",module = "scipy",message = "internal gelsd")加载并查看数据
import os
datapath = os.path.join("datasets","lifesat","")
import numpy as np
import pandas as pd
oecd_bli = pd.read_csv(datapath + "oecd_bli_2015.csv", thousands=',')
gdp_per_capita = pd.read_csv(datapath + "gdp_per_capita.csv",thousands=',',delimiter='\t',
encoding='latin1', na_values="n/a")
def prepare_country_stats(oecd_bli, gdp_per_capita):
oecd_bli = oecd_bli[oecd_bli["INEQUALITY"]=="TOT"]
oecd_bli = oecd_bli.pivot(index="Country", columns="Indicator", values="Value")
gdp_per_capita.rename(columns={"2015": "GDP per capita"}, inplace=True)
gdp_per_capita.set_index("Country", inplace=True)
full_country_stats = pd.merge(left=oecd_bli, right=gdp_per_capita,
left_index=True, right_index=True)
full_country_stats.sort_values(by="GDP per capita", inplace=True)
remove_indices = [0, 1, 6, 8, 33, 34, 35]
keep_indices = list(set(range(36)) - set(remove_indices))
return full_country_stats[["GDP per capita", 'Life satisfaction']].iloc[keep_indices]
country_stats = prepare_country_stats(oecd_bli, gdp_per_capita)
X = np.c_[country_stats["GDP per capita"]]
y = np.c_[country_stats["Life satisfaction"]]
import matplotlib
import matplotlib.pyplot as plt
country_stats.plot(kind='scatter', x="GDP per capita", y='Life satisfaction')
plt.show()
import sklearn.linear_model
model = sklearn.linear_model.LinearRegression()
model.fit(X, y)
X_new = [[22587]]
print(model.predict(X_new)) 
载入并准备生活满意度
oecd_bli.head(2)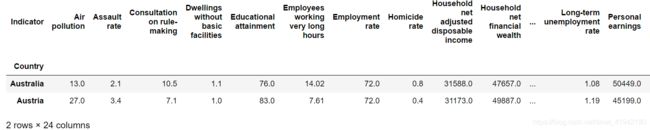
oecd_bli["Life satisfaction"].head()
载入并准备人均GDP
gdp_per_capita.head(2)
对full_country_stats数据进行操作
full_country_stats

full_country_stats[["GDP per capita",'Life satisfaction']].loc["Uited States"]
对sample_data数据进行操作
sample_data = full_country_stats[["GDP per capita", 'Life satisfaction']].iloc[keep_indices]
missing_data = full_country_stats[["GDP per capita", 'Life satisfaction']].iloc[remove_indices]
sample_data.plot(kind='scatter', x="GDP per capita", y='Life satisfaction', figsize=(5,3))
plt.axis([0, 60000, 0, 10])
position_text = {
"Hungary": (5000, 1),
"Korea": (18000, 1.7),
"France": (29000, 2.4),
"Australia": (40000, 3.0),
"United States": (52000, 3.8),
}
for country, pos_text in position_text.items():
pos_data_x, pos_data_y = sample_data.loc[country]
country = "U.S." if country == "United States" else country
plt.annotate(country, xy=(pos_data_x, pos_data_y), xytext=pos_text,
arrowprops=dict(facecolor='black', width=0.5, shrink=0.1, headwidth=5))
plt.plot(pos_data_x, pos_data_y, "ro")
save_fig('money_happy_scatterplot')
plt.show()
sample_data.to_csv(os.path.join("datasets","lifesat","lifesat.csv"))
sample_data.loc[list(position_text.keys)]
import numpy as np
sample_data.plot(kind='scatter', x="GDP per capita", y='Life satisfaction', figsize=(5,3))
plt.axis([0, 60000, 0, 10])
X=np.linspace(0, 60000, 1000)
plt.plot(X, 2*X/100000, "r")
plt.text(40000, 2.7, r"$\theta_0 = 0$", fontsize=14, color="r") # r"$公式$"
plt.text(40000, 1.8, r"$\theta_1 = 2 \times 10^{-5}$", fontsize=14, color="r")
plt.plot(X, 8 - 5*X/100000, "g")
plt.text(5000, 9.1, r"$\theta_0 = 8$", fontsize=14, color="g")
plt.text(5000, 8.2, r"$\theta_1 = -5 \times 10^{-5}$", fontsize=14, color="g")
plt.plot(X, 4 + 5*X/100000, "b")
plt.text(5000, 3.5, r"$\theta_0 = 4$", fontsize=14, color="b")
plt.text(5000, 2.6, r"$\theta_1 = 5 \times 10^{-5}$", fontsize=14, color="b")
save_fig('tweaking_model_params_plot')
plt.show()
from sklearn import linear_model
lin1 = linear_model.LinearRegression()
Xsample = np.c_[sample_data["GDP per capita"]]
ysample = np.c_[sample_data["Life satisfaction"]]
lin1.fit(Xsample, ysample)
t0, t1 = lin1.intercept_[0], lin1.coef_[0][0]
t0, t1![]()
sample_data.plot(kind='scatter', x="GDP per capita", y='Life satisfaction', figsize=(5,3))
plt.axis([0, 60000, 0, 10])
X=np.linspace(0, 60000, 1000)
plt.plot(X, t0 + t1*X, "b")
plt.text(5000, 3.1, r"$\theta_0 = 4.85$", fontsize=14, color="b")
plt.text(5000, 2.2, r"$\theta_1 = 4.91 \times 10^{-5}$", fontsize=14, color="b")
save_fig('best_fit_model_plot')
plt.show()

cyprus_gdp_per_capita = gdp_per_capita.loc["Cyprus"]["GDP per capita"]
print(cyprus_gdp_per_capita)
#cyprus_gdp_per_capita = np.array(cyprus_gdp_per_capita).reshape(1, -1) [[22587.49]]
cyprus_predicted_life_satisfaction = lin1.predict(np.array(cyprus_gdp_per_capita).reshape(1, -1))[0][0]
cyprus_predicted_life_satisfaction
sample_data.plot(kind='scatter', x="GDP per capita", y='Life satisfaction', figsize=(5,3), s=1)
X=np.linspace(0, 60000, 1000)
plt.plot(X, t0 + t1*X, "b")
plt.axis([0, 60000, 0, 10])
plt.text(5000, 7.5, r"$\theta_0 = 4.85$", fontsize=14, color="b")
plt.text(5000, 6.6, r"$\theta_1 = 4.91 \times 10^{-5}$", fontsize=14, color="b")
plt.plot([cyprus_gdp_per_capita, cyprus_gdp_per_capita], [cyprus_predicted_life_satisfaction,0], "r--")
plt.text(25000, 5.0, r"Prediction = 5.96", fontsize=14, color="b")
plt.plot(cyprus_gdp_per_capita, cyprus_predicted_life_satisfaction, "ro")
save_fig('cyprus_prediction_plot')
plt.show()
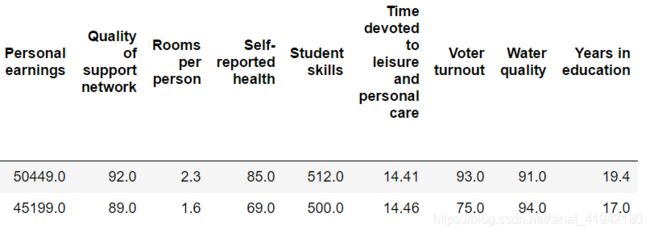
sample_data[7:10]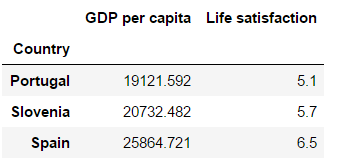
对missing_data数据进行操作
missing_data
position_text2 = {
"Brazil": (1000, 9.0),
"Mexico": (11000, 9.0),
"Chile": (25000, 9.0),
"Czech Republic": (35000, 9.0),
"Norway": (60000, 3),
"Switzerland": (72000, 3.0),
"Luxembourg": (90000, 3.0),
}
sample_data.plot(kind='scatter', x="GDP per capita", y='Life satisfaction', figsize=(8,3))
plt.axis([0, 110000, 0, 10])
for country, pos_text in position_text2.items():
pos_data_x, pos_data_y = missing_data.loc[country]
plt.annotate(country, xy=(pos_data_x, pos_data_y), xytext=pos_text,
arrowprops=dict(facecolor='black', width=0.5, shrink=0.1, headwidth=5))
plt.plot(pos_data_x, pos_data_y, "rs")
X=np.linspace(0, 110000, 1000)
plt.plot(X, t0 + t1*X, "b:")
lin_reg_full = linear_model.LinearRegression()
Xfull = np.c_[full_country_stats["GDP per capita"]]
yfull = np.c_[full_country_stats["Life satisfaction"]]
lin_reg_full.fit(Xfull, yfull)
t0full, t1full = lin_reg_full.intercept_[0], lin_reg_full.coef_[0][0]
X = np.linspace(0, 110000, 1000)
plt.plot(X, t0full + t1full * X, "k")
save_fig('representative_training_data_scatterplot')
plt.show()
用流水线对full_country_stats进行操作
full_country_stats.plot(kind='scatter', x="GDP per capita", y='Life satisfaction', figsize=(8,3))
plt.axis([0, 110000, 0, 10])
from sklearn import preprocessing
from sklearn import pipeline
poly = preprocessing.PolynomialFeatures(degree=60, include_bias=False)
scaler = preprocessing.StandardScaler()
lin_reg2 = linear_model.LinearRegression()
pipeline_reg = pipeline.Pipeline([('poly', poly), ('scal', scaler), ('lin', lin_reg2)])
pipeline_reg.fit(Xfull, yfull)
curve = pipeline_reg.predict(np.array(X).reshape(-1,1))
plt.plot(X, curve)
save_fig('overfitting_model_plot')
plt.show()
full_country_stats.loc[[c for c in full_country_stats.index if "W" in c.upper()]]["Life satisfaction"]
gdp_per_capita.loc[[c for c in gdp_per_capita.index if "W" in c.upper()]].head()
plt.figure(figsize=(8,3))
plt.xlabel("GDP per capita")
plt.ylabel('Life satisfaction')
plt.plot(list(sample_data["GDP per capita"]), list(sample_data["Life satisfaction"]), "bo")
plt.plot(list(missing_data["GDP per capita"]), list(missing_data["Life satisfaction"]), "rs")
X = np.linspace(0, 110000, 1000)
plt.plot(X, t0full + t1full * X, "r--", label="Linear model on all data")
plt.plot(X, t0 + t1*X, "b:", label="Linear model on partial data")
ridge = linear_model.Ridge(alpha=10**9.5)
Xsample = np.c_[sample_data["GDP per capita"]]
ysample = np.c_[sample_data["Life satisfaction"]]
ridge.fit(Xsample, ysample)
t0ridge, t1ridge = ridge.intercept_[0], ridge.coef_[0][0]
plt.plot(X, t0ridge + t1ridge * X, "b", label="Regularized linear model on partial data")
plt.legend(loc="lower right")
plt.axis([0, 110000, 0, 10])
save_fig('ridge_model_plot')
plt.show()