数据预处理
数据预处理
- 概述
-
- (一)数据清理
- (二)数据集成
- (三)数据变换
- (四)数据规约
- python的数据预处理
-
-
- 数据缺失处理函数
- (1)数据过滤dropna
- (2)数据填充fillna
- (3)检测和过滤异常值
- (4)移除重复数据
- (5)数据规范化
- (6)汇总和描述等统计量的计算
-
概述
常遇见的数据存在噪声、冗余、关联性、不完整性等。
数据预处理的常见方法
(1)数据清理:将数据中缺失的值补充完整、消除噪声数据、识别或删除离群点并解决不一致性。
(2)数据集成:将多个数据源中的数据进行整合并统一存储
(3)数据变换:通过平滑聚集、数据概化、规范化等方式将数据转换成适用于数据挖掘的形式
(4)数据归约:数据挖掘经常数据量很大,通过对数据集进行规约或简化,可以保持元数据的完整性,且数据归约后的结果与规约前的结果几乎相同。
(一)数据清理
(1)异常数据处理:个别值的数据明显偏离其余的观测值.
在对异常数据处理之前,先对数据进行分析。
分析方法;
1.使用统计量进行判断【如平均值,最值】;
2.使用盖帽原则【距离平均值三倍标准差外的数值出现属于小概率事件,若出现,则可以认为是异常点】;
3.箱线图,直观看见数据分布的具体情况,数据超出箱线图的上下界,则认为是异常数据。
异常数据处理方法:
1.删除有异常数据的记录;
2.视为缺失值:按照缺失值的处理方法进行处理;
3.平均值修正:使用前后两个观测值的平均值代替,或使用整个数据集的平均值;
4.不处理:当作正常值。
(2)缺失值处理:记录数据由于某原因使部分数据丢失
产生数据缺失的原因:
1.部分信息因为不确定原因暂时无法获取;
2.信息虽然记录,但保管不当,造成缺失;
3.人员疏忽,漏记。
缺失数据处理方法;
1.忽略缺失数据;
2.去掉包含缺失数据的属性;
3.手工填写缺失值;
4.默认值代替;
5.平均值或众数代替。
6.最近邻补插;附近其他样本数据代替,或前后数据平均值代替;
7.回归方法:使用其他样本该属性的值建立拟合模型,用该模型预测缺失值;
7.插值法:和回归法类似。
(3)噪声数据处理:
1.分箱方法:把待处理的数据(某列属性值)按照一定的规则放进一些箱子(区间),考察每个箱子数据,,然后采用某种方法对各个箱子进行数据处理。
2.等深分箱法:统一权重法:即设权重为4,则一个区间4个数据
3.等宽分箱法:统一区间法:即设置区间范围为40,则每个区间最大值-最小值为40
4.用户自定义
分箱后的平滑处理
1.按平均值平滑:对同一箱中的数据求平均值,并用平均值代替该箱子所有数据
2.按边界值平滑:用距离较小的边界值代替箱中每一个数据
3.按中值平滑:取箱子中的中值,代替箱子中所有数据
(二)数据集成
人们日常使用的数据有的连续,有的离散,有的模糊,有的定性,有的定量。
数据集成就是将多文件或多数据库的异构数据进行合并,然后存放在一个统一的数据库中存储。
要考虑的问题:
1.实体识别:
(1)同名异义:数据源A 某个数据特征的名称和数据源B某个数据特征的名称一样,但表达的内容一样。
(2)异名同义:数据源A某个数据特征的名称和数据源B某个特征的名称不一样,但表示的内容一样。
(3)单位不统一:不同的数据源记录的单位不一样,如身高,可能是米,可能是英尺
2.冗余属性:
(1)同一属性多次出现:如两个数据源都记录了每天的最高温,最低温,数据集成时就会出现两次。
(2)同一属性命名不一致导致数据重复
3.数据不一致:如日期“2021/1/1”和“1/1/2021”
(三)数据变换
将数据转换或统一成试和机器学习的形式
数据变换的方法:
(1)使用简单数学函数
开方、平方,取对数、差分运算等
具体看情况。如果数据量大,可取对数或开方压缩数据;数据较小,可平方扩大数据。时间序列经常使用对数变换或差分运算将非平稳转换为平稳序列。
(2)归一化
将数据落入一个有限的范围,常见的归一化将数据调整到【0,1】或【-1,1】内
i.最小——最大归一化 。x’=(x-x_min)/(x_max-x_min)
ii. Z_score标准化方法 。要求原始数据的分布近似高斯分布,x’=(x-u)/标准差
iii. 小数定标规范化 。通过移动数据的小数点位置 x’=x/(10^K)
(3)连续属性离散化
将连续空间划分为若干个区间,用不同的符号或整数值代表每个子区间的数据
i. 等宽法:每个区间间隔相同
ii. 等频法:每个区间数据相同
iii. 基于聚类分析的方法:k_means算法
(四)数据规约
尽可能保持原始数据原貌的情况下,最大限度地精简数据量
(1)维归约:维归约也称特征规约,是指减少属性特征的方式压缩数量。
如;【AIC准则选择最优模型选择属性;LASSO约束选择变量;分类树、随机森林通过对分类效果的影响筛选属性;主成分分析经过数据变换来降低维度】
(2)数值规约:从数据集中选择一个有代表性的样本的子集。
如:【参数方法中使用模型估计数据;回归模型和对数模型可以用来进行参数化数据规约;非参数可以用直方图、聚类、抽样和数据立方体聚集】
python的数据预处理
python的数据结构
(1)Series:一维数组,主要有两个属性:索引index和数据values
from pandas import Series ,DataFrame
s=Series([1,2,3,0,"abc","dfr"])
print(s)
0 1
1 2
2 3
3 0
4 abc
5 dfr
dtype: object
索引从0开始,是自动生成的,也可以直接传递索引。
from pandas import Series ,DataFrame
s=Series([1,2,3,0,"abc","dfr"],index=[10,20,30,40,50,60])
print(s)
10 1
20 2
30 3
40 0
50 abc
60 dfr
dtype: object
(2)DataFrame:一个DataFramE类似于一个表格,有行和列的索引。
from pandas import Series ,DataFrame
data={"id":[100,101,102,103,104],"name":["aa","bb","cc","dd","ee"],"age":[18,19,20,21,19]}
data1=DataFrame(data)
print(data1)
id name age
0 100 aa 18
1 101 bb 19
2 102 cc 20
3 103 dd 21
4 104 ee 19
索引从0开始,是自动生成的,也可以直接传递索引。
from pandas import Series ,DataFrame
data={"id":[100,101,102,103,104],"name":["aa","bb","cc","dd","ee"],"age":[18,19,20,21,19]}
data2=DataFrame(data,index=["one","two","three","four","five"])
print(data2)
id name ageone 100 aa 18
two 101 bb 19
three 102 cc 20
four 103 dd 21
five 104 ee 19
数据缺失处理函数
pandas使用浮点值NaN表示浮点和非浮点数组中的缺失数据,内置的None值也会被当作NA 处理
from pandas import Series ,DataFrame
from numpy import nan as NA
data=Series([12,None,34,NA,67])
print(data)
0 12.0
1 NaN
2 34.0
3 NaN
4 67.0
dtype: float64
可以看出,这个数据的第二个和第四个都被视为缺失值。可以使用isnull来检测是否为缺失值,这种方法返回的是一个布尔型数组。
print(data.isnull())
0 False
1 True
2 False
3 True
4 False
dtype: bool
(1)数据过滤dropna
将缺失值的数据直接过滤掉,不再考虑
dropna(axis=0,how=“any”,thresh=None)
axis=0表示行,1表示列
how参数为any或all,all表示去掉全为NA的行
thresh整数类型,删除的条件.thresh=3,表示一行中至少有3个NA值时才将其保留
from pandas import Series, DataFrame
from numpy import nan as NA
data=Series([12,None,34,NA,68])
print(data.dropna())
0 12.0
2 34.0
4 68.0
dtype: float64
可以看出,缺失值被删除了
from pandas import Series, DataFrame
from numpy import nan as NA
import numpy as np
data=DataFrame(np.random.randn(5,4))
data.iloc[:2,1]=NA
data.iloc[:3,2]=NA
print(data)
print("--删除后的结果—")
print(data.dropna(axis=0,thresh=2))
print(data.dropna(thresh=2))
0 1 2 30 -0.200218 NaN NaN -0.867163
1 -1.385513 NaN NaN 1.838033
2 -0.953998 -1.456857 NaN -2.299435
3 -1.249145 0.760627 1.102958 -0.848231
4 -1.094464 -0.061005 0.883289 0.327752
–删除后的结果—
0 1 2 3
0 -0.200218 NaN NaN -0.867163
1 -1.385513 NaN NaN 1.838033
2 -0.953998 -1.456857 NaN -2.299435
3 -1.249145 0.760627 1.102958 -0.848231
4 -1.094464 -0.061005 0.883289 0.327752
0 1 2 3
0 -0.200218 NaN NaN -0.867163
1 -1.385513 NaN NaN 1.838033
2 -0.953998 -1.456857 NaN -2.299435
3 -1.249145 0.760627 1.102958 -0.848231
4 -1.094464 -0.061005 0.883289 0.327752
哎呀,这个地方不知道为什么没有删除成功,搜了一下也没有找到!!有没有大佬知道原因能指导指导!!!
(2)数据填充fillna
fillna(value,method,axis) axis=0表示行,=1表示列;method表示采用的填补数值的方法
from pandas import Series, DataFrame,np
from numpy import nan as NA
data=DataFrame(np.random.randn(5,4))
data.iloc[:2,1]=NA
data.iloc[:3,2]=NA
print(data)
print("--数据填充后的结果—")
print(data.fillna(0))
0 1 2 30 0.375913 NaN NaN -0.567619
1 -0.896926 NaN NaN 0.375548
2 -0.083053 -0.051676 NaN 1.092362
3 1.344795 1.007109 -1.431133 -1.887074
4 1.057978 0.131849 2.358150 -0.241893
–数据填充后的结果—
0 1 2 3
0 0.375913 0.000000 0.000000 -0.567619
1 -0.896926 0.000000 0.000000 0.375548
2 -0.083053 -0.051676 0.000000 1.092362
3 1.344795 1.007109 -1.431133 -1.887074
4 1.057978 0.131849 2.358150 -0.241893
在上面程序中,把所有缺失值NaN用0代替
下面是对字典的方法对缺失值填充
from pandas import Series, DataFrame,np
from numpy import nan as NA
data=DataFrame(np.random.randn(5,4))
data.iloc[:2,1]=NA
data.iloc[:3,2]=NA
print(data)
print("--数据填充后的结果—")
print(data.fillna({1:11,2:22}))
0 1 2 30 -0.253480 NaN NaN -0.229835
1 -0.425062 NaN NaN -0.617864
2 -2.830569 0.686721 NaN -0.163425
3 0.867149 -0.663633 -0.843753 0.583036
4 1.997611 -1.950240 0.278901 -1.166493
–数据填充后的结果—
0 1 2 3
0 -0.253480 11.000000 22.000000 -0.229835
1 -0.425062 11.000000 22.000000 -0.617864
2 -2.830569 0.686721 22.000000 -0.163425
3 0.867149 -0.663633 -0.843753 0.583036
4 1.997611 -1.950240 0.278901 -1.166493
在这个代码中,使用fillna({1:11,2:22})将第一列的缺失值用11代替,第二列的缺失值用22代替
from pandas import Series, DataFrame,np
from numpy import nan as NA
data=DataFrame(np.random.randn(5,4))
data.iloc[:2,1]=NA
data.iloc[:3,2]=NA
print(data)
print("--数据填充后的结果—")
print(data.fillna({1:data[1].mean(),2:data[2].mean()}))
0 1 2 30 -1.363661 NaN NaN -0.913740
1 -0.437810 NaN NaN 1.100868
2 1.071662 0.418858 NaN -2.619486
3 -0.768608 -1.021960 -0.069304 -0.563550
4 0.023320 -0.437949 -0.156693 -0.450456
–数据填充后的结果—
0 1 2 3
0 -1.363661 -0.347017 -0.112999 -0.913740
1 -0.437810 -0.347017 -0.112999 1.100868
2 1.071662 0.418858 -0.112999 -2.619486
3 -0.768608 -1.021960 -0.069304 -0.563550
4 0.023320 -0.437949 -0.156693 -0.450456
将第一列的缺失值用这一列其他值的均值代替,第二列同理。
(3)检测和过滤异常值
from pandas import Series, DataFrame,np
from numpy import nan as NA
data=DataFrame(np.random.randn(10,4))
print(data.describe()) #描述性统计
print("\n...找出某一列中绝对值大小超过1的项...\n")
data1=data[2] #将第二列数据赋值给data1
print(data1[np.abs(data1)>1])
data1[np.abs(data1)>1]=100 #将所有大于1的数修改为100
0 1 2 3count 10.000000 10.000000 10.000000 10.000000
mean 0.357868 0.393356 -0.487434 0.097425
std 0.963464 0.834344 0.773542 1.349689
min -1.772427 -0.779077 -1.576785 -2.610861
25% 0.058369 -0.181608 -0.809393 -0.782549
50% 0.339938 0.381917 -0.720482 0.375036
75% 0.986934 0.797928 0.056824 1.057615
max 1.737456 1.639013 0.901008 1.789583
…找出某一列中绝对值大小超过1的项…
0 -1.369672
1 -1.576785
Name: 2, dtype: float64
(4)移除重复数据
pandas中的duplicated发现重复值,drop_duplicated移除重复值
import pandas as pd
import numpy as np
data=pd.DataFrame({"name":["zhang"]*3+["wang"]*4,"age":[18,18,19,19,20,20,21]})
print(data)
print("--重复的内容是:---\n")
print(data.duplicated())
name age
0 zhang 18
1 zhang 18
2 zhang 19
3 wang 19
4 wang 20
5 wang 20
6 wang 21
–重复的内容是:—
0 False
1 True
2 False
3 False
4 False
5 True
6 False
dtype: bool
可以看出,返回的是一个布尔型,表示各行是否重复
(5)数据规范化
import pandas as pd
import numpy as np
datafile="D://数据来源"
data=pd.read.excel(datafile,header=None)
min=(data-data.min())/(data.max()-data.min()) #最小最大规范化
zero=(data-data.mean())/data.std() #零一均值规范化
float=data/10**np.ceil(np.log10(data.abs(),max())) #小数定标规范化
print("原始数据为:\n",data)
print("最小-最大规范后的数据:\n",min)
print("零一均值规范后的数据:\n",zero)
print("小数定标规范化后的数据:\n",float)
(6)汇总和描述等统计量的计算
import pandas as pd
import numpy as np
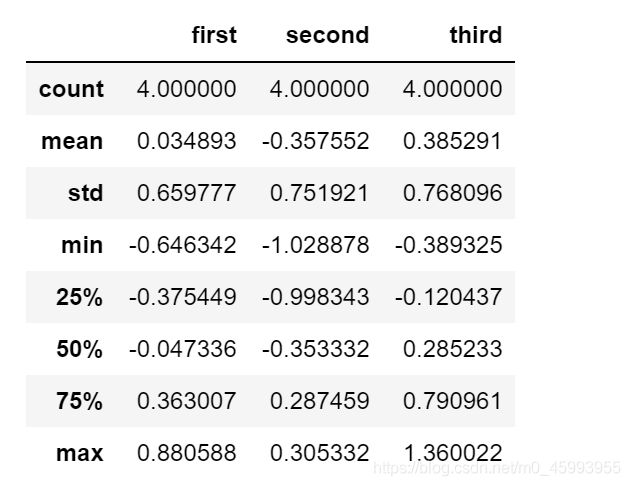
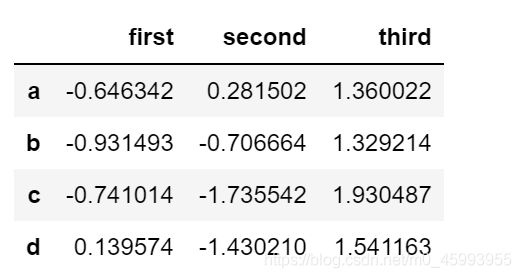
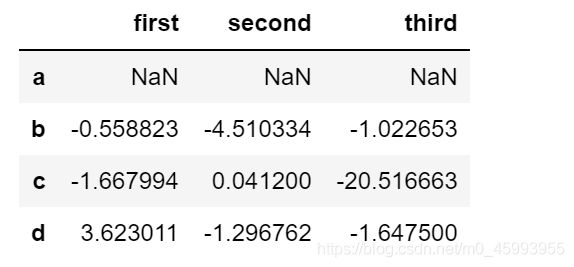
df=pd.DataFrame(np.random.randn(4,3),index=list("abcd"),columns=["first","second","third"])
#np.random.randn()以给定的形状返回一个或一组样本,具有标准正态分布
df.describe() #描述性统计分析
df.sum() #统计每列数据的和
first 0.139574
second -1.430210
third 1.541163
dtype: float64
df.sum(axis=1) #统计每行数据的和
a 0.995182
b -1.304125
c -0.237125
d 0.796595
dtype: float64
df.idxmin()#统计每列最小数值所在的行
first a
second c
third d
dtype: object
df.idxmin(axis=1) #统计每行最小数值的列
a first
b second
c second
d third
dtype: object
df.idxmax() #统计每列最大数值所在的行
first d
second d
third a
dtype: object
df.cumsum() #计算相对于上一行的累计结果
df.var() #计算方差
df.std() #计算标准差
df.pct_change() #计算百分数的变化
df.cov() #计算协方差
df.corr() #计算相关系数,默认皮尔森方法