HEVC学习笔记(1)
图像处理单元
CTU —— 编码树单元,由YCbCr推知,CTU包含三个CTB,一个亮度两个色度
CTU 的大小类型可以有 16x16 32x32 64x64三种类型
CU —— 编码单元,同理包含三个CB,CU是决定进行帧内预测还是帧间预测的单元。
TU —— HEVC中变换、量化与熵编码的基本单位。CU划分TU,由当前CU的大小与头信息中规定的最大和最小TU尺寸决定。
CTU为块处理时的基本单元,可以按四叉树划分为CU,也可以不分解,为一个CU。
CTU向CU划分,CU向PU和TU划分,都是采用的四叉树划分。
在HEVC中,由于PU和TU都由CU划分得到,因此二者大小没有确定的关系。一个PU可能包含多个TU,一个TU也可能跨越多个PU,但显然二者大小必须小于等于CU。
需要注意的是:对于帧内编码(前提条件),由于相邻PU之间存在依赖关系(已编码的PU须用于预测与之相邻的PU),因此一个PU可以包含一个或多个TU,但一个TU最多只能对应一个PU。
图像的划分有Slice和Tilie
Slice是带状的,Tilie是矩形
一幅图像的各个Slice或Tilie独立编解码
预测编码
帧(图像)内相邻像素pixel 之间存在空间相关性,帧间又存在时间相关性,由此可以引出帧内预测和帧间预测。
在编码上,是将真实值和预测值之间的差值进行编码,这样可以提高压缩效率。
有记忆信源的编码方式
联合编码和条件编码是两种有记忆信源的有效编码方式。
这个好像不是很重要
预测编码的基本过程如下图所示:
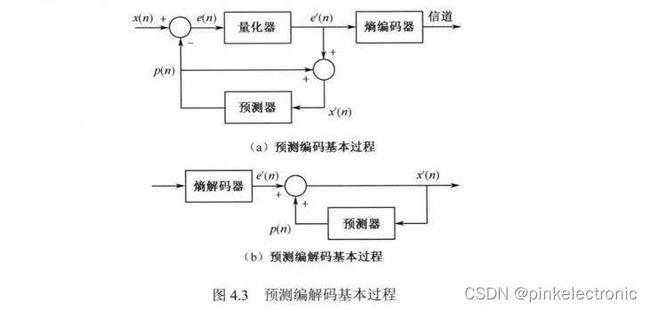
由图可知,量化、编码的对象为残差e(n),解码后得到的对象为输入像素的重建值x'(n),获得的x'(n)通过预测器可以获得下一个输入样本真实值。
帧内预测编码
随着离散余弦变换(DCT)的广泛应用,帧内预测转为在频域进行,如相邻块DC系数的差分编码。
由DCT的性质可知,DC系数仅能反映当前块像素值的平均大小,即频域上基于DC系数的帧内预测无法反映出视频的纹理信息。
因此,H.264引出了很多预测模式。为了选择出最合适的帧内预测模式,H.264/AVC使用拉格朗日率失真优化(RDO)进行模式选择,为每一种模式计算拉格朗日代价:
![]()
其中,D表当前预测模式下的失真,R表示编码当前预测模式下所有信息所需的比特数,λ为拉格朗日因子。
需要注意的是,最优的预测模式不一定满足残差e最小,而应指残差信号经过编码模块后的编码性能最优。
帧间预测编码
目前主要的视频编码标准,帧间预测部分都采用了基于块的运动补偿技术,其主要原理是:为当前图像的每个像素块在之前已编码的图像中寻找一个最佳匹配块,该过程称为运动估计(Motion Estimation,ME),其中用于预测的图像(已编码)称为参考图像,参考块到当前像素块的位移称为运动向量(Motion Vector,MV),当前像素块与参考块的差值称为预测残差(Predicition Residual)
早期的视频编码标准H.261定义了两种类型的图像——I图像和P图像,其中I图像仅能使用帧内编码,而P图像可以利用帧间预测编码。
在H.261标准中,P图像的预测方式必须是由前一幅图像预测当前图像,这种方式称为“前向预测”(FP).但实际场景中往往会产生不可预测的运动和遮挡,因此当前图像的某些像素块可能无法从之前的图像中找到匹配块,而在之后的图像中很容易找到匹配块。
于是,定义出了第三类图像——B图像,并规定B图像可以使用前、后和双向预测。
这样,B图像的一个块可以对应两个MV,一个来自前向一个来自后向。
由于实际场景中物体运动的距离不一定是像素尺寸的整数倍,为了提高运动估计的精度,引出了半像素精度的运动估计,然后之后的标准就越来越小。
帧间预测编码的关键技术
1)运动估计
运动估计(ME):提取当前图像运动信息的过程。
由于在图像中准确分割出运动物体和背景是很困难的(是不是没用cv),目前大多数运动估计算法都是基于像素值进行的。其中有基于像素的运动表示法和基于区域的运动表示法。
基于像素的运动表示法要给每一个像素一个MV,基于区域的运动表示法,则是把图像分为多个区域,使得每个区域恰好表征一个完整的运动物体,即每个区域中的像素具有相同的运动形式,但由于准确的划分是比较难的,所以这个也不怎么用。
像素太小了,数据量太大;区域太大了,太难准确划分——引出了折衷方案,基于块的运动表示法。块的运动表示法将图像分为不同大小的像素块,只要块的大小合适,则块的运动形式可以看成是统一的,每个块的运动参数都可以独立地进行估计。
基于块的运动估计方法,有几个核心问题:
(1)运动估计准则
运动估计的目的是为了给当前块在参考图像中找到一个最佳匹配块,因此也需要一个标准。
有很多标准 MSE(Mean Square Error)、MAD(Mean Absolute Difference)和MPC(Matching-Pixel Count)。为了简化计算,一般用SAD(Sum Absolute Difference)
SAD还有不足,仅考虑了残差的大小,没有考虑编码运动信息所需的bit数。
因此,在H.264/AVC中,使用了拉格朗日率失真优化的方法来选择MV。
(2)搜索算法
写这个之前想理一理逻辑:
为了更好的进行帧间预测,我们先确定了要用基于块的运动表示法,或者说基于块的运动补偿。于是引出了一个问题,我们怎么知道哪个块最匹配?于是有了一个运动估计准则,帮助去判断最好的块。判断最匹配的块的方法也有了,可是问题又来了,参考图像中的块那么多,通过准则去运算又很复杂,每个块都去算,实时性就不好,所以我们希望减少这个运算量,怎么减少呢?于是引出了搜索方法,希望不要算参考图像中的每个块。
常用的搜索算法有:全搜索算法、二维对数搜索算法、三步搜索算法等。
全搜索算法顾名思义,就是对搜索窗内所有可能的位置计算两个块的匹配误差,这样就进入了我们之前说到的点,效率、实时性不好。
除全搜索算法外,其余搜索算法都称为快速搜索算法,有个缺点是容易陷入局部最优点,从而无法找到全局最优点(所以都是大同小异,深度学习中也有如此说法)
(3)亚像素精度运动估计
之前也说到了,相邻两图像之间物体的运动不一定是以整像素为基本单位的,H.265/HEVC 使用1/4像素精度运动估计。
图像是以像素为单位的,然而因为相邻帧运动幅度可能会比像素单位小,因此人为的希望细划分,实际上图像并没有再小的单位了,这就引入了插值,通过已知的像素值来获得那些更小单位的值。
2)MV预测(Motion vector)
在大多数图像和视频中,一个运动物体可能会覆盖多个运动补偿块,因此这些相邻运动块的运动向量在空间中会较强的相关性,有了相关性我们就想用已编码预测再跟真实值做差,将这个差值进行编码。(帧内)
同理,由于物体运动的连续性,相邻图像同一位置像素块的MV也具有一定的相关性。(帧间)
帧内预测
在 H.265/HEVC中,35种预测模式是在PU的基础上定义的,而具体帧内预测过程的实现则是以TU为单位的。标准规定PU可以以四叉树的形式划分TU,且一个PU内的所有TU共享同一种预测模式。
HEVC帧内预测可分为以下三个步骤:
①判断当前TU相邻参考像素是否可用并作相应处理;
②对参考像素进行滤波; (更好地利用邻近像素之间的相关性,提高预测精度)
③根据滤波后的参考像素计算当前TU的预测像素值。
1. 相邻参考像素的获取(参考是已编码的)
设当前TU大小为NXN,一般情况下的相邻参考像素如下图所示:
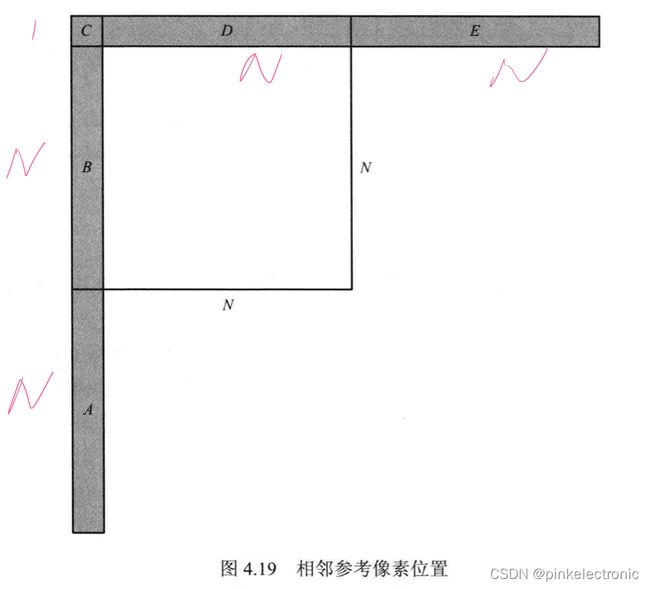
考虑到TU可能位于图像边界,或Slice、Tile的边界(HEVC规定,相邻Slice或Tile不能相互参考),此时,相邻参考像素可能会不存在或不可用,为了解决这种情况,HEVC标准会使用最邻近的像素进行填充。
2.参考像素的滤波
之前也提到过,为了更好地利用邻近像素之间的相关性,提高预测精度。