C++ 多线程学习12 线程池
引言
为什么要做线程池:
在做高并发时线程的创建和销毁都是有开销的,因此提前将线程池创建好再,用的时候再到线程池中取就行了
16个线程是共享任务列表的,在添加任务前要做好互斥访问
一、启动线程池
mian()函数中先创建线程池对象:
XThreadPool pool;
调用线程的初始化函数init(),向init()传参数n来为线程池的线程数量成员赋值:
this->thread_num_ = num;
用start()启动线程,在run中先判断线程池是否完成初始化,再判断线程是否以及启动了:
然后创建thread_num_个线程,每个线程的线程入口为run()
auto th = make_shared<thread>(&XThreadPool::Run, this);
threads_.push_back(th);
为指向对象的类型,新建一个thread对象需要一个入口函数,由于这个函数是类成员函数,所以还需要一个this指针,返回类型为一个指针th,随后用一个线程列表threads_来管理这个th:
std::vector< std::shared_ptr<std::thread> > threads_;
此时线程池已经启动了:
二、线程池开始服务于用户
main()在启动线程后紧跟一个无限循环,与用户在终端上进行交互,
(1)输入L时调用线程池的task_run_count(),返回任务计数,任务计数在task run前+1,结束时减1,
(2)输入e时直接break结束无限循环
(3)输入v时开始视频转码:先用make_shared来创建一个task对象,输入视频源,输出尺寸,保存信息等。将这些信息丢给创建好的task对象,然后将这个任务丢到线程池中,用线程池来判断任务的启动时机
//线程池线程的入口函数
void XThreadPool::Run()
{
cout << "begin XThreadPool Run " << this_thread::get_id() << endl;
while (!is_exit())
{
auto task = GetTask();
if (!task)continue;
++task_run_count_;
try
{
auto re = task->Run();
//task->SetValue(re);
}
catch (...)
{
}
--task_run_count_;
}
cout << "end XThreadPool Run " << this_thread::get_id() << endl;
}
因为一个线程的错误不能影响这个线程池的运行因此要捕获异常
线程池中的线程本身无任务,每个线程在while()中不断重复三件事
(第一件事)通过GetTask()来获得线程池中任务列表tasks_中的task:
unique_lock<mutex> lock(mux_);
if (tasks_.empty())
{
cv_.wait(lock);
}
if (is_exit())
return nullptr;
if (tasks_.empty())
return nullptr;
auto task = tasks_.front();
tasks_.pop_front();
return task;
用户可能大批量输入任务,若没有使用多线程则一次只能处理一个,效率非常低下,又不想无限制创建线程来处理他们,这可能导致系统崩溃,于是使用线程池规定一次只能处理16个任务,未处理的任务在任务队列tasks_中排队,当任务队列为空时,将一直阻塞在cv_.wati(lock)处,直到用户在终端处输入任务后通过cv.notify才会运行后面的
(第二件事)调用刚刚获得的任务的run(),在其中将用户在终端输入的指令组合起来成一个能ffmpeg的命令行,比如:
ffmpeg -y -i test.mp4 -s 400x300 400.mp4 >log.txt 2>&1,然后用system()中直接进行系统调用:
int XVideoTask::Run()
{
//ffmpeg -y -i test.mp4 -s 400x300 400.mp4 >log.txt 2>&1
stringstream ss;
ss << "ffmpeg.exe -y -i " << in_path<<" ";
if (width > 0 && height > 0)
ss << " -s " << width << "x" << height<<" ";
ss << out_path;
ss << " >" << this_thread::get_id() << ".txt 2>&1";
return system(ss.str().c_str());
}
三、线程池退出
当输入e退出后,调用线程池的stop()
/// 线程池退出
void XThreadPool::Stop()
{
is_exit_ = true;
cv_.notify_all();
for (auto& th : threads_)
{
th->join();
}
unique_lock<mutex> lock(mux_);
threads_.clear();
}
注意点:
结合线程入口函数去理解:
//线程池线程的入口函数
void XThreadPool::Run()
{
cout << "begin XThreadPool Run " << this_thread::get_id() << endl;
while (!is_exit())
{
auto task = GetTask();
if (!task)continue;
++task_run_count_;
try
{
auto re = task->Run();
//task->SetValue(re);
}
catch (...)
{
}
--task_run_count_;
}
}
01设置is_exit_ = true;让线程的run()停掉无限循环
02为啥要cv_.notify_all();
若没有这句,退出时将卡在这:
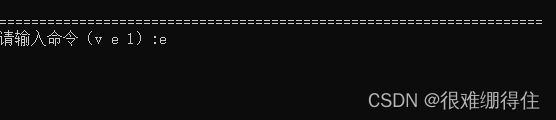
就算没有任务进来但此时线程池中的16个线程正在run,GetTask()中卡在cv.wait(),其等待cv发给他信号,这个时候这个线程将一直保持阻塞态,所以会卡在这里
03为啥要让所以的线程join()
当一个线程是joinable时调用析构将会报错(当其是可加入时即使其运行完了,其线程资源释放需要其他线程通过join()来完成)
四、跑起来
先开启16个线程,后面是其线程号
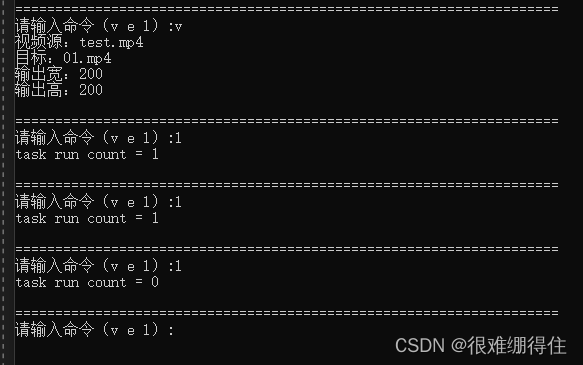
输入一次转码命令,然后不停查看当前运行任务个数,先是1,运行结束后再l显示0
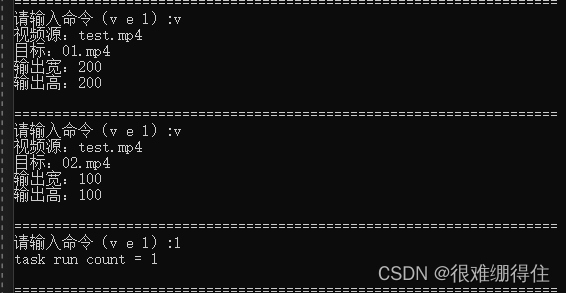
由于测试视频较短加上手速较慢,显示不出2:
五、注意点
(1)线程池的stop()做了哪些事情:
1.先让is_exit变量置true,使线程池中的线程的run不再进入while()
2.调用cv_.notify_all();让线程池中的线程的get_task的cv.wait()跳过
3.通过管理线程池中线程的列表来依次让这些join(),等待其退出(其实是等待这些线程资源的释放:如寄存器中的值,每个线程独有的一些空间等)
(2)为什么用std::vector< std::shared_ptr来做管理线程的列表:
1.管理线程的目的主要是在退出时可以依次对这些线程来join,只需要遍历一遍列表,依次调用join即可
2.使用智能指针可以在退出时不用new
3.创建往智能指针列表中传的指针值时的方法:
for (int i = 0; i < thread_num_; i++)
{
auto th = make_shared<thread>(&XThreadPool::Run, this);
//shared_ptrth(new thread(&XThreadPool::Run, this));
threads_.push_back(th);
}
使用make_shared与shared_ptr皆可,但是有点小区别:
使用make_shared代替share_ptr x(new xxx())的好处:
①性能更好:new来构造shared_ptr指针,那么new的过程是一次堆上面的内存分配,而在构造shared_ptr对象的时候,由于需要使用堆上面共享的引用计数,所以又需要在堆上面分配一次内存,即需要分配两次内存,而如果用make_shared函数,则只需分配一次内存,性能会好很多。
②更加安全:shared_ptr构造时,包含两步操作,(1)new一个堆内存,(2)分配一个引用计数区域管理该内存空间,并没有保证这两个步骤的原子性,当做了第(1)步,没有做第二步如果程序抛出了异常,将导致内存泄露,因此更推荐使用make_shared来分配内存。
③缺点:make_shared一次性分配堆内存的做法,在释放的时候可能会导致内存延迟释放,因为如果有weak_ptr持有了指针,引用计数不会释放,而引用计数和实际的对象分配在同一块堆内存,因此无法将该对象释放,如果两块内存分开申请,则不存在这个延迟释放的问题。
总结:
因此make_shared和传统的shared_ptr构造各有优劣,通常情况,推荐使用make_shared,因为更加高效和安全,当对内存释放比较敏感时,应该使用普通的shared_ptr构造。
原文链接:https://blog.csdn.net/XiaoH0_0/article/details/101791274
4…使用std::vector< std::unique_ptrstd::thread > threads_;可以吗
答案是肯定的,先看直接修改成uniq_ptr:
for (int i = 0; i < thread_num_; i++)
{
//auto th = new thread(&XThreadPool::Run, this);
//auto th = make_shared(&XThreadPool::Run, this);
//shared_ptrth(new thread(&XThreadPool::Run, this));
unique_ptr<thread>th(new thread(&XThreadPool::Run, this));
//threads_.push_back(move(th));
threads_.push_back(th);
}

错误原因是unique_ptr是auto_ptr的改进,auto_ptr在转移对象的所有权时,原ptr的空间可能被访问到造成运行时错误,unique_ptr改进这个缺点在编译时就就认为转移对象所有权的操作是非法的(编译阶段错误比潜在的程序崩溃更安全),而在将其插入threads_时会调用对象的转移,将会报错
想使用unique_ptr的话需要使用move()将其变为右值(move带来的好处并非是让程序员能够编写出使用右值引用的代码,而是能够利用右值引用实现移动语义的库代码):
for (int i = 0; i < thread_num_; i++)
{
//auto th = new thread(&XThreadPool::Run, this);
//auto th = make_shared(&XThreadPool::Run, this);
//shared_ptrth(new thread(&XThreadPool::Run, this));
unique_ptr<thread>th(new thread(&XThreadPool::Run, this));
//threads_.push_back(move(th));
threads_.push_back(move(th));
}
右值引用的作用:
假设有个类data,其中有一个指针成员pt,其对+进行了重载,可以将data1的pt指向的数据与data2的pt指向的数据相加,然后新对象的pt指向相加后的数据,若是用两个data对象相加做为拷贝构造函数(创建data3)的参数,将先调用重载的+获得一个对象,再调用拷贝构造函数,比较浪费内存,于是引出了移动语义的概念,让+创建的对象的pt指向的对象留在原来的地方,data3的pt指向这个对象的pt的数据。
要实现移动语义,就要让编译器知道什么时候调用拷贝构造,什么时候不需要,这就是右值引用发挥作用的地方。
使用移动语义的移动构造函数:
data(data&&d)
{
pt=d.pt;
d.pt=nullptr;
}
再调用data data3(data1+data2)时由于data1+data2为右值,将直接调用移动构造函数而不是拷贝构造函数,节约了内存。
5.为什么要先解锁再通知
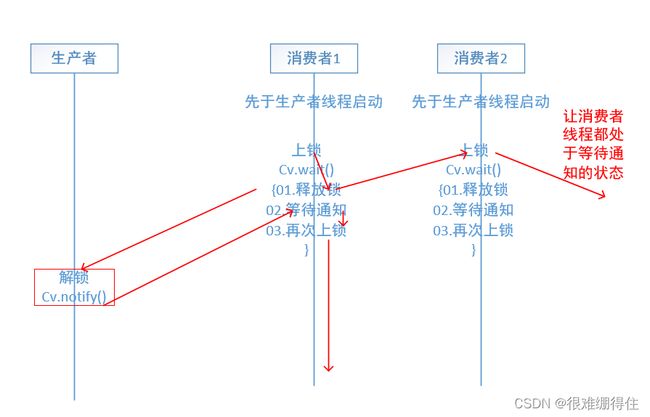
先通知再解锁也是可以的,不过相对来说会浪费时间和效率,这是因为消费线程是先启动的,所有消费者线程都卡在wait处等待生产者线程发出通知,等某个消费者线程收到通知后的下一步操作是上锁,若先通知再解锁的话可能消费者线程要多次尝试获取锁,就会稍微浪费一些资源
6.为什么get_task要判断两次队列是否为空:
unique_lock<mutex> lock(mux_);
if (tasks_.empty())
{
cv_.wait(lock);
}
if (is_exit())
return nullptr;
if (tasks_.empty())
return nullptr;
auto task = tasks_.front();
tasks_.pop_front();
return task;
这是常见的双重检查锁模式,在单例模式中线程安全的懒汉模式也是这样用的。
其中第一个判断为了性能问题,如果任务队列不为空的话就不用去尝试加锁了
第二个判断是为了互斥访问,当两个任务队列为空的线程都进到这里了话要互斥访问