NLP论文:BERT各层表示在不同NLP任务上的解释 笔记
NLP论文:BERT各层表示在不同NLP任务上的解释 笔记
- 论文
- 介绍
- 模型结构
- 文章翻译
-
- Abstract
- 1 Introduction
- 2 Model
- 3 Metrics
-
- 3.1 Scalar Mixing Weights
- 3.2 Cumulative Scoring
- 4 Results
-
- 4.1 Per-Example Analysis
- 5 Conclusion
- A Appendix
- 相关视频
- 相关的笔记
- 相关代码
-
- pytorch
- tensorflow
-
- keras
- pytorch API:
- tensorflow API
论文
NLP论文笔记合集(持续更新)
原论文:《BERT Rediscovers the Classical NLP Pipeline》
NLP经典论文:BERT 笔记
介绍
2019-08发表的文章,预训练 BERT 在nlp任务上有出色的发挥,但模型的可解释性欠缺,因为该文章提出了量化语言信息在网络中的位置的方法。传统 NLP 任务中模型的 pipeline 的步骤顺序:词性标记、解析、NER、语义角色,然后是指代关系。该文章提出了2个量化指标,标量混合权重 scalar mixing weights 和累积得分 cumulative scoring,可定位出语言信息在网络中的位置,并揭示了 BERT 的 pipeline 的步骤。简单地来说就是,揭示了每一层的表示,适合于作为什么样的NLP任务的输入。
模型结构
BERT 结构参考NLP经典论文:BERT 笔记。
文章翻译
Abstract
预训练的文本 encoder 已经在许多NLP任务上迅速提升了最新技术水平。我们关注一个这样的模型,BERT,目的是量化语言信息在网络中的位置。我们发现,该模型通过可解释和可定位的方式可以表示传统 NLP pipeline 的步骤,并且负责每个步骤的位置按预期顺序出现:词性标记、解析、NER、语义角色,然后是指代关系。定性分析表明,该模型可以并经常会动态调整该 pipeline,在消除高层表示的信息的歧义的基础上修改下层决策。
1 Introduction
诸如 ELMo(Pe ters et al.,2018a)和 BERT(Devlin et al.,2019)等经过预训练的句子 encoder 已经迅速改进了许多NLP任务的最新技术水平,并且似乎准备取代静态单词嵌入(Mikolov et al.,2013)和离散管道(Manning et al.,2014)作为自然语言处理系统的基础。虽然这对性能有好处,但它是以牺牲可解释性为代价的,目前还不清楚这些模型实际上是在学习我们直觉上认为对表示自然语言很重要的抽象,还是只是在为复杂的共现统计建模。
最近的一批工作已经开始“探索”最先进的模型,以了解它们是否以令人满意的方式表达语言。这项工作大多是基于行为的,设计受控测试组件并分析错误,以便对模型可能代表或可能不代表的抽象类型进行逆向工程(例如Conneau等人,2018年;Marvin和Linzen,2018年;Poliak等人,2018年)。并行工作直接检查网络的结构,以评估是否存在与不同类型的语言决策相关的可定位区域。这项工作证明,深层语言模型可以对一系列句法和语义信息进行编码(如Shi等人,2016年;Belinkov,2018年;Tenney等人,2019年),并且更复杂的结构按层次表示于模型更高的层中(Peters等人,2018b;Blevins等人,2018年)。
我们把后一种工作作为基础,重点关注 BERT 模型(Devlin et al.,2019),并使用一套从传统NLP pipeline 衍生的探测任务(Tenney et al.,2019)来量化特定类型语言信息的编码位置。根据观察(Peters等人,2018b),语言模型的较低层编码更多的局部语法,而较高层捕获更复杂的语义,我们提出了两个新的贡献。首先,我们提供了一个跨越传统NLP pipeline 的公共组件的分析。我们表明,特定抽象的编码顺序反映了这些任务的传统层次结构。其次,我们定性地分析了 BERT 网络是如何逐层处理单个句子的。我们表明,虽然 pipeline 顺序在总体上保持不变,但该模型可以允许单个决策以任意方式相互依赖,推迟不明确的决策或根据更高级别的信息修改不正确的决策。
2 Model
Edge Probing. \quad\quad 我们的实验基于Tenney et al.(2019)的“边缘探测”方法,该方法旨在测量从预训练的 encoder 中提取语言结构信息的效果。边缘探测将结构化预测的任务分解为通用格式,其中探测分类器接收跨越 s 1 = [ i 1 , j 1 ) \boldsymbol{s}_1 = [i_1,j_1) s1=[i1,j1) 和(可选) s 2 = [ i 2 , j 2 ) \boldsymbol{s}_2 = [i_2,j_2) s2=[i2,j2) 的数据,并且必须预测标签,例如成分或关系类型 1 ^1 1。探测分类器只能访问目标范围内的每个 token 的上下文向量,因此必须依靠 encoder 提供有关这些范围和它们在句子中的作用之间的关系的信息。
我们使用边缘探测组件中的八个标记任务:词性(POS)、成分(Consts.),依赖项(Deps.),实体、语义角色标记(SRL)、协同引用(Coref.),语义原型角色(SPR;Reisinger等,2015)和关系分类(SemEval)。这些任务来自标准基准数据集,并使用通用指标(微平均F1)进行评估,以便于在任务之间进行比较 2 ^2 2。
BERT. \quad\quad BERT模型(Devlin等人,2019年)在许多任务上显示了最先进的性能,其深度 Transformer 架构(Vaswani等人,2017年)是许多最新模型的典型(例如Radford等人,2018年、2019年;Liu等人,2019年)。我们重点研究了基于3.3B单词英语语料库的多任务目标(masked 语言建模和下一句预测)训练的股票 BERT 模型(base 和 large,uncased)。由于我们想了解网络是如何通过预训练来表示语言的,因此我们遵循Tenney等人(2019)(与标准的BERT用法不同)并固定 encoder 权重。这会防止 encoder 重新排列其内部表示以更好地适应探测任务。
给定输入标记 T = [ t 0 , t 1 , … , t n ] T=[t_0,t_1,…,t_n] T=[t0,t1,…,tn],深度 encoder 产生一组层激活 H ( 0 ) , H ( 1 ) , . . . , H ( L ) H^{(0)},H^{(1)},...,H^{(L)} H(0),H(1),...,H(L),其中 H ( ℓ ) = [ h 0 ( ℓ ) , h 1 ( ℓ ) , . . . , h n ( ℓ ) ] H^{(\ell)}=[\mathbf{h}^{(\ell)}_0,\mathbf{h}^{(\ell)}_1,...,\mathbf{h}^{(\ell)}_n] H(ℓ)=[h0(ℓ),h1(ℓ),...,hn(ℓ)] 是 encoder 第 ℓ \ell ℓ 层的激活向量, H ( 0 ) H^{(0)} H(0) 对应于非上下文的 word(piece) embedding。我们使用各层的加权总和(§3.1)将其汇集到一组单 token 表示向量 H = [ h 0 , h 1 , . . . , h n ] H=[\mathbf{h}_0,\mathbf{h}_1,...,\mathbf{h}_n] H=[h0,h1,...,hn],并使用Tenney等人(2019)的体系结构和步骤为每个任务训练探测分类器 P τ P_\tau Pτ。
Limitations \quad\quad 这项工作是探索性的。我们专注于一个特定的 encoder——BERT——来探索在深层语言模型中信息是如何组织的,需要进一步的工作来确定趋势在总体上保持的程度。此外,我们的工作具有所有基于检查的探测的局限性:我们的探测分类器没有观察到语言模式这一事实并不保证它不存在,对模式的观察也不能告诉我们它是如何使用的。因此,我们强调将结构分析与行为研究相结合(如§1所述)的重要性,以便更全面地了解这些模型编码的信息以及这些信息如何影响下游任务的性能。
3 Metrics
我们定义了两个互补的度量。第一,标量混合权重 scalar mixing weights(§3.1)告诉我们,当探测分类器能够访问整个 BERT 模型时,组合中的哪些层最相关。第二,累积得分 cumulative scoring(§3.2)告诉我们,可以通过引入每一层以在探测任务中获得更高的分数。这些度量提供了关于模型内部发生的事情的补充视图。混合权重仅从训练数据中学习——它们告诉我们探测模型发现哪些层最有用。相比之下,累积得分完全来自 evaluation 集,并告诉我们正确预测需要多少层。
3.1 Scalar Mixing Weights
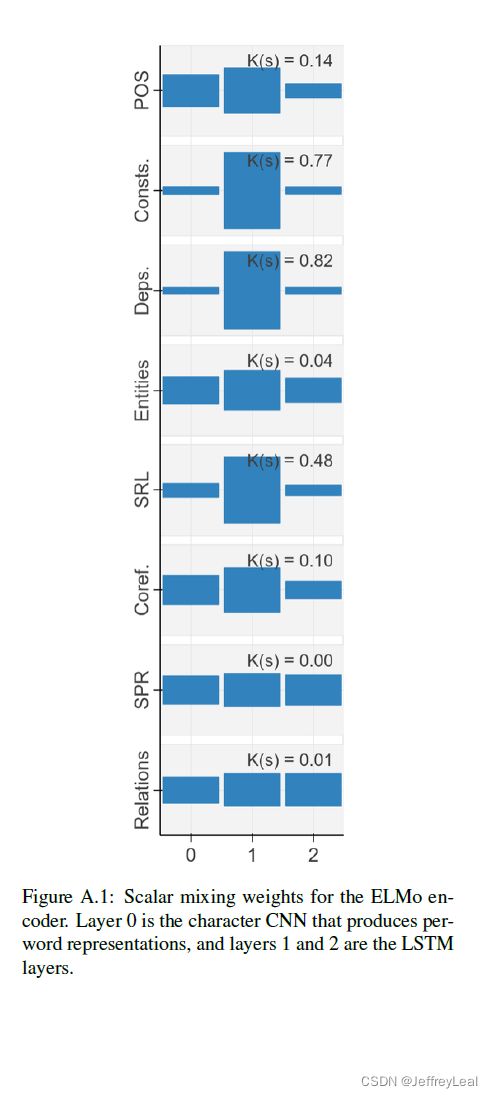
为了整合所有层,我们使用 ELMo 模型引入的标量混合技术。根据Peters等人(2018a)的方程式(1),对于每项任务,我们引入标量参数 P τ P_\tau Pτ 和 a τ ( 0 ) , a τ ( 1 ) , . . . , a τ ( L ) a_\tau^{(0)},a_\tau^{(1)},...,a_\tau^{(L)} aτ(0),aτ(1),...,aτ(L),并设: h i , τ = γ τ ∑ ℓ = 0 L s τ ( ℓ ) h i ( ℓ ) ( 1 ) \mathbf{h}_{i,\tau} = \gamma_\tau \sum\limits _{\ell=0}^L s_\tau^{(\ell)} \mathbf{h}_i^{(\ell)} \quad\quad\quad\quad(1) hi,τ=γτℓ=0∑Lsτ(ℓ)hi(ℓ)(1)其中 s τ \mathbf{s}_\tau sτ 是 softmax( a τ \mathbf{a}_\tau aτ)。我们与探测分类器 P τ P_\tau Pτ 一起学习这些权重,以便在不添加大量参数的情况下从 encoder 的许多层提取信息。训练探测模型后,我们提取学习系数,以估计不同层对特定任务的贡献。我们将较高的权重解释为相应层包含与特定任务相关的更多信息的证据。
Center-of-Gravity. \quad\quad 作为概括统计,我们将混合重量重心定义为: E ˉ s [ ℓ ] = ∑ ℓ = 0 L ℓ ⋅ s τ ( ℓ ) ( 2 ) \bar{E}_s[\ell] = \sum\limits_{\ell = 0}^L \ell \cdot s_\tau^{(\ell)} \quad\quad\quad\quad(2) Eˉs[ℓ]=ℓ=0∑Lℓ⋅sτ(ℓ)(2)这反映了每个任务所涉及的平均层;直观地说,我们可以将更高的值解释为该任务所需的信息由更高的层捕获。
3.2 Cumulative Scoring
我们希望估计在 encoder 的哪一层可以正确预测目标( s 1 , s 2 , l a b l e \boldsymbol{s}_1,\boldsymbol{s}_2,\boldsymbol{lable} s1,s2,lable)。混合权重不能直接告诉我们这一点,因为它们是作为参数学习的,不能与数据的分布相对应。单个层上的朴素分类器也不能,因为关于特定跨度的信息可能分布在多个层上,正如Peters等人(2018b)所观察到的,encoder 可能选择丢弃更高层上的信息。
为了解决这个问题,我们训练了一系列分类器 { P τ ( ℓ ) } ℓ \{P_\tau^{(\ell)}\}_\ell {Pτ(ℓ)}ℓ,它们使用标量混合(等式1)来处理层l以及所有之前的层。 P τ ( 0 ) P_\tau^{(0)} Pτ(0) 对应于仅使用词(片段)袋模型的 embedding 的非上下文基准,而 P τ ( L ) = P τ P_\tau^{(L)}=P_\tau Pτ(L)=Pτ 对应于探测 BERT 模型的所有层。
这些分类器是累积的,从这个意义上讲, P τ ( ℓ + 1 ) P_\tau^{(\ell+1)} Pτ(ℓ+1) 具有相似数量的参数,但严格上可以访问比 P τ ( ℓ ) P_\tau^{(\ell)} Pτ(ℓ) 更多的信息,我们直观地看到,性能(F1分数)通常随着添加更多层而增加 3 ^3 3。然后我们可以计算一个差分 Δ τ ( ℓ ) \Delta_\tau^{(\ell)} Δτ(ℓ),它衡量了如果我们观察一个额外的 encoder 层 ℓ \ell ℓ,我们在探测任务上做得有多好: Δ τ ( ℓ ) = Score ( P τ ( ℓ ) ) − Score ( P τ ( ℓ − 1 ) ) ( 3 ) \Delta_\tau^{(\ell)} = \text{Score}(P_\tau^{(\ell)}) - \text{Score}(P_\tau^{(\ell-1)})\quad\quad\quad\quad(3) Δτ(ℓ)=Score(Pτ(ℓ))−Score(Pτ(ℓ−1))(3)
Expected Layer. \quad\quad 同样,我们计算一个(伪) 4 ^4 4期望值作为差分分值的概括统计。为了关注上下文 encoder 层的行为,我们省略了在第0层解析的“多余”示例的贡献,以及完整模型的剩余净空(remaining headroom)。让: E ˉ Δ [ ℓ ] = ∑ ℓ = 0 L ℓ ⋅ Δ τ ( ℓ ) ∑ ℓ = 0 L Δ τ ( ℓ ) ( 3 ) \bar{E}_\Delta [\ell] =\frac{ \sum_{\ell = 0}^L \ell \cdot \Delta_\tau^{(\ell)}}{ \sum_{\ell = 0}^L \Delta_\tau^{(\ell)}} \quad\quad\quad\quad(3) EˉΔ[ℓ]=∑ℓ=0LΔτ(ℓ)∑ℓ=0Lℓ⋅Δτ(ℓ)(3)假设示例在 encoder 的某个 ℓ ≥ 1 \ell \geq 1 ℓ≥1层解析,则这可以近似地被认为是探测模型正确标记示例的预期层。
4 Results
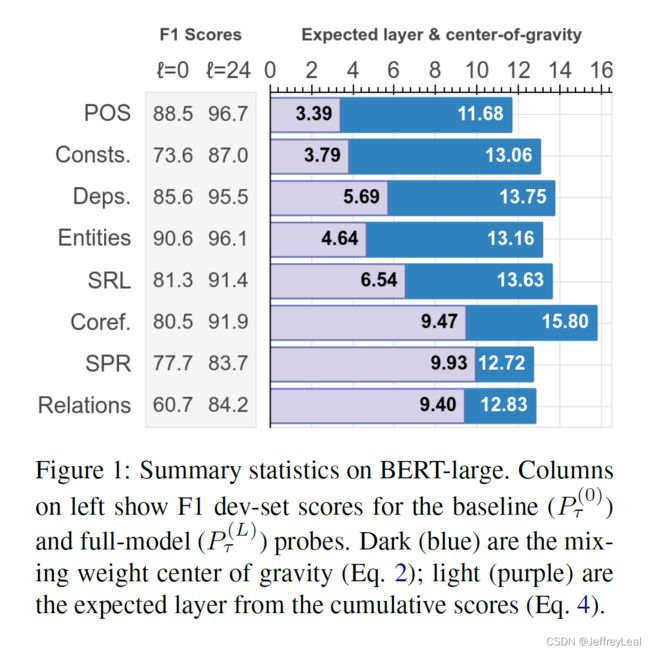
图1报告了概括统计和 F1 绝对分数,图2报告了每层的指标。两者都显示了24层 BERT-large 的结果。我们还报告了 K ( ⋆ ) = K L ( ⋆ ∣ U n i f o r m ) K(\star) = \mathrm{KL(\star | Uniform)} K(⋆)=KL(⋆∣Uniform) 来估计每个任务的每个统计 ( ⋆ = s τ , Δ τ ) (\star = s_\tau,\Delta_\tau) (⋆=sτ,Δτ) 的不均匀性 5 ^5 5。
Linguistic Patterns. \quad\quad 我们在两个指标中观察到一致的趋势,自然的发展地编码的任务:最早处理POS标记,然后是成分、依赖关系、语义角色和共同指代。也就是说,基本的语法信息出现在网络的早期,而高级语义信息出现在更高的层次。我们注意到,这一发现与Peters等人(2018b)的初步观察结果一致,后者发现成分的表示早于共指。
此外,我们观察到,一般来说,句法信息更容易定位,与句法任务相关的权重往往集中在几个层次上(高 K ( s ) K(s) K(s) 和 K ( Δ ) K(\Delta) K(Δ)), 而与语义任务相关的信息通常分布在整个网络中。例如,我们发现,对于语义关系和原型角色(SPR),混合权重几乎是一致的,并且这些任务的不容小觑的样例在几乎所有层上都逐渐得到解决。对于实体标记,许多样例在第1层中得到解决,但随后会出现一条长尾,在高层中只有少量混合权重。需要进一步的研究来确定这是因为 BERT 很难为这些任务表示正确的抽象,还是因为语义信息本身就很难定位。
Comparison of Metrics. \quad\quad 对于许多任务,我们发现在模型的前几层(BERT-large的第1-7层),差分分数最高,即大多数样例可以很早就正确分类。我们将此归因于启发式快捷方式的可用性(availability of heuristic shortcuts):虽然具有挑战性的样例可能要过很长时间才能解决,但许多情况可以从浅层的统计数据中猜测出来。相反,我们观察到,学习到的混合权重集中在后面,第9-20层更大。我们观察到——特别是在权重高度集中的情况下——最高权重出现在,该任务的F1分数中提高 Δ τ ( ℓ ) \Delta_\tau^{(\ell)} Δτ(ℓ) 的多个最高层中或之后。
这有助于解释对语义关系和SPR任务的观察:累积评分显示模型最高层的持续改善,而混合权重中缺乏集中度表明,BERT encoder 没有公开编码这些语义现象的局部特征集。同样,对于实体类型,我们看到更高层次的持续改进——可能与“Organization”(ORG)与“Geopolitical Entity”(GPE)等细粒度语义区别有关——而预期层的低值反映出许多样例只需要有限的上下文即可解决。
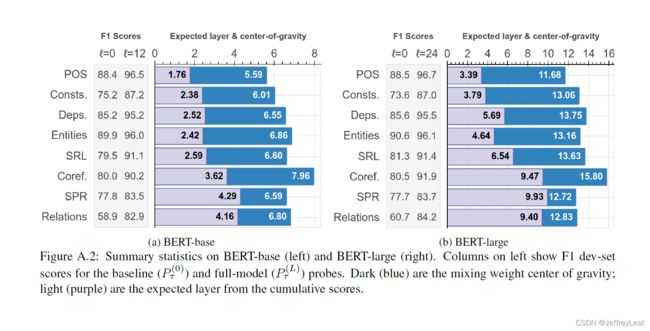
Comparison of Encoders. \quad\quad 我们在12层 BERT-base 模型上观察到相同的一般顺序(图A.2)。特别是,似乎存在“拉伸效应”,其中给定任务的表示往往集中在相对于模型顶部的相同层上;这在图A.3中并排说明。
4.1 Per-Example Analysis
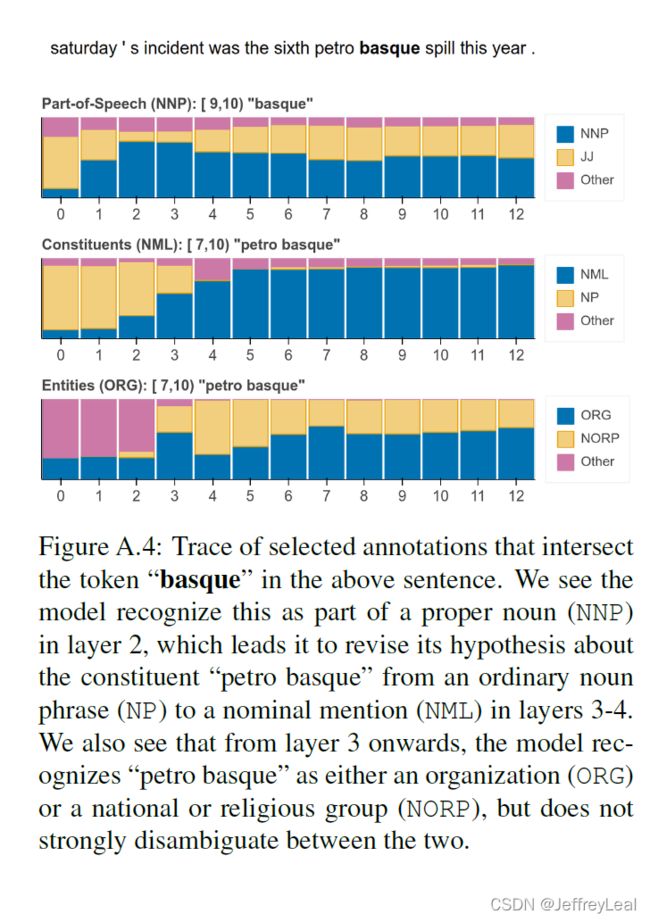
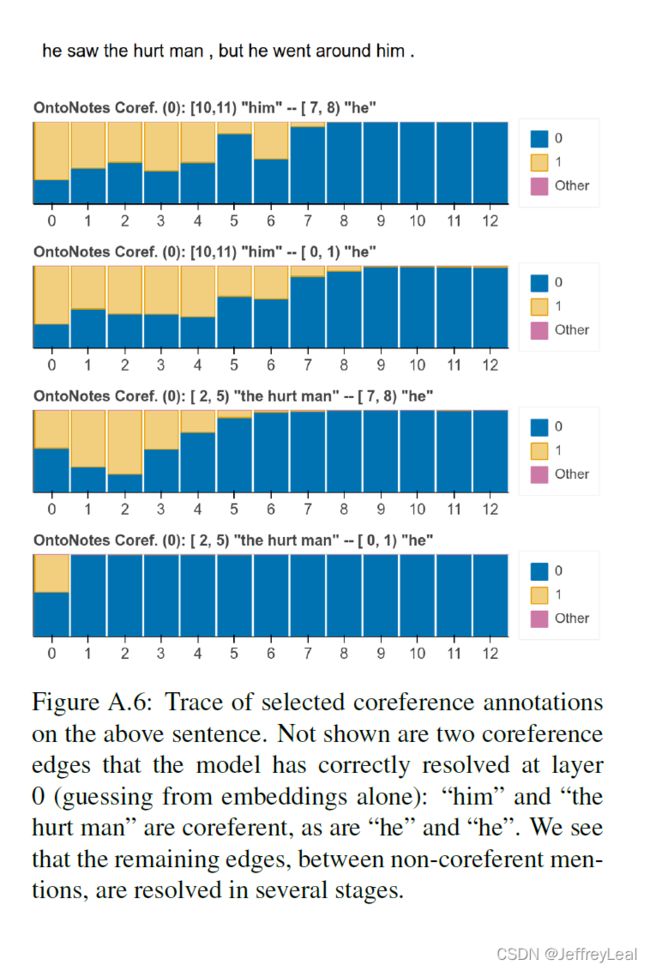
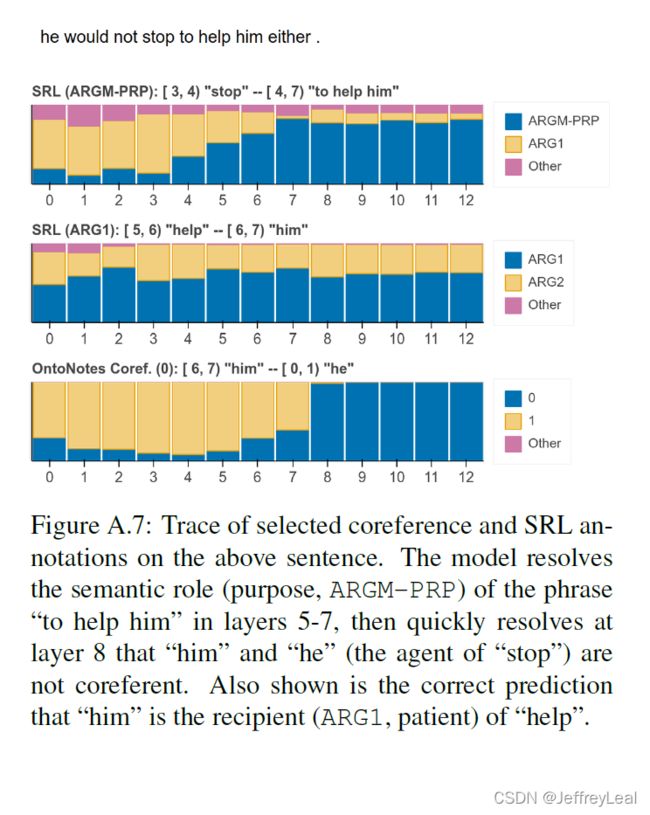
我们从定性上探讨了关于单个句子结构的概念是如何在 BERT 网络的各个层次上发展的。OntoNotes开发集包含五个探测任务的注释:POS、components、entities、SRL和coreference。我们为每个任务编译每层分类器 P τ ( ℓ ) P_\tau^{(\ell)} Pτ(ℓ) 的预测。因为许多注释都是没有价值的——例如,89%的词性标记在第0层是正确的——我们使用启发式方法来识别歧义句子,以便可视化 6 ^6 6。图3显示了两个选定的示例,更多示例见附录A.2。

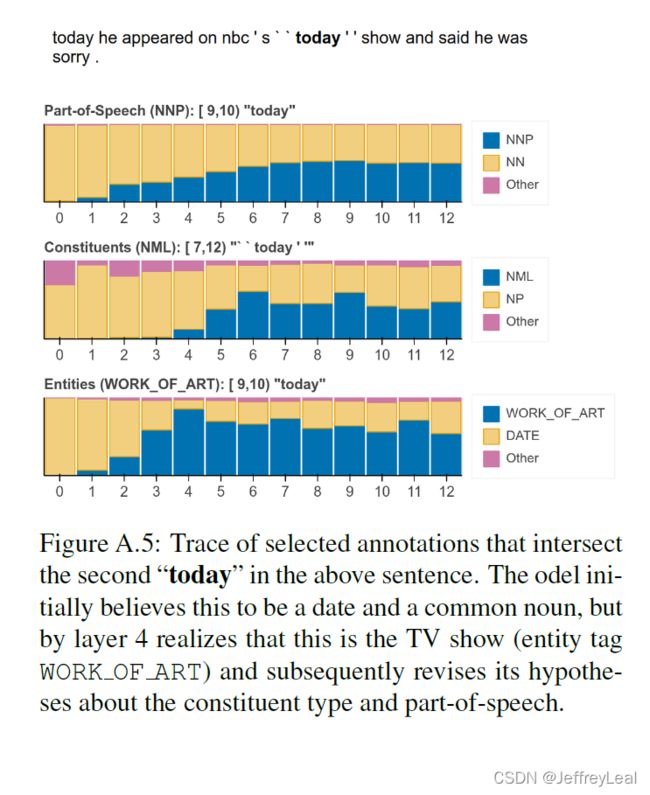
我们发现,虽然 pipeline 顺序的平均保持不变(图2),但对于个别样例,该模型可以自由选择,并且经常选择不同的顺序。在第一个样例中,模型最初(错误地)假设“Toronto”指的是城市,将其标记为 GPE。然而,在解决了语义角色后——确定“Toronto”是变得“smoked”的东西(ARG1)——实体类型决策被修改为有利于 ORG (即运动队)。在第二个样例中,模型最初将“today”标记为普通名词、日期和时间修饰语(ARGM-TMP)。然而,这个短语是模棱两可的,它后来将“今日中国”重新解释为专有名词(即电视网络),并更新了其关于实体类型(到 ORG)的概念,接着是语义角色(将其重新解释为代理ARG0)。
5 Conclusion
我们使用边缘探测任务组来探索 BERT 网络的不同层如何解析句子中的句法和语义结构。我们提出了两个互补的度量:从训练语料中学习的标量混合权重 scalar mixing weights 和在评估集上测量的累积得分 cumulative scoring,并表明出现了相一致的顺序。我们发现,虽然这种传统的 pipeline 顺序在总体上保持不变,但在个别示例中,网络可以解决无序问题,使用高级信息(如谓词-参数关系)帮助消除低级决策(如词性)的歧义。这提供了新的证据,证实深层语言模型可以表示传统上认为语言处理所必需的句法和语义抽象类型,而且它们可以模拟不同层次信息之间的复杂交互。
A Appendix

相关视频
李宏毅-ELMO, BERT, GPT讲解:0:44:41开始