手把手教你使用 Python 做 LDA 主题提取和可视化
前言
信息时代的高速发展让我们得以使用手机、电脑等设备轻松从网络上获取信息。但是,这似乎也是一把双刃剑,我们在获取到众多信息的同时,又可能没有太多时间去一一阅读它们,以至于“收藏从未停止,学习从未开始”的现象屡见不鲜。
这篇文章估计以后也会在收藏夹里面吃灰吧!
为了能够高效地处理巨大的文档信息,我在学习的过程中,接触到了 LDA 主题提取这个方法。经过学习,发现它特别有意思,它的主要功能是
能将众多文档进行主题分类,同时展示出主题词
当我发现这个功能之后,我便开始奇思妙想了,譬如我可以根据它的这个功能实现几个好玩的东西
- 分析写作平台上面的大 v 的文章,对其发表的作品进行主题抽取和可视化,从而找到平台上比较热门的主题或者说比较容易火的主题,从而对自己的写作产生一定的指导意义。
- 人工选出包含垃圾广告类的大量文章,然后训练 LDA 模型,抽取出它的主题,之后使用训练好的 LDA 模型去对自己收藏的大量文章进行主题概率分布预测,从而把包含大量垃圾和广告类的文章去掉,当然也可以抽取出自己最感兴趣的主题。
以上两点是个人根据需求出发,产生的想法,当然这两个想法经过我的初步验证,确实是有一定的实现可能性。
在这篇文章中,我将一步步教你怎么基于 Python,使用 LDA 对文档主题进行抽取和可视化,为了让你有兴趣地读下去,我先附上可视化的效果吧
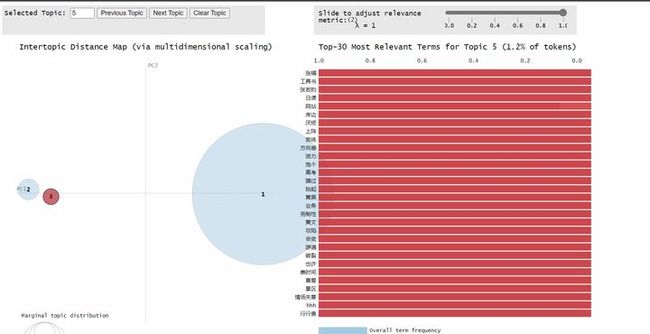
上图是我对知乎的一个百万粉大 V 的 218 个回答做 LDA 主题抽取并可视化的结果,可以看到她回答的主题非常地集中。
如果看了可视化效果之后,你感兴趣,那么就可以开始往下阅读了,当然你很赶时间的话,可以不用去阅读我是怎么一步步实现这个过程的,文末会给你附上完整的,可运行的代码。
开始之前
- Python版本要求
Python 3.7 及以上
2. 需要安装的库
tqdm
requests
retry
jieba
multitasking
pandas
pyLDAvis
bs4
sklearn
numpy
openpyxl
xlrd
库的安装方法是:打开 cmd(命令提示符或者其他终端工具),输入以下代码
pip install tqdm requests multitasking retry bs4 pandas pyLDAvis sklearn numpy jieba xlrd openpyxl输入完毕,按 Enter 键执行代码,等待 successfully 出现即可
预备知识
文本转向量
计算机是无法直接理解我们平常使用的文本的,它只能与数字打交道。为了能顺利让它可以理解我们提供的文本,我们需要对自己的文本进行一系列的转换,例如给文本里面的词进行标号,从而形成数字和词的映射。
LDA 主题抽取是基于统计学来实现的,为此我们可以考虑,给文档的词进行标号,同时统计其所对应的词频,依次构造一个二维的词频矩阵。这么说来其实是不够形象的。不过没关系,我将以下面的一个例子带你理解这一过程具体是什么。
假设有这么几段文本
今天 天气 很好 啊
天气 确实 很好我们可以发现,这两段文本中有一下几个词(不考虑单个字)
今天
天气
确实
很好如果我们分别统计每个词在每一个文档中的词频,那么我们可以将这些数据制成这样子的表格
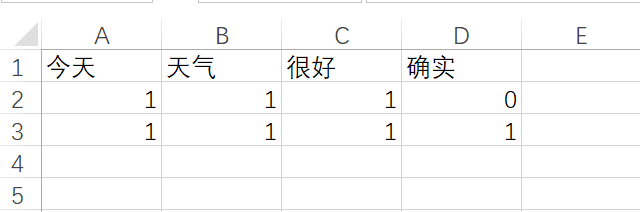
这个怎么解释呢?请看上面的表格的第 2 行,如果用 Python 里面列表来表示,那么它是这样子的
[1,1,1,0]它对应的是
今天 天气 很好 啊这么一句话。当然这样子会不可避免地丢失一些跟序列相关的信息,但在单篇文档内容足够丰富的情况下,丢失这些信息还是 OK 的。
那么我们该怎么构造这么一个表格来数字化地描述每一篇文档呢?
这这里不得不引入 sklearn 给我们提供的好工具,下面上代码给你们展示一下
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
# 多个文档构成的列表
documnets = ['今天 天气 很好 啊','今天 天气 确实 很好']
count_vectorizer = CountVectorizer()
# 构造词频矩阵
cv = count_vectorizer.fit_transform(documnets)
# 获取特征词
feature_names = count_vectorizer.get_feature_names()
# 词频矩阵
matrix = cv.toarray()
df = pd.DataFrame(matrix,columns=feature_names)
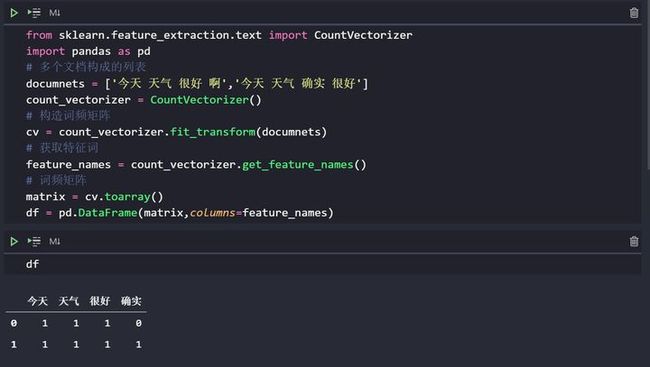
print(df)代码运行输出
今天 天气 很好 确实
0 1 1 1 0
1 1 1 1 1注意,这每一行有 5 个数字,但后面的 4 个才是词频,第一个数字是文档的标号(从 0 开始)
如果你在 jupyter 里面运行,那么它会是这样子的
上面仅仅依靠词频来构造矩阵,这样子显然是不合理的,因为一些常用词的频率肯定很高,但它却无法反映出一个词的重要性。
为此我们引入了 TF-IDF 来构造更能描述词语重要性的词频矩阵,TF-IDF 的具体原理本文就不介绍了。
TF-IDF 构造词频矩阵的 Python 实现代码如下
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
# 多个文档构成的列表
documnets = ['今天 天气 很好 啊','今天 天气 确实 很好']
tf_idf_vectorizer = TfidfVectorizer()
# 构造词频矩阵
tf_idf = tf_idf_vectorizer.fit_transform(documnets)
# 获取特征词
feature_names = tf_idf_vectorizer.get_feature_names()
# 词频矩阵
matrix = tf_idf.toarray()
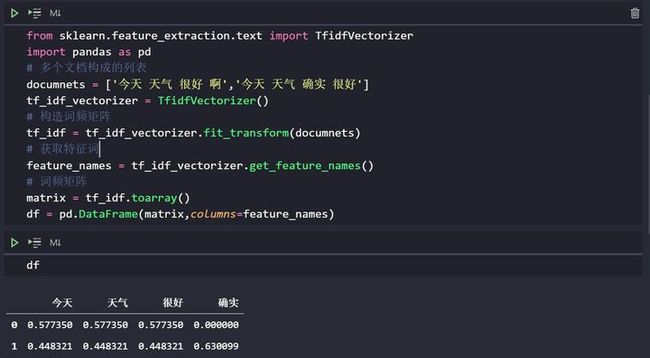
df = pd.DataFrame(matrix,columns=feature_names)代码运行输出
今天 天气 很好 确实
0 0.577350 0.577350 0.577350 0.000000
1 0.448321 0.448321 0.448321 0.630099如果你在 jupyter 里面运行,得到的结果应该是这样子的
文本分词
如果你自己观察我之前贴出的两短文本,你会发现那些文本中的词是之间总有一个空格。
但是对于中文文档而言,你指望它的词之间是用空格来分隔的就几乎不可能。
那么我为什么提供那样子的文本呢? 因为 sklearn 的词频矩阵构造器默认将文档识别为英文模式。如果你学过英语,不难发现单词之间通常是用空格来分开的。
可是我们的原始中文文档是无法做到这样子的。为此我们需要对中文文档事先进行分词,然后用空格把这些词拼接起来,最终形成英文那样子的句子。
说到分词,我们可以考虑比较有名的中文分词工具,比如我们要对下面这么一句话进行分词
今天的天气很不错分词的 Python 示例代码如下
import jieba
# 待分词的句子
sentence = '今天的天气很不错'
# 对句子分词,返回词组成的字符串列表
words = jieba.lcut(sentence)
# 输出词列表
print(words)
# 用空格拼接词并输出
print(" ".join(words))代码运行输出如下
['今天', '的', '天气', '很', '不错']
今天 的 天气 很 不错可以看到,我们很好地实现了中文句子转英文格式句子的功能!
当然,文档里面通常是有较多标点符号的,这些对我们来说意义不是很大,所以我们在进行分词之前,可以先把这些符号统一替换为空格。这一过程我就先不演示了。
后面的代码中会有这一过程的实现(主要原理是利用正则表达式的替换功能)
基于 TF- IDF 的 LDA 主题提取
在做主题抽取之前,我们显然是需要先准备一定量的文档的。上一篇文章中,我写了一个程序来获取知乎答主的回答文本数据,如果你用 excel 打开,会发现它长这样子(csv 文件)
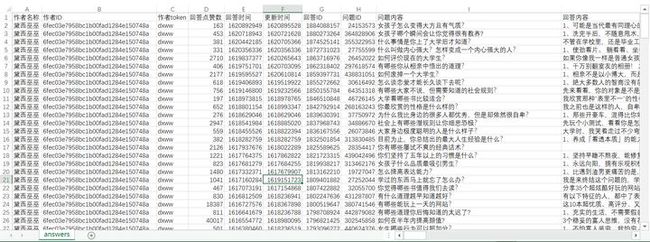
为了让你能更好地获取它,我再次附上它的下载链接,你只需要用电脑浏览器打开它即可开始下载(如果没有自动下载,则可以按电脑快捷键 ctrl s 来进行下载,记得,最好把下载的文件放在代码同级目录!)
纯文本链接
https://raw.staticdn.net/Micro-sheep/Share/main/zhihu/answers.csv可点击链接
https://raw.staticdn.net/Micro-sheep/Share/main/zhihu/answers.csvraw.staticdn.net/Micro-sheep/Share/main/zhihu/answers.csv
因为它是一个 csv 文件,而我们使用的编程语言是 Python,因此我们可以考虑使用 pandas 这个库来操作它 读取它的 Python实例代码如下
import pandas as pd
import os
# 下面的 url 是 csv 文件的远程链接,如果你缺失这个文件,则需要用浏览器打开这个链接
# 下载它,然后放到代码运行命令,且文件名应与下面的 csv_path 一致
url = 'https://raw.githubusercontents.com/Micro-sheep/Share/main/zhihu/answers.csv'
csv_path = 'answers.csv'
if not os.path.exists(csv_path):
print(f'请用浏览器打开 {url} 并下载该文件(如果没有自动下载,则可以在浏览器中按键盘快捷键 ctrl s 来启动下载)')
os.exit()
df = pd.read_csv(csv_path)
print(list(df.columns))运行输出如下
['作者名称', '作者ID', '作者token', '回答点赞数', '回答时间', '更新时间', '回答ID', '问题ID', '问题内容', '回答内容']我输出的是列名。
如果你使用的是 jupyter,那么看到的应该是这样子的(我选查看了上面的两个列)

这个 csv 文件中有很多列,当然我们主要关注的是 回答内容 这一列,它就是我们所选取的文档集合。 对于这一文档,我们将进行下面几个操作
删除空值、重复值、去除无意义标点符号、分词并拼接为英文句子格式。
具体 Python 代码如下
import pandas as pd
import os
import re
import jieba
# 下面的 url 是 csv 文件的远程链接,如果你缺失这个文件,则需要用浏览器打开这个链接
# 下载它,然后放到代码运行命令,且文件名应与下面的 csv_path 一致
url = 'https://raw.githubusercontents.com/Micro-sheep/Share/main/zhihu/answers.csv'
# 本地 csv 文档路径
csv_path = 'answers.csv'
# 待分词的 csv 文件中的列
document_column_name = '回答内容'
pattern = u'[\\s\\d,.<>/?:;\'\"[\\]{}()\\|~!\t"@#$%^&*\\-_=+a-zA-Z,。\n《》、?:;“”‘’{}【】()…¥!—┄-]+'
if not os.path.exists(csv_path):
print(f'请用浏览器打开 {url} 并下载该文件(如果没有自动下载,则可以在浏览器中按键盘快捷键 ctrl s 来启动下载)')
os.exit()
df = pd.read_csv(
csv_path,
encoding='utf-8-sig')
df = df.drop_duplicates()
df = df.dropna()
df = df.rename(columns={
document_column_name: 'text'
})
df['cut'] = df['text'].apply(lambda x: str(x))
df['cut'] = df['cut'].apply(lambda x: re.sub(pattern, ' ', x))
df['cut'] = df['cut'].apply(lambda x: " ".join(jieba.lcut(x)))
print(df['cut'])当然,这么几个操作可能有些长,那么如果你喜欢高逼格的话,我也可以给你提供下面的逼格更高的代码
import pandas as pd
import os
import re
import jieba
# 下面的 url 是 csv 文件的远程链接,如果你缺失这个文件,则需要用浏览器打开这个链接
# 下载它,然后放到代码运行命令,且文件名应与下面的 csv_path 一致
url = 'https://raw.githubusercontents.com/Micro-sheep/Share/main/zhihu/answers.csv'
# 本地 csv 文档路径
csv_path = 'answers.csv'
# 待分词的 csv 文件中的列
document_column_name = '回答内容'
pattern = u'[\\s\\d,.<>/?:;\'\"[\\]{}()\\|~!\t"@#$%^&*\\-_=+a-zA-Z,。\n《》、?:;“”‘’{}【】()…¥!—┄-]+'
if not os.path.exists(csv_path):
print(f'请用浏览器打开 {url} 并下载该文件(如果没有自动下载,则可以在浏览器中按键盘快捷键 ctrl s 来启动下载)')
os.exit()
df = (
pd.read_csv(
csv_path,
encoding='utf-8-sig')
.drop_duplicates()
.dropna()
.rename(columns={
document_column_name: 'text'
}))
# 去重、去缺失、分词
df['cut'] = (
df['text']
.apply(lambda x: str(x))
.apply(lambda x: re.sub(pattern, ' ', x))
.apply(lambda x: " ".join(jieba.lcut(x)))
)
print(df['cut'])运行之后,我们将给原来的表格中添加一列处理好后的文本。
接下来,我们将基于这一处理好后的文档,用前面写的知识来构造 TF-IDF 矩阵。 Python 示例代码如下(关键是最后那几行)
import pandas as pd
import os
import re
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
# 下面的 url 是 csv 文件的远程链接,如果你缺失这个文件,则需要用浏览器打开这个链接
# 下载它,然后放到代码运行命令,且文件名应与下面的 csv_path 一致
url = 'https://raw.githubusercontents.com/Micro-sheep/Share/main/zhihu/answers.csv'
# 本地 csv 文档路径
csv_path = 'answers.csv'
# 待分词的 csv 文件中的列
document_column_name = '回答内容'
pattern = u'[\\s\\d,.<>/?:;\'\"[\\]{}()\\|~!\t"@#$%^&*\\-_=+a-zA-Z,。\n《》、?:;“”‘’{}【】()…¥!—┄-]+'
if not os.path.exists(csv_path):
print(f'请用浏览器打开 {url} 并下载该文件(如果没有自动下载,则可以在浏览器中按键盘快捷键 ctrl s 来启动下载)')
os.exit()
df = (
pd.read_csv(
csv_path,
encoding='utf-8-sig')
.drop_duplicates()
.dropna()
.rename(columns={
document_column_name: 'text'
}))
# 去重、去缺失、分词
df['cut'] = (
df['text']
.apply(lambda x: str(x))
.apply(lambda x: re.sub(pattern, ' ', x))
.apply(lambda x: " ".join(jieba.lcut(x)))
)
# 构造 TF-IDF
tf_idf_vectorizer = TfidfVectorizer()
tf_idf = tf_idf_vectorizer.fit_transform(df['cut'])为了看的更直观,我也将这个矩阵转为表格,示例代码如下
import pandas as pd
import os
import re
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
# 下面的 url 是 csv 文件的远程链接,如果你缺失这个文件,则需要用浏览器打开这个链接
# 下载它,然后放到代码运行命令,且文件名应与下面的 csv_path 一致
url = 'https://raw.githubusercontents.com/Micro-sheep/Share/main/zhihu/answers.csv'
# 本地 csv 文档路径
csv_path = 'answers.csv'
# 待分词的 csv 文件中的列
document_column_name = '回答内容'
pattern = u'[\\s\\d,.<>/?:;\'\"[\\]{}()\\|~!\t"@#$%^&*\\-_=+a-zA-Z,。\n《》、?:;“”‘’{}【】()…¥!—┄-]+'
if not os.path.exists(csv_path):
print(f'请用浏览器打开 {url} 并下载该文件(如果没有自动下载,则可以在浏览器中按键盘快捷键 ctrl s 来启动下载)')
os.exit()
df = (
pd.read_csv(
csv_path,
encoding='utf-8-sig')
.drop_duplicates()
.dropna()
.rename(columns={
document_column_name: 'text'
}))
# 去重、去缺失、分词
df['cut'] = (
df['text']
.apply(lambda x: str(x))
.apply(lambda x: re.sub(pattern, ' ', x))
.apply(lambda x: " ".join(jieba.lcut(x)))
)
# 构造 TF-IDF
tf_idf_vectorizer = TfidfVectorizer()
tf_idf = tf_idf_vectorizer.fit_transform(df['cut'])
# 特征词列表
feature_names = tf_idf_vectorizer.get_feature_names()
# 特征词 TF-IDF 矩阵
matrix = tf_idf.toarray()
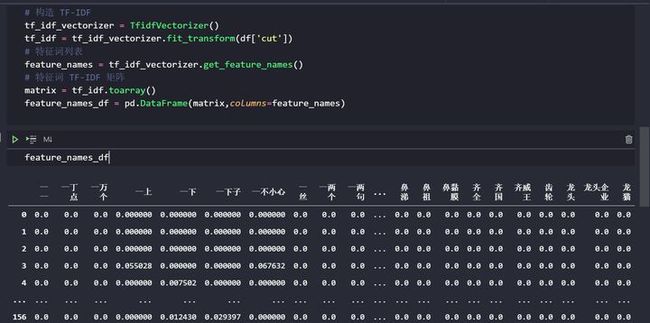
feature_names_df = pd.DataFrame(matrix,columns=feature_names)
print(feature_names_df)
feature_names_df在 Jupyter 里面运行的话,会是这样子的(截取了部分代码)
那么,有了这么一个矩阵之后,我们该怎么把它喂给 LDA 来吃呢?
噢,我们还没有 LDA 呢,所以我们得先把它造出来,当然我们可以直接使用 sklearn 给我们提供好的 LDA 模型,Python 示例代码如下
from sklearn.decomposition import LatentDirichletAllocation
# 指定 lda 主题数
n_topics = 5
lda = LatentDirichletAllocation(
n_components=n_topics, max_iter=50,
learning_method='online',
learning_offset=50.,
random_state=0)
print(lda)输出如下
LatentDirichletAllocation(learning_method='online', learning_offset=50.0,
max_iter=50, n_components=5, random_state=0)嗯,是个看不懂的东西,不过问题不大。
构造它之后,我们得给它喂东西,这样子它才能有产出,给他喂东西的 Python 示例代码如下(核心代码是最后一句)
from sklearn.decomposition import LatentDirichletAllocation
import pandas as pd
import os
import re
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
# 下面的 url 是 csv 文件的远程链接,如果你缺失这个文件,则需要用浏览器打开这个链接
# 下载它,然后放到代码运行命令,且文件名应与下面的 csv_path 一致
url = 'https://raw.githubusercontents.com/Micro-sheep/Share/main/zhihu/answers.csv'
# 本地 csv 文档路径
csv_path = 'answers.csv'
# 待分词的 csv 文件中的列
document_column_name = '回答内容'
pattern = u'[\\s\\d,.<>/?:;\'\"[\\]{}()\\|~!\t"@#$%^&*\\-_=+a-zA-Z,。\n《》、?:;“”‘’{}【】()…¥!—┄-]+'
if not os.path.exists(csv_path):
print(f'请用浏览器打开 {url} 并下载该文件(如果没有自动下载,则可以在浏览器中按键盘快捷键 ctrl s 来启动下载)')
os.exit()
df = (
pd.read_csv(
csv_path,
encoding='utf-8-sig')
.drop_duplicates()
.dropna()
.rename(columns={
document_column_name: 'text'
}))
# 去重、去缺失、分词
df['cut'] = (
df['text']
.apply(lambda x: str(x))
.apply(lambda x: re.sub(pattern, ' ', x))
.apply(lambda x: " ".join(jieba.lcut(x)))
)
# 构造 TF-IDF
tf_idf_vectorizer = TfidfVectorizer()
tf_idf = tf_idf_vectorizer.fit_transform(df['cut'])
# 特征词列表
feature_names = tf_idf_vectorizer.get_feature_names()
# 特征词 TF-IDF 矩阵
matrix = tf_idf.toarray()
# 指定 lda 主题数
n_topics = 5
lda = LatentDirichletAllocation(
n_components=n_topics, max_iter=50,
learning_method='online',
learning_offset=50.,
random_state=0)
# 核心,给 LDA 喂生成的 TF-IDF 矩阵
lda.fit(tf_idf)那么,这样子之后我们可以得到什么产出呢?
当然,产出是多种的,我们只关注下面两个产出
每一个主题的前n个主题词是什么 每一个文档属于每一个主题的概率是多大
为了更好描述这两个产出,我将定义两个函数来对其进行处理,使其变成 pandas 的 DataFrame,以便后续处理。
Python 示例代码如下
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import LatentDirichletAllocation
import pandas as pd
def top_words_data_frame(model: LatentDirichletAllocation,
tf_idf_vectorizer: TfidfVectorizer,
n_top_words: int) -> pd.DataFrame:
'''
求出每个主题的前 n_top_words 个词
Parameters
----------
model : sklearn 的 LatentDirichletAllocation
tf_idf_vectorizer : sklearn 的 TfidfVectorizer
n_top_words :前 n_top_words 个主题词
Return
------
DataFrame: 包含主题词分布情况
'''
rows = []
feature_names = tf_idf_vectorizer.get_feature_names()
for topic in model.components_:
top_words = [feature_names[i]
for i in topic.argsort()[:-n_top_words - 1:-1]]
rows.append(top_words)
columns = [f'topic {i+1}' for i in range(n_top_words)]
df = pd.DataFrame(rows, columns=columns)
return df
def predict_to_data_frame(model: LatentDirichletAllocation, X: np.ndarray) -> pd.DataFrame:
'''
求出文档主题概率分布情况
Parameters
----------
model : sklearn 的 LatentDirichletAllocation
X : 词向量矩阵
Return
------
DataFrame: 包含主题词分布情况
'''
# 求出给定文档的主题概率分布矩阵
matrix = model.transform(X)
columns = [f'P(topic {i+1})' for i in range(len(model.components_))]
df = pd.DataFrame(matrix, columns=columns)
return df当然,直接看以上的代码你是很难知道它在干什么的。为了让你能更好地理解这是在干嘛,我给你附上 sklearn 的官方文档链接吧 https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.LatentDirichletAllocation.html 如果看不懂英文,可以用浏览器翻译一下
同时这也有截图

有了上面的解释,你或许更容易理解函数为什么那样子写了。当然你还是不理解也没关系、理解它确实需要一定的Python 知识积累,跳过这一部分,仍然不会阻碍你使用 LDA 进行主题抽取的目标。
下面我将综合以上步骤,向你展示使用 LDA 进行主题抽取,并生成 文档主题概率分布以及主题词分布 csv 文件的 Python代码。
针对指定文件的 LDA 主题提取的完整代码(无可视化)
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import LatentDirichletAllocation
import pandas as pd
import jieba
import re
import os
# 本地 csv 文件,可以是本地文件,也可以是远程文件
source_csv_path = 'answers.csv'
# 文本 csv 文件里面文本所处的列名,注意这里一定要填对,要不然会报错的!
document_column_name = '回答内容'
# 输出主题词的文件路径
top_words_csv_path = 'top-topic-words.csv'
# 输出各文档所属主题的文件路径
predict_topic_csv_path = 'document-distribution.csv'
# 可视化 html 文件路径
html_path = 'document-lda-visualization.html'
# 选定的主题数
n_topics = 5
# 要输出的每个主题的前 n_top_words 个主题词数
n_top_words = 20
# 去除无意义字符的正则表达式
pattern = u'[\\s\\d,.<>/?:;\'\"[\\]{}()\\|~!\t"@#$%^&*\\-_=+a-zA-Z,。\n《》、?:;“”‘’{}【】()…¥!—┄-]+'
url = 'https://raw.githubusercontents.com/Micro-sheep/Share/main/zhihu/answers.csv'
# 待分词的 csv 文件中的列
document_column_name = '回答内容'
pattern = u'[\\s\\d,.<>/?:;\'\"[\\]{}()\\|~!\t"@#$%^&*\\-_=+a-zA-Z,。\n《》、?:;“”‘’{}【】()…¥!—┄-]+'
def top_words_data_frame(model: LatentDirichletAllocation,
tf_idf_vectorizer: TfidfVectorizer,
n_top_words: int) -> pd.DataFrame:
'''
求出每个主题的前 n_top_words 个词
Parameters
----------
model : sklearn 的 LatentDirichletAllocation
tf_idf_vectorizer : sklearn 的 TfidfVectorizer
n_top_words :前 n_top_words 个主题词
Return
------
DataFrame: 包含主题词分布情况
'''
rows = []
feature_names = tf_idf_vectorizer.get_feature_names()
for topic in model.components_:
top_words = [feature_names[i]
for i in topic.argsort()[:-n_top_words - 1:-1]]
rows.append(top_words)
columns = [f'topic {i+1}' for i in range(n_top_words)]
df = pd.DataFrame(rows, columns=columns)
return df
def predict_to_data_frame(model: LatentDirichletAllocation, X: np.ndarray) -> pd.DataFrame:
'''
求出文档主题概率分布情况
Parameters
----------
model : sklearn 的 LatentDirichletAllocation
X : 词向量矩阵
Return
------
DataFrame: 包含主题词分布情况
'''
matrix = model.transform(X)
columns = [f'P(topic {i+1})' for i in range(len(model.components_))]
df = pd.DataFrame(matrix, columns=columns)
return df
if not os.path.exists(source_csv_path):
print(f'请用浏览器打开 {url} 并下载该文件(如果没有自动下载,则可以在浏览器中按键盘快捷键 ctrl s 来启动下载)')
os.exit()
df = (
pd.read_csv(
source_csv_path,
encoding='utf-8-sig')
.drop_duplicates()
.dropna()
.rename(columns={
document_column_name: 'text'
}))
# 去重、去缺失、分词
df['cut'] = (
df['text']
.apply(lambda x: str(x))
.apply(lambda x: re.sub(pattern, ' ', x))
.apply(lambda x: " ".join(jieba.lcut(x)))
)
# 构造 tf-idf
tf_idf_vectorizer = TfidfVectorizer()
tf_idf = tf_idf_vectorizer.fit_transform(df['cut'])
lda = LatentDirichletAllocation(
n_components=n_topics,
max_iter=50,
learning_method='online',
learning_offset=50,
random_state=0)
# 使用 tf_idf 语料训练 lda 模型
lda.fit(tf_idf)
# 计算 n_top_words 个主题词
top_words_df = top_words_data_frame(lda, tf_idf_vectorizer, n_top_words)
# 保存 n_top_words 个主题词到 csv 文件中
top_words_df.to_csv(top_words_csv_path, encoding='utf-8-sig', index=None)
# 转 tf_idf 为数组,以便后面使用它来对文本主题概率分布进行计算
X = tf_idf.toarray()
# 计算完毕主题概率分布情况
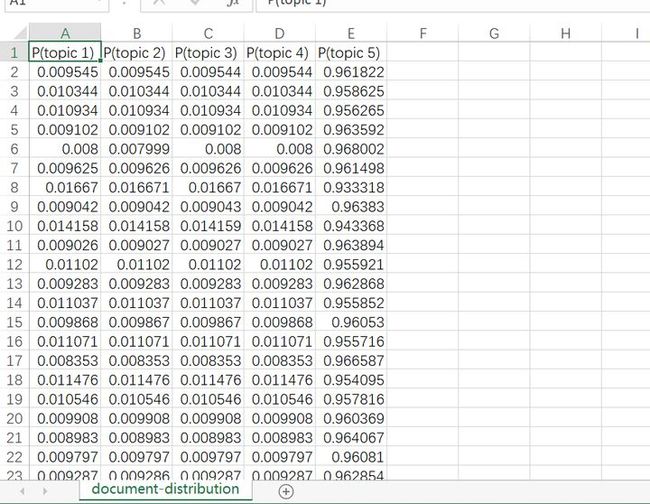
predict_df = predict_to_data_frame(lda, X)
# 保存文本主题概率分布到 csv 文件中
predict_df.to_csv(predict_topic_csv_path, encoding='utf-8-sig', index=None)运行上面的代码,你将会得到两个新的 csv 文件,它们大概是这样子的

以上即完成 LDA 对中文文档进行主题抽取
最开始的时候我们说到,本文的目标是要做 LDA 主题抽取以及可视化,昨天抽取我们已经成功地实现了,下面我们将使用 pyLDAvis 这个库来对我们抽取的主题进行动态可视化(跟前面的那张 gif 展示的那种动态效果一样)
具体实现代码有几行,我就不详细讲怎么写了,自己也是看文档来操作的,下面是最终的代码及注释,包含主题抽取和可视化
针对指定文件的 LDA 主题提取和可视化的完整代码
import pyLDAvis.sklearn
import pyLDAvis
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import LatentDirichletAllocation
import pandas as pd
import jieba
import re
import os
# 本地 csv 文件,可以是本地文件,也可以是远程文件
source_csv_path = 'answers.csv'
# 文本 csv 文件里面文本所处的列名,注意这里一定要填对,要不然会报错的!
document_column_name = '回答内容'
# 输出主题词的文件路径
top_words_csv_path = 'top-topic-words.csv'
# 输出各文档所属主题的文件路径
predict_topic_csv_path = 'document-distribution.csv'
# 可视化 html 文件路径
html_path = 'document-lda-visualization.html'
# 选定的主题数
n_topics = 5
# 要输出的每个主题的前 n_top_words 个主题词数
n_top_words = 20
# 去除无意义字符的正则表达式
pattern = u'[\\s\\d,.<>/?:;\'\"[\\]{}()\\|~!\t"@#$%^&*\\-_=+a-zA-Z,。\n《》、?:;“”‘’{}【】()…¥!—┄-]+'
url = 'https://raw.githubusercontents.com/Micro-sheep/Share/main/zhihu/answers.csv'
# 待分词的 csv 文件中的列
document_column_name = '回答内容'
pattern = u'[\\s\\d,.<>/?:;\'\"[\\]{}()\\|~!\t"@#$%^&*\\-_=+a-zA-Z,。\n《》、?:;“”‘’{}【】()…¥!—┄-]+'
def top_words_data_frame(model: LatentDirichletAllocation,
tf_idf_vectorizer: TfidfVectorizer,
n_top_words: int) -> pd.DataFrame:
'''
求出每个主题的前 n_top_words 个词
Parameters
----------
model : sklearn 的 LatentDirichletAllocation
tf_idf_vectorizer : sklearn 的 TfidfVectorizer
n_top_words :前 n_top_words 个主题词
Return
------
DataFrame: 包含主题词分布情况
'''
rows = []
feature_names = tf_idf_vectorizer.get_feature_names()
for topic in model.components_:
top_words = [feature_names[i]
for i in topic.argsort()[:-n_top_words - 1:-1]]
rows.append(top_words)
columns = [f'topic {i+1}' for i in range(n_top_words)]
df = pd.DataFrame(rows, columns=columns)
return df
def predict_to_data_frame(model: LatentDirichletAllocation, X: np.ndarray) -> pd.DataFrame:
'''
求出文档主题概率分布情况
Parameters
----------
model : sklearn 的 LatentDirichletAllocation
X : 词向量矩阵
Return
------
DataFrame: 包含主题词分布情况
'''
matrix = model.transform(X)
columns = [f'P(topic word {i+1})' for i in range(len(model.components_))]
df = pd.DataFrame(matrix, columns=columns)
return df
if not os.path.exists(source_csv_path):
print(f'请用浏览器打开 {url} 并下载该文件(如果没有自动下载,则可以在浏览器中按键盘快捷键 ctrl s 来启动下载)')
os.exit()
df = (
pd.read_csv(
source_csv_path,
encoding='utf-8-sig')
.drop_duplicates()
.dropna()
.rename(columns={
document_column_name: 'text'
}))
# 去重、去缺失、分词
df['cut'] = (
df['text']
.apply(lambda x: str(x))
.apply(lambda x: re.sub(pattern, ' ', x))
.apply(lambda x: " ".join(jieba.lcut(x)))
)
# 构造 tf-idf
tf_idf_vectorizer = TfidfVectorizer()
tf_idf = tf_idf_vectorizer.fit_transform(df['cut'])
lda = LatentDirichletAllocation(
n_components=n_topics,
max_iter=50,
learning_method='online',
learning_offset=50,
random_state=0)
# 使用 tf_idf 语料训练 lda 模型
lda.fit(tf_idf)
# 计算 n_top_words 个主题词
top_words_df = top_words_data_frame(lda, tf_idf_vectorizer, n_top_words)
# 保存 n_top_words 个主题词到 csv 文件中
top_words_df.to_csv(top_words_csv_path, encoding='utf-8-sig', index=None)
# 转 tf_idf 为数组,以便后面使用它来对文本主题概率分布进行计算
X = tf_idf.toarray()
# 计算完毕主题概率分布情况
predict_df = predict_to_data_frame(lda, X)
# 保存文本主题概率分布到 csv 文件中
predict_df.to_csv(predict_topic_csv_path, encoding='utf-8-sig', index=None)
# 使用 pyLDAvis 进行可视化
data = pyLDAvis.sklearn.prepare(lda, tf_idf, tf_idf_vectorizer)
pyLDAvis.save_html(data, html_path)
# 清屏
os.system('clear')
# 浏览器打开 html 文件以查看可视化结果
os.system(f'start {html_path}')
print('本次生成了文件:',
top_words_csv_path,
predict_topic_csv_path,
html_path)当然,如果你没有下载我前面说的那个 csv 文件,上面的代码会提前结束,你最好是翻到前面下载我说的 csv 文件。
运行以上代码之后,会生成 2 个 csv 文件以及 1 个 html 文件,其中 html 会默认用浏览器自动打开,如果没有自动打开,则你需要自己用浏览器打开它以查看可视化效果!
下面是本文的终极代码,也是全文中最通用的代码
通用的 LDA 主题提取和可视化完整代码
import pyLDAvis.sklearn
import pyLDAvis
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import LatentDirichletAllocation
import pandas as pd
import jieba
import re
import os
# 待做 LDA 的文本 csv 文件,可以是本地文件,也可以是远程文件,一定要保证它是存在的!!!!
source_csv_path = 'answers.csv'
# 文本 csv 文件里面文本所处的列名,注意这里一定要填对,要不然会报错的!!!
document_column_name = '回答内容'
# 输出主题词的文件路径
top_words_csv_path = 'top-topic-words.csv'
# 输出各文档所属主题的文件路径
predict_topic_csv_path = 'document-distribution.csv'
# 可视化 html 文件路径
html_path = 'document-lda-visualization.html'
# 选定的主题数
n_topics = 5
# 要输出的每个主题的前 n_top_words 个主题词数
n_top_words = 20
# 去除无意义字符的正则表达式
pattern = u'[\\s\\d,.<>/?:;\'\"[\\]{}()\\|~!\t"@#$%^&*\\-_=+a-zA-Z,。\n《》、?:;“”‘’{}【】()…¥!—┄-]+'
def top_words_data_frame(model: LatentDirichletAllocation,
tf_idf_vectorizer: TfidfVectorizer,
n_top_words: int) -> pd.DataFrame:
'''
求出每个主题的前 n_top_words 个词
Parameters
----------
model : sklearn 的 LatentDirichletAllocation
tf_idf_vectorizer : sklearn 的 TfidfVectorizer
n_top_words :前 n_top_words 个主题词
Return
------
DataFrame: 包含主题词分布情况
'''
rows = []
feature_names = tf_idf_vectorizer.get_feature_names()
for topic in model.components_:
top_words = [feature_names[i]
for i in topic.argsort()[:-n_top_words - 1:-1]]
rows.append(top_words)
columns = [f'topic word {i+1}' for i in range(n_top_words)]
df = pd.DataFrame(rows, columns=columns)
return df
def predict_to_data_frame(model: LatentDirichletAllocation, X: np.ndarray) -> pd.DataFrame:
'''
求出文档主题概率分布情况
Parameters
----------
model : sklearn 的 LatentDirichletAllocation
X : 词向量矩阵
Return
------
DataFrame: 包含主题词分布情况
'''
matrix = model.transform(X)
columns = [f'P(topic {i+1})' for i in range(len(model.components_))]
df = pd.DataFrame(matrix, columns=columns)
return df
df = (
pd.read_csv(
source_csv_path,
encoding='utf-8-sig')
.drop_duplicates()
.dropna()
.rename(columns={
document_column_name: 'text'
}))
# 设置停用词集合
stop_words_set = set(['你', '我'])
# 去重、去缺失、分词
df['cut'] = (
df['text']
.apply(lambda x: str(x))
.apply(lambda x: re.sub(pattern, ' ', x))
.apply(lambda x: " ".join([word for word in jieba.lcut(x) if word not in stop_words_set]))
)
# 构造 tf-idf
tf_idf_vectorizer = TfidfVectorizer()
tf_idf = tf_idf_vectorizer.fit_transform(df['cut'])
lda = LatentDirichletAllocation(
n_components=n_topics,
max_iter=50,
learning_method='online',
learning_offset=50,
random_state=0)
# 使用 tf_idf 语料训练 lda 模型
lda.fit(tf_idf)
# 计算 n_top_words 个主题词
top_words_df = top_words_data_frame(lda, tf_idf_vectorizer, n_top_words)
# 保存 n_top_words 个主题词到 csv 文件中
top_words_df.to_csv(top_words_csv_path, encoding='utf-8-sig', index=None)
# 转 tf_idf 为数组,以便后面使用它来对文本主题概率分布进行计算
X = tf_idf.toarray()
# 计算完毕主题概率分布情况
predict_df = predict_to_data_frame(lda, X)
# 保存文本主题概率分布到 csv 文件中
predict_df.to_csv(predict_topic_csv_path, encoding='utf-8-sig', index=None)
# 使用 pyLDAvis 进行可视化
data = pyLDAvis.sklearn.prepare(lda, tf_idf, tf_idf_vectorizer)
pyLDAvis.save_html(data, html_path)
# 清屏
os.system('clear')
# 浏览器打开 html 文件以查看可视化结果
os.system(f'start {html_path}')
print('本次生成了文件:',
top_words_csv_path,
predict_topic_csv_path,
html_path)
如果你要使用其他文件来进行 LDA 主题抽取和可视化,你需要关注上面代码的这一块
# 文本 csv 文件,可以是本地文件,也可以是远程文件
source_csv_path = 'answers.csv'
# 文本 csv 文件里面文本所处的列名,注意这里一定要填对,要不然会报错的!
document_column_name = '回答内容'
# 输出主题词的文件路径
top_words_csv_path = 'top-topic-words.csv'
# 输出各文档所属主题的文件路径
predict_topic_csv_path = 'document-distribution.csv'
# 可视化 html 文件路径
html_path = 'document-lda-visualization.html'
# 选定的主题数
n_topics = 5
# 要输出的每个主题的前 n_top_words 个主题词数
n_top_words = 20按注释修改即可!
如果你使用的文件不是 .csv 文件,而是 .xlsx 或者 .xls 文件,则把代码里面的
df = (
pd.read_csv(
source_csv_path,
encoding='utf-8-sig')
.drop_duplicates()
.dropna()
.rename(columns={
document_column_name: 'text'
}))改为
df = (
pd.read_excel(
".xlsx 或者 .xlsx 文件路径")
.drop_duplicates()
.dropna()
.rename(columns={
document_column_name: 'text'
}))例如 (Windows 系统)
df = (
pd.read_excel(
"C:/Users/me/data/data.xlsx")
.drop_duplicates()
.dropna()
.rename(columns={
document_column_name: 'text'
}))例如 (Linux 系统)
df = (
pd.read_excel(
"/home/me/data/data.xlsx")
.drop_duplicates()
.dropna()
.rename(columns={
document_column_name: 'text'
}))同时要记得使用 pip 来安装 xlrd 和 openpyxl。
写在最后
本文详细地向你展示了怎么一步步做 LDA 主题抽取以及可视化,如果你仔细阅读,那收获是会比较大的。最后祝大家天天进步!!如果大家在刚开始学习中遇到困难,想找一个python学习交流环境,可以加入我们,领取学习资料,一起讨论