Slurm超算集群跑深度学习代码教程
参考教程
http://docs.hpc.whu.edu.cn/
- 登录武汉大学信息门户,在办事大厅的搜索栏进行搜索,然后按照指示进行VPN和超算中心的账号申请。超算中心的用户名和密码在武汉大学超算中心申请成功后,会发到指定邮箱。
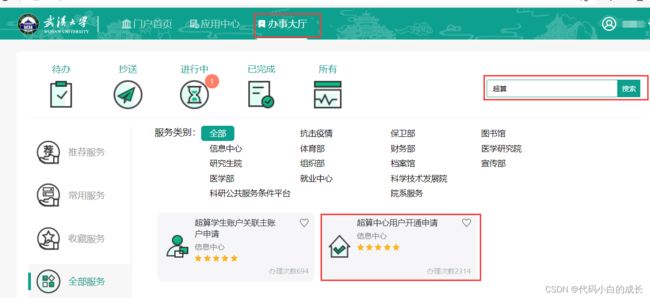
- 超算学生账户关联主账户申请
如果是校外操作,则需要通过easyconnect登陆集群专属VPN
https://.whu.edu.cn/
1.连接超算
使用支持 SSH 协议的客户端软件MobaXterm来登录超算
https://mobaxterm.mobatek.net/
使用 SSH 客户端连接超算的登录节点 swarm.whu.edu.cn(202.114.96.180)

用户存储与数据传输

/bin/myDiskQuota

文件传输(SFTP 协议)
服务器IP地址: 202.114.96.180 or 202.114.96.177
anaconda安装
https://repo.anaconda.com/archive/
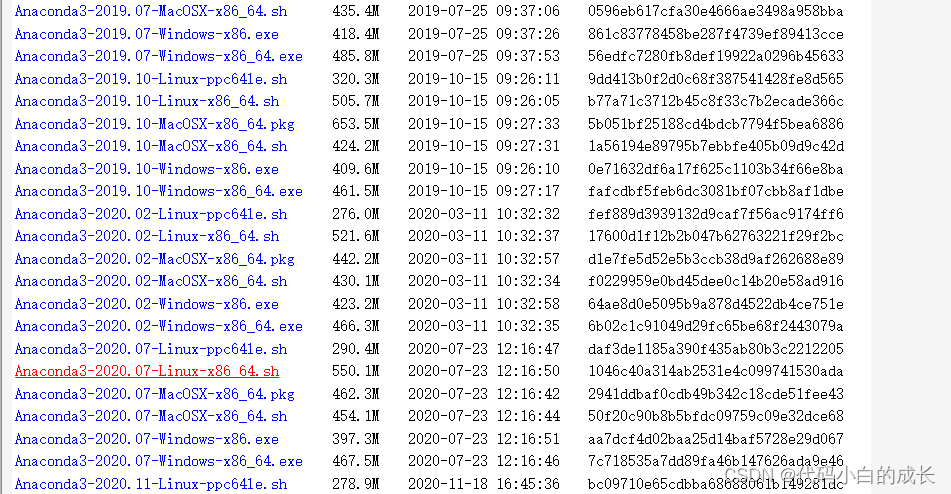
- 通过
wget从官网下载相关版本到根目录下
wget https://repo.anaconda.com/archive/Anaconda3-2020.07-Linux-x86_64.sh
- 执行命令:
bash Anaconda3-2020.07-Linux-x86_64.sh安装
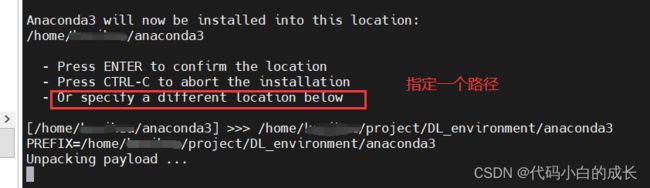
注意:这里指定新的路劲,是由于默认的路径存储空间不够导致安装失败
-
选择
yes添加环境变量

-
修改 ~/.bashrc文件
- 打开bashrc文件:
vim ~/.bashrc - 输入
i进入插入状态,可在最后加入:export PATH='anaconda的安装目录/bin:$PATH' - “
ESC”退出编辑模式, 输入:wq保存退出; - 执行命令:
source ~/.bashrc让修改生效
输入命令行source /home/xxx/.bashrc,xxx为用户账号名称。这样就完成了anaconda3的配置。
- 输入conda -V验证是否安装成功

创建虚拟环境
通过conda create -n 环境名字 python=3.7创建一个虚拟环境
conda activate 环境名字
conda deactivate 环境名字
pip install torch==1.6.0+cu101 torchvision==0.7.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html
Slurm系统下的作业调度管理
https://blog.csdn.net/lovebaby1689/article/details/123208698
作业脚本基本结构

作业脚本

–account
付费账号关联,用户使用收费分区时,需要关联付费账号,在作业脚本里加入
#SBATCH --account=supervisor
请将 supervisor 替换为导师的账号名
–partition
超算上不同类型的计算资源,以分区的形式组织
- 免费用户使用的 CPU 集群,分区命名 hpxg
- 付费用户使用的 CPU 集群,分区命名 hpib
- Intel Knight Landing 7250 集群,分区命名 knl
- Nvidia Tesla V100 集群,分区命名 gpu
指定使用哪个分区,在作业脚本里加入
#SBATCH --partition=gpu
–nodes
申请计算节点的数量,在作业脚本里加入
#SBATCH --nodes=X
其中 X 是数量,需要的计算节点的个数
–ntasks-per-node
控制每个计算节点上运行 task 的数量,一般与 --nodes 配合使用,例如
MPI 程序需要 3 个计算节点,每节点 4 个进程,一共 12 个 task,对应 12 个 cpu 核
#SBATCH --nodes=3
#SBATCH --ntasks-per-node=4
还可以与 --cpus-per-task 选项配合使用,例如
MPI 程序需要 1个计算节点,每节点 2 个进程,每个进程使用 OpenMP 运行 8 个线程,一共16 个 cpu 核
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=2
#SBATCH --cpus-per-task=8
–cpus-per-task
单个 task 需要的 cpu 核数。一个 task 进程可以多线程,需要使用多个 cpu 核。此选项 Slurm 系统会保证一个 task 进程所在的计算节点上有指定数量的 cpu 核可用。
例如,每个计算节点有 4 个 cpu 核,一个计算作业需要 24 个 cpu 核
- 直接声明 24 个 task,Slurm 系统将分配 6 个计算节点
- 指定 --cpus-per-task=3,Slurm 系统将分配 8个计算节点,确保一个 task 需要的 3 个 cpu 核是在同一个节点上
如果不设置此选项,Slurm 系统默认值是 1,即默认一个 task 分配一个 cpu 核
–gres
申请每计算节点上 GPU 资源的数量,在作业脚本里加入
#SBATCH --gres=gpu:X
其中 X 是数量,目前 gpu 分区每计算节点有 4 张 Nvidia Tesla V100,因此 X 不超过 4
提交作业
将脚本跟 mycode.py 放在同一个目录下,然后运行以下命令提交作业
sbatch myjob.sh
sbatch 命令把作业脚本提交给 Slurm 系统,获得一个 JobID 作业编号,并显示给用户
作业编号 JobID 是一个正整数数字。
Slurm 系统将根据作业脚本选项所列出的计算资源申请需求,结合当前可用的资源现状,给计算任务排队、分配资源、启动计算程序、输出各种中间过程信息、计算结束后回收计算资源。
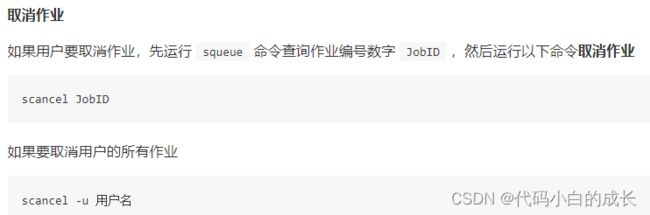
作业管理
squeue命令查看作业状态信息
![]()

如何查看导师(付费)账号下资源及使用情况`
在登录节点执行命令 accountInfos + 导师(付费)账号
导师(付费)账号为xinming的查询方法
accountInfos xinming
作业脚本选项
日志 log 输出控制
作业脚本的标准输出和标准错误默认保存到同一个日志文件,名为
slurm-%j.out #
%j是作业编号
要改变标准输出,在作业脚本里加入
#SBATCH --output=filename.out