公众号:尤而小屋
作者:Peter
编辑:Peter
从26个字母中精选出23个Pandas常用的函数,将它们的使用方法介绍给大家。其中o、y、z没有相应的函数。

import pandas as pd
import numpy as np
下面介绍每个函数的使用方法,更多详细的内容请移步官网:https://pandas.pydata.org/docs/reference/general_functions.html
assign函数
df = pd.DataFrame({
'temp_c': [17.0, 25.0]},
index=['Portland', 'Berkeley'])
df
|
temp_c |
| Portland |
17.0 |
| Berkeley |
25.0 |
# 生成新的字段
df.assign(temp_f=df['temp_c'] * 9 / 5 + 32)
|
temp_c |
temp_f |
| Portland |
17.0 |
62.6 |
| Berkeley |
25.0 |
77.0 |
df # 原来DataFrame是不改变的
|
temp_c |
| Portland |
17.0 |
| Berkeley |
25.0 |
如果是通过下面的方式来生成新的字段,那么原来的数据则会改变:
df["temp_f1"] = df["temp_c"] * 9 / 5 + 32
df
|
temp_c |
temp_f1 |
| Portland |
17.0 |
62.6 |
| Berkeley |
25.0 |
77.0 |
df
|
temp_c |
temp_f1 |
| Portland |
17.0 |
62.6 |
| Berkeley |
25.0 |
77.0 |
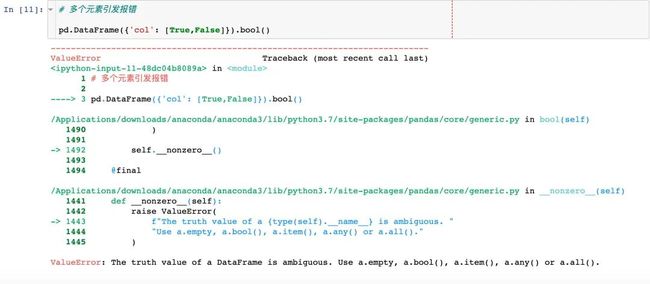
bool函数
返回单个Series或者DataFrame中单个元素的bool值:True或者False
pd.Series([True]).bool()
True
pd.Series([False]).bool()
False
pd.DataFrame({'col': [True]}).bool()
True
pd.DataFrame({'col': [False]}).bool()
False
# # 多个元素引发报错
# pd.DataFrame({'col': [True,False]}).bool()
concat函数
该函数是用来表示多个DataFrame的拼接,横向或者纵向皆可。
df1 = pd.DataFrame({
"sid":["s1","s2"],
"name":["xiaoming","Mike"]})
df1
|
sid |
name |
| 0 |
s1 |
xiaoming |
| 1 |
s2 |
Mike |
df2 = pd.DataFrame({
"sid":["s3","s4"],
"name":["Tom","Peter"]})
df2
|
sid |
name |
| 0 |
s3 |
Tom |
| 1 |
s4 |
Peter |
df3 = pd.DataFrame({
"address":["北京","深圳"],
"sex":["Male","Female"]})
df3
|
address |
sex |
| 0 |
北京 |
Male |
| 1 |
深圳 |
Female |
# 使用1:纵向
pd.concat([df1,df2])
|
sid |
name |
| 0 |
s1 |
xiaoming |
| 1 |
s2 |
Mike |
| 0 |
s3 |
Tom |
| 1 |
s4 |
Peter |
# 使用2:横向
pd.concat([df1,df3],axis=1)
|
sid |
name |
address |
sex |
| 0 |
s1 |
xiaoming |
北京 |
Male |
| 1 |
s2 |
Mike |
深圳 |
Female |
dropna函数
删除空值:可以对整个DataFrame删除,也可以指定某个属性来删除
df4 = pd.DataFrame({
"sid":["s1","s2", np.nan],
"name":["xiaoming",np.nan, "Mike"]})
df4
|
sid |
name |
| 0 |
s1 |
xiaoming |
| 1 |
s2 |
NaN |
| 2 |
NaN |
Mike |
df4.dropna()
df4.dropna(subset=["name"])
|
sid |
name |
| 0 |
s1 |
xiaoming |
| 2 |
NaN |
Mike |
explode函数
爆炸函数的使用:将宽表转成长表。爆炸之后原数据是没有改变的
df5 = pd.DataFrame({
"sid":["s1","s2"],
"phones":[["华为","小米","一加"],["三星","苹果"]]
})
df5
|
sid |
phones |
| 0 |
s1 |
[华为, 小米, 一加] |
| 1 |
s2 |
[三星, 苹果] |
df5.explode("phones")
|
sid |
phones |
| 0 |
s1 |
华为 |
| 0 |
s1 |
小米 |
| 0 |
s1 |
一加 |
| 1 |
s2 |
三星 |
| 1 |
s2 |
苹果 |
df5 # 原数据没有变
|
sid |
phones |
| 0 |
s1 |
[华为, 小米, 一加] |
| 1 |
s2 |
[三星, 苹果] |
fillna函数
填充缺失值;可以整体填充,也可以对每个属性单独填充
df4
|
sid |
name |
| 0 |
s1 |
xiaoming |
| 1 |
s2 |
NaN |
| 2 |
NaN |
Mike |
df4.fillna({"sid":"s3","name":"Peter"})
|
sid |
name |
| 0 |
s1 |
xiaoming |
| 1 |
s2 |
Peter |
| 2 |
s3 |
Mike |
groupby函数
同组统计的功能
图解Pandas的groupby机制
# 借用这个结果
df6 = df5.explode("phones")
df6
|
sid |
phones |
| 0 |
s1 |
华为 |
| 0 |
s1 |
小米 |
| 0 |
s1 |
一加 |
| 1 |
s2 |
三星 |
| 1 |
s2 |
苹果 |
df6.groupby("sid")["phones"].count()
sid
s1 3
s2 2
Name: phones, dtype: int64
head函数
查看前几行的数据,默认是前5行
df7 = pd.DataFrame({
"sid":list(range(10)),
"name":list(range(80,100,2))})
df7
|
sid |
name |
| 0 |
0 |
80 |
| 1 |
1 |
82 |
| 2 |
2 |
84 |
| 3 |
3 |
86 |
| 4 |
4 |
88 |
| 5 |
5 |
90 |
| 6 |
6 |
92 |
| 7 |
7 |
94 |
| 8 |
8 |
96 |
| 9 |
9 |
98 |
df7.head() # 默认前5行
|
sid |
name |
| 0 |
0 |
80 |
| 1 |
1 |
82 |
| 2 |
2 |
84 |
| 3 |
3 |
86 |
| 4 |
4 |
88 |
df7.head(3) # 指定前3行
|
sid |
name |
| 0 |
0 |
80 |
| 1 |
1 |
82 |
| 2 |
2 |
84 |
isnull函数
判断是否存在缺失值,超级常用的函数
df4
|
sid |
name |
| 0 |
s1 |
xiaoming |
| 1 |
s2 |
NaN |
| 2 |
NaN |
Mike |
df4.isnull() # True表示缺失
|
sid |
name |
| 0 |
False |
False |
| 1 |
False |
True |
| 2 |
True |
False |
df4.isnull().sum() # 每个字段缺失的总和
sid 1
name 1
dtype: int64
df6.isnull().sum() # 没有缺失值
sid 0
phones 0
dtype: int64
join函数
用于连接不同的DataFrame:图解Pandas数据合并:concat、join、append
df7 = pd.DataFrame({
'key': ['K0', 'K1', 'K2', 'K3', 'K4', 'K5'],
'A': ['A0', 'A1', 'A2', 'A3', 'A4', 'A5']})
df7
|
key |
A |
| 0 |
K0 |
A0 |
| 1 |
K1 |
A1 |
| 2 |
K2 |
A2 |
| 3 |
K3 |
A3 |
| 4 |
K4 |
A4 |
| 5 |
K5 |
A5 |
df8 = pd.DataFrame({
'key': ['K0', 'K1', 'K2'],
'B': ['B0', 'B1', 'B2']})
df8
|
key |
B |
| 0 |
K0 |
B0 |
| 1 |
K1 |
B1 |
| 2 |
K2 |
B2 |
df7.join(df8,lsuffix="_df7",rsuffix="_df8")
|
key_df7 |
A |
key_df8 |
B |
| 0 |
K0 |
A0 |
K0 |
B0 |
| 1 |
K1 |
A1 |
K1 |
B1 |
| 2 |
K2 |
A2 |
K2 |
B2 |
| 3 |
K3 |
A3 |
NaN |
NaN |
| 4 |
K4 |
A4 |
NaN |
NaN |
| 5 |
K5 |
A5 |
NaN |
NaN |
kurt函数
查找数据的峰度值:从统计和数据角度出发,如何看待房价?
df9 = pd.DataFrame({
"A":[12, 4, 5, 44, 1],
"B":[5, 2, 54, 3, 2],
"C":[20, 16, 7, 3, 8],
"D":[14, 3, 17, 2, 6]})
df9
|
A |
B |
C |
D |
| 0 |
12 |
5 |
20 |
14 |
| 1 |
4 |
2 |
16 |
3 |
| 2 |
5 |
54 |
7 |
17 |
| 3 |
44 |
3 |
3 |
2 |
| 4 |
1 |
2 |
8 |
6 |
df9.kurt()
A 3.936824
B 4.941512
C -1.745717
D -2.508808
dtype: float64
loc函数
loc就是location的缩写,定位查找数据
df9
|
A |
B |
C |
D |
| 0 |
12 |
5 |
20 |
14 |
| 1 |
4 |
2 |
16 |
3 |
| 2 |
5 |
54 |
7 |
17 |
| 3 |
44 |
3 |
3 |
2 |
| 4 |
1 |
2 |
8 |
6 |
df9.loc[1,:] # 第一行全部列的数据
A 4
B 2
C 16
D 3
Name: 1, dtype: int64
df9.loc[1:3,"B"] # 1到3行的B列
1 2
2 54
3 3
Name: B, dtype: int64
merge函数
同样也是数据的合并函数,类似SQL中的join,功能最为强大
df7
|
key |
A |
| 0 |
K0 |
A0 |
| 1 |
K1 |
A1 |
| 2 |
K2 |
A2 |
| 3 |
K3 |
A3 |
| 4 |
K4 |
A4 |
| 5 |
K5 |
A5 |
df8
|
key |
B |
| 0 |
K0 |
B0 |
| 1 |
K1 |
B1 |
| 2 |
K2 |
B2 |
pd.merge(df7,df8) # 默认how的参数是inner
|
key |
A |
B |
| 0 |
K0 |
A0 |
B0 |
| 1 |
K1 |
A1 |
B1 |
| 2 |
K2 |
A2 |
B2 |
pd.merge(df7,df8,how="outer")
|
key |
A |
B |
| 0 |
K0 |
A0 |
B0 |
| 1 |
K1 |
A1 |
B1 |
| 2 |
K2 |
A2 |
B2 |
| 3 |
K3 |
A3 |
NaN |
| 4 |
K4 |
A4 |
NaN |
| 5 |
K5 |
A5 |
NaN |
nunique函数
用于统计数据的唯一值
df10 = pd.DataFrame({
"sid":list("acbdefg"),
"score":[9,8,9,7,8,9,3]
})
df10
|
sid |
score |
| 0 |
a |
9 |
| 1 |
c |
8 |
| 2 |
b |
9 |
| 3 |
d |
7 |
| 4 |
e |
8 |
| 5 |
f |
9 |
| 6 |
g |
3 |
df10.nunique()
sid 7
score 4
dtype: int64
pct_change函数
计算当前时期和前一个时期的比值
s = pd.Series([90, 91, 85])
s
0 90
1 91
2 85
dtype: int64
s.pct_change()
0 NaN
1 0.011111
2 -0.065934
dtype: float64
(91 - 90) / 90
0.011111111111111112
(85 - 91) / 91
-0.06593406593406594
# 和前两个时期相比
s.pct_change(periods=2)
0 NaN
1 NaN
2 -0.055556
dtype: float64
# 如果存在空值,用填充方法
s = pd.Series([90, 91, None, 85])
s
0 90.0
1 91.0
2 NaN
3 85.0
dtype: float64
s.pct_change(fill_method='ffill')
0 NaN
1 0.011111
2 0.000000
3 -0.065934
dtype: float64
query函数
根据条件查询取值
df10
|
sid |
score |
| 0 |
a |
9 |
| 1 |
c |
8 |
| 2 |
b |
9 |
| 3 |
d |
7 |
| 4 |
e |
8 |
| 5 |
f |
9 |
| 6 |
g |
3 |
df10.query("score >= 8")
|
sid |
score |
| 0 |
a |
9 |
| 1 |
c |
8 |
| 2 |
b |
9 |
| 4 |
e |
8 |
| 5 |
f |
9 |
rank函数
进行排名的函数,类似SQL的窗口函数功能:
df10
|
sid |
score |
| 0 |
a |
9 |
| 1 |
c |
8 |
| 2 |
b |
9 |
| 3 |
d |
7 |
| 4 |
e |
8 |
| 5 |
f |
9 |
| 6 |
g |
3 |
df10["rank_10"] = df10["score"].rank()
df10
|
sid |
score |
rank_10 |
| 0 |
a |
9 |
6.0 |
| 1 |
c |
8 |
3.5 |
| 2 |
b |
9 |
6.0 |
| 3 |
d |
7 |
2.0 |
| 4 |
e |
8 |
3.5 |
| 5 |
f |
9 |
6.0 |
| 6 |
g |
3 |
1.0 |
df10["rank_10_max"] = df10["score"].rank(method="max")
df10
|
sid |
score |
rank_10 |
rank_10_max |
| 0 |
a |
9 |
6.0 |
7.0 |
| 1 |
c |
8 |
3.5 |
4.0 |
| 2 |
b |
9 |
6.0 |
7.0 |
| 3 |
d |
7 |
2.0 |
2.0 |
| 4 |
e |
8 |
3.5 |
4.0 |
| 5 |
f |
9 |
6.0 |
7.0 |
| 6 |
g |
3 |
1.0 |
1.0 |
df10["rank_10_min"] = df10["score"].rank(method="min")
df10
|
sid |
score |
rank_10 |
rank_10_max |
rank_10_min |
| 0 |
a |
9 |
6.0 |
7.0 |
5.0 |
| 1 |
c |
8 |
3.5 |
4.0 |
3.0 |
| 2 |
b |
9 |
6.0 |
7.0 |
5.0 |
| 3 |
d |
7 |
2.0 |
2.0 |
2.0 |
| 4 |
e |
8 |
3.5 |
4.0 |
3.0 |
| 5 |
f |
9 |
6.0 |
7.0 |
5.0 |
| 6 |
g |
3 |
1.0 |
1.0 |
1.0 |
sort_values函数
根据数据进行排序的函数
df9
|
A |
B |
C |
D |
| 0 |
12 |
5 |
20 |
14 |
| 1 |
4 |
2 |
16 |
3 |
| 2 |
5 |
54 |
7 |
17 |
| 3 |
44 |
3 |
3 |
2 |
| 4 |
1 |
2 |
8 |
6 |
df9.sort_values("A") # 默认是升序排列
|
A |
B |
C |
D |
| 4 |
1 |
2 |
8 |
6 |
| 1 |
4 |
2 |
16 |
3 |
| 2 |
5 |
54 |
7 |
17 |
| 0 |
12 |
5 |
20 |
14 |
| 3 |
44 |
3 |
3 |
2 |
# 先根据B升序,如果B相同,再根据D降序
df9.sort_values(["B","D"], ascending=[True,False])
|
A |
B |
C |
D |
| 4 |
1 |
2 |
8 |
6 |
| 1 |
4 |
2 |
16 |
3 |
| 3 |
44 |
3 |
3 |
2 |
| 0 |
12 |
5 |
20 |
14 |
| 2 |
5 |
54 |
7 |
17 |
tail函数
查看末尾的数据
df7.tail()
|
key |
A |
| 1 |
K1 |
A1 |
| 2 |
K2 |
A2 |
| 3 |
K3 |
A3 |
| 4 |
K4 |
A4 |
| 5 |
K5 |
A5 |
df7.tail(3)
|
key |
A |
| 3 |
K3 |
A3 |
| 4 |
K4 |
A4 |
| 5 |
K5 |
A5 |
unique函数
查找每个字段的唯一元素
df10
|
sid |
score |
rank_10 |
rank_10_max |
rank_10_min |
| 0 |
a |
9 |
6.0 |
7.0 |
5.0 |
| 1 |
c |
8 |
3.5 |
4.0 |
3.0 |
| 2 |
b |
9 |
6.0 |
7.0 |
5.0 |
| 3 |
d |
7 |
2.0 |
2.0 |
2.0 |
| 4 |
e |
8 |
3.5 |
4.0 |
3.0 |
| 5 |
f |
9 |
6.0 |
7.0 |
5.0 |
| 6 |
g |
3 |
1.0 |
1.0 |
1.0 |
df10["score"].unique()
array([9, 8, 7, 3])
df10["rank_10"].unique()
array([6. , 3.5, 2. , 1. ])
value_counts函数
用于统计字段中每个唯一值的个数
df6
|
sid |
phones |
| 0 |
s1 |
华为 |
| 0 |
s1 |
小米 |
| 0 |
s1 |
一加 |
| 1 |
s2 |
三星 |
| 1 |
s2 |
苹果 |
df6["sid"].value_counts()
s1 3
s2 2
Name: sid, dtype: int64
df6["phones"].value_counts()
华为 1
苹果 1
三星 1
一加 1
小米 1
Name: phones, dtype: int64
where函数
用于查找Series或者DataFrame中满足某个条件的数据
w = pd.Series(range(7))
w
0 0
1 1
2 2
3 3
4 4
5 5
6 6
dtype: int64
# 满足条件的显示;不满足的用空值代替
w.where(w>3)
0 NaN
1 NaN
2 NaN
3 NaN
4 4.0
5 5.0
6 6.0
dtype: float64
# 不满足条件的用8代替
w.where(w > 1, 8)
0 8
1 8
2 2
3 3
4 4
5 5
6 6
dtype: int64
xs函数
该函数是用于多层级索引中用于获取指定索引处的值,使用一个关键参数来选择多索引特定级别的数据。
d = {'num_legs': [4, 4, 2, 2],
'num_wings': [0, 0, 2, 2],
'class': ['mammal', 'mammal', 'mammal', 'bird'],
'animal': ['cat', 'dog', 'bat', 'penguin'],
'locomotion': ['walks', 'walks', 'flies', 'walks']}
# 生成数据
df11 = pd.DataFrame(data=d)
# 重置索引
df11 = df11.set_index(['class', 'animal', 'locomotion'])
df11
|
|
|
num_legs |
num_wings |
| class |
animal |
locomotion |
|
|
| mammal |
cat |
walks |
4 |
0 |
| dog |
walks |
4 |
0 |
| bat |
flies |
2 |
2 |
| bird |
penguin |
walks |
2 |
2 |
# 获取指定索引的值
df11.xs('mammal')
|
|
num_legs |
num_wings |
| animal |
locomotion |
|
|
| cat |
walks |
4 |
0 |
| dog |
walks |
4 |
0 |
| bat |
flies |
2 |
2 |
# 指定多个索引处的值
df11.xs(('mammal', 'dog'))
|
num_legs |
num_wings |
| locomotion |
|
|
| walks |
4 |
0 |
# 获取指定索引和级别(level)的值
df11.xs('cat', level=1)
|
|
num_legs |
num_wings |
| class |
locomotion |
|
|
| mammal |
walks |
4 |
0 |
df11
|
|
|
num_legs |
num_wings |
| class |
animal |
locomotion |
|
|
| mammal |
cat |
walks |
4 |
0 |
| dog |
walks |
4 |
0 |
| bat |
flies |
2 |
2 |
| bird |
penguin |
walks |
2 |
2 |
# 获取多个索引和级别的值
df11.xs(('bird', 'walks'),level=[0, 'locomotion'])
|
num_legs |
num_wings |
| animal |
|
|
| penguin |
2 |
2 |
# 获取指定列和轴上的值
df11.xs('num_wings', axis=1)
class animal locomotion
mammal cat walks 0
dog walks 0
bat flies 2
bird penguin walks 2
Name: num_wings, dtype: int64
往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载黄海广老师《机器学习课程》视频课黄海广老师《机器学习课程》711页完整版课件
本站qq群955171419,加入微信群请扫码:
