OpenCV基础入门
主要了解包括
- opencv 的下载和环境配置
- opencv目录的了解
- opencv中highgui模块
- opencv中core模块
- opencv中imgproc模块
- opencv中feature2d模块
- opencv视频操作
1.OpenCV简介
图像是人类视觉的基础,是自然景物的客观反映。
- 模拟图像通过某种物理量的强弱变化来记录图像信息,所以是连续变换的。因为模拟信号容易受到干扰,如今已经被数字图像全面替代
- 数字图像,其亮度用离散的数值表示
- 位数:0~255灰度图,其中0,代表最黑,255,表示最白
图像分类
- 二值图像:由0和1组成的二值图像
- 灰度图:采用像素8位的非线性尺度来保存,有256级灰度,如果16位,则65536级灰度
- 彩色图:通常采用RGB三个分量表示,分别介于(0~255),采用8位无符号整形
1.1 安装教程
如果是C++的话,可以参考这篇教程,
opencv+vs studio环境配置_addict_jun的博客-CSDN博客_opencv_ffmpeg342_64.dll
或者直接登录Releases - OpenCV官网,然后选择一个版本,点击下载即可。
python的话,则非常简单
pip安装
pip install opencv-python == 3.4.2.17
测试
import cv2
lena = cv2.imread("1.jpg")
cv2.imshow("image",lena)
cv2.waitKey(0)
扩展
pip install opencv-contrib-python==3.4.2.17
1.2 目录解析
当我们下载opencv3.x的版本时,我们经常会发现,有着opencv和opencv2两个文件夹。
- opencv这个文件夹里面包含着旧版的头文件。
- opencv2里面包含着具有时代意义的新版openCV2系列的头文件。
opencv中还能看到OpenCV1.0最核心的头文件,可以把他们整体理解为一个大的组件。

而我们主要关注的是opencv2这个文件夹。

这里介绍几个常用的模块。
- 【calib3d】—-校准和3D这两个词的缩写,主要用来处理相机校准、三维重建相关的内容,包括基本的多视角几何算法、单个立体摄像头标定、物体姿态估计、立体相似算法、3D信息的重建等。
- 【core】—-核心模块功能,比如基本的数据结构,动态数据结构,绘图函数,数组操作相关函数,辅助功能与系统函数和宏以及openGL的互操作。
- 【imgproc】—-Image和Process这两个单词的缩写组合,图像处理模块
- 【features2d】—-Features2D,即2D功能框架,听名字就知道和特征有关。
- 【flann】—-Fast Library for Approximate Nearest Neigh波瑞斯,高维的近似近邻快速搜索算法库,包含以下两个部分。
- 【gpu】—-运用GPU加速的计算机视觉模块
- 【highgui】—-高层GUI图形用户界面,包含媒体的输入输出、视频捕捉、图像和视频的编码解码,图形交互界面的接口等内容。
- 【ml】—-机器学习模块,神奇,opencv连这个都可以做
- 【objectect】—-目标检测模块
- 【ocl】—-OpenCL加速计算机的组件模块
- 【photo】—-图像修复和图像去噪
- 【stiching】—-图像拼接模块
- 【video】—-视频相关的逐渐
通过一个目录文件,就可以粗略的对图像领域的知识有一个大致的了解。

我个人的认为是,core模块是基础,而imgproc,gpu,ocl,video等则是辅助功能,最上层则是具体的应用了,可见3D立体匹配,图像校准,特征选择,机器学习,目标检测,去噪以及拼接等都是图像的应用领域。
那么目录的解析就到这里了,接下来是对于opencv的安装的教程。
highgui则是一个与人交互的终端,显示界面,严格上来说也算是上层应用,而作为opencv的学习,我想首先是core,然后是各类应用。辅助应用则是在应用过程中进行学习。
1.3 OpenCV优势
OpenCV
- 基于C++实现,同时提供python,Ruby,Matlab等语言的接口。
- 跨平台:在windows,linux,os x,android和ios。基于CUDA和OpenCL的高速GPU操作接口也在积极开发中
- 丰富的API,完善的传统计算机视觉算法,涵盖主流的机器学习算法,同时添加了对深度学习的支持
OpenCV-Python
- python是目前的主流语言,可读性很高
- Python可以使用C++轻松扩展,可以在C++中编写计算密集型代码,并创建可用做Python模块的Python包装器,运行速度和C++一样快,且可以使用
Numpy,配合SciPy和Matplotlib集成更容易。
安装OpenCV之前,还可以安装
numpy,matplotlib。OpenCV 3.4.3 以上一些经典算法因为申请了版权而不能使用,新版本有一定的限制
2 highgui高层GUI图形用户界面
主要用于图像的载入、显示和输出到文件的详细分析。
2.1 读取图像
python
cv.imread(img, flag)
'''
参数
-要读取的图像
-读取的标志
+ cv.IMREAD*COLOR:以彩色模式加载图片,任何图像的透明度都将被忽略。这是默认参数。
+ cv.IMREAD*GRAYSCALE:以灰度模式加载图像
+ cv.IMREAD_UNCHANGED:包括alpha通道的加载图像模式
可以使用1,0或者-1来替代上面三个标志
'''
C++
imread(const string& filename, int flags=1)
/*
参数:
+ 文件名
+ 标志位,以不同的颜色读取图片
*/
2.2 显示图像
python
cv.imshow(name, img)
'''
参数
-显示图像的窗口名称,以字符串类型表示
-要加载的图像
注意:在调用显示图像API后,要调用cv.waitKey()给图像绘制留下时间,否则窗口会出现无响应情况,导致图像无法显示出来。
'''
#opencv中显示
cv.imshow("image", img)
cv.waitKey(0)
# matplotlib中展示
'''因为cv中采用BGR进行存储,这里需要转换成RGB的'''
plt.imshow(img[:,:,::-1])
plt.show()
C++
imshow(const string& winname, InputArray mat)'
/*
参数:
+ 显示窗口的名称
+ 显示的图像
*/
// 创建namedWindow()函数
// 如果只是简单使用窗口,imread和imshow就足够了,但是如果需要添加比如滑动条的创建等操作时,则需要使用namedWindow来先创建窗口。
void nameWindow(const string & winname, int flags=WINDOW_AUTOSIZE)
//创建滑动条
createTrackbar()
//滑动条的使用
int getTrackbarPos(const string& trackbarname, const string& winname)
//opencv中的鼠标操作
void setMouseVallback(conststring& winname, MouseCallback onMouse)
2.3 保存图像
python
cv.imwrite(name, img)
'''
参数:
- 文件名,要保存在哪里
- 要保存的图像
'''
C++
bool imwrite(cosnt string& filename, InputArray img, const vector<int>& params=vector<int>());
3 core核心模块
基本的数据结构,Mat是oepnCV踏入2.0时代的主打,使用Mat类数据结构作为主打之后,OpenCV变得越发像需要很少编程涵养的Matlab那样,上手很方便。
- opencv函数中的输出图像的内存分配是自动完成的
- 使用opencv的C++接口时不需要考虑内存释放问题
- 赋值运算符和拷贝构造函数只复制信息头
- 使用clone()或copyTo()来复制一幅图像的矩阵。
3.1 像素值的存储方法
- RGB是最常见的,和人眼采用相似的工作机制。
- HSV和HLS把颜色分解成色调、饱和度和亮度、明度。
- YCrCb在JPEG图像格式中广泛应用
- CIE L*a*b*是一种在感知上均匀的颜色空间,它适合用来度量两个颜色之间的距离。
3.2 常见的数据结构
- 图像表示:Mat类
- 点的表示:Point类
- 颜色表示:Scalar类
- 尺寸表示:Size类
- 矩阵表示:Rect类
- 颜色空间转换:cvtColor()函数
3.3 绘图函数
基本图形的绘制
- 用于绘制直线的line函数
cv.line(img,start,end,color,thickness)
'''
参数
-img:要绘制直线的图像
-Start,end:直线的起点和终点
-color:线条的颜色
-Thickness:线条宽度
'''
- 用于绘制椭圆的ellipse函数
- 用于绘制矩形的rectangle函数
cv.rectangle(img, leftupper, rightdown, color, thickness)
'''
参数
-img:要绘制矩形的图像
-Leftupper,rightdown:矩形的左上角和右下角坐标
-color:线条的颜色
-Thickness:线条的宽度
'''
- 用于绘制圆的circle函数
cv.circle(img, centerpoint, r, color, thickness)
'''
参数
-img:要绘制圆形的图像
-Centerpoint,r:圆心和半径
-color:线条的颜色
-Thickness:线条的宽度,为-1时,会填充颜色
'''
- 用于绘制填充的多边形的fillPoly函数
如果需要在图像中添加文字
cv.putText(img, text, station, font, fontsize, color, thickness, cv.LINE_AA)
‘’’
参数
-img:图像
-text:要写入的文本数据
-station:文本的防治位置
-font:字体
-Fontsize:字体大小
‘’’
3.4 数组操作相关函数
访问图像元素
- LUT函数,Look up table操作
- 计时函数,getTickCount(),getTickFrequency()
- 访问图像中的像素
- 指针访问
- 迭代器访问
- 动态地址计算
- ROI感兴趣区域:使用rect矩形,range:从起始索引到中止索引。
- 线性混合操作:前后页面切换的叠化效果
- 计算数组加权和:addWeighted()函数
- 通道分离:split()函数
- 通道合并:merge()函数
- 图像对比度、亮度值调整
- 离散傅里叶变换:简单来说就是将图像分解成正弦和余弦两个部分。以及一些二维矢量的幅值,自然对数以及矩阵归一化等数学运算。
- XML和YAML文件的操作
这里以python做一些解释
图像的属性包括行数,列数和通道数,图像数据类型,像素数等。
img.shape
img.dtype
img.size #像素个数
图像通道的拆分与合并
有时需要在B,G,R通道图像上单独工作。在这种情况下,需要将BGR图像分割为单个通道。或者在其他情况下,可能需要将这些单独的通道合并到BGR图像。你可以通过以下方式完成。
#拆分通道
b,g,r = cv.split(img)
#通道合并
img = cv.merge((b,g,r))
色彩空间的改变
OpenCV中有150多种颜色空间转换方法。最广泛使用的转换方法有两种,BGR《》Gray和BGR《》HSV
cv.cvtColor(input_image, flag)
'''
参数
-input_image:进行颜色空间转换的图像
-flag:转换类型
+ cv.COLOR_BGR2GRAY:
+ cv.COLOR_BGR2HSV:
'''
图像的加法
可以使用OpenCV的cv.add()函数把两幅图像相加,或者可以简单地通过numpy操作添加两个图像,如res = img1 + img2。两个图像应该具有相同的大小和类型,或者第二个图像可以是标量值。
注意:OpenCV加法和Numpy加法之间存在差异。OpenCV的加法是饱和操作,而Numpy添加是模运算。
图像的混合
这其实也是加法,但是不同的是两幅图像的权重不同,这就会给人一种混合或者透明的感觉
cv.addWeighted(img1, 0.7, img2, 0.3, 0)
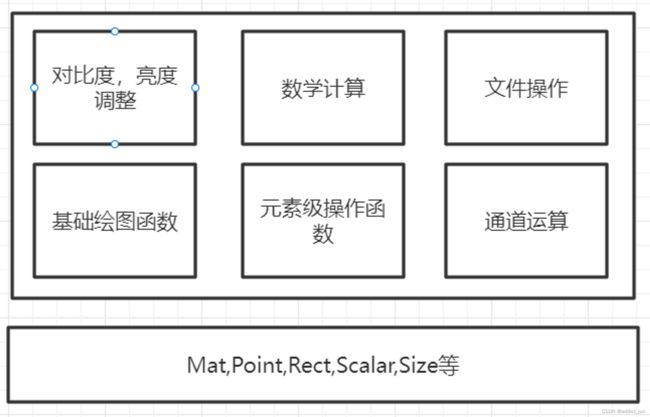
我认为大致的体系如上图所示,数据都是底层,上层则是对数据的操作,从来都是如此。
4 imgproc图像处理
4.1 传统图像处理
传统的图像处理知识主要包括
- 三种线性滤波:方框滤波、均值滤波、高斯滤波。
- 两种非线性滤波:中值滤波、双边滤波。
- 7种图像处理形态学:腐蚀、膨胀、开运算、闭运算、形态学梯度、顶帽、黑帽。
- 漫水填充
- 图像缩放
- 图像金字塔
- 阈值化
4.1.1 三种线性滤波
- 方框滤波
- 均值滤波
- 高斯滤波
4.1.2 非线性滤波
- 中值滤波
- 双边滤波
4.1.3 形态学
源于生物学的一个分支,该分支主要研究动植物的形态和结构。而我们图像处理种的形态学,往往指的是数学形态学。
- 膨胀:对白色高亮部分进行膨胀
- 腐蚀:对白色高亮部分进行腐蚀
- 开运算:先腐蚀,在膨胀。对高亮部分的进行一个分离,或者说剔除小物体
- 闭运算;先膨胀,在腐蚀。对低亮度部分进行提出小物体的操作。
- 形态学梯度:膨胀图与腐蚀图之差。可以将团块的边缘突出出来。
- 顶帽:开运算结果与原图之差,用于背景的提取。
- 黑帽:闭关算的结果图与原图像之差。
4.1.4 漫水填充
我的理解就是选择一种颜色,然后用其他颜色进行填充,就好像我们画图,画一个圈,然后把中间的白色填充为其他颜色一样。
4.1.5 图像金字塔
这里首先就要引出两个概念
- 图像上采样
- 图像下采样
而图像金字塔就是图片从一个最高分辨率逐级向下递减,直到满足某个中止条件,这些多分辨率图像的集合称为图像金字塔。
4.1.5 阈值化
简而言之,就是将超出某个阈值的像素,进行重新的定义的操作。
python设置阈值
| 选项 | 像素值>thresh | 其他情况 |
|---|---|---|
| cv2.THRESH_BINARY | maxval | 0 |
| cv2.THRESH_BINARY_INV | 0 | maxval |
| cv2.THRESH_TRUNC | thresh | 当前灰度值 |
| cv2.THRESH_TOZERO | 当前灰度值 | 0 |
| cv2.THRESH_TOZERO_INV | 0 | 当前灰度值 |
cv2.threshold(src, thresh, maxval, type[, dst])
'''
参数:
-src:灰度图片
-thresh:起始阈值
-maxval:最大值
-type:如上表的关系
'''
这步妥妥的奥运五环。
4.2 imgproc图像变换
4.2.1 边缘检测
一般步骤:
- 滤波:这个就是上面我们常用的高斯滤波,线性滤波等。
- 增强:通过计算各点领域强度的变化值,将显著变化的点凸显出来。
- 检测:还需要对领域变化大的点进行筛选
canny算子
1986年开发的,是边缘检测计算理论的创立者。
- 低错误率:表示出尽可能多的实际边缘,同时尽可能地减少噪声产生的误报。
- 高定位性:标识出的边缘要与图像中的实际边缘尽可能接近。
- 最小响应:图像中的边缘只能标识一次,并且可能存在的图像噪声不应表示为边缘。
sobel算子
sobel算子是一个主要用于边缘检测的离散微分算子。
Laplacian算子
该算子是n为欧几里得空间中的一个二阶微分算子,定义为梯度grad的散度div。
scharr滤波器
顾名思义,他就是一个滤波器,不过是为了配合sobel算子的运算而存在。
4.2.2 霍夫变换
用于识别几何形状图形的基本方法之一。
4.2.3 映射变换
重映射
对像素坐标进行重映射。
仿射变换
可以这样理解,主要是对图像的缩放,旋转和平移等操作的组合。
透射变换
投射变换是视角变化的结果,是指利用透视中心、像点、目标点三点共线的条件,按透视旋转定律使承影面(透视面)绕迹线(透视轴)旋转某一角度,破坏原有的投影光线束,仍能保持承影面上投影几何图形不变的变换。
4.2.4 直方图均衡化
就是计算直方图的频数,然后对其进行平均分布。

5 opencv之feature2d组件
图像特征可以分为三种
- 边缘
- 角点(感兴趣关键点)
- 斑点(感兴趣区域)
5.1 角点检测
我对角点的感觉,有点类似边缘点,该点周围的区域,沿着一个方向,出现明显的亮度变化。
- harris角点检测
- shi-Tomasi角点检测
dst = cv.cornerHarris(src, blockSize, Ksize, k)
'''
参数
-img:数据类型为float32的输入图像
-blockSize:角点检测中要考虑的领域大小
-ksize:sobel求导使用的核大小
-k:角点检测方程中的自由参数,取值参数为【0.04,0.06】
'''
corners = cv2.goodFeaturesToTrack(image, maxcorners, qualityLevel, minDistance)
'''
参数
-image:输入灰度图像
-maxCorners:获取角点数的数目
-qualityLevel:该参数指出最低可接受的角点质量水平,在0-1之间
-minDistance:角点之间最小的欧式距离,避免得到相邻特征点
返回
-corners:搜索到的角点,在这里所有低于质量水平的角点被排除掉了。
'''
- 亚像素级角点检测
5.2 特征检测与匹配
- FAST
- STAR
- SIFT
- SURF
- ORB
- MSER
- GFTT
- HARRIS
- Dense
- SimpleBlob
以上是10中特征检测算法
SIFT
sitf = cv.xfeatures2d.SIFT_create()
kp,des = sift.detectAndCompute(gray, None)
'''
参数
-gray:进行关键点检测的图像,注意是灰度图像
返回:
-kp:关键点信息,包括位置,尺度,方向信息
-des:关键点描述符,每个关键点对应128个梯度信息的特征向量
'''
cv.drawKeypoints(image, keypoints, outputimage, color, flags)
'''
参数:
-image:原始图像
-keypoints:关键点信息,将其绘制在图像上
-outputimage:输出图片,可以是原始图像
-color:颜色设置,通过修改(b,g,r)的值,更改画笔的颜色
-flag:绘图功能
+cv2.DRAW_MATCHES_FLAGS_DEFAULT:创建输出图像矩阵,使用现存的输出图像绘制匹配特征点,每一个关键点只绘制中间点
+cv2.DRAW_MATCHES_FLAGS_DRAW_OVER_OUTIMG:不创建输出图像矩阵,而是在输出图像上绘制匹配对
+cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS:对每一个特征点绘制带大小和方向的关键点图形
+cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINT:单点的特征点不被绘制
'''
FAST
fast = cv.FastFeatureDetector_create(threshold, nonmaxSuppression)
'''
参数
-threshold:阈值t,有默认值10
-nonmaxSuppression:是否进行非极大值抑制,默认值True
返回
-Fast:创建FastFeatureDetector对象
'''
kp = fast.detect(grayImg, None)
'''
参数
-gray:进行关键点检测的图像,注意是灰度图像
返回
-kp:关键点信息,包括位置,尺度,方向
'''
cv.drawKey(image, keypoints, outputimage, color, flags)
ORB算法
orb = cv.xfeatures2d.orb_create(nfeatures)
'''
-nfeatures:特征点的最大数量
'''
kp, dex = orb.detectAndCompute(gray,None)
'''
参数
-gray:进行关键点检测的图像,注意是灰度图像
返回
-kp:关键点
-res:描述符
'''
cv.deawKeypoints(image, keypoints, outputimage, color, flags)
随着图像领域的发展,现在feature2d往往也成为了辅助的图像处理,用于更高一层的应用,比如深度学习。最后我们在了解一下视频操作,就完成了对opencv的基础了解。
6 视频操作
6.1 视频读取
在OpenCV中我们要获取一个视频,需要创建一个VideoCapture对象,指定你要读取的视频文件
#创建读取视频的对象
cap = cv.VideoCapture(filepath)
'''
参数
-filepath:视频文件路径
'''
#获取视频的某些属性
retval = cap.get(propId)
'''
参数
-propId:从0到18的数字,每个数字表示视频的属性
'''
#修改视频的属性信息
retval = cap.set(propId, value)
#判断是否读取成功
isornot = cap.isOpened()
#获取视频的一帧图像
ret, frame = cap.read()
'''
返回
-ret:成功则返回true
-Frame:获取到的某一帧图像
'''
#显示
cv.imshow()
#释放调视频对象
cap.realease()
6.2 保存视频
保存视频使用的是VedioWriter对象
out = cv2.VideoWriter(filename, fourcc, fps, frameSize)
'''
参数
-filename:视频保存的位置
-fourcc:指定视频编解码器的4字节代码
-fps:帧率
-frameSize:帧大小
'''
retval = cv2.VideoWriter_fourcc(c1, c2, c3, c4)
'''
参数
-c1,c2,c3,c4:是视频编码器的4字节代码,在fourcc.org中可以找到代码列表,与平台紧密相关
'''
总结
主要讲解opencv的底层core以及图像基础操作和图像处理内容。