1、什么是自动分词技术
在搜索中,我们常把搜索项作为一个句子提取出来当做特征项,如果提取出来的是英文,那么单词和单词之间用空格将句子拆分。而在中文文本中,词与词之间没有天然的分隔符,中文词汇大多是由两个或两个以上的汉字组成的,并且语句是连续书写的。这就要求在对中文文本进行自动分析前,先将整句切割成小的词汇单元,即中文分词。用具体的例子来说明,就是如何把“我的爸爸是李刚”这样连续书写的语句切分为“我”、“的”、“爸爸”、“是”、“李刚”这五个词汇单元。
2、自动分词技术的重要性
对索引网页库信息进行预处理包括网页分析和建立倒排文件索引两个部分。文档由被称作特征相的索引词(词或者字)组成,网页分析是将一个文档表示为特征项的过程。中文自动分词则是建立网页分析的前提。在检索和文档分类系统中,自动分词系统的速度直接影响整个系统的效率。
3、中文自动分词常用算法
现在自动分词算法分为三类:基于词典的机械匹配的分词方法、基于理解的分词方法和基于统计的分词方法。
4、算法介绍:自动分词的基本方法有:基于字符串匹配的分词方法和基于统计的分词方法。
1) 基于字符串匹配的分词方法
这种方法又称为机械分词方法,它是按照一定的策略将待分析的汉字串与一个充分大的词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功(识别出一个词)。
按照扫描方向的不同,串匹配分词方法可以分为正向匹配和逆向匹配;按照不同长度优先匹配的情况,可以分为最大或最长和最小或最短匹配;按照是否与词性标注过程相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。常用的几种机械分词方法如下:
l 正向最大匹配
l 逆向最大匹配
l 最少切分
还可以将上述各种方法相互结合,例如,可以将正向最大匹配方法和逆向最大匹配方法相结合起来构成双向匹配法。由于汉字单词成词的特点,正向最小匹配和逆向最小匹配一般很少使用。一般说来,逆向匹配的切分精度略高于正向匹配,遇到的歧义现象也较少。统计结果表明,单纯使用正向最大匹配的错误率为1/169,单纯使用逆向最大匹配的错误率为1/245。
对于机械分词方法,可以建立一个一般的模型,形式地为ASM(d,a,m),即Automatic Segmentation Model。其中,d:匹配方向,+表示正向,-表示逆向;a:每次匹配失败增加或减少字串长度,+为增字,-为减字;m:最大或最小匹配标志,+为最大匹配,-为最小匹配。
例如,ASM(+,-,+)就是正向减字最大匹配法,ASM(-,-,+)就是逆向减字最大匹配法。
2) 基于统计的分词方法
从形式上看,词是稳定的字的组合,因此在上下文中,相邻的字同时出现的次数越多,就越有可能构成一个词。因此与字相邻共现得频率或概率能够较好的反映成词的可行度。可以对预料中相邻共现的各个字的组合的频率进行统计,计算它们的互现信息。计算汉字X和Y的互现信息公式为M(X,Y)=lg(P(X,Y)/P(X)P(Y))其中,P(X,Y)是汉字X,Y的相邻共现概率,P(X)、P(Y)分别是X,Y在语料中出现的频率。互现信息体现了汉字之间结合的关系的紧密程度。当紧密程度高于某一个阈值时,便可认为此字组可能构成了一个词。这种方法只需对语料中的字组频度进行统计,不需要切分词典,因而又叫做无词典分词法或统计取词方法。但这种方法也有一定的局限性,会经常抽出一些共现频度高、但并不是词的常用词组,例如,“这一”、“之一”、“有的”、“我的”、“许多的”等,并且对常用词的识别精度差,时空开销大。实际应用的统计分词系统都要使用一部基本的分词词典进行串匹配分词,同时使用统计方法识别一些新的词,即将串频统计和串匹配结合起来,既发挥匹配分词切分速度快、效率高的特点,有利用了无词典分词结合上下文识别生词、自动消除歧义的优点。
5、正向减字最大匹配法
正向减字最大匹配法切分的过程是从自然语言的中文语句中提取出设定的长度字串,与词典比较,如果在词典中,就算一个有意义的词串,并用分隔符分割输出,否则缩短字串,再词典中重新查找。
算法要求为:
输入:中文词典,待切分的文本d,d中有若干被标点符号分割的句子s1,设定的最大词长Maxlen。
输出:每个句子s1被切成若干长度不超过Maxlen的字符串,并用分隔符分开,记为s2,所有s2的连接构成d切分之后的文本。
该算法的思想是:事先将网页预处理成每行是一个句子的纯文本格式。从d中逐句提取,对于每个句子s1从左向右以Maxlen为界选出候选字串W,如果W在词典中,处理下一个长为Maxlen的候选字段;否则,将W最右边一个字去掉,继续与词典比较;s1切分完之后,构成词的字符串或者此时W已经为单字,用分割符隔开输出给s2。从s1中减去W,继续处理后续的字串。S1处理结束,取T中的下一个句子赋给s1,重复前述步骤,直到整篇文本d都切分完毕。
考虑到词典的条目较多,而且每切一个词都要比较,采用STL中的map容器作为存储词典的数据结构。Map容器采用的数据结构是“红黑树”。“红黑树”是一种较常用的查找效率较高的平衡二叉搜索树。在实际应用中可以采用hash表数据结构存储获得更快速的查找。
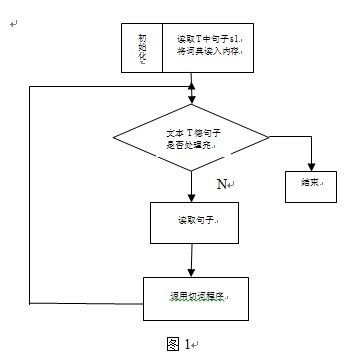
算法的主程序流程如下图1所示,分词程序如图2所示。其中Maxlen是一个经验值,通常设为8个字节,Maxlen过小,长词会被切断;过长,又会导致切分效率低。
|
图1 |
6、算法分析结论
中文自动分词的实现为Web文档挖掘研究以及中文信息处理提供了可能,使得人们能够在这个基础上进行更加深入的研究。本文利用visual C++开发工具实现了中文自动分词算法,通过实验可知在算法中逆向匹配算法精度要求高,速度要快。

 代码
代码
1 While(getASentenceFromFile(T,s1)) //循环读入文件中的每一行
2 s2=CutWord(s1) //调用句子分词处理函数
3 OutputSetence(s2) //将分词结果写入目标文件
String CutWord(s1)
4 Preprocess(s1) //跳过非汉字部分字符串
5 While(s1!=””) //如果输入不为空
6 W=s1.sustr(0,Maxlen) //取等于最大词长的候选词
7 While(length(w)>1)
8 If(FindInRBTree(W)=false)//如果不是词并且不是单字
9 Then W=W-1 //将W最右边一个字去掉
10 s2=W+”/” //将找到的词用分隔符分开
11 s1=s1-W //去掉找到的词,继续分析
12 Return s2

7、算法分析
设文本文件含有句子的数目为m,句子的平均长度为k,词典的条目为n。实际中m和k远远小于n,整个算法复杂度中起决定作用的步骤在于n相关的语句。
行1,O(m) 行2,O(klg n) 行3,O(1) 行4,O(1)
行5,O(k) 行6,O(1) 行7,O(1) 行8,O(lg n)
行9,O(1) 行10,O(1) 行11,O(1) 行12, O(1)
整个算法的时间复杂度为O(mk lg n)。