MIT 6.824 学习(二)【Raft】
文章目录
- 一、理论
-
- 1.1 概述
- 1.2 Raft
-
- 1.2.1 Log Replication
- 1.2.2 leader election
- 二、实验
-
- 2.1 基础模块
-
- 2.1.1 Raft 结构体
- 2.1.2 投票 RPC (RequestVote RPC)
- 2.1.3 追加日志 RPC (AppendEntries RPC)
- 2.1.4 节点需要实现的性质
- 2.2 lab2 - A leader election
- 2.3 lab2 - B log
- 2.4 lab2 - C persistence
- 2.5 lab2 - D log compaction
- 2.6 优化
-
- 2.6.1 Pre Vote
- 2.6.2 Lease
一、理论
内容参考
《In search of an Understandable Consensus Algorithm (Extended Version)》
MIT 6.824 中文翻译
1.1 概述
为了提供更稳定的服务,例如避免单点故障,降低网络分区的影响等,很多时候会使用复制,来使得主从或者主备的数据达成一致,常见的两种做法,一种是状态转移(State Transfer),另一种是复制状态机(Replicated State Machine)。
状态转移:也就是拷贝一个副本或者主机的状态内容,然后通过网络传递给另一个副本,简单来说就是复制内容,为了节约资源可能会采用增量复制。复制状态机:因为引起服务内部发生变化的往往是一条指令或者一个操作,所以不传递状态内容,而是传递引起状态变化的外部事件,简单来说就是复制命令。
Raft 就是复制状态机的一种正确实现。
还需要梳理的概念是脑裂。
对于很多多副本系统,往往只有一个单节点作为 Master 来决策。好处是不会产生冲突,坏处是可能产生单点故障。
如果期望只有单个主节点的集群中出现多个主节点,即脑裂,可能造成集群数据的决策不一致。例如在两个网络分区,两个成为主节点的候选人都可以和一部分节点通信,而认为对方分区节点下线,导致两个节点都成为主节点接受不同的操作请求。
解决的方式在于过半票决(Majority Vote),这样就能天然解决脑裂的问题。只要超过一半的节点赞同提案,才能继续执行操作。另外,对于一轮任期和一个节点的投票都持久化到了磁盘中,来保证不会有多余的投票。
1.2 Raft
通常 Raft 会以库的形式存在于服务中,上层是应用程序,下层是 Raft 库,应用程序会对 Raft 库进行函数,来传递自己的状态和获取反馈信息。比如应用程序的一个操作,Raft 会记录自己的操作日志并和集群内多副本达成一致。
Raft 的实现主要包括两部分内容,日志复制和Leader选举,我在之前的博客中就有写过一些浅显的了解,显然疏漏了很多细节。
1.2.1 Log Replication
Raft Log 的日志内容:
每一个模块的数据结构是一个 entry,包括三个部分。
- Term:请求时 leader 的term
- Index:索引,也就是当前日志在 logs 中的位置
- Command:包含客户端的请求指令
Raft Log 的作用:
- Leader 对操作排序的一种手段,保证操作指令的顺序性。
- Follower 节点对还没有 commit 指令的保存。
- Leader 保存历史的操作日志,在需要的时候重传给 Follower。
- 对所有节点备份,可以用来容灾恢复。
Raft Log 复制过程:
其实就类似于一个二阶段提交的过程。
- leader 将客户端的请求指令组成一个新的log条目添加到本地的log中,然后发送包含最新log 的 RPC 给其他的follower(通过AppendEntries RPC)
- 然后如果超过一半的 Follower 执行 RPC ,将 log 写入成功,返回给 Leader ACK 消息,则代表本次复制成功,Leader 完成 commit。但是本次 commit 消息不会马上同步给 Follower 也就是只有Leader 提交了该操作。
- 本次的 commit 信息会在下一次 Leader 向 Follower 发送 RPC 请求的时候带上提交的版本信息,Follower 发现 commit 号大于自身,则会进行提交。
- 对于之后对 Follower 的读请求,Raft 协议都会转发到 Leader 进行校验,所以不会出现不一致的情况。
在对于一些异常情况的处理中,一般以 Leader 为准,回退后修复一些 Log 内容。
1.2.2 leader election
Raft的所有节点分为三种状态,Leader、Follower 和 Candidate。
其实没有 Leader 也可以达成一致,例如 paxos 就是这么做的,但是,通常情况下,Leader 是不会发生故障的, Leader 的作用是可以更搞笑的协调集群,来达成一致,而不是每次的协调需要先投票选举一个临时的 Leader。
如何触发选举
- Leader 周期性的发送心跳包(AppendEntries RPC)给所有 Follower 节点,来重置 Follower 节点的选举定时器。
- 如果选举定时器到达了一定时间(一般是一个随机的时间值,每次不同,因为相同的时间可能导致持续的多方分割选票),也就是 Follower 在周期内没有收到心跳包,则发起选举。
选举流程
- Follower 发起重新选举,把 term + 1 代表新的一轮,然后变成 Candidate 状态。
- 首先给自己投票,然后像其他节点发送 RequestVote Rpc 收集投票。
- 如果节点还没有进行投票,并且候选人满足以下两个要求,就会投票给该候选人。
- 候选人最后一条Log条目的任期号大于本地最后一条Log条目的任期号;
- 或者,候选人最后一条Log条目的任期号等于本地最后一条Log条目的任期号,且候选人的Log记录长度大于等于本地Log记录的长度
- 如果超过半数的节点都投票给该节点,则该节点就会变成新Leader。
- 一个 Term 只会产生一个 Leader ,如果没有选举出Leader就会进入下一轮。
- 老的Leader如果重连回集群,发现term比他的大,就会更新term并变成Follower。
另外,Raft 会持久化三个数据,分别是Log、currentTerm、votedFor。持久化 Log 来保证日志不会丢失,currentTerm 和 votedFor 保证一个任期只会产生一个 Leader。
二、实验
实验来自 MIT 6.824 lab 2 6.824 Lab 2: Raft
2.1 基础模块
这整个 Lab 的浓缩的精华都在这部分,包括一些核心字段,两个最重要的 RPC 和节点主要的属性。

2.1.1 Raft 结构体
// Raft 结构
type Raft struct {
mu sync.RWMutex // 读写锁
peers []*labrpc.ClientEnd // 每个节点
persister *Persister // 持久化工具类
me int // 节点的索引
dead int32 // 标识位,用来优雅关闭(我觉得不如搞个 stopCh)
applyCh chan ApplyMsg
applyTimer *time.Timer
notifyApplyCh chan struct{} // 欢迎应用日志的chan
state StateType // 节点类型
currentTerm int // 当前 Term
votedFor int // 投票给
logs []Entry // 日志数组
commitIndex int // 已经提交的索引
lastApplied int // 最后应用的索引
nextIndex []int // 每个节点的日志下一个索引
matchIndex []int // 每个节点目前匹配的日志索引
electionTimer *time.Timer // 选举定时器
heartbeatTimer *time.Timer // 心跳定时器
stopCh chan struct{} //首尾呼应,用来优雅关闭
}
2.1.2 投票 RPC (RequestVote RPC)
用来发起拉票请求 RPC
type RequestVoteArgs struct {
Term int // 发起请求节点的 Term
CandidateId int // 候选人的ID
LastLogIndex int // 最新的日志索引
LastLogTerm int // 最新日志的 Term
}
type RequestVoteReply struct {
Term int // 响应节点的 Term
VoteGranted bool // 是否同意投票
}
需要实现的性质:
- (1)如果term < currentTerm返回 false,即当前节点的 Term 更大则不投票。
- (2)如果votedFor为空或者与candidateId相同(表示本来就投票给 Candidate),并且 Candidate 的日志和自己的日志一样新或者更新(表示 Candidate 有更全的状态机),则给该 Candidate 投票。
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
// All Server 情况(2)
if args.Term > rf.currentTerm {
rf.setNewTerm(args.Term)
}
// 情况(1)
if args.Term < rf.currentTerm {
reply.Term = rf.currentTerm
reply.VoteGranted = false
return
}
// 情况(2)
myLastLog := rf.log.lastLog()
upToDate := args.LastLogTerm > myLastLog.Term ||
(args.LastLogTerm == myLastLog.Term && args.LastLogIndex >= myLastLog.Index)
if (rf.votedFor == -1 || rf.votedFor == args.CandidateId) && upToDate {
reply.VoteGranted = true
rf.votedFor = args.CandidateId
rf.persist()
rf.resetElectionTimer()
} else {
reply.VoteGranted = false
}
reply.Term = rf.currentTerm
}
2.1.3 追加日志 RPC (AppendEntries RPC)
该RPC用来向 Follower 节点追加日志以及发送心跳来重置选举定时器。
type AppendEntriesArgs struct {
Term int // 当前任期
LeaderId int // Leader 的节点下标
PrevLogIndex int // 新加入日志之前的最新日志索引
PrevLogTerm int // 新加入日志之前的最新日志任期
Entries []Entry // 追加的日志条目
LeaderCommit int // Leader 提交的索引
}
type AppendEntriesReply struct {
Term int // 响应节点自己的任期
Success bool // 是否成功追加
}
需要实现的性质:
- (1)如果 term < currentTerm返回 false,也就是如果当前节点 Term 更大,则不接受追加。
- (2)如果在 prevLogIndex 处的日志的任期号与 prevLogTerm 不匹配时,返回 false,表明之前日志不一致。
- (3)如果一条已经存在的日志与新的冲突(index 相同但是任期号 term 不同),则删除已经存在的日志和它之后所有的日志,可能情况是本机曾是 Leader,追加完日志之后就发生宕机。
- (4)添加任何在已有的日志中不存在的条目,也就是如果发现Leader和当前节点中间缺少了一些log,则需要补齐。
- (5)如果leaderCommit > commitIndex,将commitIndex设置为leaderCommit和最新日志条目索引号中较小的一个。
2.1.4 节点需要实现的性质
对于所有节点:
- (1)如果commitIndex > lastApplied,lastApplied自增,将log[lastApplied]应用到状态机,表示提交之前的所有的状态机。
- (2)如果 RPC 的请求或者响应中包含一个 term T 大于 currentTerm,则currentTerm赋值为 T,并切换状态为 Follower ,避免候选人或者 Leader一直选举或者重连还是Leader。
Follower 的性质:
- (1)响应来自 Candidate 和 Leader 的 RPC
- (2)如果在超过选取 Leader 时间之前没有收到来自当前 Leader 的AppendEntries RPC或者没有收到 Candidate 的投票请求,则自己转换状态为 Candidate
Candidate 的性质:
- (1)转变为选举人之后开始选举:
- currentTerm自增
- 给自己投票
- 重置选举计时器
- 向其他服务器发送RequestVote RPC
- (2)如果收到了来自大多数服务器的投票:成为 Leader
- (3)如果收到了来自新 Leader 的AppendEntries RPC(heartbeat):转换状态为 Follower
- (4)如果选举超时:开始新一轮的选举
Leader 的性质:
- (1)一旦成为 Leader :向其他所有服务器发送空的AppendEntries RPC(heartbeat);在空闲时间重复发送以防止选举超时。
- (2)如果收到来自客户端的请求:向本地日志增加条目,在该条目应用到状态机后响应客户端
- (3)如果 Leader 节点中当前log的索引大于发送给的 Follower 的 nextIndex,则发送 Follower 缺少的所有Log Entry。
- 如果发送成功:将该 Follower 的 nextIndex和matchIndex更新。
- 如果失败,说明还有不一致,则进入不一致的纠正。
- (4)如果存在一个值 N 大于 CommitIndex ,并且大于所有 matchIndex,并且该索引位置的 Term 和当前的 Term 一致,则将 CommitIndex 修改为 N。也就是对 CommitIndex 修复。
2.2 lab2 - A leader election
第一个部分是 leader election 也就是集群 Leader 的选举。
Leader 的选举主要也就是两部分内容:
- 如何触发选举?
触发选举的方式是某个节点的选举定时器触发一轮选举。
这又牵扯到的问题的是,如何刷新选举定时器,就要通过 Leader 定期发送心跳 RPC 来刷新 Follower 的选举定时器。
// 定时触发选举和发送心跳逻辑
func (rf *Raft) ticker() {
for rf.killed() == false {
select {
case <-rf.stopCh:
return // 优雅关闭
case <-rf.electionTimer.C:
rf.startElection() // 触发一轮选举
case <-rf.heartbeatTimer.C:
// leader 发送心跳
rf.mu.Lock()
if rf.state == StateLeader {
rf.broadcastAppendEntries(true)
rf.heartbeatTimer.Reset(HeartBeatTimeout)
}
rf.mu.Unlock()
}
}
}
- 如何选举?
主要就是角色的转换,变成 StateCandidate 以及票数的统计,需要自己实现 RequestVote RPC 和 AppendEntries RPC 来帮助进行拉票和完成心跳不会造成下一轮选举。
// 开启选举
func (rf *Raft) startElection() {
rf.mu.Lock()
if rf.state != StateFollower {
DPrintf("【startElection】not Follower launch an election")
return
}
DPrintf("【startElection】 start a election")
rf.ChangeState(StateCandidate)
args := RequestVoteArgs{
Term: rf.currentTerm,
CandidateId: rf.me,
}
rf.persist()
rf.mu.Unlock()
// 并发计算选票
grantedCount := 1
chResCount := 1
votesCh := make(chan bool, len(rf.peers))
for index, _ := range rf.peers {
if index == rf.me {
continue
}
go func(ch chan bool, index int) {
reply := RequestVoteReply{}
rf.sendRequestVote(index, &args, &reply)
ch <- reply.VoteGranted
// 如果发现更大的 Term,变回 Follower
if reply.Term > args.Term {
if rf.currentTerm < reply.Term {
rf.currentTerm = reply.Term
rf.ChangeState(StateFollower)
rf.resetElectionTimer()
rf.persist()
}
}
}(votesCh, index)
}
for {
r := <-votesCh
chResCount += 1
if r == true {
grantedCount += 1
}
if chResCount == len(rf.peers) || grantedCount > len(rf.peers)/2 || chResCount-grantedCount > len(rf.peers)/2 {
break
}
}
if grantedCount <= len(rf.peers)/2 {
DPrintf("【startElection】 granted vote less than half, server = %v", rf.me)
return
}
rf.mu.Lock()
if rf.currentTerm == args.Term && rf.state == StateCandidate {
rf.ChangeState(StateLeader)
rf.persist()
}
if rf.state == StateLeader {
rf.broadcastAppendEntries(true)
}
rf.mu.Unlock()
}
第一个实验根据论文的几个要点基本能实现,主要难点在一些细节和锁的粒度上。

2.3 lab2 - B log
lab2B 就是实现 Raft 日志的复制,是比较核心并且有难度的一个 part,主要要对日志复制过程的实现,包括日志2pc的过程,写入的过程以及错误纠正的过程。
按照论文的描述写出 entry 的结构体,包括字段状态机指令,对应的任期号,和位于日志中的索引。
type Entry struct {
Term int
Index int
Command interface{}
}
该 lab 的入口是在 start 函数。输入 Command ,如果是 Leader 节点追加日志并且启动 Raft 。
// 客户端执行指令的入口
// 启动 Raft 协议之后快速返回
func (rf *Raft) Start(command interface{}) (int, int, bool) {
rf.mu.Lock()
defer rf.mu.Unlock()
isLeader := rf.state == StateLeader
if !isLeader {
return -1, -1, false
}
index := rf.getLastLogIndex() + 1
term := rf.currentTerm
// 在 Leader 节点追加日志
rf.logs = append(rf.logs, Entry{
Term: term,
Index: index,
Command: command,
})
// 增加当前节点的 match 索引
rf.matchIndex[rf.me] = index
// 启动协议,广播追加日志
rf.broadcastAppendEntries(false)
return index, term, isLeader
}
// 广播 AppendEntries RPC 发送心跳或者追加日志
func (rf *Raft) broadcastAppendEntries(isHeartBeat bool) {
DPrintf("【broadcastHeartBeat】 server = %v", rf.me)
for peer := range rf.peers {
if peer == rf.me {
rf.resetElectionTimer()
continue
}
// 心跳检测
if isHeartBeat {
go rf.sentAppendEntries(peer, &AppendEntriesArgs{
Term: rf.currentTerm,
LeaderId: rf.me,
PrevLogIndex: rf.getLastLogIndex(),
PrevLogTerm: rf.getLastLogTerm(),
LeaderCommit: rf.commitIndex,
})
}
// Leader 的第(3)个性质,补全 Follower 的缺失日志
// 也有可能是追加一条日志就是 == 情况
if rf.getLastLogIndex() >= rf.nextIndex[peer] {
nextIndex := rf.nextIndex[peer]
if nextIndex <= 0 {
nextIndex = 1
}
entries := make([]Entry, rf.getLastLogIndex()-nextIndex+1)
copy(entries, rf.logs[nextIndex:])
prevLog := rf.logs[nextIndex-1]
args := AppendEntriesArgs{
Term: rf.currentTerm,
LeaderId: rf.me,
PrevLogIndex: prevLog.Index,
PrevLogTerm: prevLog.Term,
Entries: entries,
LeaderCommit: rf.commitIndex,
}
go rf.sentAppendEntries(peer, &args)
}
}
}
sentAppendEntries 方法的实现比较复杂,主要在于日志不一致的纠正情况,而单纯的添加日志,比较简单,主要就是实现论文对应的性质。
// 追加日志的 RPC 对应的 Handle
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
reply.Success = false
reply.Term = rf.currentTerm
// 全部节点性质(2),响应Term更大则修改 Term 并且变成 Follower
if reply.Term > rf.currentTerm {
rf.currentTerm = reply.Term
rf.ChangeState(StateFollower)
return
}
// AppendEntries RPC 性质(1)如果当前节点的 Term 更大,不接受追加
if args.Term < rf.currentTerm {
return
}
// 经过前两个校验,说明是当前 Leader
rf.resetElectionTimer()
// Candidate 的性质(3)收到 RPC 则变回 Follower
if rf.state == StateCandidate {
rf.state = StateFollower
}
// 发现中间还缺少一段日志,说明当前节点丢失了一些数据
if rf.getLastLogIndex() < args.PrevLogIndex {
// 不需要记录一些值,最开始记录了两个参数,
// 其实可以把冲突的一些Index,Term 加入到 reply 里,但是这里就还原论文的实现
return
}
// AppendEntries RPC 性质(2),发现之前日志不一致
if rf.logs[args.PrevLogIndex].Term != args.PrevLogTerm {
return
}
// 逐个追加日志
for idx, entry := range args.Entries {
// AppendEntries RPC 性质(3),如果一条存在的日志和追加的日志比,index 相同,但是 Term 不同,
// 说明出现冲突,则删除该日志以及之后的日志
if entry.Index <= rf.getLastLogIndex() && rf.logs[entry.Index].Term != entry.Term {
rf.logs = rf.logs[:entry.Index]
rf.persist()
}
// AppendEntries RPC 性质(4)
// 追加所有不存在的日志
if entry.Index > rf.getLastLogIndex() {
rf.logs = append(rf.logs, args.Entries[idx:]...)
rf.persist()
break
}
}
// AppendEntries RPC 性质(5)
// 如果Leader 提交的索引大于当前节点的提交索引,则提交能提交的所有日志
if args.LeaderCommit > rf.commitIndex {
rf.commitIndex = min(args.LeaderCommit, rf.getLastLogIndex())
// 应用状态机
rf.apply()
}
reply.Success = true
}
而对于不一致情况的纠正,在 Raft 算法中,leader 通过强制 follower 复制它的日志来解决不一致的问题。要使得 follower 的日志跟自己一致,leader 必须找到两者达成一致的最大的日志条目(索引最大),删除 follower 日志中从那个点之后的所有日志条目,并且将自己从那个点之后的所有日志条目发送给 follower 。
找对应日志条目的方法是 Leader 先发送一个 AppendEntries RPC 包括了一个 nextIndex,也就是当前日志 Index 最新值 + 1 和 任期,如果 Follower 不匹配,会返回拒绝请求,则 Leader 递减 nextIndex,直到找到一致的条目。
func (rf *Raft) sentAppendEntries(serverId int, args *AppendEntriesArgs) {
for !rf.killed() {
rf.mu.Lock()
var reply AppendEntriesReply
ok := rf.peers[serverId].Call("Raft.AppendEntries", args, reply)
if !ok {
return
}
// 全部节点性质(2),响应Term更大则修改 Term 并且变成 Follower
if reply.Term > rf.currentTerm {
rf.currentTerm = reply.Term
rf.ChangeState(StateFollower)
return
}
// Leader 性质(3.1)追加日志成功更新 matchIndex 和 nextIndex
if reply.Success {
match := args.PrevLogIndex + len(args.Entries)
next := match + 1
rf.nextIndex[serverId] = max(rf.nextIndex[serverId], next)
rf.matchIndex[serverId] = max(rf.matchIndex[serverId], match)
break
} else {
// 纠正策略,递减 nextIndex,直到找到匹配项
nextIndex := args.PrevLogIndex
entries := make([]Entry, rf.getLastLogIndex()-nextIndex+1)
copy(entries, rf.logs[nextIndex:])
prevLog := rf.logs[nextIndex - 1]
args.PrevLogIndex = prevLog.Index
args.PrevLogTerm = prevLog.Term
args.Entries = entries
}
rf.mu.Unlock()
}
// 每追加一次日志就尝试提交,也就是看是否有一半 matchIndex 大于提交的 Index
// 尝试提交 循环找到 CommitIndex 范围 [rf.commitIndex + 1, rf.getLastLogIndex()] 里可以提交的最大值
rf.tryCommit()
}
还有一个就是 applier 函数去执行状态机,比较简单,就是循环执行 lastApplied 到 commitIndex 之间的状态机,写 ApplyMsg 进一个 Channel,上层应用程序响应进行一些操作。
2.4 lab2 - C persistence
该 Lab part 是将一些信息持久化,需要持久化的信息包括日志,当前 Term 和 投票对象 votedFor。
实验中不是真正存储在磁盘,而是用一个 Persister 对象代替。
我的实现是就是当上述几个数据出现修改就调用 rf.persist() 持久化。
TODO:有时间也可以优化成真正的磁盘读写,如果随机读写效率太低,也可以加入 WAL 等优化。
2.5 lab2 - D log compaction
对于日志的压缩,在该 lab 部分好像没有具体的入口,只是调用了两个函数进行模拟,一个是 Snapshot 对于快照的生成,一个是 CondInstallSnapshot 对于快照的载入,所以实现这两个函数即可。实际上就是将之前的日志删除,并且保存一个状态供发送给别的节点或者自身恢复。
感觉现在实现比较抽象,等实现上层 KV 再做。

- 如果term < currentTerm立刻回复
- 如果是第一个分块(offset 为 0)则创建新的快照
- 在指定的偏移量写入数据
- 如果 done为 false,则回复并继续等待之后的数据
- 保存快照文件,丢弃所有存在的或者部分有着更小索引号的快照
- 如果现存的日志拥有相同的最后任期号和索引值,则后面的数据继续保留并且回复
- 丢弃全部日志
- 能够使用快照来恢复状态机(并且装载快照中的集群配置)
2.6 优化
参考 Consensus: Bridging Theory and Practice
两种优化主要对于网络分区。
2.6.1 Pre Vote
第一种情况,是网络出现分区,一个节点连接不上另外两个节点。
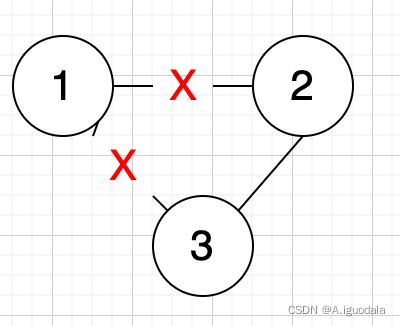
这种情况,节点一因为接收不到 Leader 的心跳包,会不断递增 Term 并且发起选举,并且在分区恢复后,因为Term 更新,会使得 Leader 的请求失败,变成 Follower (全部节点性质(2),响应Term更大则修改 Term 并且变成 Follower),从而心跳超时重新发起选举,导致不可用。
这种情况就引入 Pre Vote ,类似于 2PC
- 节点在发起正式选举之前,会进行一次 Pre Vote,也进入 Pre Candidate 的状态,把 Term 预➕1 并发起选举。
- 如果获取了超过半数的选票说明可能成为 Leader 然后发起选举,避免了一直选举不成功导致一直递增 Term。
2.6.2 Lease
第二种情况是每两个节点之间存在联系,但是和另一个节点存在分区。

这种情况可能导致 1 选举为 Leader 之后,没有 append log,2 因为没有接受到 1 的心跳包,所以发起一轮选举成为 Leader(没有追加日志,索引log 一样新),之后 1 又因为没有收到心跳包发起选举,导致集群一直在选举状态。
这种情况就可以使用 Lease 租约来解决。
- Follower 节点维护一个 Lease 计时器,维护的是上一次心跳的时间。
- 相当于维护了一份租约,只有在超过 election time 没有收到心跳才会选择投票。