OpenCV学习
【OpenCV学习】(一)开篇
Excerpt
在业界很多项目都是基于OpenCV这个强大的库进行开发的,随着深度学习的发展,在一些任务上拜托了传统算法的依赖,但对于前处理以及后处理来说,OpenCV还是一个高效可用的图像库
背景
OpenCV作为图像领域最常用的工具,是从事图像行业工程师必不可缺的技能;
在业界很多项目都是基于OpenCV这个强大的库进行开发的,随着深度学习的发展,在一些任务上拜托了传统算法的依赖,但对于前处理以及后处理来说,OpenCV还是一个高效可用的图像库;
OpenCV涉及的领域相当广泛,例如目标识别、自动驾驶、医学影像、视频内容理解等;
选择Python版本的原因
本次学习统一采用Python版本,主要考虑以下几点:
1、Python语言相对简单,开发速度快(相较C++版本开发容易些);
2、底层使用C++,使用Python版本也可保证运行速度,性能影响不大;
3、有完整的生态链;
OpenCV与FFmpeg的关系
OpenCV与FFmpeg其实是相互调用的关系,OpenCV内部可以调用FFmpeg的接口,关于二者的关系详情可看下图,具体介绍了FFmpeg的功能模块:

目标
本次专栏学习主要有以下几点目标:
1、了解OpenCV的常用操作;
2、可以使用OpenCV处理一些简单图像问题;
3、完成几个实战项目,熟练OpenCV的使用;
安装
OpenCV的Python版本安装很简单,pip直接安装即可:
pip install numpy matplotlib opencv-python
如果opencv安装失败,可以尝试换源或手动下载安装的方式;
【OpenCV学习】(二)数据的加载和展示
背景
在实际工程中,最重要的往往是数据的读取和展示,OpenCV能够支持图像和视频数据,并且给予了很好的支持;不管是做传统项目还是基于深度学习的项目,读取数据都是必不可少的;
创建和显示窗口
使用API:
- namedWindow():创建一个窗口,给定名字和传窗口类型;
- imshow():展示窗口;
- destroyAllWindows():销毁所有窗口;
- resizeWindow():
代码案例:
import cv2
// cv2.WINDOW_NORMAL是定义一个可调整大小的窗口
cv2.namedWindow('window', cv2.WINDOW_NORMAL)
cv2.resizeWindow('window', 1920, 1080)
cv2.imshow('window', 0)
key = cv2.waitKey(0)
if(key == 'q'):
cv2.destroyAllWindows()
读取图片
-
imread(图片路径,图片类型)
图片类型一般情况下有两种:0表示灰度图,1表示彩色图,不传值默认为彩色图;
代码案例:
img = cv2.imread('test2.jpg')
cv2.imshow('img', img)
cv2.waitKey(0)
保存图片
- imwrite(图片保存路径及名称,Mat格式数据)
代码案例:
imwrite("save.jpg", img)
视频采集和读取
使用API:
-
VideoCapure():参数需要设备id号,默认填0即可;
注意:如果想要读取视频,只需要将传入参数改为视频路径即可;
-
read():返回两个值,第一个为状态值(读取到为true),第二个值为视频帧;
-
release():释放视频资源;
代码案例:
cv2.namedWindow('video', cv2.WINDOW_NORMAL)
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
cv2.imshow('video', frame)
key = cv2.waitKey(10)
# 键盘事件,用户输入q退出
if(key == ord('q')):
break
cap.release()
cv2.destroyAllWindows()
视频录制
使用API:
-
VideoWrite():参数一为输出文件,参数二为多媒体文件格式,参数三为帧率,参数四为分辨率;
-
VideoWriter_fourcc(*‘四字符格式’):创建多媒体文件格式;
媒体文件格式举例:DIVX(.avi)、MJPG(.mp4)、X264(.mkv)
-
write():将数据写入视频文件中;
-
release():释放资源;
代码案例:
# 创建VideoWriter为写多媒体文件
fourcc = cv2.VideoWriter_fourcc(*'MJPG')
# 注意如果读取摄像头数据的话,保存的分辨率需要和摄像头采集的一致
vw = cv2.VideoWriter('./out.mp4', fourcc, 25, (1280, 720))
# 写数据到多媒体文件, 中间省略读取数据部分
vw.write(frame)
# 释放VideoWriter
vw.release()
鼠标控制
使用API:
- setMouseCallback(winname,callback,userdata)
- callback(event,x,y,flags,userdata):event就是事件(鼠标移动、按下左键等),flags是鼠标键及组合键;
event的类别可以参考源码中highgui.hpp的定义:

代码案例:
#鼠标回调函数
def mouse_callback(event, x, y , flags, userdata):
print(event, x, y, flags, userdata)
#创建窗口
cv2.namedWindow('mouse', cv2.WINDOW_NORMAL)
cv2.resizeWindow('mouse', 640, 360)
#设置鼠标回调
cv2.setMouseCallback('mouse', mouse_callback, "123")
#显示窗口和背景
img = np.zeros((360, 640, 3), np.uint8)
while True:
cv2.imshow('mouse', img)
key = cv2.waitKey(1)
if key & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
上述代码创建了一个窗口,并传入一个全黑的图像,会返回鼠标事件的值,如下图:

TrackBar控件
使用API:
- createTrackbar(trackname,winname,默认当前值,最大值,callback函数)
- getTrackbarPos(trackname,winname)
代码案例(一个简单调色板,调整RGB的值):
def callback():
pass
#创建窗口
cv2.namedWindow('trackbar', cv2.WINDOW_NORMAL)
#创建trackbar
cv2.createTrackbar('R', 'trackbar', 0, 255, callback)
cv2.createTrackbar('G', 'trackbar', 0, 255, callback)
cv2.createTrackbar('B', 'trackbar', 0, 255, callback)
#创起家一个背景图片
img = np.zeros((480, 640, 3), np.uint8)
while True:
#获取当前trackbar的值
r = cv2.getTrackbarPos('R', 'trackbar')
g = cv2.getTrackbarPos('G', 'trackbar')
b = cv2.getTrackbarPos('B', 'trackbar')
#改变背景图片颜色
img[:] = [b, g, r]
cv2.imshow('trackbar', img)
key = cv2.waitKey(10)
if key & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
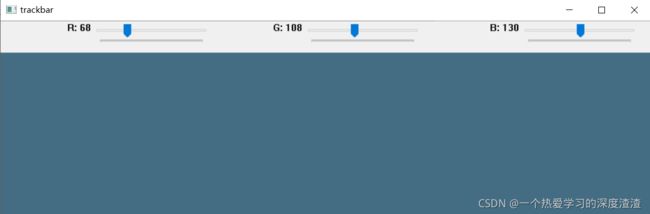
随机调了一个我喜欢的海蓝色,大家可以自己尝试调出自己喜欢的颜色;
总结
OpenCV这个库对图像和视频是非常友好的,支持多种格式,并且功能强大;本篇仅仅介绍了数据的读取和写入,重点是窗口的创建和一些辅助操作。
【OpenCV学习】(三)色彩及矩阵操作
背景
之前主要介绍了数据的读取和展示操作,本篇将开始介绍数据的简单处理操作;
一、颜色空间转换
1、介绍一些常见的颜色空间
RGB:人眼的色彩空间;
BGR:OpenCV默认使用的色彩空间;
HSV的说明:
- Hue:色相,即色彩如红色、绿色;
- Saturation:饱和度,颜色的纯度;
- Value:明亮度;

2、转换色彩空间
cvtColor(原始数据,变换格式);
变换格式有很多种,例如:COLOR_BGR2RGB、COLOR_BGR2BGRA等;
代码案例:
cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
二、Numpy基本操作
Numpy使用原因:
1、OpenCV中用到的矩阵都要转换成Numpy数组;
2、Numpy是一个经过高度优化的Python数值库;
相信大家对于Numpy都比较熟悉,这里主要来回顾一下:
1、创建矩阵
- 创建数组:array()
- 创建全0数组:zeros()/ ones()
- 创建全值数组:full()
- 创建单位矩阵:identity()/ eye()
2、Numpy的检索
需要注意的是,我们访问img[y,x]的时候,第一个元素代表竖轴,第二个元素代表横轴;
如果想要给一个像素点中的某个通道赋值,也可以如下:
img[100, 100] = [0, 0, 255]# B,G,R分别赋值
3、获取子矩阵(ROI)
举个例子,得到图像的一个ROI区域:
img = cv2.imread('test2.jpg')
roi = img[100:400, 200:400, :]
当然不只有这一种用法,还有很多的使用方式,在实际工程中可以多尝试;
三、Mat
定义:从Python角度来说Mat就是一个矩阵,也是R、G、B的组合;
Mat属性

Mat拷贝
Mat的拷贝形式有两种:浅拷贝与深拷贝;
浅拷贝示意图:

代码实现:
A = cv2.imread("test.jpg")
B = A
特点:改变B的数据,A也会发生改变;
深拷贝代码实现:
A = cv2.imread("test.jpg")
B = A.copy()
特点:不会改变原来Mat的数据,是将Data数据拷贝一份;
图像属性
- img.shape:图像的高度、长度和通道数;
- img.size:图像占用空间大小(高度 x 长度 x 通道数);
通道的分离与合并
使用API:
- split(mat):分离通道;
- merge((ch1,ch2,ch3)):合并通道;
代码案例:
b, g, r = cv2.split(img)
img2 = cv2.merge((b, g, r))
总结
本篇讲的比较基础,主要是介绍一些基础知识,对于了解图像和Mat的可以直接跳过本篇学习;下一篇将讲解图像的绘制,这样是为之后的项目做一个铺垫;
【OpenCV学习】(四)图形绘制
背景
使用OpenCV进行图形绘制是一种必备的技能,在图像的任务中,不管是图像检测还是图像识别,我们都需要通过绘制图形和绘制文字对处理的结果进行说明,本篇就详细介绍下图形的绘制;
一、画线
line(图像,起始点,终点,颜色,线宽,线形):一般只需要前面四个参数即可;
代码案例:
cv2.line(img, (20, 100), (20, 500), (0,0,255))
画出了一条Y方向上的红色线段;
二、画矩形
这个相对来说是应用最多的一种方法了,往往在检测项目中返回目标的结果就是(x,y,w,h)或者(x1,y1,x2,y2)这两种形式,当然我们这里绘制需要的是第二种形式,而通过左上角点计算右下角也是很简单的;
cv2.rectangle(img, (x1,y1), (x2,y2), (0,0,255), 3)# 后面两个参数为颜色和线长
简单展示一下我用DeepFashion数据画出矩形框的效果:

三、画圆
画圆在应用的其实并不多,更多的是画点的操作,例如关键点的任务,需要将关键点在目标图像上显示出来;而实际上点就是一个实心圆,这里就介绍画圆和画点的两种形式吧。
# 函数
cv2.circle(img, (x,y), 半径长度, (0,0,255), -1)// 画一个实心圆(点),最后参数设置为负数
cv2.circle(img, (x,y), 半径长度, (0,0,255), 4)// 画一个空心圆
下面还是展示我画出关键点的一个效果:

四、画多边形
绘制多边形在实际应用中也很常见,例如分割以及OCR的任务,往往需要用多个点描述出目标的轮廓。
函数原型如下:
polylines(img,点集,是否闭环,颜色…),注意这里的点集必须是32位的
案例代码:
pot = np.array([(100, 100), (200, 200), (300, 400)], np.int32)
cv2.polylines(img, [pot], True, (0, 0, 255))
# 如果输出填充的多边形,用以下api
cv2.fillPoly(img, [pot], (0, 0, 255))
五、画文本
绘制文本在实际项目中,往往用来标记类别,对于一些结果输出,可以通过文本的方式绘制到图像上,便于观察结果和验证;
函数原型:
putText(img,字符串,起始点,字体,字号…)
案例代码:
cv2.putText(img, "Hello World", (100, 100), 字体, 3, (0,0,255))
六、鼠标绘制
实现功能:
可通过鼠标进行基本图形的绘制:按下l画线,按下r画矩形,按下c画圆;
代码实现:
import cv2
import numpy as np
star = (0, 0)
select = 0
img = np.zeros((480, 640, 3), np.uint8)
// 定义鼠标回调函数
def mouse_callback(event, x, y, flags, userdata):
global star,select
if (event & cv2.EVENT_LBUTTONDOWN == cv2.EVENT_LBUTTONDOWN):
star = (x, y)
elif (event & cv2.EVENT_LBUTTONUP == cv2.EVENT_LBUTTONUP):
if select == 0:
cv2.line(img, star, (x, y), (0, 0, 255))
elif select == 1:
cv2.rectangle(img, star, (x, y), (0, 0, 255))
elif select == 2:
a = (x - star[0])
b = (y - star[1])
r = int((a**2+b**2)**0.5)
cv2.circle(img, star, r, (0, 0, 255))
else:
print('no shape')
cv2.namedWindow('drawshape', cv2.WINDOW_NORMAL)
cv2.setMouseCallback('drawshape', mouse_callback, "111")
while True:
cv2.imshow('drawshape', img)
key=cv2.waitKey(1) & 0xFF
if key == ord('q'):
break
elif key == ord('l'):
select = 0
elif key == ord('r'):
select = 1
elif key == ord('c'):
select = 2
下图是我自己随意画的结果,大家可以创造出更有趣的图画;

总结
常用的图形绘制就是上面的几种,其中中文文本还存在问题(需要引入字体样式文件),在后续会进行补充;之后将学习图形学的一些进阶知识,也是为后续实战做准备;
【OpenCV学习】(五)图像运算
背景
图像本质就是矩阵,对图像的处理往往就是矩阵的运算;常见的运算有加法、减法和位运算等,一些进阶的滤波等操作,也是基于这些简单运算而来的,只是修改了一些参数而已;
一、加法运算
实际上就是像素值的相加,起到一个调节亮度(曝光)的效果;
案例代码:
org = cv2.imread('./org.jpg')
# 创建一个相同大小的背景图
img = np.ones((1200, 1920, 3), np.uint8) * 30
# 像素值相加
result = cv2.add(org, img)
cv2.imshow('result', result)
cv2.waitKey(0)
深度思考一下,在具体项目中,对于数据的预处理也可以用加法的操作;通过两张图像相加并且设置一定权重,可以生成一张新的图像,扩展数据集的同时也提高了泛化能力;
二、减法运算
函数原型:
subtract(A,B):代表A减B
案例代码:
result = cv2.subract(org, img)
效果就是使图片变暗,也就是降低亮度;
三、图像融合
之前介绍加法操作时提及到可以设定权重,实际上opencv中有给定这样的函数addWeighted(A,alpha,B,bate,gamma),其中alpha和beta是代表AB图像的权重,gamma表示静态权重;
案例代码:
A = cv2.imread('A.jpg')
B = cv2.imread('B.jpg')
result = cv2.addWeighted(A, 0.7, B, 0.3, 0)
注意:不管做任何运算,需要确保两张图像的大小一致;
四、位运算
1、非运算
bitwise_not(图像):也就是把黑的变白,白的变黑;
2、与运算
bitwise_and(图像A,图像B):也就是像素值相同的部分为白,不同部分为黑;(求交集)
3、或运算
bitwise_or(图像A,图像B):也就是像素值为白的部分全部为白,其余部分为黑;(求并集)
4、异或运算
bitwise_xor(图像A,图像B):也就是像素值相同部分为黑,其余部分不变;(并集减去交集)
五、添加水印案例
主要步骤:
1、引入原始图像;
2、设计一个LOGO图像;
3、计算添加位置,将原始图像中该区域设置成黑色;
4、将LOGO图像与处理后图像用add叠加;
代码示例:
dog = cv2.imread('./dog.jpeg')
# 创建LOGO和mask
logo = np.zeros((200,200,3), np.uint8)
mask = np.zeros((200,200), np.uint8)
# 绘制图形
logo[10:110,10:110] = [0, 255, 0]
logo[90:190, 90:190] = [0, 0, 255]
mask[10:110,10:110] = 255
mask[90:190, 90:190] = 255
# 对mask求反
mask = cv2.bitwise_not(mask)
# 选择图像的一个区域
roi = dog[0:200, 0:200]
# 与mask进行操作
tmp = cv2.bitwise_and(roi, roi, mask)
# 叠加操作(由于图像过大,这里进行了缩放)
dst = cv2.add(tmp, logo)
dog[0:200,0:200] = dst
dog = cv2.resize(dog, (500,500), interpolation = cv2.INTER_AREA)
# 显示图像
cv2.imshow('dog', dog)
cv2.waitKey(0)

总结
图像的运算基本上都是用函数实现了,从使用上看起来比较简单,但其内在的原理相对会复杂一些;并且对于一些分割任务需要设置掩码的,本质上就是一种图像的运算,在后续会深入再运用;
【OpenCV学习】(六)图像基本变换
背景
图像的变换通常用于数据预处理部分,例如缩放旋转等常见的图像变换方法;在一些深度学习框架内部都分装了图像变换的方法,对训练集做统一的图像变换操作;
一、图像缩放
函数原型:
resize(src,dsize,[fx,fy,interpolation])
- fx:x轴的缩放因子;
- fy:y轴的缩放因子;
- interpolation:插值算法;
插值算法有以下几种:
1、INTER_NEAREST:最近邻插值,速度快,效果差;
2、INTER_LINEAR:双线性插值,基于原图的四个点;(默认插值方法)
3、INTER_CUBIC:三次插值,基于原图16个点,效果好但耗时大;
4、INTER_AREA:效果最好,速度也最慢;
二、图像翻转
图像翻转不等同于旋转,类似于一些视频的拍摄,拍摄后实际是左右颠倒的,通过图像翻转可进行还原;
函数原型:
filp(img,filpCode):filpCode等于0(上下翻转)、大于0(左右翻转)、小于0(上下+左右翻转)
代码案例:
cv2.filp(img, 0)# 上下翻转
cv2.filp(img, 1)# 左右翻转
cv2.filp(img, -1)# 上下左右翻转
三、图像旋转
函数原型:
rotate(img,rotateCode)
- ROTATE_90_CLOCKWISE:顺时针旋转90°
- ROTATE_180:旋转180°
- ROTATE_90_COUNTERCLOCKWISE:逆时针旋转90°
四、图像仿射变换——平移
首先介绍一下放射变换,简单来说就是图像旋转、缩放、平移的总称;
函数原型:
warpAffine(src,M,dsize,flags,mode,value)
- M:变换矩阵
- dsize:输出尺寸大小
- flags:与size中的插值算法一致
- mode:边界外推法标志
- value:填充边界的值
实际上平移矩阵就是一个2x2的单位矩阵加上一个2x1的平移向量,也就是2x3的矩阵;
代码案例:
img = cv2.imread('img.jpg')
h,w,c = img.shape
M = np.float32([[1, 0, 500], [0, 1, 0]])# x方向平移500个像素点
new = cv2.warpAffine(img, M, (w, h))
cv2.imshow('new', new)
cv2.waitKey(0)
五、图像仿射变换——旋转
获取变换矩阵M的两种方法:
1、getRotationMatrix2D(center,angle,scale)
- center:中心点
- angle:旋转角度(逆时针)
- scale:缩放比例(宽高同时缩放)
代码案例:
M = cv2.getRotationMatrix2D((100,100), 30, 1.0)
new = cv2.warpAffine(img, M, (w, h))
2、getAffineTransform(src[],dst[])
定义:通过点对应找到变换矩阵,一般三个点就可以;
拓展:这里可以联想到TPS算法,也是通过对应点进行变换的一种方法,二者可能有想通之处;
代码案例:
src = np.float32([[100, 200], [300, 400], [500, 700]])
dst = np.float32([[300, 400], [800, 500], [900, 800]])
cM = cv2.getAffineTransform(src, dst)
new = cv2.warpAffine(img, M, (w, h))
六、透视变换
这里用一个具体案例来介绍,例如拍照搜题的软件,当拍摄整页时会有一种书本和桌面组合的样子,经过透视变换后能更好的将想要的信息放在图像中;
仿射变换函数原型:
warpPerspective(img,M,dsize,…)
获取变换矩阵函数原型:
getPerspective(src,dst):和getAffineTransform函数比较类似,不同的是需要四个坐标点(图形四个角);
代码案例:
paper = cv2.imread('paper.png')
src = np.float32([[100,1100], [2100, 1100], [0, 4000], [2500, 3900]])
dst = np.float32([[0, 0], [2300, 0], [0, 3000], [2300, 3000]])
M = cv2.getPerspectiveTransform(src, dst)
new = cv2.warpPerspective(paper, M, (2300, 3000))
paper = cv2.resize(paper, (460, 600))
new = cv2.resize(new, (460, 600))
cv2.imshow('org', paper)
cv2.imshow('new', new)
cv2.waitKey(0)

总结
图像的变换在解决一些小问题上十分有效,特别是变换矩阵的获取,本质上变换矩阵就是一个滤波器,通过该滤波器改变了图像中一些点的像素值;像仿射变换、透视变换,都是十分常用的方法,用于图像的前处理部分;
【OpenCV学习】(七)图像滤波
背景
图像滤波的作用简单来说就是将一副图像通过滤波器得到另一幅图像;明确一个概念,滤波器又被称为卷积核,滤波的过程又被称为卷积;实际上深度学习就是训练许多适应任务的滤波器,本质上就是得到最佳的参数;当然在深度学习之前,也有一些常见的滤波器,本篇主要介绍这些常见的滤波器;
一、卷积相关概念
卷积核大小一般为奇数的原因:
1、增加padding的原因;
2、保证锚点在中间,防止位置发生偏移;
卷积核大小的影响:卷积核越大,感受野越大,提取的特征越好,同时计算量也越大;
边界扩充(padding)作用:使得输出数据的尺寸与输入相等;
计算公式:
N = (W - F + 2P)/ S + 1
- N:输出图像大小
- W:原图大小
- F:卷积核大小
- P:扩充尺寸
- S:步长大小
二、卷积实战
首先介绍两个简单的滤波:低通滤波与高通滤波;
低通滤波:低于阈值的可通过,去除噪音或平滑图像;
高通滤波:高于阈值的可 通过,用于边缘检测;
函数原型:
filter2D(src,ddepth,kernel,[anchor,delta,borderType])
- ddepth:位深,一般设定为-1;
代码案例:
kernel = np.ones((5, 5), np.float32) / 25
result = cv2.filter2D(img, -1, kernel)
这是一个平均卷积,起到一个降噪的作用,但效果并不明显;
三、均值滤波
首先介绍一个方盒滤波,实际上就是全为1的卷积核乘以权重a;
函数原型:boxFilter(src,ddepth,ksize,anchor,normalize,borderType)
说明:当normalize为True时,乘以1/W*H,也就是均值滤波,所以一般不用这个滤波函数;
均值滤波函数原型:blur(src,ksize,[anchor,borderType])
注意:一般均值滤波就是使用这个API;
代码案例:
result = cv2.blur(img, 5)
四、高斯滤波
原理:越靠近中心,权重越大,离中心越远,权重越小;
函数原型:
GaussianBlur(img,kernel,sigmaX,[sigmaY,…])
说明:对效果有影响的参数为kernel和sigmaX,这两者越大图像平滑(模糊)的效果会越明显;
代码案例:
gauss = cv2.imread('gaussian.png')
result = cv2.GaussianBlur(gauss, (5, 5), 5)
cv2.imshow('org', gauss)
cv2.imshow('result', result)
cv2.waitKey(0)

从图中可看出,处理后高斯噪点减少了,但整体图像也变模糊了;
五、中值滤波
本质:取中间值作为卷积结果;
作用:对胡椒噪音有很好的处理效果;
函数原型:
medianBlur(img,ksize)
代码案例:
img = cv2.imread('papper.png')
result = cv2.medianBlur(img, 5)
cv2.imshow('org', img)
cv2.imshow('result', result)
cv2.waitKey(0)

从上图可以看出,效果是相当不错的;
六、双边滤波
作用:可以保留边缘,同时对边缘内的区域进行平滑处理;(主要进行美颜)
参考文章:https://zhuanlan.zhihu.com/p/127023952
函数原型:
bilateralFilter(img,d,sigmaColor,sigmaSpace)
案例代码:
img = cv2.imread('1.jpg')
result = cv2.bilateralFilter(img, 9, 50, 50)
cv2.imshow('org', img)
cv2.imshow('result', result)
cv2.waitKey(0)

从图中可以看出,美颜效果是比较明显的,并且对于边缘轮廓也处于能接受范围;
七、Sobel算子
上述介绍的几种滤波均为低通滤波,接下来介绍高通滤波,最主要作用是检测边缘;
实现步骤:
x轴方向求导 —— y轴方向求导 —— 最终结果为二者相加
函数原型:
Sobel(src,ddepth,dx,dy,ksize=3,…)
代码案例:
chess = cv2.imread('chess.png')
# 求y方向边缘
dy = cv2.Sobel(chess, cv2.CV_64F, 1, 0, ksize=5)
# 求x方向边缘
dx = cv2.Sobel(chess, cv2.CV_64F, 0, 1, ksize=5)
# 二者相加
result = dy + dx
cv2.imshow('chess', chess)
cv2.imshow('dy', dy)
cv2.imshow('dx', dx)
cv2.imshow('result', result)
cv2.waitKey(0)

从上图可以明显看出,当dx设置为1时,求得y方向上的边缘信息,反之也是,最终二者相加的结果也就是Sobel算子的结果。不能一开始就设定dx,dy为1,这样子不能达到该效果;
八、Scharr算子
定义:与Sobel类似,但使用的kernel值不同,并且只能为3x3,只能求x方向或y方向一个方向的边缘信息;
函数原型:
Scharr(src,ddepth,dx,dy)
在这里就不演示了,该算子不常用,主要优点是能检测到不明显的边缘,当Sobel的ksize设置为-1时等同;
九、拉普拉斯算子
优点:可同时求得两个方向的边缘;
缺点:对噪音比较敏感,一般需要先进行去噪在调用拉普拉斯算子;
函数原型:
Laplacian(img,ddepth,ksize=1)
代码案例:
chess = cv2.imread('chess.png')
result = cv2.Laplacian(chess, cv2.CV_64F, ksize=5)
cv2.imshow('chess', chess)
cv2.imshow('result', result)
cv2.waitKey(0)

从效果上看,比起Sobel步骤更加简单,并且效果也比较好,缺点就是如果噪声过多的话效果会比较差;
十、Canny算法
实现步骤:
1、使用5x5高斯滤波消除噪音;
2、使用Sobel计算图像梯度的方向(0°、45°、90°、135°);
3、取局部极大值;
4、阈值计算;
函数原型:
Canny(img,minVal,maxVal,…)
其中的minVal和maxVal代表边缘的阈值,两者差值过大的话会损失一定的边缘信息;
代码案例:
img = cv2.imread('1.jpg')
result = cv2.Canny(img, 100, 200)
cv2.imshow('org', img)
cv2.imshow('result', result)
cv2.waitKey(0)

总结
图像滤波中最重要的算法就是Canny,本篇并没有涉及内部数学知识的讲解,主要还是在于算法的应用,也是后续完成实际案例的基础;
【OpenCV学习】(八)图像形态学
背景
形态学处理方法是基于对二进制图像进行处理的,卷积核决定图像处理后的效果;形态学的处理哦本质上相当于对图像做前处理,提取出有用的特征,以便后续的目标识别等任务;
一、图像二值化
定义:将图像的每个像素变成两种值,如0和255;
全局二值化的函数原型:
threshold(img,thresh,maxVal,type)
-
img:最好是灰度图像
-
thresh:阈值
-
maxVal:超过阈值,替换为maxVal
-
type:有几种类型,THRESH_BINARY为二值化的类型
案例代码:
img = cv2.imread('1.jpg')
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, dst = cv2.threshold(img, 100, 255, cv2.THRESH_BINARY)
cv2.imshow('org', img)
cv2.imshow('dst', dst)
cv2.waitKey(0)

关于type类型,可查看下图:

二、自适应阈值
解决的问题:由于光照不均匀以及阴影的存在,只有一个阈值会使得在阴影处的白色被二值化成黑色;
若采用全局二值化,在有阴影的图片中,阴影信息会丢失,如下图:

当阈值设置较高时,会出现部分阴影信息丢失,如果需要不断尝试找到合适阈值是一件耗时的事情,因此就有了自适应阈值的方法;
自适应阈值函数原型:
adaptiveThreshold(img,maxVal,adaptiveMethod,,type,blockSize, C)
- adaptiveMethod:计算阈值的方法;
- blockSize:邻近区域的大小;
- C:常量,应从计算出的平均值或加权平均值中减去,一般设置为0;
计算阈值主要有两种两种方法:
① ADAPTIVE_THRESH_MEAN_C:计算邻近区域的平均值;(根据blockSize大小做平均滤波)
② ADAPTIVE_THRESH_GAUSSIAN_C:高斯窗口加权平均值;(根据blockSize大小做高斯滤波)
代码案例:
img = cv2.imread('new.jpg')
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
dst = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY_INV, 11, 0)
cv2.imshow('org', img)
cv2.imshow('dst', dst)
cv2.waitKey(0)

可以看出,虽然信息成功提取出来,但背景的噪点过多,后续会加以处理;
三、腐蚀
本质卷积核的值全为1,可通过下图简单理解其原理:

函数原型:
erode(img,kernel,iterations=1)
- iterations:执行的次数;
代码案例:
img = cv2.imread('./j.png')
kernel = np.ones((3, 3), np.uint8)
dst = cv2.erode(img, kernel, 1)
cv2.imshow('org', img)
cv2.imshow('dst', dst)
cv2.waitKey(0)

上图为腐蚀后的结果,明显白色区域变小了,如果增大卷积核或增加腐蚀次数会使得腐蚀效果更明显;
四、卷积核获取
函数原型:
getStructuringElement(type,size)
-
size一般设置成(3,3)或(5,5)这样;
-
type类型:
MORPH_RECT:矩形形状的卷积核;
MORPH_ELLIPSE:椭圆形状卷积核;
MORPH_CROSS:十字架形状卷积核;
腐蚀中的全为1的卷积核可以通过这个函数构造:
kernrl = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
相比于用numpy构造更好;
五、膨胀
膨胀和腐蚀相反,其原理是卷积核中间不为0,则整个卷积核区域的值都为1,如下图:

函数原型:
dilate(img,kernel,iterations=1)
代码案例:
img = cv2.imread('./j.png')
kernel = np.ones((7, 7), np.uint8)
dst = cv2.dilate(img, kernel, 1)
cv2.imshow('org', img)
cv2.imshow('dst', dst)
cv2.waitKey(0)

本次采用7x7的卷积核,所以效果会比较明显一些;
六、开运算
本质:先腐蚀,后膨胀;
函数原型:
morphologyEx(img,cv2.MORPH_OPEN,kernel)
代码案例:
img = cv2.imread('./dotj.png')
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (7, 7))
dst = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel)
cv2.imshow('org', img)
cv2.imshow('dst', dst)
cv2.waitKey(0)

从图中可看出,开运算很好的解决了小的噪点,也就是背景噪点去除;
七、闭运算
本质:先膨胀,后腐蚀;
函数原型等同于开运算,其中的类型进行修改即可;
代码案例:
img = cv2.imread('./dotinj.png')
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (7, 7))
dst = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel)
cv2.imshow('org', img)
cv2.imshow('dst', dst)
cv2.waitKey(0)

中间还是有一些噪点没有完全消除,可以调整卷积核大小,将卷积核调大,可以得到更好的效果;
八、形态学梯度
本质:梯度 = 原图 - 腐蚀
函数还是morphologyEx,其中类型为MORPH_GRADIENT;
代码案例:
img = cv2.imread('./j.png')
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
dst = cv2.morphologyEx(img, cv2.MORPH_GRADIENT, kernel)
cv2.imshow('org', img)
cv2.imshow('dst', dst)
cv2.waitKey(0)

可以看出来腐蚀的部分,也相当于提取了边缘;
九、顶帽运算
本质:顶帽 = 原图 - 开运算
函数还是morphologyEx,其中类型为MORPH_TOPHAT;
代码案例:
img = cv2.imread('./tophat.png')
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (19, 19))
dst = cv2.morphologyEx(img, cv2.MORPH_TOPHAT, kernel)
cv2.imshow('org', img)
cv2.imshow('dst', dst)
cv2.waitKey(0)

十、黑帽运算
本质:黑帽 = 原图 - 闭运算
函数还是morphologyEx,其中类型为MORPH_BLACKHAT;
代码案例:
img = cv2.imread('./dotinj.png')
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (7, 7))
dst = cv2.morphologyEx(img, cv2.MORPH_BLACKHAT, kernel)
cv2.imshow('org', img)
cv2.imshow('dst', dst)
cv2.waitKey(0)

总结
开运算:先腐蚀再膨胀,去除大图形外的小图形;
闭运算:先膨胀再腐蚀,去除大图形内的小图形;
梯度:求图形的边缘;
顶帽:原图减开运算,得到大图形外的小图形;
黑帽:原图减闭运算,得到大图形内的小图形;
所有应用的基础都是腐蚀和膨胀,这两者需要掌握清楚,后续也会使用形态学进行实际应用!
【OpenCV学习】(九)目标识别之车辆检测及计数
背景
本篇将具体介绍一个实际应用项目——车辆检测及计数,在交通安全中是很重要的一项计数;当然,本次完全采用OpenCV进行实现,和目前落地的采用深度学习的算法并不相同,但原理是一致的;本篇将从基础开始介绍,一步步完成车辆检测计数的项目;
一、图像轮廓
本质:具有相同颜色或强度的连续点的曲线;
作用:
1、可用于图形分析;
2、应用于物体的识别与检测;
注意点:
1、为了检测的准确性,需要先对图像进行二值化或Canny操作;
2、画轮廓的时候回修改输入的图像,需要先深拷贝原图;
轮廓查找的函数原型:
findContours(img,mode,ApproximationMode…)
-
mode
RETR_EXTERNAL=0,表示只检测外轮廓;
RETR_LIST=1,检测的轮廓不建立等级关系;(常用)
RETR_CCOMP=2,每层最多两级;
RETR_TREE=3,按树形结构存储轮廓,从右到左,从大到小;(常用)
-
ApproximationMode
CHAIN_APPROX_BOBE:保存轮廓上所有的点;
CHAIN_APPROX_SIMPLE:只保存轮廓的角点;
代码实战:
img = cv2.imread('./contours1.jpeg')
# 转变成单通道
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 二值化
ret, binary = cv2.threshold(gray, 150, 255, cv2.THRESH_BINARY)
# 轮廓查找
contours, hierarchy = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
contours输出结果:
(array([[[ 0, 0]],
[[ 0, 435]],
[[345, 435]],
[[345, 0]]], dtype=int32),)
可以看出,我们找最外层轮廓,找出了一个矩形轮廓的四个点;
当然,我们不需要通过画形状来绘制轮廓,可以通过一个内置函数来绘制轮廓;
绘制轮廓函数原型:
drawContours(img,contours,contoursIdx,color,thickness,…)
- contours:表示保存轮廓的数组;
- contoursIdx:表示绘制第几个轮廓,-1表示所有轮廓;
代码案例:
img = cv2.imread('./contours1.jpeg')
img2 = img.copy()
# 转变成单通道
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 二值化
ret, binary = cv2.threshold(gray, 150, 255, cv2.THRESH_BINARY)
# 轮廓查找
contours, hierarchy = cv2.findContours(binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
cv2.drawContours(img, contours, -1, (0, 0, 255), 1)
cv2.drawContours(img2, contours, -1, (0, 0, 255), -1)
cv2.imshow('org', img)
cv2.imshow('org2', img2)
cv2.waitKey(0)

如上图所示,左图是线宽设置为1,右图为线宽设置为-1,也就是填充的效果;
当然,OpenCV还提供了计算轮廓周长和面积的方法;
轮廓面积函数原型:
contourArea(contour)
轮廓周长函数原型:
arcLength(curve,closed)
- curve:表示轮廓;
- closed:是否是闭合的轮廓;
上述两个函数比较简单,在这就不做代码演示了;
二、多边形逼近与凸包
多边形逼近函数原型:
approxPolyDP(curve,epsilon,closed)
- epslion:精度;
凸包的函数原型:
convexHull(points,clockwise,…)
- points:轮廓;
- clockwise:绘制方向,顺时针或逆时针;(不重要)
首先我们看一下基于轮廓查找输出的轮廓形状:

可以看出轮廓点十分密集,接下来看一下基于多变形逼近和凸包的效果:
代码案例:
img = cv2.imread('./hand.png')
img2 = img.copy()
# 转变成单通道
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 二值化
ret, binary = cv2.threshold(gray, 150, 255, cv2.THRESH_BINARY)
# 轮廓查找
contours, hierarchy = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# cv2.drawContours(img, contours, -1, (0, 0, 255), 1)
e = 20
approx = cv2.approxPolyDP(contours[0], e, True) # 多边形逼近
approx = (approx, )
cv2.drawContours(img, approx, 0, (0, 0, 255), 3)
hull = cv2.convexHull(contours[0])
hull = (hull, )
cv2.drawContours(img2, hull, 0, (0, 0, 255), 3) # 凸包
cv2.imshow('org', img)
cv2.imshow('org2', img2)
cv2.waitKey(0)

这里需要注意一点,绘制轮廓的函数对于轮廓的传入需要为元组,需要将得到的数组放到一个元组中!
当然,多边形逼近这里设置的精度为20,所以比较粗糙,设置小一些可以达到更好的效果;
三、外接矩形
外接矩阵分为最大外接矩阵和最小外接矩阵,如下图所示:

最小外接矩阵还有一个功能,就是计算旋转角度,从上图的绿框应该可以很明显看出;
最小外接矩阵函数原型:
minAreaRect(points)
返回值:起始点(x,y)、宽高(w,h)、角度(angle)
最大外接矩形函数原型:
boundingRect(array)
返回值:起始点(x,y)、宽高(w,h)
代码案例:
img = cv2.imread('./hello.jpeg')
img2 = img.copy()
# 转变成单通道
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 二值化
ret, binary = cv2.threshold(gray, 150, 255, cv2.THRESH_BINARY)
# 轮廓查找
contours, hierarchy = cv2.findContours(binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# 获取最小外接矩形
r = cv2.minAreaRect(contours[1])
box = cv2.boxPoints(r) # 提取其中的点
box = np.int0(box) # 将浮点型转换为整型
cv2.drawContours(img, (box, ), 0, (0, 0, 255), 2)
# 获取最大外接矩形
x, y, w, h = cv2.boundingRect(contours[1])
cv2.rectangle(img2, (x, y), (x+w, y+h), (0, 0, 255), 2)
cv2.imshow('org', img)
cv2.imshow('org2', img2)
cv2.waitKey(0)

四、车辆统计实战
涉及的知识点:
- 窗口展示
- 图像、视频的加载
- 基本图形的绘制
- 基本图像运算与处理
- 形态学
- 轮廓查找
实现流程:
加载视频 —— 通过形态学识别车辆 —— 对车辆进行统计 —— 显示统计信息
1、加载视频
这里就是一个简单加载视频的实现:
cap = cv2.VideoCapture('video.mp4')
while True:
ret, frame = cap.read()
if(ret == True):
cv2.imshow('video', frame)
key = cv2.waitKey(1)
if(key == 27): # Esc退出
break
cap.release()
cv2.destroyAllWindows()
2、去除背景
函数原型:
createBackgroundSubtractorMOG()
- history:缓冲,表示多少毫秒,可不指定参数,用默认的即可;
具体实现原理比较复杂,用到了一些视频序列关联信息,把像素值不变的认为是背景;
注意:在opencv中已经不支持该函数,而是用createBackgroundSubtractorMOG2()替代;如果需要使用可以安装opencv_contrib模块,在其中的bgsegm中保留了该函数;
代码实现:
cap = cv2.VideoCapture('video.mp4')
bgsubmog = cv2.bgsegm.createBackgroundSubtractorMOG()
while True:
ret, frame = cap.read()
if(ret == True):
# 灰度处理
cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 高斯去噪
blur = cv2.GaussianBlur(frame, (3, 3), 5)
mask = bgsubmog.apply(blur)
cv2.imshow('video', mask)
key = cv2.waitKey(1)
if(key == 27): # Esc退出
break
cap.release()
cv2.destroyAllWindows()

这里尽量采用旧版的MOG函数,新版的MOG2函数比较精细,会将树叶等信息输出,去除效果没那么好;
3、形态处理
这里主要是为了处理一些小的噪声点以及目标中的黑色块;
代码实现:
cap = cv2.VideoCapture('video.mp4')
bgsubmog = cv2.bgsegm.createBackgroundSubtractorMOG()
# 形态学kernel
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
while True:
ret, frame = cap.read()
if(ret == True):
# 灰度处理
cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 高斯去噪
blur = cv2.GaussianBlur(frame, (3, 3), 5)
mask = bgsubmog.apply(blur)
# 腐蚀
erode = cv2.erode(mask, kernel)
# 膨胀
dilate = cv2.dilate(erode, kernel, 3)
# 闭操作
close = cv2.morphologyEx(dilate, cv2.MORPH_CLOSE, kernel)
close = cv2.morphologyEx(close, cv2.MORPH_CLOSE, kernel)
contours, h = cv2.findContours(close, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE,)
for (i, c) in enumerate(contours):
(x, y, w, h) = cv2.boundingRect(c)
cv2.rectangle(frame, (x, y), (x+w, y+h), (0,0,255), 2)
cv2.imshow('video', frame)
key = cv2.waitKey(1)
if(key == 27): # Esc退出
break
cap.release()
cv2.destroyAllWindows()
从图中效果来看,还是会有很多小的检测框,接下来就是处理重合检测框以及去掉一些多余的检测框,类似于NMS去重,当然原理还不太一样;
4、车辆统计
首先需要过滤一些小的矩形,已经检测框的长和宽,设定一些阈值即可;
代码实现:
cap = cv2.VideoCapture('video.mp4')
bgsubmog = cv2.bgsegm.createBackgroundSubtractorMOG()
# 保存车辆中心点信息
cars = []
# 统计车的数量
car_n = 0
# 形态学kernel
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
while True:
ret, frame = cap.read()
if(ret == True):
# 灰度处理
cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 高斯去噪
blur = cv2.GaussianBlur(frame, (3, 3), 5)
mask = bgsubmog.apply(blur)
# 腐蚀
erode = cv2.erode(mask, kernel)
# 膨胀
dilate = cv2.dilate(erode, kernel, 3)
# 闭操作
close = cv2.morphologyEx(dilate, cv2.MORPH_CLOSE, kernel)
close = cv2.morphologyEx(close, cv2.MORPH_CLOSE, kernel)
contours, h = cv2.findContours(close, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE,)
# 画一条线
cv2.line(frame, (10, 550), (1200, 550), (0, 255, 255), 3)
for (i, c) in enumerate(contours):
(x, y, w, h) = cv2.boundingRect(c)
# 过滤小的检测框
isshow = (w >= 90) and (h >= 90)
if(not isshow):
continue
# 保存中心点信息
cv2.rectangle(frame, (x, y), (x+w, y+h), (0,0,255), 2)
centre_p = (x + int(w/2), y + int(h/2))
cars.append(centre_p)
cv2.circle(frame, (centre_p), 5, (0,0,255), -1)
for (x, y) in cars:
if(593 < y < 607):
car_n += 1
cars.remove((x, y))
cv2.putText(frame, "Cars Count:" + str(car_n), (500, 60), cv2.FONT_HERSHEY_SIMPLEX, 2, (0, 0, 255), 5)
cv2.imshow('video', frame)
key = cv2.waitKey(1)
if(key == 27): # Esc退出
break
cap.release()
cv2.destroyAllWindows()
简单的效果已经出来了,对于大部分车辆都能够很好的检测并且计数了;
存在问题:
由于是用中心点与线的距离来判断,车速过慢可能会在两帧内重复计数,车速过快可能会计数不到;这就是传统算法存在的一个问题,基于深度学习的方法可以很好解决这些问题,可关注目标跟踪实战的那一篇文章!
总结
项目到这里就介绍了,通过该项目主要是将所学的知识点进行串联,重点在于形态学的运用!当然这个效果可能达不到实际应用的标准,这也是传统算法的一个弊端;有能力的可以采用深度学习的方法进行实现,也可以关注我后续的目标跟踪是实现车辆计数,效果会远比这个好。
【OpenCV学习】(十)特征点检测与匹配
背景
提取图像的特征点是图像领域中的关键任务,不管在传统还是在深度学习的领域中,特征代表着图像的信息,对于分类、检测任务都是至关重要的;
特征点应用的一些场景:
- 图像搜索:以图搜图(电商、教育领域)
- 图像拼接:全景拍摄(关联图像拼接)
- 拼图游戏:游戏领域
一、Harris角点
哈里斯角点检测主要有以下三种情况:

- 光滑区域:无论向哪个方向移动,衡量系数不变;
- 边缘区域:垂直边缘移动时,衡量系数变化强烈;
- 角点区域:不管往哪个方向移动,衡量系数变化强烈;
函数原型:
cornerHarris(img,blockSize,ksize,k)
- blockSize:检测窗口大小;
- k:权重系数,一般取0.02~0.04之间;
代码案例:
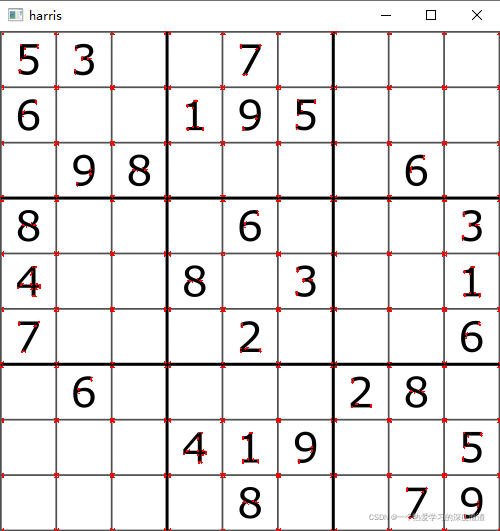
img = cv2.imread('chess.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
dst = cv2.cornerHarris(gray, 2, 3, 0.04)
img[dst > 0.01*dst.max()] = (0, 0, 255)
cv2.imshow('harris', img)
cv2.waitKey(0)
二、Shi-Tomasi角点检测
说明:是Harris角点检测的改进,在Harris中需要知道k这个经验值,而在Shi-Tomasi不需要;
函数原型:
goodFeaturesToTrack(img,…)
-
maxCorners:角点的最大数量,值为0表示所有;
-
qualityLevel:角点的质量,一般在0.01~0.1之间(低于的过滤掉);
-
minDistance:角点之间最小欧式距离,忽略小于此距离的点;
-
mask:感兴趣区域;
-
useHarrisDetector:是否使用Harris算法(默认为false)
代码案例:
img = cv2.imread('chess.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
dst = cv2.goodFeaturesToTrack(gray, 1000, 0.01, 10)
dst = np.int0(dst) # 实际上也是np.int64
for i in dst:
x, y = i.ravel() # 数组降维成一维数组(inplace的方式)
cv2.circle(img, (x, y), 3, (0, 0, 255), -1)
cv2.imshow('harris', img)
cv2.waitKey(0)
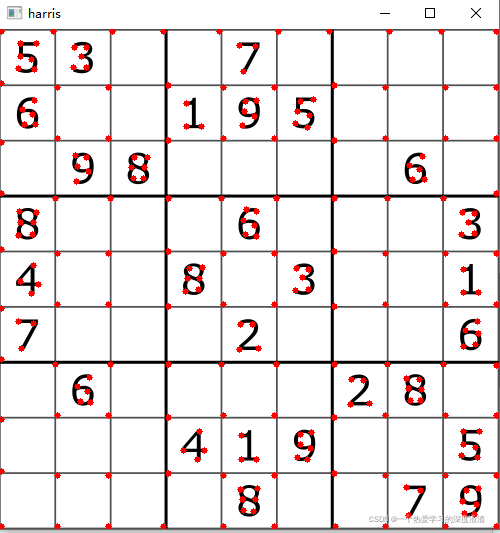
本质上和Harris角点检测相同,效果会好一些,角点数量会多一些;
三、SIFT关键点
中文简译:与缩放无关的特征转换;
说明:Harris角点检测具有旋转不变性,也就是旋转图像并不会影响检测效果;但其并不具备缩放不变性,缩放大小会影响角点检测的效果;SIFT具备缩放不变性的性质;
实现步骤:
创建SIFT对象 —— 进行检测(sift.detect) —— 绘制关键点(drawKeypoints)
代码案例:
img = cv2.imread('chess.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
sift = cv2.xfeatures2d.SIFT_create()
kp = sift.detect(gray, None) # 第二个参数为mask区域
cv2.drawKeypoints(gray, kp, img)
cv2.imshow('sift', img)
cv2.waitKey(0)
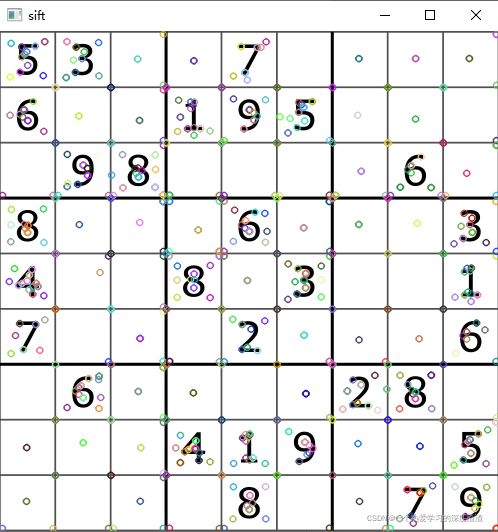
四、SIFT描述子
首先需要说明,关键点和描述子是两个概念;
关键点:位置、大小和方向;
关键点描述子:记录了关键点周围对其有贡献的像素点的一组向量值,其不受仿射变换,光照变换等影响;描述子的作用就是用于特征匹配;
同时计算关键点和描述子的函数(主要使用):
detectAndCompute(img,…)
代码案例:
img = cv2.imread('chess.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
sift = cv2.xfeatures2d.SIFT_create()
kp, dst = sift.detectAndCompute(gray, None) # 第二个参数为mask区域
得到的dst即为描述子的信息;
五、SURF
中译:加速的鲁棒性特征检测;
说明:SIFT最大的缺点是速度慢,因此才会有SURF(速度快);
实现步骤与SIFT一致,代码如下:
surf = cv2.xfeatures2d.SURF_create()
kp, dst = surf.detectAndCompute(gray, None) # 第二个参数为mask区域
cv2.drawKeypoints(gray, kp, img)
由于安装的opencv-contrib版本过高(有版权问题),已经不支持该功能了,在此就不作展示了;
六、ORB
说明:最大的优势就是做到实时检测,缺点就是缺失了很多信息(准确性下降);
主要是两个技术的结合:FAST(特征点实时检测)+ BRIEE(快速描述子建立,降低特征匹配时间)
使用步骤与之前的SIFT一致,代码如下:
img = cv2.imread('chess.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
orb = cv2.ORB_create()
kp, dst = orb.detectAndCompute(gray, None) # 第二个参数为mask区域
cv2.drawKeypoints(gray, kp, img)
cv2.imshow('orb', img)
cv2.waitKey(0)

可以看出,相比于SIFT以及SURF关键点变少了,但是其速度有了很大提升;
七、暴力特征匹配(BF)
匹配原理:类似于穷举匹配机制,使用第一组中每个特征的描述子与第二组中的进行匹配,计算相似度,返回最接近的匹配项;
实现步骤:
- 创建匹配器:BFMatcher(normType,crossCheck)
- 进行特征匹配:bf.match(des1,des2)
- 绘制匹配点:cv2.drawMatches(img1,kp1,img2,kp2)
代码案例:
img1 = cv2.imread('opencv_search.png')
img2 = cv2.imread('opencv_orig.png')
g1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
g2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
sift = cv2.SIFT_create()
kp1, dst1 = sift.detectAndCompute(g1, None) # 第二个参数为mask区域
kp2, dst2 = sift.detectAndCompute(g2, None) # 第二个参数为mask区域
bf = cv2.BFMatcher_create(cv2.NORM_L1)
match = bf.match(dst1, dst2)
img3 = cv2.drawMatches(img1, kp1, img2, kp2, match, None)
cv2.imshow('result', img3)
cv2.waitKey(0)

从上图可看出,匹配的效果还是不错的,只有一个特征点匹配错误;
八、FLANN特征匹配
优点:在进行批量特征匹配时,FLANN速度更快;
缺点:由于使用的时邻近近似值,所有精度较差;
实现步骤与暴力匹配法一致,代码如下:
img1 = cv2.imread('opencv_search.png')
img2 = cv2.imread('opencv_orig.png')
g1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
g2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
sift = cv2.SIFT_create()
kp1, dst1 = sift.detectAndCompute(g1, None) # 第二个参数为mask区域
kp2, dst2 = sift.detectAndCompute(g2, None) # 第二个参数为mask区域
index_params = dict(algorithm = 1, trees = 5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
matchs = flann.knnMatch(dst1, dst2, k=2)
good = []
for i, (m, n) in enumerate(matchs):
if m.distance < 0.7 * n.distance:
good.append(m)
img3 = cv2.drawMatchesKnn(img1, kp1, img2, kp2, [good], None)
cv2.imshow('result', img3)
cv2.waitKey(0)

上图可以看出,匹配的特征点数量相比暴力匹配明显变少了,但速度会快很多;
九、图像查找
实现原理:特征匹配 + 单应性矩阵;
单应性矩阵原理介绍:
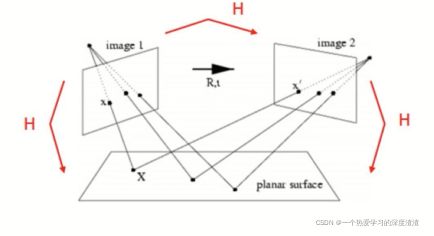
上图中表示从两个不同角度对原图的拍摄,其中H为单应性矩阵,可通过该矩阵将图像进行转换;
下面使用两个函数实现图像查找的功能:
findHomography():获得单应性矩阵;
perspectivveTransform():仿射变换函数;
代码实现如下图:
img1 = cv2.imread('opencv_search.png')
img2 = cv2.imread('opencv_orig.png')
g1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
g2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
sift = cv2.SIFT_create()
kp1, dst1 = sift.detectAndCompute(g1, None) # 第二个参数为mask区域
kp2, dst2 = sift.detectAndCompute(g2, None) # 第二个参数为mask区域
index_params = dict(algorithm = 1, trees = 5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
matchs = flann.knnMatch(dst1, dst2, k=2)
good = []
for i, (m, n) in enumerate(matchs):
if m.distance < 0.7 * n.distance:
good.append(m)
if len(good) >= 4:
# 获得源和目标点的数组
srcPts = np.float32([kp1[m.queryIdx].pt for m in good]).reshape(-1, 1, 2)
dstPts = np.float32([kp2[m.trainIdx].pt for m in good]).reshape(-1, 1, 2)
# 获得单应性矩阵H
H, _ = cv2.findHomography(srcPts, dstPts, cv2.RANSAC, 5.0)
h, w = img1.shape[:2]
pts = np.float32([[0,0], [0, h-1], [w-1, h-1], [w-1, 0]]).reshape(-1, 1, 2)
# 进行放射变换
dst = cv2.perspectiveTransform(pts, H)
# 绘制查找到的区域
cv2.polylines(img2, [np.int32(dst)], True, (0,0,255))
else:
print('good must more then 4.')
exit()
img3 = cv2.drawMatchesKnn(img1, kp1, img2, kp2, [good], None)
cv2.imshow('result', img3)
cv2.waitKey(0)

总结
本篇主要介绍了特征点检测和匹配,其中重要的部分时SIFT算法以及FLANN算法;通过所学的知识,可以简单实现一个图像查找的功能,也就是找子图的功能。甚至可以目标识别的效果;当然这里需要的是完全一致的,不同于深度学习中的目标识别任务。
【OpenCV学习】(十一)图像拼接实战
背景
图像拼接可以应用到手机中的全景拍摄,也就是将多张图片根据关联信息拼成一张图片;
实现步骤
1、读文件并缩放图片大小;
2、根据特征点和计算描述子,得到单应性矩阵;
3、根据单应性矩阵对图像进行变换,然后平移;
4、图像拼接并输出拼接后结果图;
一、读取文件
第一步实现读取两张图片并缩放到相同尺寸;
代码如下:
img1 = cv2.imread('map1.png')
img2 = cv2.imread('map2.png')
img1 = cv2.resize(img1, (640, 480))
img2 = cv2.resize(img2, (640, 480))
input = np.hstack((img1, img2))
cv2.imshow('input', input)
cv2.waitKey(0)

上图为我们需要拼接的两张图的展示,可以看出其还具有一定的旋转变换,之后的图像转换必定包含旋转的操作;
二、单应性矩阵计算
主要分为以下几个步骤:
1、创建特征转换对象;
2、通过特征转换对象获得特征点和描述子;
3、创建特征匹配器;
4、进行特征匹配;
5、过滤特征,找出有效的特征匹配点;
6、单应性矩阵计算
实现代码:
def get_homo(img1, img2):
# 1实现
sift = cv2.xfeatures2d.SIFT_create()
# 2实现
k1, p1 = sift.detectAndCompute(img1, None)
k2, p2 = sift.detectAndCompute(img2, None)
# 3实现
bf = cv2.BFMatcher()
# 4实现
matches = bf.knnMatch(p1, p2, k=2)
# 5实现
good = []
for m1, m2 in matches:
if m1.distance < 0.8 * m2.distance:
good.append(m1)
# 6实现
if len(good) > 8:
img1_pts = []
img2_pts = []
for m in good:
img1_pts.append(k1[m.queryIdx].pt)
img2_pts.append(k2[m.trainIdx].pt)
img1_pts = np.float32(img1_pts).reshape(-1, 1, 2)
img2_pts = np.float32(img2_pts).reshape(-1, 1, 2)
H, mask = cv2.findHomography(img1_pts, img2_pts, cv2.RANSAC, 5.0)
return H
else:
print('piints is not enough 8!')
exit()
三、图像拼接
实现步骤:
1、获得图像的四个角点;
2、根据单应性矩阵变换图片;
3、创建一张大图,拼接图像;
4、输出结果
实现代码:
def stitch_img(img1, img2, H):
# 1实现
h1, w1 = img1.shape[:2]
h2, w2 = img2.shape[:2]
img1_point = np.float32([[0,0], [0,h1], [w1,h1], [w1,0]]).reshape(-1, 1, 2)
img2_point = np.float32([[0,0], [0,h2], [w2,h2], [w2,0]]).reshape(-1, 1, 2)
# 2实现
img1_trans = cv2.perspectiveTransform(img1_point, H)
# 将img1变换后的角点与img2原来的角点做拼接
result_point = np.concatenate((img2_point, img1_trans), axis=0)
# 获得拼接后图像x,y的最小值
[x_min, y_min] = np.int32(result_point.min(axis=0).ravel()-0.5)
# 获得拼接后图像x,y的最大值
[x_max, y_max] = np.int32(result_point.max(axis=0).ravel()+0.5)
# 平移距离
trans_dist = [-x_min, -y_min]
# 构建一个齐次平移矩阵
trans_array = np.array([[1, 0, trans_dist[0]],
[0, 1, trans_dist[1]],
[0, 0, 1]])
# 平移和单应性变换
res_img = cv2.warpPerspective(img1, trans_array.dot(H), (x_max-x_min, y_max-y_min))
# 3实现
res_img[trans_dist[1]:trans_dist[1]+h2,
trans_dist[0]:trans_dist[0]+w2] = img2
return res_img
H = get_homo(img1, img2)
res_img = stitch_img(img1, img2, H)
# 4实现
cv2.imshow('result', res_img)
cv2.waitKey(0)

最终结果图如上图所示,还有待优化点如下:
- 边缘部分有色差,可以根据取平均值消除;
- 黑色区域可进行裁剪并用对应颜色填充;
优化部分难度不大,有兴趣的可以实现一下;
总结
图像拼接作为一个实用性技术经常出现在我们的生活中,特别是全景拍摄以及图像内容拼接;当然,基于传统算法的图像拼接还是会有一些缺陷(速度和效果上),感兴趣的可以了解下基于深度学习的图像拼接算法。
【OpenCV学习】(十二)图像分割与修复
背景
图像分割本质就是将前景目标从背景中分离出来。在当前的实际项目中,应用传统分割的并不多,大多是采用深度学习的方法以达到更好的效果;当然,了解传统的方法对于分割的整体认知具有很大帮助,本篇将介绍些传统分割的一些算法;
一、分水岭法
原理图如下:

利用二值图像的梯度关系,设置一定边界,给定不同颜色实现分割;
实现步骤:
标记背景 —— 标记前景 —— 标记未知区域(背景减前景) —— 进行分割
函数原型:
watershed(img,masker):分水岭算法,其中masker表示背景、前景和未知区域;
distanceTransform(img,distanceType,maskSize):矩离变化,求非零值到最近的零值的距离;
connectedComponents(img,connectivity,…):求连通域;
代码实现:
img = cv2.imread('water_coins.jpeg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 加入cv2.THRESH_OTSU表示自适应阈值(实现更好的效果)
ret, thresh = cv2.threshold(gray, 100, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
# 开运算(去噪点)
kernel = np.ones((3,3), np.int8)
open1 = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, kernel, iterations = 2)
#膨胀
beijing = cv2.dilate(open1, kernel, iterations = 1)
# 获取前景
tmp = cv2.distanceTransform(open1, cv2.DIST_L2, 5)
ret, qianjing = cv2.threshold(tmp, 0.7*tmp.max(), 255, cv2.THRESH_BINARY)
# 获取未知区域
beijingj = np.uint8(beijing)
qianjing = np.uint8(qianjing)
unknow = cv2.subtract(beijing, qianjing)
# 创建连通域
ret, masker = cv2.connectedComponents(qianjing)
masker = masker + 1
masker[unknow==255] = 0
# 进行图像分割
result = cv2.watershed(img, masker)
img[result == -1] = [0, 0, 255]
cv2.imshow('result', img)
cv2.waitKey(0)

二、GrabCut法
原理:通过交互的方式获得前景物体;
1、用户指定前景的大体区域,剩下的为背景区域;
2、用户可以明确指定某些地方为前景或背景;
3、采用分段迭代的方法分析前景物体形成模型树;
4、根据权重决定某个像素是前景还是背景;
函数原型:
grabCut(img,mask,rect,bgdModel,fbgModel,5,mode)
- mask:表示生成的掩码,函数输出的值,其中0表示背景、1表示前景、2表示可能背景、3表示可能前景;
代码如下:
class App:
flag_rect = False
rect=(0, 0, 0, 0)
startX = 0
startY = 0
def onmouse(self, event, x, y, flags, param):
if event == cv2.EVENT_LBUTTONDOWN:
self.flag_rect = True
self.startX = x
self.startY = y
print("LBUTTIONDOWN")
elif event == cv2.EVENT_LBUTTONUP:
self.flag_rect = False
cv2.rectangle(self.img,
(self.startX, self.startY),
(x, y),
(0, 0, 255),
3)
self.rect = (min(self.startX, x), min(self.startY, y),
abs(self.startX - x),
abs(self.startY -y))
print("LBUTTIONUP")
elif event == cv2.EVENT_MOUSEMOVE:
if self.flag_rect == True:
self.img = self.img2.copy()
cv2.rectangle(self.img,
(self.startX, self.startY),
(x, y),
(255, 0, 0),
3)
print("MOUSEMOVE")
print("onmouse")
def run(self):
print("run...")
cv2.namedWindow('input')
cv2.setMouseCallback('input', self.onmouse)
self.img = cv2.imread('./lena.png')
self.img2 = self.img.copy()
self.mask = np.zeros(self.img.shape[:2], dtype=np.uint8)
self.output = np.zeros(self.img.shape, np.uint8)
while(1):
cv2.imshow('input', self.img)
cv2.imshow('output', self.output)
k = cv2.waitKey(100)
if k == 27:
break
if k == ord('g'):
bgdmodel = np.zeros((1, 65), np.float64)
fgdmodel = np.zeros((1, 65), np.float64)
cv2.grabCut(self.img2, self.mask, self.rect,
bgdmodel, fgdmodel,
1,
cv2.GC_INIT_WITH_RECT)
# 注意np.where的用法可以用来筛选前景
mask2 = np.where((self.mask==1)|(self.mask==3), 255, 0).astype('uint8')
self.output = cv2.bitwise_and(self.img2, self.img2, mask=mask2)
由于效果并不是特别明显,并且运行时耗时会比较长,在这里就不展示了;
注意:np.where的用法需要掌握,可以将一个矩阵中选定的值与未选定的值做二值化的处理;
三、MeanShift法
实现原理:
- 并不是用来进行图像分割的,而是在色彩层面的平滑滤波;
- 中和色彩分布相近的颜色,平滑色彩细节,腐蚀掉面积较小的颜色区域;
- 以图像上任意点P为圆心,半径为sp,色彩幅值为sr进行不断的迭代;
函数原型:
pyrMeanShiftFiltering(img,sp,sr,…)
代码实现:
img = cv2.imread('flower.png')
result = cv2.pyrMeanShiftFiltering(img, 20, 30)
cv2.imshow('img', img)
cv2.imshow('result', result)
cv2.waitKey(0)

通过该函数可以实现色彩的平滑处理,做特效也是不错的(有种卡通化的效果),虽然该函数并不能直接做图像分割,但处理后的图像可以通过canny算法进行边缘检测;
Canny代码:
img = cv2.imread('key.png')
result = cv2.pyrMeanShiftFiltering(img, 20, 30)
img_canny = cv2.Canny(result, 150, 300)
contours, _ = cv2.findContours(img_canny, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cv2.drawContours(img, contours, -1, (0, 0, 255), 2)
cv2.imshow('img', img)
cv2.imshow('result', result)
cv2.imshow('canny', img_canny)
cv2.waitKey(0)

四、MOG前景背景分离法
首先需要了解视频的一些原理:
- 视频是一组连续帧组成的(一帧也可以看作一副图像)
- 帧与帧之间关系密切(又称为GOP)
- 在GOP中,背景几乎是不变的
主要有以下几种方法:
1、MOG去背景
原理:混合高斯模型为基础的前景、背景分割法;
函数原型:
createBackgroundSubtractorMOG(其中的默认值就不做讲解了)
代码实战:
cap = cv2.VideoCapture('./vtest.avi')
mog = cv2.bgsegm.createBackgroundSubtractorMOG()
while(True):
ret, frame = cap.read()
mask = mog.apply(frame)
cv2.imshow('img', mask)
k = cv2.waitKey(10)
if k == 27:
break
cap.release()
cv2.destroyAllWindows()

五、拓展方法
1、MOG2
说明:与MOG算法类似,但对于亮度产生的阴影有更好的识别效果,噪点更多;
函数原型:createBackgroundSubtractorMOG2(默认参数不作介绍)
效果展示:

2、GMG
说明:静态背景图像估计和每个像素的贝叶斯分割抗噪性更强;
函数原型:createBackgroundSubtractorGMG()
效果展示:

总结:GMG开始会不显示一段时间,这是由于初始参考帧的数量和过大;对比业界的效果来看,这些传统方法的效果并不好,特别是对比深度学习的算法;但很多原理值得我们取思考借鉴,模型只是给出我们问题的优解,如果能将传统算法结合深度学习算法,那是否能在提速的同时,也达到一个可观的效果,这是我思考的一个点,欢迎大家发表自己的意见;
六、图像修复
说明:我们的图像往往会有一些马赛克的存在,特别是一些老照片会有不必要的图案,图像修复就是用于解决这类问题,并不等同于超清化;
函数原型:
inpaint(img,mask,inpaintRadius,两种方式:INPAINT_NS、INPAINT_TELEA)
代码案例:
img = cv2.imread('inpaint.png')
mask = cv2.imread('inpaint_mask.png', 0)
result = cv2.inpaint(img, mask, 5, cv2.INPAINT_TELEA)
cv2.imshow('img', img)
cv2.imshow('result', result)
cv2.waitKey()

总结:从结果来看,效果相当不错,但前提我们需要知道需要修复的部分,所以应用的场景也会比较局限;
总结
简单介绍了一些传统的一些图像分割算法,并没有涉及原理,感兴趣的可以自行了解;当然,现在业界的分割算法都采用深度学习的方式了,并且也有了很好的效果和落地应用,后续也会开对应的专栏,科普一下深度学习中分割算法的发展历史,其主要为模型的迭代了,感兴趣可以先了解下编解码这个结构;
【OpenCV学习】(十三)机器学习
背景
OpenCV中也提供了一些机器学习的方法,例如DNN;本篇将简单介绍一下机器学习的一些应用,对比传统和前沿的算法,能从其中看出优劣;
一、人脸识别
主要有以下两种实现方法:
1、哈尔(Haar)级联法:专门解决人脸识别而推出的传统算法;
实现步骤:
- 创建Haar级联器;
- 导入图片并将其灰度化;
- 调用函数接口进行人脸识别;
函数原型:
detectMultiScale(img,scaleFactor,minNeighbors)
-
scaleFactor:缩放尺寸;
-
minNeighbors:最小像素值;
代码案例:
# 创建Haar级联器
facer = cv2.CascadeClassifier('./haarcascades/haarcascade_frontalface_default.xml')
# 导入人脸图片并灰度化
img = cv2.imread('p3.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 调用接口
faces = facer.detectMultiScale(gray, 1.1, 5)
for (x,y,w,h) in faces:
cv2.rectangle(img, (x,y), (x+w, y+h), (0,0,255), 2)
cv2.imshow('img', img)
cv2.waitKey()

结论:Haar级联法对于完整脸部的检测效果还是不错的,但对于不完整脸部识别效果差,这可能也是传统算法的一个缺陷所在,泛化能力比较差;
拓展:Haar级联器还可以对脸部中细节特征进行识别
代码如下:
# 创建Haar级联器
facer = cv2.CascadeClassifier('./haarcascades/haarcascade_frontalface_default.xml')
eyer = cv2.CascadeClassifier('./haarcascades/haarcascade_eye.xml')
# 导入人脸图片并灰度化
img = cv2.imread('p3.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 调用接口
faces = facer.detectMultiScale(gray, 1.1, 5)
i = 0
for (x,y,w,h) in faces:
cv2.rectangle(img, (x,y), (x+w, y+h), (0,0,255), 2)
ROI_img = img[y:y+h, x:x+w]
eyes = eyer.detectMultiScale(ROI_img, 1.1, 5)
for (x,y,w,h) in eyes:
cv2.rectangle(ROI_img, (x,y), (x+w, y+h), (0,255,0), 2)
i += 1
name = 'img'+str(i)
cv2.imshow(name, ROI_img)
cv2.waitKey()
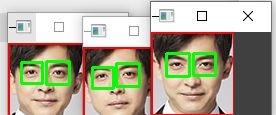
总结:Haar级联器提供了多种脸部属性的识别,眼睛鼻子嘴巴都可以,但效果不一定那么准确;
二、车牌识别
结构:Haar+Tesseract车牌识别;
说明:Haar级联器仅用于定位车牌的位置,Tesseract用于提取其中的内容;
实现步骤:
1、Haar级联器定位车牌位置;
2、车牌预处理操作(二值化、形态学、滤波去噪、缩放);
3、调用Tesseract进行文字识别;
注意:这里需要预先安装Tesseract;
代码案例:
import pytesseract
# 创建Haar级联器
carer = cv2.CascadeClassifier('./haarcascades/haarcascade_russian_plate_number.xml')
# 导入人脸图片并灰度化
img = cv2.imread('chinacar.jpeg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 调用接口
cars = carer.detectMultiScale(gray, 1.1, 3)
for (x,y,w,h) in cars:
cv2.rectangle(img, (x,y), (x+w, y+h), (0,0,255), 2)
# 提取ROI
roi = gray[y:y+h, x:x+w]
# 二值化
ret, roi_bin = cv2.threshold(roi, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# 文字识别
pytesseract.pytesseract.tesseract_cmd = r"D:\Tesseract_OCR\tesseract.exe"
text = pytesseract.image_to_string(roi, lang='chi_sim+eng',config='--psm 8 --oem 3')
print(text)
cv2.putText(img, text, (20,100), cv2.FONT_HERSHEY_SIMPLEX, 2, (0,0,255), 3)
cv2.imshow('img', img)
cv2.waitKey()

结论:车牌的位置检测比较准确,但Tesseract的识别并不那么准确,可能用ORC识别会准确一些;当然识别的准确率也和图像处理后比较模糊有关,做一些处理能够提升文字的识别率;
三、DNN图像分类
DNN为深度神经网络,并且是全连接的形式;
注意:OpenCV能够使用DNN模型,但并不能训练;
DNN使用步骤:
- 读取模型,得到网络结构;
- 读取数据(图片或视频)
- 将图片转成张量,送入网络;
- 模型输出结果;
函数原型:
导入模型:readNet(model,[config])
图像转张量:blobFromImage(image,scalefactor,size,mean,swapRB,crop)
送入网络:net.setInput(blob)
模型推理:net.forward()
代码案例:
# 导入模型
config = "./model/bvlc_googlenet.prototxt"
model = "./model/bvlc_googlenet.caffemodel"
net = dnn.readNetFromCaffe(config, model)
# 加载图片,转成张量
img = cv2.imread('./smallcat.jpeg')
blob = dnn.blobFromImage(img, 1.0, (224,224), (104,117,123))
# 模型推理
net.setInput(blob)
r = net.forward()
idxs = np.argsort(r[0])[::-1][:5]
# 分类结果展示
path = './model/synset_words.txt'
with open(path, 'rt') as f:
classes = [x[x.find(" ")+1:]for x in f]
for (i, idx) in enumerate(idxs):
# 将结果展示在图像上
if i == 0:
text = "Label: {}, {:.2f}%".format(classes[idx],
r[0][idx] * 100)
cv2.putText(img, text, (5, 25), cv2.FONT_HERSHEY_SIMPLEX,
0.7, (0, 0, 255), 2)
# 显示图像
cv2.imshow("Image", img)
cv2.waitKey(0)

结论:实际上有了模型之后,推理的步骤并不复杂,难点在于前处理与后处理;往往图像的处理上的错误,或者是对结果的处理问题,会导致结果不符,这是需要特别注意的;
总结
至此OpenCV的学习告一段落,后续需要在实际应用中多使用才能够更加熟练,现在多数场景的应用都是基于C++的OpenCV,相对来说各种依赖以及环境的配置会复杂一些,但其功能和Python版本是一致的。