知识图谱 数据模型和查询语言
文章目录
-
- 1. RDF图数据模型
-
- 1.1 资源描述框架RDF
- 1.2 RDF图数据模型
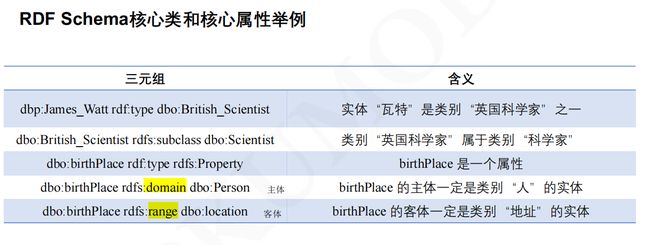
- 1.3 RDF Schema(简称RDFS)
- 2.SPARQL查询语言
-
- 2.1 SPARQL 语法
- 2.2 SPARQL 命名空间
- 2.3 SPARQL 数据集
- 2.4 SPARAL 查询语言
- 2.5 图模式定义
- 2.6 SPAQAL 组图模式 联合图模式
- 2.7 SPAQAL 符号优先级
- 2.8 SPAQAL 结果修饰
- 2.9 SPAQAL语义
- 2.10 图模式的匹配
- 2.11 SPARQL 新特性
- 3.属性图模型和Cypher查询语言
-
- 3.1 属性图模型
- 3.2 Cypher查询语言
- 4.TinkerPop图计算框架与Gremlin图遍历语⾔及遍历机
-
- 4.1 TinkerPop图计算框架
- 4.2 Gremlin 图遍历语言与图遍历机
- 4.3 Gremilin语法
-
- Gremlin 查询示例
- Gremlin 语法特性
-
- 路径
- 迭代
- 转换
- 排序
- 逻辑
- 统计
- 分支
1. RDF图数据模型
1.1 资源描述框架RDF
-
RDF是知识图谱数据的事实标准
-
RDF是由W3C组织提出的一种
-
描述资源概念模型的语言
-
RDF是语义网的一个基石
-
语义网的目标是网络上的资源是“机器可理解”(Machine understandable)
1.2 RDF图数据模型
1.3 RDF Schema(简称RDFS)

2.SPARQL查询语言
SPARQL
• 是W3C 制定的RDF 图数据的标准查询语言;
• SPARQL 从语法上借鉴了SQL,同样属于声明式查询语言;
• SPARQL 提供了强大的基于图匹配的查询功能,也包括可选匹配(
OPTIONAL)、对结果的排序(ORDER BY)、去重(DISTINCT)和限定(
LIMIT)及值约束条件(FILTER) 等多种操作符,以及直接回答YES/NO 的ASK
查询等其他形式的查询。同时,SPARQL 语句也具备增、删、改的功能;
• 具体语法细节见SPARQL官网:https://www.w3.org/TR/rdf-sparql-query/
2.1 SPARQL 语法
2.2 SPARQL 命名空间
- PREFIX 关键字是把前缀标签和IRI连接起来,一个有前缀的名称是由一个带前
缀的标签和一个本地的名称所组成中,其中由冒号“:”来分开
- 常用的命名空间前缀与IRI 的关系之前已经显示了
2.3 SPARQL 数据集
-
一个SPARQL 查询可以在包含一个或者多个RDF 数据图的RDF数据集上执行
-
指定使用默认图用关键字FROM,而指定使用某个命名图用关键字FROM NAMED
2.4 SPARAL 查询语言
SPARQL的六种查询方式
-
选择查询(SELECT 查询),用来从RDF 数据中选择出满足条件的值来构造⼀张关系表并返回 -
构造查询(CONSTRUCT 查询),用来从RDF 数据中选择出满足条件的值并⽤这些值按条件构造⼀个新的RDF 数据; -
询问查询(ASK 查询),⽤来从RDF 数据中判定出RDF 数据中是否有满⾜条件的值并返True/False; -
描述查询(DESCRIBE 查询),⽤来从RDF 数据中选择出⼀个RDF 数据图来描述某些特点的资源; -
插⼊语句(INSERT 语句),向RDF 数据中插⼊⼀个或者多个三元组 -
删除语句(DELETE 语句),从RDF 数据中删除⼀个或者多个三元组。


其中 V表示变量,J表示资源标识符集合,B表示空白节点集合,L表示字面值
"."表示AND关系
2.5 图模式定义
一个图模式(Graph Pattern)是由下面递归定义的:
-
如果P 是一个基本图模式,则P 也是一个图模式;
-
如果P1 和P2 都是图模式,则P1 AND P2 也是一个图模式;
-
如果P1 和P2 都是图模式,则{P1} UNION {P2}, P1 OPTIONAL {P2} 都是图模
式。注意到{Pi} 表示一个组图模式;
- 如果P 是一个图模式,C 是SPARQL 中的FILTER 过滤条件,则(P FILTER C)也是一个图模式。
2.6 SPAQAL 组图模式 联合图模式
- 一个组图模式(Group Graph Pattern)如下递归定义:
-
如果P 是一个图模式,则{P} 是一个组图模式
-
如果P 是一个组图模式,则P 也是一个图模式
- 一个联合图模式(Union Graph Pattern)如下递归定义:
-
如果{P1} 是一个组图模式或者联合图模式,P2 是一个组图模式,则(P1 UNION P2) 是一个联合图模式
-
如果(P1 UNION P2) 是一个联合图模式,则(P1 UNION P2) 也是一个图模式。
2.7 SPAQAL 符号优先级
• 优先级从大到小分别是: (group)、UNION、AND、OPTIONAL、FILTER。
• OPTIONAL 操作符是左结合(left-associative)的
2.8 SPAQAL 结果修饰
SPARQL结果修饰
1. 排序(ORDER BY),⽤来对结果进⾏排序;
SELECT ?x ?label WHERE { ?x rdfs:label ?label } ORDER BY ?label
2. 映射(PROJECTION) ⽤来从结果中取若干变量组成新的结果;
SELECT ?label WHERE { ?x rdfs:label ?label }
3. 去重(DISTINCT),⽤来只返回不同的结果;
SELECT DISTINCT ?label WHERE { ?x rdfs:label ?label }
4. 偏移(OFFSET),⽤来使结果在指定的数量后开始;
SELECT ?label WHERE { ?x rdfs:label ?label } OFFSET 2
5. 限定结果数量(LIMIT),⽤来对结果数量设置了上限
SELECT ?label WHERE { ?x rdfs:label ?label } LIMIT 3
2.9 SPAQAL语义








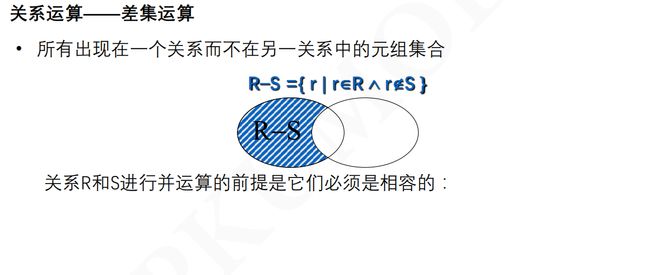


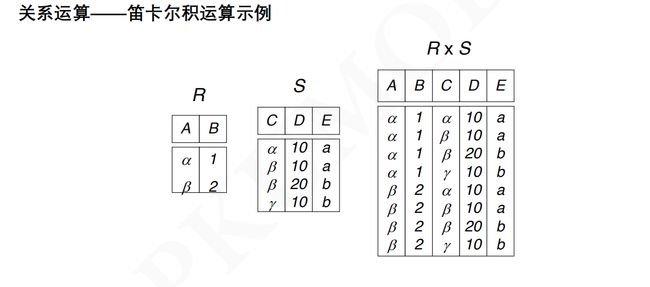
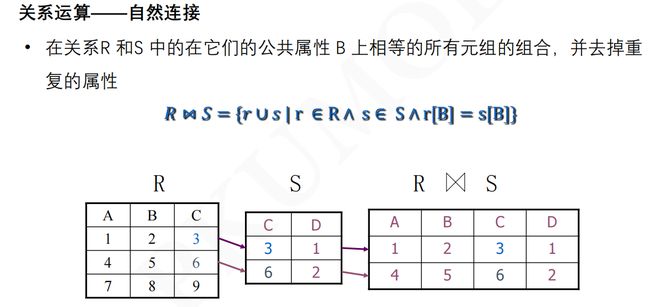


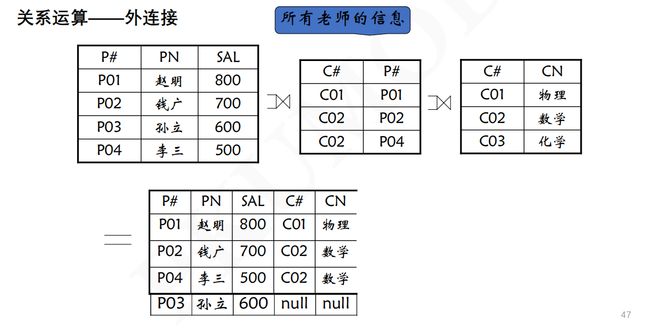

2.10 图模式的匹配




2.11 SPARQL 新特性
2013 年,SPARQL 1.1被提出,其中引入了一些新特性,包括且不限于:
• 属性路径(Property Path)
• 联邦查询(Federated Query)
SPARQL 1.1的属性路径
• 所谓属性路径(Property Path),就是找出RDF 数据上两点间满足属性限制
条件的路径。这个属性限制条件允许用属性组成的正则表达式来表达
SELECT ?x WHERE { dbr:James_Watt dbo:influenceBy∗ ?x }
*表示属性可以重复1次到n次,例如influenceBy 表示直接影响,influenceBy 属性出现多次表示
SPARQL 1.1的联邦查询
• 所谓联邦查询(Federated Query),就是允许查询调用远程的其它SPARQL
查询接口来与当前的结果进行组合
SELECT ?name WHERE {
dbr:James_Watt dbo:influenceBy ?person .
SERVICE https://dbpedia.org/sparql {
?person dbo:name ?name . }
}
3.属性图模型和Cypher查询语言


3.1 属性图模型
• 属性图模型是一种不同于RDF 三元组的一种图数据模型
• 这个模型由点来表示现实世界中的实体,由边来表示实体与实体之间的关系。
同时,点和边上都可以通过键值对的形式被关联上任意数量的属性和属性值
• 在这种图模型中,关系被提到了一个和实体本身一样重要的程度
• 从形式化的角度来看,属性图模型包含三种元素组成:值、图和表

属性图模型组成元素——值




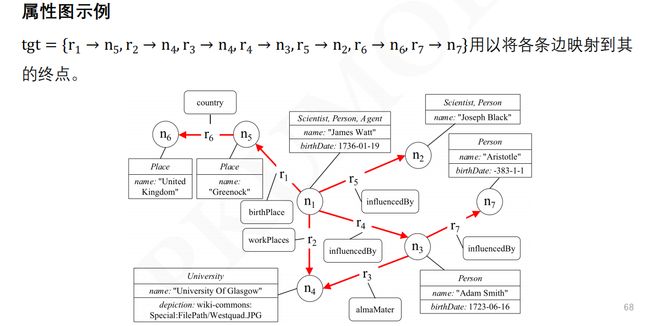


属性图模型组成元素——表



3.2 Cypher查询语言






Cypher 查询语言——语法和语义
• 一个Cypher 查询语言包括四部分:表达式、图模式、子句和查询
• 针对一个属性图而言,Cypher 语句既包括查询也包括数据更新和操作等功能
Cypher查询语言语法






4.TinkerPop图计算框架与Gremlin图遍历语⾔及遍历机
4.1 TinkerPop图计算框架
• Apache TinkerPop 是一个由Apache 软件基金会维护的独立于具体图数据库厂 商的开源图计算框架
• 如果一个图数据库系统使用图数据作为底层数据模型并能支持使用Gremlin 图遍历语言对其进行查询,那么该系统被称为**“支持TinkerPop 框架的”(TinkerPop-enabled)**
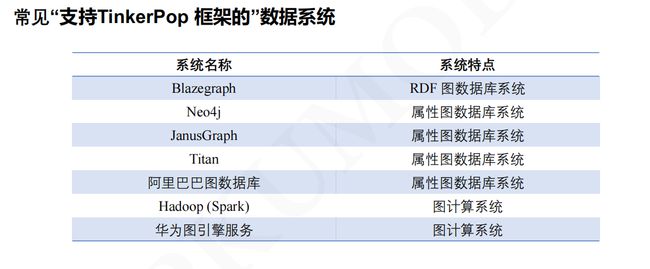
4.2 Gremlin 图遍历语言与图遍历机
• TinkerPop 框架的核心是Gremlin 图遍历语言
• **Gremlin 图遍历语言**是一种函数式语言,用来定义Gremlin 图遍历机对图数据进行基于遍历的查询
• **Gremlin 图遍历机**是一种逻辑上的自动机。该自动机机由若干指令集组成并由执行引擎来执行,执行引擎具体实现独立于编程语言,只要求这个编程语言是支持函数式编程的。目前已经有基于Java、Scala 等多种函数编程语言的执行引擎
属性图模型——Gremlin

JanusGraph背景

Gremlin 图遍历语言简介

遍历器及步骤

遍历分类
• 简单遍历
• 分支遍历
• 路径遍历
• 映射遍历
• 变异遍历
• 声明式遍历
• 定义域限定式遍历
简单遍历

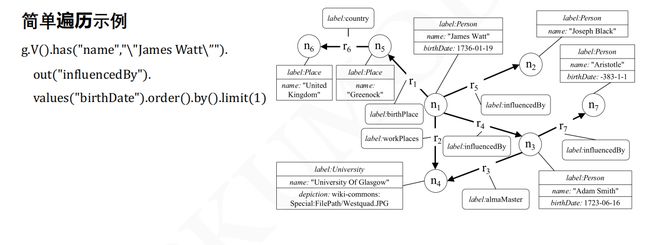

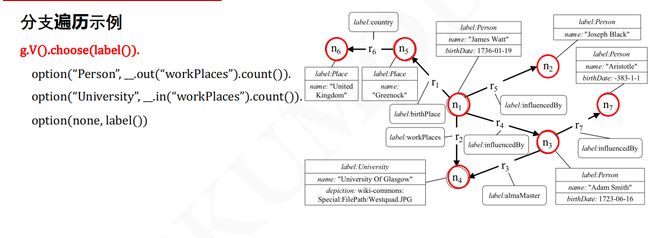
分支遍历


循环遍历



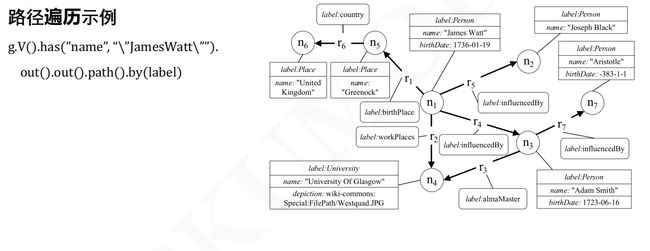
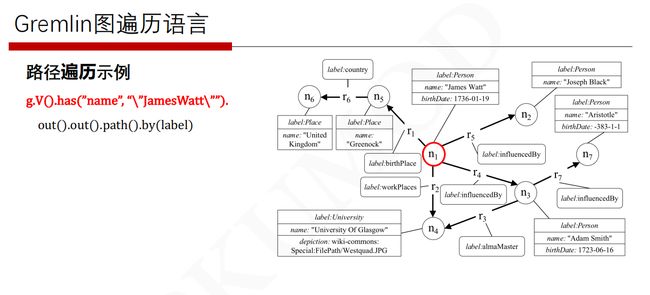
路径遍历


映射遍历


说明:图中的a节点为n1,b节点为n2和n3,对于a节点而言,计算入边:即有边属性为influencedBy的入边,很明显n1节点没有influencedBy的入边;对于b节点,需要计算出边:即有边属性为influencedBy的出边,n2节点没有,但是n3节点有一条influencedBy的出边
变异遍历


声明式遍历

定义了两个节点,a点有入边influencedBy,b点有出边influencesBy n2和n3节点都符合条件
定义域限定式搜索
4.3 Gremilin语法
Gremlin是 Apache TinkerPop 框架下的图遍历语言。Gremlin是一种函数式数据流语言,可以使得用户使用简洁的方式表述复杂的属性图(property graph)的遍历或查询。每个Gremlin遍历由一系列步骤(可能存在嵌套)组成,每一步都在数据流(data stream)上执行一个原子操作。
Gremlin 语言包括三个基本的操作:
- map-step:对数据流中的对象进行转换;
- filter-step:对数据流中的对象就行过滤;
- sideEffect-step:对数据流进行计算统计;
Tinkerpop3 模型核心概念
- Graph: 维护节点&边的集合,提供访问底层数据库功能,如事务功能
- Element: 维护属性集合,和一个字符串label,表明这个element种类
- Vertex: 继承自Element,维护了一组入度,出度的边集合
- Edge: 继承自Element,维护一组入度,出度vertex节点集合.
- Property: k-v键值对
- VertexProperty: 节点的属性,有一组健值对k-v,还有额外的properties 集合。同时也继承自element,必须有自己的id, label.
- Cardinality: 「single, list, set」 节点属性对应的value是单值,还是列表,或者set。
Gremlin 查询示例
下面先介绍下本文中所用到的图的 Schema(Lable):
顶点:
- person
- software
边:person
- uses(person -> software)
- develops(person -> software)
- knows(person -> person)
下面结合上面的 Schema 给出一些常用的图操作。完整的语法见下一部分。
查询点
g.V().limit(100) // 查询所有点,但限制点的返回数量为100,也可以使用range(x, y)的算子,返回区间内的点数量。
g.V().hasLabel('software') // 查询点的label值为'software'的点。
g.V('11') // 查询id为‘11’的点。
查询边
g.E() // 查询所有边,不推荐使用,边数过大时,这种查询方式不合理,一般需要添加过滤条件或限制返回数量。
g.E('55-81-5') // 查询边id为‘55-81-5’的边。
g.E().hasLabel('develops') // 查询label为‘develops’的边。
g.V('46').outE('develops') // 查询点id为‘46’所有label为‘develops’的边。
查询属性
g.V().limit(3).valueMap() // 查询点的所有属性(可填参数,表示只查询该点, 一个点所有属性一行结果)。
g.V().limit(1).label() // 查询点的label。
g.V().limit(10).values('name') // 查询点的name属性(可不填参数,表示查询所有属性, 一个点每个属性一行结果,只有value,没有key)。
新增点
graph.addVertex(label,'person',id,'500','age','18-24') //新增点,Label为user,ID为500,age为18-24。
g.addV('person').property(id,'600').property('age','18-24') //新增点,Label为user,ID为500,age为18-24。
新增边
a = graph.addVertex(label,'person',id,'501','age','18-24')
b = graph.addVertex(label,'software',id,'502','title','love')
a.addEdge('develops', b, 'Year','1994') // 新增边,边的两个点ID分别为501、502。
删除点
g.V('600').drop() // 删除ID为600的点。
删除边
g.V('600').drop() // 删除ID为600的点。
Gremlin 语法特性
基础
V():查询顶点,一般作为图查询的第1步,后面可以续接的语句种类繁多。例,g.V(),g.V('v_id'),查询所有点和特定点;E():查询边,一般作为图查询的第1步,后面可以续接的语句种类繁多;id():获取顶点、边的id。例:g.V().id(),查询所有顶点的id;label():获取顶点、边的 label。例:g.V().label(),可查询所有顶点的label。key() / values():获取属性的key/value的值。properties():获取顶点、边的属性;可以和 key()、value()搭配使用,以获取属性的名称或值。例:g.V().properties('name'),查询所有顶点的 name 属性;valueMap():获取顶点、边的属性,以Map的形式体现,和properties()比较像;values():获取顶点、边的属性值。例,g.V().values()等于g.V().properties().value()
遍历
顶点为基准:
out(label):根据指定的 Edge Label 来访问顶点的 OUT 方向邻接点(可以是零个 Edge Label,代表所有类型边;也可以一个或多个 Edge Label,代表任意给定 Edge Label 的边,下同);in(label):根据指定的 Edge Label 来访问顶点的 IN 方向邻接点;both(label):根据指定的 Edge Label 来访问顶点的双向邻接点;outE(label): 根据指定的 Edge Label 来访问顶点的 OUT 方向邻接边;inE(label):根据指定的 Edge Label 来访问顶点的 IN 方向邻接边;bothE(label):根据指定的 Edge Label 来访问顶点的双向邻接边;
边为基准的:
outV():访问边的出顶点,出顶点是指边的起始顶点;inV():访问边的入顶点,入顶点是指边的目标顶点,也就是箭头指向的顶点;bothV():访问边的双向顶点;otherV():访问边的伙伴顶点,即相对于基准顶点而言的另一端的顶点;
过滤
在众多Gremlin的语句中,有一大类是filter类型,顾名思义,就是对输入的对象进行条件判断,只有满足过滤条件的对象才可以通过filter进入下一步。
has
has语句是filter类型语句的代表,能够以顶点和边的属性作为过滤条件,决定哪些对象可以通过。常用的有下面几种:
has(key,value): 通过属性的名字和值来过滤顶点或边;has(label, key, value): 通过label和属性的名字和值过滤顶点和边;has(key,predicate): 通过对指定属性用条件过滤顶点和边,例:g.V().has('age', gt(20)),可得到年龄大于20的顶点;hasLabel(labels…): 通过 label 来过滤顶点或边,满足label列表中一个即可通过;hasId(ids…): 通过 id 来过滤顶点或者边,满足id列表中的一个即可通过;hasKey(keys…): 通过 properties 中的若干 key 过滤顶点或边;hasValue(values…): 通过 properties 中的若干 value 过滤顶点或边;has(key): properties 中存在 key 这个属性则通过,等价于hasKey(key);hasNot(key): 和 has(key) 相反;
例:
g.V().hasLabel('person') // lable 等于 person 的所有顶点;
g.V().has('age',inside(20,30)).values('age') // 所有年龄在20(含)~30(不含)之间的顶点;
g.V().has('age',outside(20,30)).values('age') // 所有年龄不在20(含)~30(不含)之间的顶点;
g.V().has('name',within('josh','marko')).valueMap() // name 是'josh'或'marko'的顶点的属性;
g.V().has('name',without('josh','marko')).valueMap() // name 不是'josh'或'marko'的顶点的属性;
g.V().has('name',not(within('josh','marko'))).valueMap() // 同上
g.V().properties().hasKey('age').value() // age 这个属性的所有 value
g.V().hasNot('age').values('name') // 不含 age 这个属性的所有 顶点的 name 属性
路径
在使用Gremlin对图进行分析时,关注点有时并不仅仅在最终达到顶点、边或者属性,通过什么样的路径到达最终的顶点、边和属性同样重要。此时可以借助path() 来获取经过的路径信息。
path() 返回当前遍历过的所有路径。有时需要对路径进行过滤,只选择没有环路的路径或者选择包含环路的路径,Gremlin针对这种需求提供了两种过滤路径的step:simplePath() 和cyclicPath()。
path():获取当前遍历过的所有路径;simplePath():过滤掉路径中含有环路的对象,只保留路径中不含有环路的对象;cyclicPath():过滤掉路径中不含有环路的对象,只保留路径中含有环路的对象。
例1:寻找4跳以内从 andy 到 jack 的最短路径。
g.V("andy")
.repeat(both().simplePath()).until(hasId("target_v_id")
.and().loops().is(lte(4))).hasId("jack")
.path().limit(1)
例2:“Titan” 顶点到与其有两层关系的顶点的不含环路的路径(只包含顶点)
g.V()
.hasLabel('software').has('name','Titan')
.both().both().simplePath()
.path()
迭代
-
repeat():指定要重复执行的语句; -
times(): 指定要重复执行的次数,如执行3次; -
until():指定循环终止的条件,如一直找到某个名字的朋友为止; -
emit():指定循环语句的执行过程中收集数据的条件,每一步的结果只要符合条件则被收集,不指定条件时收集所有结果; -
loops():当前循环的次数,可用于控制最大循环次数等,如最多执行3次。 -
repeat()和until()的位置不同,决定了不同的循环效果:
repeat()+until():等同 do-while;until()+repeat():等同 while-do。
repeat() 和 emit() 的位置不同,决定了不同的循环效果:
repeat()+emit():先执行后收集;emit()+repeat():表示先收集再执行。
注意:
emit()与times()搭配使用时,是“或”的关系而不是“与”的关系,满足两者间任意一个即可。
emit()与until()搭配使用时,是“或”的关系而不是“与”的关系,满足两者间任意一个即可。
例1:根据出边进行遍历,直到抵达叶子节点(无出边的顶点),输出其路径顶点名:
g.V(1)
.repeat(out())
.until(outE().count().is(0))
.path().by('name')
例2:查询顶点’1’的3度 OUT 可达点路径
g.V('1')
.repeat(out())
.until(loops().is(3))
.path()
转换
- map():可以接受一个遍历器 Step 或 Lamda 表达式,将遍历器中的元素映射(转换)成另一个类型的某个对象(一对一),以便进行下一步处理
- flatMap():可以接受一个遍历器 Step 或 Lamda 表达式,将遍历器中的元素映射(转换)成另一个类型的某个对象流或迭代器(一对多)。
例:
// 创建了 titan 的作者节点的姓名
g.V('titan').in('created').map(values('name'))
// 创建了 titan 的作者节点的所有出边
g.V('titan').in('created').flatMap(outE())
排序
order()order().by()
排序比较简单,直接看例子吧。
// 默认升序排列
g.V().values('name').order()
// 按照元素属性age的值升序排列,并只输出姓名
g.V().hasLabel('person').order().by('age', asc).values('name')
逻辑
is():可以接受一个对象(能判断相等)或一个判断语句(如:P.gt()、P.lt()、P.inside()等),当接受的是对象时,原遍历器中的元素必须与对象相等才会保留;当接受的是判断语句时,原遍历器中的元素满足判断才会保留,其实接受一个对象相当于P.eq();and():可以接受任意数量的遍历器(traversal),原遍历器中的元素,只有在每个新遍历器中都能生成至少一个输出的情况下才会保留,相当于过滤器组合的与条件;or():可以接受任意数量的遍历器(traversal),原遍历器中的元素,只要在全部新遍历器中能生成至少一个输出的情况下就会保留,相当于过滤器组合的或条件;not():仅能接受一个遍历器(traversal),原遍历器中的元素,在新遍历器中能生成输出时会被移除,不能生成输出时则会保留,相当于过滤器的非条件。
例1:
// 筛选出顶点属性“age”等于28的属性值,与`is(P.eq(28))`等效
g.V().values('age').is(28)
// 所有包含出边“supports”和“created”的顶点的名字“name”
g.V().
and(
outE('supports'),
outE('created'))
.values('name')
// 使用 where语句 实现上面的功能
g.V().where(outE('supports')
.and()
.outE('created')
.values('name')
// 筛选出所有不是“person”的顶点的“label”
g.V().not(hasLabel('person')).label()
例2:获取所有最多只有一条“created”边并且年龄不等于28的“person”顶点
g.V().hasLabel('person')
.and(outE('created').count().is(lte(1)),
values("age").is(P.not(P.eq(28))))
.values('name')
统计
- sum():将 traversal 中的所有的数字求和;
- max():对 traversal 中的所有的数字求最大值;
- min():对 traversal 中的所有的数字求最小值;
- mean():将 traversal 中的所有的数字求均值;
- count():统计 traversal 中 item 总数。
例:
// 计算所有“person”的“created”出边数的均值
g.V().hasLabel('person')
.map(outE('created').count())
.mean()
分支
choose():分支选择, 常用使用场景为:choose(predicate, true-traversal, false-traversal),根据 predicate 判断,当前对象满足时,继续 true-traversal,否则继续 false-traversal;optional():类似于 by() 无实际意义,搭配 choose() 使用;
例1:if-else
g.V().hasLabel('person').
choose(values('age').is(lte(30)),
__.in(),
__.out()).values('name')
例2:if-elseif-else
// 查找所有的“person”类型的顶点
// 如果“age”属性等于0,输出名字
// 如果“age”属性等于28,输出年龄
// 如果“age”属性等于29,输出他开发的软件的名字
// choose(predicate).option().option()...
g.V().hasLabel('person')
.choose(values('age'))
.option(0, values('name'))
.option(28, values('age'))
.option(29, __.out('created').values('name'))
.option(none, values('name'))