基于Seq2Seq的问答摘要与推理问题方案
1.项目背景:
主题为汽车大师问答摘要与推理。要求使用汽车大师提供的11万条 技师与用户的多轮对话与诊断建议报告 数据建立模型,模型需基于对话文本、用户问题、车型与车系,输出包含摘要与推断的报告文本,综合考验模型的归纳总结与推断能力。
汽车大师是一款通过在线咨询问答为车主解决用车问题的APP,致力于做车主身边靠谱的用车顾问,车主用语音、文字或图片发布汽车问题,系统为其匹配专业技师提供及时有效的咨询服务。由于平台用户基数众多,问题重合度较高,大部分问题在平台上曾得到过解答。重复回答和持续时间长的多轮问询不仅会花去汽修技师大量时间,也使用户获取解决方案的时间变长,对双方来说都存在资源浪费的情况。
为了节省更多人工时间,提高用户获取回答和解决方案的效率,汽车大师希望通过利用机器学习对平台积累的大量历史问答数据进行模型训练,基于汽车大师平台提供的历史多轮问答文本,输出完整的建议报告和回答,让用户在线通过人工智能语义识别即时获得全套解决方案。
2.数据预处理
train_df = pd.read_csv(train_data_path)
test_df = pd.read_csv(test_data_path)
print('train data size {},test data size {}'.format(len(train_df), len(test_df)))
print(train_df.iloc[:1])train data size 82943,test data size 20000QID Brand Model Question \
0 Q1 奔驰 奔驰GL级 方向机重,助力泵,方向机都换了还是一样
Dialogue Report
0 技师说:[语音]|车主说:新的都换了|车主说:助力泵,方向机|技师说:[语音]|车主说:换了... 随时联系 -
2.1空值填充
train_df.dropna(subset=['Question', 'Dialogue', 'Report'], how='any', inplace=True)
test_df.dropna(subset=['Question', 'Dialogue'], how='any', inplace=True)-
2.2多线程批量处理数据
from multi_proc_utils import parallelize
train_df = parallelize(train_df, sentences_proc)
test_df = parallelize(test_df, sentences_proc)
-
清除无用词
def clean_sentence(sentence):
'''
特殊符号去除
:param sentence: 待处理的字符串
:return: 过滤特殊字符后的字符串
'''
if isinstance(sentence, str):
return re.sub(
# r'[\s+\-\!\/\[\]\{\}_,.$%^*(+\"\')]+|[::+——()?【】“”!,。?、~@#¥%……&*()]+|车主说|技师说|语音|图片|你好|您好',
r'[\s+\-\/\[\]\{\}_$%^*(+\"\')]+|[+——()【】“”~@#¥%……&*()]+|你好|您好',
' ', sentence)
else:
return ' '-
过滤停用词
def filter_words(sentence):
'''
过滤停用词
:param seg_list: 切好词的列表 [word1 ,word2 .......]
:return: 过滤后的停用词
'''
words = sentence.split(' ')
# 去掉多余空字符
words = [word for word in words if word]
# 去掉停用词 包括一下标点符号也会去掉
words = [word for word in words if word not in stop_words]
return words-
2.3合并训练测试集合
将训练数据中['Question', 'Dialogue', 'Report']列和测试数据中['Question', 'Dialogue']合并,并保存
train_df['merged'] = train_df[['Question', 'Dialogue', 'Report']].apply(lambda x: ' '.join(x), axis=1)
test_df['merged'] = test_df[['Question', 'Dialogue']].apply(lambda x: ' '.join(x), axis=1)
print(train_df['merged'].shape)
print(test_df['merged'].shape)
merged_df = pd.concat([train_df[['merged']], test_df[['merged']]], axis=0)
merged_df.to_csv(merger_seg_path, index=None, header=False)
3.生成词向量
使用gensim工具生成初始词向量
from gensim.models.word2vec import LineSentence, Word2Vec
wv_model = Word2Vec(LineSentence(merger_seg_path),
size=embedding_dim,
sg=1,
workers=8,
iter=wv_train_epochs,
window=5,
min_count=5)分离数据和标签:['Question', 'Dialogue']当做数据,['Report']当做标签train_df['X'] = train_df[['Question', 'Dialogue']].apply(lambda x: ' '.join(x), axis=1)
test_df['X'] = test_df[['Question', 'Dialogue']].apply(lambda x: ' '.join(x), axis=1)
填充开始结束符号,未知词填充 oov, 长度填充def pad_proc(sentence, max_len, vocab):
'''
# 填充字段
< start > < end > < pad > < unk > max_lens
'''
# 0.按空格统计切分出词
words = sentence.strip().split(' ')
# 1. 截取规定长度的词数
words = words[:max_len]
# 2. 填充< unk > ,判断是否在vocab中, 不在填充 < unk >
sentence = [word if word in vocab else '' for word in words]
# 3. 填充< start > < end >
sentence = [''] + sentence + ['']
# 4. 判断长度,填充 < pad >
sentence = sentence + [''] * (max_len - len(words))
return ' '.join(sentence)
# 使用GenSim训练得出的vocab
vocab = wv_model.wv.vocab
# 获取适当的最大长度
train_x_max_len = get_max_len(train_df['X'])
test_X_max_len = get_max_len(test_df['X'])
X_max_len = max(train_x_max_len, test_X_max_len)
train_df['X'] = train_df['X'].apply(lambda x: pad_proc(x, X_max_len, vocab))
# 获取适当的最大长度
test_df['X'] = test_df['X'].apply(lambda x: pad_proc(x, X_max_len, vocab))
# 获取适当的最大长度
train_y_max_len = get_max_len(train_df['Report'])
train_df['Y'] = train_df['Report'].apply(lambda x: pad_proc(x, train_y_max_len, vocab))
保存pad oov处理后的,数据和标签train_df['X'].to_csv(train_x_pad_path, index=None, header=False)
train_df['Y'].to_csv(train_y_pad_path, index=None, header=False)
test_df['X'].to_csv(test_x_pad_path, index=None, header=False)再次训练词向量,因为新加的符号不在词表 和 词向量矩阵wv_model.build_vocab(LineSentence(train_x_pad_path), update=True)
wv_model.train(LineSentence(train_x_pad_path), epochs=1, total_examples=wv_model.corpus_count)
print('1/3')
wv_model.build_vocab(LineSentence(train_y_pad_path), update=True)
wv_model.train(LineSentence(train_y_pad_path), epochs=1, total_examples=wv_model.corpus_count)
print('2/3')
wv_model.build_vocab(LineSentence(test_x_pad_path), update=True)
wv_model.train(LineSentence(test_x_pad_path), epochs=1, total_examples=wv_model.corpus_count)保存词向量模型和、字典和词向量矩阵 # 保存词向量模型
wv_model.save(save_wv_model_path)
print('finish retrain w2v model')
print('final w2v_model has vocabulary of ', len(wv_model.wv.vocab))
# 更新vocab
vocab = {word: index for index, word in enumerate(wv_model.wv.index2word)}
reverse_vocab = {index: word for index, word in enumerate(wv_model.wv.index2word)}
# 保存字典
save_dict(vocab_path, vocab)
save_dict(reverse_vocab_path, reverse_vocab)
# 保存词向量矩阵
embedding_matrix = wv_model.wv.vectors
np.save(embedding_matrix_path, embedding_matrix)4.保存训练测试数据
# 数据集转换 将词转换成索引 [ 方向机 重 ...] -> [32800, 403, 986, 246, 231
train_ids_x = train_df['X'].apply(lambda x: transform_data(x, vocab))
train_ids_y = train_df['Y'].apply(lambda x: transform_data(x, vocab))
test_ids_x = test_df['X'].apply(lambda x: transform_data(x, vocab))
# 数据转换成numpy数组
# 将索引列表转换成矩阵 [32800, 403, 986, 246, 231] --> array([[32800, 403, 986 ]]
train_X = np.array(train_ids_x.tolist())
train_Y = np.array(train_ids_y.tolist())
test_X = np.array(test_ids_x.tolist())
# 保存数据
np.save(train_x_path, train_X)
np.save(train_y_path, train_Y)
np.save(test_x_path, test_X) 5.模型训练
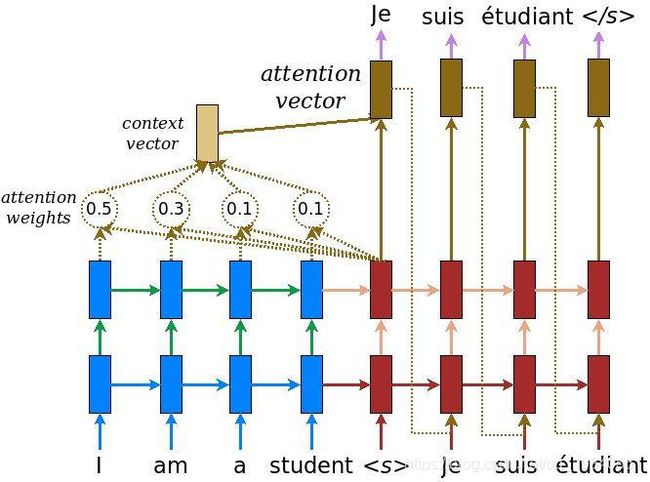
输入通过一个编码器模型,该模型给出了形状的编码器输出(batch_size, max_length, hidden_size)和编码器隐藏形状的状态(batch_size, hidden_size)
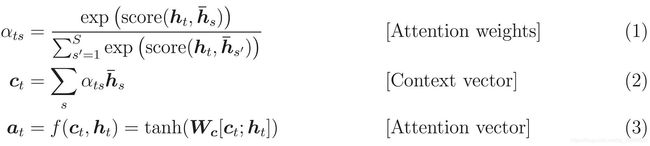
FC=全连接层,EO=编码器输出,H=隐藏层状态,X=解码器输入,模型计算过程如下表示:
- score = FC(tanh(FC(EO) + FC(H)))
- attention weights = softmax(score, axis = 1)
- context vector = sum(attention weights * EO, axis = 1)
- embedding output=解码器输入X,输入词嵌入层
- merged vector=concat(embedding output, context vector)
- 将merged vector输入到GRU
5.1基本参数设置
# 训练集的长度
BUFFER_SIZE = len(train_X)
# 输入的长度
max_length_inp=train_X.shape[1]
# 输出的长度
max_length_targ=train_Y.shape[1]
BATCH_SIZE = 64
# 训练一轮需要迭代多少步
steps_per_epoch = len(train_X)//BATCH_SIZE
# 词向量维度
embedding_dim = 300
# 隐藏层单元数
units = 1024
# 词表大小
vocab_size = len(vocab)
# 构建训练集
dataset = tf.data.Dataset.from_tensor_slices((train_X, train_Y)).shuffle(BUFFER_SIZE)
dataset = dataset.batch(BATCH_SIZE, drop_remainder=True)5.2构建Encoder

class Encoder(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim ,embedding_matrix , enc_units, batch_sz):
super(Encoder, self).__init__()
self.batch_sz = batch_sz
self.enc_units = enc_units
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim,weights=[embedding_matrix],trainable=False)
self.gru = tf.keras.layers.GRU(self.enc_units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
def call(self, x, hidden):
x = self.embedding(x)
output, state = self.gru(x, initial_state = hidden)
return output, state
def initialize_hidden_state(self):
return tf.zeros((self.batch_sz, self.enc_units))测试Encoder:
encoder = Encoder(vocab_size, embedding_dim,embedding_matrix, units, BATCH_SIZE)
# example_input
example_input_batch = tf.ones(shape=(BATCH_SIZE,max_length_inp), dtype=tf.int32)
# sample input
sample_hidden = encoder.initialize_hidden_state()
sample_output, sample_hidden = encoder(example_input_batch, sample_hidden)
print ('Encoder output shape: (batch size, sequence length, units) {}'.format(sample_output.shape))
print ('Encoder Hidden state shape: (batch size, units) {}'.format(sample_hidden.shape))Encoder output shape: (batch size, sequence length, units) (64, 261, 1024)
Encoder Hidden state shape: (batch size, units) (64, 1024)5.3构建Attention
定一组向量集合values,以及查询向量query,我们根据query向量去计算values加权和,即成为attention机制。
attention的重点即为求这个集合values中每个value的权值。
class BahdanauAttention(tf.keras.layers.Layer):
def __init__(self, units):
super(BahdanauAttention, self).__init__()
self.W1 = tf.keras.layers.Dense(units)
self.W2 = tf.keras.layers.Dense(units)
self.V = tf.keras.layers.Dense(1)
def call(self, query, values):
# query为上次的GRU隐藏层
# values为编码器的编码结果enc_output
# 在seq2seq模型中,St是后面的query向量,而编码过程的隐藏状态hi是values。
hidden_with_time_axis = tf.expand_dims(query, 1)
# 计算注意力权重值
score = self.V(tf.nn.tanh(
self.W1(values) + self.W2(hidden_with_time_axis)))
# attention_weights shape == (batch_size, max_length, 1)
attention_weights = tf.nn.softmax(score, axis=1)
# # 使用注意力权重*编码器输出作为返回值,将来会作为解码器的输入
# context_vector shape after sum == (batch_size, hidden_size)
context_vector = attention_weights * values
context_vector = tf.reduce_sum(context_vector, axis=1)
return context_vector, attention_weights测试Attention:
attention_layer = BahdanauAttention(10)
attention_result, attention_weights = attention_layer(sample_hidden, sample_output)
print("Attention result shape: (batch size, units) {}".format(attention_result.shape))
print("Attention weights shape: (batch_size, sequence_length, 1) {}".format(attention_weights.shape))Attention result shape: (batch size, units) (64, 1024)
Attention weights shape: (batch_size, sequence_length, 1) (64, 261, 1)5.4构建Decoder
class Decoder(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim,embedding_matrix, dec_units, batch_sz):
super(Decoder, self).__init__()
self.batch_sz = batch_sz
self.dec_units = dec_units
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim,weights=[embedding_matrix],trainable=False)
self.gru = tf.keras.layers.GRU(self.dec_units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
self.fc = tf.keras.layers.Dense(vocab_size)
# used for attention
self.attention = BahdanauAttention(self.dec_units)
def call(self, x, hidden, enc_output):
# 使用上次的隐藏层(第一次使用编码器隐藏层)、编码器输出计算注意力权重
# enc_output shape == (batch_size, max_length, hidden_size)
context_vector, attention_weights = self.attention(hidden, enc_output)
# x shape after passing through embedding == (batch_size, 1, embedding_dim)
x = self.embedding(x)
# 将上一循环的预测结果跟注意力权重值结合在一起作为本次的GRU网络输入
# x shape after concatenation == (batch_size, 1, embedding_dim + hidden_size)
x = tf.concat([tf.expand_dims(context_vector, 1), x], axis=-1)
# passing the concatenated vector to the GRU
output, state = self.gru(x)
# output shape == (batch_size * 1, hidden_size)
output = tf.reshape(output, (-1, output.shape[2]))
# output shape == (batch_size, vocab)
x = self.fc(output)
return x, state, attention_weights测试Decoder:
decoder = Decoder(vocab_size, embedding_dim,embedding_matrix, units, BATCH_SIZE)
sample_decoder_output, _, _ = decoder(tf.random.uniform((64, 1)),
sample_hidden, sample_output)
print ('Decoder output shape: (batch_size, vocab size) {}'.format(sample_decoder_output.shape))Decoder output shape: (batch_size, vocab size) (64, 32804)5.5定义优化函数
optimizer = tf.keras.optimizers.Adam()
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True, reduction='none')
pad_index=vocab['']
def loss_function(real, pred):
#找到非对应的位置
mask = tf.math.logical_not(tf.math.equal(real, pad_index))
loss_ = loss_object(real, pred)
mask = tf.cast(mask, dtype=loss_.dtype)
#排除的loss
loss_ *= mask
return tf.reduce_mean(loss_) 5.6保存点设置
checkpoint_dir = 'data/checkpoints/training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(optimizer=optimizer,
encoder=encoder,
decoder=decoder)6.训练
用到teacher forcing,Decoder阶段的target作为输入,使用先验单词提高收敛速度
@tf.function
def train_step(inp, targ, enc_hidden):
loss = 0
with tf.GradientTape() as tape:
# 1. 构建encoder
enc_output, enc_hidden = encoder(inp, enc_hidden)
# 2. 复制
dec_hidden = enc_hidden
# 3. * BATCH_SIZE
dec_input = tf.expand_dims([vocab['']] * BATCH_SIZE, 1)
# Teacher forcing - feeding the target as the next input
for t in range(1, targ.shape[1]):
# decoder(x, hidden, enc_output)
predictions, dec_hidden, _ = decoder(dec_input, dec_hidden, enc_output)
loss += loss_function(targ[:, t], predictions)
# using teacher forcing
dec_input = tf.expand_dims(targ[:, t], 1)
batch_loss = (loss / int(targ.shape[1]))
variables = encoder.trainable_variables + decoder.trainable_variables
gradients = tape.gradient(loss, variables)
optimizer.apply_gradients(zip(gradients, variables))
return batch_loss EPOCHS = 10
for epoch in range(EPOCHS):
start = time.time()
# 初始化隐藏层
enc_hidden = encoder.initialize_hidden_state()
total_loss = 0
for (batch, (inp, targ)) in enumerate(dataset.take(steps_per_epoch)):
#
batch_loss = train_step(inp, targ, enc_hidden)
total_loss += batch_loss
if batch % 1 == 0:
print('Epoch {} Batch {} Loss {:.4f}'.format(epoch + 1,
batch,
batch_loss.numpy()))
# saving (checkpoint) the model every 2 epochs
if (epoch + 1) % 2 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
print('Epoch {} Loss {:.4f}'.format(epoch + 1,
total_loss / steps_per_epoch))
print('Time taken for 1 epoch {} sec\n'.format(time.time() - start))Epoch 1 Batch 0 Loss 2.6071
Epoch 1 Batch 1 Loss 2.4794
Epoch 1 Batch 2 Loss 2.6189
Epoch 1 Batch 3 Loss 2.3431
Epoch 1 Batch 4 Loss 3.1416
Epoch 1 Batch 5 Loss 2.5989
Epoch 1 Batch 6 Loss 2.8121
Epoch 1 Batch 7 Loss 2.6711
Epoch 1 Batch 8 Loss 2.3373
Epoch 1 Batch 9 Loss 2.2395
Epoch 1 Loss 2.5849
Time taken for 1 epoch 122.1180808544159 sec
Epoch 2 Batch 0 Loss 2.3729
Epoch 2 Batch 1 Loss 2.6925
Epoch 2 Batch 2 Loss 2.6551
Epoch 2 Batch 3 Loss 2.5503
Epoch 2 Batch 4 Loss 2.5938
Epoch 2 Batch 5 Loss 2.2217
Epoch 2 Batch 6 Loss 2.3711
Epoch 2 Batch 7 Loss 2.4233
Epoch 2 Batch 8 Loss 2.3542
Epoch 2 Batch 9 Loss 2.4876
Epoch 2 Loss 2.4722
Time taken for 1 epoch 122.43454432487488 sec
Epoch 3 Batch 0 Loss 2.2104
Epoch 3 Batch 1 Loss 2.3985
Epoch 3 Batch 2 Loss 2.3234
Epoch 3 Batch 3 Loss 2.2387
Epoch 3 Batch 4 Loss 2.2565
Epoch 3 Batch 5 Loss 2.4140
Epoch 3 Batch 6 Loss 1.8723
Epoch 3 Batch 7 Loss 2.1348
Epoch 3 Batch 8 Loss 2.7321
Epoch 3 Batch 9 Loss 2.6459
Epoch 3 Loss 2.3227
Time taken for 1 epoch 122.04101395606995 sec
Epoch 4 Batch 0 Loss 2.1034
Epoch 4 Batch 1 Loss 2.4706
Epoch 4 Batch 2 Loss 2.0830
Epoch 4 Batch 3 Loss 2.2704
Epoch 4 Batch 4 Loss 1.8460
Epoch 4 Batch 5 Loss 2.2392
Epoch 4 Batch 6 Loss 2.1061
Epoch 4 Batch 7 Loss 1.7663
Epoch 4 Batch 8 Loss 2.3976
Epoch 4 Batch 9 Loss 2.1924
Epoch 4 Loss 2.1475
Time taken for 1 epoch 122.41424536705017 sec
Epoch 5 Batch 0 Loss 2.1025
Epoch 5 Batch 1 Loss 1.8814
Epoch 5 Batch 2 Loss 1.8141
Epoch 5 Batch 3 Loss 2.2037
Epoch 5 Batch 4 Loss 1.8383
Epoch 5 Batch 5 Loss 2.0435
Epoch 5 Batch 6 Loss 2.0946
Epoch 5 Batch 7 Loss 1.8200
Epoch 5 Batch 8 Loss 2.0206
Epoch 5 Batch 9 Loss 1.9670
Epoch 5 Loss 1.9786
Time taken for 1 epoch 122.04332089424133 sec
Epoch 6 Batch 0 Loss 1.7780
Epoch 6 Batch 1 Loss 2.0647
Epoch 6 Batch 2 Loss 1.8531
Epoch 6 Batch 3 Loss 1.7665
Epoch 6 Batch 4 Loss 1.7081
Epoch 6 Batch 5 Loss 1.8388
Epoch 6 Batch 6 Loss 1.7397
Epoch 6 Batch 7 Loss 1.8886
Epoch 6 Batch 8 Loss 1.9132
Epoch 6 Batch 9 Loss 1.7469
Epoch 6 Loss 1.8298
Time taken for 1 epoch 122.37464952468872 sec
Epoch 7 Batch 0 Loss 1.5922
Epoch 7 Batch 1 Loss 1.6886
Epoch 7 Batch 2 Loss 1.6815
Epoch 7 Batch 3 Loss 1.7721
Epoch 7 Batch 4 Loss 1.5859
Epoch 7 Batch 5 Loss 1.5939
Epoch 7 Batch 6 Loss 1.6164
Epoch 7 Batch 7 Loss 1.8224
Epoch 7 Batch 8 Loss 1.8248
Epoch 7 Batch 9 Loss 1.7638
Epoch 7 Loss 1.6942
Time taken for 1 epoch 121.93808913230896 sec
Epoch 8 Batch 0 Loss 1.6082
Epoch 8 Batch 1 Loss 1.6250
Epoch 8 Batch 2 Loss 1.4295
Epoch 8 Batch 3 Loss 1.8100
Epoch 8 Batch 4 Loss 1.5442
Epoch 8 Batch 5 Loss 1.4713
Epoch 8 Batch 6 Loss 1.6918
Epoch 8 Batch 7 Loss 1.6335
Epoch 8 Batch 8 Loss 1.6160
Epoch 8 Batch 9 Loss 1.3867
Epoch 8 Loss 1.5816
Time taken for 1 epoch 122.38609957695007 sec
Epoch 9 Batch 0 Loss 1.6677
Epoch 9 Batch 1 Loss 1.4375
Epoch 9 Batch 2 Loss 1.3425
Epoch 9 Batch 3 Loss 1.4567
Epoch 9 Batch 4 Loss 1.3913
Epoch 9 Batch 5 Loss 1.4414
Epoch 9 Batch 6 Loss 1.4123
Epoch 9 Batch 7 Loss 1.4082
Epoch 9 Batch 8 Loss 1.6062
Epoch 9 Batch 9 Loss 1.6140
Epoch 9 Loss 1.4778
Time taken for 1 epoch 121.9051079750061 sec
Epoch 10 Batch 0 Loss 1.1795
Epoch 10 Batch 1 Loss 1.2038
Epoch 10 Batch 2 Loss 1.4458
Epoch 10 Batch 3 Loss 1.4928
Epoch 10 Batch 4 Loss 1.4383
Epoch 10 Batch 5 Loss 1.2833
Epoch 10 Batch 6 Loss 1.6028
Epoch 10 Batch 7 Loss 1.4659
Epoch 10 Batch 8 Loss 1.3429
Epoch 10 Batch 9 Loss 1.4269
Epoch 10 Loss 1.3882
Time taken for 1 epoch 122.23126912117004 sec
7.预测评估
def evaluate(sentence):
attention_plot = np.zeros((max_length_targ, max_length_inp+2))
inputs = preprocess_sentence(sentence,max_length_inp,vocab)
inputs = tf.convert_to_tensor(inputs)
result = ''
hidden = [tf.zeros((1, units))]
enc_out, enc_hidden = encoder(inputs, hidden)
dec_hidden = enc_hidden
dec_input = tf.expand_dims([vocab['']], 0)
for t in range(max_length_targ):
predictions, dec_hidden, attention_weights = decoder(dec_input,
dec_hidden,
enc_out)
# storing the attention weights to plot later on
attention_weights = tf.reshape(attention_weights, (-1, ))
attention_plot[t] = attention_weights.numpy()
predicted_id = tf.argmax(predictions[0]).numpy()
result += reverse_vocab[predicted_id] + ' '
if reverse_vocab[predicted_id] == '':
return result, sentence, attention_plot
# the predicted ID is fed back into the model
dec_input = tf.expand_dims([predicted_id], 0)
return result, sentence, attention_plot def translate(sentence):
result, sentence, attention_plot = evaluate(sentence)
print('Input: %s' % (sentence))
print('Predicted translation: {}'.format(result))
attention_plot = attention_plot[:len(result.split(' ')), :len(sentence.split(' '))]
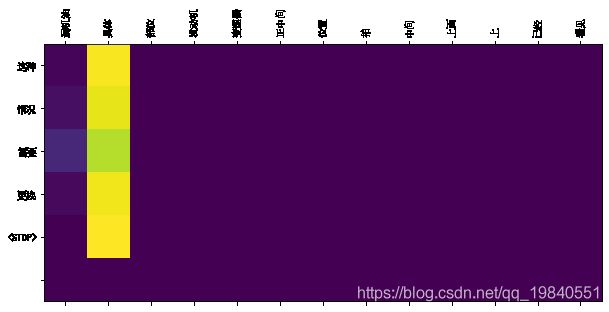
plot_attention(attention_plot, sentence.split(' '), result.split(' '))sentence='漏机油 具体 部位 发动机 变速器 正中间 位置 拍 中间 上面 上 已经 看见'
translate(sentence)
Input: 漏机油 具体 部位 发动机 变速器 正中间 位置 拍 中间 上面 上 已经 看见
Predicted translation: 这种 情况 需要 更换 根据attention weights作图:
8.将Encoder-attention-Decoder构建成Baseline Seq2Seq结构
class Seq2Seq(tf.keras.Model):
def __init__(self, params):
super(Seq2Seq, self).__init__()
self.embedding_matrix = load_embedding_matrix()
self.params = params
self.encoder = Encoder(params["vocab_size"],
params["embed_size"],
self.embedding_matrix,
params["enc_units"],
params["batch_size"])
self.attention = BahdanauAttention(params["attn_units"])
self.decoder = Decoder(params["vocab_size"],
params["embed_size"],
self.embedding_matrix,
params["dec_units"],
params["batch_size"])
def call(self, dec_input, dec_hidden, enc_output, dec_target):
predictions = []
attentions = []
context_vector, _ = self.attention(dec_hidden, enc_output)
for t in range(1, dec_target.shape[1]):
_, pred, dec_hidden = self.decoder(dec_input,
dec_hidden,
enc_output,
context_vector)
context_vector, attn = self.attention(dec_hidden, enc_output)
# using teacher forcing
dec_input = tf.expand_dims(dec_target[:, t], 1)
predictions.append(pred)
attentions.append(attn)
return tf.stack(predictions, 1), dec_hidden9.存在的问题和改进思路:
存在的问题:
1.存在UNK未登录词,导致出现OOV问题;
2.生成的句子存在重复文本的现象
改进思路:
参考论文指针生成网络的pointer generater 和coverage机制
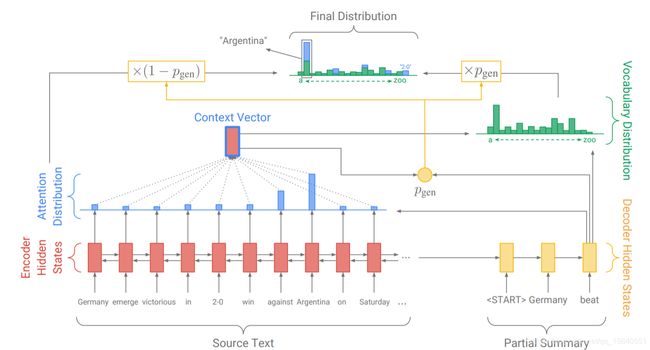
1.pointer generater
Seq2Seq+point
混合了 Baseline seq2seq和PointerNetwork的网络,它具有Baseline seq2seq的生成能力和PointerNetwork的Copy能力。如何权衡一个词应该是生成的还是复制的?原文中引入了一个权重pgen
在Seq2Seq baseline基础上,加上Pointer指针部分记录pgen
class Pointer(tf.keras.layers.Layer):
def __init__(self):
super(Pointer, self).__init__()
self.w_s_reduce = tf.keras.layers.Dense(1)
self.w_i_reduce = tf.keras.layers.Dense(1)
self.w_c_reduce = tf.keras.layers.Dense(1)
def __call__(self, context_vector, dec_hidden, dec_inp):
return tf.nn.sigmoid(self.w_s_reduce(dec_hidden) + self.w_c_reduce(context_vector) + self.w_i_reduce(dec_inp))
从Baseline seq2seq的模型结构中得到了St和ℎ∗ht∗,和解码器输入 xt 一起来计算 pgen :
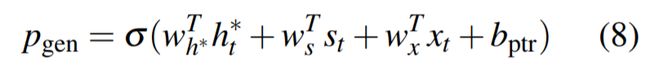
-
context vector ℎ∗ht∗
-
decoder input xt
-
the decoder state
Final_dists
这时,会扩充单词表形成一个更大的单词表--扩充单词表(将原文当中的单词也加入到其中),该时间步的预测词概率为:

其中 ait 表示的是原文档中的词。我们可以看到解码器一个词的输出概率有其是否拷贝是否生成的概率和决定。当一个词不出现在常规的单词表上时()Pvocab(w) 为0.
这里值得注意的是,如果w是词汇表外(oov)单词,则 Pvocab(w) 为零;。产生OOV单词的能力是指针生成器模型的主要优势之一;通过对比模型,如baseline仅限于其预设词汇,而指针网络则有复制能力,不再局限于预设词汇表 Pvocab.
2.coverage attention
将先前时间步的注意力权重加到一起得到所谓的覆盖向量 ct (coverage vector),用先前的注意力权重决策来影响当前注意力权重的决策,这样就避免在同一位置重复,从而避免重复生成文本。计算上,先计算coverage vector ct

- ct就是一个长度为输入长度的向量
- 第一项是之前时刻输入第一个词attention权重的叠加和
- 加这个参数的目的是为了给attention之前生成词的信息,如果之前生成过这些词那么后续要抑制。抑制通过loss函数加惩罚项实现.
Ct 是对源文档单词的分布,它表示到目前为止这些单词从关注机制接收到的覆盖程度。注意,c0 是一个零向量,因为在第一个时间步骤中,没有覆盖任何源文档。 覆盖向量用作注意机制,将方程式(1)改为:
![]()
改造BahdanauAttention:
class BahdanauAttention(tf.keras.layers.Layer):
def __init__(self, units):
super(BahdanauAttention, self).__init__()
self.W_s = tf.keras.layers.Dense(units)
self.W_h = tf.keras.layers.Dense(units)
self.W_c = tf.keras.layers.Dense(units)
self.V = tf.keras.layers.Dense(1)
def call(self, dec_hidden, enc_output, enc_pad_mask, use_coverage, prev_coverage):
# query为上次的GRU隐藏层
# values为编码器的编码结果enc_output
# 在seq2seq模型中,St是后面的query向量,而编码过程的隐藏状态hi是values。
# hidden shape == (batch_size, hidden size)
# hidden_with_time_axis shape == (batch_size, 1, hidden size)
# we are doing this to perform addition to calculate the score
hidden_with_time_axis = tf.expand_dims(dec_hidden, 1)
if use_coverage and prev_coverage is not None:
# self.W_s(values) [batch_sz, max_len, units] self.W_h(hidden_with_time_axis) [batch_sz, 1, units]
# self.W_c(prev_coverage) [batch_sz, max_len, units] score [batch_sz, max_len, 1]
score = self.V(tf.nn.tanh(self.W_s(enc_output) + self.W_h(hidden_with_time_axis) + self.W_c(prev_coverage)))
# attention_weights shape (batch_size, max_len, 1)
mask = tf.cast(enc_pad_mask, dtype=score.dtype)
masked_score = tf.squeeze(score, axis=-1) * mask
masked_score = tf.expand_dims(masked_score, axis=2)
attention_weights = tf.nn.softmax(masked_score, axis=1)
coverage = attention_weights + prev_coverage
else:
# score shape == (batch_size, max_length, 1)
# we get 1 at the last axis because we are applying score to self.V
# the shape of the tensor before applying self.V is (batch_size, max_length, units)
# 计算注意力权重值
score = self.V(tf.nn.tanh(
self.W_s(enc_output) + self.W_h(hidden_with_time_axis)))
mask = tf.cast(enc_pad_mask, dtype=score.dtype)
masked_score = tf.squeeze(score, axis=-1) * mask
masked_score = tf.expand_dims(masked_score, axis=2)
attention_weights = tf.nn.softmax(masked_score, axis=1)
# attention_weights = masked_attention(attention_weights)
if use_coverage:
coverage = attention_weights
# attention_weights sha== (batch_size, max_length, 1)
attention_weights = tf.nn.softmax(score, axis=1)
# # 使用注意力权重*编码器输出作为返回值,将来会作为解码器的输入
# context_vector shape after sum == (batch_size, hidden_size)
context_vector = attention_weights * enc_output
context_vector = tf.reduce_sum(context_vector, axis=1)
return context_vector,attention_weights, coverage其中 Wc 是和v长度一样的学习参数。这确保注意力机制当前的决定(选择下一个注意点)通过提醒前一个决定而得到通知。即在下一次选择之前,应用了以前注意力的信息,这应该使注意力机制更容易避免重复关注同一地点,从而避免生成重复文本。 定义一个coverage loss 来对同一地点的重复惩罚:
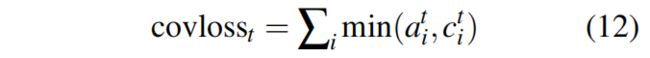
def mask_coverage_loss(attn_dists, coverages, padding_mask):
"""
Calculates the coverage loss from the attention distributions.
Args:
attn_dists coverages: [max_len_y, batch_sz, max_len_x, 1]
padding_mask: shape (batch_size, max_len_y).
Returns:
coverage_loss: scalar
"""
cover_losses = []
# transfer attn_dists coverages to [max_len_y, batch_sz, max_len_x]
attn_dists = tf.squeeze(attn_dists, axis=3)
coverages = tf.squeeze(coverages, axis=3)
for t in range(attn_dists.shape[0]):
cover_loss_ = tf.reduce_sum(tf.minimum(attn_dists[t, :, :], coverages[t, :, :]), axis=-1) # max_len_x wise
cover_losses.append(cover_loss_)
# change from[max_len_y, batch_sz] to [batch_sz, max_len_y]
cover_losses = tf.stack(cover_losses, 1)
# cover_loss_ [batch_sz, max_len_y]
mask = tf.cast(padding_mask, dtype=cover_loss_.dtype)
cover_losses *= mask
# mean loss of each time step and then sum up
loss = tf.reduce_sum(tf.reduce_mean(cover_losses, axis=0))
tf.print('coverage loss(batch sum):', loss)
return losscoverage loss是有边界的,我们假设应该有一个大致一对一的转换率;因此,如果最终覆盖向量大于或小于1,则会受到惩罚。 我们的损失函数更灵活:因为总结不需要统一的覆盖,我们只惩罚到目前为止每个注意力分布和覆盖之间的重叠-防止重复的注意力。最后,在主损失函数中加入由超参数λ重新加权的coverage loss,得到一个新的复合损失函数:
![]()