ResNet 高精度预训练模型在 MMDetection 中的最佳实践
目录
1 前言
2 rsb 和 tnr 在 ResNet50 上训练策略对比
2.1 汇总表
2.2 ResNet baseline 训练技巧详情
2.3 TIMM 训练技巧详情
2.4 TorchVison 训练技巧详情
3 高性能预训练模型在目标检测任务上的表现
3.1 仅替换预训练权重下表现
3.2 ResNet baseline 预训练模型参数调优实验
3.3 mmcls rsb 预训练模型参数调优实验
3.4 TIMM rsb 预训练模型参数调优实验
3.5 TorchVision tnr 预训练模型参数调优实验
4 总结
1 前言
作为最常见的骨干网络,ResNet 在目标检测算法中起到了至关重要的作用。许多目标检测经典算法,如 RetinaNet 、Faster R-CNN 和 Mask R-CNN 等都是以 ResNet 为骨干网络,并在此基础上进行调优。同时,大部分后续改进算法都会以 RetinaNet 、Faster R-CNN 和 Mask R-CNN 为 baseline 进行公平对比。
近期,TIMM 和 TorchVision 都公布了最新的提升 ResNet 性能的训练技巧方案。在 TIMM 中将该方案称为 ResNet Strikes Back (rsb),在 ImageNet 1k 数据集上将 ResNet50 的 top1 准确率从 76.1 提升到 80.4,而 TorchVision 中将其称为 TorchVision New Recipes (tnr),将 top1 准确率提升到了 80.86,两者都提升比较大。
有了如此强的预先训练好的 ResNet 骨干网络,将其应用于下游目标检测任务上是否会带来巨大提升?这是一个非常值得思考的问题。为此,MMDetection 团队通过大量的实验和参数调优给这个问题提供了不错的答案。以 Faster R-CNN 为例,在 COCO Val 数据集上性能表如下所示:
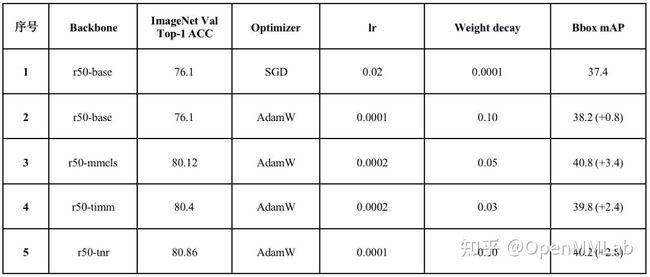
序号 1 是 Faster R-CNN baseline,可以看出基于高精度预训练的 ResNet 模型 r50-mmcls,经过优化器、学习率和权重衰减系数的调优,Faster R-CNN 上 mAP 性能最高能提升 3.4 (r50-mmcls 是指采用 rsb 策略在 MMClassification 上训练出的预训练模型)。同时我们为每一个 backbone 都搜索了一套最优参数,方便用户参考。
2 rsb 和 tnr 在 ResNet50 上训练策略对比
本文将先仔细分析说明 rsb 和 tnr 的训练策略,然后再描述如何在下游目标检测任务中微调从而大幅提升经典检测模型的性能。
2.1 汇总表
首先为了方便查看和对比,我们梳理了如下对比表格:
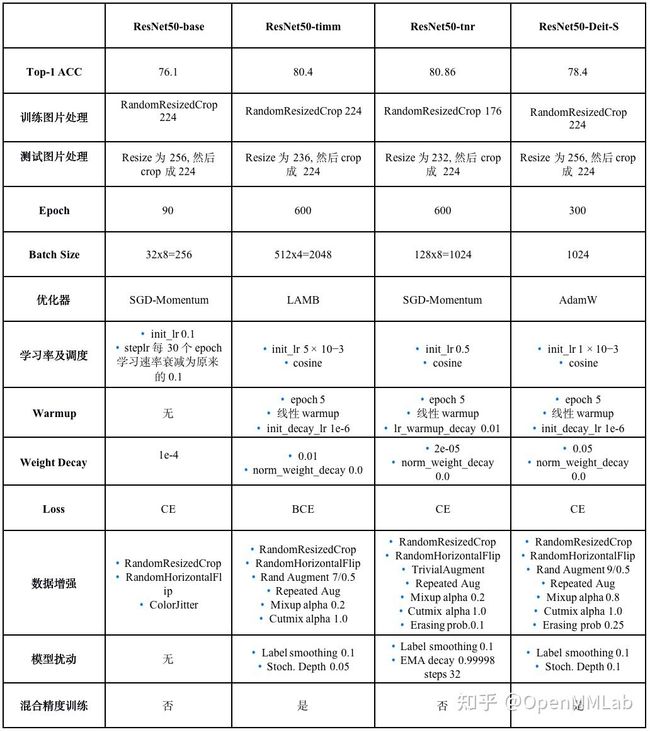
- ResNet50-base 是指 ResNet50 baseline 结果
- ResNet50-rsb 是指 TIMM 提出的 ResNet Strikes Back 策略训练结果,具体是 A1 策略
- ResNet50-tnr 是指 TorchVision 提出的 New Recipe 策略训练结果
- ResNet50-Deit-S 是指 TIMM 中所采用的基于 Deit-S 算法策略来训练 ResNet 的结果,本实验是为了公平对比 DeiT-S 和 ResNet Strikes Back
2.2 ResNet baseline 训练技巧详情
ResNet baseline 即上表的 ResNet50-base 一列。注意 ResNet 由于历史原因有两个版本:ResNet-PyTorch 和 ResNet-Caffe,其差别在于 Bottleneck 模块,Bottleneck 是 1x1-3x3-1x1 堆叠结构,在 caffe 模式模式下 stride=2 参数放置在第一个 1x1 卷积处,而 pyorch 模式下 stride=2 放在第二个 3x 卷积处。一个简单示例如下:
if self.style == 'pytorch':
self.conv1_stride = 1
self.conv2_stride = stride
else:
self.conv1_stride = stride
self.conv2_stride = 1 而此处的 baseline 则是指的 ResNet-PyTorch 。ResNet50是在 ImageNet 1K 训练数据集上从头训练,并在 ImageNet 1K 验证集上计算 top-1 accuracy。其训练技巧如下所示:
- batch size: 32*8, 8卡,每张卡 32 bs
- 优化器: SGD 且 Momentum 为 0.9
- 学习率:初始学习率为 0.1, 每 30 个epoch 学习速率衰减为原来的 0.1
- Epoch 总数:90
- 权重正则: weight decay 为 1e-4
- 训练数据增强
- 随机缩放裁剪(RandomResizedCrop)
- 随机水平翻转(RandomHorizontalFlip)
- 随机颜色抖动 (ColorJitter)
- 图片输入大小:训练和测试时图像大小均为 224
基于上述配置,ResNet50 在 ImageNet 1k 验证数据集上 top-1 accuracy 是 76.1。
2.3 TIMM 训练技巧详情
TIMM 总结了目前最新的训练技巧,并将其应用到 ResNet 中,提出了 ResNet-rsb 版本。其有三个变种,分别对应 epochs 600, 300 和 100,称为 A1、A2 和 A3 版本,如下所示:

- A1 是为了提供 ResNet50 上最佳性能模型
- A2 是为了和 DeiT 进行相似对比(不是完全公平对比,因为 bs/训练 trick 不一样)
- A3 是为了和原始 ResNet50 进行公平对比
作者在三个数据集上进行评估,具体为:
- Val 表示在 ImageNet 1k 验证数据集
- v2 表示 ImageNet 1k v2 版本数据集
以 A1 为例,其训练技巧如下所示:
- batch size: 512x4=2048, 4卡,每张卡 512 bs
- 优化器: LAMB
- 学习率:初始学习率为 5x10^-3, 学习率调度策略采用 consine
- Epoch 总数:600
- 权重正则: weight decay 为 0.01
- Wramup:总共 5 epoch
- 训练数据增强
- 随机缩放裁剪(RandomResizedCrop)
- 随机水平翻转(RandomHorizontalFlip)
- 随机增强 Rand Augment 7/0.5
- Repeated Aug
- Mixup Aug,参数 alpha 0.2
- Cutmix Aug,参数 alpha 1.0
- Loss 不再是采用 CE,而是替换为 BCE
- 训练模型扰动
- Label smoothing,参数 0.1
- Stochastic-Depth, 参数 0.05
- 图片输入大小:
- 训练输入网络的图片大小为 224x224
- 基于 FixRes 策略,将图片 Resize 为 236, 然后 crop 成 224
可以看出,相比 ResNet-base 版本,由于训练 epoch 变长,训练中引入了很多新的数据增强和模型扰动策略。基于上述策略重新训练 ResNet50,在 ImageNet 1k 验证数据集上 top-1 accuracy 是 80.4。除了以上结果,作者还通过实验还得到了其他发现:
- 加入如此多且强的数据增强和模型扰动,虽然可以提升模型性能,但是在网络训练早期收敛速度会很慢
- 如果训练总 batch 为 512 时候,SGD 和 AdamW 都可以收敛,但是当训练的总 batch 为 2048,如果采用 SGD 和 BCE Loss,很难收敛
作者提供的非常详细的对比表如下所示:
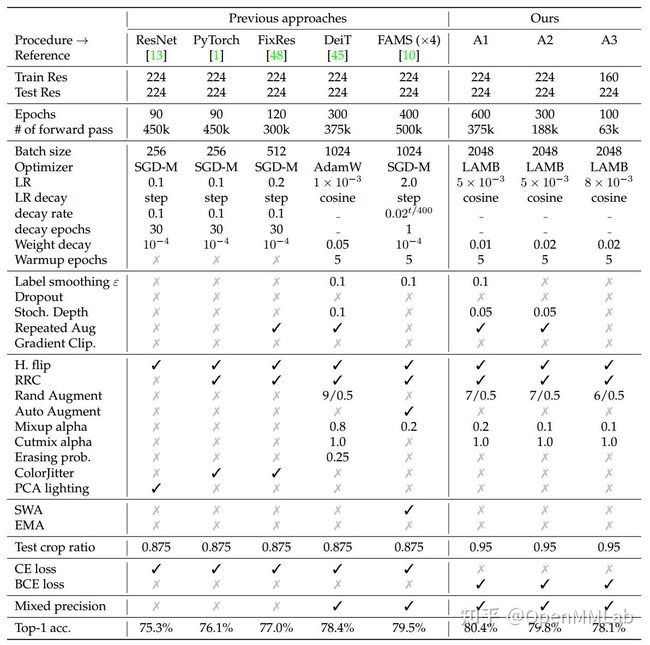
同时,作者还验证 A1、A2 和 A3 这套设置在不同架构下的泛化能力。
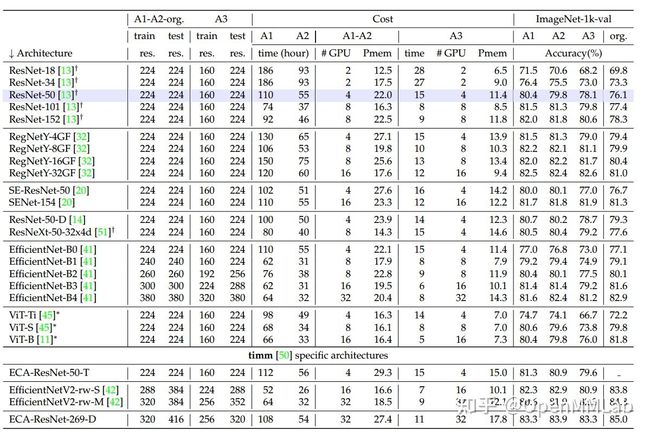
其中加号表示 TorchVision 结果,而 ∗ 来自 DeiT 结果。
作者还对 ResNet-50 和 Deit-S 两者进行了对比,性能如下:
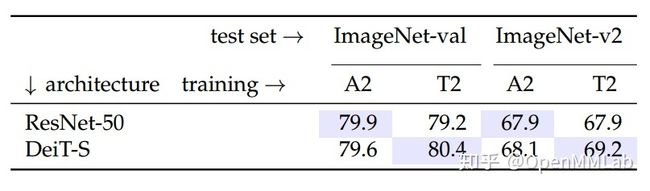
2.4 TorchVison 训练技巧详情
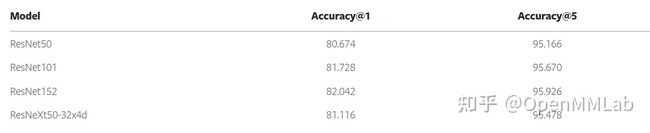
TorchVision 也推出了自己的训练技巧,其官方推文中有详细说明,其余相关讨论见 https://github.com/pytorch/vision/issues/3911,最终结果如下所示:
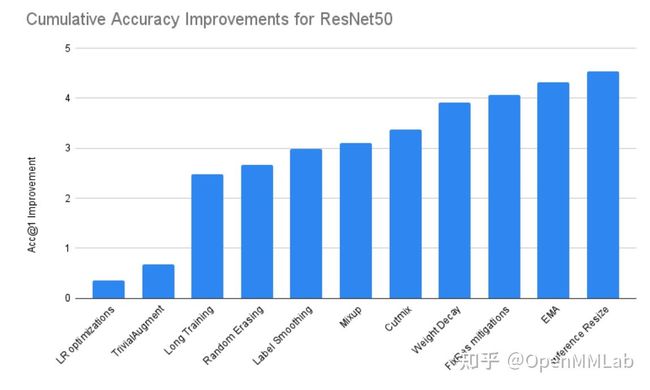
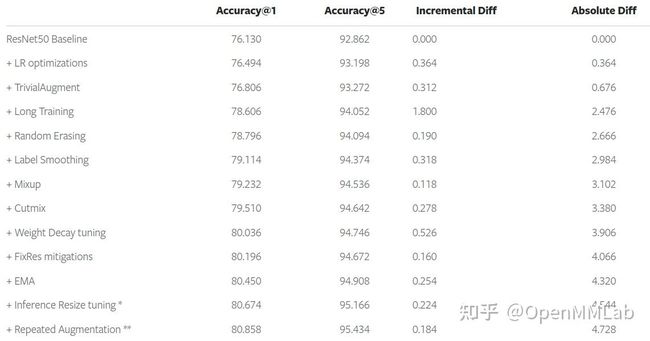
作者还贴心地绘制了每个 trick 所带来的提升,如下所示:
训练技巧汇总:
- batch size: 128x8=1024, 8卡,每张卡128 bs
- 优化器: SGD 且 Momentum 为 0.9
- 学习率:初始学习率为 0.5, 学习率调度策略采用 consine
- Epoch 总数:600
- 权重正则: weight decay 为 2e-05,且 norm 不进行 decay
- Wramup:总共 5 epoch,采用线性 warmup,lr_warmup_decay 为 0.01
- 训练数据增强
- 随机缩放裁剪(RandomResizedCrop)
- 随机水平翻转(RandomHorizontalFlip)
- TrivialAugment
- Mixup,参数 alpha 为 0.2
- Cutmix,参数 alpha 为 1.0
- 随机擦除 (Random Erase),概率参数为 0.1
- 训练模型扰动
- Label smoothing,参数 0.1
- EMA,decay 参数为 0.99998,每隔 32 次迭代更新一次
- 图片输入大小:
- 训练输入网络的图片大小为 176x176
- 基于 FixRes 策略,对图片 Resize 为 232, 然后 crop 成 224
可以看出,rsb 和 torchvision 所提策略的重点都在于引入强的 aug、更多的模型扰动已经更长的训练 epoch。除此之外,作者还通过实验还得到了其他发现:
- 使用一些更复杂的优化器,例如 Adam、RMSProp 和 SGD with Nesterov momentum,发现效果不会更好,但是作者没有实验 LAMB
- 作者尝试了不同的 LR 调度器方案,例如 StepLR 和 Exponential。 尽管后者倾向于与 EMA 一起更好地工作,但它通常需要额外的超参数,例如定义最小 LR 才能正常工作,所以作者最终还是采用了对超参不那么敏感的 cosine
- 作者尝试了不同的增强策略,例如 AutoAugment 和 RandAugment,但是这些都没有优于更简单的无参数 TrivialAugment
- 使用双三次或最近邻插值并没有提供比双线性更好的结果
- 使用 Sync Batch Norm 并没有比使用常规 Batch Norm 产生明显更好的结果
- Mixup 和 Cutmix 两者配合使用时可以采用等概率的随机选择一种的方式,单独采用 Mixup 可以提升0.118,配合 Cutmix 可以额外提升 0.278
- FixRes 中作者发现,训练时采用 176 图片尺寸,测试采用 272 尺寸效果最好,不过作者还是采用 224 ,目的是为了 baseline 保持一致,而如果训练时候采用 224 尺寸,测试采用 256 效果最好
3 高性能预训练模型在目标检测任务上的表现
本节探讨高性能预训练模型在目标检测任务上的表现。本实验主要使用 COCO 2017 数据集在 Faster R-CNN FPN 1x 上进行。具体设置请参考 MMDetection 配置文件 。
# https://github.com/open-mmlab/mmdetection/blob/master/configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py
_base_ = [
'../_base_/models/faster_rcnn_r50_fpn.py',
'../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
] 几个核心配置为:
- 8 卡训练,总 batch size 为 16
- 1x 训练时长即 12 epoch
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001) - 优化器相关配置是: SGD+ 0.9 momentum,lr 为 0.02,weight_decay 为 0.0001
如果想理解 Faster R-CNN 代码及其配置参数等细节信息可以参考 轻松掌握 MMDetection 中常用算法(二):Faster R-CNN|Mask R-CNN 一文。
3.1 仅替换预训练权重下表现
为了快速评估不同性能的预训练权重在 Faster R-CNN FPN baseline 配置下的性能,我们直接替换预训练权重,验证在 Faster R-CNN 上的性能,结果如下所示:
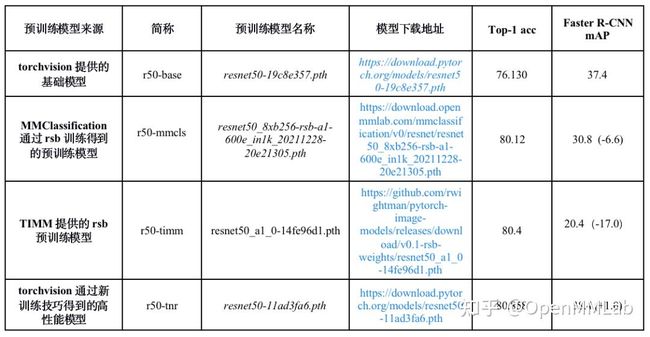
模型下载链接:
https://download.pytorch.org/models/resnet50-19c8e357.pth
https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb256-rsb-a1-600e_in1k_20211228-20e21305.pth
https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-rsb-weights/resnet50_a1_0-14fe96d1.pth
https://download.pytorch.org/models/resnet50-11ad3fa6.pth
需要说明的是,为了保证实验的公平性,我们在实验中设置了随机种子 (Seed=0),全部实验均在 8 x V100上进行,batch size = 16(8×2)。
从上表可以看出:替换成高精度的预训练权重的 ResNet 后,Faster R-CNN 没有显著提升甚至有些性能下降非常严重,这说明高精度预训练的 ResNet 可能不再适合用同一套超参,故而非常有必要对其进行参数调优。主要可能因为预训练模型的训练策略调整使 SGD 优化器不能很好适应预训练模型。因此我们计划通过调整优化器、学习率和权重正则来对检测器进行微调。
3.2 ResNet baseline 预训练模型参数调优实验
由于 ResNet Strikes Back 中使用 AdamW 优化器来训练,我们尝试在目标检测下游任务中使用 AdamW 作为优化器,希望能够达到和使用 SGD 优化器相同的测试精度。
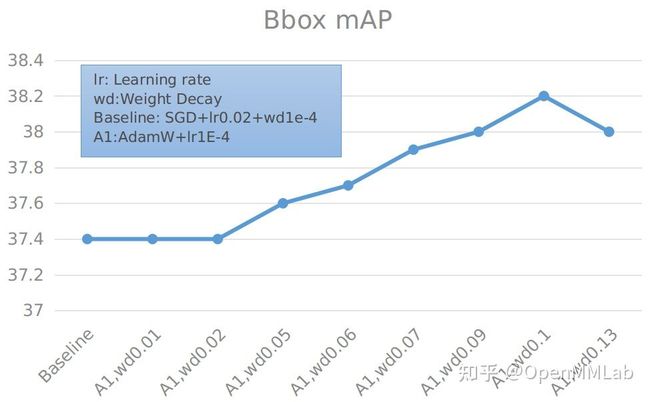
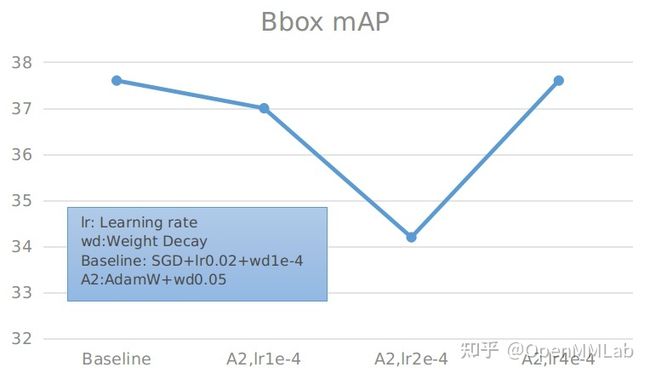
具体细节可见下表:
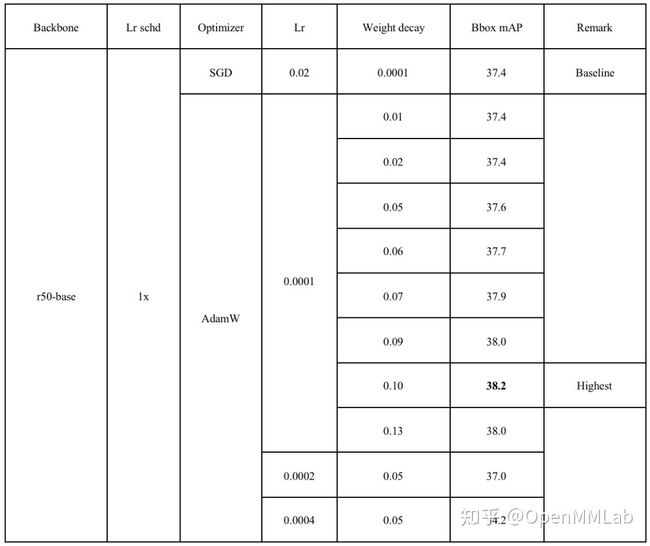
可以看到,在使用 AdamW 优化器,学习率为 0.0001 时,整体精度均可以超过 SGD 优化器,而在权重正则为 0.1 时,性能最优。
3.3 mmcls rsb 预训练模型参数调优实验
通过修改配置文件中预训练模型,我们可以将 ResNet 的预训练模型替换为 MMClassification 通过 rsb 训练出的预训练模型。在此基础上,我们分别通过 AdamW 与 SGD 来训练 Faster R-CNN ,从而获得 MMClassification 通过 rsb 训练出的预训练模型在检测任务上的效果。MMDetection 中配置文件写法为:
_base_ = [
'../_base_/models/faster_rcnn_r50_fpn.py',
'../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
checkpoint = 'https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb256-rsb-a1-600e_in1k_20211228-20e21305.pth' # noqa
model = dict(
backbone=dict(
init_cfg=dict(
type='Pretrained', prefix='backbone.', checkpoint=checkpoint)))
# 此处配置参数是最佳性能参数
optimizer = dict(
_delete_=True,
type='AdamW',
lr=0.0002,
weight_decay=0.05,
paramwise_cfg=dict(norm_decay_mult=0., bypass_duplicate=True)) 基于上一小节的先验,我们首先使用 AdanW 为优化器,学习设置为 0.0001。
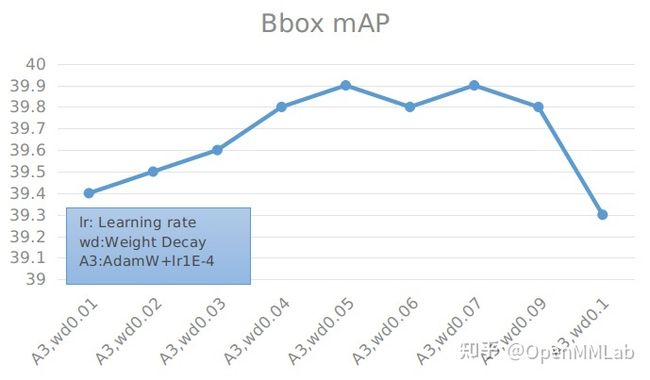
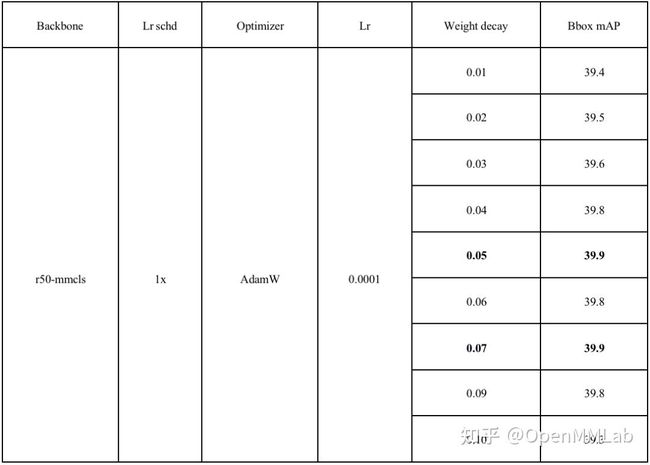
具体数值见下表:
为了验证学习率对精度的影响,我们做了学习率验证实验。
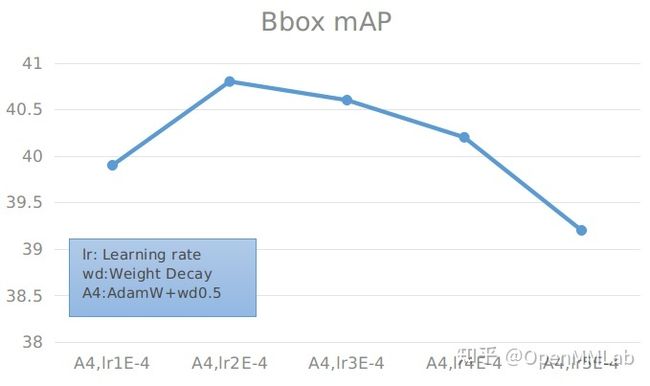
具体数值见下表:
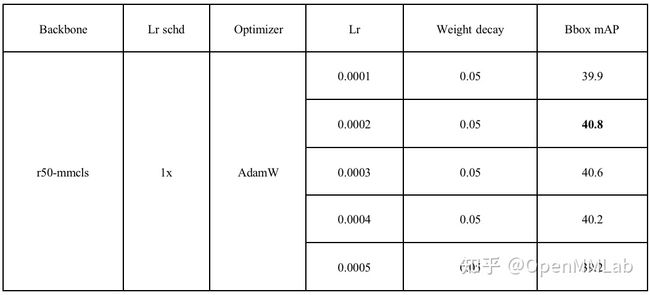
基于上述实验,我们发现在学习率为 0.0002 时,检测精度明显提高,因此我们设置了学习率为 0.0002 的对照实验:
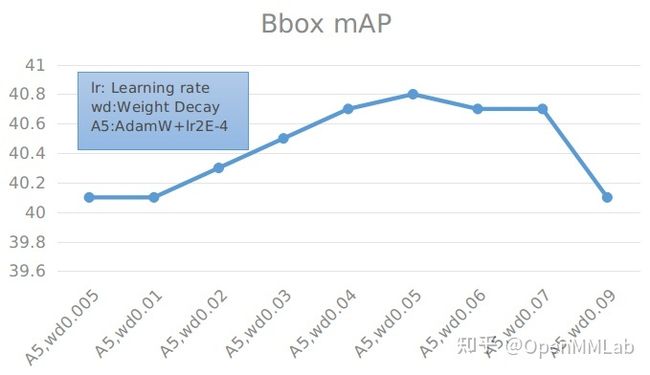
具体数值见下表:
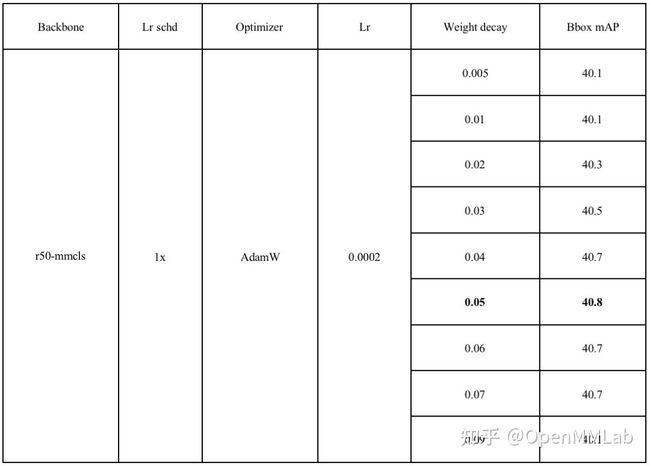
能够看到,在 lr=0.0002, weight decay=0.05 时,精度最高。同时也可以发现,weight decay 在某一个区间范围内对精度的影响不会很大,一旦超过这个区间,精度会下降明显。
3.4 TIMM rsb 预训练模型参数调优实验
接下来,我们将 ResNet 的预训练模型替换为 PyTorch Image Models (TIMM) 的模型。在此基础上,我们通过 AdamW 来训练 Faster R-CNN ,从而获得 TIMM 预训练模型在检测任务上的效果。MMDetection 中的配置写法如下所示:
_base_ = [
'../_base_/models/faster_rcnn_r50_fpn.py',
'../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
checkpoint = 'https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-rsb-weights/resnet50_a1_0-14fe96d1.pth' # noqa
model = dict(
backbone=dict(
init_cfg=dict(
type='Pretrained', checkpoint=checkpoint)))
# 此处配置参数是最佳性能参数
optimizer = dict(
_delete_=True,
type='AdamW',
lr=0.0002,
weight_decay=0.03,
paramwise_cfg=dict(norm_decay_mult=0., bypass_duplicate=True))
基于上述微调先验信息,我们首先分别固定学习率为 0.0001 和 0.0002 ,调整 weight decay。实验结果如下:
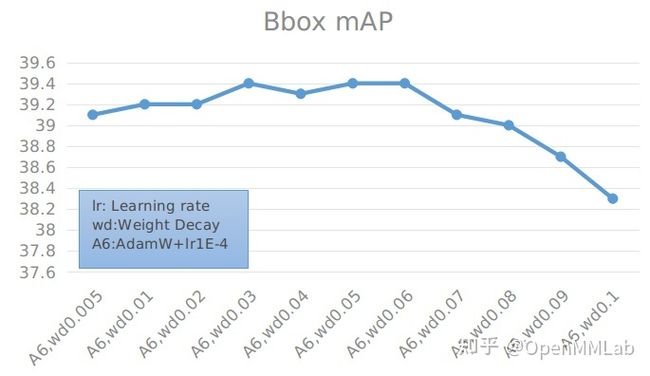
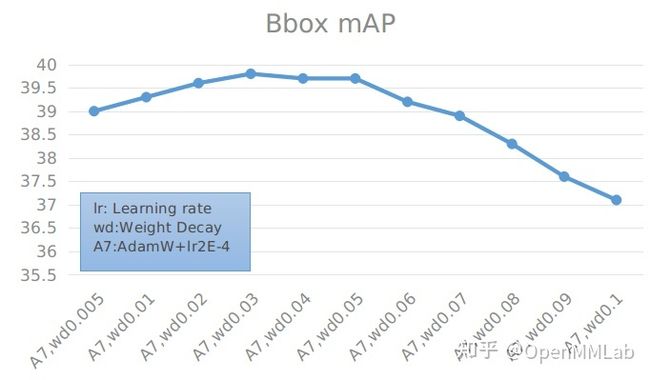
具体数值见下表:
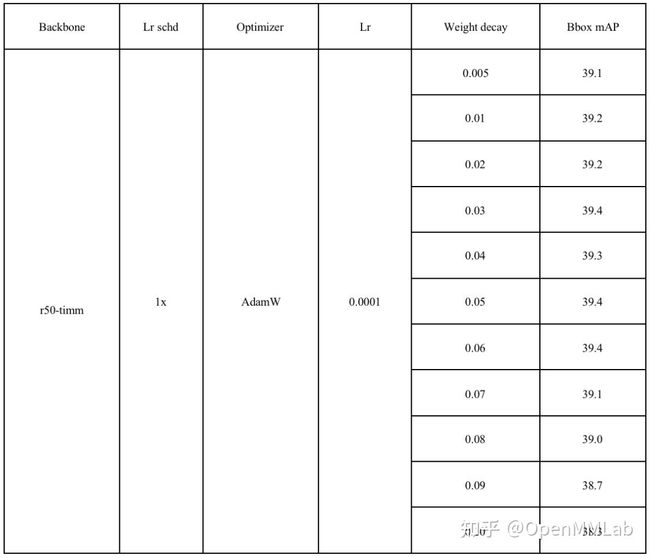
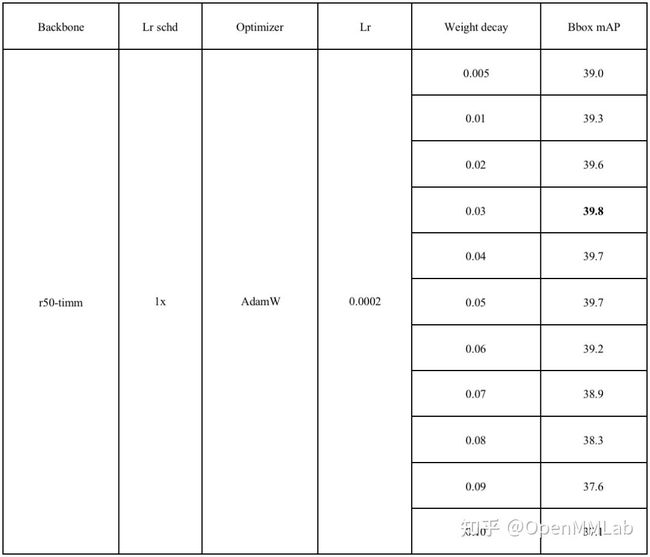
可以看到,尽管相比于基础的 Bbox mAP=37.4,有了一定的提高,最高能够达到 39.8。但是相比于使用 mmcls 的预训练模型得到的最高 Bbox mAP = 40.8 还是有一定的差距。之后我们还调整学习率来观察结果:
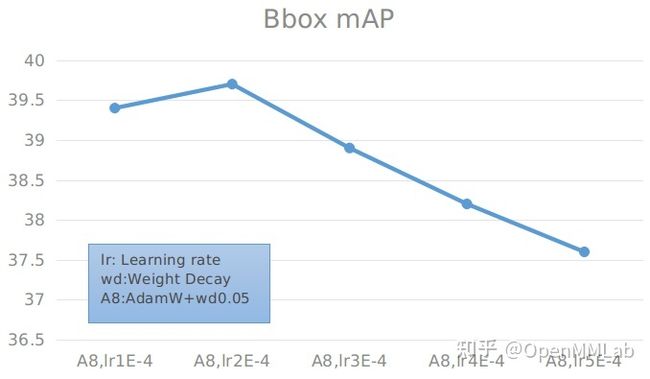
具体数值见下表:
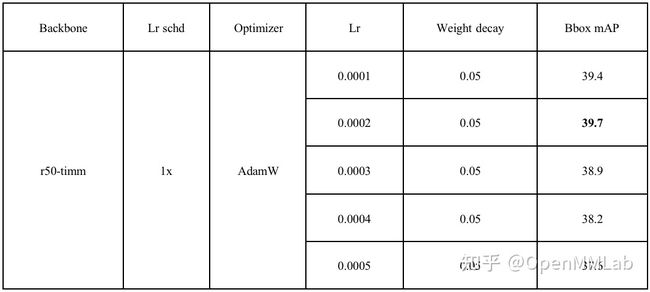
综合前面结果,能够看到,AdamW 在学习率为 0.0001 和 0.0002 时精度差距不大,超过 0.0003 后,精度会明显下降。
3.5 TorchVision tnr 预训练模型参数调优实验
最后,我们还将 ResNet 的预训练模型替换为 TorchVision 通过新技巧训练出来的高精度模型,并分别通过 SGD 与 AdamW 来训练 Faster R-CNN,从而获得 TorchVision 通过新技巧训练出来的高精度模型在检测任务上的效果。MMDetection 中配置文件写法如下所示:
_base_ = [
'../_base_/models/faster_rcnn_r50_fpn.py',
'../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
checkpoint = 'https://download.pytorch.org/models/resnet50-11ad3fa6.pth'
model = dict(
backbone=dict(
init_cfg=dict(
type='Pretrained', checkpoint=checkpoint)))
# 此处配置参数是最佳性能参数
optimizer = dict(
_delete_=True,
type='AdamW',
lr=0.0001,
weight_decay=0.1,
paramwise_cfg=dict(norm_decay_mult=0., bypass_duplicate=True))
我们首先使用 SGD 算法来优化 Faster R-CNN,并尝试搜索最优的学习率与 weight decay:
SGD 算法下固定 weight decay 搜索最优 learning rate 实验
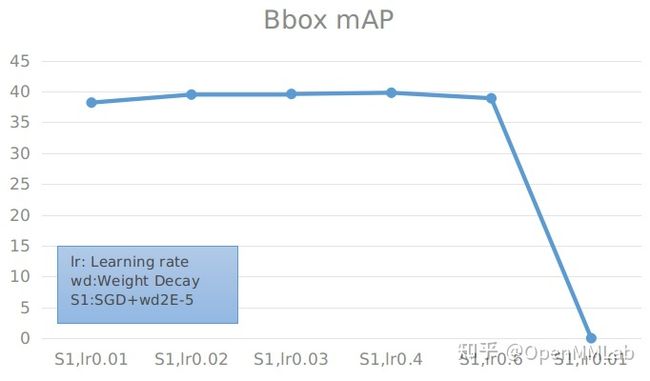
具体数值见下表:

SGD 算法下固定 learning rate 搜索最优 weight decay 实验

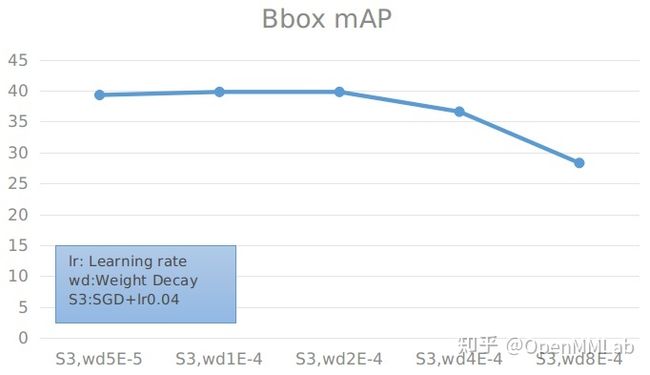
具体数值见下表:

根据实验结果可以看到,当保持训练参数一致,仅将预训练模型换为 TorchVision 的高精度预训练模型可以使精度上涨 2.2(37.4 -> 39.6) 个点。当学习率为 0.04,weight decay 为 0.00001 时,使用 r50-tnr 作为预训练模型,在 SGD 算法下优化的 Faster R-CNN 可以达到最高的 39.8% mAP 的结果。
接下来,我们尝试使用 AdamW 算法优化模型:
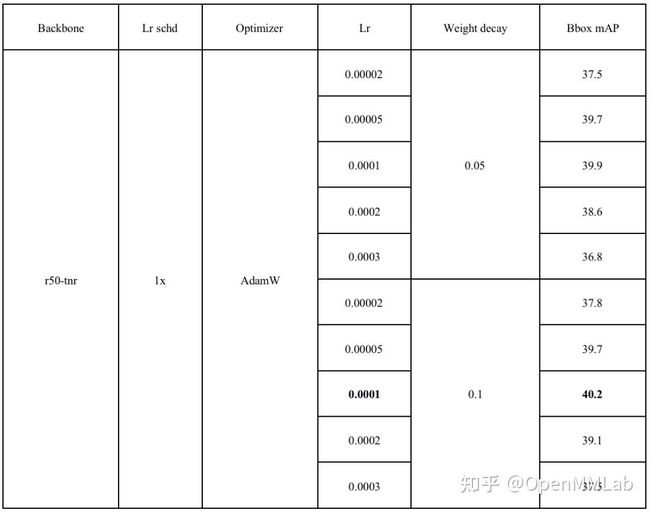
AdamW 算法下固定 weight decay 搜索最优 learning rate 实验


具体数值见下表:
AdamW 算法下固定 learning rate 搜索最优 weight decay 实验
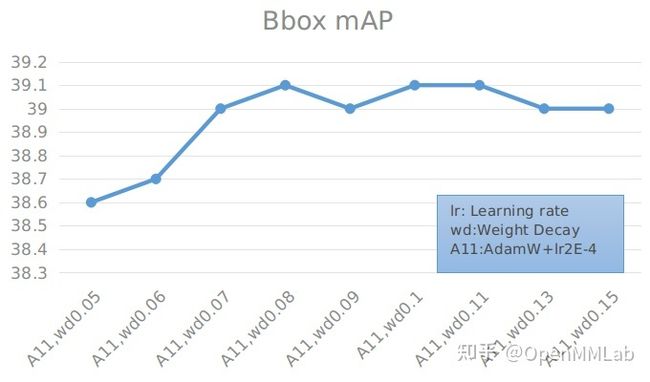
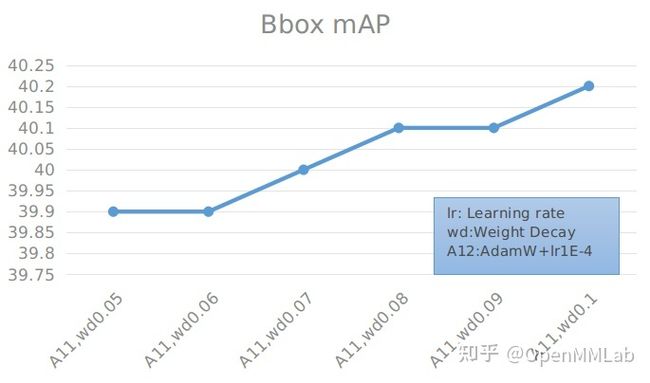
具体数值见下表:

通过实验可以得出,在使用 AdamW 优化器时,学习率为 0.0001 的效果要比 0.0002 好上很多。而 weight decay 在 0.1 左右达到最高,其变化对最终的结果影响不大。当学习率使用 0.0001,weight decay 为 0.1 时,加载 r50-tnr 的 Faster R-CNN 达到最大精度的 40.2% mAP,相比于 SGD 上升了 0.4 (39.8 -> 40.2)。
4 总结
通过之前的实验,我们可以看出使用高精度的预训练模型可以极大地提高目标检测的效果,所有预训练模型最高的结果与相应的参数设置如下表所示:
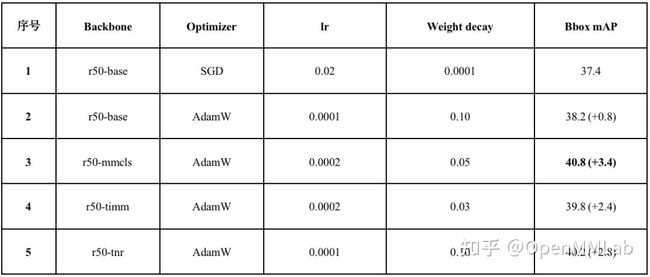
从表格中可以看出,使用任意高性能预训练模型都可以让目标检测任务的性能提高 2 个点左右。其中使用 MMClassification 训练出来地高精度模型使 Faster R-CNN 增长了 3.4 个点,达到了最高的 40.8% mAP,这证明使用高性能预训练模型对目标检测任务有极大地帮助。
如果你想复现或者进一步实验,可以参考相关的配置文件和 PR
- TorchVision 高精度模型配置和 PR:https://github.com/open-mmlab/mmdetection/blob/master/configs/faster_rcnn/README.md#torchvision-new-receipe-tnr
- TIMM 高精度模型配置:https://github.com/open-mmlab/mmdetection/blob/master/configs/resnet_strikes_back/README.md
欢迎大家来 MMDetection 体验,感谢 MMClassification 团队对本文内容的仔细校对!
如果我们的分享给你带来一定的帮助,欢迎点赞收藏关注,比心~
