联邦学习-论文阅读-Incentive Mechanism for Reliable Federated Learning: A Joint Optimization Approach to Comb
Incentive Mechanism for Reliable Federated Learning: A Joint Optimization Approach to Combining Reputation and Contract Theory
1、概要
针对本地节点(worker)有意无意的恶意更新行为,找出一个公平的指标来评估本地节点的可靠性,从而选出每轮参与聚合的高质量节点。本文通过声誉作为衡量标准来评估联邦学习中节点的可靠性,以此高声誉的节点拥有高质量的数据,从而其上传的本地模型更新更加可靠及具有更高的质量。
对于声誉的计算方法,利用一个多权重的主观逻辑模型来有效地计算工人的声誉,并通过联盟区块链以分散的方式管理声誉。
利用契约理论(contract theory)设计了一种有效的激励机制,以激励拥有高质量数据的高声誉员工参与模型培训,从而防止联邦学习中的中毒攻击。
节点的可靠性,从而选出每轮参与聚合的高质量节点。本文通过声誉作为衡量标准来评估联邦学习中节点的可靠性,以此高声誉的节点拥有高质量的数据,从而其上传的本地模型更新更加可靠及具有更高的质量。
对于声誉的计算方法,利用一个多权重的主观逻辑模型来有效地计算工人的声誉,并通过联盟区块链以分散的方式管理声誉。
利用契约理论(contract theory)设计了一种有效的激励机制,以激励拥有高质量数据的高声誉员工参与模型培训,从而防止联邦学习中的中毒攻击。
2、动机
有意和无意行为都会降低局部数据精度和局部模型更新质量,从而对全局模型的精度和收敛时间产生负面影响;因此,为联邦学习设计一个可靠的工作者选择方案(激励+选择)()
3、细节
恶意更新产生的原因:设备被恶意篡改(有意)、通过不安全的通信通道传输数据(无意)
联邦学习框架仍为中心化的,对于声誉管理采取区块链的方式进行去中心化的存储及管理。
框架结构:
(1)任务发布者发布任务和契约项:任务发布者首先根据学习任务的数据和计算资源需求设计契约项,满足要求的移动设备可以成为参加联合学习任务的模型培训工作者候选人。
(2)计算候选人声誉:任务发布者根据资源信息选择合格的工作人员候选人。然后,任务发布者根据(i)来自交互历史的直接声誉意见和(ii)来自其他任务发布者的间接声誉意见(即推荐的声誉意见),通过多权重主观逻辑模型计算候选员工的声誉值。推荐的声誉意见在开放访问声誉区块链上存储和管理。
(3)选择员工进行联邦学习:声誉计算后,声誉大于阈值的员工候选人可以被选为员工。这些工作人员根据与本地数据集的准确性和资源条件相关的类型,自行做出最佳决策,以选择任务发布者给出的合同项。
(4)评估本地模型更新的质量:(本文根据模型的准确率来评估其本地质量)任务发布者通过攻击检测方案对本地模型更新进行质量评估。对于IID的数据场景有RONI方案[1](通过比较本地模型更新和不更新对任务发布者预定义数据库的影响(验证集)来验证本地模型更新。如果数据库上本地模型更新的性能下降超过系统给定的指定阈值,则在集成所有本地模型更新时,将拒绝此本地模型更新),对non-IID的数据场景有FoolsGold[2]方案(non-IID联邦学习中,由于每个工人的训练数据具有唯一的分布,所以FoolsGold方案根据局部模型更新的梯度更新多样性来识别不可靠工人。不可靠的工作人员在每次迭代中反复上传类似的外观梯度作为局部模型更新,可以被检测到);选择合适的节点更新进行模型聚合,并采取适当的激励机制对选择的节点进行奖励,并为所有的节点生成直接的声誉意见。
(5)将声誉意见更新到声誉区块链:在完成联合学习任务后,任务发布者根据交互历史更新其对交互工作人员的直接声誉意见。这些带有工人数字签名的声誉意见被记录为“交易”,并上传到声誉区块链的矿工。矿工们将声誉意见放入一个数据块中,并在块验证和执行共识方案(如实用拜占庭容错(PBFT))后将该块添加到声誉区块链中。
步骤二中的基于多权重主观逻辑的声誉计算
A、主观逻辑的声誉观点表示
(1)基于主观逻辑模型[5,6,7]有(第i个任务发布者对第j个节点在时间窗![]() 内的声誉评价):
内的声誉评价):
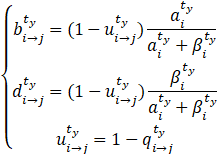
分别代表发布者认为节点可信、不可信、不确定时的声誉表示,且三者和为1,
即![]()
![]() 为传输成功的概率,
为传输成功的概率,![]() (
(![]() )分别为
)分别为![]() 时间内的正(负)相互作用数量
时间内的正(负)相互作用数量
故第i个任务发布者对第j个节点在时间窗![]() 内的声誉评价可以定义为:
内的声誉评价可以定义为:
![]()
![]() 为确定程度的系数
为确定程度的系数
(2)为了阻止负的相互作用时间,定义正负相互作用事件的权重为![]()
,且![]() ,则改写声誉表达:
,则改写声誉表达:
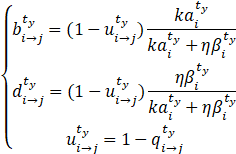
(3)考虑到随着时间淡化,越久远的声誉评价对现在的声誉表达影响越低:
![]() ,z为淡化系数
,z为淡化系数
故第i个任务发布者对第j个节点在时间窗![]() 内的声誉评价可以重新定义为:
内的声誉评价可以重新定义为:

B、加权其他发布者对其的声誉评价
C、将直接声誉意见与推荐声誉意见相结合
步骤四中的激励机制:
为什么要设计激励机制:
- 由于缺乏先验知识,任务发布者不知道哪些移动设备希望加入模型培训。
- 任务发布者不知道工作人员的准确信誉值和本地数据质量。
- 任务发布者不知道模型培训工人提供的可用计算资源量和数据大小。
因此,任务发布者在向移动设备提供激励时可能会承受太多的成本。为了减少信息不对称的影响,任务发布者必须设计有效的激励机制。
A、计算模型(一次本地迭代所需的能耗)
![]()
![]() 为第n个节点的有效电容参数,
为第n个节点的有效电容参数,![]() 执行一个数据样本的的cpu周期,
执行一个数据样本的的cpu周期,![]() 为cpu周期频率,
为cpu周期频率,![]() 为本地数据样本大小。
为本地数据样本大小。
B、通信耗能(一个全局迭代的总耗能)
- 当本地模型的的精度较大时,可以减少本地及全局的迭代次数。
- 全局的精度固定时,可以计算本地迭代次数为
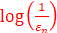 。[9,10]
。[9,10] - 一轮全局迭代的时间为本地模型训练的时间及模型上传的通信时间(Flchain中后者应该为客户端到区块链节点之间的通信成本以及共识的时间成本)
(1、本地迭代时间)
![]()
(2、通信时间)
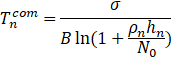
(3、通信耗能)
![]()
(4、一次全局迭代中中,本地节点n的总耗时)
![]()
(5、根据通信时间可以推出通信能耗,即![]() 之间的关系)
之间的关系)
![]()
其中![]() 为本地精度(代表了第n个客户端的本地数据质量),
为本地精度(代表了第n个客户端的本地数据质量),![]() 为传输更新时的能耗。
为传输更新时的能耗。
C、任务发布者的利润函数
(1、定义不同本地节点数据的质量,将模型的分为n类)
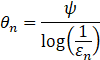
![]() 为受本地精度影响的局部模型迭代次数的系数(),可对不同的节点的模型质量进行量化,即
为受本地精度影响的局部模型迭代次数的系数(),可对不同的节点的模型质量进行量化,即![]() ,(总共N个本地节点,则一共有N类的节点,即本地节点n的模型质量类型不一定为类型n,即
,(总共N个本地节点,则一共有N类的节点,即本地节点n的模型质量类型不一定为类型n,即![]() )。θn
)。θn![]() 越高代表本地模型的质量越高,故可以减少其本地训练的次数[11,12](减少其计算资源的消耗、减少本地训练时间等,可以合理分配每个本地节点训练的迭代次数从而降低一轮训练时长)。
越高代表本地模型的质量越高,故可以减少其本地训练的次数[11,12](减少其计算资源的消耗、减少本地训练时间等,可以合理分配每个本地节点训练的迭代次数从而降低一轮训练时长)。
对上面质量的定义,可以通过对每个节点以前的历史行为(?),估计每个节点属于哪个质量的概率,即有n=1Npn=1![]() 。(即现在对于一个本地节点n(
。(即现在对于一个本地节点n(![]() )只能知道一个分布:(
)只能知道一个分布:(![]() )(?)
)(?)
(其θn![]() 类型可以根据其他选取出来的可信节点共同确定)
类型可以根据其他选取出来的可信节点共同确定)
由于信息不对称(任务发布者不知道节点的数据质量、计算能力、参与意愿等),任务发布者应该为数据质量不同的不同本地节点设计特定的合同(Contract Theory),以增加其利润,从而为不同的节点提供不同的奖励。
(2、设计契约)
设计的契约为:![]() ,
,![]() 为第n个节点的计算资源,设计的契约为节点根据其提供的计算资源获得相应的回报,
为第n个节点的计算资源,设计的契约为节点根据其提供的计算资源获得相应的回报,![]() 为节点得到的奖励。
为节点得到的奖励。
(3、任务发布者的利润函数,对本地节点n)
![]()
其中ω>0![]() 为一个参数代表任务发布者的满意度,
为一个参数代表任务发布者的满意度,![]() 为一轮联邦学习的最大容忍时间,l
为一轮联邦学习的最大容忍时间,l![]() 为给节点奖励的单位成本。
为给节点奖励的单位成本。![]() 可以理解为对节点n一次全局迭代总时间的满意度函数,即其迭代时间越短对其越满意[8](可扩展)(从Tnt
可以理解为对节点n一次全局迭代总时间的满意度函数,即其迭代时间越短对其越满意[8](可扩展)(从Tnt![]() 可知提高本地精度,减少迭代时间都可以提高任务发布者对其的满意度,以此发布者收益越大,从而可以给参与方即本地节点提供更多的奖励)。
可知提高本地精度,减少迭代时间都可以提高任务发布者对其的满意度,以此发布者收益越大,从而可以给参与方即本地节点提供更多的奖励)。
(4、任务发布者的目标:最大化其利润)(从所有节点,从其获得最大化利润)(?)
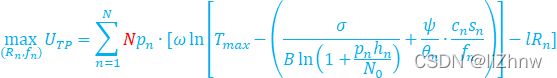
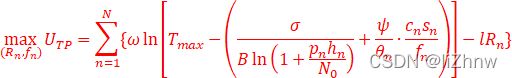
(对于上式,因为任务发布者不知道本地节点n的质量具体为哪个(即上面分类中的不知道节点n的质量属于哪个类型),故其目标函数中,只能知道其本地质量的类型分布,既不能确定的知道本地节点i的质量为类型j,故为![]() )(?)
)(?)
 为从类型n获得利润,
为从类型n获得利润,![]() 为N个节点中有这么多个类型n的节点)
为N个节点中有这么多个类型n的节点)
D、节点n的利润函数
知一个节点可以根据其提供资源获得回报,即通过签订的契约获得相应的报酬![]()
故可以定义第n个本地节点的利润函数(![]() 为其贡献的计算资源):
为其贡献的计算资源):
![]()
其中![]() 是能耗的预定义权重参数;当
是能耗的预定义权重参数;当![]() 为0是,认为
为0是,认为![]() 为0(即没有报酬,则利润为0)
为0(即没有报酬,则利润为0)
以此根据契约理论知道,对应数据质量的节点签订对应的契约获得对应的报酬,节点的质量越高其获得的报酬越多,利润越大,故对于恶意节点其上传恶意的更新获得的报酬很低。基于契约理论:可以激励高质量的节点加入联邦学习(恶意节点也可以加入训练过程,但其不会获得很高的报酬,可以通过节点选择方案剔除不良节点)
(1、节点n的目标:最大化其利润,最小化其能耗)(通过其提供高质量模型,减少本地迭代次数来减少其能耗)
![]()
E、最优化契约设计
为了实现任务方以及本地参与方的利益最大化,两个约束条件:个人理性(Individual Rationality)、激励相容性(ncentive Compatibility)
个人理性:即参与方的利润应该大于0
![]()
激励相容性:为了实现最大化利润,基于契约理论,每个节点只能选取为其设计的契约(即根据本地模型的精度),即拥有![]() 计算资源的节点只能获得
计算资源的节点只能获得![]() 的奖励,而不能去获取为m节点设计的契约
的奖励,而不能去获取为m节点设计的契约![]() 中的
中的![]() ,即:
,即:
![]()
(即为n节点设计的契约得到的利润最大,若使用其他人的契约,其利润不可能超过![]() )中获得的利润)
)中获得的利润)
本文定义![]() ,且通信时间一致,即
,且通信时间一致,即![]() ,将任务发布者和参与方的目标函数合并:
,将任务发布者和参与方的目标函数合并:
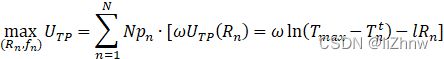
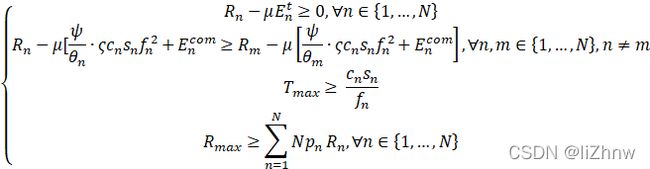
其中Rmax![]() 为发出去的奖励总和
为发出去的奖励总和
上述为非凸规划问题
转为凸规划问题()
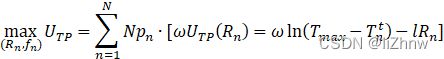
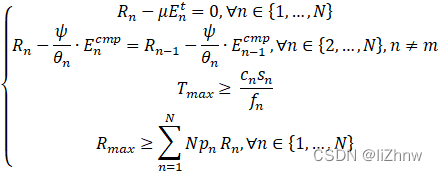
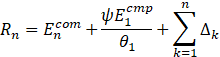
θn![]() 用来评判第n个节点数据的质量,数值越大质量越高;ψ
用来评判第n个节点数据的质量,数值越大质量越高;ψ![]() 为受本地精度影响的系数;其中
为受本地精度影响的系数;其中![]() ,Δ1=0
,Δ1=0![]() 。
。
实验部分:
看不下去了qaq