3D语义分割——PVD
PVD(
CVPR2022)主要贡献:
- 研究了如何将知识蒸馏应用于 3D 点云语义分割中从而进行模型压缩
- 提出
point-to-voxel的知识蒸馏,从而应对点云数据稀疏(sparsity)、随机(randomness)和变化密度(varying density)的固有属性- 提出了超体素(
supervoxel)划分方法,使affinity distillation过程易于操作- 提出
difficulty-aware的采样策略,使包含少数种类(minority classes)和远处物体(distant objects)的超体素更容易被采样到,从而提高这些较难处理的物体的蒸馏效果(distillation efficacy)
PVD 在 nuScenes 和 SemanticKITTI 这两个流行的 LiDAR 分割基准上进行了广泛的实验,其在 Cylinder3D、SPVNAS 和 MinkowskiNet 这三个有代表性的骨干上,始终以较大的优势胜过以前的蒸馏方法。值得注意的是,在具有挑战性的 nuScenes 和 SemanticKITTI 数据集上,它可以在具有竞争力的 Cylinder3D 模型上实现大约 75% 的 MACs 减少和 2 倍的速度提升,在 Waymo 和 SemanticKITTI(single-scan)挑战中排名第一,在 SemanticKITTI(multi-scan)挑战中排名第三。
网络结构
下图以 Cylinder3D 为例描述 PVD 的网络结构,其包含教师(teacher)和学生(student)这 2 个网络。其中,学生网络的每一层通道数为教师网络的一半,而教师网络主要由 5 部分组成,分别是点特征提取模块( point feature extraction module)、体素化模块(point-to-voxel transformation module)、编解码器模块(encoder-decoder module)、DDCM 模块、点优化模块(point refinement module)

- 将输入的点云划分到固定数量的超体素中,并根据
difficulty-aware采样策略来采样K个超体素(图中K=1,由红框标注出来) - 将采样到的超体素送入点特征提取模块(
MLPs)中,得到pointwise的输出 - 通过体素化模块将
pointwise的输出进行体素化 - 体素化后的数据再输入编解码器模块(使用非对称三维卷积网络)得到
voxelwise输出 - 体素再经过
DDCM模块来捕获高秩的上下文特征,从而有足够的能力来捕获上下文信息 - 将上下文特征送入点优化模块(
MLPs)中得到pointwise的输出,从而预测相关的语义信息
✍️在知识蒸馏的架构中,学生网络需要从教师网络中学习两个层次的知识,第一个层次是 pointwise 和 voxelwise 的输出,第二个层次是 inter-point 和 inter-voxel 的 affinity matrix。关于 Cylinder3D 的相关简介可参考我之前的一篇博客【3D 语义分割——Cylinder3D】
Point-to-Voxel Output Distillation
相比于图像数据,点云本身具有稀疏性,从而导致较难通过稀疏的监督信号来训练一个有效的学生网络。此外,尽管点云数据包含细粒度的环境的感知信息,但由于点云中有成千上万的点,导致这样的知识学习起来效率很低。为了提高学习效率,除了 pointwise 输出,论文建议蒸馏(distil)voxelwise 输出,因为体素数量更少且更容易学习。pointwise 和 voxelwise 的蒸馏损失如下:
L o u t p ( O S p , O T p ) = 1 N C ∑ n = 1 N ∑ c = 1 C K L ( O S p ( n , c ) ∣ ∣ O T p ( n , c ) ) L o u t v ( O S v , O T v ) = 1 R A H C ∑ r = 1 R ∑ a = 1 A ∑ h = 1 H ∑ c = 1 C K L ( O S v ( r , a , h , c ) ∣ ∣ O T v ( r , a , h , c ) ) \begin{aligned} L_{out}^p(O_S^p, O_T^p) &= \frac{1}{NC}\sum_{n=1}^N \sum_{c=1}^C KL(O_S^p(n, c)||O_T^p(n, c)) \\ L_{out}^v(O_S^v, O_T^v) &= \frac{1}{RAHC}\sum_{r=1}^R \sum_{a=1}^A \sum_{h=1}^H \sum_{c=1}^C KL(O_S^v(r, a, h, c) || O_T^v(r, a, h, c)) \end{aligned} Loutp(OSp,OTp)Loutv(OSv,OTv)=NC1n=1∑Nc=1∑CKL(OSp(n,c)∣∣OTp(n,c))=RAHC1r=1∑Ra=1∑Ah=1∑Hc=1∑CKL(OSv(r,a,h,c)∣∣OTv(r,a,h,c))
✍️其中, L o u t p L_{out}^p Loutp 为 pointwise 蒸馏损失, L o u t v L_{out}^v Loutv 为 voxelwise 蒸馏损失。 N N N 是点的数量, C C C 为类别数, R R R 为体素半径, A A A 为体素角度, H H H 为体素高度, K L ( ⋅ ) KL(\cdot) KL(⋅) 为 Kullback-Leibler divergence loss
✍️同一个体素可能包含来自不同类别的点,因此,如何为体素分配合适的标签对性能也至关重要。论文沿用 Cylinder3D 中的多数编码策略(majority encoding strategy),使用体素内拥有最多点的那类标签作为体素标签
Point-to-Voxel Affinity Distillation
只对 pointwise 和 voxelwise 的输出做知识蒸馏是不够的,因为它只考虑每个元素的知识,而不能捕捉周围环境的结构信息。因为输入点是无序的,所以这种结构知识对于基于激光雷达的语义分割模型至关重要。一种自然的补救方法是采用关系型知识蒸馏(relational knowledge distillation),其计算所有点特征的相似度,但该方案存在计算成本太高、难以学习且忽视点(不同类别、不同距离)之间的差异性这几个缺点。因此,论文通过超体素划分来降低计算成本并提高学习效率,通过 difficulty-aware 采样来正确对待不同点之间的差异性。
-
超体素划分:为了更高效地学习相关知识,论文将整个点云划分成多个大小为 R s × A s × H s R_s \times A_s \times H_s Rs×As×Hs 的超体素。每个超体素由固定数量的体素组成,且超体素的总数为 N s = ⌈ R R s ⌉ × ⌈ A A s ⌉ × ⌈ H H s ⌉ N_s = \lceil \frac{R}{R_s} \rceil \times \lceil \frac{A}{A_s} \rceil \times \lceil \frac{H}{H_s} \rceil Ns=⌈RsR⌉×⌈AsA⌉×⌈HsH⌉。在每个蒸馏步骤中,只采样
K个超体素进行affinity distillation -
difficulty-aware采样:该采样策略是为了使包含较不频繁类和较远对象的超体素更容易被采样。该采样策略先确定超体素的权重,再归一化权重,最后得到超体素被采样到的概率。相关公式如下:
W i = 1 f c l a s s × d i R × 1 N s f c l a s s = 4 exp ( − 2 N m i n o r ) + 1 P i = W i ∑ i = 1 N s W i \begin{aligned} W_i &= \frac{1}{f_{class}} \times \frac{d_i}{R} \times \frac{1}{N_s} \\ f_{class} &= 4 \exp(-2N_{minor}) + 1 \\ P_i &= \frac{W_i}{\sum_{i=1}^{N_{s}}W_i} \end{aligned} WifclassPi=fclass1×Rdi×Ns1=4exp(−2Nminor)+1=∑i=1NsWiWi
✍️其中, W i W_i Wi 为第i个超体素的权重, f c l a s s f_{class} fclass 为类出现的频率(class frequency), P i P_i Pi 为第i个超体素被采样的概率, d i d_i di 为第i个超体素的外弧(outer arc)到XOY面原点的距离, N m i n o r N_{minor} Nminor 为超体素中少数类体素的数量。
✍️论文将在整个数据集中拥有超过1%的点的类视为大多数类,其余为少数类。少数类体素是指其类标签为少数类,体素标签根据多数编码策略来确定。当没有少数类体素时, f c l a s s = 5 f_{class}=5 fclass=5;当少数类体素增加时, f c l a s s f_{class} fclass 会快速减小,最小为1 -
特征处理:对于点云,输入点的数量以及密度都是变化的,从而导致超体素中点特征和体素特征的数量也是变化的。在计算损失时,通常需要保持特征数量固定(
keep the number of features fixed)。为了解决这一问题,若超体素的点特征数量大于 N p N_p Np,则随机去除多余的点特征(标签为多数类);若点特征数量小于 N p N_p Np,则添加全 0 的点特征。对于体素特征(数量为 N v N_v Nv),也采用类似的做法。其中, N p N_p Np 和 N v N_v Nv 是人为设定的。
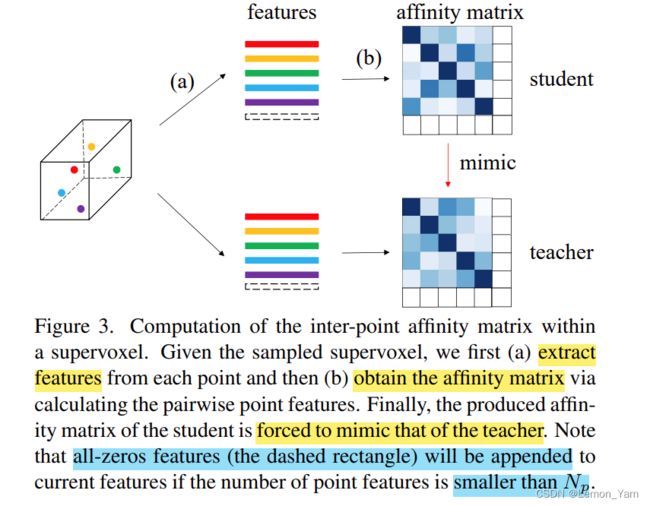
经过上面对特征的处理后,在第 r r r 个超体素中有 N p N_p Np 个点特征 F ^ r p ∈ R N p × C f \hat{F}_r^p \in R^{N_p \times C_f} F^rp∈RNp×Cf 和 N v N_v Nv 个体素特征 F ^ r v ∈ R N v × C f \hat{F}_r^v \in R^{N_v \times C_f} F^rv∈RNv×Cf。此外,对于每个超体素,论文通过下面式子计算其 inter-point affinity matrix:
C p ( i , j , r ) = F ^ r p ( i ) T F ^ r p ( j ) ∥ F ^ r p ( i ) T ∥ 2 ∥ F ^ r p ( j ) ∥ 2 , r ∈ { 1 , ⋯ , K } C^p(i, j, r) = \frac{\hat{F}_r^p(i)^T \hat{F}_r^p(j)}{\parallel \hat{F}_r^p(i)^T \parallel_2 \parallel \hat{F}_r^p(j) \parallel_2}, r \in \{1, \cdots, K \} Cp(i,j,r)=∥F^rp(i)T∥2∥F^rp(j)∥2F^rp(i)TF^rp(j),r∈{1,⋯,K}
affinity score 获取每对点特征的相似性,且该分数可看作是学生网络需要学习的高层次结构性知识(high-level structural knowledge)。此外,inter-point affinity 蒸馏损失计算如下:
L a f f p ( C S p , C T p ) = 1 K N p 2 ∑ r = 1 K ∑ i = 1 N p ∑ j = 1 N p ∥ C S p ( i , j , r ) − C T p ( i , j , r ) ∥ 2 2 L_{aff}^p (C_S^p, C_T^p) = \frac{1}{KN_p^2}\sum_{r=1}^K \sum_{i=1}^{N_p} \sum_{j=1}^{N_p}\parallel C_S^p(i, j, r) - C_T^p(i, j, r) \parallel_2^2 Laffp(CSp,CTp)=KNp21r=1∑Ki=1∑Npj=1∑Np∥CSp(i,j,r)−CTp(i,j,r)∥22
inter-voxel 的计算与 inter-point 类似,其蒸馏损失如下:
L a f f v ( C S v , C T v ) = 1 K N v 2 ∑ r = 1 K ∑ i = 1 N v ∑ j = 1 N v ∥ C S v ( i , j , r ) − C T v ( i , j , r ) ∥ 2 2 L_{aff}^v (C_S^v, C_T^v) = \frac{1}{KN_v^2}\sum_{r=1}^K \sum_{i=1}^{N_v} \sum_{j=1}^{N_v}\parallel C_S^v(i, j, r) - C_T^v(i, j, r) \parallel_2^2 Laffv(CSv,CTv)=KNv21r=1∑Ki=1∑Nvj=1∑Nv∥CSv(i,j,r)−CTv(i,j,r)∥22
总损失函数
该网络的总损失由 7 部分组成,分别是 pointwise 和 voxelwise 的 weighted cross entropy 损失(1、2 项)、lovasz-softmax 损失(第 3 项)、point-to-voxel 的蒸馏损失(后 4 项)
L = L w c e p + L w c e v + L l o v a s z + α 1 L o u t p ( O S p , O T p ) + α 2 L o u t v ( O S v , O T v ) + β 1 L a f f p ( C S p , C T p ) + β 2 L a f f v ( C S v , C T v ) \begin{aligned} L = &L_{wce}^p + L_{wce}^v + L_{lovasz}\\ &+\alpha_1 L_{out}^p(O_S^p, O_T^p) + \alpha_2 L_{out}^v(O_S^v, O_T^v) \\ &+\beta_1 L_{aff}^p(C_S^p, C_T^p) + \beta_2 L_{aff}^v (C_S^v, C_T^v) \end{aligned} L=Lwcep+Lwcev+Llovasz+α1Loutp(OSp,OTp)+α2Loutv(OSv,OTv)+β1Laffp(CSp,CTp)+β2Laffv(CSv,CTv)
✍️其中, α 1 \alpha_1 α1、 α 2 \alpha_2 α2、 β 1 \beta_1 β1、 β 2 \beta_2 β2 用来平衡蒸馏损失对主要任务损失的影响
论文:https://arxiv.org/pdf/2206.02099.pdf
代码:https://github.com/cardwing/Codes-for-PVKD