聚类kmeans和DBSCAN算法的简单实现
在无监督学习中,我们首先就会接触到kmeans算法,因为既简单,又实用,而且速度也很快。所以今天在这里写一个非常简单的kmeans算法,以帮助我们更快的领悟算法的思想,以及它的变种。一下是其实现步骤
- 确定聚类数,数据分为多少类。
- 随机初始化每一类的中心点。
- 计算每一个样本点到每一类中心点的距离,并分配给距离它最小的那个中心点。
- 更新中心点,新的中心点为属于它所有点的平均值。
- 重复3,4操作,即可完成。
数据不是太漂亮,实现的效果也不是特别好,代码写的很简单,还有优化的空间。
from sklearn.datasets import load_iris
import numpy as np
import matplotlib.pyplot as plt
a,b = load_iris(return_X_y=True)
x = a[:,:2] #便于绘图
center_1 = np.array([5,3.5]) #初始化中心点
center_2 = np.array([6,2])
center_3 = np.array([7,3])
for k in range(200):
center_list1 = []
center_list2 = []
center_list3 = []
for i in x:
a = ((i[0] - center_1[0])*(i[1]-center_1[1]))**2
b = ((i[0] - center_2[0])*(i[1]-center_2[1]))**2
c = ((i[0] - center_3[0])*(i[1]-center_3[1]))**2
if a<b and a<c :
center_list1.append(i)
elif b<c:
center_list2.append(i)
elif c<b :
center_list3.append(i)
new_1_x = 0
new_1_y = 0
for a in center_list1:
new_1_x +=a[0]
new_1_y +=a[1]
center_1[0] = new_1_x / (len(center_list1))
center_1[1] = new_1_y / (len(center_list1))
new_1_x = 0
new_1_y = 0
for a in center_list2:
new_1_x += a[0]
new_1_y += a[1]
print(len(center_list3))
center_2[0] = new_1_x / (len(center_list2))
center_2[1] = new_1_y / (len(center_list2))
new_1_x = 0
new_1_y = 0
for a in center_list3:
new_1_x += a[0]
new_1_y += a[1]
center_3[0] = new_1_x / (len(center_list3))
center_3[1] = new_1_y / (len(center_list3))
plt.scatter([x[0] for x in center_list1],[x[1] for x in center_list1],c='red')
plt.scatter([x[0] for x in center_list2],[x[1] for x in center_list2],c='green')
plt.scatter([x[0] for x in center_list3],[x[1] for x in center_list3],c='blue')
plt.scatter(center_1[0],center_1[1],c='black')
plt.scatter(center_2[0],center_2[1],c = 'black')
plt.scatter(center_3[0],center_3[1],c='black')
plt.show()
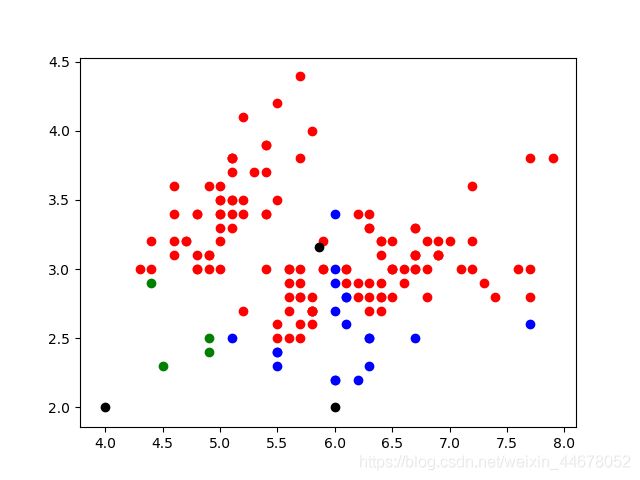
下面的这个代码是一个优化的版本,参考于https://www.cnblogs.com/zxzhu/p/7994612.html,
该博客主写的方法也太简单的,便于阅读,很适合学习。
1
2
3
4
5
6 from sklearn.datasets import make_blobs
7 import numpy as np
8 import matplotlib.pyplot as plt
9
10
11 def Distance(x):
12 def Dis(y):
13 return np.sqrt(sum((x-y)**2)) #欧式距离
14 return Dis
15
16 def init_k_means(k):
17 k_means = {}
18 for i in range(k):
19 k_means[i] = []
20 return k_means
21
22 def cal_seed(k_mean): #重新计算种子点
23 k_mean = np.array(k_mean)
24 new_seed = np.mean(k_mean,axis=0) #各维度均值
25 return new_seed
26
27 def K_means(data,seed_k,k_means):
28 for i in data:
29 f = Distance(i)
30 dis = list(map(f,seed_k)) #某一点距所有中心点的距离
31 index = dis.index(min(dis))
32 k_means[index].append(i)
33
34 new_seed = [] #新的样本中心点
35 for i in range(len(seed_k)):
36 new_seed.append(cal_seed(k_means[i]))
37 new_seed = np.array(new_seed)
38 return k_means,new_seed
39
40 def run_K_means(data,k):
41 seed_k = data[np.random.randint(len(data),size=k)] #随机产生样本中心点
42 k_means = init_k_means(k) #初始化每一类
43 result = K_means(data,seed_k,k_means)
44 count = 0
45 while not (result[1] == seed_k).all(): #种子点改变,继续聚类
46 count+=1
47 seed_k = result[1]
48 k_means = init_k_means(k=7)
49 result = K_means(data,seed_k,k_means)
50 print('Done')
51 #print(result[1])
52 print(count)
53 plt.figure(figsize=(8,8))
54 Color = 'rbgyckm'
55 for i in range(k):
56 mydata = np.array(result[0][i])
57 plt.scatter(mydata[:,0],mydata[:,1],color = Color[i])
58 return result[0]
59 x,y = make_blobs(n_features=3,n_samples=1000,random_state=21)
60
61 run_K_means(data,k=3)
程序中那个闭包的操作需要我们多去捋一捋。
在聚类中使用的较多的一种聚类是基于密度的DBSCAN算法,该算法不需要指定类别数,但是要指定半径大小以及该范围内包含点的最小数目。
DBSCAN算法描述:输入:
输入: 包含n个对象的数据库,半径e,最少数目MinPts;
输出:所有生成的簇,达到密度要求。
(1)Repeat
(2)从数据库中抽出一个未处理的点;
(3)IF抽出的点是核心点 THEN 找出所有从该点密度可达的对象,形成一个簇;
(4)ELSE 抽出的点是边缘点(非核心对象),跳出本次循环,寻找下一个点;
(5)UNTIL 所有的点都被处理。
DBSCAN对用户定义的参数很敏感,细微的不同都可能导致差别很大的结果,而参数的选择无规律可循,只能靠经验确定。
- 与K-means方法相比,DBSCAN不需要事先知道要形成的簇类的数量。
- 与K-means方法相比,DBSCAN可以发现任意形状的簇类。
- 同时,DBSCAN能够识别出噪声点。
4.DBSCAN对于数据库中样本的顺序不敏感,即Pattern的输入顺序对结果的影响不大。但是,对于处于簇类之间边界样本,可能会根据哪个簇类优先被探测到而>其归属有所摆动。
具体的实现如下,过程很简单,细读后,复现应该是没有问题的,我也是从
https://www.cnblogs.com/tiaozistudy/p/dbscan_algorithm.html,里面学来的,代码基本一样,他里面有跟详细的介绍。
import math
import numpy as np
from sklearn.datasets import make_circles
import random
import matplotlib.pyplot as plt
class visited:
'''
记录那些点是被标记了的,那些点是没有被标记的,以及没有被标记点的个数 , 记录的是每个点在data里面的位置,也就是index
'''
def __init__(self,count=0):
self.visitedlist = list()
self.unvisitedlist = [i for i in range(count]
self.unvisitednum = count
def visvit(self,opints):
self.visitedlist.append(opints)
self.unvisitedlist.remove(opints)
self.unvisitednum -= 1
#计算距离
def dist(x , y):
return math.sqrt(np.power(x-y,2).sum())
def DBSCAN(data,eps,minpts):
count = data.shape[0]
visit = visited(count)
k = -1 #表示类别
C = [-1 for i in range(count]
while (visit.unvisitednum > 0 ):
p = random.choice(visit.unvisitedlist)
visit.visvit(p)
N = [i for i in visit.unvisitedlist if dist(data[i],data[p]) <= eps]
if len(N) >= minpts:
k += 1
C[p] = k
for p1 in N:
visit.visvit(p1)
M = [i for i in visit.unvisitedlist if dist(data[i],data[p]) <= eps]
if len(M) >=minpts:
for i in M:
if i not in N:
N.append(i)
C[p1] = k
else:
C[p] = -1
return C
x ,y = make_circles(n_samples=2000,factor=0.6,noise=0.05,random_state=1)
a = DBSCAN(x,0.1,10)
plt.figure(figsize=(12,9))
plt.scatter(x[:,0],x[:,1],c = a)
plt.show()
上面讲述了两种常用的聚类方法,里面的DBSCAN还可以用KD树来优化,这里就不讲述了,(我也不会)。聚类方法也还挺简单的,没有那些复杂的数学公式推导,相信你们也和我一样,看到公式就头疼。聚类的算法重点还是其思想,理解了它的思想,那么你也就成功了65%。