语义分割代码学习笔记
代码来源:憨批的语义分割重制版9——Pytorch 搭建自己的DeeplabV3+语义分割平台_Bubbliiiing的博客-CSDN博客
网络结构:
首先需要根据自己的电脑的性能决定下采样多少倍,一般会下采样16倍或者8倍获取到高级的语义特征,但是这样的特征丢失了细粒度特征,所将低层的语义特征与之结合,然后再通过双线性插值或者上采样将结果输出成与输入图片大小一致,通道数为分类个数加上背景数。下面是以mobilenet网络作为模型的,但是该网络的倒数第三层的步长由2变成了1,因为原来的网络的下采样适用于分类网络的,但是对于该语义分割任务不需要很大的下采样。具体代码如下:那么对于其他网络也是同样的道理,但是也可以不改,这样的效果应该会差一点,但是也许会更高也说不一定。
import math
import os
import torch
import torch.nn as nn
import torch.utils.model_zoo as model_zoo
BatchNorm2d = nn.BatchNorm2d
def conv_bn(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
BatchNorm2d(oup),
nn.ReLU6(inplace=True)
)
def conv_1x1_bn(inp, oup):
return nn.Sequential(
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
BatchNorm2d(oup),
nn.ReLU6(inplace=True)
)
class InvertedResidual(nn.Module):
def __init__(self, inp, oup, stride, expand_ratio):
super(InvertedResidual, self).__init__()
self.stride = stride
assert stride in [1, 2]
hidden_dim = round(inp * expand_ratio)
self.use_res_connect = self.stride == 1 and inp == oup
if expand_ratio == 1:
self.conv = nn.Sequential(
# dw
nn.Conv2d(hidden_dim, hidden_dim, 3, stride, 1, groups=hidden_dim, bias=False),
BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=True),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
BatchNorm2d(oup),
)
else:
self.conv = nn.Sequential(
# pw
nn.Conv2d(inp, hidden_dim, 1, 1, 0, bias=False),
BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=True),
# dw
nn.Conv2d(hidden_dim, hidden_dim, 3, stride, 1, groups=hidden_dim, bias=False),
BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=True),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
BatchNorm2d(oup),
)
def forward(self, x):
if self.use_res_connect:
return x + self.conv(x)
else:
return self.conv(x)
class MobileNetV2(nn.Module):
def __init__(self, n_class=1000, input_size=224, width_mult=1.):
super(MobileNetV2, self).__init__()
block = InvertedResidual
input_channel = 32
last_channel = 1280
interverted_residual_setting = [
# t, c, n, s
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
# building first layer
assert input_size % 32 == 0
input_channel = int(input_channel * width_mult)
self.last_channel = int(last_channel * width_mult) if width_mult > 1.0 else last_channel
self.features = [conv_bn(3, input_channel, 2)]
# building inverted residual blocks
for t, c, n, s in interverted_residual_setting:
output_channel = int(c * width_mult)
for i in range(n):
if i == 0:
self.features.append(block(input_channel, output_channel, s, expand_ratio=t))
else:
self.features.append(block(input_channel, output_channel, 1, expand_ratio=t))
input_channel = output_channel
# building last several layers
self.features.append(conv_1x1_bn(input_channel, self.last_channel))
# make it nn.Sequential
self.features = nn.Sequential(*self.features)
# building classifier
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(self.last_channel, n_class),
)
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = x.mean(3).mean(2)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
n = m.weight.size(1)
m.weight.data.normal_(0, 0.01)
m.bias.data.zero_()
def load_url(url, model_dir='./model_data', map_location=None):
if not os.path.exists(model_dir):
os.makedirs(model_dir)
filename = url.split('/')[-1]
cached_file = os.path.join(model_dir, filename)
if os.path.exists(cached_file):
return torch.load(cached_file, map_location=map_location)
else:
return model_zoo.load_url(url,model_dir=model_dir)
def mobilenetv2(pretrained=False, **kwargs):
model = MobileNetV2(n_class=1000, **kwargs)
if pretrained:
model.load_state_dict(load_url('http://sceneparsing.csail.mit.edu/model/pretrained_resnet/mobilenet_v2.pth.tar'), strict=False)
return model
损失函数:
既然我们知道了网络结构,那么我们就知道输入的是一张图片,输出的是与输入图片大小一样的特征图,并且通道数是分类种数加上背景数,那么我们就知道,对于每个像素我们需要知道它是属于那个类,那么我们就一定需要分类任务,因此交叉熵损失函数一定是不能少的,这个分类任务是在通道上进行的,其次,我们还需要知道我们分类的效果好不好,就是与真实的分割图片重合的程度,那么此时我们一定是要进行交并比计算的,但是语义分割网络在这方面又有一点改变。
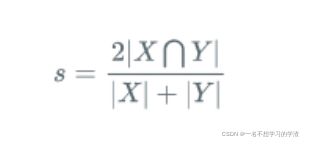
其中代码如下:虽然代码和公式有些区别,但是代码是更好一点,考虑的因素比较多。
#用于交叉熵计算
def CE_Loss(inputs, target, cls_weights, num_classes=21):
n, c, h, w = inputs.size()
nt, ht, wt = target.size()
if h != ht and w != wt:#防止两者的大小不一样
inputs = F.interpolate(inputs, size=(ht, wt), mode="bilinear", align_corners=True)
#如果不一样就需要进行双线性插值
temp_inputs = inputs.transpose(1, 2).transpose(2, 3).contiguous().view(-1, c)
# 该步骤就是将特征图展平成二维的
temp_target = target.view(-1)
#下面就开始计算交叉熵损失
CE_loss = nn.CrossEntropyLoss(weight=cls_weights, ignore_index=num_classes)(temp_inputs, temp_target)
return CE_loss
def Dice_loss(inputs, target, beta=1, smooth = 1e-5):
n, c, h, w = inputs.size()
nt, ht, wt, ct = target.size()
if h != ht and w != wt:
inputs = F.interpolate(inputs, size=(ht, wt), mode="bilinear", align_corners=True)
temp_inputs = torch.softmax(inputs.transpose(1, 2).transpose(2, 3).contiguous().view(n, -1, c),-1)
temp_target = target.view(n, -1, ct)
#--------------------------------------------#
# 计算dice loss
#--------------------------------------------#
tp = torch.sum(temp_target[...,:-1] * temp_inputs, axis=[0,1])#计算的相同区域的像素点的和,也就是交集
fp = torch.sum(temp_inputs , axis=[0,1]) - tp#得到的是去除交集的像素点的和
fn = torch.sum(temp_target[...,:-1] , axis=[0,1]) - tp#得到的是去除交集的像素点的和
score = ((1 + beta ** 2) * tp + smooth) / ((1 + beta ** 2) * tp + beta ** 2 * fn + fp + smooth)
#该部分就是公式所展现的那样,其实自己还有些看不懂,裂开
dice_loss = 1 - torch.mean(score)
return dice_loss
数据集读取:
由上面的损失函数我们可以知道它的标签其实是两个,一个是用于分类任务的,一个就是用于进行计算交并比的。那么我们在制作数据集的时候就需要进行注意,首先我们要知道数据集的图片的维度是[3,w,h],分割图维度是[w,h],当然对于图片的像素值我们需要进行归一化的,这样计算损失值的不会太大。当我们有了输入图片和输出特征,那么我们的输出特征就可以与分割图进行交叉熵计算了,两者分别为[n_class,w*h]和[w*h]。那么对于交并比计算的标签该怎么弄呢,我们首先要知道标签是什么样子的,它是和输出的维度是一样的,需要自己去定义一个和分割图一样的零矩阵[w,h],然后将每一个像素点变成独热编码,也就是在通道上进行独热编码。其实这一块我也不知道想的对不对,但是大概率就是这个样子的,比较抽象,得到的结果为[w*h,n_class]。当然在该博主的代码中得到的结果是[w*h,n_class+1],他的代码解释是因为分割图片有一些白框,所以需要进行删除,代码如下:
seg_labels = np.eye(self.num_classes + 1)[seg_labels.reshape([-1])]
seg_labels = seg_labels.reshape((int(self.input_shape[0]), int(self.input_shape[1]), self.num_classes + 1))但是在损失计算的时候,那个+1并没有进行计算,代码如下所示:temp_target[...,:-1]去除了最后的+1。
tp = torch.sum(temp_target[...,:-1] * temp_inputs, axis=[0,1])
fp = torch.sum(temp_inputs , axis=[0,1]) - tp
fn = torch.sum(temp_target[...,:-1] , axis=[0,1]) - tp最后祝大家学有所成!