Attention based ASR(LAS)
目录
1. Encoder-Decoder
2. 引入Attention的Encoder-Decoder(AED)
3. LAS
3.1 listen
3.2 Attention
3.3 spell
4. LAS训练
5.总结
1. Encoder-Decoder
在传统的机器翻译中,我们做的是把一种语言的句子 翻译成另一个语言的句子
翻译成另一个语言的句子 的任务。
的任务。
: ?
: 今天天气怎么样?
神经机器翻译是通过单个神经网络实现机器翻译的方法,这种神经网络框架称作 或者 , 其包含俩个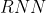 .
.
注:是一种模型框架。编码器将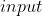 (文字、图片、语音)编码输出向量
(文字、图片、语音)编码输出向量 ,接收向量,一一预测输出结果。而可以看作是针对某一类任务的模型框架。
,接收向量,一一预测输出结果。而可以看作是针对某一类任务的模型框架。
强调的是模型设计,强调的是任务类型(序列到序列的问题).

部分每个单词是这么生成的:
其中 是解码器的非线性变换函数, 可以看出来,在生成目标句子的单词时,无论生成哪一个单词,它们使用的输入句子与语义编码都是一样的,没有任何区别。
是解码器的非线性变换函数, 可以看出来,在生成目标句子的单词时,无论生成哪一个单词,它们使用的输入句子与语义编码都是一样的,没有任何区别。
而语义编码是由句子的每个单词经过编码产生的,这意味着不论是生成哪个单词,句子中任意单词对某个目标单词 的影响力都是相同的,就像是人类的眼中没有注意力焦点一样。
的影响力都是相同的,就像是人类的眼中没有注意力焦点一样。
假设输入的英文句子为: , 输出中文单词:“汤姆” “追逐” “杰瑞”。在翻译”杰瑞“这个单词的时候,模型里面每个英文单词对于翻译目标单词”杰瑞“的贡献程度是相同的,这很显然是不合道理的。显然”Jerry“对于翻译成”杰瑞“更为重要。
那么它会存在什么问题呢?类似RNN无法捕捉长序列的道理,没有引入Attention机制在输入句子较短时影响不大,但是如果输入句子比较长,此时所有语义通过一个中间语义向量表示,单词自身的信息避免不了会消失,也就是会丢失很多细节信息,这也是为何引入Attention机制的原因。
2. 引入Attention的Encoder-Decoder(AED)
我们希望,在翻译“杰瑞”的时候,会体现出每个英文单词对输出当前中文单词的不同影响程度。现假设这三个英文单词对翻译出“杰瑞”的影响程度是:
其中,0.3、0.2、0.5就表示对于生成“杰瑞”,注意力分配给不同英文单词的权重大小,这对正确翻译目标单词有着积极作用。
目标句子中的每个单词都应该学会其对应的源语句子中单词的注意力分配概率信息。这意味着在生成每个单词  的时候,原先都是相同的中间语义表示C会被替换成根据当前生成单词而不断变化的
的时候,原先都是相同的中间语义表示C会被替换成根据当前生成单词而不断变化的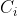 。理解Attention模型的关键就是这里,即由固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型的变化的。增加了注意力模型的Encoder-Decoder框架理解起来如下图所示:
。理解Attention模型的关键就是这里,即由固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型的变化的。增加了注意力模型的Encoder-Decoder框架理解起来如下图所示:
即生成目标句子单词的过程成了下面的形式:
而每个可能对应着不同的source单词的注意力分配概率分布,比如对应上面的翻译来说,其对应的信息可能如下:
汤姆 =
追逐 =
杰瑞 =
其中, 代表对输入英文单词的某种变换函数,如果是的话,就对应输出隐层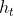 。
。
而 代表根据单词的中间表示合成整个句子中间语义表示的变换函数。一般做法就是进行weighted sum即加权和:
代表根据单词的中间表示合成整个句子中间语义表示的变换函数。一般做法就是进行weighted sum即加权和:
 就代表输入句子source的长度,
就代表输入句子source的长度, 表示隐层输出。
表示隐层输出。 表示输出句子第个词,
表示输出句子第个词, 就是输入句子每个词对输出第个单词的注意力分配概率。
就是输入句子每个词对输出第个单词的注意力分配概率。
在上面的例子当中,对于“杰瑞”,输入句子有三个英文单词,即。h1=f(“Tom”),h2=f(“Chase”), h3=f(“Jerry”)分别是输入句子每个单词的隐层输出,对应的注意力模型权值则分别是0.3,0.2,0.5,即表示对生成“杰瑞”的影响程度。
总结:

Query关键字,对应上面的输出单词“杰瑞”。这里的四个value,对应上面的输入source英文单词 。这里key和value等价,是一个东西。
第一步:关键字Query和每个value进行相关性计算,即,得到注意力得分s1 s2 s3 s4
第二步:对注意力得分softmax进行归一化处理,得到合为1的概率分布a1 a2 a3 a4
第三步: 计算语义向量
补充:第一步计算相关性的方式有很多种。
1. 向量点积,
2.求两者的余弦相似度,
3.引入一个额外的神经网络来求值,
3. LAS
是、、的简称。listener是以fbank为输入的pyramidal RNN decoder, speller是基于attention 的RNN decoder,建模单元为字符。
此模型所需的所有组件的训练是jointly的,不再像CTC模型里那样输出字符independent。
3.1 listen
的作用是输入一段语音信号,输出一段向量,去掉语音中的杂序,只保留和语音相关的部分。
输入特征:
listener:
输出隐层:

对于T帧的语音,经过RNN之后就会产生T个隐层。实际中会有成千上百帧,这会导致listen收敛缓慢,可能需要几个月的训练时间。这是因为很难从大量的time step中提取到相关信息。我们通过使用一个类似金字塔型的RNN来规避这个问题。将3个pBLSTMs堆叠在底部BLSTM层的顶部,以减少时间分辨率8倍。从而,让之后的attention model能够从更小的time step中提取更多的相关信息。
down sampling:

3.2 Attention
这里的就是上文说到的关键字,在这里指的是decode的隐层。 一般来说,初始化的 是语音中的初始字符

那么这个相关性大小怎么计算呢?我们在上面提到了点积法和余弦计算法。
点积法(dot-product attention):
h和z分别乘上一个linear的transform,得到新的vector,再进行向量点乘。

Addictive attention:
h和z经过transform之后相加,通过一个tanh,最后再乘上一个linear的transform。

那么整个attention的过程就是 :
1. decorder的隐层与输入source的四个隐层作相关性计算
2. 对得到的进行softmax归一化输出,得到[0.5 0.5 0 0]
3. 计算上下文向量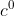

3.3 spell
对于第一个时刻的隐层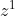 ,输入前一个初始化的隐层和上一个上下文向量,输出probability distribution,对应生成每一个字符的概率。比如生成“c”的概率最大为0.6,那么这个时候就输出“c”
,输入前一个初始化的隐层和上一个上下文向量,输出probability distribution,对应生成每一个字符的概率。比如生成“c”的概率最大为0.6,那么这个时候就输出“c”

t1时刻完成之后,重复上述流程,用再和 四个隐层作相关性计算, 并softmax。计算上下文向量。
那么t2时刻,将上一个的hidden state 、上一个上下文向量、上一个预测输出 ("c")送入decode,进一步预测t2时刻的输出结果“a”。
("c")送入decode,进一步预测t2时刻的输出结果“a”。
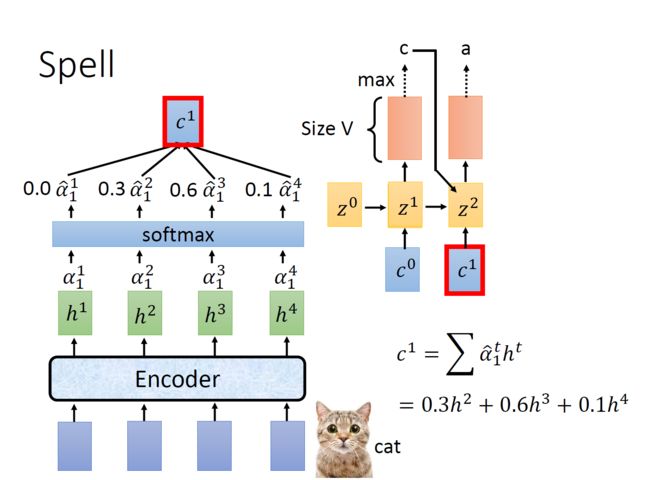
从而,一直到最后一个结束符
4. LAS训练
按照上面的思路,在每个时刻我们得到对应每个字符的probability distribution,将每个时刻的标签进行one-hot编码,很明显就可以用crossentropy来计算损失了。
但是有一个注意的问题,每个时刻的预测输出都会受到上一时刻预测输出的影响。如果第一时刻就预测错了,比如本来应该是“c”,错成了“b”,在第二时刻,模型本该学到的是:你来一个c我倾向输出a,却变成了 你来一个b我倾向输出a。如果前面错了的话,后面无论怎么训练都很难达到好的训练效果。因此在训练的时候,加一个teacher forcing,直接将上一时刻的标签(即正确结果)作为下一时刻的输入。


总结:
1. encoder:通过循环神经网络把输入特征序列转为隐藏层向量序列,这部分相当于声学模型。
2.decoder:计算输出符号基于前一个预测标签和输入特征分布的概率分布。这一部分相当于语言模型。
3. Attention:从encoder输出所有向量序列,计算注意力权重,并基于注意力分配概率来构建decoder网络的上下文向量, 进而建立输出序列和输入序列之间的对齐关系。
Attention模型通过接收encoder传递过来的高层特征表示,学习输入特征和模型输出之间的对齐信息,并指导decoder的输出。
Decoder经softmax的输出序列Y由X生成的概率为:
其中,表示真实标签, 表示预测标签。从式子中可以看出,每个时刻都是基于所有输入特征(这也是LAS不能online的原因)和前一刻标签
表示预测标签。从式子中可以看出,每个时刻都是基于所有输入特征(这也是LAS不能online的原因)和前一刻标签
Decoder一般采用RNN,在每个输出标签u位置,RNN基于上一个输出、上一个隐层、上一个上下文向量,产生当前的隐层:
上下文向量由注意力机制得到:
其中,表示和之间的注意力权重:
其中,表示注意力得分(原始分数),经过softmax之后得到。
而。
5.总结
Attention based ASR 是对整个句子进行建模,在encoder层需要输入整个特征序列,而每一个输出标签是基于整句来预测得到的。按照我们的想法,在attention的过程中,应该是从左到右,注意力慢慢转移到最后。但是在实际运算中,注意力可能是随便乱跳的。因此attention模型的输出序列和输入序列不一定按顺序严格对齐。Attention比CTC具有更强的上下文建模能力,因此运用更加广泛。