实时采集MySQL数据之轻量工具Maxwell实操
文章目录
- 概述
-
- 定义
- 原理
- Binlog说明
- Maxwell和Canal的区别
- 部署
-
- 安装
- MySQL准备
- 初始化Maxwell元数据库
- Maxwell进程启动
-
- 命令行参数
- 配置文件
- 实时监控Mysql输出Kafka
- Kafka Topic分区控制
- 实时监控MySQL指定表
- 监控MySQL指定表同步全量数据
概述
定义
Maxwell 官网地址 https://maxwells-daemon.io/
Maxwell GitHub源码地址 https://github.com/zendesk/maxwell
Maxwell 是由美国 Zendesk 开源,采用 Java 语言开发的 MySQL 实时抓取工具,通过实时读取MySQL binlog二进制日志并作为生产者生产 JSON 格式消息发送给 Kafka、Kinesis、RabbitMQ、Redis或其他流媒体平台的应用程序。最新版本为1.39.4
Maxwell的操作开销很低,只需要mysql和数据同步目的地,常用场景包括ETL、缓存构建/过期、指标收集、搜索索引和服务间通信。
原理
Maxwell 的工作原理很简单,就是把自己伪装成 MySQL 的一个 slave,然后以 slave的身份从 MySQL master服务器复制数据,需要MySQL的binlog数据格式设置为row模式。
Binlog说明
MySQL开启binlog大概会有 1%的性能损耗,主要用于主从复制和数据恢复。二进制日志包括两类文件
- 二进制日志索引文件(文件名后缀为.index):用于记录所有 的二进制文件
- 二进制日志文件(文件名后缀为.00000*):记录数据库所有的 DDL 和 DML(除了数据查询语句)语句事件。
MySQL 生成的 binlog 文件初始大小一定是 154 字节,然后前缀是 log-bin 参数配置的,后缀是默认从.000001,然后依次递增(包括每次重启mysql也会递增)。除了 binlog 文件文件以外,MySQL 还会额外生产一个.index 索引文件用来记录当前使用的 binlog 文件。
Maxwell和Canal的区别
Maxwell最初的设计思想是MySQL+Kafka,用于对MySQL数据采集个人比较推荐Maxwell,当然还有我们前面学过的FlinkCDC。
- 服务端+客户端一体,轻量级
- 支持断点还原功能+bootstrap+json,全量同步
- maxwell社区比canal社区活跃

部署
安装
# 下载最新版本1.39.4的maxwell,注意从github的release历史中可知maxwell从v1.30.0开始就已经不再支持JDK8,支持JDK11
wget https://github.com/zendesk/maxwell/releases/download/v1.39.4/maxwell-1.39.4.tar.gz
# 解压文件
tar -xvf maxwell-1.39.4.tar.gz
# 进入主目录
cd maxwell-1.39.4
MySQL准备
修改mysql的配置文件,开启mysql的binlog设置,vim /etc/my.cnf
# mysql server的id,如果有多台id需要唯一
server_id=1
# 设置生成的二进制文件的前缀
log-bin=mysql-bin
# 设置binlog的二进制文件的日志级别 行级模式
binlog_format=row
# binlog的执行的库 如果不加这个参数那么mysql会对所有的库都生成对应的binlog 即对所有的库尽心binlog监控
# 设置只监控某个或某些数据库
binlog-do-db=my_maxwell_01
binlog-do-db=my_maxwell_02
# 修改后重启MySQL的服务
service mysqld restart
初始化Maxwell元数据库
在 MySQL 中建立一个 maxwell 库用于存储 Maxwell 的元数据
# 创建数据库,在我们使用的时候它会自己创建对应的表,这里我们只需建库不需要创表
CREATE DATABASE maxwell;
# 创建用户任意远程访问
CREATE USER 'maxwell'@'%';
# 修改密码
ALTER USER 'maxwell'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
#给用户授权
GRANT SELECT ,REPLICATION SLAVE , REPLICATION CLIENT ON *.* TO maxwell@'%';
GRANT ALL PRIVILEGES ON maxwell.* TO "maxwell"@"%";
#刷新权限
FLUSH PRIVILEGES;
Maxwell进程启动
命令行参数
# 启动maxwell
bin/maxwell --user='maxwell' --password='123456' --host='hadoop3' --port=3308 --producer=stdout
详细参数配置可以查阅官网
# 在mysql中创建前面在MySQL的配置文件中binlog数据库
CREATE DATABASE my_maxwell_01;
# 数据表,账号表
use my_maxwell_01;
CREATE TABLE `account` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` int(4) DEFAULT 0,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
# 插入数据
INSERT INTO account(name,age) VALUES('张三三',20),('李思',23),('王乐',26);
从日志可以看出创建数据库、数据表和数据插入捕获的binlog由maxwell转换为json的日志,向 mysql 的my_maxwell_01库的account表同时插入 3 条数据,控制台出现了 3 条 json日志,说明 maxwell 是以数据行为单位进行日志的采集的。

通过启动maxwell后我们也可以maxwell元数据库的内容,包含核心几张表数据。

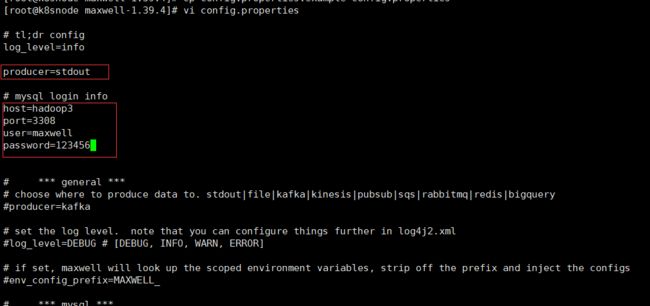
配置文件
# 拷贝maxwell根目录下config.properties.example
cp config.properties.example config.properties
# 修改config.properties配置文件
log_level=info
producer=stdout
# mysql login info
host=hadoop3
port=3308
user=maxwell
password=123456
# 通过指定配置文件启动maxwell
bin/maxwell --config ./config.properties
# 再次插入数据测试
INSERT INTO account(name,age) VALUES('吴三',25);
# 也可以通过jps查看maxwell进程com.zendesk.maxwell.Maxwell
jps -l

接下里看下修改数据和删除数据json数据内容,后续主要就是针对json内容做处理
UPDATE account SET age = 28 WHERE id =4;
UPDATE account SET age = 30 WHERE name ='吴三';
DELETE FROM account WHERE id =4;

json内容分别如下,主要是type类型区分,更新包含old数据的值,ts为秒级时间戳。
# 添加
{
"database": "my_maxwell_01",
"table": "account",
"type": "insert",
"ts": 1671434231,
"xid": 5097,
"commit": true,
"data": {
"id": 4,
"name": "吴三",
"age": 25
}
}
# 更新
{
"database": "my_maxwell_01",
"table": "account",
"type": "update",
"ts": 1671434616,
"xid": 6302,
"commit": true,
"data": {
"id": 4,
"name": "吴三",
"age": 28
},
"old": {
"age": 25
}
}
# 删除
{
"database": "my_maxwell_01",
"table": "account",
"type": "delete",
"ts": 1671434700,
"xid": 6584,
"commit": true,
"data": {
"id": 4,
"name": "吴三",
"age": 30
}
}
实时监控Mysql输出Kafka
# 启动 Maxwell 监控 binlog
bin/maxwell --user='maxwell' --password='123456' --host='hadoop3' --producer=kafka --kafka.bootstrap.servers=kafka1:9092 --kafka_topic=test_topic_1
一旦mysql表有了数据的更新么mysql底层的binlog文件肯定会有变化,binlog变化了则maxwell进程就能捕捉到这个变化,将之解析并转换为json数据写入到kafka里面。使用kafka的图形化工具kafka tool查看数据,点击test_topic_1查看,不更新数据这里的topic是不会被创建的,插入数据后test_topic_1就有相关的消息数据了
# 继续插入数据
INSERT INTO account(name,age) VALUES('刘说',27);

# 官方的命令行消费脚本也可以消费到数据
kafka-console-consumer.sh --bootstrap-server kafka1:9092 --topic test_topic_1
通过 kafka 消费者来查看到了数据,说明数据成功传入 kafka
![]()
Kafka Topic分区控制
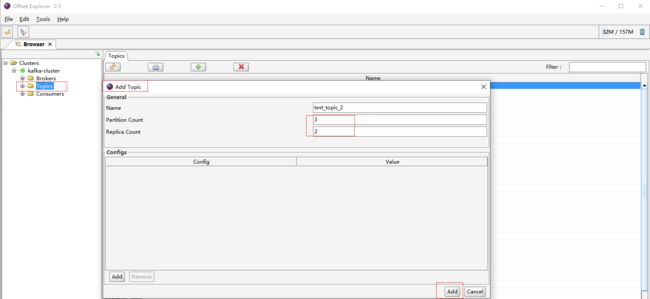
上面的示例往kafka写入的消息都是是发往一个分区,在实际生产环境中一般都会用 maxwell 监控多个 mysql 库的数据,然后将这些数据发往 kafka 的一个主题 Topic,提高并发度主题肯定是多分区的。先创建一个名称test_topic_2,分区为3副本为2的topic。
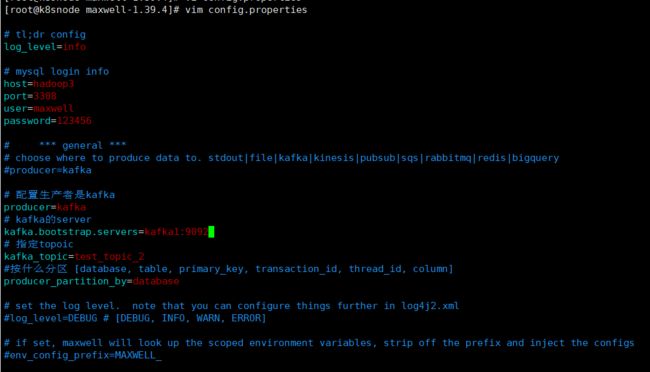
这次使用配置文件方式,修改config.properties
# 配置生产者是kafka
producer=kafka
# kafka的server
kafka.bootstrap.servers=kafka1:9092
# 指定topoic
kafka_topic=test_topic_2
#按什么分区 [database, table, primary_key, transaction_id, thread_id, column]
producer_partition_by=database
使用配置文件的方式启动maxwell进程
bin/maxwell --config ./config.properties
# 在mysql中创建前面在MySQL的配置文件中binlog数据库
CREATE DATABASE my_maxwell_02;
# 数据表,账号表
use my_maxwell_02;
CREATE TABLE `account` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` int(4) DEFAULT 0,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
# 分别往两个数据库的account表插入一条数据
INSERT INTO my_maxwell_01.account(name,age) VALUE('李丹',30);
INSERT INTO my_maxwell_02.account(name,age) VALUE('李丹',30);
再来看看topic,在test_topic_2中两条数据分区分别为0和1,验证不同数据库的数据会发往不同的分区。

实时监控MySQL指定表
主要是通过–filter参数设置exclude排除,include是包含来实现
# 启动maxwell
bin/maxwell --user='maxwell' --password='123456' --host='hadoop3' --filter 'exclude: *.*, include:my_maxwell_01.product' --port=3308 --producer=stdout
创建新的数据表,分别往两张表插入数据
use my_maxwell_02;
CREATE TABLE `product` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`type` int(4) DEFAULT 0,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO my_maxwell_01.account(NAME,age) VALUE('李丹',30);
INSERT INTO my_maxwell_01.product(NAME,TYPE) VALUE('iphone13',1);

可以看到只有product表捕获变更数据,此外还可以设置 include:my_maxwell_01.*,通过此种方式来监控 mysql 某个库的所有表,也就是说过滤整个库。
监控MySQL指定表同步全量数据
监控MySQL指定表同步全量数据常用于数据初始化操作,Maxwell 进程默认只能监控 mysql 的 binlog 日志的新增及变化的数据,但是Maxwell 是支持数据初始化的,可以通过修改 Maxwell 的元数据,来对 MySQL 的某张表进行数据初始化,也就是我们常说的全量同步。接下来演示将 my_maxwell_01库下的 account表的5条数据全量导入输出到 maxwell 控制台。
前面我们创建过maxwel的元数据库,这里需求修改 Maxwell 的元数据以触发数据初始化机制,在 mysql 的 maxwell 库中 bootstrap表中插入一条数据,写明需要全量数据的库名和表名
insert into maxwell.bootstrap(database_name,table_name) values('my_maxwell_01','account');

# 启动 maxwell 进程,此时初始化程序会直接打印account表的所有数据
bin/maxwell --user='maxwell' --password='123456' --host='hadoop3' --port=3308 --producer=stdout
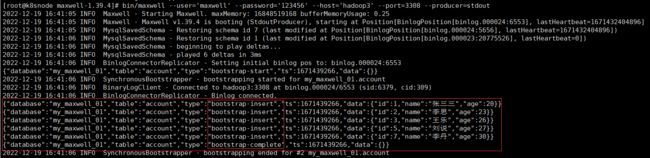
当数据全部初始化完成以后,Maxwell 的元数据会变化,is_complete 字段从 0 变为 1,start_at 字段从 null 变为具体时间(数据同步开始时间),complete_at 字段从 null 变为具体时间(数据同步结束时间),在Maxwell 运行过程中继续往maxwell.bootstrap插入数据也会触发处理。

本人博客网站IT小神 www.itxiaoshen.com