大数据旅游项目(离线数仓实战)
文章目录
- 大数据旅游项目
-
- 1 项目分析
-
- 1.1 项目分析流程图
- 2 项目前期准备
-
- 2.1 hdfs权限验证
- 3 数仓前期准备
-
- 3.1 本地创建对应账号(root权限)
- 3.2 hdfs创建分层对应目录(root权限)
- 3.3 修改hdfs分层目录所属用户(root权限)
- 3.4 hive进行分库(root权限)
-
- 3.4.1 hive后台启动命令
- 3.4.2 修改tmp目录权限
- 3.4.3 为每一个用户安装hive
- 3.4.4 修改权限
- 3.4.5 每个用户配置该用户环境变量
- 3.4.6 更改每个用户hive的临时目录
- 3.4.7 修改hive权限
- 4 建立数据仓库
-
- 4.1 每一个用户在hive创建每个库
-
- 4.1.1 报错问题
- 4.1.2 创库语句
- 4.2 ods层建表(ods权限)
-
- 4.2.1 ods_ddr
- 4.2.2 ods_dpi
- 4.2.3 ods_wcdr
- 4.2.4 ods_oidd
- 4.2.5 ods_usertag_m(用户画像表)
- 4.2.6 ods_scenic_boundary
- 4.2.7 ods_admincode
- 4.3 dwi层建表(dwi权限)
-
- 4.3.1 dwi_res_regn_mergelocation_msk_d(位置数据融合表)
- 4.3.2 dwi_staypoint_msk_d(停留点表)
- 4.4 dim层建表(dim权限)
-
- 4.4.1 dim_admincode
- 4.4.2 dim_bsid
- 4.4.3 dim_geotag_grid
- 4.4.4 dim_scenic_boundary
- 4.4.5 dim_usertag_msk_m
- 4.4.6 dim_scenic_grid
- 4.5 dal_tour层建表(dal_tour权限)
-
- 4.5.1 dal_tour_city_tourist_msk_d
- 4.5.2 dal_tour_city_day_index
- 4.5.3 dal_tour_scenic_tourist_msk_d
- 4.5.4 dal_tour_province_tourist_msk_d
- 5 数据集成
-
- 5.1 ods数据集成,上传hdfs
- 5.2 数据库数据准备
-
- 5.2.1 mysql建库
- 5.2.2 创建usertag(用户表)并导入数据
- 5.2.3 创建scenic_boundary(景区配置表)并导入数据
- 5.2.4 创建admin_code(行政区配置表)并导入数据
- 5.3 datax拉取数据
-
- 5.3.1 编写usertag_mysql_to_usertag_hive_ods.json
- 5.3.2 hdfs创建数据归属目录
- 5.3.3 执行导入数据代码(ods权限)
- 5.3.4 编写scenic_boundary_mysql_to_scenic_boundary_hive_dim.json
- 5.3.5 hdfs创建数据归属目录
- 5.3.6 执行导入数据代码(ods权限)
- 5.3.7 编写admin_code_mysql_to_admin_code_hive_dim.json
- 5.3.8 hdfs创建数据归属目录
- 5.3.9 执行导入数据代码(ods权限)
- 6 数据处理
-
- 6.1 创建maven项目my_dwi_tour
- 6.2 dim层数据处理(dim权限,脚本执行)
-
- 6.2.1 UserTagOdsToDIm
- 6.2.2 AdminCodeOdsToDIm
- 6.2.3 ScenicBoundaryOdsToDIm
- 6.2.4 ScenicGridApp
- 6.3 dwi层数据处理(dwi权限,脚本执行)
-
- 6.3.1 MerGeLocationApp
- 6.3.2 dwi_staypoint_msk_d
- 6.4 dal_tour层数据处理(dal_tour权限,脚本执行)
-
- 6.4.1 CityTouristApp
- 6.4.2 CityTouristWideApp
- 6.4.3 ScenicTouristApp
- 6.4.4 ProvinceTouristApp
- 7 数据可视化
大数据旅游项目
1 项目分析
1.1 项目分析流程图
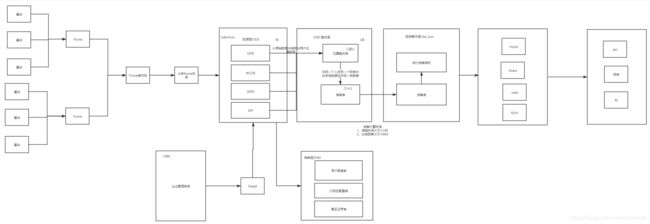
由于我们只负责数据从flume端拉来处理,所以纵观整个项目的架构,可以将数据处理分为四层,分别为ods(贴源层)、dwi(整合层)、dal_tour(旅游集市层)、dim(维表层),最终由dal_tour的结果存储在数据库便于数据展示
2 项目前期准备
2.1 hdfs权限验证
关闭hdfs
stop-all.sh
cd /usr/local/soft/hadoop-2.6.0/etc/hadoop
修改hdfs-site.xml
dfs.permissions
true
同步到所有节点
scp hdfs-site.xml node1:`pwd`
scp hdfs-site.xml node2:`pwd`
启动hadoop
start-all.sh
3 数仓前期准备
3.1 本地创建对应账号(root权限)
由于项目后期是具体责任到层,所以每一层会有专门的用户去访问工作,而在其他层这些用户只能阅读,甚至有时候练读都不可以
useradd ods
useradd dwi
useradd dim
useradd dal_tour
3.2 hdfs创建分层对应目录(root权限)
hadoop dfs -mkdir -p /daas/motl/ods/
hadoop dfs -mkdir -p /daas/motl/dwi/
hadoop dfs -mkdir -p /daas/motl/dim/
hadoop dfs -mkdir -p /daas/motl/dal_tour/
hadoop dfs -mkdir -p /user/ods/
hadoop dfs -mkdir -p /user/dwi/
hadoop dfs -mkdir -p /user/dim/
hadoop dfs -mkdir -p /user/dal_tour/
3.3 修改hdfs分层目录所属用户(root权限)
hadoop dfs -chmod 755 /user
hadoop dfs -chown ods:ods /daas/motl/ods/
hadoop dfs -chown dwi:dwi /daas/motl/dwi/
hadoop dfs -chown dim:dim /daas/motl/dim/
hadoop dfs -chown dal_tour:dal_tour /daas/motl/dal_tour/
hadoop dfs -chown ods:ods /user/ods/
hadoop dfs -chown dwi:dwi /user/dwi/
hadoop dfs -chown dim:dim /user/dim/
hadoop dfs -chown dal_tour:dal_tour /user/dal_tour/
3.4 hive进行分库(root权限)
3.4.1 hive后台启动命令
nohup hive --service metastore >> metastore.log 2>&1 &
3.4.2 修改tmp目录权限
hive需要存储临时文件
hadoop dfs -chmod 777 /tmp
hadoop dfs -chmod -R 755 /user
3.4.3 为每一个用户安装hive
cp -r /usr/local/soft/hive-1.2.1/ /home/ods/
cp -r /usr/local/soft/hive-1.2.1/ /home/dwi/
cp -r /usr/local/soft/hive-1.2.1/ /home/dim/
cp -r /usr/local/soft/hive-1.2.1/ /home/dal_tour/
3.4.4 修改权限
chown -R ods:ods /home/ods/hive-1.2.1/
chown -R dwi:dwi /home/dwi/hive-1.2.1/
chown -R dim:dim /home/dim/hive-1.2.1/
chown -R dal_tour:dal_tour /home/dal_tour/hive-1.2.1/
3.4.5 每个用户配置该用户环境变量
是为每一个用户,下面只是用ods用户举例,.bash_profile是隐藏文件用ls -a可以查看到
vim .bash_profile
export HIVE_HOME=/home/ods/hive-1.2.1
PATH=$PATH:$HOME/bin:$HIVE_HOME/bin
3.4.6 更改每个用户hive的临时目录
防止后面出现hive tmp的冲突,这里四个都有改,以dwi为例子
cd /home/dwi/hive-1.2.1/conf/
vim hive-site.xml
<property>
<name>hive.querylog.locationname>
<value>/home/dwi/hive-1.2.1/tmp/value>
<description>Location of Hive run time structured log filedescription>
property>
3.4.7 修改hive权限
hadoop dfs -chmod 777 /user/hive/warehouse
如果这里显示Name node is in safe mode,则说明当前分布式系统处于安全模式下,下面代码可以脱离安全模式
hadoop dfsadmin -safemode leave
4 建立数据仓库
4.1 每一个用户在hive创建每个库
4.1.1 报错问题
这里应该会出现问题,java.lang.RuntimeException: Unable to create log directory /usr/local/soft/hive-1.2.1/tmp ,解决方法:切换root用户到hive里将tmp目录加权限
chmod 777 tmp/

4.1.2 创库语句
create database ods;
create database dwi;
create database dim;
create database dal_tour;
4.2 ods层建表(ods权限)
4.2.1 ods_ddr
CREATE EXTERNAL TABLE IF NOT EXISTS ods.ods_ddr(
mdn string comment '手机号码'
,start_time string comment '业务时间'
,county_id string comment '区县编码'
,longi string comment '经度'
,lati string comment '纬度'
,bsid string comment '基站标识'
,grid_id string comment '网格号'
,biz_type string comment '业务类型'
,event_type string comment '事件类型'
,data_source string comment '数据源'
)
comment 'ddr'
PARTITIONED BY (
day_id string comment '天分区'
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/daas/motl/ods/ods_ddr';
/*增加分区*/
alter table ods.ods_ddr add if not exists partition(day_id='20180503') ;
4.2.2 ods_dpi
CREATE EXTERNAL TABLE IF NOT EXISTS ods.ods_dpi(
mdn string comment '手机号码'
,start_time string comment '业务开始时间'
,county_id string comment '区县编码'
,longi string comment '经度'
,lati string comment '纬度'
,bsid string comment '基站标识'
,grid_id string comment '网格号'
,biz_type string comment '业务类型'
,event_type string comment '事件类型'
,data_source string comment '数据源'
)
comment '位置数据融合表'
PARTITIONED BY (
day_id string comment '天分区'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/daas/motl/ods/ods_dpi';
/*增加分区*/
alter table ods.ods_dpi add if not exists partition(day_id='20180503') location '/daas/motl/ods/ods_dpi/day_id=20180503';
4.2.3 ods_wcdr
CREATE EXTERNAL TABLE IF NOT EXISTS ods.ods_wcdr (
mdn string comment '手机号码'
,start_time string comment '业务开始时间'
,county_id string comment '区县编码'
,longi string comment '经度'
,lati string comment '纬度'
,bsid string comment '基站标识'
,grid_id string comment '网格号'
,biz_type string comment '业务类型'
,event_type string comment '事件类型'
,data_source string comment '数据源'
)
comment 'wcdr'
PARTITIONED BY (
day_id string comment '天分区'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/daas/motl/ods/ods_wcdr';
/*增加分区*/
alter table ods.ods_wcdr add if not exists partition(day_id='20180503') location '/daas/motl/ods/ods_wcdr/day_id=20180503';
4.2.4 ods_oidd
CREATE EXTERNAL TABLE IF NOT EXISTS ods.ods_oidd(
mdn string comment '手机号码'
,start_time string comment '业务开始时间'
,county_id string comment '区县编码'
,longi string comment '经度'
,lati string comment '纬度'
,bsid string comment '基站标识'
,grid_id string comment '网格号'
,biz_type string comment '业务类型'
,event_type string comment '事件类型'
,data_source string comment '数据源'
)
comment 'oidd'
PARTITIONED BY (
day_id string comment '天分区'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/daas/motl/ods/ods_oidd';
/*增加分区*/
alter table ods.ods_oidd add if not exists partition(day_id='20180503') location '/daas/motl/ods/ods_oidd/day_id=20180503';
4.2.5 ods_usertag_m(用户画像表)
CREATE EXTERNAL TABLE IF NOT EXISTS ods.ods_usertag_m (
mdn string comment '手机号大写MD5加密'
,name string comment '姓名'
,gender string comment '性别,1男2女'
,age string comment '年龄'
,id_number string comment '证件号码'
,number_attr string comment '号码归属地'
,trmnl_brand string comment '终端品牌'
,trmnl_price string comment '终端价格'
,packg string comment '套餐'
,conpot string comment '消费潜力'
,resi_grid_id string comment '常住地网格'
,resi_county_id string comment '常住地区县'
)
comment '用户画像表'
PARTITIONED BY (
month_id string comment '月分区'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/daas/motl/ods/ods_usertag_m';
/*增加分区*/
alter table ods.ods_usertag_m add if not exists partition(month_id='201805') ;
4.2.6 ods_scenic_boundary
CREATE EXTERNAL TABLE IF NOT EXISTS ods.ods_scenic_boundary (
scenic_id string comment '景区id'
,scenic_name string comment '景区名称'
,boundary string comment '景区边界'
)
comment '景区配置表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/daas/motl/ods/ods_scenic_boundary';
4.2.7 ods_admincode
CREATE EXTERNAL TABLE IF NOT EXISTS ods.ods_admincode (
prov_id string comment '省id'
,prov_name string comment '省名称'
,city_id string comment '市id'
,city_name string comment '市名称'
,county_id string comment '区县id'
,county_name string comment '区县名称'
,city_level string comment '城市级别,一级为1;二级为2...依此类推'
,economic_belt string comment 'BJ为首都经济带、ZSJ为珠三角经济带、CSJ为长三角经济带、DB为东北经济带、HZ为华中经济带、HB为华北经济带、HD为华东经济带、HN为华南经济带、XB为西北经济带、XN为西南经济带'
,city_feature1 string comment 'NL代表内陆、YH代表沿海'
)
comment '行政区配置表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/daas/motl/ods/ods_admincode';
4.3 dwi层建表(dwi权限)
4.3.1 dwi_res_regn_mergelocation_msk_d(位置数据融合表)
CREATE EXTERNAL TABLE IF NOT EXISTS dwi.dwi_res_regn_mergelocation_msk_d (
mdn string comment '手机号码'
,start_time string comment '业务时间'
,county_id string comment '区县编码'
,longi string comment '经度'
,lati string comment '纬度'
,bsid string comment '基站标识'
,grid_id string comment '网格号'
,biz_type string comment '业务类型'
,event_type string comment '事件类型'
,data_source string comment '数据源'
)
comment '位置数据融合表'
PARTITIONED BY (
day_id string comment '天分区'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/daas/motl/dwi/dwi_res_regn_mergelocation_msk_d';
4.3.2 dwi_staypoint_msk_d(停留点表)
CREATE EXTERNAL TABLE IF NOT EXISTS dwi.dwi_staypoint_msk_d (
mdn string comment '用户手机号码'
,longi string comment '网格中心点经度'
,lati string comment '网格中心点纬度'
,grid_id string comment '停留点所在电信内部网格号'
,county_id string comment '停留点区县'
,duration string comment '机主在停留点停留的时间长度(分钟),lTime-eTime'
,grid_first_time string comment '网格第一个记录位置点时间(秒级)'
,grid_last_time string comment '网格最后一个记录位置点时间(秒级)'
)
comment '停留点表'
PARTITIONED BY (
day_id string comment '天分区'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/daas/motl/dwi/dwi_staypoint_msk_d';
4.4 dim层建表(dim权限)
4.4.1 dim_admincode
CREATE EXTERNAL TABLE IF NOT EXISTS dim.dim_admincode (
prov_id string comment '省id'
,prov_name string comment '省名称'
,city_id string comment '市id'
,city_name string comment '市名称'
,county_id string comment '区县id'
,county_name string comment '区县名称'
,city_level string comment '城市级别,一级为1;二级为2...依此类推'
,economic_belt string comment 'BJ为首都经济带、ZSJ为珠三角经济带、CSJ为长三角经济带、DB为东北经济带、HZ为华中经济带、HB为华北经济带、HD为华东经济带、HN为华南经济带、XB为西北经济带、XN为西南经济带'
,city_feature1 string comment 'NL代表内陆、YH代表沿海'
)
comment '行政区配置表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/daas/motl/dim/dim_admincode';
4.4.2 dim_bsid
CREATE EXTERNAL TABLE IF NOT EXISTS dim.dim_bsid (
bsid string comment '扇区编码'
,bsc_longi string comment '基站经度'
,bsc_lati string comment '基站纬度'
,center_longi string comment '扇区中心点经度'
,center_lati string comment '扇区中心点维度'
,boundary string comment '扇区边界顶点坐标'
,city_code string comment '城市区号'
,country_id string comment '区县编码'
,city_id string comment '城市编码'
,prov_id string comment '省编码'
)
comment '扇区配置表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/daas/motl/dim/dim_bsid';
4.4.3 dim_geotag_grid
CREATE EXTERNAL TABLE IF NOT EXISTS dim.dim_geotag_grid (
grid_id string comment '网格ID,500米级别'
,center_longi string comment '中心点经度'
,center_lati string comment '中心点纬度'
,county_id string comment '区县id'
,county_type string comment '区县类型,0郊区,1城区'
,grid_type string comment '网格类型,详见网格类型码表'
)
comment 'gis网格配置表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS PARQUET
location '/daas/motl/dim/dim_geotag_grid';
4.4.4 dim_scenic_boundary
CREATE EXTERNAL TABLE IF NOT EXISTS dim.dim_scenic_boundary (
scenic_id string comment '景区id'
,scenic_name string comment '景区名称'
,boundary string comment '景区边界'
)
comment '景区配置表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/daas/motl/dim/dim_scenic_boundary';
4.4.5 dim_usertag_msk_m
CREATE EXTERNAL TABLE IF NOT EXISTS dim.dim_usertag_msk_m (
mdn string comment '手机号大写MD5加密'
,name string comment '姓名'
,gender string comment '性别,1男2女'
,age string comment '年龄'
,id_number string comment '证件号码'
,number_attr string comment '号码归属地'
,trmnl_brand string comment '终端品牌'
,trmnl_price string comment '终端价格'
,packg string comment '套餐'
,conpot string comment '消费潜力'
,resi_grid_id string comment '常住地网格'
,resi_county_id string comment '常住地区县'
)
comment '用户画像表'
PARTITIONED BY (
month_id string comment '月分区'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/daas/motl/dim/dim_usertag_msk_m';
4.4.6 dim_scenic_grid
CREATE EXTERNAL TABLE IF NOT EXISTS dim.dim_scenic_grid (
scenic_id string comment '景区id'
,scenic_name string comment '景区名称'
,grid string comment '网格编号'
)
comment '景区网格配置表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/daas/motl/dim/dim_scenic_grid';
4.5 dal_tour层建表(dal_tour权限)
4.5.1 dal_tour_city_tourist_msk_d
CREATE EXTERNAL TABLE IF NOT EXISTS dal_tour.dal_tour_city_tourist_msk_d (
mdn string comment '手机号大写MD5加密'
,source_county_id string comment '游客来源区县'
,d_city_id string comment '旅游目的地市代码'
,d_stay_time double comment '游客在该省停留的时间长度(小时)'
,d_max_distance double comment '游客本次出游距离'
)
comment '旅游应用专题数据城市级别-天'
PARTITIONED BY (
day_id string comment '日分区'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/daas/motl/dal_tour/dal_tour_city_tourist_msk_d';
/*增加分区*/
alter table dal_tour.dal_tour_city_tourist_msk_d add if not exists partition(day_id='20180503') ;
4.5.2 dal_tour_city_day_index
CREATE EXTERNAL TABLE IF NOT EXISTS dal_tour.dal_tour_city_day_index (
d_city_id string comment '旅游目的地市代码'
,d_city_name string comment '旅游目的地市名'
,o_city_id string comment '旅游来源地地市代码'
,o_city_name string comment '旅游来源地地市名'
,o_province_id string comment '旅游来源地地省代码'
,o_province_name string comment '旅游来源地省名'
,number_attr string comment '号码归属地'
,d_distance_section string comment '出游距离'
,d_stay_time int comment '停留时间按小时'
,gender string comment '性别'
,trmnl_brand string comment '终端品牌'
,pckg_price int comment '套餐'
,conpot int comment '消费潜力'
,age int comment '年龄'
,only_pt int comment '电信游客量'
)
comment '旅游应用专题数据城市级别-天-宽表'
PARTITIONED BY (
day_id string comment '日分区'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/daas/motl/dal_tour/dal_tour_city_day_index';
4.5.3 dal_tour_scenic_tourist_msk_d
CREATE EXTERNAL TABLE IF NOT EXISTS dal_tour.dal_tour_scenic_tourist_msk_d (
mdn string comment '游客手机号码'
,source_city_id string comment '游客来源城市'
,d_scenic_id string comment '旅游目的地景区代码'
,d_scenic_name string comment '旅游目的地景区名'
,d_arrive_time string comment '游客进入景区的时间'
,d_stay_time double comment '游客在该景区停留的时间长度(小时)'
)
comment '旅游应用专题数据景区级别-天'
PARTITIONED BY (
day_id string comment '日分区'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/daas/motl/dal_tour/dal_tour_scenic_tourist_msk_d';
/*增加分区*/
alter table dal_tour.dal_tour_scenic_tourist_msk_d add if not exists partition(day_id='20180503')
4.5.4 dal_tour_province_tourist_msk_d
CREATE EXTERNAL TABLE IF NOT EXISTS dal_tour.dal_tour_province_tourist_msk_d (
mdn string comment '手机号大写MD5加密'
,source_county_id string comment '游客来源区县'
,d_province_id string comment '旅游目的地省代码'
,d_stay_time double comment '游客在该省停留的时间长度(小时)'
,d_max_distance double comment '游客本次出游距离'
)
comment '旅游应用专题数据省级别-天'
PARTITIONED BY (
day_id string comment '日分区'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/daas/motl/dal_tour/dal_tour_province_tourist_msk_d';
/*增加分区*/
alter table dal_tour.dal_tour_province_tourist_msk_d add if not exists partition(day_id='20180503') location '/daas/motl/dal/tour/dal_tour_province_tourist_msk_d/day_id=20180503';
5 数据集成
5.1 ods数据集成,上传hdfs
这边省略了flume数据采集的功能,因为运用flume采集数据会很慢,因而这边直接给数据,注意切换到数据所在目录执行代码,为了方便可以把原来创建的文件全部删除,直接put所有文件
hdfs dfs -rmr /daas/motl/ods/*
hdfs dfs -put * /daas/motl/ods
上传完成后发现权限不对,因为刚才使用root用户传的,因而进一步修改权限,-R表示递归修改
hadoop dfs -chown -R ods:ods /daas/motl/ods/*
5.2 数据库数据准备
5.2.1 mysql建库
5.2.2 创建usertag(用户表)并导入数据
数据被放在了/root/data下
DROP TABLE IF EXISTS `usertag`;
CREATE TABLE `usertag` (
mdn varchar(255)
,name varchar(255)
,gender varchar(255)
,age int(10)
,id_number varchar(255)
,number_attr varchar(255)
,trmnl_brand varchar(255)
,trmnl_price varchar(255)
,packg varchar(255)
,conpot varchar(255)
,resi_grid_id varchar(255)
,resi_county_id varchar(255)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*导入数据*/
LOAD DATA LOCAL INFILE '/root/data/usertag.txt' INTO TABLE usertag FIELDS TERMINATED BY ',' ;
5.2.3 创建scenic_boundary(景区配置表)并导入数据
CREATE TABLE scenic_boundary (
scenic_id varchar(255) ,
scenic_name varchar(255) ,
boundary text
) ;
/*导入数据*/
LOAD DATA LOCAL INFILE '/root/data/scenic_boundary.txt' INTO TABLE scenic_boundary FIELDS TERMINATED BY '|' ;
5.2.4 创建admin_code(行政区配置表)并导入数据
CREATE TABLE admin_code (
prov_id varchar(255)
,prov_name varchar(255)
,city_id varchar(255)
,city_name varchar(255)
,county_id varchar(255)
,county_name varchar(255)
,city_level varchar(255)
,economic_belt varchar(255)
,city_feature1 varchar(255)
) ;
/*导入数据*/
LOAD DATA LOCAL INFILE '/root/data/ssxdx.txt' INTO TABLE admin_code FIELDS TERMINATED BY ',' ;
5.3 datax拉取数据
5.3.1 编写usertag_mysql_to_usertag_hive_ods.json
放在/home/ods 目录下
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://master:3306/tour"
],
"table": [
"usertag"
],
}
],
"column": ["*"],
"password": "123456",
"username": "root"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://master:9000",
"fileType": "text",
"path": "/daas/motl/ods/ods_usertag_m/month_id=${month_id}",
"fileName": "data",
"column": [
{
"name": "mdn",
"type": "STRING"
},
{
"name": "name",
"type": "STRING"
},
{
"name": "gender",
"type": "STRING"
},
{
"name": "age",
"type": "INT"
},
{
"name": "id_number",
"type": "STRING"
},
{
"name": "number_attr",
"type": "STRING"
},
{
"name": "trmnl_brand",
"type": "STRING"
},
{
"name": "trmnl_price",
"type": "STRING"
},
{
"name": "packg",
"type": "STRING"
},
{
"name": "conpot",
"type": "STRING"
},
{
"name": "resi_grid_id",
"type": "STRING"
},
{
"name": "resi_county_id",
"type": "STRING"
}
],
"writeMode": "append",
"fieldDelimiter": "\t"
}
}
}
],
"setting": {
"errorLimit": {
"percentage": 0,
"record": 0
},
"speed": {
"channel": 4,
"record": 1000
}
}
}
}
5.3.2 hdfs创建数据归属目录
hdfs dfs -mkdir -p /daas/motl/ods/ods_usertag_m/month_id=201805
5.3.3 执行导入数据代码(ods权限)
datax.py -p "-Dmonth_id=201805" usertag_mysql_to_usertag_hive_ods.json
5.3.4 编写scenic_boundary_mysql_to_scenic_boundary_hive_dim.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://master:3306/tour"
],
"table": [
"scenic_boundary"
],
}
],
"column": ["*"],
"password": "123456",
"username": "root"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://master:9000",
"fileType": "text",
"path": "/daas/motl/ods/ods_scenic_boundary",
"fileName": "data",
"column": [
{
"name": "scenic_id",
"type": "STRING"
},
{
"name": "scenic_name",
"type": "STRING"
},
{
"name": "boundary",
"type": "STRING"
}
],
"writeMode": "append",
"fieldDelimiter": "\t"
}
}
}
],
"setting": {
"errorLimit": {
"percentage": 0,
"record": 0
},
"speed": {
"channel": 1,
"record": 1000
}
}
}
}
5.3.5 hdfs创建数据归属目录
hdfs dfs -mkdir -p /daas/motl/ods/ods_scenic_boundary
5.3.6 执行导入数据代码(ods权限)
datax.py scenic_boundary_mysql_to_scenic_boundary_hive_dim.json
5.3.7 编写admin_code_mysql_to_admin_code_hive_dim.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://master:3306/tour"
],
"table": [
"admin_code"
],
}
],
"column": ["*"],
"password": "123456",
"username": "root"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://master:9000",
"fileType": "text",
"path": "/daas/motl/ods/ods_admincode",
"fileName": "data",
"column": [
{
"name": "prov_id",
"type": "STRING"
},
{
"name": "prov_name",
"type": "STRING"
},
{
"name": "city_id",
"type": "STRING"
},
{
"name": "city_name",
"type": "STRING"
},
{
"name": "county_id",
"type": "STRING"
},
{
"name": "county_name",
"type": "STRING"
},
{
"name": "city_level",
"type": "STRING"
},
{
"name": "economic_belt",
"type": "STRING"
},
{
"name": "city_feature1",
"type": "STRING"
}
],
"writeMode": "append",
"fieldDelimiter": "\t"
}
}
}
],
"setting": {
"errorLimit": {
"percentage": 0,
"record": 0
},
"speed": {
"channel": 1,
"record": 1000
}
}
}
}
5.3.8 hdfs创建数据归属目录
hdfs dfs -mkdir -p /daas/motl/ods/ods_admincode
5.3.9 执行导入数据代码(ods权限)
datax.py admin_code_mysql_to_admin_code_hive_dim.json
6 数据处理
6.1 创建maven项目my_dwi_tour
具体代码如下,git拉取
https://gitee.com/xiaoyoupei/my_dwi_tour.git
6.2 dim层数据处理(dim权限,脚本执行)
6.2.1 UserTagOdsToDIm
UserTagOdsToDIm,主要的功能就是将ods层的用户画像表导入dim层,对数据进行脱敏,下面是集群提交脚本
#!/usr/bin/env bash
month_id=$1
spark-submit \
--class com.shujia.dim.UserTagOdsToDIm \
--master yarn-client \
--jars common-1.0.jar \
dim-1.0.jar \
${month_id}
6.2.2 AdminCodeOdsToDIm
AdminCodeOdsToDIm,主要的功能是将ods层的行政区配置表导入dim层
#!/usr/bin/env bash
spark-submit \
--class com.shujia.dim.AdminCodeOdsToDIm \
--master yarn-client \
dim-1.0.jar
6.2.3 ScenicBoundaryOdsToDIm
ScenicBoundaryOdsToDIm,主要的功能是将ods层的景区配置表导入dim层
#!/usr/bin/env bash
spark-submit \
--class com.shujia.dim.ScenicBoundaryOdsToDIm \
--master yarn-client \
dim-1.0.jar
6.2.4 ScenicGridApp
ScenicGridApp,景区网格配置表,主要的功能是用于匹配所有景区所的网格
#!/usr/bin/env bash
spark-submit \
--class com.shujia.dim.ScenicGridApp \
--master yarn-client \
--num-executors 2 \
--executor-memory 2G \
--executor-cores 2 \
--jars common-1.0.jar \
dim-1.0.jar
6.3 dwi层数据处理(dwi权限,脚本执行)
6.3.1 MerGeLocationApp
MerGeLocationApp(位置融合表),主要是将ods层的数据进行整合脱敏处理
#!/usr/bin/env bash
day_id=$1
spark-submit \
--class com.shujia.dwi.MerGeLocationApp \
--master yarn-client \
--num-executors 2 \
--executor-memory 2G \
--executor-cores 4 \
--jars common-1.0.jar \
dwi-1.0.jar \
${day_id}
6.3.2 dwi_staypoint_msk_d
dwi_staypoint_msk_d(停留点表),主要是将MerGeLocationApp表进一步处理数据
#!/usr/bin/env bash
day_id=$1
spark-submit \
--class com.shujia.dwi.StayPointApp \
--master yarn-client \
--num-executors 2 \
--executor-memory 4G \
--executor-cores 1 \
--jars common-1.0.jar \
--conf spark.network.timeout=10000s \
dwi-1.0.jar \
${day_id}
6.4 dal_tour层数据处理(dal_tour权限,脚本执行)
6.4.1 CityTouristApp
CityTouristApp,旅游应用专题数据城市级别-天,主要功能
本表主要思路是搞清楚两个要求:
1、判断最大的出游距离是否大于10KM
2、判断总的停留时间是否大于3个小时
#!/usr/bin/env bash
day_id=$1
spark-submit \
--class com.shujia.tour.CityTouristApp \
--master yarn-client \
--num-executors 2 \
--executor-memory 4G \
--executor-cores 1 \
--jars common-1.0.jar \
dal_tour-1.0.jar \
${day_id}
6.4.2 CityTouristWideApp
CityTouristWideApp,旅游应用专题数据城市级别-天-宽表,主要功能是将实际需求进行整理抽离出需求字段制作宽表,方便直接拉取
#!/usr/bin/env bash
day_id=$1
spark-submit \
--class com.shujia.tour.CityTouristWideApp \
--master yarn-client \
--num-executors 2 \
--executor-memory 4G \
--executor-cores 1 \
--jars common-1.0.jar \
dal_tour-1.0.jar \
${day_id}
6.4.3 ScenicTouristApp
ScenicTouristApp,旅游应用专题数据景区级别-天,主要功能是应用旅游应用专题数据景区级别
#!/usr/bin/env bash
day_id=$1
spark-submit \
--class com.shujia.tour.ScenicTouristApp \
--master yarn-client \
--num-executors 2 \
--executor-memory 2G \
--executor-cores 2 \
--jars common-1.0.jar \
dal_tour-1.0.jar \
${day_id}
6.4.4 ProvinceTouristApp
ProvinceTouristApp省游客计算,主要功能是计算省游客数据
#!/usr/bin/env bash
#!/usr/bin/env bash
#***********************************************************************************
# ** 文件名称: ProvinceTouristAppRun.sh
# ** 创建日期: 2021年3月18日
# ** 编写人员: xiaoyoupei
# ** 输入信息:
# ** 输出信息:
# **
# ** 功能描述:市游客计算
# ** 处理过程:
# ** Copyright(c) 2016 TianYi Cloud Technologies (China), Inc.
# ** All Rights Reserved.
#***********************************************************************************
#***********************************************************************************
#==修改日期==|===修改人=====|======================================================|
#
#***********************************************************************************
#获取脚本所在目录
shell_home="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )"
#进入脚本目录
cd $shell_home
day_id=$1
spark-submit \
--class com.shujia.tour.ProvinceTouristApp \
--master yarn-client \
--num-executors 2 \
--executor-memory 4G \
--executor-cores 1 \
--jars common-1.0.jar \
dal_tour-1.0.jar \
${day_id}
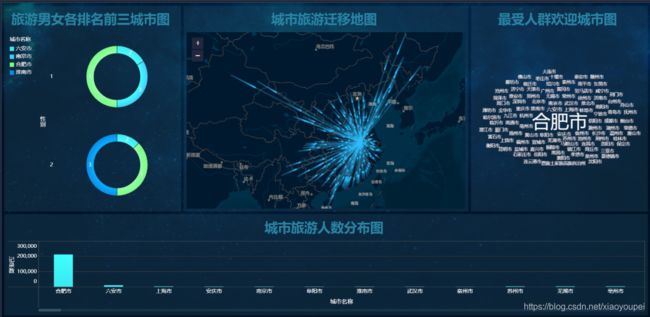
7 数据可视化
利用可视化的工具进行数据展示,这里选用的是FineBi(linux版),显示一部分,具体的使用操作finebi官网有详细的说明