Redis中的基本数据类型及其存储原理
前言
redis是一种常见的NOSQL数据库,它支持五种数据类型:String字符串,Hash哈希,List列表,Set集合及ZSet有序集合,今天我们来讲讲它们的用法以及存储原理
基本数据类型
String字符串
主要用来存储字符串、整数、浮点数
操作命令
插入一个值
set test 1
批量插入
mset tom 2 jack 6
获取值
get test
批量获取
mget tom jack
加锁插入,如果 key 存在,则不成功。可用于分布式锁,可通过del key释放锁
setnx test 1
设置过期时间
set key value [expiration EX seconds|PX milliseconds][NX|XX]
set test 1 EX 10 NX
值递增
incr test
incrby test100
值递减
decr test
decrby test 100
存储原理
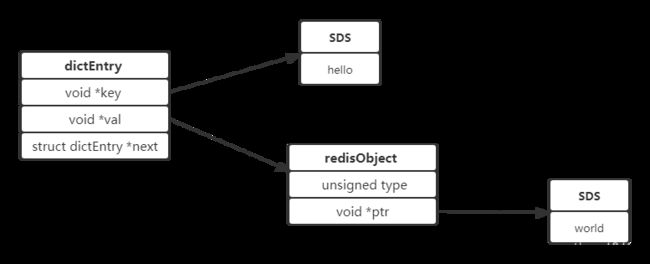
redis是字典结构的存储方式,采用 key-value 存储。key 和 value 的最大长度限制是512M。redis是用C语言开发的数据库,我们先看看源码,源码的下载地址:http://download.redis.io/releases/
redis-6.0.8\src\dict.h:dictEntry
typedef struct dictEntry {
void *key; //key定义
union {
void *val; //value定义
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; //指向下一个键值对节点
} dictEntry;
key是字符串,但是C语言里面没有字符串,只能通过字符数组。但是redis里没有通过字符数组去管理字符串,而是自定义了一种SDS的结构。
value也不是直接作为字符串存储,也不是存储在SDS中,而是存储在redisObject中,实际上五种常用的数据类型的任何一种,都是通过 redisObject 来存储。
redis-6.0.8\src\server.h:redisObject
typedef struct redisObject {
unsigned type:4; /*对象的类型,包括:OBJ_STRING、OBJ_LIST、OBJ_HASH、OBJ_SET、OBJ_ZSET*/
unsigned encoding:4;/*具体的数据结构*/
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;/*引用计数。当refcount为0的时候,表示该对象已经不被任何对象引用,则可以进行垃圾回收了*/
void *ptr;/*指向真正的数据结构*/
} robj;
在 3.2 以后的版本中,SDS 又有多种结构(sds.h):sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdshdr64,用于存储不同的长度的字符串,分别代表 2^5=32byte, 28=256byte,216=65536byte=64KB,2^32byte=4GB。
redis-6.0.8\src\sds.h:sdshdr8
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* 当前字符数组的长度 */
uint8_t alloc; /*当前字符数组总共分配的内存大小 */
unsigned char flags; /* 当前字符数组的属性、用来标识到底是 sdshdr8 还是 sdshdr16 等*/
char buf[];/*字符串真正的值*/
};
以set hello world为例,它的数据结构如下图:
内部编码
通过上面的结构我们知道在redisObject结构中有一个encoding是管理其编码的,接下来我们通过命令来看看字符串类型内部的编码:
127.0.0.1:6379> set num 1
OK
127.0.0.1:6379> set tom "abcdefghijklmnopqrstuvwrasqqdggwqeqrqrdcvbfheerqzzfegbnttqeq"
OK
127.0.0.1:6379> set jack bighead
OK
127.0.0.1:6379> object encoding num
"int"
127.0.0.1:6379> object encoding jack
"embstr"
127.0.0.1:6379> object encoding tom
"raw"
字符串类型的内部编码有三种:
- int,存储 8 个字节的长整型(long,2^63-1)
- embstr, 代表 embstr 格式的 SDS(Simple Dynamic String 简单动态字符串), 存储小于 44 个字节的字符串
- raw,存储大于 44 个字节的字符串(3.2 版本之前是 39 字节)
这个44在代码中有定义:
/* Create a string object with EMBSTR encoding if it is smaller than
* OBJ_ENCODING_EMBSTR_SIZE_LIMIT, otherwise the RAW encoding is
* used.
*
* The current limit of 44 is chosen so that the biggest string object
* we allocate as EMBSTR will still fit into the 64 byte arena of jemalloc. */
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
问题
1.为什么不直接使用字符数组,而是重新定义一个SDS结构?
我们知道,C语言本身没有字符串类型(只能用字符数组 char[]实现)。所以就会有以下问题:
- 使用字符数组必须先给目标变量分配足够的空间,否则可能会溢出。
- 如果要获取字符长度,必须遍历字符数组,时间复杂度是 O(n)。
- C 字符串长度的变更会对字符数组做内存重分配。
- 通过从字符串开始到结尾碰到的第一个’\0’来标记字符串的结束,因此不能保 存图片、音频、视频、压缩文件等二进制(bytes)保存的内容,二进制不安全
而SDS的特点:
- 不用担心内存溢出问题,如果需要会对SDS进行扩容
- 获取字符串长度时间复杂度为 O(1),因为定义了len属性
- 通过“空间预分配”( sdsMakeRoomFor)和“惰性空间释放”,防止多次重分配内存
- 判断是否结束的标志是 len 属性(它同样以’\0’结尾是因为这样就可以使用 C语言中函数库操作字符串的函数了),可以包含’\0’
2.embstr 和 raw 的区别
embstr 的使用只分配一次内存空间(因为 RedisObject 和 SDS 是连续的),而 raw 需要分配两次内存空间(分别为 RedisObject 和 SDS 分配空间)。 因此与 raw 相比,embstr 的好处在于创建时少分配一次空间,删除时少释放一次 空间,以及对象的所有数据连在一起,寻找方便。 而 embstr 的坏处也很明显,如果字符串的长度增加需要重新分配内存时,整个 RedisObject 和 SDS 都需要重新分配空间,因此 Redis 中的 embstr 实现为只读。
应用场景
- 热点数据
- 分布式锁
- 全局ID
- 计数器
Hash哈希
包含键值对的无序散列表。value 只能是字符串,不能嵌套其他类型
操作命令
插入
hset name key val
批量插入
hmset name k1 v1 k2 v2 k3 v3
取值
hget name k1
批量取值
hmget name k1,k2,k3
获得所有的key
hkeys name
获得所有的value
hvals name
存储原理
redis的Hash 本身也是一个 KV 的结构,类似于 Java 中的HashMap
hash底层主要使用两种数据结构实现:ziplist和hashtable
ziplist压缩列表
在ziplist.c文件中有这样一句话:
The ziplist is a specially encoded dually linked list that is designed to be very memory efficient. It stores both strings and integer values, where integers are encoded as actual integers instead of a series of characters. It allows push and pop operations on either side of the list in O(1) time. However, because every operation requires a reallocation of the memory used by the ziplist, the actual complexity is related to the amount of memory used by the ziplist.
翻译过来就是:
ziplist 是一个经过特殊编码的双向链表,它不存储指向上一个链表节点和指向下一 个链表节点的指针,而是存储上一个节点长度和当前节点长度,通过牺牲部分读写性能,来换取高效的内存空间利用率,是一种时间换空间的思想。只用在字段个数少,字段值小的场景里面。
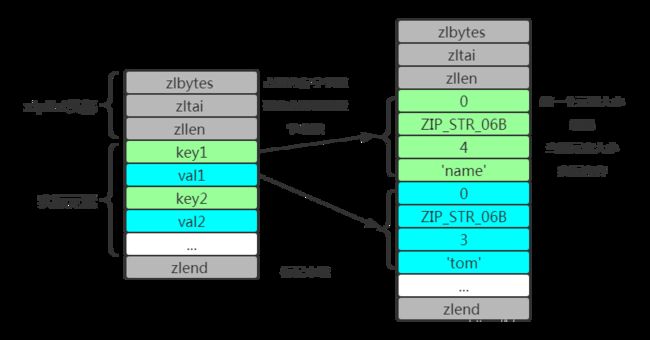
ziplist的结构如下:
< zlbytes > < zltai > < zllen > < entry > < entry > … < entry > < zlend >
我们先来看一下entry的底层结构:
redis-6.0.8\src\ziplist.c:zlentry
typedef struct zlentry {
unsigned int prevrawlensize; /* 上一个链表节点占用的长度*/
unsigned int prevrawlen; /* Previous entry len. */
unsigned int lensize; /* 存储当前链表节点长度数值所需要的字节数*/
unsigned int len; /* 当前链表节点占用的长度 */
unsigned int headersize; /* prevrawlensize + lensize. */
unsigned char encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending on
the entry encoding. However for 4 bits
immediate integers this can assume a range
of values and must be range-checked. */
unsigned char *p; /* 压缩链表以字符串的形式保存,该指针指向当前节点起始位置 */
} zlentry;
ziplist整体结构如下图所示:
hashtable(dict)
在 redis 中,hashtable 被称为字典(dictionary),它是一个数组+链表的结构。当一个哈希对象超过配置的阈值,即键和值的长度有>64byte,键值对个数>512 个时, 会转换成哈希表(hashtable)
先来看一下hashtable结构:
redis-6.0.8\src\dict.h:dictht
typedef struct dictht {
dictEntry **table; /* 哈希表数组 */
unsigned long size; /* 哈希表大小 */
unsigned long sizemask;/* 掩码大小,用于计算索引值。总是等于 size-1 */
unsigned long used;/* 已有节点数 */
} dictht;
ht又放到dict里面
redis-6.0.8\src\dict.h:dict
typedef struct dict {
dictType *type;/* 字典类型 */
void *privdata;
dictht ht[2];/* 一个字典有两个哈希表 日常使用ht[0],ht[1]不会初始化*/
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
所以,hashtable结构如下图所示:

问题
1.什么时候使用 ziplist 存储?
当 hash 对象同时满足以下两个条件的时候,使用 ziplist 编码:
- 所有的键值对的健和值的字符串长度都小于等于 64byte(一个英文字母 一个字节)
- 哈希对象保存的键值对数量小于 512 个
redis-6.0.8\src\redis.conf
hash-max-ziplist-value 64 // ziplist 中最大能存放的值长度
hash-max-ziplist-entries 512 // ziplist 中最多能存放的 entry 节点数量
2.dict里面为什么会定义两个hash表呢?
主要是用来扩容
redis 的 hash 默认使用的是 ht[0],ht[1]不会初始化和分配空间。
哈希表 dictht 是用链地址法来解决碰撞问题的。在这种情况下,哈希表的性能取决 于它的大小(size 属性)和它所保存的节点的数量(used 属性)之间的比率:
- 比率在 1:1 时(一个哈希表 ht 只存储一个节点 entry),哈希表的性能最好;
- 如果节点数量比哈希表的大小要大很多的话(这个比例用 ratio 表示,5 表示平均 24 一个 ht 存储 5 个 entry),那么哈希表就会退化成多个链表,哈希表本身的性能 优势就不再存在。 在这种情况下需要扩容。
redis 里面的这种操作叫做 rehash。 rehash 的步骤:
- 为字符 ht[1]哈希表分配空间,这个哈希表的空间大小取决于要执行的操作,以 及 ht[0]当前包含的键值对的数量。 扩展:ht[1]的大小为第一个大于等于 ht[0].used*2。
- 将所有的 ht[0]上的节点 rehash 到 ht[1]上,重新计算 hash 值和索引,然后放 入指定的位置。
- 当 ht[0]全部迁移到了 ht[1]之后,释放 ht[0]的空间,将 ht[1]设置为 ht[0]表, 并创建新的 ht[1],为下次 rehash 做准备。
3.dict什么时候触发扩容?
redis-6.0.8\src\redis.conf
static int dict_can_resize = 1;
static unsigned int dict_force_resize_ratio = 5; //ratio = used / size,
已使用节点与字典大小的比例 dict_can_resize 为 1 并且 dict_force_resize_ratio 已使用节点数和字典大小之间的 比率超过 1:5,触发扩容
应用场景
- 存储对象类型的数据,类似于购物车
List列表
存储有序的字符串(从左到右),元素可以重复。
操作命令
插入
lpush name val
lpush name v1 v2
rpush name v1 v2
取值
lpop name
rpop name
存储原理
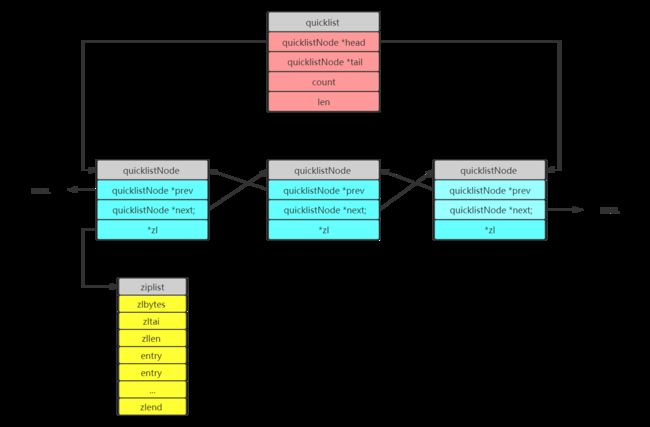
在3.2版本之后,采用quicklist+ziplist实现
quicklist
quicklist是 ziplist 和 linkedlist 的结合体
redis-6.0.8\src\quicklist.h:quicklist
typedef struct quicklist {
quicklistNode *head; /* 指向双向列表的表头 */
quicklistNode *tail;/* 指向双向列表的表尾 */
unsigned long count; /* 所有的 ziplist 中一共存了多少个元素 */
unsigned long len; /* 双向链表的长度,node 的数量 */
int fill : QL_FILL_BITS; /* fill factor for individual nodes */
unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
redis-6.0.8\src\quicklist.h:quicklistNode
typedef struct quicklistNode {
struct quicklistNode *prev;/* 前一个节点 */
struct quicklistNode *next; /* 后一个节点 */
unsigned char *zl; /* 指向实际的 ziplist */
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
quicklist结构如下图所示:
应用场景
- 用户消息时间线
- 消息队列
Set集合
存储的String 类型的无序集合,最大存储数量 2^32-1(40 亿左右)。
操作命令
添加
sadd name v1 v2 v3
获取所有元素
smembers name
统计元素个数
scard name
随机弹出一个元素
spop name
移除元素
srem name v1 v2 v3
查看元素是否存在
sismember name v1
存储原理
Set用 intset 或 hashtable存储。如果元素都是整数类型,就用 inset 存储。 如果不是整数类型,就用 hashtable(key就是元素的值,value为null)
我们先来看看intset结构:
redis-6.0.8\src\intset.h:intset
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;
如果元素个数超过 512 个,也会用 hashtable 存储,hashtable上面我有讲过,这里不再叙述
应用场景
- 抽奖
- 点赞、打卡、签到
- 标签
ZSet有序集合
sorted set,有序的 set,每个元素有个 score。 当score 相同时,按照 key 的 ASCII 码排序
操作命令
添加
zadd myname 10 java 20 php 30 ruby 40 cpp 50 python
获取元素
zrange myzset 0 -1 withscores
zrevrange myzset 0 -1 withscores
获取分值区间元素
zrangebyscore myzset 20 30
统计元素个数
zcard myzset
根据分值统计个数
zcount myzset 20 60
获取元素score
zsocre myzset java
存储原理
同时满足以下条件时使用 ziplist 编码:
- 元素数量小于 128 个
- 所有 member 的长度都小于 64 字节
在 ziplist 的内部,按照 score 排序递增来存储。插入的时候要移动之后的数据
超过阈值之后,使用 skiplist+dict 存储
我们下来看看什么是skiplist:

就是在有序列表的基础上加上层级,比如7,12,21又形成一个新的链表
再来看看ziplist 底层结构
redis-6.0.8\src\server.h:zset
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
redis-6.0.8\src\server.h:zskiplist
typedef struct zskiplist {
struct zskiplistNode *header, *tail; /* 指向跳跃表的头结点和尾节点 */
unsigned long length;/* 跳跃表的节点数 */
int level; /* 最大的层数 */
} zskiplist;
redis-6.0.8\src\server.h:zskiplistNode
typedef struct zskiplistNode {
sds ele; /* zset 的元素 */
double score; /* 分值 */
struct zskiplistNode *backward; /* 后退指针 */
struct zskiplistLevel {
struct zskiplistNode *forward;/* 前进指针,对应 level 的下一个节点 */
unsigned long span; /* 从当前节点到下一个节点的跨度(跨越的节点数) */
} level[];/* 层 */
} zskiplistNode;
应用场景
- 排行榜