c++ opencv实现区域填充_OpenCV简介及其工程应用——游戏色块检测
OpenCV是一个基于BSD许可(开源)发行的跨平台的计算机视觉和机器学习软件库,可以运行在Linux、Windows、Android和Mac OS操作系统上。它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,同时提供了Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。
OpenCV在图像分割、人脸识别、物体识别、动作跟踪、动作分析、机器视觉等领域都有广泛的应用。以下是OpenCV的基本操作及其应用案例。
一、OpenCV基本操作
1. 读取、显示以及保存操作
import cv2
image = cv2.imread("test.jpg") # 读取操作
cv2.imshow("test", image) # 显示操作
cv2.waitKey() # 等待按键
cv2.imwrite("save.jpg") # 保存操作 2. 改变色彩空间
image = cv2.imread("test.jpg")
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV) # 转换到HSV空间
hls = cv2.cvtColor(image, cv2.COLOR_BGR2HLS) # 转换到HLS空间
lab = cv2.cvtColor(image, cv2.COLOR_BGR2Lab) # 转换到Lab空间
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 转换到GRAY空间(灰度图) 
HSV这个模型中颜色的参数分别是:色调(H),饱和度(S),明度(V),该模型常用来做绿幕分割。
在图像检测中,可以对样本进行色彩空间转换实现数据增强,如将训练数据直接转换到HSV空间,或者调整V(明度)通道的大小,改变图片的明暗,再转到BGR格式。
3. 几何变换–缩放、平移、旋转
a. 缩放
image = cv2.imread("test.jpg")
resize = cv2.resize(image, (), fx=0.5, fy=0.5, interpolation=cv2.INTER_AREA) # 长宽缩小到0.5倍
b. 平移
在对图像作平移操作时,需创建2行3列变换矩阵,M矩阵表示水平方向上平移为x,竖直方向上的平移距离为y。
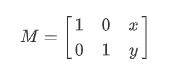
import cv2
import numpy as np
image = cv2.imread("test.jpg")
rows, cols, channels = image.shape
M = np.float32([[1,0,100],[0,1,50]])
res = cv.warpAffine(image, M, (cols, rows))
c. 旋转
旋转所需的变换矩阵可以通过函数cv2.getRotationMatrix2D得到。
image = cv2.imread('test.jpg')
rows, cols, channels = image.shape
rotate = cv2.getRotationMatrix2D((rows*0.5, cols*0.5), 45, 1) # 第一个参数:旋转中心点 第二个参数:旋转角度 第三个参数:缩放比例
res = cv2.warpAffine(image, rotate, (cols, rows))
4. 平滑处理–模糊、滤波
模糊滤波操作去除图像中的椒盐噪声、提高图像的对比度、实现锐化处理、提高立体感等。
image = cv2.imread('test.jpg')
blur = cv2.blur(image, (5, 5)) # 均值滤波 第二个参数是卷积核大小
median_blur = cv2.medianBlur(image, 5) # 中值滤波
gaussian_blur = cv2.GussianBlur(image, (5, 5)) # 高斯模糊
5. 膨胀、侵蚀
a. 图像形态学操作
图像形态学操作是基于形状的一系列图像处理操作的合集,主要是基于集合论基础上的形态学数学
- 形态学有四个基本操作:侵蚀、膨胀、开、闭
- 膨胀与腐蚀是图像处理中最常用的形态学操作手段
- 膨胀就是图像中的高亮部分进行膨胀,“领域扩张”,效果图拥有比原图更大的高亮区域。侵蚀就是原图中的高亮部分被腐蚀,“领域被蚕食”,效果图拥有比原图更小的高亮区域
b. 膨胀与侵蚀
它们能实现多种多样的功能,主要如下:
- 消除噪声
- 分割出独立的图像元素,在图像中连接相邻的元素
- 寻找图像中的明显的极大值区域或极小值区域
- 求出图像的梯度
image = cv2.imread("test.jpg")
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(3, 3)) # 获取卷积核
eroded = cv2.erode(image, kernel) # 腐蚀图像
dilated = cv2.dilate(image, kernel) # 膨胀图像
c. 开运算和闭运算
- 开运算:先腐蚀后膨胀,用于移除由图像噪音形成的斑点
- 闭运算:先膨胀后腐蚀,用来连接被误分为许多小块的对象
6. 查找绘制轮廓
a. 查找轮廓
轮廓查找在图像检测领域有很广泛的应用,比如查找图像中明显的色块、条纹、物体边缘等等,查找轮廓前先要对图像进行二值化处理。
# opencv版本大于3
contours, hierarchy = cv2.findContours(image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE) # 第一个参数:查找的二值图像 第二个参数:轮廓检索模式 第三个参数:轮廓近似方法
# 返回值contours为查找到的轮廓列表,hierarhy为轮廓之间的层级关系
b. 绘制轮廓
查找到轮廓后可以通过drawContours函数绘制出轮廓
cv2.drawContours(temp,contours,-1,(0,255,0),3) # 第一个参数:画布,可以是原图 第二个参数:查找到的轮廓 第三个参数:-1表示全画 第四个参数:颜色 第五个参数:轮廓宽度
二、OpenCV的工程应用-色块检测
1. 问题背景
游戏画面因为美术资源缺失、程序bug都会产生各种色块,常见的有白色、紫色等,怎么通过程序筛选出这类异常画面,加快测试过程呢?
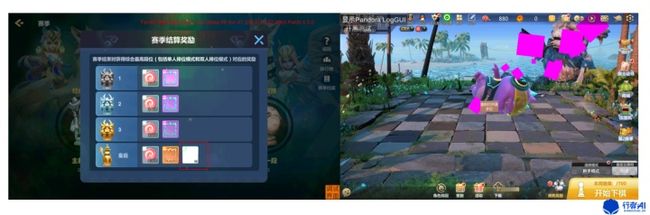
2. 问题分析
通过观察,我们发现色块类的异常都是一些比较规则的矩形图像,色彩差很明显,基于这些特点,我们可以很容易的筛选出色块。

3. 程序设计
a. 图像二值化
通过RGB通道的数值大小剔除掉其它的颜色,得到黑白二值图
import cv2
import numpy as np
image = cv2.imread("test.jpg")
b, g, r = cv2.split(self.image) # 分离B、G、R通道
b = np.where(b >= 250, 1, 0) # 找到G通道符合要求的像素点置1,不符合置0
g = np.where(g >= 250, 1, 0) # 找到G通道符合要求的像素点置1,不符合置0
r = np.where(r >= 250, 1, 0) # 找到G通道符合要求的像素点置1,不符合置0
gray = b + g + r # 将三个通道叠加成一个通道
gray = np.where(gray==3, 255, 0).astype(np.uint8) # 像素点为3的即为满足要求的点设置为白色,不符合设置为黑色

b. 查找轮廓
得到的黑白二值图由于除了色块外其它图像位置也有接近色块颜色的位置被保留了下来,需要剔除
通过查找二值图轮廓的方法我们可以筛选出分离的小色块
contours, hierarchy = cv2.findContours(gray, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE) # 获取轮廓及层级关系
c. 轮廓筛选
通过轮廓周长和面积剔除掉小色块,这些色块很可能就是提取的正常区域颜色较相似的点。
def screen_contour(contour):
contour_area = cv2.contourArea(contour)
if contour_area > self.area_limit:
return True
return False
pass_contours = []
for contour in contours:
if screent_contour(contour):
pass_contours.append(contour)
由于色块更接近于矩形,我们可以通过轮廓计算出色块的宽和高,色块的面积可以估算出来,色块面积与估算面积越接近,说明检测到的色块更接近矩形,通过这个方法,可以筛选出大部分不规则的色块。
def screent_contour(contour):
width = np.max(contour[:,:,0]) - np.min(contour[:,:,0])
height = np.max(contour[:,:,1]) - np.min(contour[:,:,1])
block_area = width * heigh
contour_area = cv2.contourArea(contour)
slimier = cv2.contourArea(contour) / block_area
if slimier > self.simliar_rate:
return True
return False
pass_contours = []
for contour in contours:
if screent_contour(contour):
pass_contours.append(contour)

三、OpenCV与矩阵
OpenCV是如何完成以上这些操作的呢?
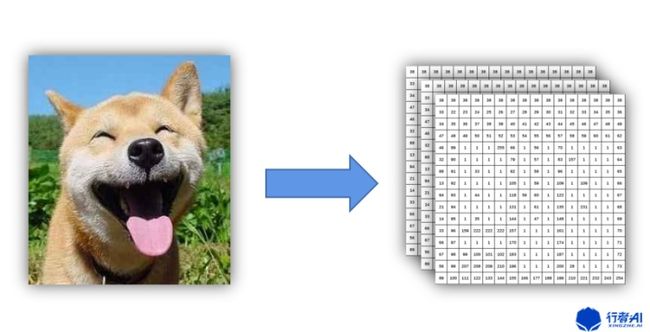
1. 图像读取
OpenCV在读取图像的时候是将图像信息转换成了矩阵,默认矩阵为(height,width,channel),channel对应的是B、G、R通道,每个像素点的颜色由三个通道一起决定,和三元色的关系是一样的,B、G、R的大小代表的是色彩比例。
2. 色彩空间转换
色彩空间的转换是将图像数据从一种表示关系变换到了另一种表示关系,比如BGR转换到HSV颜色空间是将原本的三原色表示法转换到了色调(H),饱和度(S),明度(V)表示法,每个channel所表示的含义发生了变化。
从信息的角度考虑,摄像机将光照信息采集后转化成了数字的形式(图像矩阵),颜色空间的转换是将图像数据从一种表示方法变换到另一种表示方法,信息的转化也会引起信息的丢失或者引入噪声,比如摄像机在采集光照信息的时候很容易采集到椒盐噪声,丢弃光照信息中的一些频段,清晰度降低等等,在做色彩空间转换的时候也可能发生信息丢失,比如从彩色图片转化到灰度图。深度学习中的图像检测、人脸识别就是要从这些图像信息中提取我们想要的信息。
3. 图像旋转的数学含义
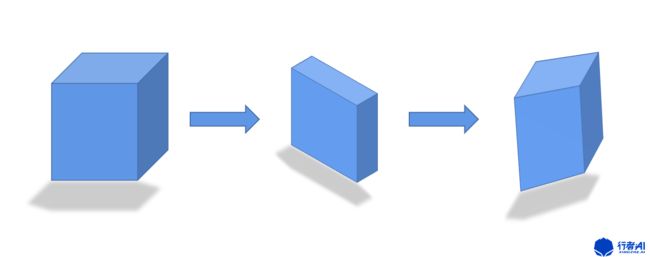
在做图像几何变换的时候,我们需要提供变换矩阵,矩阵是怎么完成这些操作的呢?
我们知道矩阵代表的就是一种空间映射,nxm的矩阵(列向量线性无关)代表的是n维空间到m维空间的映射,如上图所示,第一个立方体所在的空间通过一个3x3的矩阵映射到了第二个立方体所在的空间,立方体的形状发生了变化,再比如第一个立方体所在的空间通过一个3x2的矩阵映射到了它的影子所在的空间,立方体被压缩成了一个平面。
立方体可以通过矩阵(实数范围)映射成球体吗?因为其代表的是线性变换,所以是不可以的。
我们在处理图像问题的时候要将信息从一个空间映射到另一个空间,由于问题的复杂性所以线性映射是满足不了要求的,这也就是为什么在深度学习中需要加入激活函数的原因。
四、OpenCV与机器学习
从上一节的分析中我们发现,图像的处理过程就是从数据中找规律,将图像信息从一种表示变换到另一种表示,这个工作正好是机器学习的强项,再延申一下,不管是图像数据、文本数据、音频数据,要从数据中找规律,都会用到机器学习,从信息的角度考虑,这些问题本质上是没有区别的。
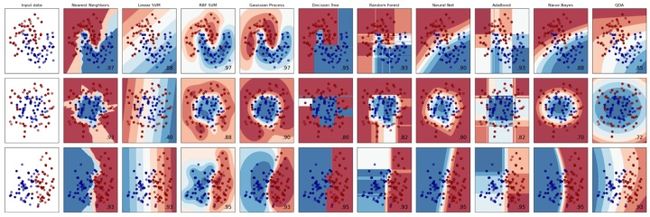
openCV已经集成了很多机器学习算法、如K近邻(KNN),支持向量机(SVM)、决策树、随机森林、Boost、逻辑回归、ANN等。
下图是摘自scikit-learn的一张图片,很形象的展示了不同的机器学习算法是如何对数据进行处理的,从宏观角度来讲就是如何将信息变换到不同的空间。
五、视频书籍推荐
篇幅限制,还有很多有趣的东西,没办法一一列举,推荐一些视频和书籍,供细细品尝。
1. 线性代数
3blue1brown《线性代数的本质》系列视频通过形象图像的动画直观的解释了线性代数的魔力,还有其它系列也很棒。
《程序员的数学3 线性代数》也是一本很不错的线性代数教材,细细读完,受益匪浅。
2. 概率论
《程序员的数学2 概率统计》很系统的讲解了概率统计的知识,不是很理解线性代数的话,推荐先看线性代数。
3. OpenCV
《学习OpenCV》是一本很不错的工具书。
PS:
我们是行者AI,我们在“AI+游戏”中不断前行。
如果你也对游戏感兴趣,对AI充满好奇,那就快来加入我们([email protected])。