“深度学习”学习日记。输出层的设计、MNIST的数据的下载和导入
2022.12.24 明天要考试,今天还在学习代码(主要是那个科目不想去复习)
# 神经网络输出层的设计
# 一般而言,回归问题用恒等函数,分类问题用softmax函数,我们识别图片中的人的问题属于分类问题,我们预测图片中人的身高属于回归问题
import numpy as np
def softmax(a):
exp_a = np.exp(a)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
# soft函数的使用要注意“溢出”问题
# 比如:数值超过有限的字符宽度
a = np.array([1010, 1000, 900])
print(softmax(a), '\n') # [nan nan nan] 产生缺省值 没有被正确计算
# 通过指数函数运算规则改进的soft函数
def new_softmax(a):
tmp = np.max(a)
exp_a = np.exp(a - tmp)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
print(new_softmax(a), '\n') # [9.99954602e-01 4.53978687e-05 1.68883521e-48]
# 回归函数
def identity_function(x):
return x
# 输出层需要的神经元的数量,对于分类问题,输出层的神经元一般设定维类别数量。比如mnist图像是数字0~9,则我们需要10个神经元
MNIST内容很多,我相信这里让所有的初学者都头疼了挺久。这里写了两种方法下载和导入数据。第二种方法有待完善
# mnist数据集
# 这里mnist是0~9手写数字图像。训练集有6万张,测试图像有1万张,这些图像可以用于学习与推理。
# 一般的使用方法是,先用训练图像进行学习,再用学习到的模型能量能在多大程度上对预测图像进行正确分类
import torch
import torchvision
import numpy as np
from matplotlib import pyplot as plt
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 使用pytorch自带的库函数下载、导入mnist
train_data = datasets.MNIST(
root="./data/",
train=True,
transform=transforms.ToTensor(),
download=True)
test_data = datasets.MNIST(
root="./data/",
train=False,
transform=transforms.ToTensor(),
download=True)
# root=存放的路径,注意相对路径和绝对路径;train=表示是否维训练集;
# transform 指定导入数据集时需要进行何种变换操作
# 此处ToTensor()将shape为(H, W, C)的nump.ndarray或img转为shape为(C, H, W)的tensor,其将每一个数值归一化到[0,1],其归一化方法比较简单,直接除以255即可
# download=如果不存在数据集则下载
train_data_loader = torch.utils.data.DataLoader(
dataset=train_data,
batch_size=64,
shuffle=True,
drop_last=True)
test_data_loader = torch.utils.data.DataLoader(
dataset=test_data,
batch_size=64,
shuffle=False,
drop_last=False)
# dataset=指的导入数据的路径; batch_size=每次导入的数据图片个数;
# shuffle=表示数据是否随机打乱;drop_last=保证总数据集/batch_size为整数,余数舍弃
# 进行一个批次的数据的图像预览
images, labels = next(iter(train_data_loader)) # images:Tensor(64,1,28,28)、labels:Tensor(64,)
img = torchvision.utils.make_grid(images) # 把64张图片拼接为1张图片
# pytorch网络输入图像的格式为(C, H, W),而numpy中的图像的shape为(H,W,C)。故需要变换通道才能有效输出
img = img.numpy().transpose(1, 2, 0)
std = [0.5, 0.5, 0.5]
mean = [0.5, 0.5, 0.5]
img = img * std + mean # 对图片灰度进行计算,调整图片的灰度
print(labels)
print(labels.shape)
print(images)
plt.imshow(img)
plt.show()
# 进行一个图像的预览
# images:Tensor(64,1,28,28)、labels:Tensor(64,) next(iter())是一个迭代器,
images, labels = next(iter(train_data_loader)) # (1,28,28)表示该图像的 height、width、color(颜色通道,即单通道)
images = images.reshape(64, 28, 28)
img = images[0, :, :] # 取batch_size中的第一张图像
np.savetxt('img.txt', img.cpu().numpy(), fmt="%f", encoding='UTF-8') # 将像素值写入txt文件,以便查看
img = img.cpu().numpy() # tensor转为numpy类型,方便有效输出 cpu()表示在CPU上的tensor这里可有可无
print(images)
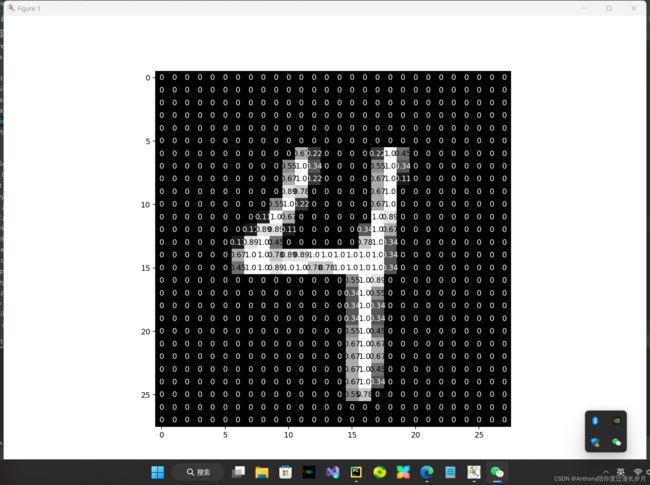
fig = plt.figure(figsize=(12, 12))
ax = fig.add_subplot(111)
ax.imshow(img, cmap='gray')
width, height = img.shape
thresh = img.max() / 2.5
# 调节图片像素的颜色
for x in range(width):
for y in range(height):
val = round(img[x][y], 2) if img[x][y] != 0 else 0
ax.annotate(str(val), xy=(y, x),
horizontalalignment='center',
verticalalignment='center',
color='white' if img[x][y] < thresh else 'black')
plt.show()


import sys
import os
import numpy as np
from PIL import Image
from dataset.mnist import load_mnist
def img_show(img):
pil_img = Image.fromarray(np.uint8(img))
pil_img.show()
sys.path.append(os.pardir)
(x_train, t_train), (x_text, t_test) = load_mnist(flatten=True, normalize=False)
img = x_train[0]
label = t_train[0]
print(label)
print(img.shape)
img = img.reshape(28, 28)
print(img.shape)
img_show(img)