R语言进行模型交叉验证比较
我们建立模型后,需要对模型变量调整比较,得出最优模型,交叉验证为目前评价模型质量的一个比较流行的方法。我们今天使用BOOT包的cv.glm函数来交叉验证,得出最优模型,并和其他指标进行比较。

使用的是一个纽约房价的数据(公众号回复:纽约房价数据,可以得到该数据),嫌麻烦的可以在这里下载https://download.csdn.net/download/dege857/86891240,我们先把R包和数据导入
library(boot)
housing<-read.csv("E:/r/test/housing.csv",sep=',',header=TRUE)
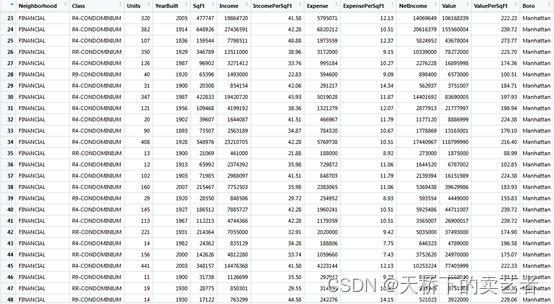
ValuePerSqFt是目前土地的售价,为结局变量,其他的都是协变量,如建造年份,收入,不同地区和街区等等,我就不一一解释了。
建立一个房价的预测模型
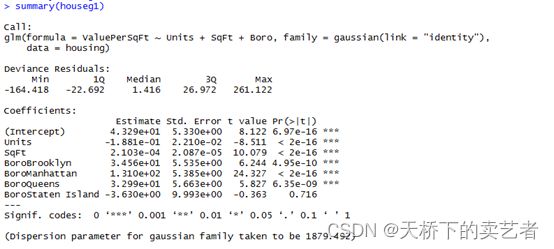
houseg1<-glm(ValuePerSqFt~Units+SqFt+Boro,data = housing,family = gaussian(link = "identity"))
解析模型
summary(houseg1)
使用cv.glm函数进行5折交叉验证
housecv1<-cv.glm(housing,houseg1,K=5)
从cv.glm可以得到交叉验证残差和修正的交叉验证残差。
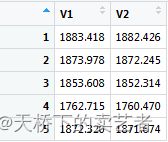
housecv1$delta
![]()
我们可以通过改变或增加变量,改变模型的残差,通过比较残差,得出适合预测变量的最优模型。下面我们多建立几个模型,然后进行比较
houseg2<-glm(ValuePerSqFt~Units*SqFt+Boro,data = housing,family = gaussian(link = "identity"))
houseg3<-glm(ValuePerSqFt~Units+SqFt*Boro,data = housing,family = gaussian(link = "identity"))
houseg4<-glm(ValuePerSqFt~Units+SqFt*Boro+SqFt*Class,data = housing,family = gaussian(link = "identity"))
houseg5<-glm(ValuePerSqFt~Boro+Class,data = housing,family = gaussian(link = "identity"))
把这些模型都进行交叉验证
housecv2<-cv.glm(housing,houseg2,K=5)
housecv3<-cv.glm(housing,houseg3,K=5)
housecv4<-cv.glm(housing,houseg4,K=5)
housecv5<-cv.glm(housing,houseg5,K=5)
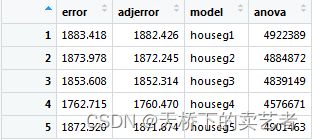
把结果做成表格
cvresults<-as.data.frame(rbind(housecv1$delta,housecv2$delta,
housecv3$delta,housecv4$delta,
housecv5$delta))
更改一下表头名字
names(cvresults)<-c("error","adjerror")
cvresults$model<-sprintf("houseg%s",1:5)

由此看出,模型4的残差最小,模型4是最佳模型。
我们使用其他验证方法和交叉验证进行比较
Anova:
cvanova<-anova(houseg1,houseg2,houseg3,houseg4,houseg5)
cvresults$anova<-cvanova$`Resid. Dev`
AIC:
AIC<-AIC(houseg1,houseg2,houseg3,houseg4,houseg5)
cvresults$AIC<-AIC$AIC
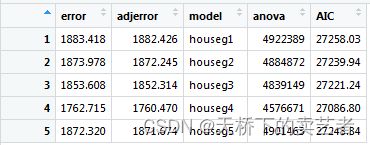
最后我们把长数据转换成寛数据,然后进行可视化绘图
library(reshape2)
cvmelt<-melt(cvresults,id.vars = "model",variable.name = "measure",value.name = "value")
cvmelt

通过绘图进行比较
library(ggplot2)
ggplot(cvmelt,aes(x=model,y=value))+
geom_line(aes(group=measure,col=measure))+
facet_wrap(~measure,scales = "free_y")+
theme(axis.text = element_text(angle = 90,vjust = .5))+
guides(col=F)

最后通过多个模型指标比较,得出了模型4是最优模型。