【期末课设】python爬虫基础与可视化,使用python语言以及支持python语言的第三方技术实现爬虫功能,定向爬取网页的图片数据,并且实现批量自动命名分类下载。
1.大作业的内容
本要求使用python语言以及支持python语言的第三方技术实现爬虫功能,定向爬取网页的图片数据,并且实现批量自动命名分类下载。
2.案例需求
要求采用虚拟浏览器等动态爬虫技术,完成定向图片网站的图片数据,并且实现批量自动命名分类下载,为后续人工智能数据集收集和大数据分析提供可靠的技术栈。
3.概要设计
本系统设计主要的包括以下两个个部分:数据爬取、数据存储。
3.1数据爬取

首先爬虫程序以网站的网址为起始点,分析初始爬取网页URL及其网页信息,所以需要对起始网址进行格式上的分析和构造。完成起始网址的分析后就可以对其分析到的初始URL进行爬取,获取数据。
3.2数据存储
将获取到的数据分类存到文件夹中。
4.详细设计
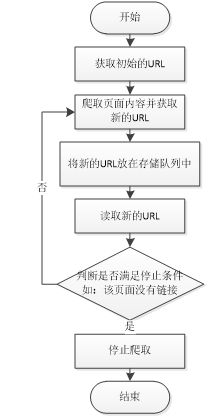
4.1数据爬取
本次爬虫设计的目标是对要求采用虚拟浏览器等动态爬虫技术,完成定向图片网站的图片数据,并且实现批量自动命名分类下载,数据爬取模块的运行基本流程如图2所示。
4.2数据采集
打开图片网站页面并分析网页源代码结构。分析初始爬取网页URL及其网页信息,对起始网址进行格式上的分析和构造,如该网站图片链接信息,根据网址抓取网页并将网页内容分离开来。
首先,通过pip install parsel下载安装parsel库。
html_str=response.text #text 获取对象里面的额文数据 字符串 --> 正则表达式
pic_url_list=selector_2.xpath(‘//div[@class=“entry-content”]//img/@src’).getall() #获取url地址
4.3数据提取


#遍历每一个图片链接
for pic_url in pic_url_list:
#发送图片链接请求,获取图片数据
img_data=requests.get(url=pic_url,headers=headers).content
4.4数据存储
Python中可采用的存储方式有很多,常用的有json文件、csv文件、excel文件、MySQL数据库等。本案例数据存储为jpg文件格式。
本案例将爬取到的该网站所有图片数据通过os数模块保存到本地。
- 通过import os语句导入os模块。
- 将下载下来文件按照类别进行分类。
for li in lis:
pic_title=li.xpath('.//h2/a/text()').get() #相册标题,用于保存相册的文件夹名
pic_url = li.xpath('.//h2/a/@href').get() #相册链接
print('正在下载相册',pic_title)
效果:


4.5数据可视化
数据可视化分析模块就是使用Pyecharts可视化工具将数据以可视化图表的形式展示出来。将各个文件夹中的图片进行分析统计。
在该功能中,用户可以看到相册文件的名字,文件夹下照片的数量,并将其可视化在图表当中。数据可视化模块流程图如图所示。

5.系统实现
5.1数据爬取功能
数据爬取模块包括数据采集、数据提取等。本爬虫程序爬取该网站的图片链接和文件title名。
数据爬取程序的核心代码部分:
url='https://www.jdlingyu.com/tag/%e5%b0%91%e5%a5%b3'
headers={'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.116 Safari/537.36'}
#发送指定地址请求,请求数据 get post 请求 响应 请求的数据
response=requests.get(url=url,headers=headers)
html_str=response.text #text 获取对象里面的额文数据 字符串 --> 正则表达式
#print(html_str)
#通过xpath提取数据
selector=parsel.Selector(html_str) #转换数据类型
lis=selector.xpath('//div[@id="post-list"]/ul/li') #所有的li标签
for li in lis:
pic_title=li.xpath('.//h2/a/text()').get() #相册标题,用于保存相册的文件夹名
pic_url = li.xpath('.//h2/a/@href').get() #相册链接
5.2数据存储功能
数据存储模块的核心代码部分:
#创建相册文件夹
if not os.path.exists('img\\' + pic_title):
os.mkdir('img\\' + pic_title)
#发送相册详情页地址请求
response_pic=requests.get(url=pic_url,headers=headers).text #详情页数据
selector_2=parsel.Selector(response_pic)
pic_url_list = selector_2.xpath('//div[@class="entry-content"]//img/@src').getall() #获取url地址
#print(pic_url_list)
#遍历每一个图片链接
for pic_url in pic_url_list:
#发送图片链接请求,获取图片数据
img_data=requests.get(url=pic_url,headers=headers).content
#准备图片的文件名
file_name=pic_url.split('/')[-1]
#print(file_name)
with open(f'img\\{pic_title}\\{file_name}',mode='wb') as f:
f.write(img_data)
print('保存完成:',file_name)
5.3数据可视化功能
代码:
list1.append(pic_title) #将相册名放入list1
list2.append(n) #将相册内的照片数放入list2
bar = Bar()
bar.add_xaxis(list1) #相册名为x坐标
bar.add_yaxis("相册名",list2) #相册数量为y坐标
bar.render("show.html")
5.4完整代码
(1)运行环境:python3.x,安装扩展库parsel。
(2)爬虫程序代码:
import requests
import parsel
import os
url='https://www.jdlingyu.com/tag/%e5%b0%91%e5%a5%b3'
headers={'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.116 Safari/537.36'}
#发送指定地址请求,请求数据 get post 请求 响应 请求的数据
response=requests.get(url=url,headers=headers)
html_str=response.text #text 获取对象里面的额文数据 字符串 --> 正则表达式
#print(html_str)
#通过xpath提取数据
selector=parsel.Selector(html_str) #转换数据类型
lis=selector.xpath('//div[@id="post-list"]/ul/li') #所有的li标签
for li in lis:
pic_title=li.xpath('.//h2/a/text()').get() #相册标题,用于保存相册的文件夹名
pic_url = li.xpath('.//h2/a/@href').get() #相册链接
print('正在下载相册',pic_title)
#创建相册文件夹
if not os.path.exists('img\\' + pic_title):
os.mkdir('img\\' + pic_title)
#发送相册详情页地址请求
response_pic=requests.get(url=pic_url,headers=headers).text #详情页数据
selector_2=parsel.Selector(response_pic)
pic_url_list = selector_2.xpath('//div[@class="entry-content"]//img/@src').getall()
#print(pic_url_list)
#遍历每一个图片链接
for pic_url in pic_url_list:
#发送图片链接请求,获取图片数据
img_data=requests.get(url=pic_url,headers=headers).content
#准备图片的文件名
file_name=pic_url.split('/')[-1]
#print(file_name)
with open(f'img\\{pic_title}\\{file_name}',mode='wb') as f:
f.write(img_data)
print('保存完成:',file_name)
6.学习心得及体会
通过这段时间的学习,我学会了很多知识。从python的基础语法,到各种各样库的运用。通过老师的讲解,我理解了爬虫的基本原理;通过几次课堂的实践,我体会到爬虫库的强大。我学会了遇到不同的问题使用不同的库,通过对网页的分析,更快地找出想要的内容。从这段课程中,提高的不仅仅是我对爬虫的认识,还有我对python本身的理解。使我在日常学习中,对python这门语言有了更好的认识。
源码分享
from turtle import width
import requests
import parsel
import os
from pyecharts import options as opts
from pyecharts.charts import Bar
import pandas as pd
url='https://www.jdlingyu.com/tag/%e5%b0%91%e5%a5%b3'
headers={'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.116 Safari/537.36'}
#发送指定地址请求,请求数据 get post 请求 响应 请求的数据
response=requests.get(url=url,headers=headers)
html_str=response.text #text 获取对象里面的额文数据 字符串 --> 正则表达式
#print(html_str)
#通过xpath提取数据
selector=parsel.Selector(html_str) #转换数据类型
lis=selector.xpath('//div[@id="post-list"]/ul/li') #所有的li标签
list1=[]
list2=[]
for li in lis:
pic_title=li.xpath('.//h2/a/text()').get() #相册标题,用于保存相册的文件夹名
pic_url = li.xpath('.//h2/a/@href').get() #相册链接
print('正在下载相册',pic_title)
n=0
#创建相册文件夹
if not os.path.exists('img\\' + pic_title):
os.mkdir('img\\' + pic_title)
#发送相册详情页地址请求
response_pic=requests.get(url=pic_url,headers=headers).text #详情页数据
selector_2=parsel.Selector(response_pic)
pic_url_list = selector_2.xpath('//div[@class="entry-content"]//img/@src').getall() #获取url地址
#print(pic_url_list)
#遍历每一个图片链接
for pic_url in pic_url_list:
#发送图片链接请求,获取图片数据
img_data=requests.get(url=pic_url,headers=headers).content
#准备图片的文件名
file_name=pic_url.split('/')[-1]
#print(file_name)
with open(f'img\\{pic_title}\\{file_name}',mode='wb') as f:
f.write(img_data)
print('保存完成:',file_name)
n+=1
list1.append(pic_title) #将相册名放入list1
list2.append(n) #将相册内的照片数放入list2
# print(list1,list2)
# dataframe = pd.DataFrame({'相册名': list1, '数量': list2})
# print(dataframe)
# dataframe.to_excel('list.xls')
bar = Bar()
bar.add_xaxis(list1) #相册名为x坐标
bar.add_yaxis("相册名",list2) #相册数量为y坐标
bar.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-45))
)
bar.render("show.html")