TensorFlow入门(1)深度学习基础知识以及tf.keras
目录
目录
多层感知器MLP
隐藏层的选择
Dense层
Activation层
Dropout层
Flatten层
activation激活函数:
relu
sigmoid
Tanh
leaky relu
神经网络的拟合能力
参数选择原则:
梯度下降法——多层感知器的优化
5、学习速率(人为规定的变化速率)
7、反向传播算法(计算loss)——一种高效计算数据流图中梯度的技术
8、compile() 函数将一个字符串编译为字节代码。
常见的优化函数
Adam优化器
SGD:随机梯度下降优化器
RMSprop:深度学习网络优化算法
多层感知器MLP
整个过程如下图:
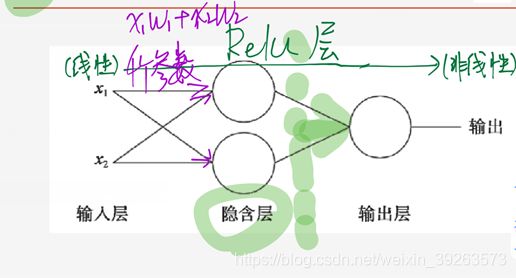
输入为x1,x2经过权重w1,w2加持到达隐藏层,隐藏层可以有多个且多种,可以互相掺杂只为得到更好的拟合结果,此时数据的类型取决于所用的model.add(tf.keras.layers.Dense(128, activation='relu'))的layers后面的是什么层,比如Dense层、Flatten层、Activation层、Dropout层……数据结果取决于所用的activation激活函数、以及其他参数设置,比如relu、sigmoid、tanh……。隐藏层输出的结果确定后进入输出层。
#提高网络的拟合能力,增加神经元个数、增加层
#input_shape=(15,)是一个元组,数据的形状就是前十五列,activation用“relu"激活
#增加两个隐藏层,准确率从80多涨到了90多
#增加三个Dropout(0.5)抑制过拟合
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28,28))) # 28*28
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
#%%
#validation使用test数据来验证
history = model.fit(train_image, train_label_onehot,
epochs=10,
validation_data=(test_image, test_label_onehot))
history.history.keys()
隐藏层的选择
Dense层
输入形状是input: (A * B),输出是output: (A * C)
outputs=activation(inputs * kernel + bias)
tf.layers.Dense(input,c) /
tf.keras.layers.Dense()
model.add(tf.keras.layers.Dense(128, activation='relu'))
kernel该层创建的权重矩阵
bias该层创建的偏置向量(仅当use_bias为True时)
Activation层
keras.layers.Activation(activation)
将激活函数应用于输出。
Dropout层
keras.layers.Dropout(rate, noise_shape=None, seed=None)
将 Dropout 应用于输入。Dropout 包括在训练中每次更新时,将输入单元的按比率随机设置为 0,这有助于防止过拟合。
Flatten层
keras.layers.Flatten(data_format=None)
将输入展平。不影响批量大小。
keras的layers详细介绍:
https://keras.io/zh/layers/core/
activation激活函数:
relu
——当输入 x<0 时,输出为 0,当 x> 0 时,输出为 x
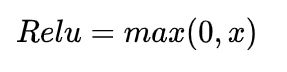
sigmoid
——该函数将大的负数转换成0,将大的正数转换为1。输出在(0,1)之间,它可以将一个实数映射到(0,1)的范围内,可以用来做二分类。

Tanh
—— Tanh 函数将其压缩至-1 到 1 的区间内。负数输入被当作负值,零输入值的映射接近零,正数输入被当作正值。
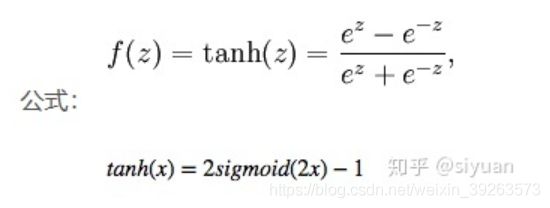
leaky relu
——当 x < 0 时,它得到 0.01 的正梯度。

详细见
https://zhuanlan.zhihu.com/p/192497127?utm_source=wechat_timeline
神经网络的拟合能力
网络中的可训练参数越多,网络容量越大
网络中的神经单元数越多,层数越多,神经网络的拟合能力越强。
但是训练速度、难度越大,越容易产生过拟合。
过拟合: 在训练数据上得分很高,在测试数据上得分相对比较低
欠拟合: 在训练数据上得分比较低,在测试数据上得分相对比较低
如何选择超参数?
超参数——搭建神经网络中,需要自己选择的参数(不是通过梯度下降算法去优化)
比如:中间层的神经元个数、学习速率
如何提高网络的拟合能力(增大网络容量)?
1、增加层——大大提高网络的拟合能力
2、增加隐藏层神经元个数——不咋明显
参数选择原则:

梯度下降法——多层感知器的优化
1、梯度下降法是一种致力于找到函数极值点的算法。沿着损失函数减小的方向移动,并再次计算梯度值,并重复上述过程,直至梯度的模为0,将到达损失函数的极小值点。
2、梯度的输出是一个由若干偏导数构成的向量,它的每个分量对应于函数对输入向量的相应分量的偏导。

3、梯度的输出向量表明了在每个位置损失函数增长最快的方向,可将它是为表示了在函数的每个位置向哪个方向移动函数值可以增长。
4、曲线——损失函数、点——权值的当前值、箭头——梯度、箭头长度——在对应方向移动

5、学习速率(人为规定的变化速率)
梯度就是表明损失函数相对参数的变化率,对梯度进行缩放的参数被称为学习速率(learning rate),如果学习速率太小,则找到损失函数极小值点可能需要很多轮的迭代;如果太大,可能周期性的跳跃,而永远无法找到极值点。
6、怎样判断学习速率选择的对不对?
查看损失函数随时间的变化曲线
合适的学习速率——损失函数随时间下降,直到一个底部
不合适的学习速率——损失函数可能发生震荡
7、反向传播算法(计算loss)——一种高效计算数据流图中梯度的技术
前馈时,从输入开始,逐一计算每个隐含层的输出,直到输出层
然后计算导数,并从输出层经各隐含层逐一反向传播。为了减少计算量,还需对所有已完成计算的元素进行复用。
8、compile() 函数将一个字符串编译为字节代码。
keras model.compile(loss='目标函数 ', optimizer='adam', metrics=['accuracy'])
常见的优化函数
优化器(optimizer)是编译模型的所需的两个参数之一。可以先实例化一个优化器对象,然后将它传入model.compile(),或者可以通过名称来调用优化器。在后一种情况下,将使用优化器的默认参数 。
#可以更改Adam的默认参数(adam的两种写法)
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss='categorical_crossentropy',
metrics=['acc']
)
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['acc']
)
#训练
history = model.fit(x,y,epochs=100)
#预测x可取(pd.series([20]))
model.predict(x)
Adam优化器
1、Adam算法可以看做是修正后的Momentum+RMSProp算法
2、Adam通常被认为对超参数的选择相当鲁棒
3、学习率建议为0.001
Adam是一种可以替代传统随机梯度下降过程的一阶优化算法,它能基于训练数据迭代地更新神经网络权重。
Adam通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数涉及独立的自适应学习率。
Adam常见参数:lr(learning rate):float>=0. 学习率。 decay:float>=0 每次参数额更新后学习率衰减值
SGD:随机梯度下降优化器
抽取m个小批量(独立同分布)样本,通过计算他们平均梯度值
RMSprop:深度学习网络优化算法
1、RMSprop增加了一个衰减系数来控制历史信息的获取多少,会对学习率进行衰减。
2、建议使用优化器的默认参数
3、这个优化器通常是训练循环神经网络RNN的不错选择
另外各种loss大总结(loss=’这里的函数该是啥’)
https://blog.csdn.net/wfei101/article/details/82531737
常见的优化参数详细见:
https://www.cnblogs.com/smuxiaolei/p/8662177.html