【HBZ分享】Kafka集群部署从0开始搭建---springboot整合kafka集群---关闭kafka/zk,一步步跟着走就能搭建起集群
第一步:环境准备
-
java环境准备(如果linux本身就有了java可忽略)
java安装请参考: https://blog.csdn.net/a645293829/article/details/122352371. -
zookeeper下载
下载地址:https://zookeeper.apache.org/releases.html.
下载apache-zookeeper-3.7.0-bin.tar.gz


- kafka下载
下载地址:http://kafka.apache.org/downloads.
下载kafka_2.12-2.8.0.tgz


第二步:把下载好的压缩包上传到3台服务器上,并解压
- 我上传的路径是/software/kafka

- 解压
进入/software/kafka目录下
# 3台服务器都进入到/software/kafka目录
cd ../software/kafka
# 解压
tar -zxvf apache-zookeeper-3.7.0-bin.tar.gz
tar -zxvf kafka_2.12-2.8.0.tgz
# 改下名
mv apache-zookeeper-3.7.0-bin zookeeper
mv kafka_2.12-2.8.0 kafka
第三步:zookeeper配置
- 进入到zookeeper的conf下,并分别复制一份zoo_sample.cfg文件,命名副本为zoo.cfg,这将作为启动zookeeper的配置文件,执行如下命令
# 进入zk的conf目录
cd /software/kafka/zookeeper/conf
# 复制zoo_sample.cfg,并命名zoo.cfg
cp zoo_sample.cfg zoo.cfg
- 进入zoo.cfg配置文件,追加一条配置
注意:如果是单台服务器部署多个节点,配置文件的clientPort=2181 和 admin.serverPort=8881要更改成不同的端口,比如2182,2183 和 8882,8883
# 追加管理员端口为8881
admin.serverPort=8881
配置后的完整配置文件截图:
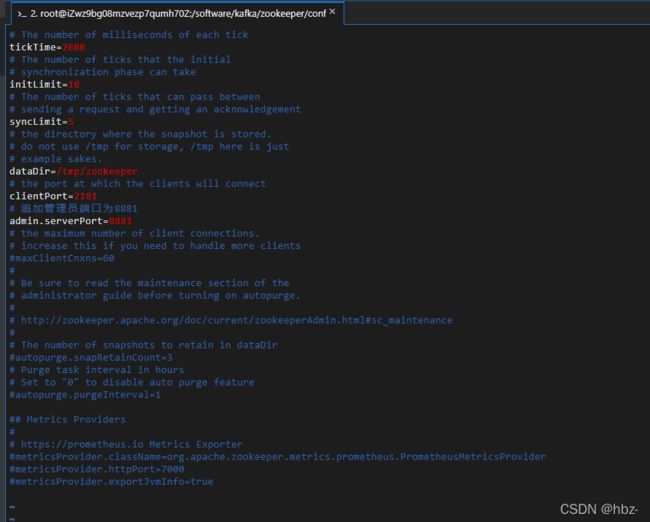
第四步:zookeeper集群配置
- 去cd /tmp下创建zookeeper文件夹,没有zookeeper目录的创建一个mkdir zookeeper
命令如下
# 现在tmp下创建一个zookeeper文件夹
mkdir /tmp/zookeeper
- 去第一台服务器的/tmp/zookeeper文件夹下,执行【echo 1 > myid】, 第二台服务器的/tmp/zookeeper下执行【echo 2 > myid】, 第三台服务器的/tmp/zookeeper下执行【echo 3 > myid】
echo 1 > myid这个1随便起名,后面会用到,只要名字能对上就行
命令
# 进入/tmp/zookeeper文件夹
cd /tmp/zookeeper
# 执行echo 1 > myid
echo 1 > myid
# 其他服务器照做,只不过不要都写1,写个其他不同的
...

- 集群配置,去3台服务器的zookeeper的zoo.cfg文件下,复制如下几句
# 进入conf目录
cd /software/kafka/zookeeper/conf
# 进入zoo.cfg文件
vim zoo.cfg
# 复制下面几句
server.1=39.108.92.253:2881:3881
server.2=120.78.195.178:2881:3881
server.3=112.74.179.112:2881:3881
quorumListenOnAllIPs=true

注意:这里的server.1/2/3,这块要和当时输入的echo 1 > myid中的1, echo 2 > myid中的2, echo 3 > myid中的3对应上,还有就是1,2,3分别写在哪个服务器的IP别对错了,如果忘记了就去/tmp/zookeeper下执行 【cat myid】看一下。
第五步:启动Zookeeper
进入3台服务器/software/kafka/zookeeper/bin目录下,执行./zkServer.sh start
# 进入bin目录
cd /software/kafka/zookeeper/bin
# 启动zk
./zkServer.sh start

看到上面字样,说明启动成功
第六步:kafka集群配置
- Kafka配置文件更改
# 进入Kafka的config目录
cd /software/kafka/kafka/config
# 进入kafka配置文件
vim server.properties
更改配置文件: 下列配置项有一些是原配置文件注释掉的,需要删除#注释,有一些本身就有,不过需要改,自己搜一下即可,进入vim时的查看状态输入/listener就能搜到位置,linux基础命令这里不多解释
Kafka1节点
# 3台服务器的节点名不能一致,必须改成不一样的
broker.id=1
# 这里要写当前机器的内网地址, 如果是同一台服务器,9092这个端口不能相同
listeners=PLAINTEXT://172.31.13.102:9092
# 这里要写当前机器公网地址, 如果是同一台服务器,9092这个端口不能相同
advertised.listeners=PLAINTEXT://xxx.xx.xxx.xx:9092
# 配置zookeeper集群地址,多个zk节点用","分割
zookeeper.connect=172.31.13.102:2181,172.28.124.76:2181,172.31.13.103:2181
Kafka2节点
# 3台服务器的节点名不能一致,必须改成不一样的
broker.id=2
# 这里要写当前机器的内网地址, 如果是同一台服务器,9092这个端口不能相同
listeners=PLAINTEXT://172.28.124.76:9092
# 这里要写当前机器公网地址, 如果是同一台服务器,9092这个端口不能相同
advertised.listeners=PLAINTEXT://xxx.xx.xxx.xx:9092
# 配置zookeeper集群地址,多个zk节点用","分割
zookeeper.connect=172.31.13.102:2181,172.28.124.76:2181,172.31.13.103:2181
Kafka3节点
# 3台服务器的节点名不能一致,必须改成不一样的
broker.id=3
# 这里要写当前机器的内网地址, 如果是同一台服务器,9092这个端口不能相同
listeners=PLAINTEXT://172.31.13.103:9092
# 这里要写当前机器公网地址, 如果是同一台服务器,9092这个端口不能相同
advertised.listeners=PLAINTEXT://xxx.xx.xxx.xx:9092
# 配置zookeeper集群地址,多个zk节点用","分割
zookeeper.connect=172.31.13.102:2181,172.28.124.76:2181,172.31.13.103:2181

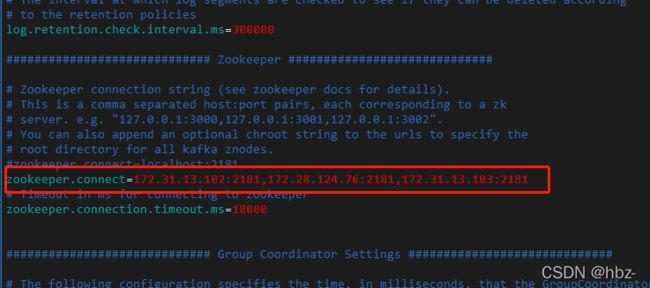
第七步:启动kafka
- 进入每个kafka节点的bin目录下,
执行【./kafka-server-start.sh -daemon …/config/server.properties】
命令
# 进入bin目录
cd /software/kafka/kafka/bin
# 启动kafka
./kafka-server-start.sh -daemon ../config/server.properties

第八步:验证集群生效
- 创建一个topic,因为是3个broker,所以创建3个副本
命令
# 进入bin目录
cd /software/kafka/kafka/bin
# 创建topic
./kafka-topics.sh --create --zookeeper 172.31.13.102:2181,172.28.124.76:2181,172.31.13.103:2181 --replication-factor 3 --partitions 6 --topic hbz-kafka-cluster
# 查看topic信息命令
./kafka-topics.sh --zookeeper 172.31.13.102:2181,172.28.124.76:2181,172.31.13.103:2181 --list
![]()
出现此景,表示kafka集群搭建成功
或者 去另一个节点,创建同样的topic,如果报错已存在,更进一步说明集群创建成功
![]()
通过查询topic命令,去所有节点查询,看下显示列表是否都相同,如果相同,亦可证明集群成功

第九步:springboot整合kafka
- pom.xml引入kafka依赖: 没有版本号是因为parent是springboot
org.springframework.kafka
spring-kafka
- application.yml
spring:
kafka:
# kafka的连接地址(注意,是kafka所在服务器的公网ip,不要写成zookeeper的了)
bootstrap-servers: ip:9092, ip:9092, ip:9092
producer:
#消息重发次数, 如果配置了事务,则不能为0,或者干脆不配置这个参数也可以
retries: 1
# 一次处理消息消息的大小batch,一批消息最大多大时发送
batch-size: 16384
# 生产者最大可发送的消息大小,内有多个batch,一旦满了,只有发送到kafka后才能空出位置,否则阻塞接受新消息
buffer-memory: 33554432
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# 确认等级ack, 如果配置了事务,那必须是-1或者all
acks: all
# 配置事务,名随便起
transaction-id-prefix: hbz-transaction-
consumer:
# 自动提交时间间隔,前提需要开启自动提交,需要符合特定时间格式: 1S, 1M, 1H,2D(秒,分,小时,天)
auto-commit-interval: 1S
# 消费者在读取一个没有offset的分区或者offset无效时的策略,earliest是从头都。latest是不从头读
auto-offset-reset: earliest
# 是否自动提交偏移量offset, 一般是false, 如果选false,则上面auto-commit-interval属性则无效
enable-auto-commit: false
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# 手工提交,调用ack后,立刻提交offset
ack-mode: manual_immediate
# 容器运行的线程数
concurrency: 4
- java中配置
package com.study.kafka.springboot_kafka.config;
import org.apache.kafka.clients.admin.AdminClient;
import org.apache.kafka.clients.admin.AdminClientConfig;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.Properties;
/**
* 使用kafka-cliend对topic与partition一些列操作的配置文件
* 将之前test那些每个页面都写一遍的连接配置整合到了spring容器
* 针对test下的, com.study.kafka.topic下的那些文件的连接方式
*/
@Configuration
public class KafkaConfig {
@Bean
public AdminClient initAdminClient(){
Properties properties = new Properties();
// 参数1: 固定写法,常量转换成字符串就是"bootstrap.servers",写这个字符串也行
// 参数2: kafka所在的服务器ip:端口号, 多个集群用"," 隔开(要和application.yml写的spring.kafka.bootstrap-servers值一致,因为他俩一个意思)
properties.setProperty(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, "ip:9092, ip:9093, ip:9094");
AdminClient adminClient = AdminClient.create(properties);
return adminClient;
}
}
把上面3个配置都写完,springboot整合kafka集群就完毕了,剩下的就正常使用kafkaAPI就可以了
第十步:关闭kafka 与 zookeeper
注意:推荐先关闭zookeeper, 再关闭kafka
- 关闭zookeeper
# 进入zookeeper的bin
cd /software/kafka/zookeeper/bin
# 执行关闭命令
./zkServer.sh stop
- 关闭kafka
# 进入kafka的bin
cd /software/kafka/kafka/bin
# 执行关闭命令
./kafka-server-stop.sh
关闭zookeeper成功样子

kafka关闭后没啥提示

至此,kafka集群搭建–整合springboot–关闭kafka与zk【圆满结束】