Vulnerability Detection in Smart Contracts Using Deep Learning
Vulnerability Detection in Smart Contracts Using Deep Learning
利用深度学习检测智能合约中的漏洞
这项研究对机器学习模型(即LSTM和TCN)进行了实验和测试,并提出了具有竞争力的新模型。作者建立了深度学习架构,如长短时记忆(LSTM)和时间卷积网络(TCN),以研究如何利用这些模型来识别SC中的漏洞分类和异常情况检测。为了有更好的洞察力,作者将模型(即TCN和LSTM)的性能与Gogineni等人[19]的报告进行了比较。
使用技术:
“artificial recurrent neural network architecture” 人工递归神经网络架构
-
“Long Short-Term Memory (LSTM)” 长短期记忆(LSTM)
-
“Temporal Convolutional Network (TCN)” 时间卷积网络(TCN)
扩展自:“Multi-class classification of vulnerabilities in smart contracts using awd-lstm, with pre-trained encoder inspired from natural language processing.”
本文提出的工作扩展了[19]中讨论的研究。[19]的作者使用平均随机梯度下降加权LSTM(AWD-LSTM)来检测漏洞被标记为自杀(即包含自毁操作码的SC)、2)浪子(即向任何任意SC发送以太)、3)贪婪(即具有冻结以太特征的SC)和4)正常(即没有任何漏洞的SC)的SC。他们从(Tann 等, 2019)中提出的工作中获取了他们的训练数据,上述研究将数据分为自杀类、浪子类和贪婪类。然而,由于不同的操作码组合较少,这些类受到数据不平衡的影响。
创新点:
我们是第一次将TCN用于漏洞检测,并将其性能与基于LSTM的模型进行比较。
贡献:
-
我们通过从类似的资源库中下载更多的SC来解决数据不平衡的问题,然后按照[48]中的讨论,将这些SC转化为操作码排序字符串进行分类。
-
我们为我们的数据集建立了基于LSTM和TCN的漏洞检测模型。
-
我们报告说,我们基于TCN的模型优于现有的工作(如LSTM模型)。通过TCN模型的数据超采样,我们在精度、召回率、F1得分和准确率方面分别达到了95.95%、93.73%、94.83%和94.77%。
技术背景
-
“B. Long Short-Term Memory (LSTM)”
b .长期短期记忆(LSTM)
长短期记忆是一种基于梯度的方法,是为了克服在长期执行递归反向传播时的数据存储延迟而引入的[22]。递归反向传播是为递归神经网络改变的反向传播算法。基于梯度的方法使用输入数据和成本函数(或激活函数),这样,输入数据有助于训练网络。相比之下,成本函数通过进行一些计算来帮助确定准确性。因此,成本函数减少了输出的变化。
LSTM网络是递归网络的例子,解决了与递归神经网络相关的一个特殊问题。递归网络通过首先产生一个所有输入的加权总和,对总和施加一个偏置,并使用成本函数进行处理来产生输出。一些调整会给权重分配大的数值,导致爆炸性梯度问题。反之,调整可以给权重分配较浅的值,导致梯度消失的问题。LSTM通过扩展内存来解决这个问题,允许递归网络在很长一段时间内记住它以前的数据,从而照顾到连续的数据。
LSTM的顺序数据处理能力有助于将LSTM用于文本处理,在这种情况下,句子的每个单词都会成为递归神经网络的输入数据。另一方面,计算机程序是一连串的指令。因此,研究人员也将LSTM用于漏洞检测,如[46]、[6]、[13]、[30]中讨论的那样。
LSTM中的工作函数使用门函数来控制所提供的递归单元中的信息流。LSTM模型由一个记忆单元、一个输入门、一个输出门和一个遗忘门组成[47]。记忆单元在较长的时间内保持信息。LSTM还为较小的数据集提供了一种变体,称为门控递归单元(GRU),专注于较少的参数,没有输出门。输入门的一个常见功能是允许信号通过隐藏内容。输出门作为一种预测机制,而遗忘门则计算出当前时间步长所记忆的先前信息量。通过将0乘以矩阵中的一个位置,遗忘门的输出通知单元格状态,哪些信息需要遗忘。例如,如果遗忘门的输出为1,则该信息被储存在单元格状态中[18]。 -
“C. Temporal Convolutional Network (TCN)”
c .时间卷积网络(TCN)
像LSTM一样,TCN在机器学习中的时间序列和语音识别等连续数据的比较上有应用。这一事实为我们基于TCN的漏洞检测相关研究提供了刺激。顺序数据(即连接数据)可能属于几种文件格式,如图像[32]、音频[29]、视频[3]和文本[54]。此外,与LSTM相比,使用TCN有几个优势;1)由于填充特性,TCN可以接受任何大小的输入数据,而LSTM的工作是固定大小的输入;2)TCN可以在较长的时间内保持数据而不成为遗忘;3)TCN使用灵活的接受场来为连续数据建模的时间性[36],以及4)与LSTM和GRU相比,TCN的架构更加直接[7]。TCN将因果滤波器与扩张卷积相结合,以支持长历史序列[14]。这种组合增加了网络的感受野长度。此外,因果滤波器不依赖于未来的输入来产生输出。TCN的另一个组成部分是帮助训练网络深层的剩余连接。由于这种可比性和易于使用,TCN作为一个强大的工具包用于序列建模。
-
“IV. THE GENERAL MODEL BUILDING ALGORITHM” 四、一般的模型建立算法
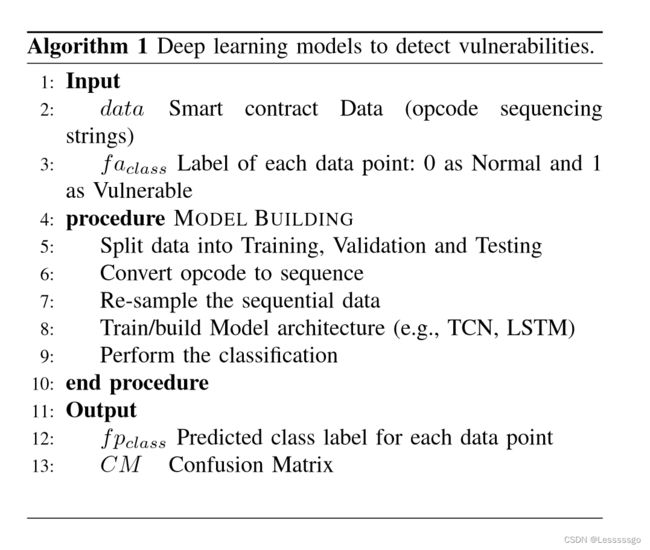
算法1描述了检测SC漏洞的一般程序。算法1首先将整个数据集划分为训练、验证和测试子集。如果模型在测试期间没有取得好的结果,验证数据有助于完善训练过程。另一方面,测试数据有助于交叉验证。下一步是对操作码序列进行重新取样,作者只进行一次。一般来说,重新取样技术,如过量取样和欠量取样,有助于为分类问题建立一个平衡的数据集。重新采样的数据集被输入到深度学习模型(即LSTM和TCN)进行训练。该模型的输出将SC分类为脆弱或不脆弱。如果是脆弱的,该模型将预测测试数据中的脆弱程度(即浪子、贪婪和自杀)。然而,如果预测结果不准确,可以通过调整模型和观察损失和准确度值,用验证数据集重复训练。该模型的输出使用混淆矩阵对测试数据进行预测。混淆矩阵报告精度、召回率和f1得分信息。
“ 实验步骤”
“ 数据集”
作者直接从[19]的作者那里获得了SC数据集的操作码。
解决类不平衡问题:采用了过度采样和欠采样的方法
“The technique of lowering all classes to the same number of data points as the minority class is known as undersampling;” "将所有类别的数据点降低到与少数类别别相同的数量,这种技术被称为欠采样;"
“Oversampling is the process of increasing the quantity of data points in all classes to match the majority class.” 过度取样是指增加所有类别中的数据点的数量,使之与多数类别相匹配的过程。
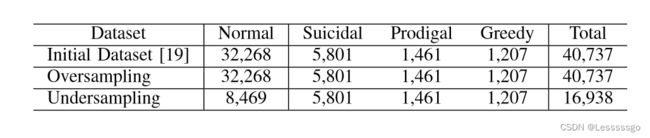
这个图的过采样有问题
一些概念:
-
“TensorFlow”
TensorFlow™是一个基于数据流编程(dataflow programming)的符号数学系统,被广泛应用于各类机器学习(machine learning)算法的编程实现,其前身是谷歌的神经网络算法库DistBelief [1] 。
Tensorflow拥有多层级结构,可部署于各类服务器、PC终端和网页并支持GPU和TPU高性能数值计算,被广泛应用于谷歌内部的产品开发和各领域的科学研究 [1-2] 。
TensorFlow由谷歌人工智能团队谷歌大脑(Google Brain)开发和维护,拥有包括TensorFlow Hub、TensorFlow Lite、TensorFlow Research Cloud在内的多个项目以及各类应用程序接口(Application Programming Interface, API) [2] 。自2015年11月9日起,TensorFlow依据阿帕奇授权协议(Apache 2.0 open source license)开放源代码 [2] 。
-
“Keras”
Keras是一个由Python编写的开源人工神经网络库,可以作为Tensorflow、Microsoft-CNTK和Theano的高阶应用程序接口,进行深度学习模型的设计、调试、评估、应用和可视化 [1] 。
Keras在代码结构上由面向对象方法编写,完全模块化并具有可扩展性,其运行机制和说明文档有将用户体验和使用难度纳入考虑,并试图简化复杂算法的实现难度 [1] 。Keras支持现代人工智能领域的主流算法,包括前馈结构和递归结构的神经网络,也可以通过封装参与构建统计学习模型 [2] 。在硬件和开发环境方面,Keras支持多操作系统下的多GPU并行计算,可以根据后台设置转化为Tensorflow、Microsoft-CNTK等系统下的组件 [3] 。
Keras的主要开发者是谷歌工程师François Chollet,此外其GitHub项目页面包含6名主要维护者和超过800名直接贡献者 [4] 。Keras在其正式版本公开后,除部分预编译模型外,按MIT许可证开放源代码 [1] 。
-
混淆矩阵(confusion matrix.)
混淆矩阵也称误差矩阵,是表示精度评价的一种标准格式,用n行n列的矩阵形式来表示。具体评价指标有总体精度、制图精度、用户精度等,这些精度指标从不同的侧面反映了图像分类的精度。 [1] 在人工智能中,混淆矩阵(confusion matrix)是可视化工具,特别用于监督学习,在无监督学习一般叫做匹配矩阵。在图像精度评价中,主要用于比较分类结果和实际测得值,可以把分类结果的精度显示在一个混淆矩阵里面。混淆矩阵是通过将每个实测像元的位置和分类与分类图像中的相应位置和分类相比较计算的。
混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。每一列中的数值表示真实数据被预测为该类的数目:第一行第一列中的1567表示有1567个实际归属第一类的实例被预测为第一类,同理,第一行第二列的127表示有127个实际归属为第一类的实例被错误预测为第二类。

每一行之和表示该类别的真实样本数量,每一列之和表示被预测为该类别的样本数量
评估指标

实验结果
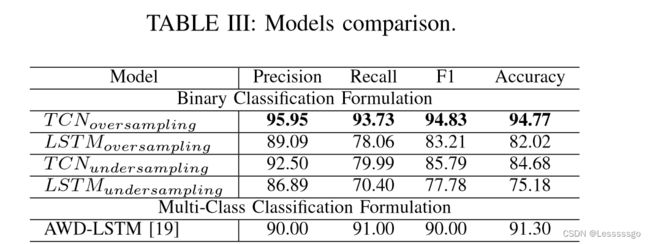
(Gopali 等, 2022, p. 1253)

(Gopali 等, 2022, p. 1253) 如表三所示,TCNoversampling的表现优于基于LSTM的模型。我们的工作结果可能无法与AWDLSTM[19]报告的结果相提并论,因为[19]的作者将问题作为多类分类来处理;而我们的方法是针对二进制分类。根据该表,当进行过量采样时,TCN获得的精度为95.95,而当进行欠采样时,精度为92.50。
未来的研究方向:
然而,将合同标记为正常并不能保证合同不存在漏洞,因为我们不知道的新漏洞仍然可以被攻击者实现。因此,在未来,需要解决创建更多精确识别的SC的问题,以进一步提高该模型的效率。