Word2Vec原理解析二:层级Softmax与负采样
上篇文章介绍了Word2Vec的精髓内容,这篇文章主要介绍层次Softmax和负采样的内容,即Word2Vec的训练技巧,但不是Word2Vec特有的技巧哟。
1. Hierarchical Softmax
1.1 哈夫曼树
哈夫曼树是一种带权路径长度最短的二叉树,即最优二叉树。

权重*步长 的和 = 带权路径长度
图b即为最优二叉树(哈夫曼树)
如何构建哈夫曼树呢?如下图的过程

每个节点都有唯一指定的一个编码形式。
为什么在Word2Vec中使用哈夫曼树呢?(重点)
假设是CBOW模型,上下文x预测中间词y,那么其输出层有词袋大小V个神经元,我们对这V个神经元一开始是等同对待的,但是如果V的数值非常大,等同对待,会导致效率过低。而用哈夫曼树去构造这V个神经元(词),越靠近root节点的地方,词频是越高的,我们可以更快的使用到该词,而越靠近叶节点的地方,词频越低,这样就提高了训练效率,这就是Word2Vec的层次softmax的训练trick。
1.2 逻辑回归 (略)
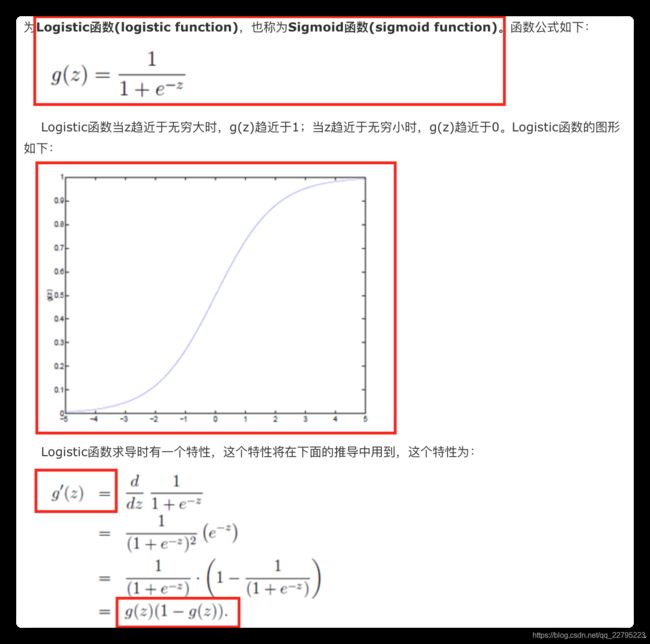

1.3 预先符号定义
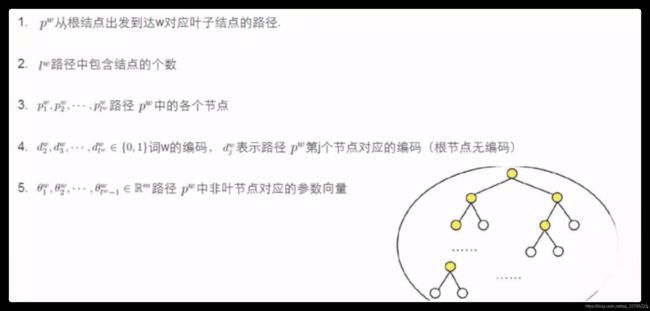
第五点中的Θ为逻辑回归中的参数,因为每个节点都在做二分类任务,即逻辑回归
1.4 基于层级Softmax的CBOW模型 (重点)
注意哈夫曼树的0、1表示与我们所定义的逻辑回归输出的正、负例是相反的。
图中的哈夫曼树左1右0,我们设左为逻辑回归输出的负例,右为正例,正负概率如右上角所示。
输入多个上下文词,进行求和后得到 X w X_w Xw。
假设我们要计算中间词为足球,此时的CBOW的条件概率为 p ( 足 球 ∣ c o n t e x t ( 足 球 ) ) p(足球|context(足球)) p(足球∣context(足球)),过程为:
- root节点进行二分类,同时包含 Θ 1 w Θ^w_1 Θ1w的逻辑回归参数,判定为负例
- d 2 w d^w_2 d2w处进行二分类,包含 Θ 2 w Θ^w_2 Θ2w参数,判定为正例
- 二分类,判定为正例
- 二分类,判定为负例
最后 p ( 足 球 ∣ c o n t e x t ( 足 球 ) ) p(足球|context(足球)) p(足球∣context(足球)) = 以上概率的乘积。
总结一下面试如何回答:
因为Word2Vec词嵌入的生成常常基于CBOW,所以以CBOW为例,描述下层级softmax的这个过程。层级softmax涉及到一个叫做哈夫曼树的东西,哈夫曼树是带权路径和最短的最优二叉树,所以通过对词表中的词进行树构造,可以生成一个哈夫曼树,越接近根节点的词,其词频是越高的,我们需要优先更新,越向下,词频越低,更新频率也小一点,通过这样的方式就可以实现训练速度的加快。
具体来说,CBOW是上下文预测中间词,我们将上下文初始化的词嵌入进行求和得到一个X表示,哈夫曼树的每一个节点都是一个逻辑回归判断,从根节点开始,向下判断,直到落到目标节点上,此时把已走的路径的LR值相乘,即得到此时的条件概率,而训练的目标就是使得整个条件概率达到最大(loss优化过程1.5推导)。
1.5 数学推导CBOW层级Softmax过程(掌握1、2行公式,推出第3行)
和推LR Loss的极大似然估计是一样的,但这里的似然函数写错了!!!

- 第二行 为CBOW的损失函数,加入log只是为了后续计算方便,使得连乘变成连加。
- 第一行 为逻辑回归输出概率值,正例或负例的情况,只不过写在一起了而已, d j w d^w_j djw可能为0可能为1,其是哈夫曼树编码。
- 第一行带入第二行得到第三行,即最终的目标损失函数,我们要对其进行优化求解。
而该优化问题中,我们要更新两个参数,第一个是各个逻辑回归的 Θ Θ Θ值:

第二个是 X w X_w Xw,但需要注意的是,本质更新目标并非 X w X_w Xw,而是输入层的上下文:

w w w是中间词, C o n t e x t ( w ) Context(w) Context(w)是上下文词集合, w ′ w' w′是集合中的一个词, v ( w ′ ) v(w') v(w′)表示该词的词向量。
1.6 基于层级Softmax的Skip-gram模型 (略)
CBOW模型有一个投影层到 X w X_w Xw,那Skip-gram模型则不需要投影,其余和CBOW模型一模一样,不多说了。数学推导的变化条件概率前和后替换一下即可。
2. Negative Sampling
对于词袋大小V而言,如果V非常大,即使是构建哈夫曼树,复杂度也会很高,所以提出使用负采样。使用负采样的时候,可以明显感觉到训练速度快于层次softmax,而且不需要构建复杂的哈弗曼树。
什么是负样本呢?
例如在CBOW中,我们是知道了 C o n t e x t ( w ) Context(w) Context(w),然后来预测单词 w w w,那么这个时候,相对于 C o n t e x t ( w ) Context(w) Context(w),我们提供一组结果,这些结果中包含正确的解 w w w,剩下的都是错误的解,那么 w w w就是正样本,剩下的解就是负样本。
Skip-gram类似,相当于给一组输入 v v v,然后预测正确的输出 C o n t e x t ( w ) Context(w) Context(w),输入的一组数据里面,有一个是正确的输入,为 v ( w ) v(w) v(w),剩下的都是错误的输入,也就是负样本。
那么如何确定 怎么选取负样本呢?见下图,一种带权采样的方法:

每次进行负采样时,如果采样到正样本,word2vec源代码的处理方式是直接跳过去,忽略这次采样的结果就行了,毕竟这样的概率不太高,

也就是说,正常情况下的预测结果是包括大量正样本和负样本的,但是由于词表V非常大,所以我们每次只随机采样一定数量个负样本参与到损失函数的计算中。——负采样
2.1 CBOW 负采样(掌握推导)

w w w是真中心词(正样本), N E G ( w ) NEG(w) NEG(w)中为负样本。

对图中文字进行进一步补充: u u u为所有中间词中的某一个词。
掌握 p ( u ∣ C o n t e x t ( w ) ) p(u|Context(w)) p(u∣Context(w))的表达式。
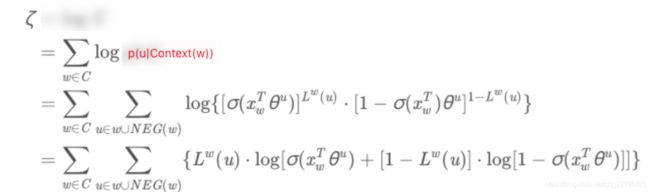

2.2 Skip-gram 负采样(扩展)


3. Word2Vec最后一点补充内容 (掌握)

负采样进行时,更倾向于采样高词频负样本,其对高词频更友好;
层级softmax虽然越接近root节点,词频会越高,但不代表其不对低频词进行更新,只是这样设计的层级softmax训练速度会加快,所以相比负采样策略,其对低词频更加友好。
CBOW上下文预测中间词时,是去尽可能的找到最为合适的中间词,很大可能性会对低词频词进行忽略;而SG中间词预测上下文时,低词频词同样会被模型考虑进去,这相当于给了低频词更多的学习机会,所以其对低频词更加友好。

传统意义上的CBOW和SG模型中的输入层到隐藏层的权重矩阵即为我们需要的词向量,输入层为one hot编码(但gensim 和 google的 word2vec 里面并没有用到one hot,而是初始化的时候直接为每个词随机生成一个N维的向量,并且把这个N维向量作为模型参数学习)
而例如基于层级的CBOW方法,模型结构为:输入层-输入层累加为向量-哈夫曼树的结构,这里的输入层也可以理解为是one hot向量,只不过再随机初始化对应的外部向量表,one hot可以与表中向量进行选中,每次更新向量时,更新对应向量表中的数据。这也是一种理解思路,这个目前业界存在理论分歧,但代码实现是如上段所述。
