C++primer plus学习笔记
第一章 预备知识
1.1 C++简介
C++融合了3种不同的编程方式:
- C语言代表的过程性语言
- C++在C语言基础上添加的类代表面向对象语言
- C++模型支持的泛型编程
C++继承C语言高效、简洁、快速和可移植性的传统
1.2 C++简史
在20世纪70年代,C和Pascal这样的语言引领人们进入结构化编程时代。
在20世纪80年代,C语言称为统治地位的编程语言,因素如下:
- C能够生成简洁、快速运行的程序
- 提供处理硬件问题的能力,如管理通信端口和磁盘驱动器
在这个年代,出现了新的编程模式:面向对象编程(OOP).
1.2.1 C语言
20世纪70年代早期,Bell实验室的Dennis Ritchie为了设计开发UNIX的通用性、可移植性等,在旧语言的基础上开发了C语言
汇编语言依赖于计算机的内部机器语言,可以直接操作硬件。
1.2.1 C语言编程原理
计算机语言要处理两个概念—>数据和算法。
数据是程序使用和处理的信息。
算法是程序使用的方法。
C语言是过程性语言,其强调的是编程的算法方面,其也是一种结构化的编程方式。
C语言的新原则:自顶向下设计,理念是:将大型程序分解成小型,便于管理的任务。
1.2.3 面向对象编程
过程性语言(C语言)强调算法,OPP(C++、Java等)强调数据。
OOP不像过程性编程,其理念是设计与问题的本质特性相对应的数据格式。区别如下:
过程性语言(让问题来满足语言)OOP编程(让语言来满足问题)
在C++中,类是一种规范,描述了新型数据格式,对象则根据类规范构造的特定数据结构。
类规定了可使用哪些数据来表示对象以及可以对这些数据执行哪些操作。
OOP程序设计方法:先设计类(可以明确表示程序要处理的东西),然后设计使用类的对象的程序。
从低级组织(如类)到高级组织(如程序)的处理过程叫作 自下而上 的编程思想。
类定义 = 数据 + 方法
OOP可以创建可重用的代码,减少大量的工作,信息隐藏可以保护数据,使其免遭不适当的访问。
不同的环境(Windows和Macintosh)下提供编程的类库,可以方便地重用和修改现有的、经过仔细测试的代码。
1.2.4 C++和泛型编程
泛型编程(generic programming)是C++支持的另一种编程模式。与OOP目标系统。
术语:泛型(指创建独立于类型的代码)。
OOP与泛型编程的区别:
OOP强调编程的数据方面,是管理大型项目的工具泛型编程强调独立于特定数据类型,提供执行常见任务(如对数据排序或合并链表)的工具。
C++泛型编程需要对语言进行扩展,以便于可以只编写一个泛型(即不是特定类型的)函数,并将其用于各种实际类型。
1.2.5 C++的起源
C++是C语言的超集,意味着任何有效的C程序都是有效的C++程序。
C++可以使用已有的C软件库。库是编程模块的集合,提供解决很多常见的编程问题的解决办法
1.3、可移植性和标准
C++是C语言的超集,任何有效的C程序都是有效的C++程序。
1.3.1 可移植性的两个障碍
- 硬件:分块放置模块,通过重写模块,最大限度降低可移植性问题。
- 语言上的差异性:国际组织定义了C语言标准、定义了C++99、C++11、C++14等标准。
1.3.2 C++的二重性
- OOP提供了高级抽象
- C提供了低级硬件访问
C++既可以通过OOP进行抽象,也可完成类似C一样的对硬件访问的操作。
1.4、程序创建的技巧
1.4.1 编程步骤

| C++实现 | 源代码文件的扩展名 |
|---|---|
| UNIX | C、cc、cxx、c |
| GNU C++ | C、cc、cxx、cpp、C++ |
| Digital Mars | cpp、cxx |
| Borland C++ | cpp |
| Watcom | cpp |
| Microsoft Visual C++ | cp、cpp、cc、cxx、C++ |
1.4.2 编译和链接
UNIX编译和链接
//第一种 在终端进入cpp文件目录时,输入g++ -o 文件名 文件名.cpp
cd desktop //进入桌面
cd Demo //进入一个文件夹
vi C_p.cpp //编写C_p.cpp 用:wq
g++ -o C_p C_p.cpp //编译
./C_p //执行
//第二种
g++ C_p.cpp //编译,会产生一个a.out的文件
./a.out //运行
linux
g++ spiffy.cxx//该命令将生成可执行文件a.out
g++ spiffy.cxx -lg++//有些版本可能要求链接c++库
//如果要编译多个源文件,只需将它们全部放到命令行中即可
//此时会生成一个a.out可执行文件和两个目标代码文件my.o和precious.o
g++ my.cxx precious.cxx
//如果接下来修改了其中的某个源代码文件,如mu.cxx,则可以使用my.cxx 和 precious.o 来重新编译
g++ my.cxx precious.o
1.4.3 常见的编译器
- Linux/UNIX : GNU gcc/g++
- Windows :软件IDE
- Mac OS : Xcode自带g++和clang
第二章 开始学习C++
2.1 进入C++
/*第一个C++程序*/
#include //a PREPROCESSOR directive-(预处理指令)
using namespace std; //make definition visible(使定义可视化)
int main(void) //function header(函数头)
{ //start of function body
cout<<"Come up an C++"< 对于一个C++ 程序主要包含以下元素:
- 注释:由前缀
//或者是/* */标识 - 预处理器编译指令
#include - 函数头:
int main() - 编译指令:
using namespace - 函数体:用
{ }括起来 - 使用C++ 的
cout工具显示消息的语句 - 结束
main()函数的return语句
2.1.1 main()函数头
main() 被启动代码调用,而启动代码是编译器添加到程序中。
函数头描述
main()和 OS(UNIX/Linux、Windows、mac os等)直接的接口。
空括号的main() 不接受任何参数。
int main(void)
{
statement
return 0;
}
main()函数描述了函数的行为。同时也构成了两部分的 函数定义(function definition) :第一行int main()函数叫做 函数头(function heading),花括号({和})中包括的部分叫 函数体。
函数体:指出函数应做什么的计算机指令。
在C++中,每条完整的指令叫做语句。所有的语句都是以 分号结束。

main()中最后一条语句叫做 返回语句(return statement),结束main()函数。
⚠️注意:C++程序通常是以main() 函数开始执行,如果没有,程序不完整,则编译器会指出未定义main()函数。
大小写都必须准确
不需要
main()函数的特殊情况:
- Windows中的
动态链接(DLL)模块。- 单片机或机器人芯片
⚠️补充
在C++中 int main() 与 int main(void)等效
在C中 int main() 与 int main(void)有所不同
用int main()的话允许您使用任意数量的参数调用main。 main(void) 强制您在没有参数的情况下调用main
2.1.2、C++注释
C++中的注释以 双斜杠(//) 打头。以行尾作为结束。
注释的作用:为程序提供解释说明,使得程序通俗易懂。
通常标识程序的一部分或者是标识代码的某个方面。
注意点:编译器不会运行,会直接忽略注释。
C++也可以识别C语言的注释
C语言风格的注释
多行注释:符号/*和*/之间,以*/作为注释的结束。单行注释:以双斜杠(//)开始,行尾作为结束。
2.1.3、预处理器和头文件
如果程序要使用C++输入或输出工具时,必须使用两行代码:
#include
using namespace std;
使用了 #include作为了预编译指令,也就是所谓的预处理器指令。
预处理器的操作:在源代码被编译之前,替换或添加文本。
例如:
#include
像iostream这样的文件叫做 包含文件(include file) ———— 也被包含在其他的文件中,所以也叫做 **头文件(header file) **。
头文件命名约定
| 头文件类型 | 约定 | 示例 | 说明 |
|---|---|---|---|
| C++旧式风格 | 以 .h 结尾 |
iostream.h | C++程序可以使用 |
| C旧式风格 | 以 .h 结尾 |
math.h | C、C++ 程序可以使用 |
| C++ 新式风格 | 没有扩展名 | iostream | C++程序可以使用,使用namespace std; |
| 转换后的C | 加上前缀c,没有扩展名 | cmath | C++ 程序可以使用,可以使用不是C的特性,如namespace std; |
2.1.4、名称空间(namespace)
如果程序中使用的是 iostream ,那么就需要使用名称空间编译指令来使得对程序可用。
using namespace std;
也叫做 using编译指令。
2.1.5、使用cout进行C++的输出
cout<<"Come up an C++"<双引号 括起来的部分就是要打印的消息。
在C++中,使用双引号括起来的一系列字符叫做 字符串,由于若干个字符组合而成。
<< 指出信息流动的路径,cout是一个预定义的对象。
初识运算符重载
<< 既可以是插入运算符,也可以是左移运算符。
典型的运算符重载的情况,通过重载,同一个运算符代表不同的含义。具体含义编译器会通过上下文来确定。
常见的运算符重载例子
&----> 既表示地址运算符,又表示按位AND运算符。*----> 既表示乘法,也表示对指针解除引用。
控制符endl
cout<endl 是C++中的一个特殊符号,作用:重起一行。
在输出流中插入endl使得屏幕光标移到下一行开头。
endl在头文件iostream中定义,且位于名称空间std中。
换行符
C++也也提供了早期C语言表示换行的方法;C语言符号\n。
\n 被视为一个字符,名为换行符,也就是C++中的endl的重起一行。
显示字符串时,在字符串中包含换行符,而不是在末尾添加endl,可减少输入量。
/*两个语法都是一样的,都是:重起一行*/
cout<<"\n";
cout<2.1.6、C++源代码风格
C++中源代码的风格遵循以下规则:
- 每条语句各占一行。
- 每个函数都有一个
开始花括号和一个结束花括号,两个花括号各占一行。 - 函数中的语句都相对于花括号进行缩进。
- 与函数名称相关的
圆括号周围没有空白。
2.2 C++语句
程序代码例子:
#include
using namespace std;
int main()
{
int carrots; // 声明一个整型变量
carrots = 25; // 给变量赋值
cout<<"我有 "< 2.2.1 声明语句和变量
在C++中,首次使用变量时,必须声明 。可以避免因拼写错误而难以发现错误。
声明通常指出要存储的数据类型和程序对存储在内存里的数据使用的名称。
程序中的声明语句叫作定义声明语句,简称定义。定义会使得编译器为变量分配内存。
⚠️注意:声明不一定是定义。
2.2.2 赋值语句
赋值语句将值赋给存储单元。
符号 = 叫作赋值运算符。 小Tips:C++中允许连续使用赋值运算符。
赋值是从右向左进行。
2.3. 其他C++语句
2.3.1 cin 和cout
cin 使用 >> 运算符从输入流中抽取字符。
可以将通过键盘输入的一列字符(即输入)转换为接收信息的变量能够接受的形式。
cout 的对象属性包含一个插入运算符 << ,将右侧的信息插入到输出流中。
<< 运算符可以进行多条输出语句的拼接。
2.3.2 类的简介
类是C++ 面向对象编程(OOP)的核心概念之一。
什么是类?
类是用户定义的一种数据类型。
要定义类,需要描述它能够表示什么信息和可对数据执行什么操作。
类定义描述的是:数据格式及其用法,而对象则是根据数据格式规范创建的实体。
两个类cin类 和 cout类
cin类:istream类对象cout类:ostream类对象,ostream类定义描述了ostream对象表示的数据以及对它执行的操作。
两个类没有被内置到编译器中。 注意点:
类描述了一种数据类型的全部属性(包括使用它执行的操作),对象则是根据描述创建的实体。
C++中信息发送的方式
- 使用类方法(函数调用等)
- 重新定义运算符
2.4. 函数
两种C++函数
- 有返回值
- 无返回值
2.4.1 有返回值的函数
有返回值的函数将生成一个值,而值将赋值给变量或其他的表达式中使用。
- 被调用函数:被调用的函数
- 调用函数:包含调用的函数
- 返回值:发送回的值
参数 是发送给函数的信息, 返回值 是从函数中发送回去的值。
小Tips:对于C++编译器而言,函数的参数类型和返回值类型必须一致 。
⚠️注意:C++程序应当为程序中使用的每个函数提供原型。
函数原型结尾必须以
分号(;)结束。如果省略分号,编译器则认为是函数头,要求提供定义该函数的函数体。
不要混淆函数原型和函数定义
函数原型只描述函数接口。
函数定义包含函数的代码。
小Tips:首次使用函数之前提供原型,一般把原型放在 main()函数定义前面。
2.4.2 函数变体
-
在原型中使用关键字void来指定返回类型,指出函数没有返回值。
void bucks(double); -
关键字void不接受任何参数。如果省略void,让括号为空,则C++解释为一个不接受任何参数的隐式声明。
rand(void);
2.4.3 用户定义的函数
对于库函数,在使用之前必须提供其原型,通常把原型放在main()定义之前。
-
函数格式 函数格式为:
一个函数头 + 花括号的函数体。
type functionname(arguementlist) { statements }
C++ 不允许将函数定义嵌套在另一个函数中,每个函数定义独立。
- 函数头 例如
main()函数头。
⚠️注意:关键字是专用词,不能用作他用。
return不能用作变量名,double不能用作函数名。

2.4.4 用户定义的有返回值的函数
有返回值的函数,使用关键字return来提供返回值,并结束函数。
函数的特性
- 有函数头和函数体
- 接受一个参数
- 返回一个值
- 需要一个原型
2.4.5 在多函数程序中使用using编译指令
让程序访问名称空间std的4种方法
- 将
using namespace std;放在函数定义之前,让文件种所有的函数都能够使用名称空间std中所有的元素。 - 将
using namespace std;放在特定的函数定义之前,让该函数能够使用名称空间std中的所有元素。 - 在特定的函数中使用类似
using std::cout;编译命令,而不是using namespace std;让该函数能使用指定的元素,如cout。 - 完全不使用
编译指令using,而在需要使用名称空间std中的元素是,使用前缀std::。
第三章 数据处理
3.1 简单变量
程序必须记录3个基本属性
- 信息将存储在哪里
- 要存储什么值
- 存储何种类型的信息
变量先声明是为了让程序找到一个能够存储整数的内存,将该内存单元标记为“变量名”,并将对应的数值复制到该内存单位中。
3.1.1 变量名
C++变量命名规则
- 变量名只能使用
字母字符、数字和下划线(_)。 - 名称的
第一个字符不能是数字。 - 区分大小写
不能将关键字用作名称- 以
两个下划线或下划线和大写字母开头的名称被保留给实现(编译器及其使用的资源)使用。以一个下划线开头的名称被保留给实现,用作全局标识符。 - 对名称长度没有限制,名称中所有字符都有意义。
✅ 小Tips:变量名建议使用 驼峰式 的格式。例如:myEyeTooth 或 my_eyes。
3.1.2 整型
整数:没有小数部分的数字。如:77、-120等。
C++中,不同的整型使用不同的内存量,使用的内存越大,可表示的数值范围越大。
整型分为:
- 正值
- 负值
3.1.3 整型short、int、long和long long
计算机内存的基本单元:位(bit) 。
字节(byte) 通常是8位的内存单元。字节指的是描述计算机计算机内存量的度量单位。
单位换算:
1 KB = 1024 byte
1 MB = 1024 KB
在C++种也确保了类型的最小长度
- short 至少 16位
- int 至少和 short一样长
- long至少32位,且至少与int一样长
- long long 至少 64位,且至少与long一样长。
要知道系统中整数的最大长度,可以使用C++工具来检查类型的长度。
首先使用sizeof运算符返回类型或变量的长度,单位为字节。
climits中包含符号常量(预处理方式)来表示类型的限制。
#include
#include // 定义了符号常量来表示类型的限制
using namespace std;
int main()
{
// 变量的初始化
int n_int = INT_MAX;
short n_short = SHRT_MAX;
long n_long = LONG_MAX;
long long n_llong = LONG_MAX;
/**使用sizeof()运算符, 不是函数
*
* 可对类型名(如int)或者是变量名(如n_short)使用,对变量名使用时,括号可有可无。
*/
cout<<"int 是 "<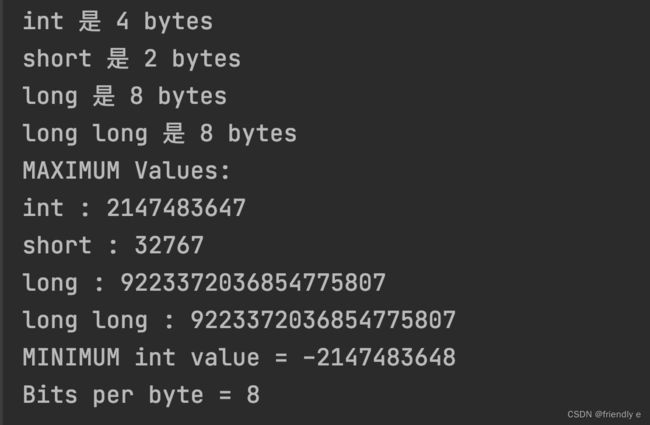
climits中的符号常量
符号常量
表示
CHAR_BIT
char的位数(8)
CHAR_MAX
char的最大值(127)
CHAR_MIN
char的最小值(-128)
SCHAR_MAX
signed char的最大值(127)
SCHAR_MIN
signed char的最小值(-128)
UCHAR_MAX
unsigned char的最大值(255)
SHRT_MAX
short 的最大值(32767)
SHRT_MIN
short 的最小值(-32768)
USHRT_MAX
unsigned short 的最大值(65535)
INT_MAX
int 的最大值(2147483647)
INT_MIN
int 的最小值(-2147483648)
UINT_MAX
unsigned int 的最大值(4294967295)
LONG_MAX
long 的最大值(9223372036854775807)
LONG_MIN
long 的最小值(-9223372036854775808)
ULONG_MAX
unsigned long的最大值(18446744073709551615)
LLONG_MAX
long long 的最大值(9223372036854775807)
LLONG_MIN
long long 的最小值(-9223372036854775808)
ULLONG_MAX
unsigned long long 的最大值(18446744073709551615)

//此程序可以判断编译器默认是signed还是unsigned
#include
using namespace std;
int main(){
char c = -1;
signed char a = -1;
unsigned char b = -1;
printf("c = %d , a = %d , b = %d",a,b,c );
return 0;
}
3.1.4 变量初始化问题
- 初始化将赋值和声明合并在一起。也可以使用
字面值常量来初始化。也可以直接使用表达式来初始化变量。
int variable00 = value;
int variable01 = value1 + value2;
int variable02(4);
- 如果不对函数内部定义的变量进行初始化,该变量的值不确定的。
- 将大括号初始化用于单值变量。
int emus{7};//set emus to 5
int rheas{12};//set rheas to 12
int var = {12};
大括号初始化器可用于任何类型(可以使用等号,也可以不使用),属于通用的初始化语法。
- 在大括号内也不包含任何东西。此时变量初始化为零。
- 变量的初始化的问题,有助于防范类型转换错误。
3.1.5 无符号类型
优点:可以增大变量能够存储的最大值。
创建无符号类型的变量时,只需要使用unsigned来进行声明即可。
short变量加 unsigned和没有 unsigned,两者显示结果都是不一样的。
#include
//deposited 后置定于 被存储(在账户中)
#define ZERO 0 //makes ZERO symbol for 0 value
#include // defines INT_MAX as largest int value
int main() {
using namespace std;
short sam = SHRT_MAX; //initialize a variable to max value
unsigned short sue = sam;//okay if variable sam already defined
cout << "Sam has " << sam << " dollars and Sue has " << sue;
cout << " dollars deposited. " << endl
<< "Add $1 to each account." << endl << "Now ";
sam += 1;
sue += 1;
cout << "Sam has " << sam << " dollars and Sue has " << sue;
cout << " dollars deposited.\n Poor Sam!" << endl;
cout << endl;
sam = ZERO;
sue = ZERO;
cout << "Sam has " << sam << " dollars and Sue has " << sue;
cout << " dollars deposited. " << endl
<< "take $1 from each account." << endl << "Now ";
sam -= 1;
sue -= 1;
cout << "Sam has " << sam << " dollars and Sue has " << sue;
cout << " dollars deposited.\n Lucky Sue!" << endl;
return 0;
}
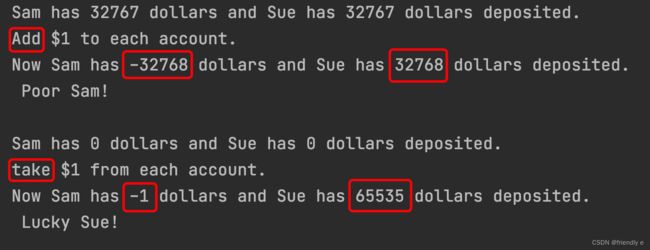
由上可知,当作为short类型且被赋予short类型的最大值的Sam加1之后,Sam会上溢,然后导致其重返最小值;而作为unsigned short类型的Sue不受此影响
当作为unsigned short类型的Sue被赋值0之后减1,会导致其下溢,令其值跳转到对应类型的最大值65535
3.1.6 选择整型类型
如果short 比 int 小,则使用short可以节省内存。如果节省内存很重要,则应使用short而不是int。例如:假设要将程序从int为16位的系统移到int为32位的系统,则用于存储int数组的内存量会加倍,但是short数组不受影响。
3.1.7 整型字面值
整型字面值(常量):显式书写的常量。如777或者是222。
C / C++中的三种计数方法:
- 十进制(第一位为1~9,基数为10)----> dec
- 八进制(第一位为0,基数为8) ----> oct
- 十六进制(前两位以0x或0X开头,基数为16,0~9和a~f(A~F)的组合)----> hex
默认情况下,cout以十进制形式显示整数。
cout << hex; //manipulator for changing number base
cout << oct;//manipulator for changing number base
标识符位于名称空间 std中,程序如果使用了该命名空间的话,不能将hex作为变量名
然而,程序如果省略了编译指令的话,hex可以当作变量名
3.1.8 char类型:字符和小整数
char类型:专门存储字符(如字母和数字),也是另外一种整型。
一般不超过128个字符,可以表示计算机系统中的所有基本符号 -----> 所有的字母、数字和标点符号等。
ASCII字符集中的字符用数值编码(ASCII码)进行表示。如字符A的编码为65。
#include
int main(void)
{
char ch = 'M';
std::cout <<"The ASCII code for "<< ch <<" is "<
成员函数cout.put() ———— C++ OOP概念中的成员函数,成员函数归类所有,描述了操作数据的方法。
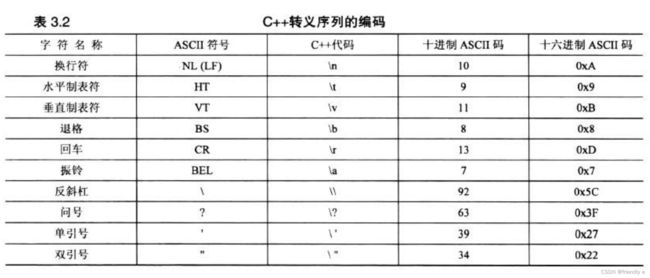
有些字符无法通过键盘输入到程序中,所以C++提供了特殊的表示方法 ----> 转义序列。常见的如下

✅ 小Tips:在可使用数字转义序列或符号转义序列(如\0x8和\b)时,应使用符号序列。
数字表示与特定的编码方式(如ASCII码)相关,而符号表示适用于任何编码方式,其可读性也更强。
将转义序列作为字符常量时,使用单引号,如果放在字符串时,则使用双引号
cout << endl; /*使用endl重起一行*/
cout <<'\n'; /*字符串常量*/
cout <<"\n"; /*字符串*/
char 在默认情况下既不是没有符号,也不是有符号。是否有符号由C++决定,如果char用作数值类型,则 unsigned char 和 signed char 之间的差异将非常重要。
wcha_t
程序需要处理的字符集可能无法用一个8位的字节表示。解决办法有二:
1⃣️编译器定义Char为16字节或以上的字节
2⃣️使用另一种类型wChar_t(宽字符类型)可以表示扩展字符集。wchar_t与underlying(底层类型)的长度和符号属性相同。
⚠️cin 和 cout 将输入和输出看作 char 流,因此不适于用来处理wChar_t类型,但可以使用类似的工具—>wcin 和 wcout
C++11 新增的类型: char16_t 和 char32_t
wchar_t 的长度和符号特征由实现决定,由此C++11 新增char16_t 和 char32_t,其中前后者都无符号。用u’C’、u"be good"指代char16_t ;用U’d’ 、U"very good"指代char32_t;
3.1.9 Bool类型
来源于数学表示法。
C++将非零值表示为true,将零表示为false。
bool is_ready = true;
3.2. const限定符
符号名称指出了常量表示的内容。
const关键字来修改变量声明和初始化。常量被初始化后,其值就被固定,编译器将不允许再修改该常量的值。
将名称的首字母大写,以便提醒是个常量,可便于阅读性增强。如果是变量名全大写,则使用 #define 。
创建常量的通用格式为:
const type name = value;
例如:
const int Months = 12; // 一年有12个月
如果在声明const常量时没有提供值,该常量的值将是不确定,且无法更改。
const int toes;//value of toes undefined at this point
toes = 10; //too late
const 比 #define好,原因如下:
1⃣️它能够明确指定类型
2⃣️可以使用C++的作用域规则将定义限制在特定的函数或文件中
3⃣️const可用在更复杂的类型中
3.3. 浮点数
浮点数就是表示小数点部分的数字。计算机将值分为两部分存储,一部分表示值,另一部分则用于对值进行放大或缩小。
3.3.1 为什么叫浮点数?
因为小数点可移动,所以称之为“浮点数”。
表示方法:
第一种 使用常用的标准小数点表示法
3.14159
10.0
第二种 表示浮点值的方法叫做E表示法(科学计数法)。
例如:
3.45E6 3.45与10的6次方相乘,E6代表的是10的6次方。
E适合表示非常大和非常小的数。

E表示法确保数字以浮点格式存储,即使没有小数点。
指数为负数意味着除以10的乘方,而不是乘以10的乘方。
8.33E~4表示:8.33 / 10的4次方,也就是:0.000833
技巧:
- d.dddE+n ———— 将小数点向右边移动n位
- d.dddE-n ———— 将小数点向左边移动n位
3.3.2 浮点数类型
根据可以表示的有效数位和允许的指数最小范围,可以分为3种浮点数类型:float、 double和long double。
#include
using namespace std;
int main(){
cout.setf(ios_base::fixed,ios_base::floatfield);//定点表示法->结果显示到小数点后6位
float tub = 10.0 / 3.0;
double mint = 10.0 / 3.0;
const float million = 1.0e6;
cout << "tub = " << tub;
cout << ", a million tubs = " << million * tub << endl;
cout << "mint = " << mint << " and a million mints = ";
cout << million * mint << endl;
return 0;
}

⚠️说明:cout会删除结尾的零,例如:将3333333.250000 显示为 3333333.25.调用cout.self 会覆盖这种行为。tub 和 mint 都是准确的,但当数据往右移动六位时,million-mints依旧准确,但是million-tub不准确了。因为系统保证float至少有6位,系统保证double至少有13位有效的。
3.3.3 浮点常量
在书写浮点常量的时候,加 后缀 , 以便区分何种类型,从而确定可表示的数值范围。例如:
3.14f // float类型
3.14L // 长浮点型long double
3.3.4 浮点数优缺点
两个优点:
- 表示整数之间的值
- 有缩放因子
缺点:
浮点数运算的速度通常比整数运算慢,而且精度完全降低。
3.4. C++算术运算符
五种基本运算符进行基本的算术运算。
加(+)、减(-)、乘(*)、除(/)、求模(%)
运算符的优先级和数学中的优先级类似。
3.4.1 除法运算符问题的总结
除法运算符(/)的行为取决于操作数的类型。
如果两个操作数都是整数,则C++将执行整数除法。把结果的小数部分丢弃,使最后的一个结果是一个整数。
如果其中有一个(或两个)操作数是浮点数,则小数部分将保留,结果为浮点数。
#include
using namespace std;
int main()
{
// 如果编译器不接受self()中的ios_base,请使用ios。
cout.setf(ios_base::fixed,ios_base::floatfield);
cout<<"整数消除: 10 / 5 = "<<10/5<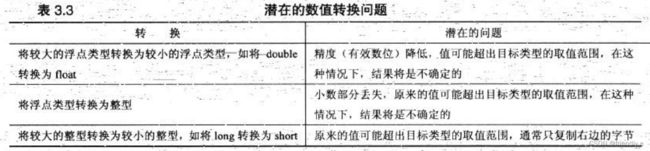
类型的强制转换
强制转换本身不会修改变量本身,而是创建一个新的、指定类型的值。
强制转换的通用格式如下:
(typename) value //来源于C语言
typename (value) // C++
#include
using namespace std;
int main(){
using namespace std;
int auks ,bats,coots;
//the following statement adds the values as double
//then converts the result to int
auks = 19.99 + 11.99;
//these statements add values as int
bats = (int) 19.99 + (int) 11.99;//old C syntax
coots = int (19.99) + int (11.99);//new C++ syntax
cout << "auks = " << auks << ", bats = " << bats;
cout << ", coots = " << coots << endl;
char ch = 'Z';
cout << "The code for " << ch << " is ";
cout << int (ch) << endl;
cout << "Yes,the code is ";
cout << static_cast(ch) << endl; //
return 0;
}

⚠️说明:
1⃣️auks 是 先将19.99和11.99相加,得到结果为31.98.然后转换为int赋值给auks;
后面的bats和coots都是将加数转换为int的类型,然后再将和赋值给bats和coots。
2⃣️cout << int(ch) << endl; //此语句是cout本来是输出char类型的,但是ch被强制转为int,所以Cout将采用int模式。
3.4.4 C++11中的auto声明
在初始化声明中,如果使用关键字auto 时,而不指定变量的类型,编译器将把变量的类型设置成与初始值相同。
auto n = 100; /*自动设置为int类型*/
auto x = 1.15; /*自动设置为double类型*/
//处理复杂类型,例如标准模块库迭代器
//c++98
std::vector scores;
std::vector ::iterator pv = scores.begin();
//C++11可以这样改
std::vector scores;
auto iterator pv = scores.begin();
第四章 复合类型
4.1. 数组概述
4.1.1 数组的定义
数组(array)是一种数据格式,能够存储多个同类型的值。每个值都存储在一个独立的数组元素中,计算机在内存中依次存储数组的各个元素。
数组声明的三个特点:
- 存储在每个元素中的值的类型
- 数组名
- 数组中的元素数
C++中可以通过修改简单变量的声明,添加中括号(其中包含元素数目)来完成数组声明。
例如:
short days[24]; // 一天有24个小时
4.1.2 数组的声明
声明数组的的一般语法格式为:
// 数组类型 数组名字[数组的大小]
// typeName arrayName[arraySize];
int score[4]; // 四个人的分数,整型数组
数组的大小是指定元素的数目,必须是整型常数或const值,也可以是常量表达式(8*sizeof(int))
4.1.3 复合类型的数组
可以使用其他的类型来创建(C语言使用术语:派生类型)
数组的用途,可以单独访问数组元素,方法是:使用下标或索引对元素进行编号。从0开始编号。
编译器不会检查下标是否有效,所以要注意下标合法性,避免程序异常问题。 C++使用索引的方括号表示法来指定数组元素。
4.1.4 数组的初始化规则
1.只有在定义数组时才能初始化,此后不能使用,也不能将一个数值赋给另一个数组。
int cards[4] = {3,6,8,10}; //okay
int hands[4]; //okay
hands[4] = {5,6,7,9}; //not allowed
hand = cards; //not allowed
2.初始化数组时,提供的值少于数组的元素数目。
3.如果只对数组的一部分进行初始化,则编译器把其他元素设置为0。
4.如果初始化为{1}而不是{0},则第一个元素被设置为1,其他元素都被设置为0.
5.如果初始化数组方括号内([])为空,C++编译器将计算元素个数。 例如:
short things[] = {1,3,5,7};
int num_elements = sizeof things / sizeof(short);
4.1.5 C++11数组初始化方法
C++11将使用大括号的初始化(列表初始化)作为一种通用的初始化方式,可用于所有类型。
在C++中列表初始化就增加了一些功能:
- 初始化数组时,可省略
等号(=)
double earnings[4] {1.2e4,1.6e4,1.1e4,1.7e4};
- 可不在大括号内包含任何东西,这会将所元素都设置为零。
unsigned int const[10] = {};
float balances[100] {};
- 列表初始化禁止缩窄转换。
long num[] = {25,92,3.0}; // 浮点数转换为整型是缩窄操作
例子:
#include
using namespace std;
int main()
{
// 创建一个名字为yams的数组,包含了3个元素,编号是0~2.
int yams[3];
yams[0] = 7;
yams[1] = 8;
yams[2] = 6;
// 使用逗号分隔的值列表(初始化列表),然后用花括号括起来即可。
// 列表中的空格是可选的,如果没有初始化函数中定义的数组,其元素值也是不确定。
int yamcosts[3] = {1,2,3};
cout<<"yams 数组是:"<
4.2. 字符串
字符串是存储在内存的连续字节中的一系列字符。
4.2.1 C++处理字符串的两种方式:
-
C语言,常常被称为
C-风格字符串(C-style String)
以空字符(\0,ASCII码对应为0)来标记字符串的结尾。'\0’是字符串的结束标志,不计入长度,但要占空间
char dog[8] = {'b','e','a','u','x',' ','I','I'}; //not a string
char cats[8] = {'f','a','t','e','s','s','a','\0'};//a string!
-
基于String类库的方法
存储在连续字节中的一系列字符意味着可以将字符串存储在char数组中。其中每个字符都位于自己的数组元素中。
使用引号括起来的字符串,这种字符串叫 字符串常量(String constant) 或 字符串字面值(string literal) 。
字符串常量(使用双引号)不能与字符常量(使用单引号)互换。
例如:
char name[] = "Soler";
字符串结尾的空字符,不用直接显式包括,机器在键盘输入,将字符串读入到char类型中,会在结尾自动加上空字符。
⚠️注意:确定了存储字符串所需的最短数组时,不要忘记把结尾的空字符包括在内。
4.2.2 字符串常量的拼接
方法:直接两个引号括起来的字符串合并为一个。任何两个由空白(空格、制表符和换行符)分隔的字符串常量都将自动拼接成一个。
cout<<"My name is " "Soler HO.\n"
4.2.3 在数组中使用字符串
将字符串存储到数组的常用方法:
- 将数组初始化为字符串常量
- 将键盘或文件输入读入到数组中。
#include
#include /*提供strlen()函数*/
using namespace std;
const int Size = 15;
int main()
{
char name1[Size];
char name2[Size] = "C++owboy";
// 字符串的拼接
cout<<"Howdy!I'm "<< name2;
cout<<"!,What's your name?\n";
cin>>name1;
cout<<"Well, "<
strlen() 函数 和 sizeof()运算符的区别
strlen()函数
- 返回的是
存储在数组中的字符串的长度,而~~不是数组本身的长度~~。
- strlen()只计算
可见的字符,而不把空字符计算在内。
sizeof() 运算符
- 指出
变量或数据类型的字节大小。
- 可用于获取
类、结构、共用体和其他用户自定义数据类型的大小。
⚠️字符串输入缺陷:
#include
using namespace std;
int main(){
const int Arsize = 20;
char name[Arsize];
char dessert[Arsize];
cout << "Enter your name:\n";
cin >> name;
cout << "Enter your favourite desert:\n";
cin >> dessert;
cout << "I have some delicious " << dessert;
cout << " for you, " << name << ".\n";
return 0;
}


解释:cin使用空白(空格、制表符和换行符)来确定字符的结束位置。一般情况,cin在获取字符数组输入时只读取一个单词。读取该单词后,cin将该字符串放到数组中,并自动在字符串末尾添加空字符。
然而,上面这个例子是,cin把Alistair作为第一个字符串,并将其赋值给name。然而,同时输入两个单词,Dreeb被留在输入队列中。下面的cin在输入队列中搜索dessert的值时,发现Dreeb,cin读取Dreeb,赋值给dessert数组。
4.2.4 读取一行字符串的输入
解决没有逐行读取输入的缺陷。
istream中提供了面向行的类成员函数:getline() 和 get() 函数
1. 面向行的输入:getline()
使用通过回车键输入的换行符来确定输入结尾。使用 cin.getline() 。
函数有两个参数:
- 第一个参数:存储输入行的
数组名称。
- 第二个参数:要读取的字符数(注意包含结尾的
空字符(\0))。
格式:
//cin.getline(name,ArSize);
#include
using namespace std;
int main(){
const int ArSize = 20;
char name[ArSize];
char dessert[ArSize];
cout << "Enter your name:\n";
cin.getline(name,ArSize);
cout << "Enter your favorite dessert:\n";
cin.getline(dessert,ArSize);
cout << "I have some delicious " << dessert;
cout << " for you, " << name << ".\n";
return 0;
}
2. 面向行的输入:get()
与getline() 函数类似,接受的参数相同,解释参数的方式也相同,并读到行尾。
区别:get() 读取并丢弃换行符,将其留在输入队列中
格式:
cin.get(name,ArSize);
get() 将两个类成员函数拼接(合并):
cin.get(name,ArSize).get();
⚠️注意:get() 函数读取空行(空格、注释)后设置会失效,输入会被阻断。可用如下恢复:
cin.clear();
cin.ignore();
混合输入数字和面向行的字符串会导致的问题:无法输入地址。
解决方法:直接使用get()进行读取之前的丢弃换行符。
⚠️attention:如果连续使用两次get的话,cin 的状态会变成失效位,输入会被阻断
#include
#include
using namespace std;
int main()
{
char str[20];
char num[20];
cout << "请输入1:";
cin >> num;
cout << "num = " << num << endl;
cout << "请输入:\n";
cin.get(str, sizeof(str));
// if(cin.rdstate() == ios::goodbit)
// {
// cout << "输入一行正确.\n";
// cout << "str: " << str << endl;
// }
if(cin.rdstate() == ios::failbit)
{
cout << "输入了空行、或者其他错误.\n";
cin.clear();
cin.ignore();
}
//cin.clear();
//cin.ignore();
cout << "请输入:\n";
cin.get(str, sizeof(str));
cout << "str: " << str << endl;
return 0;
}
<—以下均不会阻断—>
//二者不会阻断的原因: cin 不会读取 get保留的换行符
int year;
char str[20];
cin.get(str,sizeof(str));
cin>>year;
int year;
char str[20];
cin>>year;
cin.get(str,sizeof(str));
4.3. string类
string类位于名称空间std中,所以需要提供using指令或者是直接使用std::string进行引用。
要使用string类,必须在程序中包含头文件string中。
string类定义隐藏了字符串的数组性质。
4.3.1 string对象的方式
使用string对象的方式和使用字符数组相同。
C-风格字符串来初始化string对象中。
char first_date[] = {"Le Chapon Dodu"};
char second_date[] = {"The Blegant Plate"};
string third_date = {"The Bread Bowl"};
string fourth_date = {"Hank's Fine Eats"};
- 使用
cin来将键盘输入存储到string对象中。
- 使用
cout来显示string对象。
- 可以使用
数组表示方法来访问存储在string1对象中的字符。
赋值 —— 不能将一个数组赋给另一个数组,但可以将一个string对象赋另一个string对象。
char char01[20]; // 创建一个空列表
char char02[20] = "Jason"; // 创建一个初始化数组
string str01; // 创建一个空的string对象
string str02 = "Soler Ho"; // 创建一个初始化的string对象
char01 = char01; // 不可执行,一个数组不能赋值给另一个数组
str01 = str02; // 可执行,可将一个string对象赋给另一个string对象。
4.3.2 赋值、拼接和附加
string类简化字符串合并操作。
- 利用
运算符 + 将两个string对象合并起来。
string str01;
string str02 = "Soler Ho";
string = str01 + str02;
- 可以使用
运算符 += 将字符串附加到string对象的末尾。
string str01;
string str02 = "Soler Ho";
str01 += str02;
4.4. 结构简介
结构是用户定义的类型,而结构声明定义了类型的数据属性。
定义类型之后,就直接创建类型的变量。
结构比数组灵活,同一个结构中可以存储多种类型的数据。
4.4.1 创建结构的步骤:
- 定义结构描述 —— 描述并标记能够存储在结构中的各种数据类型
- 按描述创建结构变量(结构数据对象)。
4.4.2 结构的定义:
struct(关键字) 类型名(标记成为新类型的名称)
{
结构成员1;
结构成员2;
结构成员3;
};//(结束结构声明)
对于结构中的成员,使用成员运算符(.)来进行访问各个成员。
4.4.3 结构的初始化(C++11)
- 与数组一样,列表的初始化用于结构,且
等号(=)可有可无。
infor Soler_infor {"Soler HO",55,168}; // 在C++11中,= 号可以省略
- 如果大括号内未包含任何东西,各个成员都将设置为零。
infor Soler_infor {};
- 不允许缩窄转换
✅ 小Tips:C++允许在声明结构变量时省略关键字struct。
4.4.4 成员赋值
成员赋值(memberwise assignment):可以使用赋值运算符(=)将结构赋另一个同类型的结构。这样结构中的每个成员都将被设置为另一个结构中相应成员的值。即使成员是数组。这种方式就是成员赋值。
4.5. 共用体
共用体(union),也叫做联合(union)。一种 构造数据类型 。
关键字:union
联合(union):将不同类型的数据在一起共同占用同一段内存
存储不同的数据类型,但只能同时存储其中的一种类型
示例:
union sample
{
int int_val;
long long_val;
double double_val;
};
4.5.1 结构体和共用体的区别
- 结构可以
同时存储int、long和double。
- 共用体
只能存储int、long和double三种。
- 含义不同。
- 关键字不同
- 结构体:struct
- 共用体:union
4.5.2 共用体的用途:
- 当数据使用两种格式或更多格式(但不会同时使用)时,可以节省空间。
- 嵌入式系统编程(如控制烤箱、MP3播放器),内存非常宝贵。
- 常用于操作系统数据结构或硬件数据结构。
4.5.3 匿名共用体
匿名共用体(anonymous union)没有名称,其成员将成为位于相同地址处的变量。
4.6. 枚举
C++的enum工具提供了另一种创建符号常量的方式,可以代替const,允许定义新类型,但必须有严格限制。
使用enum的语法格式与结构的使用类似。
enum color{red,orange,yellow,green,blue,voilet};
4.6.1 设置枚举量的值
enum week{Monday = 1,Tuesday = 2;Wednesday = 3;Thursday = 4};
指定的值必须是整数。也可以只显示定义其中一些枚举量的值。
如果第一个变量未初始化,默认为0。后面没有被初始化的枚举量的值将比其前面的枚举量大1。也可以创建多个值相同的枚举量。
enum {zero,null = 0,numero_one,one = 1};
4.6.2 枚举的取值范围
每个枚举都有取值范围的上限,通过强制类型转换,可以将取值范围中的任何整数值赋给枚举常量,即使这个值不是枚举值。
4.6.3 取值范围的定义
- 找出上限,需要知道枚举量的最大值。
- 找到大于最大值的,最小的2的幂,减去1,得到就是取值范围的上限。
- 计算下限,知道枚举量的最小值。
- 如果不小于0,则取值范围的下限为0,否则,采用寻找上限方式相同的方式,但是要加上负号。
对于选择使用多少空间来存储枚举由编译器决定。
⚠️枚举的使用注意:
-
枚举变量可以直接输出,但不能直接输入。如:cin >> color3; //非法
-
不能直接将常量赋给枚举变量。如: color1=1; //非法
-
不同类型的枚举变量之间不能相互赋值。如: color1=color3; //非法
-
枚举变量的输入输出一般都采用switch语句将其转换为字符或字符串;枚举类型数据的其他处理也往往应用switch语句,以保证程序的合法性和可读性。
-
#include
using namespace std;
enum weekday {
SUN,
MON,
TUE,
WED,
THU,
FRI,
SAT
};
int main() {
int today;
cin >> today;
switch (today)
{
case SUN:
cout << "今天星期天"<
-
枚举量是整型的话,可被提升为int类型,但int类型不能自动转换为枚举类型(第二点)
-
int day = Sun; // valid,spectrum type promoted to int
day = 3 + Wed; //valid ,red converted to int
4.7. 指针和自由空间
对于地址显示结果是十六进制表示法,因为都是常常描述内存的表示法。
-
指针与C++基本原理
面向对象编程和传统的过程性编程的区别,OOP强调的是运行阶段(而不是编译阶段)进行决策。
- 运行阶段:程序正在运行时,取决于不同的情况。生动地描述就是:度假时候,选择参观哪些景点取决于天气和当时的心情;具体描述就是:有时候为了安全,将数组的长度设定得比较大,但是这样子会导致内存的浪费,假如通过new关键字程序运行阶段的时候动态为数组分配内存的话,就不会导致内存的浪费。
- 编译阶段:编译器将程序组合起来时。坚持原先设定的安排。生动地描述就是:不管什么条件下,都坚持预先设定的日期安排;具体描述就是,在声明一个数组前,必须指明数组的长度,因而数组长度在编译的时候就已经设定好了。
指针用于存储值的地址。指针名表示的是地址。
*运算符称为间接值或解除引用运算符,将其应用于指针,得到该地址处存储的值。
4.7.1 声明和初始化指针
指针的声明必须指定指向的数据的类型。
int *p_updates;
*p_updates 的类型是int,所以*运算符被用于指针,所以p_updates变量必须是指针。
运算符*两边的空格是可选的。
int *ptr; /*该情况强调:*ptr是一个int类型的值。*/
int* ptr; /*该情况强调:int* 是一种类型,指向int的指针。*/
在C++中,int*是一种复合类型,是指向int的指针。
double *tax_ptr;
4.7.2 指针的危险
在C++创建指针时,计算机将分配用来存储地址的内存,但是不会分配用来存储指针所指向的数据的内存。
⚠️注意:一定要在对指针应用解除引用运算符(*)之前,将指针初始化为一个确定的、适当的地址。
4.7.3 指针和数字
整数可以加减乘除等运算,而指针描述的是位置。
C++语言数字不能作为地址使用,如果要把数字当地址来使用,应通过强制类型转换将数字转换为适当的地址类型。
4.7.4 使用new分配和delete释放内存
指针在运行阶段 分配未命名的内存以存储值。然后使用内存来访问内存。
C语言中,使用 **库函数malloc()**来分配内存。C++中使用 ———— new运算符。
1. 要注意使用delete进行内存的释放
需要内存时,直接使用new来请求,这是内存管理数据包的一个方面。
如果使用了delete运算符,使得在使用完内存后,能够将其归还给内存池,这是有效使用内存的关键。
使用delete时,后面要加上指向内存块的指针。
int * ps = new int; // 使用new进行内存分配
...
delete ps; // 使用delete进行内存的释放
⚠️注意点:
1.使用delete释放ps的内存,但是不会删除指针ps本身。
2.只能用delete来释放使用new分配的内存,但是如果是空的指针使用delete是安全的。
使用delete的关键:用于new分配的内存。不是要使用于new的指针,而是用于new的地址。
❌警告:不能创建两个指向同一个内存块的指针。会增加错误地删除同一个内存块两次的可能性。
4.7.5 使用new创建动态数组
C++中,创建动态数组,只需要将数组的元素类型和元素数目告诉new即可。必须在类型名后面加上方括号,其中包含了元素数目。
静态联编和动态联编:
- 静态联编:通过声明创建数组,在编译之前就加入程序中,则程序会在编译时就给他分配内存空间了。
- 动态联编:在编译时才加入程序中,如果程序需要用到数组,则在编译的时候创建它,不需要就不创建。
通用格式:
Type_name *pointer_name = new Type_name[num_element];
//例子
int * psome =new int[10]; // 创建10个int元素的数组
new运算符会返回第一个元素的地址
如果使用完new分配的内存,使用delete进行内存的释放。
delete [] psome; // 进行内存的释放
delete和指针直接的方括号告诉程序,应释放整个数组,不仅仅是指针指向的元素。
delete中的方括号的有无取决于使用new时的方括号有无。
对于指针数组的使用,直接可以按照普通数组的使用即可。
4.7.6 使用new和delete时,要遵循的规则
- 不要使用delete来释放不是new分配的内存。
- 不要使用delete释放同一个内存块两次。
- 如果使用
new[]为数组分配内存时,则应使用delete[] 来释放。
- 如果使用new[]为一个
实体分配内存,则应使用delete(没有方括号)来释放。
- 对空指针使用delete时很安全。
4.8. 指针、数组和指针算术
指针和数组基本等价的原因:指针算术(pointer arithmetic) 和C++ 内部处理数组的方式。
- 对
整数变量 + 1,其值增加1
- 对
指针变量 + 1,增加的量等于它指向的类型的字节数。 获取数组地址的两种方式
double * pw = wages; // 数组名 = 地址 ;将pw声明为指向double类型的指针。然后将其初始化为wages - - - wages数组中第一个元素的地址。
short * ps = &wages[0]; // 使用地址操作;使用地址运算符来将ps指针初始化为stacks数组的第一个元素。
⚠️注意:
- 在64位系统中,sizeof(double ·) == sizeof(int ·) == sizeof(char ·) == 64 / 8 = 8;
- 在32位系统中,sizeof(double ·) == sizeof(int ·) == sizeof(char ·) == 32/ 8 = 4;
4.8.1 指针问题小结
1. 声明指针
要声明指向特定类型的指针,语法格式:
TypeName *pointerName;
// 例子
double * pn; // pn 指向一个double类型
char * ps; // ps 指向一个char类型
2. 给指针赋值
将内存地址赋给指针。可以对变量名应用 & 运算符,来获得被变量名的内存地址,new运算符返回未命名的内存的地址。
示例:
double * pn; // pn 指向一个double类型
double * pa; // pa 指向一个double类型
char * pc; // pc 指向一个char类型
double bubble = 3.2;
pn = &bubble; // 把bubble的地址赋值给 pn
pc = new char; // 新建char地址并分配给pc
3. 对指针解除引用
对指针解除引用意味着获得指针指向的值。
- 方法1:对指针应用解除
引用或间接值运算符(*)来解除引用。
cout<<*pn;
*pc = 's';
- 方法2:使用
数组表示法。不可以对未初始化为适当地址的指针解除引用。
4. 数组名
多数情况下,C++将数组名视为数组的第一个元素的地址。
int tacos[10]; // 此时的tacos同样也是&tacos[0]
5. 指针算术
C++中允许指针和整数相加。加1 的结果等于原来的地址值加上指向的对象占用的总字节数。
也可以将一个指针减去另一个指针,获得两个指针的差。得到一个整数,仅当两个指针指向同一个数组(也可以指向超出结尾的一个位置)时,这种情况会得到两个元素的间隔。
6. 数组的动态联编和静态联编
使用数组声明来创建数组时,将采用静态联编,即数组长度在编译时设置。
int tacos[10] // 静态联编
使用new[]运算符创建数组时,将采用动态联编(动态数组),即将在运行时为数组分配空间,其长度为运行时设置。
使用这类数组后,要使用delete[]释放所占用的内存。
7. 数组表示法和指针表示法
使用方括号数组表示法等同于对指针解除引用。
数组名和指针变量也是一样。所以对于指针和数组名,既可以使用指针表示法,也可以使用数组表示法。
int * pt = new int [10];
*pt = 5;
pt[0] = 6;
pt[9] = 5;
int coats[10];
*(coats + 4) = 12;
4.8.2 指针和字符串
数组名是第一个元素地址。
如果给cout提供一个字符的地址,则它将从该字符开始打印,直到遇到空字符为止。
在cout和多数C++表达式中,char数组名、char指针以及用引号括起来的字符串常量都被解释为字符串第一个字符的地址。
不要使用字符串常量或未被初始化的指针来接收输入。
在字符串读入程序时,应使用已分配的内存地址。该地址不是数组名,也可以使用new初始化过的指针。
strcpy()接受两个参数,第一个:目标地址,第二个:要复制的字符串的地址。
⚠️注意:一般来说如果给cout提供一个指针,它将打印地址,但如果指针类型为char* ,则cout将显示指向的字符串。如果要显示的是字符串的地址,则必须将这种指针强制转换为其他类型。
通过new与strlen、strcpy配合,很好地避免了内存浪费的现象,目标地址需要有足够空间存放需要被复制的字符串的源地址(存储副本)。
如果通过new动态开辟的空间,如果通过赋值手段将其他地址引入,那么新开辟的那个空间的地址被修改成和被引入地址等同,这样失去了程序访问新手段内存的唯一途径。(失去了new用法的重要目的)。
#include
#include
using namespace std;
int main() {
using namespace std;
char animal[20] = "bear"; // animal holds bear
const char *bird = "wren"; //birds holds address of string
cout << animal << " and "; //display bear
cout << bird << "\n";
cout << "Enter a kind of animal : ";
cin >> animal; // ok if input < 20 chars ,update the content of the array animal
//if ps is uninitialized,"cout << ps" will may display garbage or cause a crash
char *ps;
ps = animal; // set ps tp point to string
cout << "ps : " << ps << endl;
cout << "Before using strcpy()" << endl;
cout << "address of ps :" << (int *) ps << endl;
ps = new char[strlen(animal) + 1];
cout << "After using strcpy()" << endl;
strcpy(ps, animal);
cout << "address of ps :" << (int *) ps << endl;
return 0;
}

要确定目标空间有足够的空间来存储副本。
4.8.3 使用new创建动态结构
对于在指定结构成员时,句点运算符和箭头运算符的选择时:
- 如果结构标识符是
结构名,则使用句点运算符(.)。
- 如果标识符是
指向结构的指针,则使用箭头运算符(->)。
把new用于结构的两个步骤
-
创建结构
要创建结构,需要同时使用结构类型和new。
-
创建访问其成员。
4.8.4 C++管理数据内存的方式
-
自动存储 在函数内部定义的常规变量使用自动存储空间,称为自动变量。
只在特定函数被执行时存在。
自动变量时一个局部变量,作用域为包含它的代码块。通常存储在栈中,遵循后进先出(LIFO)。
-
静态存储
- 变量称为静态的方式
- 在函数外面定义
- 在声明变量时使用关键字static。
整个程序执行期间都存在的存储方式(存在于程序的整个生命周期)。
-
动态存储 内存池(自由存储空间或堆)用于静态变量和自动变量,且内存是分开的。
-
线程存储(C++11特性)
4.9. 数组替代品 — 模板类
#include
struct antarctica_years_end {
int year;
};
int main() {
antarctica_years_end s01, s02, s03;
s01.year = 1998;
antarctica_years_end * pa = &s02;
pa->year = 1999;
antarctica_years_end trio[3];
trio[0].year = 2003;
std::cout << trio->year << std::endl;//数组名为第一个元素地址
const antarctica_years_end* arp[3] = {&s01,&s02,&s03};
std::cout << arp[1]->year << std::endl;
//双指针,作为结构体指针的*ppa指向arp的地址(用运算符);(*(*ppa))是对(*ppa)解引用为结构体对象
const antarctica_years_end (*(*ppa)) = arp;
auto ppb = arp;
std::cout << (*(*ppa)).year << std::endl;
std::cout << (*(ppb+1))->year << std::endl;
return 0;
}
模板类vector和array是数组的替代品。
4.9.1 模板类vector
模板类vector类似于string类,也是一种动态数组。
vector对象包含在vector头文件中。- vector包含在名称空间std中,使用
using编译指令、using声明或std::vector。
- 模板使用不同的
语法来指出它存储的数据类型。
- vector类使用不用的语法来指定
元素数。
4.9.2 模板类array(C++11)
位于名称空间std中,与数组一样,array对象的长度固定,也使用栈(静态内存分配),而不是自由存储区。
头文件 array。
4.9.3 数组、vector和array的区别
无论是数组、vector对象还是array对象,都可使用标准数组表示法来访问各个元素。
从地址可知,array对象和数组存储在相同的内存区域(即栈)中,vector对象存储在自由存储区域或堆中。
可以将一个array对象赋给另一个array对象,对于数组,必须逐个元素复制数据。
第五章 循环和关系表达式
5.1. for循环
for循环为执行重复的操作提供了循序渐进的过程。
for循环是入口条件(entry-condition)循环。
5.1.1 for循环的组成部分
- 设置变量初始化
- 执行测试,查看循环是否继续进行。
- 执行循环操作
- 不断更新测试的值
5.1.2 for循环的通用格式
statement01
for (initialization;test-expression;update-expression)
statement01;
statement03;
说明:test_expression 决定了程序是否执行, 这里的表达式也就是所谓的关系表达式,即两个数进行比较。
结构示意图:
C++中常用的方式:在for和括号之间加上一个空格,而省略函数名与括号之间的空格。
for(int i = 6;i<=12;i++);
printf("i = %d\n",i);
5.1.3 递增运算符(++)和递减运算符(--)
-
递增/递减:增加/减少一个单位
-
前缀和后缀的区别
- 前缀递增/递减:表示
操作符(++/--)位于变量或表达式的前面。
先执行运算,再生成值。
- 后缀递增/递减:表示
操作符(++/--)位于变量或表达式的后面。
先生成值,在执行运算。
将递增 / 递减运算符用于指针时,把指针增加/减少其指向的数据类型占用的字节数。
double arr[5] = {2.3,7.5,3.7,6.5,7.8};
double *pt = arr;
++pt;
前缀递增、前缀递减和解除引用运算符的优先级相同,从右往左的方式进行结合。
vector vec {1,2,3,4,5};
int *p = &vec[0];
//将p指向的地址加1(其实是加上数据类型的大小)
//再解除引用,自右向左。 故下面*++p输出值为2
cout << *++p << endl;
int *q = &vec[0]
cout << ++*q << endl;//先对p解除引用,再+1,故 ++*q = vec[0] + 1;
后缀递增和后缀递减的优先级相同,但是比前缀运算符(或者说比解除引用运算符)的优先级高,从左往右的方式进行结合。
vector vec{1,2,3,4,5,6};
int *p = &vec[0];
cout << *p++ << endl;//输出为1
cout << *p << endl;//输出为2
// *p++输出的语句为1,而后面*p输出的语句是2呢?
// 因为后缀++的运算符优先级比解引用运算符优先级要高,所以++不是对*p进行操作
// 而是对p进行操作,原本的p指向的是vec[0]的地址,在p加1后,p的指向为vec[1]
// 所以后面*p的值解引用得到的值是vec[1]
问:i++ 和 ++i 哪个效率高?
i++是先用临时对象保存原来的对象,然后对原对象自增,再返回临时对象,不能作为左值;++i是直接对于原对象进行自增,然后返回原对象的引用,可以作为左值。
由于要生成临时对象,i++需要调用两次拷贝构造函数与析构函数(将原对象赋给临时对象一次,临时对象以值传递方式返回一次);但是通过编译器的优化,生成临时对象对应的拷贝构造函数和析构函数被优化了。
++i由于不用生成临时变量,且以引用方式返回,故没有构造与析构的开销,效率更高。
所以在使用类等自定义类型的时候,应尽量使用++i。
#include
using namespace std;
class increment {
int x_;
int y_;
public:
increment(int x = 0, int y = 0);
increment(const increment&);
~increment();
increment& operator++();//前置
const increment operator++(int);//后置
void Displayincrement();
};
increment& increment::operator++()//前置
{
++x_;
++y_;
return *this;
}
const increment increment::operator++(int)//重载--后置
{
increment temp(*this);//【将原对象赋给临时对象】,临时对象以值传递返回
this->x_++;
this->y_++;
return temp;
}
increment::increment(int x, int y)//有参构造函数
{
x_ = x;
y_ = y;
cout << "this is constructor" << endl;
}
increment::increment(const increment& b)//拷贝构造函数
{
this->x_ = b.x_;
this->y_ = b.y_;
cout << "this is copy constructor" << endl;
}
increment::~increment()//析构函数
{
cout << "this is destructor" << endl;
}
void increment::Displayincrement()
{
cout << "x: " << this->x_ << endl;
cout << "y: " << this->y_ << endl;
}
int main()
{
increment i(1, 1);
cout << endl << "this is i++: " << endl;
i.Displayincrement();
i++;
i.Displayincrement();
cout << endl << "this is ++i: " << endl;
++i;
i.Displayincrement();
return 0;
}

5.1.4 组合复制运算符
就是合并了算术运算符和赋值操作的运算符。
操作符
作用(L为左操作数,R为右操作数)
+=
将L+R赋给L
-=
将L-R赋给L
*=
将L*R赋给L
/=
将L/R赋给L
%=
将L%R赋给L
5.1.5 关系表达式

⚠️注意:等于运算符(==)和赋值运算符(=)两者不要混淆。
比较两个量是否相等时,而要使用 ==。
5.1.6 C-风格的字符串
数组名是数组的地址。用引号括起来的字符串常量也是其地址。
C-风格字符串库中的strcmp()函数来比较,函数接收两个字符串地址作为参数(参数可以是指针、字符串常量或字符数组名)。
如果字符串相同,函数返回 0;
如果第一个字符串按字母顺序排在第二个字符串之前,则strcmp()函数返回一个负值。
如果第一个字符串按字母顺序排在第二个字符串之后,则strcmp()函数返回一个正值。
注释:比较得出正负值不看长度,只看同一位置的字母顺序,str1 同一位置的字符顺序高过 str2 即判断为正值,反过来为负值。
5.2. while循环
while循环是没有初始化 和 更新部分 的for循环。只有测试条件 和 循环体。
while循环的语法格式
while(test-condition)
loop-body
5.2.1 while循环的结构图
⚠️注意:在设计循环时,请记住下面几条指导原则
- 指定循环终止的条件
- 在首次测试之前初始化条件
- 在条件被再次测试之前更新条件
for循环有个优点是,其结构提供了一个可实现上述3条指导原则的地方,因此有助于程序员记得这样做
-
小错误:
-
//1、由于没有花括号,语句的循环体
int i = 0;
while(name[i] != '\0')
cout << name << endl;
i++
cout << "Done\n";
//2、多加分号
int i = 0;
while(name[i] != '\0');
{
cout << name[i] << endl;
i++;
}
cout << "Done\n";
5.2.2 等待一段时间;编写延时循环
有时候,让程序等待一段时间是很有用的,就比如,ide打印出来程序的结果显示得太快了,来不及阅读。
原始的方法是:让计算机进行计算;例如
long wait = 0;
while (wait < 10000){
wait++; // counting silently
}
但C++中有一个函数有助于完成这样的工作,函数名为clock();
clock()返回的时间的单位为秒(或者系统里面的时间单位);它的计算方式为:**系统时间/CLOCKS_PER_SEC(每秒钟包含的系统时间单位数)= 秒 ** ,编译器将它转换为long、unsigned int 或适合系统的其他类型。
ctime 将 clock_t 作为clock() 返回类型的别名,这意味着可以将变量声明为clock_t 类型
#include
using namespace std;
int main(){
cout << "Enter the delay time,in seconds:";
float secs;
cin >> secs;
clock_t delay = secs * CLOCKS_PER_SEC;
cout << "starting\a\n";
clock_t start = clock();//记录当前的时间戳
while (clock() - start < delay){
;
}
cout << "done\a\n";
return 0;
}
5.3. do while循环
do while循环语法体
do{
}while(test-expression)
结构图:
入口条件循环比出口条件循环好,因为入口条件循环在循环开始之前就检查了
5.4.基于范围的for循环(C++11)
double prices[5] = {4.99,5.99,6.99,7.99,8.99};
for(double x : prices){
cout << x << endl;
}
//&x 表示引用同一个prices数组,使得修改同一个数组
for(double &x : prices){
x = x * 0.8;
}
5.5. 循环与文本输入
5.5.1 使用原始的cin进行输入
如果要程序使用循环来读取来自键盘的文本输入,则必须明确循环条件,一种方法是设置哨兵字符。
#include
using namespace std;
int main() {
char ch;
int count = 0;
cout << "Enter characters;enter # to quit:\n";
cin.get(ch);
while (ch != '#') {
cout << ch;
++count;
cin.get(ch);
}
cout << endl << count << "characters read\n";
return 0;
}

出现以上的情况是因为:cin忽略空格和换行符。因此输入中的空格没有被回显。重要的是:发送给cin的输入被缓冲,需要用户按下回车键才能显示出来。
5.5.2 对5.5.1 进行改进
#include
using namespace std;
int main() {
char ch;
int count = 0;
cout << "Enter characters;enter # to quit:\n";
cin.get(ch);
while (ch != '#') {
cout << ch;
++count;
cin.get(ch);
}
cout << endl << count << "characters read\n";
return 0;
}
此次改进后,回显正确,计算的字符数也包括了空格。输入仍被缓冲,❗️❗️字符数仍可能比最终到达程序的要多 (大概是这个意思:#dsjkfhs,后面的字符便不作数了)
❗️❗️C语言中,可能认为这个是个严重的错误。因为把cin.get(ch)的get(ch)当作一个函数,ch是一个变量形参,传进去无法改变变量的值,需要传地址进去。
5.5.4 文件尾条件
//命令行
gofish < fishtale(文本文件)
“<” 符号 Unix和Windows命令提示符模式的重定向运算符
很多操作系统都允许通过键盘来模拟文件尾条件。在unix中,可以在行首按下control + D 来实现
mac连续按两下才是EOF结束符,按一下的效果跟按回车一样,
如果编程环境能够检测EOF,可以类似于上面的程序模拟EOF,也可以使用重定向文件
检测到EOF后,cin将两位(eofbit 和 failbit)都设置为1。cin.eof(){cin.fali()}来查看eofbit{failbit}是否被设置,如果检测到EOF,则成员函数返回true,否则返回false;通常用得比较多的是fail()。cin作为while循环的判断语句,比cin的两个成员函数(!cin.fail() / !cin.eof())都通用,因为它可以检测磁盘故障等。
#include
using namespace std;
int main(){
char ch;
int count = 0;
cin.get(ch);
while (cin.fail() == false){
cout << ch;
++count;
cin.get(ch);
}
cout << endl << count << " characters read\n";
return 0;
}

5.5.5 另一个cin.get()版本
C语言中的getchar()还有putchar();
不接受任何参数的cin.get()成员函数返回输入中的下一个字符。也就是说,可以选择这样用它:
EOF 与常规字符混淆,经常定义为-1,因为没有ASCII码为-1的字符,但并不需要知道实际的值。
int ch;
cin.get(ch);
while (ch != EOF) //test for EOF
{
cout << ch;
++count;
cin.get(ch);
}
char ch;
cin.get(ch);
while(cin.fail() == false)
{
cout << ch;
++count;
cin.get(ch);
}
❗️❗️cin.get() 与cin.get(char)

第六章 分支语句和逻辑运算符
6.1 if 语句
if语句的语法和while相似:
if (test-condition){
statement
}
如果test-conditon(测试条件)为true,则程序将执行statement(语句),后者既可以是一条语句,也可以是语句块,如果为false,程序则跳过语句。
#include
int main(){
using std::cin; //using declarations
using std::cout;
char ch;
int spaces = 0;
int total = 0;
cin.get(ch);
while (ch!='.'){
if (ch == ' '){
++spaces;
}
++total;
cin.get(ch);
}
cout << spaces << " spaces," << total;
cout << " characters total in sentence\n";
return 0;
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-90jNkykj-1663659624890)(/Users/mac/Library/Application Support/typora-user-images/image-20220820130751151.png)]
6.1.1 if else语句
“If you have a Captain Cookie card,you get a Cookie Plus Plus,else you just get a Cookie Ordinaire”
if else 语句通用格式
if(test-condition){
statement1
}
else{
statement2
}
解释:如果测试条件为真,则执行statement1,否则跳过statement1,执行statement2.
#include
int main(){
char ch;
std::cout << "Type,and I shall repeat.\n";
std::cin.get(ch);
while (ch!='.'){
if (ch == '\n'){
std::cout << ch; //如果字符遇到了换行符,直接换行
}
else{
std::cout << ++ch; //输出当前字符的下一个字符
}
std::cin.get(ch);
}
std::cout << "\nPlease excuse the slight confusion.\n";
return 0;
}

6.1.2 格式化if else 语句
//第一种
if (ch == 'Z')
{
zorro++;
cout << "Another Zorro candidate\n";
}
else
{
dull++;
cout << "Not a Zorro candidate\n";
}
//第二种
if (ch == 'Z'){
zorro++;
cout << "Another Zorrro candidate\n";
}
else{
dull++;
cout << "Not a Zorro candidate\n";
}
第一种格式强调的是语句的块结构,第二种格式则将语句块与关键字紧密地结合起来
6.1.3 if else if else语句
顾名思义就是if或者else下再嵌入if-else语句,下面弄一个demo
#include
const int Fave = 27;
int main(){
int n;
std::cout << "Enter a number in the range 1-100 to find";
std::cout << "my favorite number:";
do {
std::cin >> n;
if (n < Fave){
std::cout << "Too low -- guess again:";
}
else if (n > Fave){
std::cout << "Too high -- guess again:";
}
else{
std::cout << "GUESS!";
}
} while (n!=Fave);
return 0;
}

6.2 逻辑表达式
6.2.1 逻辑OR运算符:||

#include
int main(){
using namespace std;
cout << "This program may reformat your hard disk\n"
"and destroy all your data.\n"
"Do you wish to continue?";
char ch;
cin >> ch;
if (ch == 'y' || ch == 'Y'){
cout << "You were warned!\a\a\n";
}
else if (ch == 'n' || ch == 'N'){
cout << "A wise choice.......bye\n";
}
else{
cout << "That wasn't a y or n!Apparently you "
"can't follow\ninstructions,so "
"I'll trash your disk anyway.\a\a\a\n";
}
return 0;
}
6.2.2 逻辑AND运算符:&&

#include
const int ArSize = 6;
int main() {
using namespace std;
float naaq[ArSize];//存储6个邻居的NAAQ值
cout << "Enter the NAAQs (New Age Awareness Quotients) "
<< "of\n your neighbors.Program terminate "
<< "when you make\n" << ArSize << " entries "
<< "or enter a negativ value.\n";
int i = 0;
float temp;
cout << "First value : ";
cin >> temp;
while (i < ArSize && temp >= 0) {//个数与值(NAAQ值最小的是0,当负值便终止循环)
naaq[i] = temp;
++i;
if (i < ArSize) {
cout << "Next value:";
cin >> temp;
}
}
if (i == 0) {
cout << "No data--bye\n";
} else {
cout << "Enter your NAAQ:";
float you;
cin >> you;
int count = 0;
for (int j = 0; j < i; ++j) {
if (naaq[j] > you) {
++count;
}
}
cout << count;
cout << " of your neighbors have greater awareness of\n"
<< "the New Age than you do.\n";
}
return 0;
}
6.2.3 用&&来设置取值范围
if(age > 17 && age < 35) //okay
//不要使用数学符号表示:
//编译器不会捕获这种错误,因为它仍然是有效的C++语法。
if(17 < age < 35) //Don't do this
//上面的表达式可以等同于
if ((17 < age) < 35)
//17 < age 无非两个值 1、true(1),2、false(0),不管哪种情况,表达式的值均为true
6.2.5 逻辑运算符细节
C++ 逻辑or和逻辑and运算符的优先级都低于关系运算符。这意味着:
x > 5 && x < 10 —> (x > 5) && (x < 10)
另一方面:!运算法的优先级高于所有的关系运算符和算术运算符。对某个事物去反,需要添加括号
例如:
!(x > 5) // is it false that x is greater than 5
!x > 5 // is !x greater than 5
//⚠️:第二个表达式一直为false,因为!x的值只能为true或者false,而他们将自动转化为1或者0
6.3 字符函数库cctype
这是C++非常方便的函数软件包,它可以简化诸如确定字符是否为大写字母、数字、标点符号等工作,这些函数的原型是在头文件cctype中定义的。
isalpha()检查字符是否为字母字符
issights()测试字符是否为数字字符
isspace()来测试字符是否为空白(如:换行符、空格、制表符)
ispunct()来测试字符是否为标点符号
#include
#include
int main() {
using namespace std;
cout << "Enter text for analysis, and type @"
"to terminate input.\n";
char ch;
int whitespace = 0;
int digits = 0;
int chars = 0;
int punct = 0;
int others = 0;
cin.get(ch); //get first character
while (ch != '@') {
if (isalpha(ch)) { // is it an alphabetic character?
chars++;
} else if (isspace(ch)) { //is it a whitespace character?
whitespace++;
} else if (isdigit(ch)) {
digits++;
} else if (ispunct(ch)) {
punct++;
} else {
others++;
}
cin.get(ch); //get next character
}
cout << chars << " letters, "
<< whitespace << " whitespace, "
<< digits << " digits, "
<< punct << " punctuations, "
<< others << " others,\n";
return 0;
}
函数名称
返回值
isalnum()
如果参数是字母数字,该函数返回true
isalpha()
如果参数是字母,该函数返回true
iscntrl()
如果参数是控制字符,该函数返回true
isdigit()
如果参数是数字(0-9),该函数返回true
isgraph()
如果参数是除空格之外的打印字符(能够显现出来的),该函数返回true
islower()
如果参数是小写字母,该函数返回true
isprint()
如果参数是打印字符(包括空格),该函数返回true
ispunct()
如果参数是标点符号,该函数返回true
isspace()
如果参数是标准空白字符,如空格、进制、换行符、回车等等,该函数返回true
isupper()
如果参数是大写字母,该函数返回true
isxdigit()
如果参数是十六进制数字,即0~9、a~f或者A~F,该函数返回true
tolower()
如果参数是大写字符,则返回其小写,否则返回该参数
toupper()
如果参数是小写字符,则返回其大写,否则返回该参数
6.4 ?:运算符
?:结构为: expression1 ? expression2 : expression3
如果expression1为true,则整个条件表达式的值为expression2的值;否则,整个表达式为expression3的值,下面为实例:
5 > 3 ? 10 : 12 // 5 > 3 is true,so expression value is 10
3 == 9 ? 25 : 18 // 3 == 9 is false,so expression value is 18
某些炫技:
const char x[2][20] = {"Jason " , "at your service\n"};
const char *y = "Quillstone ";
for(int i = 0;i < 3; i++){
cout << ((i < 2)? (!i ? x[i] : y) : x[i]);
//expression1 ? expression2 : expression3
}
上面的程序解释:
当i = 0时,i < 2 is true ,进入expression2,然而expression2里还是一个三目运算符,我们继续判断,!i is true,则输出x[0]的值–> Jason
当i = 1时,i < 2 is true ,进入expression2,!i is false,则输出*y的值–> Quillstone
当i = 2时,i < 2 is false,进入expression3,直接输出x[2]的值–>at your service
6.5 switch 语句
C++的switch语句能够更容易地从大型列表中进行选择,下面为switch通用的格式
switch (interger expression) {
case label1:statement(s)
case label2:statement(s)
.......
default : statement(s)
}
#include
using namespace std;
void showmenu(); //function prototypes
void report();
void comfort();
int main() {
showmenu();
int choice;
cin >> choice;
while (choice != 5){
switch (choice) {
case 1:
cout << "\a\n";
break;
case 2:
report();
break;
case 3:
cout << "The boss was in all day.\n";
break;
case 4:
comfort();
break;
default:
cout << "That's not a choice.\n";
}
showmenu();
cin >> choice;
}
cout << "Bye!\n";
return 0;
}
void showmenu(){
cout << "Please enter 1,2,3,4,or 5:\n"
"1)alarm 2)report\n"
"3)alibi 4)comfort\n"
"5)quit\n";
}
void report(){
cout << "It's been an excellent week for business.\n"
"Sales are up 120%. Expenses are down 35%.\n";
}
void comfort(){
cout << "Your emoloyee think you are the finest CEO\n"
"in the industry.The board of directors think\n"
"you are the finest CEO in the industry.\n";
}
6.5.1 将枚举量用作标签
#include
enum {
red, orange, yellow, green, blue, violet, indigo
};
int main(){
using namespace std;
cout << "Enter color code(0-6):";
int code;
cin >> code;
while (code >= red && code <= indigo){
switch (code) {
case red:
cout << "Her lips were red.\n";
break;
case orange:
cout << "Her hair was orange.\n";
break;
case yellow:
cout << "Her shoes were yellow.\n";
break;
case green:
cout << "Her nails were green.\n";
break;
case blue:
cout << "Her sweatsuit was blue.\n";
break;
case violet:
cout << "Her eyes were violet.\n";
break;
case indigo:
cout << "Her eyes were violet.\n";
break;
}
cout << "Enter color code(0~6):";
cin >> code;
}
6.6 break 和 continue
和C语言一样,C++也有goto语句。
char ch;
cin >> ch;
if (ch == 'p'){
goto paris;
}
cout << .....
.....
paris: cout << "You've just arrived at paris.\n";
⚠️:在大多数情况下,使用goto语句不好,应使用结构化控制语句(如:if else、switCh、Contiune)来控制程序流程
6.7 读取数字的循环
#include
using namespace std;
const int Max = 5;
int main() {
double fish[Max];
cout << "please enter the weights of your fish.\n";
cout << "You may enter up to " << Max
<< " fish .\n";
cout << "fish #1: ";
int i = 0;
//事实上,鱼要有重量才正确
//这里的顺序也比较正确,如果先判断输入的大小,又可能因为越界导致错误
while (i < Max && cin >> fish[i]) {
if (++i < Max) {
cout << "fish #" << i + 1 << ":";
}
}
double total = 0.0;
for (int j = 0; j < i; ++j) {
total += fish[j];
}
if (i == 0) {
cout << "No fish\n";
} else {
cout << total / i << " = average weight of " << i << " fish\n";
}
cout << "Done.\n";
return 0;
}
以上程序:当用户输入的不是数字时,该程序将不再读取输入。再者:非数字输入将cin设置为failbit,如果还想继续输入的话,需要将failbit重置,同时也需要重置文件尾eof
cin方法的调用将返回false
#include
using namespace std;
const int Max = 5;
int main() {
int golf[Max];
cout << "Please enter your golf scores.\n";
cout << "You must enter " << Max << " rounds.\n";
int i;
for (int j = 0; j < Max; ++j) {
cout << "round #" << j + 1 << ": ";
while (!(cin >> golf[j])) {
cin.clear(); // reset input
while (cin.get() != '\n') {
continue; //get rid of bad input
}
cout << "Please try again: ";
}
}
double total = 0.0;
for (int j = 0; j < Max; ++j) {
total += golf[j];
}
cout << total / Max << " = average score "
<< Max << " rounds\n";
return 0;
}
代码的关键部分为:
while (!(cin >> golf[j])) {
cin.clear(); // reset input
while (cin.get() != '\n') {
continue; //get rid of bad input
}
cout << "Please try again: ";
}
❗️❗️解释:如果用户先输入88,则cin表达式为true,因此将这个值放入数组中,而表达式!(cin>>golf[i])为false,因此内循环结束了。然后,如果用户输入must it?,则cin表达式为false,因此不会将任何值放到数组中,而表达式!(cin>>golf[i])为true,进入内循环,该循环第一句为clear()方法重置输入,防止后面阻碍输入。cin.get是一个字符一个字符的读取,如果读到了换行符,即可“删除”错误的整行字符。
6.8 简单文件的输入/输出
6.8.1 文本I/O和文本文件
使用cin进行输入,程序将输入视为一系列字节,其中每个字节都被解释为字符编码。不管目标数据类型是什么,输入一开始就是字符数据—文本数据。然后,cin对象负责将文本转换为其他类型。
6.8.2 写入到文本文件中
- 必须包含头文件fstream
- 头文件fstream定义了一个用于处理输出的ofstream类
- 需声明一个或者多个ofstream变量,并以自己喜欢的方式进行命名
- 必须之名名称空间std;
- 需要将ofstream对象与文件关联起来,为此,方法之一是使用open()方法
- 使用完文件后,应使用方法close()将其关闭
- 可以使用ofstream对象和运算符<<输出各种类型的数据
- 重要的是:声明一个ofstream对象并将其同文件关联起来后,便可以像使用cout那样使用它。所有可以用cout的操作和方法(如<<、endl和setf()) 都可以用于ofstream对象(如:下面示例outFile和fout)
下面演示如何声明这种对象:
ofstream outFile; //outFile an ofstream object
ofstream fout; //fout an ofstream object
下面演示了如何将这种对象与特定的文件关联起来:
outFile.open("fish.txt"); //outFile used to write to the fish.txt file
char fileName[50];
cin >> fileName; //user specifies a name
fout.open(fileName); //fout used to read specified file
❗️❗️注意:方法open()接受一个C风格字符串作为参数,这可以是一个字面字符串,也可以存储在数组中的字符串。
使用文件输出的主要步骤如下:
- 包含头文件fstream。
- 创建一个ofstream对象.
- 将该ofstream对象同一个文件关联起来
- 就像使用cout那样使用该ofstream对象
程序示例:
#include
#include
using namespace std;
int main(){
char automobile[50];
int year;
double a_price;
double b_price;
ofstream outFile;
outFile.open("carinfo.txt");
cout << "Enter the make and model of automobile: ";
cin.getline(automobile,50);
cout << "Enter the model year: ";
cin >> year;
cout << "Enter the original asking price: ";
cin >> a_price;
b_price = 0.913 * a_price;
// display information on screen with cout
cout << fixed;
cout.precision(2);
cout.setf(ios_base::showpoint);
cout << "Make and model: " << automobile << endl;
cout << "Year:" << year << endl;
cout << "Was asking $" << a_price << endl;
cout << "Now asking $" << b_price << endl;
// display information on screen with outFile instead of cout
outFile << fixed;
outFile.precision(2);
outFile.setf(ios_base::showpoint);
outFile << "Make and model:" << automobile << endl;
outFile << "Year:" << year << endl;
outFile << "Was asking $" << a_price << endl;
outFile << "Now asking $" << b_price << endl;
outFile.close();
return 0;
}
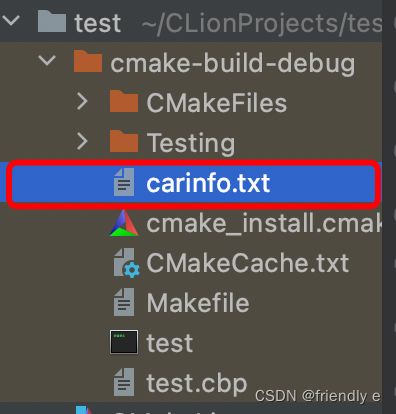

正如读者看到的,outFile将cout显示到屏幕上的内容写入到了carinfo.txt文件中
❗️❗️程序中一些知识点补充❗️❗️
cout<
cout.precision(val)—>val:小数点后保留val位
cout.setf(ios_base::showpoint)—>强制显示浮点数小数点后的0
⚠️打开已有的文件,以接受输出时,默认将其长度截断为0,因此原来的内容丢失。
如果系统中未有此文件,会自动创建这个文件
6.8.3 读取文本文件
主要步骤
- 必须包含头文件fstream
- 头文件fstream定义了一个用于处理输入的ifstream类
- 需要声明一个或者多个ifstream变量(对象),并以自己喜欢的方式对其进行命名
- 必须指明名称空间std
- 需要将ifstream对象与文件关联起来
- 使用完文件后,应使用close将其关闭
- 可结合使用ifstream对象和运算符>>来读取各种类型的数据
- 可以使用ifstream和get()方法来读取一个字符,使用ifstream对象和getline()来读取一行字符。
- 可以结合使用ifstream和eof()、fail()等方法来判断是否成功
- ifstream对象本身被用作测试条件时,如果最后一个读取操作成功,它将被转换为bool值true,否则为false
下面演示如何声明此类对象:
ifstream inFile; //inFile an ifstream object
ifstream fin; //fin an ifstream object
下面演示了如何将这种对象与特定的文件关联起来:
inFile.open("bowling.txt"); //inFile used to read bowling
char fileName[50];
cin >> fileName; //user specifies a name
fin.open(fileName); //fin used to read specified file
检查文件是否被成功打开的首先方法是使用方法is_open(),成功则返回true,否则就返回false
inFile.open("bowling.txt");
if (!inFile.is_open()){
exit(EXIT_FAILURE);
}
函数exit()的原型是在头文件cstdlib中定义的,在该头文件中,还定义了用于操作系统通信的参数值EXIT_FAILURE/函数exit()终止程序。
❗️❗️is_open()是C++比较新的内容,如果读者的编译器不支持的话,可以使用较老的方法good()
程序模拟
#include
#include
#include
const int SIZE = 60;
int main() {
using namespace std;
char filename[SIZE];
ifstream inFile;
cout << "Enter name of data file: ";
cin.getline(filename, SIZE);
inFile.open(filename);
if (!inFile.is_open()) {
cout << "Could not open the file " << filename << endl;
cout << "Program terminating.\n";
exit(EXIT_FAILURE);
}
double value;
double sum = 0.0;
int count = 0;
inFile >> value;
while (inFile.good()) // input good and not at EOF
{
inFile >> value;
++count;
sum += value;
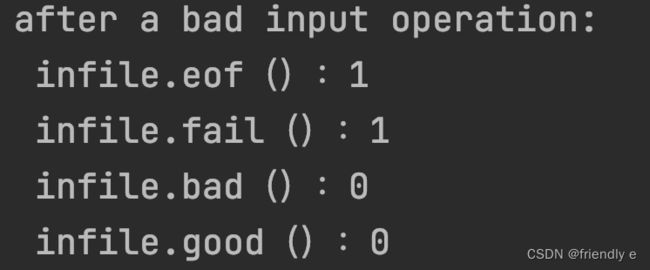
cout << "after a bad input operation:"
<< "\n infile.eof():" << inFile.eof()
<< "\n infile.fail():" << inFile.fail()
<< "\n infile.bad():" << inFile.bad()
<< "\n infile.good():" << inFile.good() << endl;
}
if (inFile.eof())
cout << "End of file reached.\n";
else if (inFile.fail())
cout << "Input terminated by data mismatch.\n";
else
cout << "Input terminated for unknown reason.\n";
if (count == 0)
cout << "No data processed.\n";
else {
cout << "Items read: " << count << endl;
cout << "Sum: " << sum << endl;
cout << "Average: " << sum / count << endl;
}
inFile.close();
return 0;
}
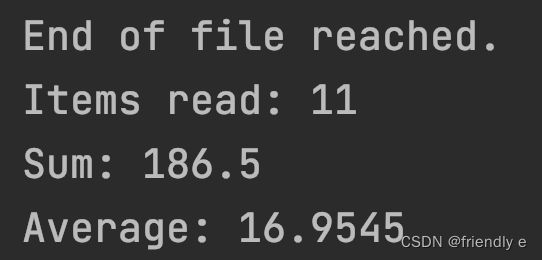
❗️12个数字,程序只数到11个数字
cout << "after a bad input operation:"
<< "\n infile.eof():" << inFile.eof()
<< "\n infile.fail():" << inFile.fail()
<< "\n infile.bad():" << inFile.bad()
<< "\n infile.good():" << inFile.good() << endl;
通过以上的程序排查,发现while循环第11次的时候,good()被置位为0,eof()被置位为1,不符合常理,然后发现:
inFile >> value;
while (inFile.good()) // input good and not at EOF
{
++count;
sum += value;
inFile >> value;
cout << "after a bad input operation:"
<< "\n infile.eof():" << inFile.eof()
<< "\n infile.fail():" << inFile.fail()
<< "\n infile.bad():" << inFile.bad()
<< "\n infile.good():" << inFile.good() << endl;
}
infile在一开始被置位为1,第一行的inFile >> value 先读取了第一个字符串,然后再进入循环,所以循环到11次的时候,相当于读到了最后一个字符,此时遇到了eof,inFile.good()被置为0,eof被置位1,条件不满足第12次循环,虽然读到了第12个数,但是进不了循环,就点不到了
更改:
while (inFile.good()) // input good and not at EOF
{
inFile >> value;
++count;
sum += value;
cout << "after a bad input operation:"
<< "\n infile.eof():" << inFile.eof()
<< "\n infile.fail():" << inFile.fail()
<< "\n infile.bad():" << inFile.bad()
<< "\n infile.good():" << inFile.good() << endl;
}
本来inFile.good()刚开始就被设置为1,直接进入循环才开始读取即可
第二种改法:
#include
#include
#include
const int SIZE = 60;
int main() {
using namespace std;
char filename[SIZE];
ifstream inFile;
cout << "Enter name of data file: ";
cin.getline(filename, SIZE);
inFile.open(filename);
if (!inFile.is_open()) {
cout << "Could not open the file " << filename << endl;
cout << "Program terminating.\n";
exit(EXIT_FAILURE);
}
double value;
double sum = 0.0;
int count = 0;
inFile >> value;
while (inFile) // input good and not at EOF
{
++count;
sum += value;
inFile >> value;
cout << "after a bad input operation:"
<< "\n infile.eof():" << inFile.eof()
<< "\n infile.fail():" << inFile.fail()
<< "\n infile.bad():" << inFile.bad()
<< "\n infile.good():" << inFile.good() << endl;
}
if (inFile.eof())
cout << "End of file reached.\n";
else if (inFile.fail())
cout << "Input terminated by data mismatch.\n";
else
cout << "Input terminated for unknown reason.\n";
if (count == 0)
cout << "No data processed.\n";
else {
cout << "Items read: " << count << endl;
cout << "Sum: " << sum << endl;
cout << "Average: " << sum / count << endl;
}
inFile.close();
return 0;
}
inFile 相当于 !inFile.fail(), failbit 表示发生可恢复的错误,如期望读取一个数值,却读出一个字符等错误。这种问题通常是可以修改的,流还可以继续使用。
一般到达末尾时,eof = fail = 1
第七章 函数—C++的编程模块
7.1 复习函数的基本知识
要使用C++函数,必须完成如下工作:
- 提供函数定义
- 提供函数原型
- 调用函数
#include
using namespace std;
void simple(); // function prototype
int main(){
cout << "main() will call the simple() function:\n";
simple(); //function call
cout << "main() is finished the simple() function:\n";
return 0;
}
//function definition
void simple(){
cout << "I'm but a simple funtion:\n";
}
解释:执行函数simple()时,将暂停执行main()中的代码:等函数simple()执行完毕后,继续执行main()中的代码。
7.1.1 定义函数
可以分为:没有返回值的函数和有返回值的函数,
没有返回值函数的通用格式为:
void functionName(parameterList){
statement(s);
return;
}
实际例子:
void cheers(int n ){ //no value returned
for(int i = 0;i < n ; i++){
std::cout<< "Cheers != ";
}
std::cout << std::endl;
}
有返回值函数的通用格式为:
typeName functionName(parameterList){
statements;
return value; //value is type cast to type typeName
}
有返回值的函数可以返回结构和对象,例如:
#include
class Point{
public:
int x;
int y;
};
Point print(){
Point p;
p.x =1;
printf("%p\n",p);
printf("%d %d\n",p.x,p.y);
return p;
}
int main(int argc, const char * argv[]) {
Point p=print();
printf("%d %d\n",p.x,p.y);
}
❗️❗️如果声明的返回类型为douBle,而函数返回一个int表达式,则该int值将被强制转换为douBle类型。
7.1.2 函数原型和函数调用
#include
using namespace std;
void cheers(int); //prototype:no return value
double cube(double x); //prototype:returns a double
int main() {
cheers(5); //function call
cout << "Give me a number:";
double side;
cin >> side;
double volume = cube(side);
cout << "A " << side << " foot cube has a volume of ";
cout << volume << " cubic feet:\n";
cheers(cube(2)); //prototype protection at work
return 0;
}
void cheers(int n) {
for (int i = 0; i < n; ++i) {
cout << "cheers! ";
}
cout << endl;
}
double cube(double x) {
return x * x * x;
}
1. 为什么需要原型
原型描述了函数到编译器的接口,也就是它将函数的返回值类型以及参数类型告诉编译器。(返回值在不调用main函数的时候,可能存放在CPU寄存器,或者内存中。)
2. 原型的语法
函数原型是一条语句,必须以分号结束。格式:函数定义中的函数头+“;”。
3. 原型功能
原型可以确保以下几点:
- 编译器正确处理函数返回值
- 编译器检查使用的参数数目是否正确
- 编译器检查使用的参数类型是否正确,如果不正确,则转换为正确的类型
在编译阶段进行的原型化被称为静态类型检查,它可以捕获许多运行阶段非常难以捕获的错误
7.2 函数参数和按值传递
double volume = cube(side);
其中,side是一个变量,cube()的函数头:double cube(double x);
cube被调用的时候,会创建一个新的名为x的double变量,并将其初始化为5,cube()执行的操作不会影响main()中的数据,因为cube()使用的是side的副本,而不是原本定义好的变量。

7.2.1 多个参数
大体形式如下:
void n_chars(char c,int n) //two arguments
该函数头指出,函数n_chars()接受一个char参数和一个int参数。传递给函数的值被赋给c和n.和一个参数的情况一样,原型中的变量名不必与定义中的变量名相同,而且可以省略变量名
#include
using namespace std;
void n_chars(char, int);
int main() {
int times;
char ch;
cout << "Enter a character:";
cin >> ch;
while (ch != 'q') {
cout << "Enter an integer:";
cin >> times;
n_chars(ch, times); //function with two arguments
cout << "\nEnter another character or press the"
" q-key to quit:";
cin >> ch;
}
cout << "The value of times is " << times << ".\n";
cout << "Bye\n";
return 0;
}
void n_chars(char c, int n) {
while (n-- > 0){
cout << c;
}
}
7.2.2 另外一个接受两个参数的函数
创建一个功能更加强大的函数,该函数将演示局部变量的用法,而不是形参的用法
题目:从51个数字中选取6个,随后,彩票管理者将随机抽取6个数字。我们通过创建相应的函数来计算中奖的几率

#include
using namespace std;
double probability(unsigned numbers, unsigned picked);
int main() {
double total, choices;
cout << "Enter the total number of choices on the game card and\n"
"the number of picked allowed:\n";
while ((cin >> total >> choices) && choices <= total) {
cout << "You have one choice in ";
cout << probability(total, choices);
cout << " of winning.\n";
cout << "Next two numbers(q to quit):";
}
cout << "Bye!\n";
return 0;
}
double probability(unsigned numbers, unsigned picked) {
double result = 1.0;
double n;
unsigned p;
for (n = numbers, p = picked; p > 0; p--, n--) {
result = result * (n/p);
}
return result;
}
probability()函数使用了两种局部变量—形参与其他局部变量,他们的区别是—》形参从调用probability()的函数那里获得自己的值,而其他变量是从函数内获得自己的值。
7.3 函数和数组
这节新的内容是:需要将形参声明为数组名,下面是一个例子:
int sum_arr(int arr[],int n);//arr = array name.n = size
arr[]中的[]表明,可以将任何长度的数组传递给该函数,但实际情况并非如此,arr实际上并不是数组,而是一个指针。
#include
const int ArSize = 8;
int sum_arr(int arr[], int n);
int main() {
using namespace std;
int cookies[ArSize] = {1, 2, 4, 8, 16, 32, 64, 128};
int sum = sum_arr(cookies, ArSize);
cout << "Total cookies eaten:" << sum << "\n";
return 0;
}
int sum_arr(int arr[], int n) {
int total = 0;
for (int i = 0; i < n; ++i) {
total = total + arr[i];
}
return total;
}
7.3.1 函数如何使用指针来处理数组
第四章介绍,C++将数组名解释为其第一个元素的地址。
cookies == &cookies[0] //array name is address of first element
数组表示法:int arr[] 提醒用户,arr不仅指向int,还指向int数组的第一个int。
指针表示法:int *arr,提醒用户,指针指向一个独立的值。
arr[i] == *(ar + i) //value in two notations
&arr[i] == arr + i //addresses in two notations
❗️❗️,将指针(数组名)加1,实际上是加上了一个与指针指向的类型和长度(以字节为单位)相等的值。
7.3.2 将数组作为参数意味着什么
传递常规变量时候,函数将使用该变量的拷贝;传递数组时候,函数将使用原来的数组。
将数组地址作为参数可以节省复制整个数组所需的时间和内存。如果数组很大,则使用拷贝的系统开销将非常大:程序不仅需要更多的计算机内存,还需要花费时间来复制大块的数据;加之,使用原始数据增加了破坏数据的风险。
#include
const int ArSize = 8;
int sum_arr(int arr[], int n);
int main() {
int cookies[ArSize] = {1, 2, 4, 8, 16, 32, 64, 128};
std::cout << cookies << " = array address,";
std::cout << sizeof(cookies) << " = sizeof cookies\n";
int sum = sum_arr(cookies,ArSize);
std::cout << "Total cookies eaten: " << sum << std::endl;
sum = sum_arr(cookies+4,4);
std::cout << "Last four eaters ate " << sum << " cookies.\n";
return 0;
}
int sum_arr(int arr[],int n){
int total = 0;
std::cout << arr << " = arr, ";
std::cout << sizeof(arr) << " = sizeof arr\n";
for (int i = 0; i < n; ++i) {
total = total + arr[i];
}
return total;
}
⚠️:地址值和数组的长度随系统而异。另外,有些c++实现以十进制而不是十六进制格式显示地址,还有些编译器以十六进制显示地址时,会加上前缀0x
❗️❗️cookies和arr都指向了同一个地址,但是我们需要知道的是:sizeof arr只是指针变量的长度(64位系统为8字节,32位系统为4字节)。加之,指针本身并没有指出数组的长度,这就要求我们要显式传递数组的长度,而不能传递sizeof(arr).
现在我们来搞一个房地产数组,分两步走:
- 填充数组
- 显示数组及用const保护数组(const 避免显示函数破坏原始数组)
- 修改数组(此时不需要const来保护数组)
#include
using namespace std;
const int Max = 5;
int fill_array(double ar[], int limit);
void show_array(const double ar[], int n); //don't change data
void revalue(double r, double ar[], int n);
int main() {
using namespace std;
double propertites[Max];
int size = fill_array(propertites, Max);
cin.get();
show_array(propertites, size);
if (size > 0) {
cout << "Enter revaluation factor:";
double factor;
while (!(cin >> factor)) { //bad input
cin.clear(); //重置cin的状态
while (cin.get() != '\n') {
continue;
}
cout << "Bad input,Please enter a number:";
}
revalue(factor, propertites, size);
show_array(propertites, size);
}
cout << "Done.\n";
cin.get();
return 0;
}
int fill_array(double ar[], int limit) { //传入所要填充的数组
using namespace std;
double temp;
int j;
for (j = 0; j < limit; ++j) {
cout << "Enter value #" << (j + 1) << ": ";
cin >> temp;
if (!cin) { //bad input
cin.clear();//重置badbit or failbit
while (cin.get() != '\n') {
continue;
}
cout << "Bad input; input process terminated.\n";
break;
} else if (temp < 0) {//signal to terminate
break;
}
ar[j] = temp;
}
return j;
}
void show_array(const double ar[], int n) { //展示数组
using namespace std;
for (int i = 0; i < n; ++i) {
cout << "Property #" << (i + 1) << ":$";
cout << ar[i] << endl;
}
}
void revalue (double r, double ar[], int n) { //修改数组
for (int i = 0; i < n; ++i) {
ar[i] = ar[i] * r;
}
}
4. 数组处理函数的常用编写方式
//假设要编写一个处理double数组的函数,数组如果需要修改的话:
void f_modify(double ar[], int n);
//如果不需要修改数组,其原型可能类似于下面这样:
void _f_no_change(const double ar[],int n);
7.3.4 使用数组区间的函数
对于处理数组的C++函数,必须将数组中的数组种类、数组的起始位置和数组中的数量提交给他;传统的c/c++方法是,将指向数组起始处的指针作为一个参数,将数组长度作为第二个参数。
以上的方法是较为传统的。现在我们来看一下另外一种方法,即指定元素区间,这可以通过传递两个指针来完成:一个指针标识数组的开头,另一个指针标识数组的尾部。STL一般采用“超尾(指的是指针标识数组的尾部的下一个位置)”
#include
using namespace std;
const int ArSize = 8;
int sum_arr(const int *begin, const int *end);
int main() {
int cookies[ArSize] = {1, 2, 4, 8, 16, 32, 64, 128};
int sum = sum_arr(cookies, cookies + ArSize);
cout << "Total cookies eaten: " << sum << endl;
sum = sum_arr(cookies, cookies + 3); //first 3 elements
cout << "First three eaters ate " << sum << " cookies.\n";
sum = sum_arr(cookies + 4, cookies + 8); //last 4
cout << "Last four eaters ate " << sum << " cookies.\n";
return 0;
}
int sum_arr(const int *begin, const int *end) {
const int *pt;
int total = 0;
//当pt == end的时候,意味着它将指向区间中的最后一个元素的后一个位置
for (pt = begin; pt != end; pt++) {
total = total + *pt;
}
return total;
}
7.3.5 指针和const
一级指针
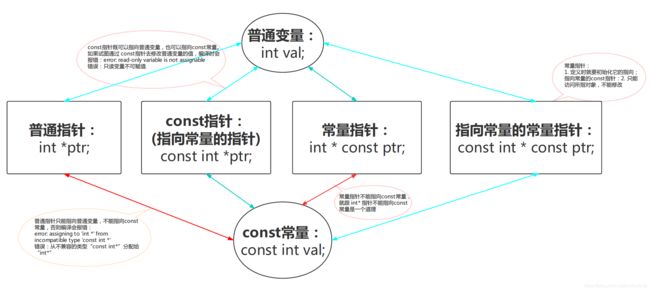
将const关键字用于指针。第一种方法是让指针指向一个常量对象,这样可以防止使用该指针来修改所指向的值(指向常量的指针),第二种方法是将指针本身声明为常量,这样可以防止改变指针指向的的位置(常量指针)。
//首先,声明一个指向常量的指针pt
int age = 39;
const int* pt = &age;
该声明指出,pt指向一个const int(这里为39),因此不能使用pt来修改这个值,换句话来说,*pt的值是const,不能被修改
*pt += 1; //INVALID because pt points to a const int
cin >> *pt; //INVALID for the same reason
但是现在有一个很微妙的问题,pt的声明并不意味着它指向的是一个常量,因为age并不是const的,如果要修改pt指向的值,可以通过修改age变量。
*pt = 20; //INVALID
AGE = 20; //VALID because age is not declared to be const
以前我们将常规变量的地址赋给常规指针,而这里将常规变量的地址赋给指向const的指针。由上面的情况,我们还可以验证两种情况: 将const变量的地址赋给指向const的指针,将const的地址赋给常规指针,经过验证,第一种可行,第二种不可行
//验证第一种情况
const float g_earth = 9.80;
const float *pe = &g_earth; //VALID
//验证第二种情况
const float g_moon = 1.63;
float *pm = &g_moon; //INVALID
第一种情况:
既不能使用g_earth来修改9.80,也不能使用pe来修改。
第二种情况:
如果将g_moon的地址赋值给pm,则可以通过使用pm来修改g_moon的值,然而g_moon是不可修改的,所以这种情况很矛盾
❗️❗️c++禁止将const的地址赋值给非const指针
指向常量的常量指针:
const double pi = 2.14;
// pip是一个指向常量对象的常量指针,修饰pip,不可更改
const double *const pip = π
// 不可通过该指针修改指向的数据,变量名pip没有被const修饰,表示ptr这个变量可以被修改,比如重新赋值指向另一个地址
const double const *pip;
以上有更好的理解方法:
这里类型只有double,去掉后,前者是const const *ptr,两个const是重复的,虽然可能不算做语法错误但其实只保留一个就行了,它们都修饰*ptr,即ptr指向的数据不可变,但ptr本身是可变的
const double pi = 3.14;
const double pe = 2;
const double const *pip = π
cout << *pip << endl;//3.14
//*pip = 10;//INVALID,Read-only variable is not assignable
pip = &pe;
cout << *pip << endl;//2
后者是const *const ptr,两个const分别修饰*ptr和ptr,就是说ptr和其指向的数据都不可变
二级指针
如果,使用二级指针的话,const和非const混合的指针赋值方式不再安全,如果允许这样做,则编写的时候如下:
//编译器过不了,
const int **pp2;
int *p1;
const int n = 13;
pp2 = &p1; // not allowed 在编译器中会报错
*pp2 = &n; // INVALID ,the same as line 7
*p1 = 10; // INVALID, because line 5 --> error(Assigning to 'const int **' from 'int **' discards qualifiers in nested pointer types)【从'int **'对'const int **'赋值将丢弃嵌套指针类型中的限定符(const)】
分析:
const int **pp2;
int *p1;
const int n = 13;
//p1指向n的地址,对p1解引用的话,得到的是n地址指向的内存块所存储的n值
p1 = &n;
//pp2指的是这块内存本身的值,对pp2一级解引用的话,得到的是p1地址指向的内存块所存储的p1值(n的地址)【一级指针的值】,对pp2进行二级解引用,得到的是n的值【指向的一级指针指向的变量的值】
pp2 = &p1;
cout << "&p1 = " << uintptr_t(&p1) << endl;
cout << "p1 = " << uintptr_t(p1) << endl;
cout << "pp2 = " << uintptr_t(pp2) << endl;
cout << "&n = " << uintptr_t(&n) << endl;
cout << "*pp2 = " << uintptr_t(*pp2) << endl;
cout << "*(*pp2) = " << *(*pp2) << endl;

在网上找了一个和上面差不多的代码:
const char c = 'x';
char *p1;
const char **p2 = &p1;
*p2 = &c;
*p1 = 'X';
error:Cannot initialize a variable of type ‘const char **’ with an rvalue of type ‘char **’
报错的原因及其解决办法:https://oomake.com/question/1237772
https://c-faq.com/ansi/constmismatch.html
//在第 3 行,我们将char **分配给const char **。(编译器应该会报错。)在第 4 行,我们将const char *分配给const char *;这显然是合法的。在第 5 行,我们修改了char 指向的内容——这应该是合法的。但是,p1最终指向c,即const。这发生在第 4 行,因为p2实际上是p1。这是在第 3 行中设置的,这是一个不允许的形式的分配,这正是不允许第 3 行的原因。
//将char **分配给const char ** (如第 3 行和原始问题中所示)并不会立即造成危险的。但是它设置了一种情况,在这种情况下p2承诺最终指向的值不会被修改——是不能被遵守。
改正:
const char c = 'x';
const char *p1;
const char **p2 = &p1;//此句,使得*p2指向了p1,直白的说,两者指向了同样的地方
*p2 = &c; //由上面可知,当前语句,给*p2指明了准确的地址,使得p1也指向了同一个位置

参考:https://www.cnblogs.com/peterwarlg/p/13845608.html
const int * * p(指针常量,const修饰int)
与指针常量类似,*p指向的空间地址保存的值不能被修改,但p本身可以被修改。
int ** const p(常指针,const修饰int)
与常指针类似,p本身不能被修改,但P指向的空间地址保存的值能被修改
int * const * p(const修饰int,p的值是常量,******p和p是变量)
二级指针p所指向的一级指针p不能被修改,******p是对p的解引用,是p空间保存的值可以被修改,指针p本身也可以被修改。
const修饰变量//指针常量
int * const p2 = &a;
int * const * q2 = &p2;
const修饰了p2,因此p2中保存的数据(地址)不能改变,所以,q2指向p2的指针(紫线1)【*q2指向的便是p2(不可更改)】是应当被const修饰的
const修饰指针//常量指针
const int * p3;
const int * * q3 = &p3;
const修饰指针和常量
const int * const p4 = &a;
const int * const * q4 = &p4;

p4的*被const(上面那条绿线),因此用const修饰第一个*(紫线2)
p4同样被const掉,p4的值无法改变,因此要用const修饰掉q4指向p4的*(紫线1)
下面有一个const数据组成的数组:
const int months[12] = {31,28,31,30,31,30,31,31,30,31,30,31};
禁止将常量数组的地址赋给非常量指针,这将意味着不能将数组名作为参数传递给使用非常量形参的函数。
//例如
int sum(int arr[] , int n);//should have been const int arr[]
int j = sum(months,12); //not allowed
综上所述:禁止将const指针(months)赋给非const指针(arr)
尽可能使用const
将指针参数声明为指向常量数据的指针有两条理由:
- 这样可以避免由于无意间修改数据而导致编程出错
- 使用const使得函数能够处理const和非const的实参,否则将只能接受非const的数据。
通常,将指针作为函数参数来传递时,可以使用指向const的指针来保护数据,例如上面show_array()的原型---->void show_array(const double ar[],int n);
这里ar[]里面的元素是基本类型,如果它们是指针(二维数组)或者指向指针的指针(双指针),则不能将非const指针赋值给const指针
7.4 函数和二维数组
和一维数组一样,数组名仍然被视为地址。假设有如下代码:
int data[3][4] = {{1,2,3,4},{9,8,7,6},{2,4,6,8}};
int total = sum(data,3);
sum()的原型到底是什么样的呢?是如何将行数和列数作为参数?
data是一个数组名,该数组有3个元素。第一个元素本身是一个数组,有4个int值组成,因此data的类型是指向由4个int组成的指针,因此正确的原型如下:
int sum(int (*arr2)[4],int size);
上面的括号是必不可少的,因为:如果没有括号,就变成了一个由4个指向的int的指针组成的数组,而不是由一个指向由4个int组成的数组的指针
//函数参数不能是数组
int *arr2[4]; //error
还有另外一种格式
int sum(int arr[][4],int size);
由于指针类型指定了列数,因此sum()函数只能接受由4列组成的数组。但长度变量指定了行数,因此sum()对数组的行数没有限制:
int a[100][4];
int b[6][4];
...
int total1 = sum(a,100);
int total2 = sum(b,6);
int total3 = sum(a,10);//sum first 10 rows of a
int total4 = sum(a+10,20);
下面是一个sum可行的函数定义:
int sum(int arr2[][4],int size){
int total;
for(int r = 0;r < size;r++){
for(int c = 0;c < 4;c++){
total += arr2[r][c];
}
}
return total;
}
上面我们都是使用数组表示法,现在我们使用指针表示法:
ar2[r][c] == *(*(ar2+r)+c) //same thing
对*****(*****(ar2+r)+c)进行解释:
ar2指向数组的第一个元素,第一个元素也是一个数组,(ar2 + r)指向了数组的第r行,对此将(ar2 + r)解引用得到处于r行的一维数组的第一个元素的地址,*(ar2 + r)+c指的是一维数组的第c个元素。
7.5 函数和C-风格字符串
7.5.1 函数和c-风格字符串
表示字符串的方式有3种:
- char数组
- 用引号括起来的字符串常量
- 被设置为字符串的地址的char指针
char ghost[15] = "galloping";
char *str = "galumphing";
int n1 = strlen(ghost);//9
int n2 = strlen(str);//10
int n3 = strlen("gamboling");//9
7.5.2 返回 C-风格字符串的函数
#include
char *buildstr(char c, int n);
int main() {
using namespace std;
int times;
char ch;
cout << "Enter a character:";
cin >> ch;
cout << "Enter an integer:";
cin >> times;
char *ps = buildstr(ch, times);
cout << ps << endl;
delete[]ps;
ps = buildstr('+', 20);
cout << ps << "-DONE-" << ps << endl;
delete[]ps;
return 0;
}
char *buildstr(char c, int n) {
char *pstr = new char[n];
// pstr[n] = '\0';
while (--n >= 0) {
pstr[n] = c;
}
return pstr;
}
7.6 函数和结构
将结构作为参数传递,并在需要的时候将结构用作返回值使用。然而,按值传递结构有一个缺点:如果结构非常大,则复制结构将增加内存要求,降低系统运行的速度。我们可以使用指针来访问结构的内容来避免值传递的缺点。
7.6.1 传递和返回结构
当结构比较小的时候,按值传递结构是最合理的,下面来看例子:
有地图显示,从Thunder Falls 到 Bingo 城需要3小时50分钟,而从Bingo到Gotesquo需要1小时25分钟。对于这种时间,可以使用结构来表示------一个成员值记录小时,一个成员值记录分钟。将两者时间加起来,上述两时间总和为4小时75分钟,应将它转换为5小时15分钟
定义结构体
struct travel_time{
int hours;
int mins;
}
返回两种这样结构总和为sum()函数原型。返回值类型为:travel_time(此种方法类似创建一个临时对象)
travel_time sum(travel_time t1,travel_time t2);
完整的程序:
#include
struct travel_time {
int hours;
int mins;
};
const int mins_per_hr = 60;
travel_time sum(travel_time t1, travel_time t2);
void show_time(travel_time t);
int main() {
using namespace std;
travel_time day1 = {5, 45};
travel_time day2 = {4, 55};
travel_time temp = sum(day1, day2);
cout << "Two day total:";
show_time(temp);
travel_time day3 = {4, 32};
cout << "Three-day total:";
show_time(sum(temp, day3));
return 0;
}
travel_time sum(travel_time t1, travel_time t2) {
travel_time total;
total.mins = (t1.mins + t2.mins) % mins_per_hr;
total.hours = t1.hours + t2.hours + (t1.mins + t2.mins) / mins_per_hr;
return total;
}
void show_time(travel_time t) {
using namespace std;
cout << t.hours << " hours, "
<< t.mins << " minutes\n";
}
7.6.2 另一个处理结构的函数示例
假设要描述屏幕上的某点的位置,或者地图上某点相对于原点的位置,则一种方法是指出该点相对于原点的水平偏移量和垂直偏移量。通过“直角坐标系”可以解决
首先定义一个坐标组成结构
struct rect{
double x; //水平偏移量
double y; //垂直偏移量
}
另一种描述点的位置是,指出它偏离原点的距离和方向(极坐标)
相应的也定义一个结构体
struct polar{
double distance;
double angle;
}
下面函数是将弧度转换为角度:转换公式为–> 弧度*(180/pi)
void show_polar (polar dapos){
using namespace std;
const double Rad_to_deg = 57.29577951;
cout << "distance = " << dapos.distance;
cout << ", angle = " << dapos.angle * Rad_to_deg;
cout << " degrees\n";
}
紧接着,我们往前走,编写一个直角坐标转换为极坐标的函数,根据毕达哥拉斯定理,使用水平和垂直坐标来计算距离
distance = sqrt(x*x ,y*y);
数学库中的atan2()函数可根据x和y的值计算角度
angle = atan2(y,x);
本函数具体为:
polar rect_to_polar(rect xyos){
polar answer;
answer.distance = sqrt(xypos.x * xypos.x + xypos.y * xypos.y);
answer.angle = atan2(xypos,y,xypos.x);
return answer;
}
完整程序:
#include
#include
struct polar{
double distance;
double angle;
};
struct rect{
double x;
double y;
};
polar rect_to_polar(rect xypos);
void show_polar(polar dapos);
int main(){
using namespace std;
rect rplace;
polar pplace;
cout << "Enter the x and y value:";
while (cin >> rplace.x >> rplace.y){
pplace = rect_to_polar(rplace);
show_polar(pplace);
cout << "Next two numbers(q to quit):";
}
cout << " Done.\n";
return 0;
}
//将直角坐标转换为极坐标
polar rect_to_polar(rect xypos){
using namespace std;
polar answer;
answer.distance = sqrt(xypos.x * xypos.x + xypos.y *xypos.y);
answer.angle = atan2(xypos.y,xypos.x);
return answer;
}
//将弧度转为角度
void show_polar(polar dapos){
using namespace std;
const double Rad_to_deg = 57.29577951;
cout << "distance = " << dapos.distance;
cout << ", angle = " << dapos.angle * Rad_to_deg;
cout << " degrees\n";
}
7.6.3 传递结构的地址
假设要传递结构的地址而不是整个结构以节省时间和空间,则需要重新编写前面的函数,使用指向结构的指针,利用这种方法重新修改show_polar()函数,需要修改三处地方:
- 调用函数时,将结构的地址(&pplace)而不是结构本身(pplace)传递给它
- 将形参声明为指向polar的指针,即polar*类型。由于函数不应该修改结构,要使用const
- 由于形参是指针而不是结构,因此应间接成员运算符(->)
修改后:
void show_polar(const polar *pda){
using namespace std;
const double Rad_to_deg = 57.29577951;
cout << "distance = " << dapos.distance;
cout << ", angle = " << dapos.angle * Rad_to_deg;
cout << " degrees\n";
}
接着修改rect_to_polar()函数,需要将两个指针传递给该函数,第一个指针指向要转换的结构,第二个指针指向存储转换结果的结构。函数不返回一个新的结构,而是修改函数中已有的结构,所以第一个指针是const,第二不是。
将上面7.6.2的程序修改完后如下:
#include
#include
//极坐标
struct polar{
double distance;
double angle;
};
//直角坐标
struct rect{
double x;
double y;
};
void rect_to_polar(const rect *pxy,polar *pda);
void show_polar(const polar *pda);
int main(){
using namespace std;
rect rplace;
polar pplace;
cout << "Enter the x and y value:";
while (cin >> rplace.x >> rplace.y){
rect_to_polar(&rplace,&pplace);
show_polar(&pplace);
cout << "Next two numbers(q to quit):";
}
cout << " Done.\n";
return 0;
}
//将直角坐标转换为极坐标
void rect_to_polar(const rect *pxy,polar *pda){
using namespace std;
polar answer;//无需创建并返回临时对象,现在在现有的结构上利用指针进行修改
pda->distance = sqrt(pxy->x * pxy->x + pxy->y * pxy->y);
pda->angle = atan2(pxy->y , pxy->x);
}
//将弧度转为角度
void show_polar(const polar *dapos){
using namespace std;
const double Rad_to_deg = 57.29577951;
cout << "distance = " << dapos->distance;
cout << ", angle = " << dapos->angle * Rad_to_deg;
cout << " degrees\n";
}
7.7 函数和string对象
我们知道,可以将一个结构赋给另一个结构,也可以将一个对象赋给另一个对象。可以将结构作为完整的实体传递给函数,也可以将对象作为完整的实体进行传递。
现有一辆汽车的图纸,让你去造一个真的车出来,那么在这个过程中:
1.图纸就相当于我们定义的一个类(类似于C语言中的结构体,在C++中将会学到)
2.那么图纸中的每一个构件就相当于我们在类中定义的成员(比如方向盘模块,刹车模块和加速模块等)
3.当然我们造车的过程就叫做实例化,造出的车就是对象(对象下有属性和方法)
#include
using namespace std;
const int SIZE = 5;
void display(const string sa[], int n);
int main() {
string list[SIZE];
cout << "Enter your " << SIZE << " favorite astronomical sights:\n";
for (int i = 0; i < SIZE; ++i) {
cout << i + 1 << ": ";
getline(cin, list[i]);
}
cout << "Your list:\n";
display(list, SIZE);
return 0;
}
void display(const string sa[], int n) {
for (int i = 0; i < n; ++i) {
//sa[i]是一个string对象
cout << i + 1 << ": " << sa[i] << endl;
}
}
7.8 函数与array对象
假如你要用array对象来存储一年四个季度的开支:
std::arrayexpenses;
前面说过,要使用array类,需要包含头文件array,且array位于名称空间中。我们可以通过函数来显示expenses的内容,可按值传递(它处理的是原对象的副本),或者通过传递指针。
show(expenses);//值传递
show(&expenses);//传递指针
如果函数要修改对象expenses,则需要将该对象的地址传递给函数
fill(&expenses);
下面,我们来声明show()和fill()函数
void show(std::arrayda);
void fill(std::array*da);
最后,使用const array对象,包含4个string对象,用于表示几个季度
const std::array Snames = {"Spring","Summer","Fall","Winter"};
完整的代码如下:
#include
#include
#include
const int Seasons = 4;
const std::array Snames = {"Spring","Summer","Fall","Winter"};
void fill(std::array*pa);
void show(std::arrayda);
int main(){
std::arrayexpenses;
fill(&expenses);
show(expenses);
return 0;
}
void fill(std::array*pa){
using namespace std;
for (int i = 0; i < Seasons; ++i) {
cout << "Enter " << Snames[i] << " expenses:";
cin >> (*pa)[i];
}
}
void show(std::arrayda){
using namespace std;
double total = 0.0;
cout << "\nEXPENSES\n";
for (int i = 0; i < Seasons; ++i) {
cout << Snames[i] << ":$" << da[i] << endl;
total += da[i];
}
cout << "Total Expenses:$ " << total << endl;
}
对 void fill(std::array*****pa) 里面的 (*****pa)[i]
&expenses传进fill里,则有:
std::array*pa = &expenses;
pa 是指向expenses的指针,对pa解引用后得到的是expenses这个对象,访问expenses里面的某个对象方式expenses[i],故可以换成(*pa)[i]进行访问。
⚠️⚠️由于运算符优先级的影响,其中的括号是必不可少。
7.9 递归
7.9.1 包含一个递归调用的递归
如果递归函数调用自己,则被调用的函数也将调用自己,这将无限循环下去。如果需要终止调用链的内容,则将递归调用放在if语句中。下面是一个递归函数recurs()的代码如下:
void recurs(argumentlist){
statements1;
if(test){
recurs(arguments)
}
statements2
}
❗️test转为false时,调用的链将断开
#include
using namespace std;
void countdown(int n);
int main(){
countdown(4);
return 0;
}
void countdown(int n){
cout << "Counting down...." << n << " (n at " << uintptr_t(&n) << ")" < 0){
countdown(n-1); //function calls itself
}
cout << n << ": Kaboom!" << " (n at " << uintptr_t(&n) << ")\n";
}
输出:
Counting down....4 (n at 6171800988)
Counting down....3 (n at 6171800940)
Counting down....2 (n at 6171800892)
Counting down....1 (n at 6171800844)
Counting down....0 (n at 6171800796)
0: Kaboom! (n at 6171800796)
1: Kaboom! (n at 6171800844)
2: Kaboom! (n at 6171800892)
3: Kaboom! (n at 6171800940)
4: Kaboom! (n at 6171800988)
recurs()进行了5次递归调用,statements1部分按照函数调用顺序执行5次,然后statements2部分将以与函数调用相反的顺序执行5次,这个可以通过手写程序过程进行理解。
7.9.2 包含多个递归调用的递归
在需要将一项工作不断分为两项较小的、类似的工作时,递归是非常有用的。
我们可以使用这种情况来绘制标尺的情况。
标出两端,找出中点并将其标出,然后将同样的操作用于标尺的左半部分和右半部分。
#include
using namespace std;
const int len = 66;
const int Divs = 6;
void subdivide(char ar[], int low, int high, int level);
int main() {
char ruler[len];
int i;
for (i = 0; i < len - 2; ++i) { //有个中点值,值取奇数,左右可均分 0-64 --> 65个字符
ruler[i] = ' ';
}
ruler[len - 1] = '\0';
int max = len - 2;
int min = 0;
ruler[min] = ruler[max] = '|';
cout << ruler << endl;//第0行
for (i = 1; i <= Divs; ++i){//1-6行
subdivide(ruler,min,max,i);
cout << ruler << endl;
for (int j = 1; j < len - 2; ++j) {//重置中间区段
ruler[j] = ' ';
}
}
return 0;
}
void subdivide(char ar[], int low, int high, int level) {
if (level == 0){
return;
}
int mid = (high + low) / 2;
ar[mid] = '|';
subdivide(ar,low,mid,level - 1); //左边
subdivide(ar,mid,high,level - 1);//右边
}
递归过程:


剩余的遍历和上述的差不多
有上述过程,我们可以发现,当level=0时,函数将不再调用自己,请注意,subdivde()在递归过程中会调用自己两次,一次针对左半部分,一次针对右半部分
7.10 函数指针
与数据项相似,函数也有地址。函数的地址是存储其机器语言代码的内存的开始地址。
7.10.1 函数指针的基础知识
设计一个名为estimate()的函数,估算编写指定代码所需要的时候,希望不同的程序员都要使用该函数(说出来),对于所有的用户来说,estimate()中的一部分代码是相同的,但该函数允许每个程序员提供自己的算法来估算时间,完成这项工作需要以下步骤:
- 获取函数的地址
- 声明一个函数指针
- 使用函数指针来调用函数
1、获取函数的地址
函数名即为函数的地址。例如:think()为函数,则think就是该函数的地址
process(think);//passes address of think() to process
thought(think());// passes return value of think() to thought()
2、声明函数指针
声明指向函数的指针,也必须指定指针指向的函数类型(返回类型以及函数的参数列表)。
double pam(int); //prototype
//下面为正确的指针类型声明如下:
double (*pf)(int); //pf points to a function that takes
//one int argument and that
//returns type double
❗️❗️通常,要声明指向特定类型的函数的指针,可以首先编写这种函数的原型,然后用(*pf)替换为函数名,这样pf就是这类函数的指针
❗️❗️必须在声明中使用括号将pf括起来,因为括号的优先级比*高,因此****pf(int)意味着pf()是一个返回指针的函数,而(*****pf)(int)意味着pf是一个指向函数的指针
例如:int *****p(int a, int b); //p是返回int*类型指针的函数
3、使用指针来调用函数
double pam(int);
double (*pf)(int);
pf = pam; //pf now points to the pam() function
double x = pam(4);
double y = (*pf)(5);
实际上,c++也允许像使用函数名那样使用pf
double y = pf(5);
7.10.2 函数指针示例
#include
double betsy(int);
double pam(int);
void estimate(int lines, double (*pf)(int));
int main() {
using namespace std;
int code;
cout << "How many lines of code do you need?";
cin >> code;
cout << "Here's Betsy's estimate:\n";
estimate(code, betsy);
cout << "Here's Pam's estimate:\n";
estimate(code, pam);
return 0;
}
double betsy(int lns) {
return 0.05 * lns;
}
double pam(int lns) {
return 0.03 * lns + 0.0004 * lns * lns;
}
void estimate(int lines,double (*pf)(int)){
using namespace std;
cout << lines << " lines will take ";
cout << (*pf)(lines) << " hour(s)\n";
}
输出:
How many lines of code do you need?30
Here's Betsy's estimate:
30 lines will take 1.5 hour(s)
Here's Pam's estimate:
30 lines will take 1.26 hour(s)
7.10.3 深入探讨函数指针
下面是一些函数原型,它们的特征标和返回类型相同:
const double *f1(const double ar[],int n);
const double *f2(const double [],int);
const double *f3(const double *,int);
在函数原型中,参数列表const double ar[]与const double *ar的含义完全相同。其次,在函数原型中,可以省略标识符。因此,const double ar[]可简化为const double [],而const double *ar 可简化为const double *。另一方面,函数定义的时候必须提供标识符
假设要声明一个指针,它指向上面三个函数的其中一个。假定该指针名为pa。则只需将目标函数原型中的函数名替换为(*pa):
const double* (*p1)(const double * ,int);
也可以在声明的同时进行初始化
const double* (*p1)(const double *,int) = f1;
使用c++11 的自动类型推断功能时,代码要简单得多。
auto p2 = f2;
现在我们来看一下下面的语句:
//*(*p1)(av,3) 相当于 *((*p1)(av,3)) 因为括号的优先级比*的优先级要高
cout << (*p1)(av,3) << ": " << *(*p1)(av,3) << endl;
//*p2(av,3) 相当于 *(*p2(av,3)) 因为括号的优先级比*的优先级要高
//c++也允许像使用函数名那样使用p2
cout << p2(av,3) << ": " << *p2(av,3) << endl;
我们从前面所知:(p1)(av,3)和p2(av,3)都调用指向的函数(f1(),f2()).因此,显示的是这两个函数的返回值。返回值的类型为const double****(即double值的地址),如果我们需要查看存储在这些地址的实际值,需要对它们进行解引用。
question1⃣️:如果有一个函数指针数组将很方便。如何做?
const double* (*pa[3])(const double* ,int) = {f1,f2,f3};
question2⃣️:为什么要将[3]放在这个地方呢?
pa是一个包含三个元素的数组,则声明:pa[3],声明的数据类型已经指明了数组包含的元素都是怎么样的。运算符[]的优先级高于*, (*pa[3])表明pa是一个包含三个指针的数组。
question3⃣️:这里是否可以用auto?
不行,自动类型推断只能用于单值初始化,而不能用于初始化列表。但声明数组pa后,声明同样类型的数组就很简单了
auto pb = pa;
前面说过:数组名是指向第一个元素的指针,因此pa和pb都是指向函数指针(元素)的指针。pa[i]和pb[i]都表示数组中的指针
const double *px = pa[0](av,3);
const double *py = (*pb[i])(av,3);
要获得指针所指向的double值,解引用即可
double x = *pa[0](av,3);
double y = *(*pb[1])(av,3);
具体来说,如果喜欢自己来写声明,需要在某个地方加个*,如果这个指针名为pd,则需要指出它是一个指针,而不是一个数组。这意味着需要添加括号让pd与*****先结合
*pd[3] //an array of 3 pointers
(*pd)[3] //a pointer to an array of 3 elements
我们还可以创建指向整个数组的指针。由于数组名pa是指向函数指针的指针,我们可得指向数组的指针就是指向指针的指针
//对单个值初始化,仍可以用auto
auto pd = &pa;
//不用auto
const double *(*(*pd)[3])(const double *,int) = &pa;
解释:
第一种指针调用函数的语法:(*pd)[3] --> pd[3]
pd指向数组,那么*pd就是数组,而(*****pd)[i]是数组中的元素(即函数指针),简单的函数调用就是 (*****pd)[i] (av,3),故而 *****(*****pd)[i] (av,3)是返回指针所指向的具体的double值
第二种指针调用函数的语法: *pd[3]
使用 (*****(*****pd)[i]) (av,3) 来调用函数,而 ((*****pd)[i]) (av,3) 是返回指针所指向的具体的double值
⚠️注意⚠️:pa(它是数组名,表示地址)和&pa之间的差别。大多数情况下,pa都是数组第一个元素的地址,即&pa[0],但是&pa是整个数组的地址;从数字来看,pa与&pa的值是相同的,但他们的类型不同。差别有二:
- pa+1位数组中的下一元素的地址,而&pa+1为数组pa后面一个12字节内存块的地址。
- 要得到第一个元素的值,只需要对pa解除一次引用,但需要对&pa解除两次引用
#include
using namespace std;
const double *f1(const double ar[], int n);
const double *f2(const double [], int);
const double *f3(const double *, int);
int main() {
double av[3] = {1112.3, 1542.6, 2227.9};
//pointer to a function
const double *(*p1)(const double *, int) = f1;
auto p2 = f2;
cout << "Using pointers to function:\n";
cout << " Address value\n";
cout << (*p1)(av, 3) << ": " << *(*p1)(av, 3) << endl;
//c++的用法:p2可以像函数那样使用
cout << p2(av, 3) << ": " << *p2(av, 3) << endl;
//pa an array of pointers
const double *(*pa[3])(const double *, int) = {f1, f2, f3};
auto pb = pa;
cout << "\nUsing an array of pointers to functions:\n";
cout << " Address Value\n";
for (int i = 0; i < 3; ++i) {
cout << (*pa[i])(av, 3) << ": " << *pa[i](av, 3) << endl;
}
cout << "\nUsing an array of pointers to functions:\n";
cout << " Address Value\n";
for (int i = 0; i < 3; ++i) {
cout << pb[i](av, 3) << ": " << *pb[i](av, 3) << endl;
}
cout << "\nUsing an array of pointers to functions:\n";
cout << " Address Value\n";
//const double *(*(*pc)[3])(const double *, int) = &pa;
auto pc = &pa;
// *pc == pa
cout << (*pc)[0](av, 3) << ": " << *(*pc)[0](av, 3) << endl;
//pd points to pa,so *pd == pa;
//(*pd)[3] == pa[3]
const double *(*(*pd)[3])(const double *, int) = &pa;
const double *pdb = (*pd)[1](av,3); //第二个元素的地址
cout << pdb << ": " << *pdb << endl;
cout << (*(*pd)[2])(av,3) << ": " << *(*(*pd)[2])(av,3) << endl;
return 0;
}
const double *f1(const double *ar,int n){
return ar;
}
const double *f2(const double ar[],int n){
return ar + 1;
}
const double *f3(const double ar[],int n){
return ar + 2;
}
输出:
Using pointers to function:
Address value
0x16d2af590: 1112.3
0x16d2af598: 1542.6
Using an array of pointers to functions:
Address Value
0x16d2af590: 1112.3
0x16d2af598: 1542.6
0x16d2af5a0: 2227.9
Using an array of pointers to functions:
Address Value
0x16d2af590: 1112.3
0x16d2af598: 1542.6
0x16d2af5a0: 2227.9
Using an array of pointers to functions:
Address Value
0x16d2af590: 1112.3
0x16d2af598: 1542.6
0x16d2af5a0: 2227.9
7.10.4 使用typedef进行简化
除了auto外,typedef也有相似的作用
typedef double real;//make real another name for double
const double *f1(const double ar[], int n);
typedef const double* (*p_fun)(const double*,int);
p_fun p1 = f1;
//使用这个别名简化代码:
p_fun pa[3] = {f1,f2,f3};
p_fun (*pd)[3] = &pa;
使用typedef可以减少输入量
第8章 函数探幽
8.1 内联函数
内联函数是c++为提高程序运行速度所做的一项改进。常规函数和内联函数主要区别不在于编写方式,而在于c++编译器如何将它们组合到程序中。
编译过程中的最终产品是可执行程序------由一组机器语言指令组成。运行程序的时候,操作系统将这些指令加载到计算机的内存之中,因此每条指令都有特定的内存地址。
现在我们对“常规函数调用使得程序跳到函数的地址,并在函数结束的时候返回”这一过程进行细致分析:
执行到函数调用指令的时候,程序将在函数调用后立即存储该指令的内存地址,并将函数参数复制到为此保留的内存块之中,跳到标记函数起点的内存单元,执行函数代码(有可能函数结束的时候还需要将返回值放入到寄存器之中),然后跳回到地址被保存的指令处。来回的跳跃,需要一定的开销。
c++内联函数提供了另一种选择。内联函数的编译代码和其他程序的代码“内联”起来了。也就是说,编译器将使用相应的函数代码调用函数调用。对于内联代码,程序无需跳到另一个位置处执行代码,再跳回来。因此,内联函数运行速度比常规函数稍快,但代价是需要占用更多的内存,如果程序在10个地方调用同一个内联函数,则程序将包含该函数代码的10个副本。
我们应该有选择地使用内联函数。选择方向有二:
- 如果执行函数代码的时间比处理函数调用机制的时间长,则节省的时间将只占整个过程的很小部分,使用非内联函数可能会比较好。
- 如果代码执行的时间很短,则内联调用就可以节省非内联调用使用的大部分时间。其实这个过程相当的快,尽管节省了大部分时间,但最终节省的时间并不是很大,除非这个函数是经常调用的话,就另说了。
要使用这项特性的话,必须采取下述措施之一:
- 在函数声明前加关键字inline;
- 在函数定义前也要加inline
要注意⚠️:函数过大或者调用自己的话,编译器是不允许将函数变为内联函数的
下面,通过一个程序演示一下内联技术:
#include
inline double square(double x){
return x*x;
}
int main(){
using namespace std;
double a,b;
double c = 13.0;
a = square(5.0);
b = square(4.5+7.5); //can pass expressions
cout << "a = " << a << ", b = " << b << "\n";
cout << "c = " << c;
cout << ", c squared = " << square(c++) << "\n";
cout << "Now c = " << c << "\n";
return 0;
};
输出:
a = 25, b = 144
c = 13, c squared = 169
Now c = 14
内联与宏
c语言中使用的预处理语句#define来提供宏-----内联代码的原始实现,
例如下面是一个计算平方的宏
#define SQUARE(X) X*X
它并不是通过传递参数实现的,而是通过文本替换来实现的
a = SQUARE(5.0); //is replaced by a = 5.0*5.0
b = SQUARE(4.5 + 7.5); // is replaced by b = 4.5 + 7.5 * 4.5 + 7.5
d = SQUARE(c++); //is replaced by d = c++ * c++
如果要让语句2和语句3正常工作。可以通过使用括号来进行改进:
#define SQUARE(X) ((X)*(X))
8.2 引用变量
c++新增了一种复合类型----引用变量。引用是已定义的变量的别名(另一个名称)。引用变量主要的用途是用作函数的形参。通过将引用变量用作参数,函数将使用原始的数据,而不是副本。这样除了指针之外,引用也为函数处理大型结构提供了一种非常方便的途径,对于设计类来说,引用也是必不可少的。
8.2.1 创建引用变量
由前面的学习我们可以知道,c和c++使用&符号来指示变量的地址。c++给&符号赋予了另一个含义,将其用来声明引用。例如,要将rodents作为rats变量的别名,可以这样做:
int rats;
int &rodents =rats //makes rodents an alias for rats
这里的int&指的是指向int的引用。上述引用声明允许将rats和rodents互换----它们指向相同的值和内存单元
以下面的程序来验证:
#include
using namespace std;
int main(){
int rats = 101;
int &rodents = rats;
cout << "rats = " << rats;
cout << ", rodents = " << rodents << endl;
rodents++;
cout << "rats = " << rats;
cout << ", rodents = " << rodents << endl;
cout << "rats address :" << uintptr_t(&rats) << endl;
cout << "rodents address :" << uintptr_t(&rodents);
return 0;
}
输出:
rats = 101, rodents = 101
rats = 102, rodents = 102
rats address :6102529464
rodents address :6102529464
现在我们创建指向rats的引用和指针:
int rats;
int &rodents = rats;
int *prats = &rats;
由上面我们可以知道:rodents 和 *prats 可以与 rats互换;&rodents 和 prats都可以同&rats互换。
❗️❗️引用和指针有点像,但是实际上,引用是不同于指针的。引用必须在声明引用的时候将其初始化,而不能像指针那样,先声明,后赋值。
int rat;
int &rodent;
rodent = rat; //you can't do this.
下面程序试图将rats变量的引用改为bunnies变量的引用时,发生的情况
#include
using namespace std;
int main() {
int rats = 101;
int &rodents = rats;
cout << "rats = " << rats;
cout << ", rodents = " << rodents << endl;
cout << "rats address :" << uintptr_t(&rats) << endl;
cout << "rodents address :" << uintptr_t(&rodents) << endl;
int bunnies = 50;
rodents = bunnies;
cout << "bunnies = " << bunnies;
cout << ", rats = " << rats;
cout << ", rodents = " << rodents << endl;
cout << "bunnies address = " << uintptr_t(&bunnies) << endl;
cout << "rodents address = " << uintptr_t(&rodents) << endl;
return 0;
}
输出:
rats = 101, rodents = 101
rats address :6101333432
rodents address :6101333432
bunnies = 50, rats = 50, rodents = 50
bunnies address = 6101333420
rodents address = 6101333432
最初,rodents引用的是rats,但随着程序试图将rodents作为bunnies的引用,看起来这个做法可行,rodents的值随bunnies变为了50;但细看之后,rats也变成了50,然而rats和rodents的地址相同且在“rodents = bunnies”之后,地址仍未改变,前两者与bunnies的地址是不同的,所以第二次的引用操作是不成功的。
假如试图以下的做法:
int rats = 101;
int *pt = &rats;
int &rodents = *pt;
int bunnites = 50;
pt = &bunnies;
rodents引用的依旧是rats
8.2.2 将引用作为函数参数
引用经常被用作函数参数,使得函数中的变量名成为调用程序中的变量的别名。这种传递参数的方法称为引用传递。引用传递允许被调用的函数能够访问调用函数中的变量。
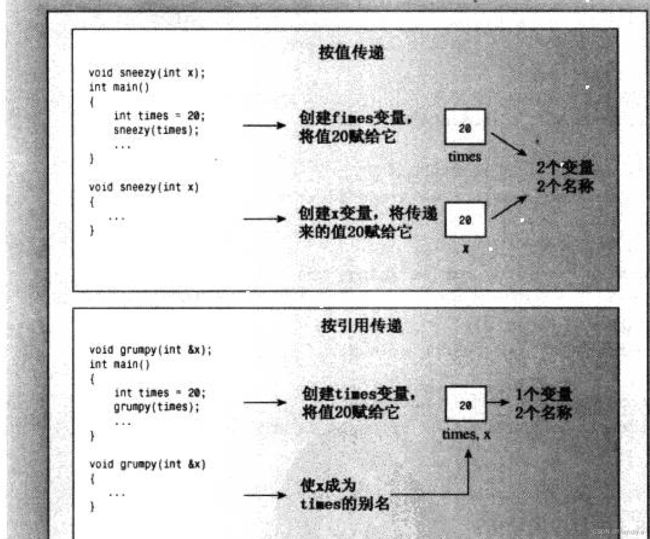
现在我们通过一个常见的计算机问题—交换两个变量的值,对使用引用和使用指针做一下比较。值传递在这个过程中不起作用,因为函数交换原始变量副本的内容,而不是变量本身的内容。
#include
using namespace std;
void swapr(int &a , int &b); //a,b are aliases for ints
void swapp(int *p,int *q); //p,q are addresses of ints
void swapv(int a,int b); //a,b are new variable
int main(){
int wallet1 = 300;
int wallet2 = 350;
cout << "wallet1 = $" << wallet1;
cout << ", wallet2 = $" << wallet2 << endl;
cout << "Using references to swap contents:\n";
swapr(wallet1,wallet2);
cout << "wallet1 = $" << wallet1;
cout << ", wallet2 = $" << wallet2 << endl;
cout << "Using pointers to swap contents:\n";
swapp(&wallet1,&wallet2);
cout << "wallet1 = $" << wallet1;
cout << ", wallet2 = $" << wallet2 << endl;
cout << "Trying to use passing by value:\n";
swapv(wallet1,wallet2);
cout << "wallet1 = $" << wallet1;
cout << ", wallet2 = $" << wallet2 << endl;
return 0;
}
void swapr(int &a,int &b){
int temp;
temp = a; //use a,b for values of variable
a = b;
b = temp;
}
void swapp(int *p,int *q){
int temp;
temp = *p; //use *p,*q for values of variable
*p = *q;
*q = temp;
}
输出:
wallet1 = $300, wallet2 = $350
Using references to swap contents:
wallet1 = $350, wallet2 = $300 //swap
Using pointers to swap contents:
wallet1 = $300, wallet2 = $350 //swap again
Trying to use passing by value:
wallet1 = $300, wallet2 = $350 //swap fail
8.2.3 引用的属性和特别之处
下面有意编写一个比较奇怪的代码:
#include
using namespace std;
double cube(double a);
double refcube(double &ra);
int main(){
double x = 3.0;
cout << cube(x);
cout << " = cube of " << x << endl;
cout << refcube(x);
cout << " = cube of " << x << endl;
return 0;
}
double cube(double a){
a *= a*a;
return a;
}
double refcube(double &ra){
ra *= ra * ra;
return ra;
}
输出:
27 = cube of 3
27 = cube of 27
程序说明:ref cube()函数修改了main()中的x值,而cube()没有。这提醒我们为何通常按值传递。变量a位于cube中,它被创建且初始化为x的值,但修改a并不会影响x。由于refcube()使用了引用参数,修改ra实际上就是修改x。如果程序员不想修改main()函数中的变量,同时又想使用引用,则应使用常量引用
double refcube(const double &ra);
但是修改ra的值时,编译器会报错。
如果ra是一个变量的别名,那么实参应该是一个变量。下面的代码就是不合理的
double z = refcube(x+3.0); // x + 3.0不是变量
临时对象、引用参数和const
如果实参与引用参数不匹配,c++将生成临时变量。当前,仅当参数为const引用时,c++才允许这样做。
如果引用参数是const,则编译器将在下面两种情况下生成临时对象
- 实参的类型正确,但不是左值
- 实参的类型不正确,但可以转换为正确的类型
左值:可被引用的数据对象,例如,变量,数组元素、结构成员、引用、和解除引用的指针
非左值:字面常量(用引号括起来的字符串除外,它们由地址表示)和包含多项的表达式
常规变量属于可修改的左值,const变量属于不可修改的左值
现在,我们重新定义refcube()。使其接受一个常量引用参数:
double refcube(const double &ra){
return ra*ra*ra;
}
接着,我们考虑下面的代码:
double side = 3.0;
double *pd = &side;
double &rd = side;
long edge = 5L;
double lens[4] = {2.0,3.0,4.0,12.0};
double c1 = refcube(side); //ra is side;
double c1 = refcube(lens[2]); //ra is lens[2];
double c1 = refcube(*pd); //ra is side is *pd;
//早期c++可以,但是现在的不可以了
double c1 = refcube(edge); //ra is temporary variable;
double c1 = refcube(7.0); //ra is temporary variable;
double c1 = refcube(side + 10.0); //ra is temporary variable;
参数side、lens[2]、rd和*pd都是有名称的、double类型的数据对象,因此可以为其创建引用。
然而,edge虽然是变量,类型却是不正确的,double引用不能指向long,参数7.0和side+10.0的类型都正确,但没有名称,在这种情况下,编译器都将生成一个临时匿名对象,并让ra指向它。临时对象只在函数调用期间存在
在早期c++较为宽松的规则下,执行下面语句会发生什么情况:
void swapr(int &a,int &b){
int temp;
temp = a; //use a,b for values of variable
a = b;
b = temp;
}
long a= 3,b = 5;
swapr(a,b);
显而易见,这里的类型不匹配,编译器将创建两个临时int变量,将他们初始化为3和5,然后交换临时变量的内容,而a和b保持不变。
简而言之,如果接受引用参数的函数的意图是修改作为参数传递的变量,则创建临时对象阻止这种意图的实现。解决方法是,禁止创建临时对象(现在的c++就是这样做的)
现在看来refcube()函数,该函数的目的只是使用传递的值,而不是修改它们,因此临时变量不会造成任何不利的影响。如果声明将引用指定为const,c++将在必要时生成临时对象。通俗地说,对于形参为const引用的c++函数,如果实参不匹配,则其行为类似于按值传递,为确保原始数据不被修改,将使用临时变量来存储值。
c++新增了另一种引用—右值引用。这种引用可指向右值,是使用&&声明的:
double &&rref = std::sqrt(36.00); //not allowed for double &
double j = 15.0;
double && jref = 2.0*j + 18.5; //not allowed for double &
std::cout << rref << '\n'; //display 6,0
std::cout << jref << '\n'; //display 48.5
新增右值引用的目的是:让库设计人员能够提供部分操作的更有效的实现。
8.2.4 将引用用于结构
引用非常适合用于结构和类。引入引用主要是为了用于这些自定义类型的。
使用结构引用参数的方式与使用几本变量引用相同,声明以及初始化的方式都差不多
struct free_throws{
std::string name;
int made;
int attempts;
float percent;
}
则可以这样编写函数原型,在函数中将指向该结构的引用作为参数:
void set_pc(free_throws &ft);
如果不希望函数修改传入的结构,可使用const修饰
void display(const free_throws &ft);
示例:
#include
#include
struct free_throws{
std::string name;
int made;
int attempts;
float percent;
};
void display(const free_throws &ft);
void set_pc(free_throws &ft);
free_throws &accumulate(free_throws &target,const free_throws &source);
int main(){
free_throws one = {"Ifelsa Branch",13,14};
free_throws two = {"Andor Knott",10,16};
free_throws three = {"Minnie Max",7,9};
free_throws four = {"Whily Looper",5,9};
free_throws five = {"Long Long",6,14};
free_throws team = {"Throwgoods",0,0};
free_throws dup;
set_pc(one);
display(one);
accumulate(team,one);
display(team);
//use return value as argument
display(accumulate(team,two));
accumulate(accumulate(team,three),four);
display(team);
//use return value in assignment
dup = accumulate(team,five);
std::cout << "Display dup after assignment:\n";
display(dup);
set_pc(four);
//ill_advised assignmet
accumulate(dup,five) = four;
std::cout << "Display dup after ill-advised assignment:\n";
display(dup);
return 0;
}
void display(const free_throws &ft){
using std::cout;
cout << "Name: " << ft.name << '\n';
cout << "Made: " << ft.made << '\t';
cout << "Attempts:" << ft.attempts << '\t';
cout << "Percent: " << ft.percent << '\n';
}
void set_pc(free_throws &ft){
if (ft.attempts != 0){
ft.percent = 100.0f * float(ft.made)/float(ft.attempts);
}
else {
ft.percent = 0;
}
}
free_throws &accumulate(free_throws &target,const free_throws &source){
target.attempts += source.attempts;
target.made += source.made;
set_pc(target);
return target;
}
输出:
Name: Ifelsa Branch
Made: 13 Attempts:14 Percent: 92.8571
Name: Throwgoods
Made: 13 Attempts:14 Percent: 92.8571
Name: Throwgoods
Made: 23 Attempts:30 Percent: 76.6667
Name: Throwgoods
Made: 35 Attempts:48 Percent: 72.9167
Display dup after assignment:
Name: Throwgoods
Made: 41 Attempts:62 Percent: 66.129
Display dup after ill-advised assignment:
Name: Whily Looper
Made: 5 Attempts:9 Percent: 55.5556
display()显示结构的内容,而不修改它(const)。这个函数也可以按值传递结构,但与复制原始结构拷贝相比,使用引用可以节省时间和内存。
我们看看以下语句:
free_throws &accumulate(free_throws &target,const free_throws &source)
如果返回类型被声明为free_throws而不是free_throws&,上述返回语句返回target的拷贝,但返回类型为引用,这意味着返回的是最初传递给accumulate()的team对象。
1⃣️我们为何千辛万苦要返回引用?
double m = sqrt(16.0);
cout << sqrt(25.0);
在第一条语句中,值4.0被复制到一个临时位置,然后被复制到m;
在第二条语句中,值5.0被复制到一个临时位置,然后被传递给cout
现在来看下面的语句:
dup = accumulate(team,five);
如果accumulate()返回的是一个结构,而不是指向结构的引用,将把整个结构复制到临时位置,再将这个拷贝复制给dup。但在返回值为引用时,将直接把team复制到dup,其效率更高。
2⃣️返回引用时需要注意的问题
返回引用时最重要的一点是,应避免返回函数终止时不再存在的内存单元引用。
//这个对于简单的程序来说不会报错,但不能有侥幸心理
const free_throws &clone2(free_throws &ft){
free_throws newguy;
newguy = ft;
return newguy;
}
❗️❗️该函数返回一个指向临时变量(newguy)的引用,函数运行完毕后它将不再存在。同样的,也应避免返回指向临时变量的指针。
看一个具体例子:
#include
#include
struct free_throws{
std::string name;
int made;
int attempts;
};
void display(const free_throws &ft){
using std::cout;
cout << "Name: " << ft.name << '\n';
cout << "Made: " << ft.made << '\t';
cout << "Attempts:" << ft.attempts << '\t';
}
const free_throws &clone(free_throws &ft){
free_throws pt;
pt = ft;
return pt;
}
int main(){
free_throws one = {"Ifelsa Branch",13,14};
free_throws dup;
dup = clone(one);
display(one);
std::cout << std::endl;
display(dup);
return 0;
}
输出:
Name: Ifelsa Branch
Made: 13 Attempts:14
Name:
Made: 1795208472 Attempts:1
造成输出结果不同的原因:程序企图引用已经释放的内存
用new为结构分配存储空间,其放在堆上,不会随着函数的调用结束而消失,需要手动释放内存。
const free_throws &clone(free_throws &ft){
free_throws *pt = new free_throws;
*pt = ft;
return *pt;
}
const free_throws &jolly = clone(three);
3⃣️为什么上面要用const修饰函数
上面完整的程序中包括一条语句:
accumulate(dup,five) = four;
能够通过编译的缘由:在赋值语句中,左边必须是可修改的左值。也就是说,在赋值表达式中,左边的子表达式必须标识为可修改的内存块。在这里,函数返回指向dup的引用,它对应的内存块完全符合要求。
另外,常规返回类型是右值—不能通过地址访问的值,为什么常规函数返回值可以是右值?这是因为这种返回值位于临时内存单元中,执行到下一个语句之后,可能就不复存在了。(four本来是左值,但是被转化为右值来用了,这也可以说明结构题变量既可以充当左值也可以充当右值)。
参考文献:https://blog.csdn.net/weixin_36162883/article/details/112115243
8.2.5 将引用用于类对象
将类对象传递给函数时,c++通常的做法是使用引用。
下面我们来看一个例子:
#include
#include
using std::string;
string version1(const string &s1, const string &s2);
const string &version2(string &s1, const string &s2);
const string &version3(string &s1, const string &s2);
int main() {
int a = 10;
const int b = 30;
string input;
string copy;
string result;
std::cout << "Enter a string:";
getline(std::cin, input);
copy = input;
std::cout << "Your string as entered: " << input << std::endl;
result = version1(input, "***");
std::cout << "Your string enhanced: " << result << std::endl;
result = version2(input, "###");
std::cout << "Your string enhanced: " << result << std::endl;
std::cout << "Your original string: " << input << std::endl;
std::cout << "Resetting original string.\n";
input = copy;
result = version3(input, "@@@");
std::cout << "Your string enhanced: " << result << std::endl;
std::cout << "Your original string: " << input << std::endl;
return 0;
}
string version1(const string &s1, const string &s2) {
string temp;
temp = s2 + s1 + s2;
return temp;
}
const string &version2(string &s1, const string &s2) {
s1 = s2 + s1 + s2;
//safe
return s1;
}
const string &version3(string &s1, const string &s2) {
string temp;
temp = s2 + s1 + s2;
//unsafe
return temp;
}
输出:
Enter a string:It's not my fault.
Your string as entered: It's not my fault.
Your string enhanced: ***It's not my fault.***
Your string enhanced: ###It's not my fault.###
Your original string: ###It's not my fault.###
Resetting original string.
Your string enhanced: `@��q��t my fault.@@@
Your original string: It's not my fault.
const string&–>函数使用原来的string对象,但不会修改它。
为什么会出现乱码现象(崩溃)呢?
原因有二:
const string &version3(string &s1, const string &s2) {
string temp;
temp = s2 + s1 + s2;
//unsafe
return temp;
}
temp在version3()函数中是临时对象,当函数调用完毕之后,temp就被清理掉了。并且,这个函数存在一直致命的缺点:返回指向version3()中声明的变量引用。
result = version3(input, "@@@");
上面的语句企图引用已经释放的内存,他的意思是(返回指向version3()中声明的变量引用,该引用会随着临时变量的消亡而消亡)。
8.2.6 对象、继承和引用
ofstream和ofstream类凸显了引用的一个有趣属性。ofstream对象可以使用ostream类的方法,使得能够将特性从一个类传递给另一个类的语言特性被称为继承。简单来说,ostream是基类,而ofstream是派生类。派生类继承了基类的方法。
继承的另一个特征:基类引用可以指向派生类对象,而无需进行强制类型转换。
现在编写一个函数:要求用户输入望远镜物镜和一些目镜的焦距,然后计算并显示每个目镜的放大倍数。放大倍数等于物镜的焦距除以目镜的焦距。
#include
#include
#include
using namespace std;
void file_it(ostream &os, double fo, const double fe[], int n);
const int LIMIT = 5;
int main() {
ofstream fout;
const char *fn = "ep-data.txt";
fout.open(fn);
if (!fout.is_open()) {
cout << "Can't open " << fn << ". Bye\n";
exit(EXIT_FAILURE);
}
double objective;
cout << "Enter the focal length of your "
<< "telescope objective in mm:";
cin >> objective;
double eps[LIMIT];
cout << "Enter the focal lengths,in mm,of " << LIMIT
<< " eyepieces:\n";
for (int i = 0; i < LIMIT; ++i) {
cout << "Eyepiece #" << i + 1 << ": ";
cin >> eps[i];
}
file_it(fout, objective, eps, LIMIT);
file_it(cout, objective, eps, LIMIT);
cout << "Done\n";
return 0;
}
void file_it(ostream &os, double fo, const double fe[], int n) {
ios_base::fmtflags initial;
initial = os.setf(ios_base::fixed); //save initial formatting state
os.precision(0);
os << "Focal length of objective: " << fo << " mm\n";
os.setf(ios::showpoint);
os.precision(1);
os.width(12);
os << "f.1. eyepiece";
os.width(15);
os << "magnification" << endl;
for (int i = 0; i < n; ++i) {
os.width(12);
os << fe[i];
os.width(15);
os << int(fo / fe[i] + 0.5) << endl;
}
os.setf(initial);//restore initial formatting state
}
输出:
Enter the focal length of your telescope objective in mm:1800
Enter the focal lengths,in mm,of 5 eyepieces:
Eyepiece #1: 30
Eyepiece #2: 19
Eyepiece #3: 14
Eyepiece #4: 8.8
Eyepiece #5: 7.5
Focal length of objective: 1800 mm
f.1. eyepiece magnification
30.0 60
19.0 95
14.0 129
8.8 205
7.5 240
Done
以上程序演示了如何使用ostream类中的格式化方法
1⃣️setf()可以设置各种格式化状态。
setf(ios_base::fixed)将对象置于使用定点表示法的模式;
setf(ios_base::showpoint)将对象置千显示小数点的模式 , 即使小数部分为零。
2⃣️precision()指定显示多少位小数(假定对象处于定点模式下)。所有这些设置都将一直保持不变,直到再次调用相应的 方法重新设置它们。
3⃣️width()设置下一次输出操作使用的字段宽度,这种设置只在显示下一个值时有效, 然后将恢复到默认设置。默认的字段宽度为零, 这意味右刚好能容纳下要显示的内容。
ofstream在文件不存在的时候,通过.open自行创建,它的作用是向文件输出字符串流。
8.2.7 何时使用引用参数
使用引用参数的原因有二:
- 程序员能够修改调用函数中的数据对象
- 通过传递引用可以提高程序的运行速度
使用“引用”,“指针”,“按值传递”的时机
- 对于使用传递的值而不作修改的函数
- 如果数据对象(内置数据类型、小型结构),则按值传递
- 如果数据对象是数组,只能用指针了,并将指针声明为指向const的指针
- 如果数据对象是很大的结构,使用const指针或者const引用(节省复制副本的时间和空间)
- 传递类对象参数的标准方式是按引用传递
- 对于修改调用函数中数据的函数
- 如果数据是数组,则只能使用指针
- 如果数据是结构,可以使用指针或者引用
- 如果数据是类对象,只能使用引用
- fixit(int &x),这种很明显是要修改x的值了。
8.3 默认参数
默认参数指的是当函数调用中省略了实参时自动使用的一个值。
例如:假设void wow(int n)中的n有默认值为1,则函数调用wow()相当于wow(1)。这极大地提高了函数的灵活性。再例如有一个left()函数,它的作用是将字符串和n作为参数,并返回该字符串的前n个(其实返回的是指针)。现在假设n有默认值为1,则函数调用left(“theory”,3)照常工作,但是函数调用left(“theory”)不会出错,因为n有了默认值(返回的是一个指向字符串“t”的指针)
以下声明函数原型:(需要自右向左添加默认值,这个过程不能有缺漏)
int harpo(int n , int m = 4,int j = 5); // valid
int chico(int n,int m = 6,int j ); //invalid
int grouchou(int k = 1;int m = 2;int n = 3); //valid
例如:harpo()原型允许调用该函数时,提供1个、2个或者3个参数
beeps = harpo(2); //same as harpo(2,4,5);
beeps = harpo(1,8); //same as harpo(1,8,5);
beeps = harpo(8,7,6); //no default arguments used
下面程序,示范默认参数的操作:
#include
using namespace std;
const int ArSize = 80;
char *left(const char *str, int n = 1);
int main() {
char sample[ArSize];
cout << "Enter a string:\n";
cin.get(sample, ArSize);
char *ps = left(sample,4);
cout << ps << endl;
delete[]ps;
ps = left(sample);
cout << ps << endl;
delete[]ps;
return 0;
}
char *left(const char *str, int n) {
if (n < 0) {
n = 0;
}
char *p = new char[n + 1];
int j;
for (j = 0; j < n && str[j]; ++j) {
p[j] = str[j];
}
while (j <= n){
p[j] = '\0';
j++;
}
return p;
}
输出:
Enter a string:
forthcoming
fort
f
另外一种设置新字符串长度的方法是,将n设置为传递的值和字符串中较小的一个:
int len = strlen(str);
n = (n < len)?n:len;
char *p = new char[n+1];
这种做法能够保证new分配的空间不会多于存储字符串需要的空间。对于像left(“Hi!",32767)这样的调用,则这种方法很有用。第一种方法比较浪费内存空间,第二种方法需要添加一个函数调用(strlen()),因此程序更长,运行速度将降低。
我们可以直接让left()确定n和字符串长度哪个小
int m = 0;
while(m <= n && str[m]){
m++;
}
char *p = new char[m+1];
8.4 函数重载
函数重载,让程序员能够使用多个同名的函数,前提是他们的参数列表不能一样,
下面定义一组原型如下的print()函数:
void print(const char *str,int width);
void print(double d,int width);
void print(long l ,int width);
void print(int i ,int width);
void print(const char *str);
使用print()函数时,编译器会根据所采取的用法使用有相应特征标的原型:
print("Pancakes",15);
print("Syrup");
print(1000.0,10);
print(1999,12);
print(1999L,15);
对于下面的语句:
unsigned int year = 3210;
print(year,6);
当前的print()与任何一个原型都不匹配。C++会尝试使用标准类型转换强制进行匹配。如果line3原型是print()唯一的原型,则函数将会把year转换为double类型,但上面代码,有3个将数字作为第一个参数的原型,因此有3种year的方式。此时,c++的尝试是无用功,
一些看起来彼此不同的特征标是不能共存的。
double cube(double x);
double cube(double &x);
匹配函数时,并不区分const和非const变量。
void dribble(char *bits);
void dribble(const char *bits);
void dabble(char *bits);
void drivel(const char *bits);
下面列出各种函数调用对应的原型
const char p1[20] = "how's the weather?";
char p2[20] = "how's business?";
dribble(p1); //dribble(const char *bits);
dribble(p2); //dribble(char *bits)
dabble(p1); //no match
dabble(p2); //dabble(char *bits)
drivel(p1); //drivel(const char *bits)
drivel(p2); //drivel(const char *bits)
非const值赋给const变量是合法的,但反过来就是非法的。
⚠️⚠️函数重载的关键是特征标的不同,而不是函数类型使得函数进行重载,下面是错误示范
long gronk(int n,float m);
double gronk(int n,float m);
改正后的:
long gronk(int n,float m);
double gronk(float n,int m);
拓展:
重载引用参数:
知道不同引用类型的重载很有用:下面看三个原型
void sink(double &r1); //matches modifiable lvalue(double 变量)
void sank(const double &r2); //matches modifiable or cosnt lvalue ,rvalue(x+y)
void sunk(double && r3); //matches rvalue
使用三种参数的函数示例:
void staff(double &rs); //matches modifiable lvalue
void staff(const double &rcs); //matches rvalue,const lvalue
void stove(double &r1); //matches modifiable lvalue
void stove(const double &r2); //natches const lvalue,rvalue
void stove(double &&r3); //matches rvalue
接着验证行为:
double x = 55.5;
const double y = 32.0;
stove(x); //calls stove(double &r1)
stove(y); //calls stove(const double &r2)
stove(x+y); //calls stove(double &&r3)
如果上面没有定义函数stove(double &&),stove(x+y)将调用函数stove(const double &)
8.4.1 重载示例
#include
unsigned long left(unsigned long num,unsigned ct);
char *left(const char *str,int n = 1);
int main(){
using namespace std;
char *trip = "Hawaii!!";
unsigned long n = 12345678;
int j;
char *temp;
for (int j = 0; j < 10; ++j) {
cout << left(n,j) << endl;
temp = left(trip,j);
cout << temp << endl;
delete []temp;
}
return 0;
}
//截取数据的前ct个数字
unsigned long left(unsigned long num,unsigned ct){
unsigned digits = 0; //记录num有多少位数字
unsigned long n = num;
if (ct == 0 || num == 0){
return 0;
}
while (n){
digits++;
n /= 10;
}
if (digits > ct){ //若数据位数比要取的位数要大,则把末尾的(digits-ct)位删掉
ct = digits - ct;
while (ct--){
num /= 10;
}
return num;
}
else //若要取的数据位要比数据本身的位数要大,直接返回当前数据即可
return num;
}
char *left(const char*str,int n){
if (n < 0){
n = 0;
}
char *p = new char[n+1];
int i = 0;
for (i = 0;i < n && str[i] ;++i){
p[i] = str[i];
}
while (i <= n){
p[i++] = '\0';
}
return p;
}
8.4.2 何时使用函数重载
仅当函数基本上执行相同的任务,但使用不同形式的数据时,才应采取函数重载。有默认参数的函数类似于函数重载。
拓展:名称修饰
c++跟踪每一个重载函数都会指定秘密身份。它是根据函数原型中指定的形参类型对每个函数名进行加密。
8.5 函数模版
函数模版是通用的函数描述。它们使用泛型(不是具体类型)来定义函数。
在前面的代码,定义了一个交换两个int值的函数,假设要交换两个double值,则一种方法是复制原来的代码,并用double替换所有的int,这种方法很繁琐。
c++的函数模版功能能自动完成这一过程,可以节约时间,而且更可靠。、
函数模版允许以任意类型的方式来定义函数。例如:
template
void Swap(AnyType &a,AnyType &b){
AnyType temp;
temp = a;
a = b;
b = temp;
}
第一行指出,要建立一个模版,并将类型命名为Anytype.关键字template和typename是必须的,除非可以使用关键字class代替typename。另外,必须使用尖括号。类型名,可以任意选择,许多人都使用简单的名称,如T。
下面程序演示函数模版的使用:
#include
using namespace std;
template
void Swap(T &a, T &b);
int main() {
int i = 10;
int j = 20;
cout << "i , j = " << i << ", " << j << ".\n";
Swap(i, j);
cout << "now,i , j = " << i << ", " << j << ".\n";
double x = 24.5;
double y = 81.7;
cout << "x,y = " << x << ", " << y << ".\n";
cout << "Using compiler-generated double swapper:\n";
Swap(x, y);
cout << "Now x,y = " << x << ", " << y << ".\n";
return 0;
}
template
void Swap(T &a,T &b){
T temp;
temp = a;
a = b;
b = temp;
}
输出:
i , j = 10, 20.
now,i , j = 20, 10.
x,y = 24.5, 81.7.
Using compiler-generated double swapper:
Now x,y = 81.7, 24.5.
8.5.1 重载的模版
需要多个对不同类型使用同一种算法的函数,可使用模版。但又并非所有的类型都使用相同的算法,所以可以重载模版定义,还有并非所有模版参数都必须是模版参数类型,也可以是具体的类型。
#include
using namespace std;
template
void Swap(T &a, T &b);
template
void Swap(T *a, T *b, int n);
void show(int a[]);
const int Lim = 8;
int main() {
int i = 10, j = 20;
cout << "i , j = " << i << ", " << j << ".\n";
cout << "Using compiler-generated double swapper:\n";
Swap(i,j);
cout << "Now,i , j = " << i << ", " << j << ".\n";
int d1[Lim] = {0,7,0,4,1,7,7,6};
int d2[Lim] = {0,7,2,0,1,9,6,9};
cout << "Original arrays:\n";
show(d1);
show(d2);
Swap(d1,d2,Lim);
cout << "Swapped arrays:\n";
show(d1);
show(d2);
return 0;
}
template
void Swap(T &a,T &b){
T temp;
temp = a;
a = b;
b = temp;
}
template
void Swap(T *a,T *b,int n) {
T temp;
for (int i = 0; i < n; ++i) {
temp = a[i];
a[i] = b[i];
b[i] = temp;
}
}
void show(int a[]){
cout << a[0] << a[1] << "/";
cout << a[2] << a[3] << "/";
for (int i = 4; i < Lim; ++i) {
cout << a[i];
}
cout << endl;
}
输出:
i , j = 10, 20.
Using compiler-generated double swapper:
Now,i , j = 20, 10.
Original arrays:
07/04/1776
07/20/1969
Swapped arrays:
07/20/1969
07/04/1776
8.5.2 模版的局限性
假设有如下模版函数
template
void f(T a,T b){}
假定T为数组的话,a = b这种假设将不成立。
8.5.3 显式具体化
假设定义了如下结构:
struct job{
char name[40];
double salary;
int floor;
};
如果我们希望交换两个结构的内容,由于c++允许将一个结构赋给另一个结构,以下的代码可以实现:
temp = a;
a = b;
b = temp;
如果只想交换salary和floor成员,而不交换name成员,则需要使用不同的代码—显式具体化。
对于给定的函数名,可以有非模版函数、模版函数和显式模版化函数以及它们的重载版本
//non template function prototype
void swap(job &,job&);
//template prototype
template
void swap(T &,T &);
//explicit specialization for the job type
template <> void swap(job &,job &);
正如前面指出,如果有多个原型,则编译器在选择原型时,自上而下选择。例如,在下面代码中,第一次调用swap()时使用通用版本,而第二次调用使用基于job类型的显式具体化版本
template
void swap(T &,T &);
template <> void swap(job &,job &);
int main(){
double u,v;
……
swap(u,v); //use template
job a,b;
....
swap(a,b); //use void swap(job &,job &)
}
swap**中的**是可选的,因为函数的参数类型表明,这是job的一个具体化。因此,可以改为下面语句:
template <>void swap(job &,job &);
下面程序演示了显式具体化的工作形式
#include
using namespace std;
template
void Swap(T &a, T &b);
struct job {
char name[40];
double salary;
int floor;
};
template<>
void Swap(job &a, job &b);
void show(job &j);
int main() {
cout.precision(2);
cout.setf(ios::fixed, ios::floatfield);
int i = 10, j = 20;
cout << "i,j = " << i << ", " << j << ".\n";
cout << "Using compiler-generated int swapper:\n";
Swap(i, j);
cout << "Now,i,j = " << i << ", " << j << ".\n";
job use = {"Susan Yaffee", 73000.60, 7};
job sidney = {"Sidney Taffee", 78060.72, 9};
cout << "Before job swapper:\n";
show(use);
show(sidney);
Swap(use, sidney);
cout << "After job swapping:\n";
show(use);
show(sidney);
return 0;
}
template
void Swap(T &a, T &b) {
T temp;
temp = a;
a = b;
b = temp;
}
template<>
void Swap(job &a, job &b) {
double t1;
int t2;
//交换两结构体的salary成员值
t1 = a.salary;
a.salary = b.salary;
b.salary = t1;
//交换两结构体的floor成员值
t2 = a.floor;
a.floor = b.floor;
b.floor = t2;
};
void show(job &j) {
cout << j.name << ": $" << j.salary
<< " on floor " << j.floor << endl;
}
输出:
i,j = 10, 20.
Using compiler-generated int swapper:
Now,i,j = 20, 10.
Before job swapper:
Susan Yaffee: $73000.60 on floor 7
Sidney Taffee: $78060.72 on floor 9
After job swapping:
Susan Yaffee: $78060.72 on floor 9
Sidney Taffee: $73000.60 on floor 7
8.5.4 实例化和具体化
请看下面的代码:
template
T Add(T a,T b){ //pass by value
return a+b;
}
int m = 6;
double x = 10.2;
cout << Add(x,m) << endl;
这里的模版与函数调用Add(x,m)不匹配,因为该模版要求两个函数参数的类型是相同的。但通过使用Add****(x,m),可强制为double类型实例化,并将参数m强制转换为double类型
引入显式实例化,必须使用新的语法----在声明中使用前缀template 和 template<>,以区分显式实例化和显式具体化。
下面的代码片段总结了这些概念:
template
void Swap(T &,T&);
template<>
void Swap(job &a, job &b);
int main(){
template void Swap(char&,char &); //显式实例化
short a,b;
...
Swap(a,b);
job n,m;
...
Swap(n,m);
char g,h;
...
Swap(g,h);
}
8.5.5 编译器选择使用哪个函数版本
我们大致了解一下过程:
- 创建候选函数列表,其中包含与被调用函数的名称相同的函数和模版函数
- 使用候选函数列表创建可行函数列表。这些都是参数数目正确的函数,为此有一个隐式转换序列(强制转换)。
- 确定是否有最佳的可行函数,如果没有,则该函数调用出错。
我们进行如下调用:
may('B');
下面是一些重载的版本:
void may(int);
float may(float,float = 3);
void may(char);
char *may(const char*);
char may(const char&);
template void may(const T&);
template void may(T *);
只考虑特征标,而不考虑返回类型,其中两个候选函数4和7都不行,因为整数类型不能被强制转换为指针类型
接下俩编译器回确定哪个函数最佳,通常,从最好到最坏的顺序如下所述:
- 完全匹配,但常规函数优先于模版
- 提升转换(例如,char和short自动转换为int,float自动转换为double)
- 标准转换(例如,int转换为char,long转换为double)
- 用户定义的转换,如类声明中定义的转换
细讲一下:函数1优于函数2,因为char到int的转换为提升转换,而char到float的转换为标准转换。而函数3、函数5和函数6都优于函数1、2,因为它们是完全匹配的。函数3、5都完全匹配,编译器通常会报错,但这一规则有两个例外。我们需要深入探讨一下:
- 完全匹配和最佳匹配
Type(argument-list)意味着用作实参的函数名与用作形参的函数指针 只要返回类型和参数列表相同,就是匹配的。
假设有如下函数代码:
struct blot{
int a;
char b[10];
};
blot ink = {25,"sports"};
....
recycle(ink);
在这种情况下,下面的原型都是完全匹配的:
void recycle(blot);
void recycle(const blot);
void recycle(blot &);
void recycle(const blot &);
如果有多个匹配的原型,编译器将生成一条错误消息,该消息可能会使用诸如"ambiguous"这样的词语
不过,凡事也会有例外,仍可完成编译解析。首先,指向非const数据的指针和引用优先与非const指针和和引用参数匹配。也就是说,在上面的例子,如果只定义函数3和4是完全匹配的,则将选择3,因为ink没有被声明为const。然而,const和非const之间的区别只适用于指针和引用指向的数据
如果两个完全匹配的函数都是模版函数,则较具体的模版函数优先。看下面:
struct blot{
int a;
char b[10];
};
templatevoid recycle(Type T);
template<> void recycle (blot &T);
blot ink = {25,"sports"};
recycle(ink); //use specialization
最具体并不意味着显式具体化,而是值编译器推断使用哪种类型时执行的转换最少。
template void recycle (Type T);
template void recycle (Type *T);
假如这个程序也有如下代码:
struct blot{
int a;
char b[10];
};
blot ink = {25,"sports"};
recycle(&ink); //use specialization
在这两个模版函数中,recycle(blot*****)被认为是更具体的,因为在生成过程中,它需要进行的转换更少。因为在生成过程中,函数1将Type作为函数参数,因此Type必须被解释为指向blot的指针。而函数2,函数参数是指向Type的指针,用blot标识Type;也就是说,在函数2中,Type已经被具体化为指针,“更具体”。
2、部分排序规则示范
以下程序有两个用来显示数组内容的模版定义。
第一个定义假设作为参数传递的数组中包含了要显示的数据
第二个定义假设数组元素为指针,指向要显示的数据
#include
using namespace std;
template
void show_array(T arr[], int n);
template
void show_array(T *arr[],int n);
struct debts{
char name[50];
double amount;
};
int main() {
int things[6] = {13,31,103,301,310,130};
struct debts mr_E[3] = {
{"Ima Wolfe",2400.0},
{"Ura Foxe",1300.0},
{"Iby Stout",1800.0}
};
double *pd[3];
for (int i = 0; i < 3; ++i) {
pd[i] = &mr_E[i].amount;
}
cout << "Listing Mr. E's counts of things:\n";
show_array(things,6);//use template A
cout << "Listing Mr. E's debts:\n"; //use template B
show_array(pd,3);
return 0;
}
template
void show_array(T arr[],int n){
cout << "template A\n";
for (int i = 0; i < n; ++i) {
cout << arr[i] << ' ';
}
cout << endl;
}
template
void show_array(T *arr[],int n){
cout << "template B\n";
for (int i = 0; i < n; ++i) {
cout << *arr[i] << ' ';
}
cout << endl;
}
输出:
Listing Mr. E's counts of things:
template A
13 31 103 301 310 130
Listing Mr. E's debts:
template B
2400 1300 1800
解释:模型B中的T被替换为类型double*。在这种情况下,模版函数将显示pd数组的内容,即3个地址。所有后面需要解引用才能看到存放在地址下的具体值。
3、自己选择
如下程序:将模版函数定义放在文件开头,从而无需提供模版原型
#include
using namespace std;
template
T lesser(T a, T b) {
return a < b ? a : b;
};
int lesser(int a, int b) {
a = a < 0 ? -a : a;
b = b < 0 ? -b : b;
return a < b ? a : b;
}
int main() {
int m = 20;
int n = -30;
double x = 15.5;
double y = 25.9;
cout << lesser(m,n) << endl;
cout << lesser(x,y) << endl;
cout << lesser <>(m,n) << endl;
cout << lesser(x,y) << endl;
return 0;
}
输出:
20
15.5
-30
15
lesser <>(m,n)中的<>指出,编译器应该选择模版函数,而不是非模版函数;编译器注意到实参的类型为int,因此使用int替代T对模版进行实例化。
8.5.6 模版函数的发展
1、是什么类型?
看一下下面的例子:
template
void fit(t1 x,t2,y){
...
?type? xpy = x + y;
....
}
xpy的类型可能是t1、t2或者其他类型。在这种情况下,加法运算将导致自动整型提升,当t1是double,t2是int时候,最终的结果是double,就是int提升到double类型。
2、关键字decltype(c++11)
int x;
decltype(x) y; // make y the same type as x
给decltype提供参数可以是表达式,上面fit()中,可以使用下面代码:
decltype(x+y) xpy;
xpy = x+ y;
//另一种方法
decltype(x + y) xpy = x + y;
decltype比这些演示要复杂些,为了确定类型,编译器必须遍历一个核对表。假如有以下声明:
decltype(expression) var;
则核对表简化如下:
1⃣️若expression是一个没有用括号括起来的标识符,则var的类型和该标识符类型相同,包括const等限定符
double x = 5.5;
double y = 7.9;
double &rx = x;
const double *pd;
decltype(x) w; //w is type double
decltype(rx) u = y; //u is type double &
decltype(pd) v; //v is type const double*
2⃣️若expression是一个函数调用,则var类型与函数的返回类型相同
long indeed(int);
decltype(indeed(3)) m; //m is type int,这里并不会调用函数,只是查看
3⃣️若expression是左值,则var为指向起类型的引用,expression是用括号括起来的标识符
double xx = 4.4;
decltype ((xx)) r2 = xx; //r2 is double &
顺带说一下,括号并不会改变表达式的值和左值性:
xx = 98.6;
(xx) = 98.6;
4⃣️如果前面都不满足,则var类型与expression类型相同
int j = 3;
int &k = j;
int &n = j;
decltype(j+6) i1; //i1 type int
decltype(100L) i2; //i2 type long
decltype(k + n) i3; //i3 type int
如果需要多次声明,可结合使用typedef和decltype
template
void ft(t1 x, t2 y){
typedef decltype(x+y) xytype;
xytype xpy = x + y;
xytype arr[10];
xytype &xy = arr[2]; //rxy is a reference
}
有一个问题是decltype也解决不了的:
template
?type? gt(t1 x,t2 y){
return x + y;
}
我们无法得知x和y相加后的值。因为x和y未声明,编译器看不到它们,所以无法使用decltype
对于下面的原型:
double h(int x,float y);
//使用新增的语法可编写成这样:
auto h(int x,float y) -> double;
这将返回类型移到了参数声明后面。->double被称为后置返回类型。auto是一个占位符,表示后置返回类型提供的类型。结合这种语法,我们可以如下操作:
template
auto gt(t1 x , t2 y) -> decltype(x + y){
return x + y;
}
现在,decltype在参数声明后面,因此x和y位于作用域内,可以使用它们。
第 9 章 内存模型和名称空间
9.1. 单独编译
C++鼓励将组件函数放在独立的文件中。可单独编译文件,然后将其链接成可执行的程序。
C++编译器既编译程序,也管理链接器。
C++都将一些结构声明或结构函数原型都放在头文件中,然后使用 #include 指令来管理头文件。(⚠️注意:不是包含源代码文件,这样会导致多重声明)。我们使用#include “头文件名”,来包含头文件。
不要将函数定义或变量声明放到头文件中,简单场景无问题,大型场景会引发问题 。
头文件中包含的内容
- 函数原型
- 使用
#define或const定义的符号常量
- 结构声明
- 类声明
- 模板声明
- 内联函数
下面就是对图上流程图的示范:
//coordin.h
#ifndef COORDIN_H_
#define COORDIN_H_
struct polar{
double distance;
double angle;
};
struct rect{
double x;
double y;
};
//prototypes
polor rect_to_polar(rect xypos);
void show_polar(polar dapos);
#endif
//file1.cpp
#include
#include
#include "coordin.h"
using namespace std;
polar rect_to_polar(rect xypos);
void show_polar(polar dapos);
int main(){
rect rplace;
polar pplace;
cout << "Enter the x and y values:";
while (cin >> rplace.x >> rplace.y){
pplace = rect_to_polar(rplace);
show_polar(pplace);
cout << "Next two numbers(q to quit):";
}
cout << "Bye!\n";
return 0;
}
polar rect_to_polar(rect xypos){
polar answer;
answer.distance = sqrt(xypos.x * xypos.x + xypos.y * xypos.x);
answer.angle = atan2(xypos.y,xypos.x);
return answer;
}
void show_polar(polar dapos){
const double rad_to_deg = 57.29577951;
cout << "distance = " << dapos.distance;
cout << ", angle = " << dapos.angle * rad_to_deg;
cout << " degrees\n";
}
在同一个文件中只能将同一个头文件包含一次。例如,可能使用包含了另外一个头文件的头文件,为了避免这种情况,可以采用以下一种技术
#ifndef COORDIN_H_
#define COORDIN_H_
//place include file contents here
#endif
9.2. 存储持续性、作用域和链接性
C++中使用了四种不同的方案来存储数据,它们的区别在于数据保留在内存中的时间。
9.2.1 作用域和链接
作用域描述了名称在文件的多大范围可见。
链接性描述了名称如何在不同单元间共享。链接性为外部的名称可在文件间共享,链接性为内部的名称只能由一个文件中的函数共享。
C++变量的作用域的种类
- 局部的变量只在定义它的代码块使用(函数体)
- 全局(文件作用域)的变量在定义位置到文件结尾直接都可用。
- 自动变量的作用域为局部。
- 静态变量的作用域取决于如何被定义。
- 函数原型中的名称只在包含参数列表的括号内可用
- 类中声明的成员的作用域为整个类。
- 名称空间中声明的变量作用域为整个名称空间。
9.2.2 自动存储持续性
在函数定义中声明的变量(包括函数参数)的存储持续性为自动的。程序执行其所属的函数或代码块时被创建,在执行完后被释放。自动变量的名称没有链接性,因为不能共享。
作用域为局部,没有链接性。
#include
using namespace std;
int main(){
int teledeli = 5;
{
cout << "Hello\n";
int websight = -2;
cout << websight << " " << teledeli << endl;
}//websight expired
// cout << websight << " " << teledeli << endl;
cout << teledeli << endl;
return 0;
}
如果代码块中将websight定义为teledeli的话,代码块就会将外部的teledeli隔离。
下面程序是说明自动变量的作用范围:
#include
void oild(int x);
int main(){
using namespace std;
int texas = 31;
int year = 2011;
cout << "In main(),texas = " << texas << ", &texas = " << uintptr_t(&texas) << endl;
cout << "In main(),year = " << year << ", &year = " << uintptr_t(&year) << endl;
oild(texas);
}
void oild(int x){
using namespace std;
int texas = 5;
cout << "In oild(),texas = " << texas << ", &texas = " << uintptr_t(&texas) << endl;
cout << "In oild(),x = " << x << ", &x = " << uintptr_t(&x) << endl;
{
int texas = 113;
cout << "In block,texas = " << texas << ", &texas = " << uintptr_t(&texas) << endl;
cout << "In block,x = " << x << ", &x = " << uintptr_t(&x) << endl;
}
cout << "Post-block texas = " << texas << ", &texas = " << uintptr_t(&texas);
}
输出:
In main(),texas = 31, &texas = 6168376764
In main(),year = 2011, &year = 6168376760
In oild(),texas = 5, &texas = 6168376696
In oild(),x = 31, &x = 6168376700
In block,texas = 113, &texas = 6168376692
In block,x = 31, &x = 6168376700
Post-block texas = 5, &texas = 6168376696
拓展:
1⃣️自动变量和栈
2⃣️寄存器变量
关键字register最初是由c语言引入的,他建议编译器使用cpu寄存器来存储自动变量
register int _count_fast; //request for a register variable
设置这个旨在提高访问变量的速度。
9.2.3 静态存储持续性
在函数定义外定义的变量和使用关键字static定义的变量的存储持续性为静态,它们在程序整个运行过程中都存在.
提供了3种链接性:
外部链接性:代码块的外面声明
- 单定义规则:变量只能有一次定义。
- C++提供了两种变量声明:
- 定义声明:给变量分配存储空间。
- 引用声明:不给变量分配存储空间(引用已有的变量)。引用声明使用
关键字extern,且不进行初始化。
- 如果多个文件中要使用外部变量,只需一个文件中包含该变量的定义(单定义规则),使用该变量的其他文件中,都必须使用关键字extern 声明。
内部链接性:在代码块的外面声明,且使用static限定符。
- 在其所属的文件中使用。
无链接性:代码块内使用,且使用static限定符。
- 一般是在函数内使用,尽管函数之间多次被调用,其值不会发生变化。
下面代码片段说明这3种变量:
int global = 1000;
static int one_file = 50;
int main(){
}
void funct1(int n){
static int count = 0;
int llama;
}
void funct2(int q){
}
上述语句中,global、one_file和count(静态持续变量)在整个程序执行期间都存在。在funct1()函数中声明的变量count作用域为局部,没有链接性,这意味着只能在funct1()函数中使用它,就像自动变量llama一样,然而,与llama不同的是,即使在funct1()函数没有被执行的时候,(由于count被static修饰),count也留在内存中。
global和one_file的作用域都为整个文件(即在从声明位置到文件末尾的范围内都可以被使用)。global的链接性为外部,程序的其他文件中使用它;而one_file的链接性是内部,它只能被包含上述代码的文件(当前文件)中使用它。
编译器将分配固定的内存块来存储所有的静态变量,所有静态持续变量在整个程序执行期间都存在。
除默认的零初始化(未被初始化的静态变量)外,可对静态变量进行常量表达式初始化和动态初始化`。
#include
int y = 5; //constant expression initialization
const double pi = 4.0 * atan(1.0); //dynamic initialization(初始化的时候需要向库函数调用atan()函数)
9.2.4 静态持续性、外部链接性
链接性为外部的变量,它们存储持续性为静态,作用域为整个文件。
1⃣️单引用规则
引用声明使用关键字extern,且不进行初始化;否则,声明为定义,导致分配存储空间
double up; //definition,up is 0
extern int bleml //blem defined elsewhere
如果在多个文件中使用同个外部变量,只需在一个文件中包含该变量的定义,其他在使用它的时候需要使用extern
//file01.cpp
extern int cats = 20; //definition because initialized
int dogs = 22;
int fleas;
//file02.cpp
//use cats and dogs from file01.cpp
extern int cats; //not definitions because they use
extern int dogs; //extern and have no initialization
下面的程序演示了自动变量将隐藏同名的全局变量。还演示了如何使用关键字extern来重新声明以前定义过的外部变量,以及如何使用c++作用域解析运算符来访问被隐藏的外部变量。
//external.cpp
#include
using namespace std;
double warming = 0.3;
void update(double dt);
void local();
int main(){
cout << "Global warming is " << warming << " degrees.\n";
update(0.1);
cout << "Global warming is " << warming << " degrees.\n";
local();
cout << "Global warming is " << warming << " degrees.\n";
return 0;
}
//support.cpp/.h
#ifndef TEST_SUPPORT_H
#define TEST_SUPPORT_H
#include
extern double warming;
using namespace std;
void update(double dt);
void local();
#endif //TEST_SUPPORT_H
#include "support.h"
void update(double dt){
extern double warming;
warming += dt;
cout << "Updating global warming to " << warming;
cout << " degrees.\n";
}
void local(){
double warming = 0.8;
cout << "Local warming = " << warming << " degrees.\n";
cout << "But global warming = " << ::warming;
cout << " degrees.\n";
}
输出:
Global warming is 0.3 degrees.
Updating global warming to 0.4 degrees.
Global warming is 0.4 degrees.
Local warming = 0.8 degrees.
But global warming = 0.4 degrees.
Global warming is 0.4 degrees.
local()函数中使用了作用域解析运算符(:。放在变量前面时,该运算符表示使用变量的全局版本。因此,local()将warming显示为0.8,但将::warming显示为0.4。
拓展:
全局和局部变量
全局变量很有吸引力–>所有函数都能访问它,因此不用传递参数,但是这个程序不可靠。经验表明,程序能够避免对数据进行不必要的访问,就越能保持数据的完整性。
9.2.5 静态持续性、内部链接性
将static限定符用于作用域为整个文件的变量时,该变量的链接性将为内部的。内部意味着内部的变量只能在其所属的文件中使用。如果文件定义了一个静态外部变量,其名称与另一个文件中声明的常规外部变量相同,则在该文件中,静态变量将隐藏常规外部变量
//file1
int errors = 20;
......
//file2
static int errors = 5; //known to file2 only
void froobish(){
cout << errors;
...
}
下面的程序演示c++如何处理链接性为外部和内部的变量。
//twofile1.cpp
#include
using namespace std;
int tom = 3; //external variable definition
int dick = 30; //external variable definition
static int harry = 300; //static,internal linkage
void remote_access();
int main(){
cout << "main() reports the following addresses:\n";
cout << uintptr_t(&tom) << " = &tom," << uintptr_t(&dick) << " = &dick,";
cout << uintptr_t(&harry) << " = &harry\n";
remote_access();
return 0;
}
//twofile2.cpp
#include
extern int tom;
static int dick = 10;
int harry = 200;
void remote_access(){
using namespace std;
cout << "remote_access() reports the following addresses:\n";
cout << uintptr_t(&tom) << " = &tom, " << uintptr_t(&dick) << " = &dick, ";
cout << uintptr_t(&harry) << " = &harry\n";
}
输出:
main() reports the following addresses:
4342530048 = &tom,4342530052 = &dick,4342530056 = &harry
remote_access() reports the following addresses:
4342530048 = &tom, 4342530064 = &dick, 4342530060 = &harry
9.2.6 静态存储持续性、无链接性
无链接性的局部变量,这种变量是这样创建的,将static限定符用于在代码块中定义的变量。在代码块中使用static时,将会导致局部变量的存储持续性为静态,它只能在代码块中使用,但是他在代码块不活动的时候仍然存在。
#include
const int Arsize = 10;
void strcount(const char *str);
using namespace std;
int main() {
char input[Arsize];
char next;
cout << "Enter a line:\n";
cin.get(input, Arsize);
while (cin) {
cin.get(next);
while (next != '\n') {
cin.get(next);
}
strcount(input);
cout << "Enter next line(empty line to quit):\n";
cin.get(input, Arsize);
}
cout << "Bye\n";
return 0;
}
void strcount(const char *str) {
static int total = 0;
int count = 0;
cout << "\"" << str << "\" contains ";
while (*str++) {
count++;
}
total += count;
cout << count << " character\n";
cout << total << " characters total\n";
}
输入:
Enter a line:
nice pants
"nice pant" contains 9 character
9 characters total
Enter next line(empty line to quit):
ok
"ok" contains 2 character
11 characters total
Enter next line(empty line to quit):
q
"q" contains 1 character
12 characters total
Enter next line(empty line to quit):
Bye
第一个cin.get(next)是input未超出长度,读取被留在输入队列的换行符,避免cin状态变为failbit导致循环终止;第二个cin.get(next)是读取超过数组长度的剩余字符,包括’\0’;
静态变量total只在程序运行的时候被设置为0,以后的函数调用,其值都保持不变。
9.2.4 线程存储持续性(C++11特性)
在多核处理器中,这些CPU可以同时处理多个执行任务,这让程序能够将计算机放在可并行处理的不同线程中,如果变量是使用关键字thread_local声明的,则其生命周期与所属的线程一样长。
9.2.5 动态存储持续性
用new运算符分配的内存一直存在,直到使用delete运算符将其释放或程序结束为止,这种内存有时被称为自由存储或堆。
9.2.7 说明符和限定符
存储说明符
-
auto(C++11中不是说明符):用于自动类型推断
-
register:声明中指示寄存器存储,C++11中显式指出变量是自动。
-
static:内部链接性,作用域为整个文件的声明中。主要使用静态局部变量。
-
extern:引用声明,声明引用在其它地方定义的变量。
-
thread_local(C++11新增):指出变量的持续性与其所属线程的持续性相同。
-
mutable:即使结构(或类)变量为const,其某个成员也可以被修改。
-
struct data{
char name[30];
mutable int accesses;
};
const data veep = {"Claybourne Clodde",0,...};
strcpy(veep.name,"Joye Joux"); //not allowed
veep.accesses++; //allowed
-
volatile:程序代码没有对内存单元进行修改,其值可能发生变化。
9.2.8 存储方案和动态分配
使用C++运算符new(或C函数malloc())分配的内存,称为动态内存。
动态内存由new 和 delete 控制。而不是作用域和链接性规则控制。
编译器的三块独立内存:静态变量、自动变量、动态存储。
- 使用new运算符初始化 如果为内置的标量类型分配存储空间并初始化,可在类型名后面加上初始值,将其用括号括起。
int *pi = new int (6);
//构造函数的类
struct where {double x;double y;double z;};
where * one = new where {2.5,5.3,7.2};
int *ar = new int [4]{2,4,6,7};
//初始化用于单值变量
double *pdo = new double{99.99};
要初始化常规结构或数组,需要使用大括号的列表初始化。
- new失败时 早期返回空指针,现在会触发异常std::bad_alloc。
- new和delete 运算符new和new[]分别调用如下函数:
//下面的std::size_t为typedef
void * operater new(std::size_t);
void * operater new[](std::size_t);
//定位new可以重载
int *pi = new int; ---> int *pi = new(sizeof(int));
int *p2 = new(buffer) int; --> int *p2 = new(sizeof(int),buffer);
int *p3 = new(buffer) int[40]; --> int *p3 = new(40 * sizeof(int),buffer);
称为分配函数,对应的释放函数如下:
void operator delete(void *);
void operator delete[](void *);
- 定位new 运算符
new的两个功能:
-
在堆中找到足以满足的内存块。
-
指定要使用的位置(定位特性)。
使用new定位特性,需要包含 头文件new。
#include
struct chaff{
char dross[20];
int slag;
};
char buffer1[50];
char buffer2[500];
int main(){
chaff *p1,*p2;
int *p3,*p4;
p1 = new chaff; //place structure in heap
p3 = new int[20]; //place int array in heap
//now,the two forms of placement new
p2 = new (buffer1) chaff; //place structure in buffer1
p4 = new (buffer2) int[20]; //place int array in buffer2
}
出于简化的目的,上述代码从buffer1中分配空间给结构chaff,从buffer2中分配空间给一个包含20个元素的int数组
下面程序使用常规new运算符和定位new运算符创建动态分配数组,说明两种new的区别
#include
using namespace std;
const int BUF = 512;
const int N = 5;
char buffer[BUF];
int main() {
double *pd1, *pd2;
int i;
cout << "Calling new and placement new:\n";
pd1 = new double[N];
pd2 = new(buffer) double[N];
for (int i = 0; i < N; ++i) {
pd2[i] = pd1[i] = 1000 + 20.0 * i;
}
cout << "Memory addresses:\n" << " heap: " << uintptr_t(pd1)
<< " static:" << uintptr_t((void*)buffer) << endl;
for (int i = 0; i < N; ++i) {
cout << pd1[i] << " at " << uintptr_t(&pd1[i]) << ";";
cout << pd2[i] << " at " << uintptr_t(&pd2[i]) << endl;
}
cout << "\nCalling new and placement new a second time:\n";
double *pd3,*pd4;
pd3 = new double [N];
pd4 = new(buffer) double[N];
for (int j = 0; j < N; ++j) {
pd4[j] = pd3[j] = 1000 + 40.0 * j;
}
cout << "Memory addresses:\n" ;
for (int i = 0; i < N; ++i) {
cout << pd3[i] << " at " << uintptr_t(&pd3[i]) << ";";
cout << pd4[i] << " at " << uintptr_t(&pd4[i]) << endl;
}
cout << "\nCalling new and placement new a third time:\n";
delete []pd1;
pd1 = new double [N];
pd2 = new(buffer + N * sizeof(double)) double[N];
for (int i = 0; i < N; ++i) {
pd2[i] = pd1[i] = 1000 + 60.0 * i;
}
cout << "Memory contents:\n" ;
for (int i = 0; i < N; ++i) {
cout << pd1[i] << " at " << uintptr_t(&pd1[i]) << ";";
cout << pd2[i] << " at " << uintptr_t(&pd2[i]) << endl;
}
delete[]pd1;
delete []pd3;
return 0;
}
输出:
Calling new and placement new:
Memory addresses:
p1->heap: 105553155375632 p2(buffer)->static:4332978176
1000 at 105553155375632;1000 at 4332978176
1020 at 105553155375640;1020 at 4332978184
1040 at 105553155375648;1040 at 4332978192
1060 at 105553155375656;1060 at 4332978200
1080 at 105553155375664;1080 at 4332978208
Calling new and placement new a second time:
Memory addresses:
1000 at 105553155375728;1000 at 4332978176
1040 at 105553155375736;1040 at 4332978184
1080 at 105553155375744;1080 at 4332978192
1120 at 105553155375752;1120 at 4332978200
1160 at 105553155375760;1160 at 4332978208
Calling new and placement new a third time:
Memory contents:
1000 at 105553155375632;1000 at 4332978216
1060 at 105553155375640;1060 at 4332978224
1120 at 105553155375648;1120 at 4332978232
1180 at 105553155375656;1180 at 4332978240
1240 at 105553155375664;1240 at 4332978248
显然,定位运算符new确实将p2放在数组buffer中,p2和buffer的地址都是4332978176。对buffer强制转换为(void*),避免cout输出的是一个字符串而不是一个地址。
第二个定位new运算符使用传递给它的地址,它不会跟踪哪些内存单元已被使用,也不会查找未使用的内存块。
第三个定位new运算符提供了一个数组buffer开头算起的偏移量,使得p2获得了新的内存。
❗️❗️delete不能释放定位new运算符分配的内存,因为delete指向常规new运算符分配的堆内存,而buffer是指向静态内存。
new定位运算符工作原理:只是返回传递给它的地址,并将其转换为void*,以便能够赋给任何指针类型
9.3. 名称空间
在C++中,名称可以是变量、函数、结构、枚举、类以及类和结构的成员。
解决名称空间冲突的问题。
9.3.1 传统的C++名称空间
声明区域:声明所在区域。
潜在作用域:变量的潜在作用域从声明点开始,到其声明区域的结尾。因此,潜在作用域比声明区域小,这是由于变量必须定义后才能使用。
9.3.2 新的名称空间特性
通过定义一个新的声明区域来创建命名的名称空间 ---- 目的:提供一个声明名称的区域。避免名称空间中的名称之间发生冲突。
默认情况下,名称空间中的声明的名称是外部链接。
名称空间可以是全局,也可是另一个名称空间,但不能是位于代码块中。
下面使用新的关键字namespace创建两个名称空间
namespace Jack{
double pail;
void fetch();
int pal;
struct Well{...};
};
namespace Jill{
double bucket(double n){...}
double fetch;
int pal;
struct Hill {...};
};
名称空间可以是全局的,也可以位于另一个名称空间,但不能位于代码块之中(链接性一般为外部的)。
任何名称空间中的名称都不会与其他名称空间中的名称发生冲突,可以共存的。
1. 访问名称空间中的方法
-
通过作用域解析运算符::,使用名称空间来限定使用。
Jack::pail = 12.34;
Jill::Hill mole; //create a type HILL structure;
Jack::fetch(); //use a function
-
C++机制(
using声明
和
using编译指令
)来简化对于名称空间中的名称使用。
- using声明:仅名称空间中的特定的名称可用,通过作用域解析运算符进行。
namespace Jill{
double bucket(double n){...}
double fetch;
int pal;
struct Hill {...};
};
char fetch; //在main()里面被覆盖了,需要作用域解析符
int main(){
using Jill::fetch; //put fetch into local namespace
double fetch; //Error!Already have a local fetch
cin >> fetch; //read a value into Jill::fetch
cin >> ::fetch; //read a value into global fetch
}
在函数的外面使用using声明时,将把名称添加到全局名称空间中,不能覆盖全局变量。
void other();
namespace Jill{
double bucket(double n){...}
double fetch;
int pal;
struct Hill {...};
};
using Jill::fetch; //put fetch into global namespace
int main(){
cin >> fetch; //read a value into Jill::fetch
other();
}
void other(){
cout << fetch; //display Jill::fetch
}
- using编译指令:使整个名称空间中的名称可用。
using namespace std;
编译器不允许同时使用上述两个using声明,因为这将导致二义性:
using Jack::pal;
using Jill::pal;
pal = 4; //which one? now have a conflict
2. using 编译指令和using声明之比较
在下面例子中,名称空间是全局的,如果使用using编译指令导入一个已经在函数中声明的名称,则局部名称将隐藏名称空间名,就像隐藏同名的全局变量:
namespace Jill{
double bucker(double n){...}
double fetch;
struct Hill{...};
}
char fetch;
int main(){
using namespace Jill;
Hill Thrill;
double water = bucket(2);
double fetch; //not an error,hides Jill::fetch and global fetch
cin >> fetch; //read a value into the local fetch
cin >> ::fetch; //read a value into global fetch
cin >> Jill::fetch; //read a value into Jill::fetch
}
int foom(){
Hill top; //ERROR
Jill::Hill crest; //valid
}
一般情况下,使用using声明比使用using编译指令更安全。using编译指令导入所有名称,包括可能并不需要的名称。如果与局部名称发生冲突,则局部名称将覆盖名称空间版本,而编译器并不会发出警告。
名称空间的支持者希望有更多的选择:
//不要这样做
using namespace std;
//应该这样做
int x;
std::cin >> x;
std::cout << x << std::endl;
//或者这样做
using std::cin;
using std::cout;
using std::endl;
int x;
cin >> x;
cout << x << endl;
3. 名称空间的其他特性
可以将名称空间声明进行嵌套
namespace elements{
namespace fire{
int flame;
}
float water;
}
这里,flame指的是element:: fire::flame。同样,可以使用using编译指令使内部的名称可用:
using namespace elements::fire;
另外,也可以在名称空间中使用using编译指令和using声明:
namespace myth{
using Jill::fetch;
using namespace elements;
using std::cout;
using std::cin;
}
假设要访问Jill::fetch,有两种方法:
std::cin >> myth::fetch;
std::cout << Jill::fetch;
//如果没有与之冲突的局部变量,则也可以这样做:
using namespace myth;
cin >> fetch;
using编译指令是可传递的
namespace my_very_favorite_things {...};
//让mvft成为my_very_favorite_things的别名
namespace mvft = my_very_favourite_things;
可以使用别名来简化嵌套名称空间的使用:
namespace MEF = myth::elements::fire;
using MEF::flame;
9.3.3 名称空间示例
下面为头文件:设定了两个名称空间,一个是pers–>包含了Person结构的定义和两个函数的原型。第二个是debts,它定义了一个结构来存储人名和金额,并且让pers中的名称在debts名称空间可用。
#ifndef TEST_NAMESP_H
#define TEST_NAMESP_H
#include
//create the pers and debts namespaces
namespace pers{
struct Person{
std::string fname;
std::string lname;
};
void getPerson(Person &);
void showPerson(const Person&);
}
namespace debts{
using namespace pers; //import all namespace names
struct Debt{
Person name;
double amount;
};
void getDebt(Debt &);
void showDebt(const Debt &);
double sumDebts(const Debt ar[],int n);
}
#endif //TEST_NAMESP_H
第二个文件为与头文件关联的源码文件(rd.name是person类型。)
#include
#include "namesp.h"
namespace pers{
using std::cout;
using std::cin;
void getPerson(Person &rp){
cout << "Enter first name:";
cin >> rp.fname;
cout << "Enter last name:";
cin >> rp.lname;
}
void showPerson(const Person &rp){
std::cout << rp.lname << ", " << rp.fname;
}
}
namespace debts{
void getDebt(Debt &rd){
getPerson(rd.name);
std::cout << "Enter debt:";
std::cin >> rd.amount;
}
void showDebt(const Debt &rd){
showPerson(rd.name);
std::cout << ": $" << rd.amount << std::endl;
}
double sumDebts(const Debt ar[] , int n){
double total = 0;
for (int i = 0; i < n; ++i) {
total += ar[i].amount;
}
return total;
}
}
第三个文件,是执行文件,演示了多种使使名称空间标识符可用的方法
#include
#include "namesp.h"
void other(void);
void another(void);
int main(){
using debts::Debt;
using debts::showDebt;
Debt golf = {{"Benny","Goatsniff"},120.0};
showDebt(golf);
other();
another();
return 0;
}
void other(void){
using std::cout;
using std::endl;
using namespace debts;
Person dg = {"Doodles","Glister"};
showPerson(dg);
cout << endl;
Debt zippy[3];
for (int j = 0; j < 3; ++j) {
getDebt(zippy[j]);
}
for (int j = 0; j < 3; ++j) {
showDebt(zippy[j]);
}
cout << "Total debt:$" << sumDebts(zippy,3) << endl;
}
void another(void){
using pers::Person;
Person collector = {"Milo","Rightshift"};
pers::showPerson(collector);
std::cout << std::endl;
}
输出:
Goatsniff, Benny: $120
Glister, Doodles
Enter first name:Arabella
Enter last name:Binx
Enter debt:100
Enter first name:Cleve
Enter last name:Delaproux
Enter debt:120
Enter first name:Eddie
Enter last name:Fiotox
Enter debt:200
Binx, Arabella: $100
Delaproux, Cleve: $120
Fiotox, Eddie: $200
Total debt:$420
Rightshift, Milo
9.4. 名称空间的一些指导原则
- 使用在已命名的名称空间中声明的变量,而不是使用
外部全局变量或静态全局变量。
- 如果开发了一个
函数库或类库;将其放在一个名称空间中。事实上,C++当前提倡将标准函数库 放在名称空间std中,这种做法扩展到了来自C语言中的函数。例如,头文件math.h 是与C语言 兼容的,没有使用名称空间,但C++头文件cmath应将各种数学库函数放在名称空间std中。实 际上,并非所有的编译器都完成了这种过渡。
- 仅将
编译指令using作为一种将旧代码转换为使用名称空间的权宜之计。
不要在头文件中使用using编译指令。首先,这样做掩盖了要让哪些名称可用;另外,包含头文件的顺序可能影响程序的行为。如果非要使用编译指令using,应将其放在所有预处理器编译指令 #include之后.- 导入名称时,首选使用
作用域解析运算符或using声明的方法。
- 对于
using声明,首选将其作用域设置为局部而不是全局。
第 10 章 对象和类 学习笔记
面向对象编程(OOP)的特性:
- 抽象
- 封装和数据隐藏
- 多态
- 继承
- 代码的可重用性
10.1 过程性和面向对象两种编程的区别
- 过程性编程 首先要考虑遵循的步骤,然后考虑如何表示这些数据(不需要程序一直运行。将数据存储到一个文件中,然后从文件中读取数据)。
- OOP编程 从用户角度考虑对象—描述对象所需要的数据以及描述用户与数据交互所需要的操作。优先考虑数据(需要考虑如何表示数据,还要考虑如何使用数据)
10.2 抽象和类
抽象和简化是处理复杂性问题的方法之一。
抽象是通往用户定义数据类型的捷径,在C++中,用户定义类型指的是 实现抽象接口的类设计。
10.2.1 类型是什么?
指定基本类型的三项工作:
- 决定数据对象需要的内存数量。
- 决定如何解释内存中的位
- 决定可使用数据对象执行的操作或方法
对内置类型有关的操作信息被内置到编译器中,而在C++中用户自定义的类型,则必须自己提供类型信息。
10.2.2 C++中的类
类是一种将抽象转换为用户定义类型的C++工具。将数据表示和操作数据的方法组合成一个包。
一般来说,类规范由两个部分组成:
-
类声明:提供类的蓝图
以数据成员的方式描述数据部分,以成员函数(被称为方法)的方式描述公有接口。
-
类方法定义:提供细节
描述如何实现类成员函数。
接口是一个共享框架,供两个系统交互时使用。
对于类(公共接口)的public 是使用类的程序,交互系统由类对象组成,而接口由编写类的人提供的方法组成。
❗️❗️getline()是istream类的公共接口的组成部分,使用cin的程序不是直接与cin对象内部交互来读取一行输入,而是使用getline();
要使用某个类,必须了解其公共接口;要编写类,必须创建其公共接口。
小Tips:C++程序员将接口(类定义)放在头文件中,将实现(类方法的代码)放在源代码文件中。
下面通过头文件表示一个类:
#ifndef TEST_STOCK00_H
#define TEST_STOCK00_H
#include
class Stock{
private:
std::string company; //存储公司名字
long shares; //持有股票数量
double share_val; //存储了每股的价格
double total_val; //存储了股票的总价格
void set_tot(){
total_val = shares * share_val;
}
public:
void acquire(const std::string &co,long n,double pr); //获得股票
void buy(long num,double price); //增持
void sell(long num,double price); //卖出股票
void update(double price); //更新股票价格
void show(); //显示关于所持有股票的信息
};
#endif //TEST_STOCK00_H
1. 访问控制
publce和private描述对类成员的访问控制。类对象可以直接访问公有部分,但private里面的成员需要通过公有成员函数来访问。private这种隔绝外界的行为被称为数据隐藏(也是一种封装)。
2. 控制对成员的访问:公有还是私有
说明:不必在类声明中使用关键字 private,因为这是类对象的默认访问控制。
类设计尽可能将共有接口与实现细节分开。
- 公有接口表示设计的抽象组件。
- 将实现细节
放在一起并将其与抽象分开称为封装。
- 数据隐藏(将数据放在类的私有部分中)是一种封装。
- 将实现的细节
隐藏在私有部分中。
- 优点:防止直接访问数据,让使用类的用户无需了解数据如何表示。
对于C++程序而言,一般使用类来实现类描述,将结构限制为只表示纯粹的数据对象。
无论类成员是数据成员还是成员函数,都可以在类的公有部分或私有部分中声明使用。但由于隐藏数据是OOP的目标之一,所以数据项一般放在私有部分,组成类接口的成员函数放在公有部分,否则无法从程序中调用这些函数。
10.2.3 实现类成员函数
创建类描述的第二部分:类声明中的原型表示的成员函数提供代码。成员函数与常规函数类似,但有特殊的特征:
-
定义成员函数时,使用
作用域解析运算符(::)
来标识函数所属的类。例如
void Stock::update(double price);
-
类方法可访问类的private组件。
作用域解析运算符确定了方法定义对应的类的身份。
类中的其它成员函数互相使用彼此,不需要解析操作符,而在类声明和方法定义之外使用时,则需要使用。
#include
#include "stock00.h"
void Stock::acquire(const std::string &co, long n, double pr) {
company = co;
if (n < 0) {
std::cout << "Number of shares can't be negative;"
<< company << " shares set to 0.\n";
shares = 0;
} else {
shares = n;
}
share_val = pr;
set_tot();
}
void Stock::buy(long num, double price) {
if (num < 0) {
std::cout << "Number of shares can't be negative;"
<< "Transaction is aborted\n";
} else {
shares += num;
share_val = price;
set_tot();
}
}
void Stock::sell(long num, double price) {
using std::cout;
if (num < 0) {
std::cout << "Number of shares can't be negative;"
<< "Transaction is aborted\n";
} else if (num > shares) {
cout << "You can't sell more than you have!"
<< "Transaction is aborted.\n";
} else {
shares -= num;
share_val = price;
set_tot();
}
}
void Stock::update(double price) {
share_val = price;
set_tot();
}
void Stock::show() {
std::cout << "Company: " << company
<< " Shares: " << shares << '\n'
<< " Share price: $" << share_val
<< " Total Worth: $" << total_val << '\n';
}
定义位于类声明中的函数都将自动称为内联函数,类声明通常将短小的成员函数作为内联函数。也可在类声明之外定义成员函数,通过在类实现部分中定义函数时使用inline限定符使其成为内联函数。
内联函数一般也放在头文件中。
class Stock
{
private:
...
void set_tot(); // 类声明内定义,但会转换为内联函数
public:
...
};
inline void Stock::set_tot() //直接使用inline限定符将其变为它是类Stock的成员函数
{
total_val = shares * shares_val;
}
要使用新类型,最关键是需要了解成员函数的功能,而不必考虑其实现细节。
10.2.4 使用类
下面程序提供了一个使用上述接口和实现文件的程序,它创建了一个名为fluffy_the_cat的Stock对象
#include
#include "stock00.h"
int main(){
Stock fluffy_the_cat;
fluffy_the_cat.acquire("NanoSmart",20,12.50);
fluffy_the_cat.show();
fluffy_the_cat.buy(15,18.123);
fluffy_the_cat.show();
fluffy_the_cat.sell(400,20.00);
fluffy_the_cat.show();
fluffy_the_cat.buy(300000,40.125);
fluffy_the_cat.show();
fluffy_the_cat.sell(300000,0.125);
fluffy_the_cat.show();
return 0;
}
输出:
Company: NanoSmart Shares: 20
Share price: $12.500
Total Worth: $250.00
Company: NanoSmart Shares: 35
Share price: $18.123
Total Worth: $634.31
You can't sell more than you have!Transaction is aborted.
Company: NanoSmart Shares: 35
Share price: $18.123
Total Worth: $634.31
Company: NanoSmart Shares: 300035
Share price: $40.125
Total Worth: $12038904.38
Company: NanoSmart Shares: 35
Share price: $0.125
Total Worth: $4.38
10.2.5 修改实现
上面输出的某个Total Worth数字格式不一致。ostream类包含一些可用于控制格式的成员函数。如setf(),避免科学计数法
std::cout.setf(std::ios_base::fixed,std::ios_base::floatfield);//强制变为定点表示法
下面语句使用定点表示法:
std::cout.precision(3);
所以我们要在show()中使用这些工具来控制格式。但本着修改方法的实现时,不应影响客户程序的其他部分。上述格式修改之后会一直有效的,所以我们在输出结果之后要重置回原来的状态
std::streamsize prec = std::cout.precision(3);
.....
std::cout.precosopm(prec); //reset to old value
std::ios_base::fmtflags orig = std::cout.setf(std::ios_base::fixed);
.....
std::cout.setf(orig,std::ios_base::floatfield); //reset to stored values
简单说明:fmtflags是在ios_base类中定义的一种类型,ios_base类又是命名空间std中定义的。floatfield包含定点表示法和科学表示法。
10.2.6 小结
指定类设计的两个步骤:
-
提供类声明
- 声明私有部分:声明的成员只能通过成员函数进行访问。
- 声明公有部分:声明的成员可被使用类对象的程序直接访问。
//典型的类声明的格式如下
class className{
private:
data member declarations;
public:
member funciton prototypes;
}
通常,数据成员放在私有部分,而成员函数放在公有部分。
-
实现类成员函数 _ 在类声明中提供完整的函数定义、而不是函数原型。
10.3 类的构造函数和析构函数
一般来说,最好在创建对象时对其自动进行初始化。
Stock gift;
gift.buy(10,24.75);
C++提供一种特殊的成员函数 ------> 类构造函数:专门用于构造新对象、将值赋给对应的数据成员。
C++为成员函数提供名称和使用语法,而程序员需要提供方法定义。
⚠️注意:构造函数没有声明类型。
10.3.1 声明和定义构造函数
现在需要创建Stock的构造函数,可以使用默认参数构造函数原型:
Stock(const string&co,long n = 0;double pr = 0.0);
⚠️注意:没有返回类型。
10.3.2 使用构造函数
C++使用构造函数来初始化对象的两种方式:
-
显式调用构造函数
Stock food = Stock("Tencent",20,450);
-
隐式调用构造函数
Stock garment("Furry Mason",50,2.5);
// 与下面的显式调用等价
Stock garment = Stock("Furry Mason",50,2.5);
每次创建类对象(甚至使用new动态分配内存)时,C++都使用类构造函数。
Stock *pstock = new Stock("Electroshoc Games",18,19.0);
构造函数被用来创建对象,而不能通过对象来调用。
10.3.3 默认构造函数
默认构造函数时在未提供显式初始值时,用来创建对象的构造函数。例如:
Stock fluffy_the_cat; //默认构造函数
如果没有提供任何构造函数,则C++将自动提供默认构造函数(隐式版本,不做任何工作)。
默认构造函数没有参数,因为声明中不包含值。当且仅当没有定义任何构造函数时,编译器才会提供默认构造函数。
如果要创建对象,而不显式地初始化,则必须定义一个不接受任何参数的默认构造函数。
定义默认构造函数的方式有两种
-
给已有构造函数的所有参数提供默认值
Stock(const std::string & co = "Error",int n = 0,double pr = 0.0);
-
通过函数重载来定义另一个构造函数 ---- 一个没有参数的构造函数
Stock();
由于只能有一种默认构造函数,所以不能同时采用这两种方式。实际上,通常应初始化所有的对象,以确保所有成员一开始就有已知的合理值。
Stock:Stock(){
company = "no name";
shares = 0;
share_val = 0.0;
total_val = 0.0;
}
❗️❗️在设计类时,通常应提供对所有类成员做隐式初始化的默认构造函数。
创建默认构造函数后,便可以声明对象变量,而不对它们进行显式初始化:
Stock first; //calls default constructor implicitly
Stock first = Stock(); //calls it explicitly
Stock *prelief = new Stock; //calls it implicitly
10.3.4 析构函数
用析构函数创建对象后,程序负责跟踪该对象,直到其过期为止。对象过期时,程序会自动调用一个特殊的成员函数 ---- 析构函数。
析构函数主要是完成清理工作。只需要让编译器生成一个什么都不做的隐式析构函数即可。
析构函数没有参数,在类名前加上 ~,所以其原型必须如下:
~Stock();
析构函数不承担任何重要的工作,所以将它编写为不执行任何操作的函数。
Stock::~Stock()
{
cout<< "Bye, " << company << "\n";
}
析构函数的调用
-
静态存储类对象:在程序结束时自动被调用。
- 被static关键字修饰
-
自动存储类对象:在程序执行完代码块时自动被调用。
- 类似局部变量,自动分配存储初始化以及自动析构清理
-
new创建的对象:将驻留在栈内存或自由存储区,使用delete来释放内存时,将自动被调用。
-
临时对象:将在结束对该对象的使用时自动调用析构函数。
由于类对象过期时析构函数将自动被调用,因此必须有一个析构函数。
如果程序中没有提供析构函数,编译器将隐式地声明一个默认析构函数,并发现导致对象被删除的代码后,提供默认析构函数的定义。
小 Tips:如果既可以通过初始化,也可通过赋值来设置对象的值,则是优先选择初始化方式。
10.3.5 改进Stock类
下面将构造函数和析构函数加入到类和方法的定义中。
1、头文件
将acquire()函数删除了。
#ifndef TEST_STOCK00_H
#define TEST_STOCK00_H
#include
class Stock{
private:
std::string company; //存储公司名字
long shares; //持有股票数量
double share_val; //存储了每股的价格
double total_val; //存储了股票的总价格
void set_tot(){
total_val = shares * share_val;
}
public:
void acquire(const std::string &co,long n,double pr); //获得股票
void buy(long num,double price); //增持
void sell(long num,double price); //卖出股票
void update(double price); //更新股票价格
void show(); //显示关于所持有股票的信息
};
#endif //TEST_STOCK00_H
2.实现文件:
#include "stock10.h"
#include
//constructors
Stock::Stock() {
std::cout << "Default constructor called\n";
company = "no name";
shares = 0;
share_val = 0.0;
total_val = 0.0;
}
Stock::Stock(const std::string &co, long n, double pr) {
std::cout << "Constructor using " << co << " called\n";
company = co;
if (n < 0) {
std::cout << "Number pf shares can't be negative;"
<< company << " shares set to 0.\n";
shares = 0;
}
else{
shares = n;
}
share_val = pr;
set_tot();
}
//class destructor
Stock::~Stock() {
std::cout << "Bye ," << company << ":\n";
}
void Stock::buy(long num, double price) {
if (num < 0) {
std::cout << "Number of shares can't be negative;"
<< "Transaction is aborted\n";
} else {
shares += num;
share_val = price;
set_tot();
}
}
void Stock::sell(long num, double price) {
using std::cout;
if (num < 0) {
std::cout << "Number of shares can't be negative;"
<< "Transaction is aborted\n";
} else if (num > shares) {
cout << "You can't sell more than you have!"
<< "Transaction is aborted.\n";
} else {
shares -= num;
share_val = price;
set_tot();
}
}
void Stock::update(double price) {
share_val = price;
set_tot();
}
void Stock::show() {
using std::cout;
using std::ios_base;
//set format to #.###
ios_base::fmtflags orig = cout.setf(ios_base::fixed, ios_base::floatfield);
std::streamsize prec = cout.precision(3);
cout << "Company: " << company
<< " Shares: " << shares << '\n'
<< " Share price: $" << share_val << '\n';
//set format to #.##
cout.precision(2);
cout << " Total Worth: $" << total_val << '\n';
//restore original formant
cout.setf(orig, ios_base::floatfield);
cout.precision(prec);
}
3.客户文件:
#include
#include "stock10.h"
int main(){
using std::cout;
cout << "Using constructor to crete new objects\n";
Stock stock1("NanoSmart",12,20.0);
stock1.show();
Stock stock2 = Stock("Boffo objects",2,2.0);
stock2.show();
cout << "Assigning stock1 to stock2:\n";
stock2 = stock1;
cout << "Listing stock1 and stock2:\n";
stock1.show();
stock2.show();
cout << "Using a constructor to reset an object\n";
//下面语句不是初始化,而是赋值操作。(创建临时对象)
stock1 = Stock("Nifty Foods",10,50.0);
cout << "Revised stock1:\n";
stock1.show();
cout << "Done\n";
return 0;
}
输出:
Using constructor to crete new objects
Constructor using NanoSmart called
Company: NanoSmart Shares: 12
Share price: $20.000
Total Worth: $240.00
Constructor using Boffo objects called
Company: Boffo objects Shares: 2
Share price: $2.000
Total Worth: $4.00
Assigning stock1 to stock2:
Listing stock1 and stock2:
Company: NanoSmart Shares: 12
Share price: $20.000
Total Worth: $240.00
Company: NanoSmart Shares: 12
Share price: $20.000
Total Worth: $240.00
Using a constructor to reset an object
Constructor using Nifty Foods called
Bye ,Nifty Foods:
Revised stock1:
Company: Nifty Foods Shares: 10
Share price: $50.000
Total Worth: $500.00
//有些编译器可能要过一段时间才删除临时对象,因此析构函数的调用将延迟
Done
Bye ,NanoSmart:
Bye ,Nifty Foods:
4、程序说明
//此语法允许编译器以两种方式执行
Stock stock2 = Stock("Boffo objects",2,2.0);
第一种:使其行为和第一种语法完全相同:
Constructor using Boffo objects called
Company: Boffo objects Shares: 2
❗️第二种:允许调用构造函数来创建一个临时对象,然后将该临时对象复制到stock2,并且丢弃它。如果编译器使用的是这种方式,则将为临时对象调用析构函数,因此生成下面的输出:
Constructor using Boffo objects called
Bye ,Boffo objects:
Company: Boffo objects Shares: 2
6、const成员函数
const成员函数,保证函数不会修改调用对象。C++的解决方法:将const关键字放在函数的括号后面。
void show() const; //声明
void Stock::show() const; //函数定义的开头
只要类方法不修改调用对象,就应该将其声明为const。
对于析构函数来说,可以没有返回类型(连void也没有),也没有参数,其名称为类名称前加上 ~。
10.4. this指针
由于程序无法访问total_val,我们可以使用内联函数返回相应的存储的数据
class Stock{
private:
...
double total_val;
...
public:
double total() const{
return total_val;
...
}
};
this指针指向用来调用成员函数的对象(this被作为隐藏参数传递给方法)。所有的类方法都将this指针设置为调用它的对象的地址。
使用 ->运算符 来访问类成员。
下面我们将两个要比较的对象提供给成员函数topval(),它的原型为:
const Stock & topval(const Stock &s) const;
top = stock1.topval(stock2);
解释原型:最后面的const是保证调用的类方法不会修改调用对象。以const引用传入(保证该函数不会修改被显式访问的对象,如上面的stock2),以const引用传出,提高效率,保证数据完整。

⚠️注意点
- 每个成员函数(包括构造函数和析构函数)都有一个this指针。this指针指向调用对象。如果方法需要引用整个调用对象,则可以直接使用表达式 *this。 在函数的括号后面使用const限定符将this限定为const,此时不能使用this来修改对象的值。
- 由于this是对象的地址,因此返回的不是this,而是对象本身,即 *this(将解除引用运算符 * 用于指针,将得到指针指向的值)。
返回类型为引用意味着返回的是调用对象本身,而不是副本,下面列出了新的头文件
#ifndef TEST_STOCK20_H
#define TEST_STOCK20_H
#include
class Stock{
private:
std::string company;
int shares;
double share_val;
double total_val;
void set_tot(){
total_val = shares * share_val;
}
public:
Stock();
Stock(const std::string &co,long n = 0,double pr = 0.0);
~Stock();
void buy(long num, double price); //增持
void sell(long num, double price); //卖出股票
void update(double price); //更新股票价格
void show();
const Stock &topval (const Stock &s) const;
};
#endif //TEST_STOCK20_H
下面接着列出源文件:
#include "stock20.h"
#include
//constructors
Stock::Stock() {
std::cout << "Default constructor called\n";
company = "no name";
shares = 0;
share_val = 0.0;
total_val = 0.0;
}
Stock::Stock(const std::string &co, long n, double pr) {
std::cout << "Constructor using " << co << " called\n";
company = co;
if (n < 0) {
std::cout << "Number pf shares can't be negative;"
<< company << " shares set to 0.\n";
shares = 0;
}
else{
shares = n;
}
share_val = pr;
set_tot();
}
//class destructor
Stock::~Stock() {
std::cout << "Bye ," << company << ":\n";
}
void Stock::buy(long num, double price) {
if (num < 0) {
std::cout << "Number of shares can't be negative;"
<< "Transaction is aborted\n";
} else {
shares += num;
share_val = price;
set_tot();
}
}
void Stock::sell(long num, double price) {
using std::cout;
if (num < 0) {
std::cout << "Number of shares can't be negative;"
<< "Transaction is aborted\n";
} else if (num > shares) {
cout << "You can't sell more than you have!"
<< "Transaction is aborted.\n";
} else {
shares -= num;
share_val = price;
set_tot();
}
}
void Stock::update(double price) {
share_val = price;
set_tot();
}
void Stock::show() {
using std::cout;
using std::ios_base;
//set format to #.###
ios_base::fmtflags orig = cout.setf(ios_base::fixed, ios_base::floatfield);
std::streamsize prec = cout.precision(3);
cout << "Company: " << company
<< " Shares: " << shares << '\n'
<< " Share price: $" << share_val << '\n';
//set format to #.##
cout.precision(2);
cout << " Total Worth: $" << total_val << '\n';
//restore original formant
cout.setf(orig, ios_base::floatfield);
cout.precision(prec);
}
const Stock & Stock::topval(const Stock &s) const {
if (s.total_val > total_val){
return s;
}
else{
return *this;
}
}
10.5. 对象数组
声明对象数组的方法与声明标准类型数组相同。如:
Stock mystuff[4]; //声明对象数组,其中包含了4个Stock对象的数()
const int STKS = 10;
Stock stocks[STKS] = {
Stock("NanoSmart",12.5,20), //stock[0]
Stock(), //使用构造函数Stock()来初始化stock[1]
Stock("Nanolithic Obelisks",120,3.25) // stock[2]
};
// 使用 Stock(const std::string &co ,long n,double pr)初始化 stock[0] 和 stock[2]。其余的7个元素则使用默认构造函数来进行初始化。
初始化对象数组的方案:
要创建对象数组,则类必须有默认构造函数。
- 使用默认构造函数创建数组元素
- 花括号中的构造函数将创建临时对象
- 将临时对象的内容复制到相应的元素中。
下面程序对4个数组元素进行初始化,显示它们的内容。并找出这些元素中总值最高的一个。
#include
#include "stock20.h"
using namespace std;
const int STKS = 4;
int main(){
Stock stock[STKS] = {
Stock("NanoSmart",12,20.0),
Stock("Boffo Objects",200,2.0),
Stock("Mono Objects",130,3.25),
Stock("Fleep Enterprises",60,6.5)
};
std::cout << "Stock holdings:\n";
int i;
for (i = 0; i < STKS; ++i) {
stock[i].show();
}
//set pointer to first element
const Stock *top = &stock[0];
for (int j = 1; j < STKS; ++j) {
top = &top->topval(stock[j]);
}
//now top points to the most valuable holding
std::cout << "\nMost valuable holding:\n";
top->show();
return 0;
}
输出:
Constructor using NanoSmart called
Constructor using Boffo Objects called
Constructor using Mono Objects called
Constructor using Fleep Enterprises called
Stock holdings:
Company: NanoSmart Shares: 12
Share price: $20.000
Total Worth: $240.00
Company: Boffo Objects Shares: 200
Share price: $2.000
Total Worth: $400.00
Company: Mono Objects Shares: 200
Share price: $2.000
Total Worth: $400.00
Company: Fleep Enterprises Shares: 60
Share price: $6.500
Total Worth: $390.00
Most valuable holding:
Company: Boffo Objects Shares: 200
Share price: $2.000
Total Worth: $400.00
Bye ,Fleep Enterprises:
Bye ,Mono Objects:
Bye ,Boffo Objects:
Bye ,NanoSmart:
c风格设置show()函数
void Stock::show(const Stock *this) {
using std::cout;
using std::ios_base;
//set format to #.###
ios_base::fmtflags orig = cout.setf(ios_base::fixed, ios_base::floatfield);
std::streamsize prec = cout.precision(3);
cout << "Company: " << this->company
<< " Shares: " << this->shares << '\n'
<< " Share price: $" << this->share_val << '\n';
//set format to #.##
cout.precision(2);
cout << " Total Worth: $" << this->total_val << '\n';
//restore original formant
cout.setf(orig, ios_base::floatfield);
cout.precision(prec);
}
10.6 类作用域
在类中定义的名称(如数据成员名和类成员函数名)的作用域都为整个类,作用域为整个类的名称只在该类中已知,在类外不可知。因此可在不同类中使用相同的类成员名称而不会引起冲突。
类作用域意味着不能用外部直接访问类的成员(包括公有成员函数),则必须通过对象来调用公有成员函数。在定义成员函数时,必须使用作用域解析运算符。
Stock sleeper("Exclusive Ore",100,0.25); // 创建对象
sleeper.show();// 使用对象去调用公有成员函数
show(); //不可用,因为不能直接调用方法
// 定义成员函数,使用作用域解析运算符
void Stock::update(double price)
{
......
}
在类声明或成员函数定义中,可使用未修饰的成员名称(未限定的名称),构造函数名称在被调用时,才能被识别(名称与类名称相同)。在其他的情况下,使用类成员名时,必须根据上下文使用直接成员运算符(.)、间接成员运算符(->)或作用域解析运算符(::)。例子:
class Ik
{
private:
int fuss; //有类作用域
public:
Ik(int f = 9){fuss = f;} // fuss在类作用域内
void ViewIk() const;
};
void Ik::ViewIk() const //作用域解析运算符使用
{
std::cout << fuss << std::endl; //fuss在作用域内调用类方法
}
...
int main()
{
Ik * pik = new Ik;
Ik ee = Ik(8); //构造函数在作用域内,则有类名
ee.ViewIk(); // 类对象将ViewIK引入到作用域内(直接成员运算符)
pik -> ViewIk(); // 间接产成员运算符
...
}
10.6.1 作用域为类的常量
使符号常量的作用域为类很有用。例如,类声明可能使用字面值30来制定数组的长度。由于该常量对于所有对象来说都相同,则创建由所有对象共享的常量也不错。你以为如下方式可行:
class Bakery
{
private:
const int months = 12;// 声明常量?直接FAILS
double costs[months];
...
}
❗️直接不可行!!!!原因:声明类只是描述对象的形式,并没有创建对象(创建对象前,将没有用于存储值的空间)。
C++提供了两种方式在类中定义常量:
-
使用关键字static
class Bakery
{
private:
// 直接在声明前使用关键字static,将常量直接与其他静态存储变量存储在一起,而不是存储在对象中
static const int months = 12;
double costs[months];
...
}
-
在类中声明一个枚举
class Bakery
{
private:
//枚举不会创建类数据成员,所有对象不包含枚举,months只是一个符号名称,编译器遇到它时会直接将值替换
enum {months = 12};
double costs[months];
...
}
10.6.2 作用域中枚举
enum egg {Small,Medium,Large,Jumbo};
enum t_shirt {Small,Medium,Large,Jumbo};
上面的语句将无法通过编译,因为它们处在相同的作用域内,如果要避免,那么将枚举的作用域
enum class egg {Small,Medium,Large,Jumbo};
enum class t_shirt {Small,Medium,Large,Jumbo};
在有些情况下,常规枚举将自动转为整型,如将其赋值给int变量或者用于比较表达式时,但是作用域内的枚举不能隐式地转为整型:
enum egg_old {small,medium,large,jumbo};
enum class t_shirt {small,medium,large,Xlarge};
egg_old one = medium;
t_shirt rolf = t_shirt::large;
int king = one;
int ring = rolf; //not allowed ,no implicit type conversion
if(king < jumbo) //allowed
if(king < t_shirt::medium) //not allowed
//必要的时候
int Frodo = int(t_shirt::small); //Frodo set to 0;
10.7. 抽象数据类型
抽象数据类型(Abstract Data Type,ADT):以通用的方式来描述数据类型,而没有引入语言或实现细节。
类很适合用于描述ADT,公有成员函数接口提供了ADT描述的服务,类的私有部分和类方法的代码提供了实现(实现对类的用户隐藏)。
下面通过多文件演示栈(容器,一种更为通用的抽象)
1、头文件
//
// Created by wzybb on 2022/9/7.
//
#ifndef TEST_STACK_H
#define TEST_STACK_H
typedef unsigned long Item;
class stack {
private:
enum {
Max = 10
};
Item items[Max];
int top;
public:
stack();
bool isempty() const;
bool isfull() const;
bool push(const Item &item);
bool pop(Item &item);
void show_stack();
};
#endif //TEST_STACK_H
2、源文件
//
// Created by wzybb on 2022/9/7.
//
#include "stack.h"
#include
stack::stack() {
top = 0;
}
bool stack::isempty() const {
return top == 0;
}
bool stack::isfull() const {
return top == Max;
}
bool stack::push(const Item &item) {
if (top < Max){
items[top++] = item;
return true;
} else{
return false;
}
}
bool stack::pop(Item &item) {
if (top > 0){
item = items[--top];
return true;
}else{
return false;
}
}
void stack::show_stack() {
using std::cout;
using std::endl;
for (int i = 0; i < top; ++i) {
cout << "#" << items[i] << endl;
}
}
3、客户文件
#include
#include "stack.h"
int main() {
using namespace std;
stack st;
char ch;
unsigned long po;
cout << "Please enter A to add a purchase order,\n"
<< "p to process a Po,or Q to quit.\n"
<< "s to show the stack\n";
while (cin >> ch && toupper(ch) != 'Q') {
while (cin.get() != '\n') {
continue;
}
if (!isalpha(ch)) {
cout << '\a';
continue;
}
switch (ch) {
case 'A':
case 'a':
cout << "Enter a Po number to add: ";
cin >> po;
if (st.isfull()) {
cout << "stack already full\n";
} else {
st.push(po);
}
break;
case 'p':
case 'P':
if (st.isempty()) {
cout << "stack already empty\n";
} else {
st.pop(po);
cout << "Po #" << po << " popped\n";
}
break;
case 's':
case 'S':
if (st.isempty()) {
cout << "stack already empty\n";
} else {
st.show_stack();
}
break;
}
cout << "Please enter A to add a purchase order,\n"
<< "p to process a Po,or Q to quit.\n"
<< "s to show the stack\n";
}
cout << "Bye\n";
return 0;
}
输出:
Please enter A to add a purchase order,
p to process a Po,or Q to quit.
s to show the stack
S
stack already empty
Please enter A to add a purchase order,
p to process a Po,or Q to quit.
s to show the stack
A
Enter a Po number to add: 123
Please enter A to add a purchase order,
p to process a Po,or Q to quit.
s to show the stack
A
Enter a Po number to add: 321
Please enter A to add a purchase order,
p to process a Po,or Q to quit.
s to show the stack
A
Enter a Po number to add: 1234567
Please enter A to add a purchase order,
p to process a Po,or Q to quit.
s to show the stack
A
Enter a Po number to add: 3216547
Please enter A to add a purchase order,
p to process a Po,or Q to quit.
s to show the stack
S
#123
#321
#1234567
#3216547
Please enter A to add a purchase order,
p to process a Po,or Q to quit.
s to show the stack
P
Po #3216547 popped
Please enter A to add a purchase order,
p to process a Po,or Q to quit.
s to show the stack
S
#123
#321
#1234567
Please enter A to add a purchase order,
p to process a Po,or Q to quit.
s to show the stack
Q
Bye
第 11 章 使用类
11.1 运算符重载
操作符重载(Operator Overloading)是一种形式的C++多态。
函数重载(函数多态):定义多个名称相同但特征标(参数列表)不同的函数。
函数重载(function overloading)、函数多态(function polymorphism)。
C++允许将运算符重载扩展到用户定义的类型。要重载运算符,需使用被称为运算符函数的特殊函数形式。运算符函数的格式如下:
// op表示要重载的操作符符号,如 operator +()
operator op(argument-list)
// 如:operator []() 数组索引运算符
op必须是有效的C++运算符,不能虚构一个新的操作符号。
假设我们有一个Saleperson类,并为它定义了一个operator+()成员函数,以重载+运算符,以便能够将两个Saleperson对象的销售额相加,则如果district2,sid和sara都是Salesperson类对象,便可以编写这样的等式:
district2 = sid + sara;
操作数是Salesperson类类对象,因此使用相应的运算符函数替换上述运算符:
district2 = sid.operator+(sara);
11.2 计算时间:一个运算符重载示例
如果今天早上Piggs的账户话费了2小时35分钟,下午又花费了2小时40分钟,则总共花了多少时间呢?这个示例与加法概念很吻合,但是相加的单位(小时与分钟混合)与内置类型不匹配,可以重载运算符。
1、头文件
#ifndef TEST_MYTIME0_H
#define TEST_MYTIME0_H
class Time{
private:
int hours;
int minutes;
public:
Time();
Time(int h,int m = 0);
void AddMin(int m);
void AddHr(int h);
void Reset(int h = 0,int m = 0);
Time Sum(const Time &t) const;
void Show()const;
};
#endif //TEST_MYTIME0_H
2、源文件
//
// Created by wzybb on 2022/9/8.
//
#include
#include "mytime0.h"
Time::Time() {
hours = minutes = 0;
}
Time::Time(int h, int m) {
hours = h;
minutes = m;
}
void Time::AddMin(int m) {
minutes+=m;
hours += minutes / 60;
minutes %= 60;
}
void Time::AddHr(int h) {
hours += h;
}
void Time::Reset(int h, int m) {
hours = h;
minutes = m;
}
Time Time::Sum(const Time &t) const {
Time sum;
sum.minutes = minutes + t.minutes;
sum.hours = hours + t.hours + sum.minutes / 60;
sum.minutes %= 60;
return sum;
}
void Time::Show() const {
std::cout << hours << " hours," << minutes << " mintues";
}
思考:为什么参数是引用,但是返回类型却不是引用?
⚠️:因为函数中创建了一个新的对象sum,来表示另外两个Time对象的和。返回对象将创建对象的副本,而调用函数可以使用它。然后返回类型是Time&,则引用的将是sum对象,但由于sum对象是局部变量,在函数结束的时候将被删除,到时候引用将指向一个不存在的对象。
3、客户文件
#include
#include "mytime0.h"
int main(){
using std::cout;
using std::endl;
Time planning;
Time coding(2,40);
Time fixing(5,55);
Time total;
cout << "Planning time = ";
planning.Show();
cout << endl;
cout << "coding time = ";
coding.Show();
cout << endl;
cout << "fixing time = ";
fixing.Show();
cout << endl;
total = coding.Sum(fixing);
cout << "coding.Sum(fixing) = ";
total.Show();
cout << endl;
return 0;
}
输出:
Planning time = 0 hours,0 mintues
coding time = 2 hours,40 mintues
fixing time = 5 hours,55 mintues
coding.Sum(fixing) = 8 hours,35 mintues
11.2.1 添加加法运算符
在添加了加法运算符重载的后,
Time operator+(const Time&t) const;
则可以像Sum()那样调用operator+()方法:
total = coding.operator+(fixing);
也可以使用运算符表示法:
total = coding + fixing;
总而言之,operator+()函数的名称使得可以使用函数表示法或者运算符表示法来调用它。编译器将根据操作数的类型来确定如何做:
int a,b,c;
Time A,B,C;
c = a + b;//use int addition
C = A + B;//use addition as defined for Time objects
可以将两个以上的对象相加,例如:
//first step
t4 = t1 + t2 + t3;
//second step
t4 = t1.operator(t2+t3);
//third step
t4 = t1.operator(t2.operator+(t3));
11.2.2 重载限制
- 重载后的运算符必须至少有一个是用户定义的类型。目的:防止用户对标准类型重载运算符。
- 使用运算符时,不能违反运算符原来的句法规则。不能改变优先级。
- 不能创建新运算符。如: operator **() 函数表示求幂(❌不允许)
- **
不能重载**下面的运算符
sizeof运算符成员运算符(.)成员指针运算符(.*)作用域解析运算符(::)条件运算符(:?)- 一个
RTTI运算符(typeid)
- 强制类型转换运算符(
const_cast、dynamic_cast、reinterpret_cast、static_cast)。
- 只能通过
成员函数重载的操作符
赋值运算符(=)函数调用运算符(())下标运算符([])- 通过
指针访问类成员的运算符(->)
11.2.3 其他重载运算符
将常见的操作符进行重载,具体例子:
函数声明:
Time operator+(const Time &t)const;
Time operator-(const Time &t)const;
Time operator*(double n)const;
函数定义:
Time Time::operator+(const Time &t)const{
Time sum;
sum.minutes = (minutes + t.minutes) % 60;
sum.hours = hours + (minutes + t.minutes) / 60 + t.hours;
return sum;
}
Time Time::operator-(const Time &t)const{
Time diff;
int tot1,tot2;
tot1 = t.minutes + 60*t.hours;
tot2 = minutes + 60 * hours;
diff.minutes = (tot2 - tot1) % 60;
diff.hours = (tot2 - tot1) / 60;
return diff;
}
Time Time::operator*(double mult)const{
Time result;
long totalminutes = hours * mult * 60 + minutes * mult;
result.hours = totalminutes / 60;
result.minutes = totalminutes % 60;
return result;
}
实现:
#include
#include "mytime1.h"
int main(){
using std::cout;
using std::endl;
Time weeding(4,35);
Time waxing(2,47);
Time total;
Time diff;
Time adjusted;
cout << "weeding time = ";
weeding.Show();
cout << endl;
cout << "waxing time = ";
waxing.Show();
cout << endl;
cout << "total work time = ";
total = weeding + waxing; //use operator+()
total.Show();
cout << endl;
diff = weeding - waxing;
cout << "weeding time - waxing time =";
diff.Show();
cout << endl;
adjusted = total * 1.5;
cout << "adjusted work time = ";
adjusted.Show();
cout << endl;
return 0;
}
输出:
weeding time = 4 hours,35 mintues
waxing time = 2 hours,47 mintues
total work time = 7 hours,22 mintues
weeding time - waxing time =1 hours,48 mintues
adjusted work time = 11 hours,3 mintues
11.3 友元简介
C++提供另外一种形式的访问权限:友元。友元有3种:
- 友元函数
- 友元类
- 友元成员函数
通过让函数成为类的友元,可以赋予该函数与类的成员函数系统的访问权限。
在为类重载二元运算符时(带两个参数的运算符)常常需要友元。
A = 2.75 * B; // can't correspond to a member function
从概念上说,2.75B应与B2.75相同,但第一个表达式不对应于成员函数,因为2.75不是Time类型对象。记住,左侧的操作数应是调用对象。
解决这个问题的方式:非成员函数。
Time operator*(double m,const Time &t);
A = operator*(2.75,B);
对于非成员重载运算符函数来说,运算符表达式左边的操作数对应于运算符函数的的第一个参数,运算符表达式右边的操作数对应于运算符函数的第二个参数,而原来的成员函数则按相反的顺序处理操作数。
通过友元函数,可以让非成员函数也可与类成员函数相同的访问权限。
11.3.1 创建友元
-
创建原型
创建友元函数,将其原型放在类声明中,并在原型声明前加上关键字 friend:
friend Time operator * (double m,const Time & t)
/** operator*() 函数是在类声明中声明的,但不是成员函数,因此不能使用成员运算符来调用
* operator*() 函数不是成员函数,但它与成员函数的访问权限相同
*/
-
编写函数定义 因不是成员函数,所以不需要使用 Time:: 限定符。不要在定义中使用关键字 friend。
Time operator*(double m, const Time & t) // 友元不用在函数定义中使用
{
Time result;
long totalminutes = t.hours * mult * 60 + t.minutes * mult;
result.hours = totalminutes / 60;
result.minutes = totalminutes % 60;
return result;
}
11.3.2 常用的友元:重载 << 运算符
<<运算符是C和C++的位运算符,将值中的位左移。ostream类对该运算符进行重载,将其转换为一个输出工具。ostream类声明中都包含相应的重载的 operator<<()定义。
要使cout能够识别Time对象,一种方式是将一个函数运算符定义添加到ostream类声明中,修改iostream文件是个危险的注意,这样做会在标准接口上浪费时间。
相反,通过Time类声明来让Time类知道如何使用cout。
- <<的第一种重载版本
要使Time类知道使用cout,必须使用友元函数,通过下面的语句解说:
//第一个是ostream类对象(cout);
cout << trip;
如果使用一个Time成员函数来重载<<,Time对象将是第一个操作数,就像使用成员函数重载*运算符那样,这意味着必须这样使用<<;
trip << cout; //if operator() were a Time member function,invalid
通过使用友元函数,可以像下面这样重载运算符:
void operator<<(ostream &os,const Time &t){
os << t.hours << " hours," << t.minutes << " minutes";
}
有了上面的语句,我们可以使用下面的语句
cout << trip;
operator<<()直接访问了Time对象的私有成员,所以它必须是Time类的友元,但由于它并不直接访问ostream对象的私有成员,所以并不一定必须是ostream类的友元。
- << 的第二种重载版本
第一种重载版本,对于下面的语句是无法实现的:
cout << "Trip time:" << trip << " (Tuesday)\n";
我们通过分析以下语句来了解上面语句不可行的原因以及解决措施:
(cout << x) << y;
cout << x 在 << y左侧,所以输出语句也要求cout << x是一个ostream类型对象。因此,ostream类将operator<<()函数实现为返回一个指向ostream对象的引用(这里是指cout)。
这样我们只要修改operator<<()函数即可:
ostream & operator <<(ostream & os, const c_name & obj)
{
os << ...; // 显示内容
return os;
}
⚠️警告:只有在类声明中的原型才能使用 friend 关键字。除非函数定义也是原型,否则不能在函数定义中使用该关键字。
下面程序是对上面的头文件的类定义进行修改:
#ifndef TEST_MYTIME0_H
#define TEST_MYTIME0_H
class Time{
private:
int hours;
int minutes;
public:
Time();
Time(int h,int m = 0);
void AddMin(int m);
void AddHr(int h);
void Reset(int h = 0,int m = 0);
friend Time operator*(double m,const Time &T){return t * m };
friend std::ostream &operator<<(std::ostream &os,const Time &t);
void Show()const;
};
#endif //TEST_MYTIME0_H
源文件:
.....
std::ostream &operator<<(std::ostream &os,const Time &t){
os << t.hours << " hours, " << t.minutes << " minutes";
}
.....
11.4 重载运算符:作为成员函数还是非成员函数
对于很多运算符来说,可选择使用成员函数或非成员函数来实现运算符重载。而非成员函数则必须是友元函数才能访问类的私有数据。
// ---------------- Time 类 --- 注意:加法属于二元操作符(需要两个操作数)-----
Time operator+(const Time & t) const; //成员函数版本(一个操作数通过this指针隐式磁道没,而另一个则是作为函数参数显式传递)
friend Time operator+(const Time & t1,const Time & t2);// 非成员函数版本(友元函数,两个操作数都是作为参数传递)
⚠️注意:非成员版本的重载运算符函数所需的形参数目与运算符使用的操作数数目相同;而成员函数所需的参数数目少一个,因为其中的一个操作数是被隐式地传递的调用对象。
T1 = T2 + T3;
T1 = T2.operator+(T3); // 成员函数格式
T1 = operator+(T2,T3); //非成员函数格式
⚠️注意:在定义运算符是,必须选择其一,而不能同时选择两种格式,否则会出现二义性,从而导致编译错误。
4. 重载示例:矢量类
使用运算符重载和友元的类设计 ----- 一个表示矢量的类。
矢量(vector)是工程和物理中使用的一个术语,是有大小和方向的量。计算机科学版本的 vector模板类在 第 16 章。
- 可以使用大小(长度)和方向(角度)描述矢量;
- 可以用分量x和y表示矢量
下面程序列出了Vector这个类声明,为复习名称空间。该清单将类声明放在Vector名称空间中,
1、头文件
#ifndef TEST_VECTOR_H
#define TEST_VECTOR_H
#include
namespace VECTOR{
class Vector{
public:
enum Mode{RECT,POL};
private:
double x;
double y;
double mag; //length of vector
double ang; //direction of vector in degrees
Mode mode; //RECT OR POL
//private methods for setting values
void set_mag();
void set_ang();
void set_x();
void set_y();
public:
Vector();
Vector(double n1,double n2,Mode form = RECT);
void reset(double n1,double n2,Mode form = RECT);
~Vector();
double xval()const{return x;}
double yval()const{return y;}
double magval()const{return mag;}
double angval()const{return ang;}
void polar_mode();
void rect_mode();
//operator overloading
Vector operator+(const Vector &b)const;
Vector operator-(const Vector &B)const;
Vector operator-()const;
Vector operator*(double n)const;
//friends
friend Vector operator*(double n,const Vector&a);
friend std::ostream &operator<<(std::ostream &os,const Vector&v);
};
}
#endif //TEST_VECTOR_H
2、源文件
#include "Vector.h"
#include
using std::sqrt;
using std::sin;
using std::cos;
using std::atan;
using std::atan2;
using std::cout;
namespace VECTOR {
//compute degrees in one radian
const double Rad_to_deg = 45.0 / atan(1.0);//atan(1.0) = pi/4
//should be about 57.2957795130823
//private methods
//calculates magnitude from x and y
void Vector::set_mag() {
mag = sqrt(x * x + y * y);
}
void Vector::set_ang() {
if (x == 0.0 && y == 0.0) {
ang = 0.0;
} else {
ang = atan2(y, x);
}
}
//set x from polar coordinate
void Vector::set_x() {
x = mag * cos(ang);
}
//set y from polar coordinate
void Vector::set_y() {
y = mag * sin(ang);
}
//public methods
Vector::Vector() {
x = y = ang = 0.0;
mode = RECT;
}
//construct vector from rectangular coordinates if form is r
//(the default) or else from polar coordinates if form is p
Vector::Vector(double n1, double n2, Mode form) {
mode = form;
if (form == RECT) {
x = n1;
y = n2;
set_mag();
set_ang();
} else if (form == POL) {
mag = n1;
ang = n2 / Rad_to_deg;
set_x();
set_y();
} else {
cout << "Incorrect 3rd argument to Vector() ";
cout << "Vector set to 0\n";
x = y = mag = ang = 0.0;
mode = RECT;
}
}
//reset vector from rectangular coordinates if form is RECT(the default)
//or else from polar coordinates if form is POL
void Vector::reset(double n1, double n2, Mode form) {
mode = form;
if (form == RECT) {
x = n1;
y = n2;
set_mag();
set_ang();
} else if (form == POL) {
mag = n1;
ang = n2 / Rad_to_deg;//Rad_to_deg 为1弧度,这是弧度转为角度的公式
set_x();
set_y();
} else {
cout << "Incorrect 3rd argument to Vector()--";
cout << "vector set to 0\n";
x = y = mag = ang = 0.0;
mode = RECT;
}
}
Vector::~Vector() { }
void Vector::polar_mode() {
mode = POL;
}
void Vector::rect_mode() {
mode = RECT;
}
//operator overloading
//add two vectors
Vector Vector::operator+(const Vector &b) const {
return Vector(x + b.x, y + b.y);
}
//subtract vector b from a
Vector Vector::operator-(const Vector &B) const {
return Vector(x - B.x, y - B.y);
}
//reverse sign-of vector
Vector Vector::operator-() const {
return Vector(-x, -y);
}
//multiply vector by n
Vector Vector::operator*(double n) const {
return Vector(n * x, n * y);
}
//friend methods
//multiply n by vector a
Vector operator*(double n, const Vector &a) {
return a * n;
}
//display rectangular coordinates if mode is RECT,
//else display polar coordinates if mode is POL
std::ostream &operator<<(std::ostream &os, const Vector &v) {
if (v.mode == Vector::RECT) {
os << "(x,y) = (" << v.x << ", " << v.y << ")";
} else if (v.mode == Vector::POL) {
os << "(m,a) = (" << v.mag << ", "
<< v.ang * Rad_to_deg << ")";
}else{
os << "Vector object mode is invalid";
}
return os;
}
}
假设shove是一个Vector对象,如果编写以下的代码:
shove.reset(100,300);
由于默认构造函数已经初始化了mode的值为RECT,所以reset()的第三个参数省略是没有错误的。
11.5.1 使用状态成员
显然,Vector类存储了矢量的直角坐标和极坐标。它使用名为mode的成员来控制使用构造函数、reset()方法等等。枚举RECT、POL这样的成员被称为状态成员(state member)
Vector foolery(20.0,30.0,VECTOR::Vector::POL);//VALID
//由于2等证书不能隐式地转换为枚举类型:
Vector rector(20.0,30.0,2);//INVALID
Vector rector(20.0,30.0,VECTOR::Vector::Mode(2))//VALID
由于operator<<()是一个友元函数,而不在类作用域内,因此必须使用Vector::RECT,由于友元函数在名称空间VECTOR中,因此无需使用全限定名VECTOR::Vector::RECT
std::ostream &operator<<(std::ostream &os, const Vector &v) {
if (v.mode == Vector::RECT) {
os << "(x,y) = (" << v.x << ", " << v.y << ")";
} else if (v.mode == Vector::POL) {
os << "(m,a) = (" << v.mag << ", "
<< v.ang * Rad_to_deg << ")";
}else{
os << "Vector object mode is invalid";
}
return os;
}
11.5.2 为Vector类重载算术运算符
在使用x,y坐标时,将两个矢量相加即可,俩x的分量相加,俩y的分量相加。根据这种描述,直接写出来的代码可能如下:
Vector Vector::operator+(const Vector &b) const{
Vector sum;
sum.x = x + b.x;
sum.y = y + b.y;
sum.set_ang();
sum.set_mag();
return sum;
}
但是呢,使用构造函数来完成这种工作,更简单可靠;
11.5.4 使用Vector类来模拟随机漫步(Drunkard Walk problem)
下面的程序允许用户选择行走的距离和步长。该程序用一个变量来表示位置(一个矢量),并报告到达指定距离处所需的步数。可以看到,行走者前进得相当慢。虽然走了1000步,每步的距离为2英尺,但离起点可能只有50英尺。这个程序将行走者所走的净距离除以步数,来指出这种行走方式的低效性。随即改变方向使得该平均值远远小于步长。为了随机选择方向,该程序使用了标准库函数rand(),srand(),time()
#include
#include
#include
#include "Vector.h"
int main(){
using namespace std;
using VECTOR::Vector;
srand(time(0));//seed random number generation
double direction;
Vector step;
Vector result(0.0,0.0);
unsigned long steps = 0;
double target;
double dstep;
cout << "Enter target distance(q to quit):";
while (cin >> target){
cout << "Enter step length:" ;
if (!(cin >> dstep)){
break;
}
while (result.magval() < target){
direction = rand() % 360;
step.reset(dstep,direction,Vector::POL);
result = result + step;
steps++;
}
cout << "After " << steps << " steps,the subject "
"has the following location:\n";
cout << result << endl;
result.polar_mode();
cout << " or\n" << result << endl;
cout << "Average outward distance per step = "
<
11.6. 类的自动转换和强制类型转换
将一个标准类型变量的值赋给另一种标准类型的变量时,如果两种类型兼容,则C++自动将该值转换为接收变量的类型。但是也会伴随精度丢失的情况发生。
int side = 3.33;
下面程序将磅转为英石的程序改为类的形式。
#ifndef TEST_STONE_H
#define TEST_STONE_H
class Stonewt{
private:
enum {Lbs_per_stn = 14}; //pounds per stone
int stone; //whole stones
double pds_left; //fractional pounds
double pounds; //entire weight in pounds
public:
Stonewt(double lbs); //for double pounds
Stonewt(int stn,double lbs); //for stone ,lbs
Stonewt();
~Stonewt();
void show_lbs()const;
void show_stn()const;
};
#endif //TEST_STONE_H
下面列出类方法具体的实现:
#include "stone.h"
#include
using std::cout;
//construct Stonewt object from double value
Stonewt::Stonewt(double lbs) {
stone = int(lbs) / Lbs_per_stn;
pds_left = int(lbs) % Lbs_per_stn;
pounds = lbs;
}
//construct Stonewt object from stone,double values
Stonewt::Stonewt(int stn,double lbs) {
stone = stn;
pds_left = lbs;
pounds = stn * Lbs_per_stn + lbs;
}
Stonewt::Stonewt() {
stone = pounds = pds_left = 0;
}
Stonewt::~Stonewt() { }
void Stonewt::show_stn() const {
cout << stone << "stone, " << pds_left << " pounds\n";
}
void Stonewt::show_lbs() const {
cout << pounds << " pounds\n";
}
在c++中,接受一个参数的构造函数将类型与该参数相同的值转换为类提供了蓝图。也就是说,可以编写以下代码:
Stone myCat;
myCat = 19.6;
解释:程序员使用构造函数Stonewt(double)来创建一个临时的Stonewt对象,并将19.6作为初始值。这一过程是隐式转换。
下面程序使用了类的构造函数初始化一些Stonewt对象,并处理类型转换。
#include
#include "stone.h"
using std::cout;
void display(const Stonewt&st,int n);
int main(){
Stonewt incognito = 275; //use constructor to initialize
Stonewt wolfe(285.7);
Stonewt taft(21,8);
cout << "The celebrity weighed ";
incognito.show_stn();
cout << "The detective weighed ";
wolfe.show_stn();
cout << "The President weighed ";
taft.show_lbs();
incognito = 276.8;
taft = 325;
cout << "After dinner,the celebrity weighed ";
incognito.show_stn();
cout << "After dinner,the President weighed ";
taft.show_lbs();
display(taft,2);
cout << "The wrestler weighed even more.\n";
display(422,2);
cout << "No stone left unearned\n";
return 0;
}
void display(const Stonewt &st,int n){
for (int i = 0; i < n; ++i) {
cout << "Wow! ";
st.show_stn();
}
}
输出:
The celebrity weighed 19stone, 9 pounds
The detective weighed 20stone, 5 pounds
The President weighed 302 pounds
After dinner,the celebrity weighed 19stone, 10 pounds
After dinner,the President weighed 325 pounds
Wow! 23stone, 3 pounds
Wow! 23stone, 3 pounds
The wrestler weighed even more.
Wow! 30stone, 2 pounds
Wow! 30stone, 2 pounds
No stone left unearned
请注意下面的语句:
void display(const Stonewt &st,int n); //函数原型
display(422,2); //convert 422 to double,then to Stonewt
在无法完成自动转换时,可以使用强制类型转换。
-
隐式转换
//使用构造函数创建一个临时对象并初始化,然后采用逐成员赋值的方式将临时对象的内容复制到myCat中,这种方式称为隐式转换。
Stonewt(double lbs);
Stonewt myCat;
myCat = 19.6;
// 只有接受一个参数的构造函数才能作为转换函数
隐式转换是自动进行,而不需要显式强制类型转换。
-
显式转换
将构造函数用于自动类型转换会出现意外情况,所以C++新特性使用 关键字 explicit 来关闭自动特性。
// 声明构造函数的格式
explicit Stonewt(double lbs); //不隐式转换(显式转换)
只接受一个参数的构造函数定义了从参数类型到类类型的转换。如果在声明中使用关键字 explicit,则只用于显式强制类型转换。否则会用于如下的隐式转换。(避免存在二义性)
- 将Stonewt对象初始化为doubel值时
- 将double值赋给Stonewt对象时。
- 将double值传递给接受Stonewt参数的函数时。
- 上述任一情况下,使用可转换为double类型的内置类型时。
11.6.1 转换函数
由上述可知,可以将数字转换为Stonewt对象,那有没有可能做相反的转换呢?如下面语句:
Stonewt wolfe(285.7);
double host = wolfe;
C++运算符函数 ----- 转换函数:用户自定义的强制类型转换,可进行类似使用内置强制类型转换一样的方式。这样可以做如下转换:
Stonewt wolfe(285.7);
double host = double (wolfe);
double thinker = (double) wolfe;
也可以让编译器自己来决定如何做(前提是要提前定义与此匹配的转换函数):
Stone wells(20,3);
double star = wells; //implicit use of conversion function
⚠️转换函数的注意点:
- 必须是类方法:需要通过类对象来调用,从而告知函数要转换的值。
- 不能指定返回类型
- 不能有参数
operator typeName(); // typeName指要转换成的类型
operator double(); //转换为double类型的函数原型
下面为具体的例子:
class Stonewt{
private:
....
public:
....
//conversion functions
operator int()const;
operator double()const;
}
成员函数定义:
Stonewt::operator int()const{
return int(pounds + 0.5);
}
Stonewt::operator double()const{
return pounds
}
具体实现:
Stonewt popins(9,2.8);
double p_wt = poppins;//128.8
cout << "Popins:" << int(poppins) << " pounds.\n";//129
转换函数没有返回类型、没有参数、但必须返回转换后的值(虽然没有声明返回值的类型)
如果将int(poppins)和cout一起使用,假设省略了显式强制类型转换,可行不?
cout << "Popins:" << poppins << " pounds.\n";//129
答案是不可行的,但是如果只定义了double转换函数,则编译器将接受该语句。
⚠️⚠️:转换函数也有缺点,提供执行自动、隐式转换的函数所存在的问题是:在用户不希望进行转换的时候,转换函数也有可能转换。例如:
int ar[20];
...
Stonewt temp(14,5);
...
int Temp = 1;
...
cout << ar[temp] << "!\n";
由于Stonewt类定义了一个operator int(),因此Stonewt对象temp转换为int 200,并用作数组索引。
C++为类提供的类型转换
- 只有
一个参数的类构造函数用于将类型与该参数相同的值转换为类类型。在构造函数声明中使用 explicit可防止隐式转换,而只允许显式转换。
- 被称为
转换函数的特殊类成员运算符函数,用于将类对象转换为其他类型。
11.6.2 转换函数和友元函数
在Time类中指出过,可以使用成员函数或者友元函数重载加法(复习):
Stonewt Stonewt::operator+(const Stonewt &st)const{
double pds = pounds + st.pounds;
Stonewt sum(pds);
return sum;
}
Stonewt Stonewt::operator+(const Stonewt &st1,const Stonewt &st2){
double pds = st1.pounds + st2.pounds;
Stonewt sum(pds);
return sum;
}
上面任何格式都允许这样做:
Stonewt jennySt(9,12);
Stonewt bennySt(12,8);
Stonewt total;
total = jennySt + bennySt;
如果有Stonewt(double)构造函数,也可以这样做:
Stonewt jennySt(9,12);
double kennyD = 176.0;
但只有友元函数才允许这样做:
total = kennyD + jennySt;
这个时候不能定义operator double()成员函数,不然会造成二义性:不是将kennyD转换为double并执行Stonewt加法,会将jennySt转换为double并执行double加法
❗️❗️如果程序经常需要将double值与Stonewt对象相加,则重载加法更适合,如果程序只是偶尔使用这种加法,则依赖自动转换更加简单,但为了保险,可以使用显式转换。
第 12 章 类和动态内存分配
12.1 动态内存和类
C++中使用 new 和 delete 运算符来动态控制内存,析构函数不可缺少,否则会导致很多新的编程问题的出现。有时必须重载赋值运算符,从而保证程序正常运行。
12.1.1 复习示例和静态类成员
我们通过一个这样的程序来复习new和delete:使用一个新的存储类型:静态类成员。首先设计一个StringBad类,然后设计一个功能稍强的String类,StringBad和String类对象将包含一个字符串指针和表示字符串长度的值,构造函数和析构函数调用的时候将显示一些消息。
1、StringBad头文件
#include
#ifndef TEST_STRNGBAD_H
#define TEST_STRNGBAD_H
class StringBad{
private:
char* str; //pointer to string
int len; //length of string
static int num_strings; //number_of_objects
public:
StringBad(const char*s); //constructor
StringBad(); //default constructor
~StringBad(); //destructor
//friend function
friend std::ostream &operator<<(std::ostream &os,const StringBad &st);
};
#endif //TEST_STRNGBAD_H
对于这个头文件,需要注意两个点。首先,它使用char指针(而不是char数组)来表示姓名。这意味着类声明没有为字符串本身分配存储空间,而是在构造函数中使用new来为字符串分配空间。这避免了在类声明中预先定义字符串长度。
2、源文件
#include "strngbad.h"
#include
using std::cout;
//initializing static class member
int StringBad::num_strings = 0;
//class methods
//construct StringBad from C string
StringBad::StringBad(const char *s) {
len = std::strlen(s); //set size
str = new char[len + 1]; //allot storage
std::strcpy(str,s); //initialize pointer
num_strings++;
cout << num_strings << ":\"" << str << "\" object created\n";
}
StringBad::StringBad() { //default constructor
len = 4;
str = new char[4];
std::strcpy(str,"c++");
num_strings++;
cout << num_strings << ":\"" << str << "\" default object created\n";
}
StringBad::~StringBad() { //necessary destructor
cout << "\"" << str << "\" object deleted,";
--num_strings;
cout << num_strings << " left\m";
delete []str;
}
std::ostream & operator<<(std::ostream &os,const StringBad &st){
os << st.str;
return os;
}
对于程序中的拷贝构造函数,使用strlen()函数计算字符串的长度,但不包括末尾的空字符,所以开辟空间时需要len+1大小。而后使用strcpy()将传递的字符串复制到新的内存中,
❗️❗️字符串单独保存在堆内存中,对象仅保存了指出哪里查找字符串的信息。
//这只保存了地址,并没有创建字符串副本
str = s;
3、下面为客户程序:
该程序将对象声明放在一个内部代码块中,因为析构函数将在定义对象的代码块执行完毕时调用。如果不这样做,析构函数默认是在main()函数执行完毕的时候才会调用,这样就看不到要显示的消息了。
#include
using std::cout;
#include "strngbad.h"
void callme1(StringBad &); //pass by reference
void callme2(StringBad); //pass by value
int main(){
using std::endl;
{
cout << "Starting an inner block.\n";
StringBad headline1("Celery Stalks at Midnight");
StringBad headline2("Lettuce Prey");
StringBad sports("Spinach Leaves Bowl for Dollars");
cout << "headline1:" << headline1 << endl;
cout << "headline2:" << headline2 << endl;
cout << "sports:" << sports << endl;
callme1(headline1);
cout << "headline1:" << headline1 << endl;
callme2(headline2);
cout << "headline2:" << headline2 << endl;
cout << "Initialize one object to another:\n";
StringBad sailor = sports;
cout << "sailor:" << sailor << endl;
cout << "Assign one object to anohter:\n";
StringBad knot;//default constructor
knot = headline1;
cout << "knot:" << knot << endl;
cout << " Exiting the block.\n";
}
cout << "End of main()\n";
}
void callme1(StringBad &rsb){
cout << "String passed by reference:\n";
cout << " \"" << rsb << "\"\n";
}
void callme2(StringBad sb){
cout << "String passed by value:\n";
cout << " \"" << sb << "\"\n";
}
输出:
test(76941,0x1051c4580) malloc: *** error for object 0x600000819120: pointer being freed was not allocated
test(76941,0x1051c4580) malloc: *** set a breakpoint in malloc_error_break to debug
Starting an inner block.
1:"Celery Stalks at Midnight" object created
2:"Lettuce Prey" object created
3:"Spinach Leaves Bowl for Dollars" object created
headline1:Celery Stalks at Midnight
headline2:Lettuce Prey
sports:Spinach Leaves Bowl for Dollars
String passed by reference:
"Celery Stalks at Midnight"
headline1:Celery Stalks at Midnight
String passed by value:
"Lettuce Prey"
"Lettuce Prey" object deleted,2 left
headline2:0��.i�
Initialize one object to another:
sailor:Spinach Leaves Bowl for Dollars
Assign one object to anohter:
3:"c++" default object created
knot:Celery Stalks at Midnight
Exiting the block.
"Celery Stalks at Midnight" object deleted,2 left
"Spinach Leaves Bowl for Dollars" object deleted,1 left
" ��.i�" object deleted,0 left
如下语句出现了严重的问题:
callme(headline2);
cout << "headline2:" << headline2 << endl;
输出:
String passed by value:
"Lettuce Prey"
"Lettuce Prey" object deleted,2 left
headline2:0��.i�
❗️❗️这里的callme2()按值传递headline2,而headline2作为函数参数来传递时,会产生一个临时对象,它和原始对象的指针是指向同块内存空间的。而这个临时对象在当前函数结束的时候,会调用析构函数,释放该临时对象指针指向的内存,到时候主函数结束的时候,原始对象也会调用析构函数,重复释放了内存。
在析构sports的时候,出现了异常。对于sports,程序只使用它来初始化sailor,但这种操作修改了sports。最后被删除的两个headline对象已经无法识别。这些字符串在被删除之前,有些操作被它们搞乱了。
通过排查我们发现下面语句有问题:
StringBad sailor = sports;
这使用了我们声明和定义之外的构造函数,它等价于下面语句:
StringBad sailor = StringBad(sports);
右值对应的构造函数原型为:
StringBad(const StringBad &);
❗️❗️当使用一个对象来初始化另一个对象的时候,编译器将会自动生成拷贝构造函数。
12.1.2 特殊成员函数
StringBad类的问题是由特殊成员函数引起的。这些成员函数是自动定义的,就StringBad而言,这些函数的行为与类设计不符。
C++提供的隐式成员函数:
-
默认构造函数,如果没有定义构造函数
如果没有提供任何构造函数,C++将创建默认构造函数。
StringBad::StringBad() {} // 隐式默认构造函数
编译器将提供一个不接受任何参数、也不执行如何操作的构造函数(默认的默认构造函数)。
如果希望在创建对象时不显式地对它进行初始化,则必须显式定义默认构造函数。
Klunk::Klunk(){} // implicit default constructor
Klunk::Klunk(){ // explict default constructor
klunk_ct = 0;
}
带参数的默认构造函数,只要所有的参数都有默认值:
Klunk(int n = 0){ klunk_ct = n;}
-
默认析构函数,如果没有定义
-
拷贝构造函数,如果没有定义
-
定义
拷贝构造函数用于将一个对象复制到新创建的对象中。用于初始化过程中(包括按值传递),而不是常规的赋值过程。类的拷贝构造函数的原型如下:
Class_name(const Class_name &); //接收一个指向对象的常量引用作为参数
-
何时调用?
每当程序生成对象副本时,编译器都会使用拷贝构造函数。常见的情况:
- 当函数按值传递对象时
- 当函数返回对象时
- 当编译器生成临时对象时
-
默认的拷贝构造函数的功能
默认的复制构造函数逐个复制非静态成员(成员复制,也称为浅拷贝),复制的是成员的值。
⚠️警告:如果类中包含了使用new初始化的指针成员,应当定义一个拷贝构造函数,以复制指向的数据,而不是指针。这种称为深拷贝。浅拷贝只拷贝指针值(拷贝指针信息)

-
赋值运算符,如果没有定义
-
定义和原型函数
C++允许类对象赋值,通过自动为类重载复制运算符来实现。函数原型如下:
Class_name & Class_name::operator=(const Class_name &);
-
赋值运算符的作用
解决默认赋值运算符不合适导致的问题。
-
实现赋值运算符(进行深拷贝)的注意点:
-
目标对象可能引用以前分配的数据,所以函数应使用 delete[] 来释放数据。
- 原因:防止内存泄漏
-
函数应当避免将对象赋值给自身。
-
原因:给对象重新赋值时,释放内存操作可能删除对象的内存。
-
StringBad & StringBad::operator=(const StringBad & st){
//if(this == &st){
// return *this;
//}
delete []str;
len = st.len;
str = new char[len+1];
std::strcpy(str,st.str);
return *this;
}
s0 = s0;
这里原来st.str 在delete []str中就的内存就被释放了,所以st.str指向的内存是不存在了,无法将其赋值给str。
-
函数返回一个指向调用对象的引用。
-
地址运算符,如果没有定义
当使用一个对象来初始化另一个对象时,编译器将自动生成复制构造函数(创建对象的一个副本)。例如:
StringBad(const StringBad &)
12.1.3 回到StringBad:拷贝构造函数的哪里出现了问题:
问题1⃣️:当callme2()被调用的时候,拷贝构造函数被用来初始化callme2()的形参,还被用来将对象sailor初始化sports。
解决计数问题:
StringBad::StringBad(const String &s){
num_strings++;
...
}
问题2⃣️:字符串内容出现乱码。
原因在于隐式拷贝构造函数是按值进行复制的,sailor和sport的拷贝,相当于:
sailor.str = sport.str;
这里拷贝的并不是字符串,而是指向字符串的指针,所以得到了两个指向同一个字符串的指针,当析构函数被调用的时候,释放sailor效果如下:
delete [] sailor.str;
轮到sports释放的时候,sports.str指向的内存已经被释放了。
1、定义一个显式拷贝构造函数以解决问题:
解决类设计这种问题的方法是进行深度拷贝,拷贝构造函数应该拷贝字符串并且将副本的地址赋给str成员。这样每个对象都有自己的字符串,而不是引用另一个对象的字符串。
StringBad::StringBad(const StringBad &st){
num_strings++;
len = st.len;
str = new char[len + 1];
std::strcpy(str,str+1);
cout << num_strings << ": \"" << str << "\" object created\n";
}
12.1.4 其他问题:赋值运算符
1、赋值运算符的功能以及何时使用它
将已有的对象赋给另一个对象,将使用重载的赋值运算符:
StringBad headline1("1231456");
..
StirngBad knot;
knot = headline1;
初始化对象的时候,并不一定使用赋值运算符:
StringBad metoo = knot;//use copy constructor ,possibly assignment,too
⚠️赋值运算符的隐式实现也对成员进行逐个赋值。
2、赋值的问题出在哪里?
knot = headline1;
为knot调用析构函数的时候没事,对headline1调用析构函数的时候有事。和拷贝构造函数出现问题的缘由如出一辙。
3、解决赋值的问题
赋值的注意事项在12.1.2中指出了。
若s0,s1,s2都是StringBad对象,则可以编写以下代码:
s0 = s1 = s2;
使用函数表示的话:
s0.operator=(s1.operator=(s2));
我们可以看出,s1.operator=(s2)的返回值是函数s0.operator=()的参数,因为返回值是一个指向StringBad对象的引用,是正确的。
下面编写赋值运算符:
StringBad & StringBad::operator=(const StringBad & st){
if(this == &st){
return *this;
}
delete []str;
len = st.len;
str = new char[len+1];
std::strcpy(str,st.str);
return *this;
}
如果运算符右边的地址和接收对象的地址相同,程序将返回*this;如果不同,函数将释放str指向的内存,如果不使用delete运算符,则上述字符串将保留在内存中。由于程序中不再包含指向该字符串的指针,所以这些内存会被浪费。
12.2 改进后的新String类
12.2.1 修订后的默认构造函数
String::String(){
len = 0;
str = new char[1];
str[0] = '\0';
}
12.2.2 比较成员函数
在String类中,可以利用strcmp对字符串进行比较。若第一个字符串在第二个字符串之前,则operator<()函数返回true,相反则返回false。
bool operator<(const String &s1,const String &s2){
return (std::strcmp(st1.str,st2.str) < 0);
}
bool operator>(const String &s1,const String &s2){
return st1 > st2;
}
bool operator==(const String &s1,const String &s2){
return (std::strcmp(st1.str,st2.str) == 0);
}
12.2.3 使用中括号表示法访问字符
在C++中,对于中括号运算符,一个操作数位于第一个中括号前面,另一个位于中括号之间
char & String::operator[](int i){
return str[i];
}
由于返回类型为:char&,这样可以给特定元素赋值,如:
String means("might");
means[0] = 'r';
//下面语句与第二句等同
means.opeartor[][0] = 'r';
//这里其实返回的是指向means.str[0]的引用,因此还可以改
means.str[0] = 'r';
假设有下面的常量对象:
const String answer("futile");
cout << answer[0]; //compile-time error
原因是answer是常量,而上述方法无法确保不修改数据,我们可以再搞一个重载版本
const char &String::operator [](int i)const{
return str[i];
}
12.2.4 静态类成员
静态类成员的特点:无论创建多少个对象,程序都只创建一个静态类变量副本(类的所有对象共享同一个静态成员)。
不能在类声明中初始化静态成员变量(声明描述了如何分配内存,但不分配内存)。可以在类声明之外单独使用单独语句来进行初始化(静态成员变量是单独存储,而不属于对象的组成部分)。
⚠️注意:静态数据成员在类声明中声明,在包含类方法的文件中的初始化。初始化时使用作用域运算符来指出静态成员所属的类。但如果静态成员是整型或枚举型const,则可以在类声明中初始化。
⚠️警告:在构造函数中使用new来分配内存时,必须在相应的析构函数中使用delete来释放内存。如果使用 new[] (包括中括号)来分配内存,则应使用delete[](包括中括号)来释放内存。
自动存储对象被删除的顺序与创建顺序相反。
静态成员函数的声明中必须包含关键字 static,但如果函数定义是独立的(“函数定义是独立”是该函数不属于任何一个类, 而static函数必须属于一个类),则其中不能包含关键字static。原因有二:
- 不能通过对象调用静态成员函数,甚至不能使用this指针。
- 静态成员函数不与特定的对象相关联(类的所有对象共享同一个静态成员),只能使用静态数据成员。
如果静态成员函数是在类公有部分声明的,则可以使用类名和作用域解析运算符来调用它。
static int HowMany(){return num_strings}
int count = String::HowMany();
12.2.5 进一步重载赋值运算符
假设要将常规字符串复制到String对象中,编写如下语句:
String name;
char temp[40];
cin.getline(temp,40);
name = temp; //use constructor to concert type
1、程序使用构造函数String(const char *)来创建一个临时对象,其中包含temp中的字符串副本。这里用到了转换函数的知识:只有一个参数的构造函数被用作转换函数。
2、为提高效率,最简单的方法是重载赋值运算符,使之能够直接使用常规字符串。
String &String::operator=(const char*s){
delete[] str;
len = std::strlen(s);
str = new char[len + 1];
std::strcpy(str,s);
return *this;
}
一般来说:必须释放str原本指向的内存,再为其分配足够的内存,防止内存泄漏。
下面程序是string修改后的完整程序:
1、头文件
//
// Created by wzybb on 2022/9/16.
//
#ifndef TEST_STRING1_H
#define TEST_STRING1_H
#include
using std::ostream;
using std::istream;
class String {
private:
char *str;
int len;
static int num_strings; //number of objects
static const int CINLIM = 80; //cin input limit
public:
//constructor and other methods
String(const char *s); //constructor
String(); //default constructor
String(const String &); //copy constructor
~String(); //destructor
int length() const { return len; }
//overloaded operator methods
String &operator=(const String &);
String &operator=(const char *);
char &operator[](int i);
const char &operator[](int i) const;
//overloaded operator friends
friend bool operator<(const String &st, const String &st2);
friend bool operator>(const String &st1, const String &st2);
friend bool operator==(const String &st1, const String &st2);
friend ostream &operator<<(ostream &os, const String &st);
friend istream &operator>>(istream &is, String &st);
//static function
static int HowMany();
};
#endif //TEST_STRING1_H
2、源文件
//
// Created by wzybb on 2022/9/16.
//
#include "string1.h"
#include
using std::cin;
using std::cout;
//initializing static class member
int String::num_strings = 0;
//static method
int String::HowMany() {
return num_strings;
}
//class methods
String::String(const char*s) { //construct String from c string
len = std::strlen(s); //set size
str = new char[len + 1]; //allot storage
std::strcpy(str,s); //initialize pointer
num_strings++; //set object count
}
String::String() { //default constructor
len = 4;
str = new char[1];
str[0] = '\0'; //default string
num_strings++;
}
String::String(const String &st) { //construct String from String
num_strings++;
len = st.len;
str = new char[len+1];
std::strcpy(str,st.str);
}
String::~String() {
--num_strings;
delete []str;
}
//overloaded operator methods
//assign a String to a String
String &String::operator=(const String &st) {
if (this == &st){ //assign it to itself
return *this;
}
delete []str;
len = st.len;
str = new char [len+1];
std::strcpy(str,st.str);
return *this;
}
//assign a c string to a String
String & String::operator=(const char *s) {
delete []str;
len = std::strlen(s);
str = new char[len+1];
std::strcpy(str,s);
return *this;
}
//read-write char access for non-const String
char &String::operator[](int i) {
return str[i];
}
//read-only char access for const String
const char&String::operator[](int i) const {
return str[i];
}
//overloaded operator friends
bool operator<(const String&st1,const String &st2){
return (std::strcmp(st1.str,st2.str) < 0);
}
bool operator>(const String &st1, const String &st2){
return (std::strcmp(st1.str,st2.str) > 0);
}
bool operator==(const String &st1, const String &st2){
return (std::strcmp(st1.str,st2.str) == 0);
}
ostream &operator<<(ostream &os, const String &st){
os << st.str;
return os;
}
//quick and dirty String input
istream &operator>>(istream &is, String &st){
char temp[String::CINLIM];
is.get(temp,String::CINLIM);
if (is){
st = temp;
}
while (is && is.get() != '\n'){
continue;
}
return is;
}
重载>>运算符提供了一种将键盘输入行读到String对象中的方法。在if条件下,由于某种原因(如到达文件尾(读取文件的时候)或者get(char*,int)读取的是一个空行),导致输入失败,istream对象的值设置为false;
3、执行文件
#include
#include "string1.h"
const int Arsize = 10;
const int Maxlen = 81;
int main(){
using std::cout;
using std::cin;
using std::endl;
String name;
cout << "Hi,whats your name?" << endl;
cin >> name; //overloaded method ">>"
cout << name << ",please enter up to " << Arsize << " short sayings :" << endl;
String sayings[Arsize];
char temp[Maxlen]; //temporary string storage
int i;
for (i = 0; i < Arsize; ++i) {
cout << i + 1 << ": ";
cin.get(temp,Maxlen);
while (cin && cin.get() != '\n'){
continue;
}
if (!cin || temp[0] == '\0'){ //empty line?
break; //i not incremented
}else{
sayings[i] = temp; //overloaded assignment
}
}
int total = i; //total # of lines read
if (total > 0){
cout << "Here are your sayings:\n";
for (int j = 0; j < total; ++j) {
cout << sayings[j][0] << ":" << sayings[j] << endl;
}
int shortest = 0;
int first = 0;
for (int j = 1; j < total; ++j) {
if (sayings[j].length() < sayings[shortest].length()){
shortest = j;
}
if (sayings[j] < sayings[first]){
first = j;
}
}
cout << "shortest saying:\n" << sayings[shortest] << endl;
cout << "First alphabetically:\n" << sayings[first] << endl;
cout << "This program used " << String::HowMany() << " String objects,bye!\n";
}else{
cout << "No input!Bye.\n";
}
return 0;
}
输出:
Hi,whats your name?
minty gutz<--(cin)
minty gutz,please enter up to 10 short sayings :
1: a fool and his money are soon parted <--(cin)
2: penny wise,pound foolish <--(cin)
3: the love of money is the root of much evil <--(cin)
4: out of sight,out of mind <--(cin)
5: absence makes the heart grow fonder <--(cin)
6: absinthe makes the hart grow fonder <--(cin)
7: <--(cin)
Here are your sayings:
a:a fool and his money are soon parted
p:penny wise,pound foolish
t:the love of money is the root of much evil
o:out of sight,out of mind
a:absence makes the heart grow fonder
a:absinthe makes the hart grow fonder
shortest saying:
penny wise,pound foolish
First alphabetically:
a fool and his money are soon parted
This program used 11 String objects,bye!
⚠️较早的版本get(char*,int)读取空行的时候,返回值不是false,而是将字符串的第一个字符赋值为一个空字符’\0’;
12.3 在构造函数中使用new时的注意事项
使用new初始化对象的指针成员时必须小心。具体做法如下:
-
如果在构造函数中使用new来初始化指针成员,则应在析构函数中使用delete。
-
new 和 delete必须相互兼容。new对应于delete,new[] 对应于 delete[]
- 参考地址:https://zhuanlan.zhihu.com/p/144600712?utm_id=0
-
如果有多个构造函数,则必须以相同的方式使用 new,要么带括号,要么都不带。
-
定义一个拷贝构造函数,通过深拷贝将一个对象初始化为另一个对象。
12.3.2 包含类成员的类的逐成员复制
假设类成员类型为String类或者标准string类:
class Magazine{
private:
string publisher;
String title;
};
如果成员都是用了动态内存分配,这是否意味着需要为类编写拷贝构造函数和赋值运算符?
不,在此时是不需要的,如果将m1对象赋值给m2对象,逐成员赋值将使用成员类型所定义的拷贝构造函数和赋值运算符。并且这里无需因其他成员的需要定义拷贝构造函数和赋值运算符…所以这里是不需要编写相应的拷贝构造函数和赋值运算符。
12.4 返回对象的问题
当成员函数或独立的函数返回对象时,有3种返回方式
-
指向对象的非const引用
-
常见的返回非const对象的情形,重载赋值运算符以及重载与cout一起使用的<<运算符。
-
1⃣️对于operator=()
-
String s1("Good stuff");
String s2,s3;
s3 = s2 = s1;
这个例子,返回类型不是const,返回的是一个对象的非const引用,意味着可以对其进行修改。
-
2⃣️对于operator<<()
-
String s1("Good stuff");
cout << s1 << "is coming";
重载的时候必须返回ostream &,因为ostream没有共有的拷贝构造函数,所以会犯错。
-
指向对象的const引用
-
如果函数返回(通过调用对象的方法或将对象作为参数)传递给它的对象,可以通过返回引用提高效率。
-
//在第十一章
double Vector::magval()const{
return mag;//length of vector
}
Vector force1(50,60);
Vector force2(10,70);
Vector max;
max = Max(force1,force2);
//version1
Vector Max(const Vector &v1,const Vector&v2){
if(v1.magval() > v2.magval()){
return v1;
}
else{
return v2;
}
}
//version2
const Vector&Max(const Vector &v1,const Vector &v2){
if(v1.magval() > v2.magval()){
return v1;
}
else{
return v2;
}
}
-
返回对象将将调用拷贝构造函数,而返回引用不会(这就是version2效率更高的缘由)。v1与v2都被声明为const引用,因此返回类型必须为const,这样才匹配。
-
const对象
-
现在针对Vector::operator+()定义来讲解这一部分的内容:
-
Vector Vector::operator+(const Vector &b) const {
return Vector(x + b.x, y + b.y);
}
net = force1 + force2;
//下面暂时可行
force1 + force2 = net;
cout << (force1 + force = net).magval() << endl;
对于语句2,程序先计算force1和force2之和,将结果通过拷贝构造函数拷贝到临时对象中,再用net覆盖临时对象的内容,最后临时对象被丢弃。因此,原来还是保持原样。
对于语句3,读取矢量的长度,然后丢弃。
如果想避免如此鸡肋的写法,我们可以将返回类型声明为const Vector,这样,(force1 + force2)返回的是const对象,那么它的内容不允许被修改,所以net想覆盖临时对象的内容是行不通的。语句3同理。
12.5 使用指向对象的指针
c++经常使用指向对象的指针,我们通过修改之前程序(使用数组索引值跟踪最短的字符串和按字母顺序排在前面的字符串),使得它使用指针指向这些类别的索引值。
#include
#include
#include "string1.h"
const int Arsize = 10;
const int Maxlen = 81;
int main(){
using std::cout;
using std::cin;
using std::endl;
String name;
cout << "Hi,what's your name?" << endl;
cin >> name;
cout << name << ",please enter up to " << Arsize << " short sayings :" << endl;
String sayings[Arsize];
char temp[Maxlen]; //temporary string storage
int i;
for (i = 0; i < Arsize; ++i) {
cout << i + 1 << ": ";
cin.get(temp,Maxlen);
while (cin && cin.get() != '\n'){
continue;
}
if (!cin || temp[0] == '\0'){ //empty line?
break; //i not incremented
}else{
sayings[i] = temp; //overloaded assignment
}
}
int total = i; //total # of lines read
if (total > 0){
cout << "Here are your sayings:\n";
for (int j = 0; j < total; ++j) {
cout << sayings[j] << endl;
}
//use pointers to keep track of shortest first strings
String *shortest = &sayings[0]; //initialize to first object
String *first = &sayings[0];
for (int j = 1; j < total; ++j) {
if (sayings[j].length() < shortest->length()){
shortest = &sayings[j];
}
if (sayings[j] < *first){
first = &sayings[j];
}
}
cout << "shortest saying:\n" << *shortest << endl;
cout << "First alphabetically:\n" << *first << endl;
cout << "This program used " << String::HowMany() << " String objects,bye!\n";
srand(time(0));
int choice = rand()%total;
//use new to create,initialize new String object
String *favorite = new String(sayings[choice]);
cout << "My favorite saying:\n" << *favorite << endl;
}else{
cout << "No input!Bye.\n";
}
return 0;
}
12.5.1 再说一下new和delete
String* favorite = new String(sayings[choice]);
这是为对象分配空间。当程序不再需要该对象时,使用delete删除它,delete对象的时候,只释放于保存str指针和len成员的空间。str指向的内存由析构函数来完成。
参照上图,我们可以总结三种关于析构函数调用的情况:
- 如果对象是自动变量,则当执行完定义该对象的程序块时,将调用该对象的析构函数。(对应上图第一个箭头)
- 如果对象是静态变量(外部、静态、静态外部或来自名称空间),则在程序结束时将调用对象的析构函数。(对应上图)
- 如果对象是new创建的,则仅当您显示使用delete对象时,其析构函数才会被调用。
⚠️:书本里面的第一点情况不是自动变量,而是动态变量;但是我认为假如是动态变量的话,那么第一点和第三点好像有矛盾了,所以我根据上图,将动态改成了自动。
12.5.2 指针和对象小结
12.5.3 再谈定位new运算符
#include
#include
#include
using namespace std;
const int BUF = 512;
class JustTesting {
private:
string words;
int number;
public:
JustTesting(const string &s = "Just Testing", int n = 0) {
words = s;
number = n;
cout << words << " constructed\n";
}
~JustTesting() {
cout << words << " destroyed\n";
}
void Show() const {
cout << words << ", " << number << endl;
}
};
int main() {
char *buffer = new char[BUF];
JustTesting *pc1, *pc2;
pc1 = new(buffer)JustTesting;
pc2 = new JustTesting("Heap1", 20);
cout << "Memory block addresses:\n" << "buffer:"
<< (void *) buffer << " heap:" << pc2 << endl;
cout << "Memory contents:\n";
cout << pc1 << ": ";
pc1->Show();
cout << pc2 << ": ";
pc2->Show();
JustTesting *pc3, *pc4;
pc3 = new(buffer)JustTesting("Bad Idea", 6);
pc4 = new JustTesting("Heap2", 10);
cout << "Memory contents:\n";
cout << pc3 << ": ";
pc3->Show();
cout << pc4 << ": ";
pc4->Show();
delete pc2; //free Heap1
delete pc4; //free Heap2
delete[]buffer; //free buffer
cout << "Done\n";
return 0;
}
输出:
Just Testing constructed
Heap1 constructed
Memory block addresses:
buffer:0x128e04470 heap:0x600001015100
Memory contents:
0x128e04470: Just Testing, 0
0x600001015100: Heap1, 20
Bad Idea constructed
Heap2 constructed
Memory contents:
0x128e04470: Bad Idea, 6
0x600001015120: Heap2, 10
Heap1 destroyed
Heap2 destroyed
Done
使用定位new运算符的时候,要给第二个new设置偏移量,不然后面的定位new会覆盖之前的所定位的。
pc1 = new(buffer)JustTesting;
pc3 = new(buffer + sizeof(JustTesting)) JustTesting("Better Idea",6);
delete不能与定位new运算符搭配,原因如下:
- 指针pc3没有收到new运算符返回的地址,因此delete pc3将会导致运行错误。
- 指针指向的地址与buffer相同,但buffer是使用new[]初始化的,因此必须使用delete[]而不是delete来释放。即使buffer是使用new而不是new[]初始化的,delete pc1也将释放buffer。
解决办法:
显式地为使用定位new运算符创建的对象调用析构函数。
pc3->JustTesting(); //destory object pointed to by pc3
pc1->JustTesting(); //destory object pointed to by pc1
仅当上面所有对象都被销毁后,才能释放用于存储这些对象的缓冲区
修改过后的程序:
#include
#include
#include
using namespace std;
const int BUF = 512;
class JustTesting {
private:
string words;
int number;
public:
JustTesting(const string &s = "Just Testing", int n = 0) {
words = s;
number = n;
cout << words << " constructed\n";
}
~JustTesting() {
cout << words << " destroyed\n";
}
void Show() const {
cout << words << ", " << number << endl;
}
};
int main() {
char *buffer = new char[BUF];
JustTesting *pc1, *pc2;
pc1 = new(buffer)JustTesting;
pc2 = new JustTesting("Heap1", 20);
cout << "Memory block addresses:\n" << "buffer:"
<< (void *) buffer << " heap:" << pc2 << endl;
cout << "Memory contents:\n";
cout << pc1 << ": ";
pc1->Show();
cout << pc2 << ": ";
pc2->Show();
JustTesting *pc3, *pc4;
pc3 = new(buffer + sizeof(JustTesting))JustTesting("Bad Idea", 6);
pc4 = new JustTesting("Heap2", 10);
cout << "Memory contents:\n";
cout << pc3 << ": ";
pc3->Show();
cout << pc4 << ": ";
pc4->Show();
delete pc2; //free Heap1
delete pc4; //free Heap2
//explicitly destroy placement new objects
pc3->~JustTesting();
pc1->~JustTesting();
delete[]buffer; //free buffer
cout << "Done\n";
return 0;
}
输出:
Just Testing constructed
Heap1 constructed
Memory block addresses:
buffer:0x11c604470 heap:0x600000ab5100
Memory contents:
0x11c604470: Just Testing, 0
0x600000ab5100: Heap1, 20
Bad Idea constructed
Heap2 constructed
Memory contents:
0x11c604490: Bad Idea, 6
0x600000ab5120: Heap2, 10
Heap1 destroyed
Heap2 destroyed
Bad Idea destroyed
Just Testing destroyed
Done
12.6 复习
12.6.3 其构造函数使用new的类
-
对于指向的内存是由new分配的所有类成员,都应在类的析构函数中对其使用delete。
-
如果析构函数通过对指针类成员使用delete来释放内存,则每个构造函数都应当使用new来初始化指针,或者将其设置为空指针。
-
new->delete, new [] ->delete[]
-
应定义一个分配内存(指针指向的内存没为他用)的拷贝构造函数。这种做法,可以用类对象初始化为另一个类对象。
-
className(const className &)
-
应定义一个重载赋值运算符的类成员函数。
-
String &String::operator=(const String &st) {
if (this == &st){ //assign it to itself
return *this;
}
delete []str;
len = st.len;
str = new char [len+1];
std::strcpy(str,st.str);
return *this;
}
12.7 队列模拟
队列是FIFO(first-in,first-out)结构
12.7.1 队列类

1、Queue类的接口
从队列的特征可知,Queue类的公有接口应该如下:
class Queue{
enum{Q_size = 10};
private:
Queue(int qs = Q_size); //create queue with a qs limit
~Queue();
bool isempty() const;
bool isfull() const;
int queuecount()const;
bool enqueue(const Item &item); //add item to end
bool dequeue(Item &item); //remove item from front
};
使用默认参数的时候:
Queue line1; //queue with 10-item limit
但可以显式初始化参数:
Queue line2(20); //queue with 20-item limit
2、Queue类的模拟
确定接口之后,我们利用链表来表示队列的数据,对于这里的数据部分都是一个Item类型的值,因此可以使用下面结构:
struct Node{
Item item; //data stored in the node
struct Node *next; //pointer to next node
};
如图为链表:
要追踪链表,必须知道链表的第一个节点的地址,可以让Queue一个数据成员指向链表的起始位置。如下图:
class Queue{
private:
//class scope definitions
// Node是嵌套在类的结构体
struct Node{
Item item;
struct Node* next;
};
//private class members
Node* front; //pointer to front of Queue
Node* rear; //pointer to rear of Queue
int items; //current number of items in Queue
const int qsize; //maxium number of items in Queue
....
public:
.....
};
3、类方法
类构造函数应提供类成员的值。最初的队列是空的,所以队头队尾都是NULL,其他的按照正常操作进行即可:
Queue::Queue(int qs){
front = rear = NULL;
items = 0;
qsize = qs; //not acceptable
}
由于qsize类型为const int(不可修改的值,即常量),所以不能给他赋值。对于const数据成员,必须在执行到构造函数之前进行初始化。c++提供了一种特殊的语法:成员初始化列表 来完成上述工作。操作如下:
Queue::Queue(int qs):qsize(qs){
front = rear = NULL;
items = 0;
}
通常,初值可以是常量或者构造函数的列表参数,所以上述语句可以改为:
Queue::Queue(int qs):qsize(qs),front(NULL),rear(NULL),items(0)
{
}
只有构造函数可以使用这种语法。另外,对于被声明为引用的类成员,也必须使用这种语法:
class Agency{...};
class Agent{
private:
Agency &belong; //must use initializer list to initialize
...
};
Agent::Agent(Agency &a):belong(a){...}
紧接着,定义isempty(),isfull(),queuecount()的代码都非常简单。将项目添加到队尾比较麻烦,下面提供一种方法
bool Queue::enqueue(const Item&item){
if(isfull()){
return false;
}
Node *add = new Node; //create node
add->item = item;//set node pointers
add->next = NULL;
items++;
if(front == NULL){ //if queue is empty
front = add; //place item at front
}
else{
rear->next = add; //else place at rear
} //have rear point to new node
rear = add;
return true;
}
下图为上面程序执行过程的可视化:
删除队首项目也需要多个步骤才能完成。下面提供一种方式
bool Queue::dequeue(const Item&item){
if(front == NULL){
return false;
}
item = front->item; //set item to first item in queue
items--;
Node*temp = front; //save location of first item
front = front->next; //reset front to next item
delete temp; //delete former first item
if(items == 0){
rear = NULL;
}
return true;
}
对于非const对象赋值给const对象的引用:(当复习用)
https://bbs.csdn.net/topics/390603852?page=1
再看看析构函数有没有要调整的,根据12.6.3来说,类构造函数没有使用new,所析构函数好像就不用delete什么东西了。但是,我们不能保证队列到期之后为空,所以类需要整一个析构函数来删除队列剩余的所有节点。下面提供一种方法:
Queue::~Queue(){
Node* temp;
while(front != NULL){//while queue is not yet empty
temp = front; //save address of front item
front = front->next; //reset pointer to next itme
delete temp; //delete former front
}
}
使用new的类通常需要包含显式拷贝构造函数和执行深拷贝的赋值运算符。若在此没包含,我们推演一下:拷贝Queue对象的成员将生成一个新的对象,该对象指向链表原来的头和尾,将项目添加到新生成的 Queue对象中,只有副本的尾指针得到了更新,原始对象什么也没改变,这将损坏链表(即无法通过原始对象正常地操作修改后的链表)。
我们再思考:拷贝队列有什么用呢?
答:拥有拆分队列的操作是非常有用的,举个简单的例子:超市在开设收款台的时候经常这样做。另外,也可能希望将两个队列结合成一个或者截短一个队列。
12.7.2 Customer类
设计客户类,ATM客户有很多属性,例如姓名、账户和账户结余。然而,这里的模拟需要使用的唯一一个属性是客户何时进入队列以及交易所需的时间。当模拟生成新客户时,程序将创建一个新的客户对象,并在其中存储客户的到达时间以及随机生成的交易时间。当客户到达队首时,程序将记录此时间,并将其与进入队列的时间相减,得到客户的等候时间。
//This queue will contain Customer items
class Customer {
private:
long arrive; //arrival time for customer
int processtime; //processing time for customer
public:
Customer() { arrive = processtime = 0; };
void set(long when);
long when() const {
return arrive;
}
int ptime() const {
return processtime;
}
};
typedef Customer Item;
下面程序为头文件和对应的源文件:
1、头文件
#ifndef TEST_QUEUE_H
#define TEST_QUEUE_H
//This queue will contain Customer items
class Customer {
private:
long arrive; //arrival time for customer
int processtime; //processing time for customer
public:
Customer() { arrive = processtime = 0; };
void set(long when);
long when() const {
return arrive;
}
int ptime() const {
return processtime;
}
};
typedef Customer Item;
class Queue {
private:
//class scope definitions
struct Node {
Item item;
struct Node *next;
};
enum {
Q_size = 10
};
//private class members
Node *front; //pointer to front of Queue
Node *rear; //pointer to rear of Queue
int items; //current number of items in Queue
const int qsize; //maximum number of items in Queue
//伪私有成员
Queue(const Queue &q):qsize(0){}
Queue & operator=(const Queue &q){return *this;}
public:
Queue(int qs = Q_size); //create queue with a qs limit
~Queue();
bool isempty()const;
bool isfull()const;
int queuecount()const;
bool enqueue(const Item &item); //add item to end
bool dequeue(Item &item); //remove item from
};
#endif //TEST_QUEUE_H
2、源文件
//
// Created by wzybb on 2022/9/20.
//
#include
#include "queue.h"
//Queue methods
Queue::Queue(int qs):qsize(qs) {
front = rear = NULL; //or nullprt
items = 0;
}
Queue::~Queue() {
Node*temp;
while (front != NULL){
temp = front; //save address of front itme
front = front->next; //reset pointer to next item
delete temp;
}
}
bool Queue::isempty() const {
return items == 0;
}
bool Queue::isfull() const {
return items == qsize;
}
//add item to queue
bool Queue::enqueue(const Item &item) {
if (isfull()){
return false;
}
Node *add = new Node;
add->item = item;
add->next = NULL;
items++;
if (front == NULL){ //if queue is empty
front = add; //place item at front
}
else {
rear->next = add; //else place at rear
}
rear = add; //have rear point to new node
return true;
}
//place front item into item variable and remove from queue
bool Queue::dequeue(Item &item) {
if (front == NULL){
return false;
}
item = front->item; //set item to first item in queue
items--;
Node* temp = front; //save location of first item
front = front->next; //reset front to next item
delete temp;
if (items == 0){
rear = NULL;
}
return true;
}
//time set to a random value in the range 1-3
void Customer::set(long when) {
processtime = std::rand()%3 + 1;
arrive = when;
}
12.7.3 ATM模拟
程序需要确定是否有新的用户到来。假设平均每小时有10名客户到达(cust_per_hour),则相当于每6分钟有一名客户到来。程序将这个值保存在min_per_cust变量中。然而,这不太现实,所以我们通过程序,模拟一个更随机的过程(但保证平均每6分钟来1个客户)。
补充一些东西:MIN_PER_HR = 60min/h, cust_per_hour = 10custs/h
则 min_per_cust = MIN_PER_HR / cust_per_hour = 60min/h / 10cust/h = 6min/cust
bool newcustomer(double x){
srand(time(0));//time(0)是得到当前时时间值(因为每时每刻时间是不一样的了)。
return (std::rand() * x / RADN_MAX < 1);
}
rand()给的数字随机返回的值[0,RAND_MAX],假如平均间隔时间为6,则(std::rand() * x / RADN_MAX)的值位于0-6之间.也就是说,平均每隔六次,这个值会有一次小于1(1~6,0,1~6,0,…)
#include
#include
#include
#include "queue.h"
const int MIN_PER_HR = 60;
bool newcustomer(double x); //is there a new customer
int main() {
using std::cin;
using std::cout;
using std::endl;
//setting things up
std::srand(std::time(0)); //random initializing of rand()
cout << "Case Study:Bank of Automatic Teller Machine\n";
cout << "Enter maximum size of queue:";
int qs;
cin >> qs;
Queue line(qs); //line queue holds up to qs people
cout << "Enter the number of simulation(模拟) hours:";
int hours; //hours of simulation
cin >> hours;
//simulation will run 1 cycle per minute
long cyclelimit = MIN_PER_HR * hours; //# of cycles
cout << "Enter the average number of customers arrives to ATM per hour:";
double cust_per_hour; //average # of arrival per hour
cin >> cust_per_hour;
double min_per_cust; //average time between arrivals
min_per_cust = MIN_PER_HR / cust_per_hour;
Item temp; //new customer data
long turnaways = 0; //turned away full queue(当队列满的时候不准入内)
long customers = 0; //joined the queue
long served = 0; //people served during the simulation
long sum_line = 0; //cumulative line length
int wait_time = 0; //time until autoteller is free
long line_wait = 0; //cumulative time in line
//running the simulation
for (int cycle = 0; cycle < 100; ++cycle) {
if (newcustomer(min_per_cust)) { //have newcomer
if (line.isfull()) { //如果满了的话,就拒绝入内,turnaways就是记录被拒绝入内的人数
turnaways++;
}else {
customers++;
temp.set(cycle); //cycle = time of arrival
line.enqueue(temp); //add newcomer to line
}
}
if (wait_time <= 0 && !line.isempty()) { //如果ATM空闲,并且队列不为空
line.dequeue(temp); //弹出队列的头
wait_time = temp.process_time(); //for wait_time minutes
line_wait += cycle - temp.arrive_time();
served++;
}
//如果ATM不空闲,那么让ATM继续服务,每轮wait_time - 1,直到它空闲(为0),就可以在下一轮把队头弹出了
if (wait_time > 0) {
wait_time--;
}
sum_line += line.queuecount();
}
//reporting results
if (customers > 0) {
cout << "customer accepted:" << customers << endl;
cout << "customer served:" << served << endl;
cout << "turnaways:" << turnaways << endl;
cout << "average queue size(length / min):";
cout.precision(2);
cout.setf(std::ios_base::fixed, std::ios_base::floatfield);
cout << (double) sum_line / cyclelimit << endl;
cout << " average wait time:"
<< (double) line_wait / served << " minutes\n";
}else{
cout << "No customers!\n";
}
cout << "Done!\n";
return 0;
}
bool newcustomer(double x){
return (std::rand() * x / RAND_MAX < 1);
}
输出:
Case Study:Bank of Automatic Teller Machine
Enter maximum size of queue:10
Enter the number of simulation(模拟) hours:100
Enter the average number of customers per hour:15
customer accepted:1474
customer served:1474
turnaways:0
average queue size:0.19
average wait time:0.79 minutes
Done!
Case Study:Bank of Automatic Teller Machine
Enter maximum size of queue:10
Enter the number of simulation(模拟) hours:100
Enter the average number of customers arrives to ATM per hour:30
customer accepted:2925
customer served:2
⚠️注意:每小时到达的客户从15名增加到30名,等待时间并不是加倍,而是增加了15倍。如果允许队列更长,情况将更糟糕。然而,程序中没有考虑到队列太长,客户不愿等待离开的情形。