Chapter 2.2 高频词和关键词提取(二)
知识点2.2.1 TF-IDF算法的基本思想
TF-IDF算法由TF和IDF两部分组成,是TF算法和IDF算法的综合使用
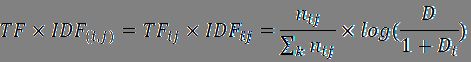
TF(词频):某词在某文档中出现的次数/该文档的总词数,词频越高表示该词对该文档的表达能力越强
IDF(逆文档频次):log(语料库中的总文档数/(1+语料库中出现某词的文档数)),分母加1是使用了拉普拉斯平滑,以避免个别新词没有在语料库中出现而导致分母为0的情况,逆文档频次越高表示该词对该文档的区分能力越强
例:“发展”在2021年的政府工作报告中出现的频数较高(TF较高),但在每一年的政府工作报告中都出现(IDF较低),因此“发展”可能不是2021年政府工作报告的关键词
“高质量”在2021年政府工作报告中出现的频数较高(TF较高),且仅在近几年的政府工作报告中出现(IDF也较高),因此“高质量”可能就是2021年政府工作报告的关键词
优点:便于理解,便于计算
缺点:考虑信息不够全面(词性、位置)
改进:在传统TF-IDF算法的基础上,按词性(比如名词)、位置(比如起始段落或结尾段落)等信息赋予某些词更高的权重
知识点2.2.2 基于jieba的TF-IDF关键词提取
基于jieba的TF-IDF关键词提取的特点:
- 能够直接分词
- 能够使用自定义词典(新词、停用词)
- 能够直接计算TF-IDF值(无需训练模型)
- 能够使用自定义语料库(计算IDF值)
- 计算结果以列表形式呈现(而非矩阵)
- 适用于单文本关键词提取
#载入需要的程序模块
import jieba.analyse
#导入需分析的文档(str类型),并打印
with open('C:\\Users\\dell-pc\\desktop\\2021.txt', "r", encoding = 'utf-8') as f:
chap2_tf = f.read()
print(chap2_tf)
#导入自定义的停用词词典
jieba.analyse.set_stop_words('C:\\Users\\dell-pc\\desktop\\停用词.txt')
#使用tf-idf算法提取前20个关键词(基于jieba默认的计算idf值的语料库)
freq_tf = jieba.analyse.extract_tags(chap2_tf, topK = 20)
freq_tf
#使用tf-idf算法提取前20个关键词及tf-idf值
freq_tf = jieba.analyse.extract_tags(chap2_tf, topK = 20, withWeight = True)
freq_tf
#使用tf-idf算法提取前20个指定词性的关键词及tf-idf值(n表示名词)
freq_tf = jieba.analyse.extract_tags(chap2_tf, topK = 20, withWeight = True, allowPOS=('n'))
freq_tf
知识点2.2.3 关键词的词云图展示
#载入需要的程序包
import wordcloud
import matplotlib.pyplot as plt
#导入需要的中文字体
myfont = r'C:\Windows\Fonts\msyhbd.ttc'
#绘制词云图(如要绘制前50个关键词的词云图,则需在关键词提取命令中将topK设置为50)
word_cloud = wordcloud.WordCloud(font_path = myfont,
width = 1200,
height = 800,
mode = 'RGBA',
background_color = None,
max_words = 50,
colormap = 'cividis').fit_words(dict(freq_tf))
- font_path 设置自定义字体路径
- width 设置图片宽度,默认为400
- height 设置图片高度,默认为200
- mode 默认为‘RGB’,当设置为’RGBA’时背景色为透明
- background_color 设置图片背景色,默认为黑色
- max_words 设置图片显示的词数,默认为200
- colormap 设置字体颜色
wordcloud官方网址(https://amueller.github.io/word_cloud/)
字体颜色参考网址(https://matplotlib.org/stable/gallery/color/colormap_reference.html)
#展示词云图
plt.imshow(word_cloud)
plt.axis("off")
plt.show()
#保存词云图
word_cloud.to_file("chap202.png")
