中文分词工具jieba使用-高频热词提取
目录
- 一、概念
- 二、使用
-
- 1.基本分词
- 2.词性标注
- 3.实战-高频热词提取
一、概念
近年来,随着NLP技术的日益成熟,开源实现的分词工具越来越多,如Ansj、盘古分词等。本文选择的是更易上手的Jieba做简单介绍。
原理:
Jieba分词结合了基于规则和基于统计这两类方法。首先基于前缀词典进行词图扫描,前缀词典是指词典中的词按照前缀包含的顺序排列,例如词典中出现了“上”,之后以“上”开头的词都会出现在这一部分,例如“上海”,进而会出现“上海市”,从而形成一种层级包含结构。如果将词看作节点,词和词之间的分词符看作边,那么一种分词方案则对应着从第一个字到最后一个字的一条分词路径。因此,基于前缀词典可以快速构建包含全部可能分词结果的有向无环图,这个图中包含多条分词路径,有向是指全部的路径都始于第一个字、止于最后一个字,无环是指节点之间不构成闭环。基于标注语料,使用动态规划的方法可以找出最大概率路径,并将其作为最终的分词结果。对于未登录词,Jieba使用了基于汉字成词的HMM模型,采用了Viterbi算法进行推导。
二、使用
1.基本分词
Jieba分词官网地址是:https://github.com/fxsjy/jieba,可以采用如下方式进行安装。
pip install jieba
Jieba提供了三种分词模式:
- 精确模式:试图将句子最精确地切开,适合文本分析。
- 全模式:把句子中所有可以成词的词语都扫描出来,速度非常快,但是不能解决歧义。
- 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
下面是使用这三种模式的对比。
> import jieba
>
> sent='中文分词是文本处理不可或缺的一步~'
> print('原始文本:',sent)
> seg_list=jieba.cut(sent,cut_all=True)
> print('全模式:',','.join(seg_list))
> seg_list=jieba.cut(sent,cut_all=False)
> print('精确模式:',','.join(seg_list))
> seg_list=jieba.cut_for_search(sent)
> print('搜索引擎模式:',','.join(seg_list))
结果:
原始文本: 中文分词是文本处理不可或缺的一步~
全模式: 中文,分词,是,文本,文本处理,本处,处理,不可,不可或缺,或缺,的,一步,,
精确模式: 中文,分词,是,文本处理,不可或缺,的,一步,~
搜索引擎模式: 中文,分词,是,文本,本处,处理,文本处理,不可,或缺,不可或缺,的,一步,~
2.词性标注
词性是词汇基本的语法属性,通常也称为词类。词性标注是在给定句子中判定每个词的语法范畴,确定其词性并加以标注的过程。例如,表示人、地点、事物以及其他抽象概念的名称即为名词,表示动作或状态变化的词为动词,描述或修饰名词属性、状态的词为形容词。如给定一个句子:“这儿是个非常漂亮的公园”,对其的标注结果应如下:“这儿/代词 是/动词 个/量词 非常/副词 漂亮/形容词 的/结构助词 公园/名词”。
词性标注需要有一定的标注规范,如将词分为名词、形容词、动词,然后用“n”“adj”“v”等来进行表示。中文领域中尚无统一的标注标准,较为主流的主要为北大的词性标注集和宾州词性标注集两大类。两类标注方式各有千秋,一般我们任选一种方式即可。本书中采用北大词性标注集作为标准,其部分标注的词性如下表所示。

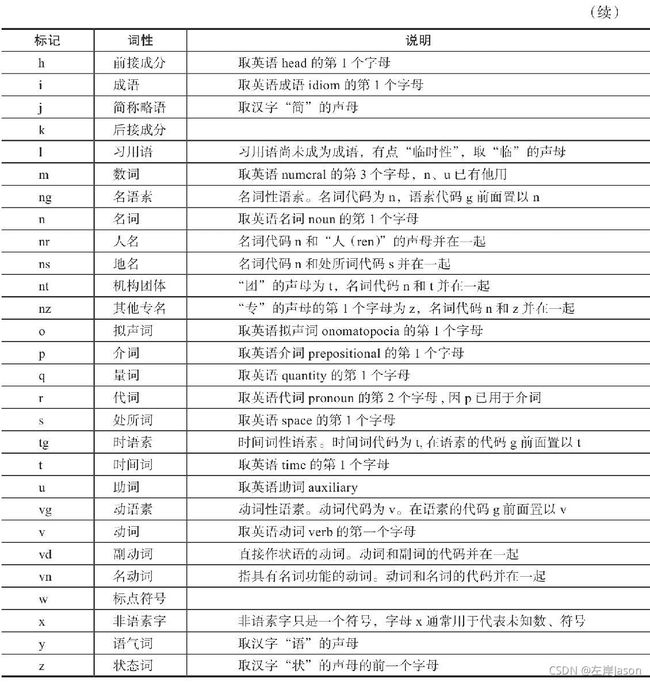 使用Jieba分词进行词性标注的示例如下:
使用Jieba分词进行词性标注的示例如下:
import jieba.posseg as psg
sent='中文分词是文本处理不可或缺的一步~'
seg_list=psg.cut(sent)
print('bbb',' '.join(['{0}/{1}'.format(w,t) for w,t in seg_list]))
结果:
![]()
3.实战-高频热词提取
高频词一般是指文档中出现频率较高且非无用的词语,其一定程度上代表了文档的焦点所在。针对单篇文档,可以作为一种关键词来看。对于如新闻这样的多篇文档,可以将其作为热词,发现舆论焦点。
高频词提取其实就是自然语言处理中的TF(Term Frequency)策略。其主要有以下干扰项:
- 标点符号:一般标点符号无任何价值,需要去除。
- 停用词:诸如“的”“是”“了”等常用词无任何意义,也需要剔除。
下载停用词文本 stopwords.txt 如下:
https://pan.baidu.com/s/1t9Mk5l3x8HlU9v0p8DGKkA?at=1636437019578
新闻内容自行查找,命名news1.txt,news2.txt 。。。
# jieba高频热词提取
import glob
import random
import jieba
# 加载文本
def get_content(path):
with open(path,'r',encoding='gbk',errors='ignore') as f:
content=''
for l in f:
l=l.strip()
content+=l
return content
# 热词计数
def get_TF(words,topK=10):
tf_dic={}
for w in words:
if w not in stop_words('stopwords.txt'):
tf_dic[w]=tf_dic.get(w,0)+1
return sorted(tf_dic.items(),key=lambda x:x[1],reverse=True)[:topK]
# 加载停用词
def stop_words(path):
with open(path,'r',encoding='gbk',errors='ignore') as f:
return[l.strip() for l in f]
files=glob.glob('./news*.txt')
corpus=[get_content(x) for x in files]
split_words=list(jieba.cut(corpus[0]))
print('样本之一:',corpus[0])
print('样本分词效果:',','.join(split_words))
print('样本的top10热词:',str(get_TF(split_words)))
结果:
样本之一: 近日,美国多所常春藤大学收到了炸弹威胁,随后发布紧急警报并进行了人员疏散。据《今日美国》及美联社7日报道,当地时间7日下午,美国康奈尔大学、哥伦比亚大学和布朗大学都收到了炸弹威胁,这些学校随后发布紧急警报,将校内的人员疏散,并警告学生们远离校园。美媒称,位于纽约的康奈尔大学被电话告知炸弹放在4栋大楼里,随即封锁了校园。纽约市哥伦比亚大学也在当天下午2点半左右收到了炸弹威胁,随后发布了校园内的紧急警报。布朗大学则向学生们发送了一条警告短信,称“校园内的多座建筑存在炸弹威胁,警方正展开调查”。
样本分词效果: 近日,,,美国,多所,常春藤,大学,收到,了,炸弹,威胁,,,随后,发布,紧急警报,并,进行,了,人员,疏散,。,据,《,今日,美国,》,及,美联社,7,日,报道,,,当地,时间,7,日,下午,,,美国康奈尔大学,、,哥伦比亚大学,和,布朗,大学,都,收到,了,炸弹,威胁,,,这些,学校,随后,发布,紧急警报,,,将,校内,的,人员,疏散,,,并,警告,学生,们,远离,校园,。,美媒称,,,位于,纽约,的,康奈尔大学,被,电话,告知,炸弹,放在,4,栋,大楼,里,,,随即,封锁,了,校园,。,纽约市,哥伦比亚大学,也,在,当天,下午,2,点,半左右,收到,了,炸弹,威胁,,,随后,发布,了,校园内,的,紧急警报,。,布朗,大学,则,向,学生,们,发送,了,一条,警告,短信,,,称,“,校园内,的,多座,建筑,存在,炸弹,威胁,,,警方正,展开,调查,”,。
样本的top10热词: [('炸弹', 5), ('威胁', 4), ('大学', 3), ('收到', 3), ('发布', 3), ('紧急警报', 3), ('美国', 2), ('人员', 2), ('疏散', 2), ('下午', 2)]