深度学习(8):基于BERT算法的文本内容情感分析
目标:基于BERT网络实现对文本的情感进行分析,将网络上的商品评论内容经过预处理后输入BERT模型训练和推理,最后将判断结果进行输出。
一、原理
1.了解BERT算法的基本原理
BERT介绍
谷歌AI团队发布的BERT模型在11种不同的自然语言处理任务中创出佳成绩,为自然语言处理带来里程碑式的改变,也是自然语言处理领域近期重要的进展。
BERT是一种对语言表征进行预训练的方法, 即是经过大型文本语料库(如维基百科)训练后获得的通用“语言理解”模型,该模型可用于自然语言处理下游任务(如自动问答)。BERT之所以表现得比过往的方法要好, 是因为它是首个用于自然语言处理预训练的无监督、深度双向系统。BERT的优势是能够轻松适用多种类型的自然语言处理任务。
Bert最关键有两点,第一点是特征抽取器采用Transformer,第二点是预训练的时候采用双向语言模型。
参考博客:Bert文本分类实战(附代码讲解)_Dr.sky_的博客-CSDN博客_bert实战
2.熟悉文本分类的常规方法
文本分类流程:1.输入文本预处理,2.文本表示及特征提取,3.构造分类器模型,4.文本分类。
文本分类技术参考博客:一文读懂文本分类技术路线_Yunlord的博客-CSDN博客_文本分类技术
二、过程
1.准备数据
#准备数据,从OSS中获取数据并解压到当前目录:
import os
import oss2
access_key_id = os.getenv('OSS_TEST_ACCESS_KEY_ID', 'LTAI4G1MuHTUeNrKdQEPnbph')
access_key_secret = os.getenv('OSS_TEST_ACCESS_KEY_SECRET', 'm1ILSoVqcPUxFFDqer4tKDxDkoP1ji')
bucket_name = os.getenv('OSS_TEST_BUCKET', 'mldemo')
endpoint = os.getenv('OSS_TEST_ENDPOINT', 'https://oss-cn-shanghai.aliyuncs.com')
# 创建Bucket对象,所有Object相关的接口都可以通过Bucket对象来进行
bucket = oss2.Bucket(oss2.Auth(access_key_id, access_key_secret), endpoint, bucket_name)
# 下载到本地文件
bucket.get_object_to_file('data/c12/bert_data.zip', 'bert_data.zip')![]()
#解压数据
!unzip -o -q bert_data.zip
!rm -rf __MACOSX![]()
!ls bert_input_data -ilht
2.导入库
import collections
import csv
import errno
import tensorflow as tf
import logging
import logging as log
import sys, os
import traceback
from sklearn.utils import shuffle
import pandas as pd
import numpy as np
import modeling
import optimization
import tokenization
%matplotlib inline ![]()
3.读取数据
#读取数据
df = pd.read_csv("./bert_input_data/train_data.tsv", header=0,sep='\t').sample(n=100,random_state=1)df.columns=['baseid','xtext','category']
df.head(5)
df.info()
# number of different class
print('\nnumber of different class: ', len(list(set(df.category))))
print(list(set(df.category))) ![]()
查看不同类别数据对比情况:
df.category.value_counts().plot(kind='bar') 
4.构建训练集
构建训练数据集,首先随机化数据:
from sklearn.utils import shuffle
df = shuffle(df,random_state=0)#查看随机化之后的数据情况
df.head() 
将数据按照8:1:1分为训练集、验证信和测试集三部分、
msk = np.random.rand(len(df)) < 0.8
train = df[msk]
dev_test = df[~msk]
msk = np.random.rand(len(dev_test)) < 0.5
dev = dev_test[msk]
test = dev_test[~msk]将数据集存为tsv格式,作为BERT模型的输入
export_csv_train = train.to_csv ('./bert_input_data/level1_train.tsv', sep='\t', index = None, header=None)
export_csv_dev = dev.to_csv ('./bert_input_data/level1_dev.tsv', sep='\t',index = None, header=None)
export_csv_test = test.to_csv ('./bert_input_data/level1_test.tsv', sep='\t',index = None, header=None)5.模型训练
定义模型超参
MODEL_OUTPUT_DIR = "./bert_output/"
init_checkpoint = "./chinese_wwm_ext_L-12_H-768_A-12/bert_model.ckpt"
bert_config_file = "./chinese_wwm_ext_L-12_H-768_A-12/bert_config.json"
vocab_file = "./chinese_wwm_ext_L-12_H-768_A-12/vocab.txt"
save_checkpoints_steps = 200
iterations_per_loop = 100
num_tpu_cores = 4
warmup_proportion =100
train_batch_size = 1
learning_rate=5e-5
eval_batch_size =1
predict_batch_size=2
max_seq_length =16
data_dir = "./bert_input_data/"#清理模型输出目录,减少磁盘占用
!rm bert_output -rfBERT算法数据准备及训练代码:
class InputExample(object):
"""A single training/test example for simple sequence classification."""
def __init__(self, guid, text_a, text_b=None, label=None):
self.guid = guid
self.text_a = text_a
self.text_b = text_b
self.label = label
class PaddingInputExample(object):
pass
class InputFeatures(object):
"""A single set of features of data."""
def __init__(self,
input_ids,
input_mask,
segment_ids,
label_id,
is_real_example=True):
self.input_ids = input_ids
self.input_mask = input_mask
self.segment_ids = segment_ids
self.label_id = label_id
self.is_real_example = is_real_example
class DataProcessor(object):
"""Base class for data converters for sequence classification data sets."""
def get_train_examples(self, data_dir):
"""Gets a collection of `InputExample`s for the train set."""
raise NotImplementedError()
def get_dev_examples(self, data_dir):
"""Gets a collection of `InputExample`s for the dev set."""
raise NotImplementedError()
def get_test_examples(self, data_dir):
"""Gets a collection of `InputExample`s for prediction."""
raise NotImplementedError()
def get_labels(self):
"""Gets the list of labels for this data set."""
raise NotImplementedError()
@classmethod
def _read_tsv(cls, input_file, quotechar=None):
"""Reads a tab separated value file."""
with tf.gfile.Open(input_file, "r") as f:
reader = csv.reader(f, delimiter="\t", quotechar=quotechar)
lines = []
for line in reader:
lines.append(line)
return lines
class SHLibProcessor(DataProcessor):
"""Processor for the SHlib data set ."""
def __init__(self, label_list):
self.static_label_list = load_labels(label_list)
def get_train_examples(self, train_lines):
"""See base class."""
return self._create_examples(train_lines, "train")
def get_dev_examples(self, eval_lines):
"""See base class."""
return self._create_examples(eval_lines, "dev")
def get_test_examples(self, predict_lines):
"""See base class."""
return self._create_examples(predict_lines, "test")
def get_labels(self):
"""See base class."""
return self.static_label_list
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev sets."""
examples = []
for (i, line) in enumerate(lines):
guid = line[0]# "%s-%s" % (set_type, i)
if set_type == "test":
text_a = tokenization.convert_to_unicode(line[1])
label = tokenization.convert_to_unicode(line[2])
else:
text_a = tokenization.convert_to_unicode(line[1])
label = tokenization.convert_to_unicode(line[2])
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=None, label=label))
return examples
def load_labels(self, label_file_path):
with open(label_file_path,'r') as label_file:
static_label_list = list(label_file.read().splitlines())
print(static_label_list)
return static_label_list
def convert_single_example(ex_index, example, label_list, max_seq_length,
tokenizer):
"""Converts a single `InputExample` into a single `InputFeatures`."""
if isinstance(example, PaddingInputExample):
return InputFeatures(
input_ids=[0] * max_seq_length,
input_mask=[0] * max_seq_length,
segment_ids=[0] * max_seq_length,
label_id=0,
is_real_example=False)
label_map = {}
for (i, label) in enumerate(label_list):
label_map[label] = i
tokens_a = tokenizer.tokenize(example.text_a)
tokens_b = None
if example.text_b:
tokens_b = tokenizer.tokenize(example.text_b)
if tokens_b:
_truncate_seq_pair(tokens_a, tokens_b, max_seq_length - 3)
else:
# Account for [CLS] and [SEP] with "- 2"
if len(tokens_a) > max_seq_length - 2:
tokens_a = tokens_a[0:(max_seq_length - 2)]
tokens = []
segment_ids = []
tokens.append("[CLS]")
segment_ids.append(0)
for token in tokens_a:
tokens.append(token)
segment_ids.append(0)
tokens.append("[SEP]")
segment_ids.append(0)
if tokens_b:
for token in tokens_b:
tokens.append(token)
segment_ids.append(1)
tokens.append("[SEP]")
segment_ids.append(1)
input_ids = tokenizer.convert_tokens_to_ids(tokens)
# The mask has 1 for real tokens and 0 for padding tokens. Only real
# tokens are attended to.
input_mask = [1] * len(input_ids)
# Zero-pad up to the sequence length.
while len(input_ids) < max_seq_length:
input_ids.append(0)
input_mask.append(0)
segment_ids.append(0)
assert len(input_ids) == max_seq_length
assert len(input_mask) == max_seq_length
assert len(segment_ids) == max_seq_length
label_id = label_map[example.label]
if ex_index < 3:
print("*** Example ***")
print("guid: %s" % (example.guid))
print("tokens: %s" % " ".join(
[tokenization.printable_text(x) for x in tokens]))
print("input_ids: %s" % " ".join([str(x) for x in input_ids]))
print("input_mask: %s" % " ".join([str(x) for x in input_mask]))
print("segment_ids: %s" % " ".join([str(x) for x in segment_ids]))
print("label: %s (id = %d)" % (example.label, label_id))
feature = InputFeatures(
input_ids=input_ids,
input_mask=input_mask,
segment_ids=segment_ids,
label_id=label_id,
is_real_example=True)
return feature
def file_based_convert_examples_to_features(examples, label_list, max_seq_length, tokenizer, output_file):
"""Convert a set of `InputExample`s to a TFRecord file."""
writer = tf.python_io.TFRecordWriter(output_file)
for (ex_index, example) in enumerate(examples):
if ex_index % 10000 == 0:
tf.logging.info("Writing example %d of %d" % (ex_index, len(examples)))
feature = convert_single_example(ex_index, example, label_list,
max_seq_length, tokenizer)
def create_int_feature(values):
f = tf.train.Feature(int64_list=tf.train.Int64List(value=list(values)))
return f
features = collections.OrderedDict()
features["input_ids"] = create_int_feature(feature.input_ids)
features["input_mask"] = create_int_feature(feature.input_mask)
features["segment_ids"] = create_int_feature(feature.segment_ids)
features["label_ids"] = create_int_feature([feature.label_id])
features["is_real_example"] = create_int_feature(
[int(feature.is_real_example)])
tf_example = tf.train.Example(features=tf.train.Features(feature=features))
writer.write(tf_example.SerializeToString())
writer.close()
def file_based_input_fn_builder(input_file, seq_length, is_training,
drop_remainder):
"""Creates an `input_fn` closure to be passed to TPUEstimator."""
name_to_features = {
"input_ids": tf.FixedLenFeature([seq_length], tf.int64),
"input_mask": tf.FixedLenFeature([seq_length], tf.int64),
"segment_ids": tf.FixedLenFeature([seq_length], tf.int64),
"label_ids": tf.FixedLenFeature([], tf.int64),
"is_real_example": tf.FixedLenFeature([], tf.int64),
}
def _decode_record(record, name_to_features):
"""Decodes a record to a TensorFlow example."""
example = tf.parse_single_example(record, name_to_features)
# tf.Example only supports tf.int64, but the TPU only supports tf.int32.
# So cast all int64 to int32.
for name in list(example.keys()):
t = example[name]
if t.dtype == tf.int64:
t = tf.to_int32(t)
example[name] = t
return example
def input_fn(params):
"""The actual input function."""
batch_size = params["batch_size"]
# For training, we want a lot of parallel reading and shuffling.
# For eval, we want no shuffling and parallel reading doesn't matter.
d = tf.data.TFRecordDataset(input_file)
if is_training:
d = d.repeat()
d = d.shuffle(buffer_size=100)
d = d.apply(
tf.contrib.data.map_and_batch(
lambda record: _decode_record(record, name_to_features),
batch_size=batch_size,
drop_remainder=drop_remainder))
return d
return input_fn
def _truncate_seq_pair(tokens_a, tokens_b, max_length):
"""Truncates a sequence pair in place to the maximum length."""
# This is a simple heuristic which will always truncate the longer sequence
# one token at a time. This makes more sense than truncating an equal percent
# of tokens from each, since if one sequence is very short then each token
# that's truncated likely contains more information than a longer sequence.
while True:
total_length = len(tokens_a) + len(tokens_b)
if total_length <= max_length:
break
if len(tokens_a) > len(tokens_b):
tokens_a.pop()
else:
tokens_b.pop()
def create_model(bert_config, is_training, input_ids, input_mask, segment_ids,
labels, num_labels, use_one_hot_embeddings):
"""Creates a classification model."""
model = modeling.BertModel(
config=bert_config,
is_training=is_training,
input_ids=input_ids,
input_mask=input_mask,
token_type_ids=segment_ids,
use_one_hot_embeddings=use_one_hot_embeddings)
# In the demo, we are doing a simple classification task on the entire
# segment.
#
# If you want to use the token-level output, use model.get_sequence_output()
# instead.
output_layer = model.get_pooled_output()
hidden_size = output_layer.shape[-1].value
output_weights = tf.get_variable(
"output_weights", [num_labels, hidden_size],
initializer=tf.truncated_normal_initializer(stddev=0.02))
output_bias = tf.get_variable(
"output_bias", [num_labels], initializer=tf.zeros_initializer())
with tf.variable_scope("loss"):
if is_training:
# I.e., 0.1 dropout
output_layer = tf.nn.dropout(output_layer, keep_prob=0.9)
logits = tf.matmul(output_layer, output_weights, transpose_b=True)
logits = tf.nn.bias_add(logits, output_bias)
probabilities = tf.nn.softmax(logits, axis=-1)
log_probs = tf.nn.log_softmax(logits, axis=-1)
one_hot_labels = tf.one_hot(labels, depth=num_labels, dtype=tf.float32)
per_example_loss = -tf.reduce_sum(one_hot_labels * log_probs, axis=-1)
loss = tf.reduce_mean(per_example_loss)
return (loss, per_example_loss, logits, probabilities)
def model_fn_builder(bert_config, num_labels, init_checkpoint, learning_rate,
num_train_steps, num_warmup_steps, use_tpu,
use_one_hot_embeddings):
"""Returns `model_fn` closure for TPUEstimator."""
def model_fn(features, labels, mode, params): # pylint: disable=unused-argument
"""The `model_fn` for TPUEstimator."""
tf.logging.info("*** Features ***")
for name in sorted(features.keys()):
print(" name = %s, shape = %s" % (name, features[name].shape))
input_ids = features["input_ids"]
input_mask = features["input_mask"]
segment_ids = features["segment_ids"]
label_ids = features["label_ids"]
is_real_example = None
if "is_real_example" in features:
is_real_example = tf.cast(features["is_real_example"], dtype=tf.float32)
else:
is_real_example = tf.ones(tf.shape(label_ids), dtype=tf.float32)
is_training = (mode == tf.estimator.ModeKeys.TRAIN)
(total_loss, per_example_loss, logits, probabilities) = create_model(
bert_config, is_training, input_ids, input_mask, segment_ids, label_ids,
num_labels, use_one_hot_embeddings)
tvars = tf.trainable_variables()
initialized_variable_names = {}
scaffold_fn = None
if init_checkpoint:
(assignment_map, initialized_variable_names) = modeling.get_assignment_map_from_checkpoint(tvars, init_checkpoint)
if use_tpu:
def tpu_scaffold():
tf.train.init_from_checkpoint(init_checkpoint, assignment_map)
return tf.train.Scaffold()
scaffold_fn = tpu_scaffold
else:
tf.train.init_from_checkpoint(init_checkpoint, assignment_map)
tf.logging.info("**** Trainable Variables ****")
for var in tvars:
init_string = ""
if var.name in initialized_variable_names:
init_string = ", *INIT_FROM_CKPT*"
tf.logging.info(" name = %s, shape = %s%s", var.name, var.shape,
init_string)
output_spec = None
if mode == tf.estimator.ModeKeys.TRAIN:
train_op = optimization.create_optimizer(
total_loss, learning_rate, num_train_steps, num_warmup_steps, use_tpu)
output_spec = tf.contrib.tpu.TPUEstimatorSpec(
mode=mode,
loss=total_loss,
train_op=train_op,
scaffold_fn=scaffold_fn)
elif mode == tf.estimator.ModeKeys.EVAL:
def metric_fn(per_example_loss, label_ids, logits, is_real_example):
predictions = tf.argmax(logits, axis=-1, output_type=tf.int32)
accuracy = tf.metrics.accuracy(
labels=label_ids, predictions=predictions, weights=is_real_example)
loss = tf.metrics.mean(values=per_example_loss, weights=is_real_example)
return {
"eval_accuracy": accuracy,
"eval_loss": loss,
}
eval_metrics = (metric_fn,
[per_example_loss, label_ids, logits, is_real_example])
output_spec = tf.contrib.tpu.TPUEstimatorSpec(
mode=mode,
loss=total_loss,
eval_metrics=eval_metrics,
scaffold_fn=scaffold_fn)
else:
# predictions = tf.argmax(logits, axis=-1, output_type=tf.int32)
# is_predicting = True
# (predicted_labels, log_probs) = create_model(
# is_predicting, input_ids, input_mask, segment_ids, label_ids, num_labels)
log_probs = tf.nn.log_softmax(logits, axis=-1)
probabilities = tf.nn.softmax(logits, axis=-1)
predicted_labels = tf.squeeze(tf.argmax(log_probs, axis=-1, output_type=tf.int32))
predictions = {
'probabilities': log_probs,
'labels': predicted_labels
}
output_spec = tf.contrib.tpu.TPUEstimatorSpec(
mode=mode,
predictions= predictions,#{"probabilities": probabilities},
scaffold_fn=scaffold_fn)
return output_spec
return model_fn
# This function is not used by this file but is still used by the Colab and
# people who depend on it.
def input_fn_builder(features, seq_length, is_training, drop_remainder):
"""Creates an `input_fn` closure to be passed to TPUEstimator."""
all_input_ids = []
all_input_mask = []
all_segment_ids = []
all_label_ids = []
for feature in features:
all_input_ids.append(feature.input_ids)
all_input_mask.append(feature.input_mask)
all_segment_ids.append(feature.segment_ids)
all_label_ids.append(feature.label_id)
def input_fn(params):
"""The actual input function."""
batch_size = params["batch_size"]
num_examples = len(features)
# This is for demo purposes and does NOT scale to large data sets. We do
# not use Dataset.from_generator() because that uses tf.py_func which is
# not TPU compatible. The right way to load data is with TFRecordReader.
d = tf.data.Dataset.from_tensor_slices({
"input_ids":
tf.constant(
all_input_ids, shape=[num_examples, seq_length],
dtype=tf.int32),
"input_mask":
tf.constant(
all_input_mask,
shape=[num_examples, seq_length],
dtype=tf.int32),
"segment_ids":
tf.constant(
all_segment_ids,
shape=[num_examples, seq_length],
dtype=tf.int32),
"label_ids":
tf.constant(all_label_ids, shape=[num_examples], dtype=tf.int32),
})
if is_training:
d = d.repeat()
d = d.shuffle(buffer_size=100)
d = d.batch(batch_size=batch_size, drop_remainder=drop_remainder)
return d
return input_fn
# This function is not used by this file but is still used by the Colab and
# people who depend on it.
def convert_examples_to_features(examples, label_list, max_seq_length,
tokenizer):
"""Convert a set of `InputExample`s to a list of `InputFeatures`."""
features = []
for (ex_index, example) in enumerate(examples):
if ex_index % 1000 == 0:
tf.logging.info("Writing example %d of %d" % (ex_index, len(examples)))
feature = convert_single_example(ex_index, example, label_list,
max_seq_length, tokenizer)
features.append(feature)
return featuresclass BTrainer(object):
def __init__(self, train_list, predict_list, lable_list, output_dir, num_train_epochs):
self.output_dir = output_dir
tokenization.validate_case_matches_checkpoint(True, init_checkpoint)
self.bert_config = modeling.BertConfig.from_json_file(bert_config_file)
tf.gfile.MakeDirs(self.output_dir)
self.processor = SHLibProcessor(lable_list)
self.label_list = self.processor.get_labels()
self.tokenizer = tokenization.FullTokenizer(
vocab_file=vocab_file, do_lower_case=True)
tpu_cluster_resolver = None
is_per_host = tf.contrib.tpu.InputPipelineConfig.PER_HOST_V2
self.run_config = tf.contrib.tpu.RunConfig(
cluster=tpu_cluster_resolver,
keep_checkpoint_max=1,
master=None,
model_dir=self.output_dir,
save_checkpoints_steps=save_checkpoints_steps,
tpu_config=tf.contrib.tpu.TPUConfig(
iterations_per_loop=iterations_per_loop,
num_shards=num_tpu_cores,
per_host_input_for_training=is_per_host))
num_train_steps = None
num_warmup_steps = None
self.train_examples = self.processor.get_train_examples(train_list)
self.num_train_steps = int(len(self.train_examples) / train_batch_size * num_train_epochs)
num_warmup_steps = int(self.num_train_steps * warmup_proportion)
self.predict_examples = self.processor.get_test_examples(predict_list)
model_fn = model_fn_builder(
bert_config=self.bert_config,
num_labels=len(self.label_list),
init_checkpoint=init_checkpoint,
learning_rate=learning_rate,
num_train_steps=self.num_train_steps,
num_warmup_steps=num_warmup_steps,
use_tpu=False,
use_one_hot_embeddings=False)
# If TPU is not available, this will fall back to normal Estimator on CPU
# or GPU.
self.estimator = tf.contrib.tpu.TPUEstimator(
use_tpu=False,
model_fn=model_fn,
config=self.run_config,
train_batch_size=train_batch_size,
eval_batch_size=eval_batch_size,
predict_batch_size=predict_batch_size)
def do_train(self):
try:
train_file = os.path.join(self.output_dir, "train.tf_record")
file_based_convert_examples_to_features(
self.train_examples, self.label_list, max_seq_length, self.tokenizer, train_file)
print("***** Running training *****")
train_input_fn = file_based_input_fn_builder(
input_file=train_file,
seq_length=max_seq_length,
is_training=True,
drop_remainder=True)
self.estimator.train(input_fn=train_input_fn, max_steps=self.num_train_steps)
print("train complete")
except Exception:
traceback.print_exc()
return -4
return 1
def do_predict(self):
num_actual_predict_examples = len(self.predict_examples)
predict_file = os.path.join(self.output_dir, "predict.tf_record")
file_based_convert_examples_to_features(self.predict_examples, self.label_list,
max_seq_length, self.tokenizer,
predict_file)
predict_drop_remainder = True
predict_input_fn = file_based_input_fn_builder(
input_file=predict_file,
seq_length=max_seq_length,
is_training=False,
drop_remainder=predict_drop_remainder)
result = self.estimator.predict(input_fn=predict_input_fn)
acc = 0
output_predict_file = os.path.join(self.output_dir, "test_results.tsv")
with tf.gfile.GFile(output_predict_file, "w") as writer:
num_written_lines = 0
print("***** Predict results *****")
correct_count = 0
for (i, prediction) in enumerate(result):
if i >= num_actual_predict_examples:
break
if self.predict_examples[i].label == self.label_list[prediction['labels']]:
correct_count += 1
num_written_lines += 1
writer.write(str(self.predict_examples[i].guid) + "\t" + str(self.predict_examples[i].text_a)
+ "\t" + str(self.predict_examples[i].label)
+ "\t" + str(self.label_list[prediction['labels']]) + "\n")
acc = correct_count/num_written_lines
print("total count:", num_written_lines, " correct:",correct_count," accuracy:",acc)
return acc#定义读取tsv和加载标签的方法
def _read_tsv(input_file, quotechar=None):
"""Reads a tab separated value file."""
with tf.gfile.Open(input_file, "r") as f:
reader = csv.reader(f, delimiter="\t", quotechar=quotechar)
lines = []
for line in reader:
lines.append(line)
return lines
def load_labels(label_file_path):
with open(label_file_path,'r') as label_file:
static_label_list = list(label_file.read().splitlines())
return static_label_list准备训练数据
train_file_path = "./bert_input_data/level1_train.tsv"
dev_file_path = "./bert_input_data/level1_dev.tsv"
test_file_path = "./bert_input_data/level1_test.tsv"
label_file_path = "./bert_input_data/label.txt"
train_epoch = 1定义模型训练方法
ef f_train_model(train_file_path,dev_file_path, lable_file_path,train_epoch):
if not os.path.exists(train_file_path) or not os.path.exists(train_file_path):
ret_value = 3
return ret_value
label_list = load_labels(lable_file_path)
if len(label_list) <= 1:
ret_value = 4
return ret_value
train = _read_tsv(train_file_path)
if len(train) <= 20:
ret_value = 5
return ret_value
dev = _read_tsv(dev_file_path)
print("train length:",len(train))
print("val length:",len(dev))
trainer = BTrainer(train, dev, lable_file_path, MODEL_OUTPUT_DIR, train_epoch)
return trainer.do_train()#训练模型
f_train_model(train_file_path, dev_file_path, label_file_path, train_epoch)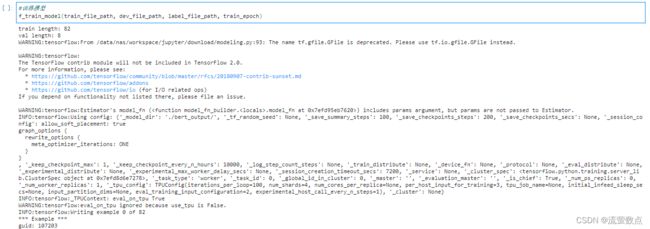
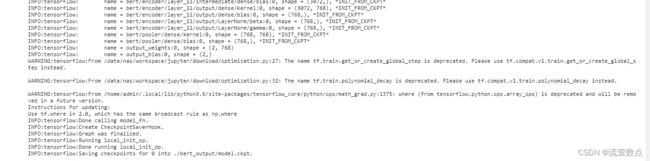 不知道怎么解决啊!
不知道怎么解决啊!
6.模型应用
定义模型验证方法
def f_test_model(train_file_path,test_file_path, lable_file_path):
if not os.path.exists(train_file_path) or not os.path.exists(train_file_path):
ret_value = 3
return ret_value
label_list = load_labels(lable_file_path)
if len(label_list) <= 1:
ret_value = 4
return ret_value
train = _read_tsv(train_file_path)
if len(train) <= 10:
ret_value = 5
return ret_value
test = _read_tsv(test_file_path)
print("test length:",len(test))
trainer = BTrainer(train, test, lable_file_path, MODEL_OUTPUT_DIR, 0)
return trainer.do_predict()#模训测试
f_test_model(train_file_path, test_file_path, label_file_path) 
好难搞啊,先放一放。