安装使用stanford corenlp以及并行加速的全教程
安装并开始使用stanford corenlp
方法一
有两种方式,一种是直接使用已经包装好的python wrapper,见网址 https://pypi.org/project/corenlp-client/,或者https://stanfordnlp.github.io/stanfordnlp/corenlp_client.html用Python开发的CoreNLP客户端工具。下载必要的软件包和相应的模型,就可以使用corenlp客户端启动corenlp服务器。
import corenlp
#tokenize pos lemma 可以选择其他的 这里就不多写了
client = corenlp.CoreNLPClient(annotators="tokenize pos lemma".split())
ann = client.annotate(sent)
缺点
不能并行,会出现以下错误
Cannot assign requested address
因为只适用于简单的测试,当数据很多,需要并行时,建议使用以下方法
方法二
直接安装(先看完后面,先别安装,这是一个排坑过程!!!!)
pip install stanfordnlp
github地址
点击下面地址
https://stanfordnlp.github.io/CoreNLP/index.html#download

下载之后解压缩。
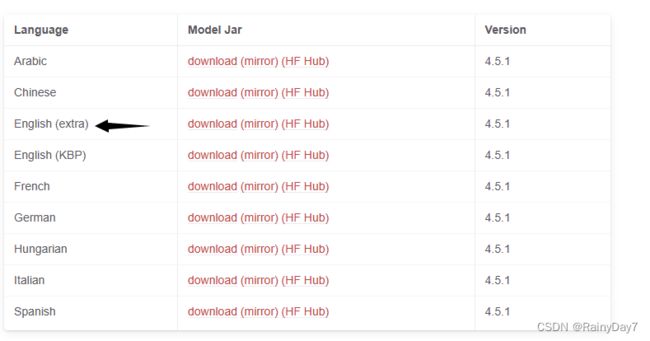
下载相应语言模型并放在上面解压缩的包里。
from stanfordcorenlp import StanfordCoreNLP
nlp = StanfordCoreNLP(r'./stanford-corenlp-full-2018-10-05',lang='en')
sentence = 'Are there any parking meters on the sidewalk near the street?'
print ('Tokenize:', nlp.word_tokenize(sentence))
print ('Part of Speech:', nlp.pos_tag(sentence))
print ('Named Entities:', nlp.ner(sentence))
print ('Constituency Parsing:', nlp.parse(sentence))
print ('Dependency Parsing:', nlp.dependency_parse(sentence))
nlp.close() # Do not forget to close! The backend server will consume a lot memery.
但是这样会遇到错误
json.decoder.JSONDecodeError:Expecting value:line 1 column 1 (char 0)
其实这是因为stanfordcorenlp和刚刚下载的安装包版本不对应,建议使用比较早的版本3.9.2版本,就不会报错
下载以往版本的链接:https://stanfordnlp.github.io/CoreNLP/history.html

其余操作同上
最后就可以了
并行处理
想要处理的数据太多
nlp = StanfordCoreNLP(r'/stanford-corenlp-full-2018-10-05',lang='en')
#进度条
pbar = tqdm(total=100)
update = lambda *args: pbar.update()
def fun(a):
return a
pool_size = multiprocessing.cpu_count()-1
print(pool_size)
p = multiprocessing.Pool(pool_size)
for i in range(100):
#可以多个参数
p.apply_async(fun, (a,), callback=update)
p.close()
p.join()
另外,如果想要多个进程对同一个数据处理(我个人的需求是,将所有语法分析的结果都保存在一个字典里)
nlp = StanfordCoreNLP(r'/stanford-corenlp-full-2018-10-05',lang='en')
#进度条
pbar = tqdm(total=100)
update = lambda *args: pbar.update()
def fun(a, share_data_dict, share_lock):
# 获取锁
share_lock.acquire()
# share_var.append(process_name)
share_var[img_id] = source_dict
# 释放锁
share_lock.release()
return a
pool_size = multiprocessing.cpu_count()-1
print(pool_size)
p = multiprocessing.Pool(pool_size)
share_data_dict = multiprocessing.Manager().dict()
share_lock = multiprocessing.Manager().Lock()
for i in range(100):
#可以多个参数
p.apply_async(fun, (a, share_data_dict, share_lock), callback=update)
p.close()
p.join()
另外两个遇到的错误
pool not running
joblib.externals.loky.process_executor._RemoteTraceback:PermissionError:[WinError 5]