Swin Transformer猫狗分类
前言
早上看了一下Swin Transformer的论文,觉得还不错,就看了看代码,还挺简洁。
我不说是谁,那么无聊画了一下午用Swin Tranformer实现猫狗分类…

代码
依赖
需要下载一个库, 在终端运行则不需要前面的英文感叹号
!pip install timm
将依赖import 进来
import torch
import torchvision
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from torchvision import models
from timm.models.swin_transformer import SwinTransformer
import numpy as np
import os
import cv2
import random
import shutil
from tqdm import tqdm
设置一些超参数
batch_size_train = 32
batch_size_test = 32
learning_rate = 0.01
momentum = 0.5
log_interval = 10
random_seed = 1
torch.manual_seed(random_seed)
如果有gpu则使用gpu加速
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(device)
数据准备
下载数据
!wget https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_3367a.zip
查看一下大小
!du -sh /content/kagglecatsanddogs_3367a.zip
# 787M
解压
!unzip kagglecatsanddogs_3367a.zip
显示一下部分图片,其实图片是彩色的,只是这段代码写的不那么好,出来时灰色的,以后再改。另外从图片看出,图片不是正方形,不是224224 或 384384,所以后面读取的时候需要resize一下。
# 本小块展示的代码来自: https://blog.csdn.net/Neuf_Soleil/article/details/83957756
DATADIR = "/content/PetImages"
CATEGORIES = ["Dog", "Cat"]
for category in CATEGORIES:
path = os.path.join(DATADIR,category)
for img in os.listdir(path):
img_array = cv2.imread(os.path.join(path, img) ,cv2.IMREAD_GRAYSCALE) # 把图片读取为数组
plt.imshow(img_array, cmap='gray') # 使用灰度图
plt.show()
break # 这里先拿一个图片测试,所以 break 两次


划分训练集和测试集
注意,有时候你的数据集已经划分好了,所以不需要该步骤。但是这里我们下载的数据集是这样的:
| PetImages
| --- Cat
| --- Dog
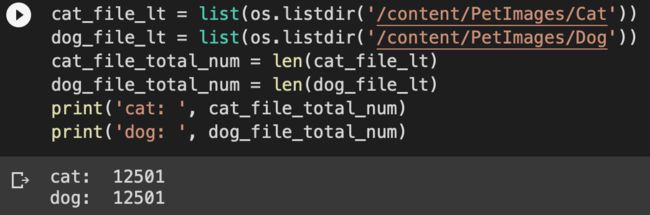
cat_file_lt = list(os.listdir('/content/PetImages/Cat'))
dog_file_lt = list(os.listdir('/content/PetImages/Dog'))
cat_file_total_num = len(cat_file_lt)
dog_file_total_num = len(dog_file_lt)
print('cat: ', cat_file_total_num)
print('dog: ', dog_file_total_num)
dir_lt = ['data', 'data/train', 'data/test',
'data/train/Cat', 'data/train/Dog',
'data/test/Cat', 'data/test/Dog']
for dir in dir_lt:
if not os.path.exists(dir):
os.mkdir(dir)
# 打乱数据
random.shuffle(cat_file_lt)
random.shuffle(dog_file_lt)
def copy_from_lt1_to_lt2(origin_dir, origin_lt, target_dir):
for pic in tqdm(origin_lt):
origin_path = os.path.join(origin_dir, pic)
target_path = os.path.join(target_dir, pic)
shutil.copyfile(origin_path, target_path)
# 做个例子,拿1000张...
# train_test_split = int(cat_file_total_num * 0.8)
train_cat_lt = cat_file_lt[:1000]
train_dog_lt = dog_file_lt[:1000]
test_cat_lt = cat_file_lt[1000:1200]
test_dog_lt = dog_file_lt[1000:1200]
train_test_path_lt = [('/content/PetImages/Cat', train_cat_lt, '/content/data/train/Cat'),
('/content/PetImages/Dog', train_dog_lt, '/content/data/train/Dog'),
('/content/PetImages/Cat', test_cat_lt, '/content/data/test/Cat'),
('/content/PetImages/Dog', test_dog_lt, '/content/data/test/Dog')]
copy_from_lt1_to_lt2(*(train_test_path_lt[0]))
copy_from_lt1_to_lt2(*(train_test_path_lt[1]))
copy_from_lt1_to_lt2(*(train_test_path_lt[2]))
copy_from_lt1_to_lt2(*(train_test_path_lt[3]))

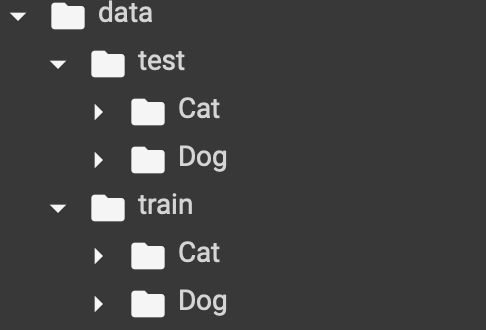
处理完后目录结构如下:
读取图片
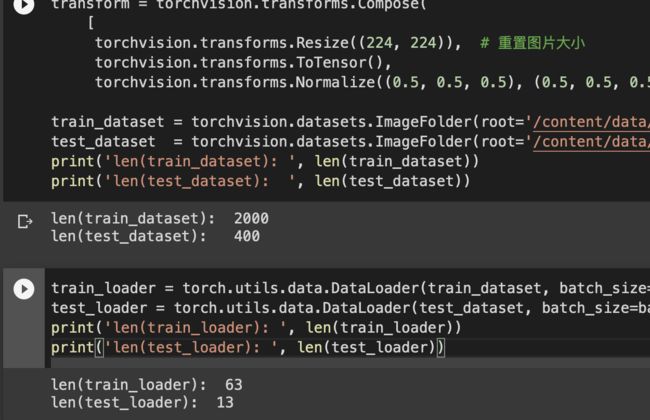
transform = torchvision.transforms.Compose(
[
torchvision.transforms.Resize((224, 224)), # 重置图片大小
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_dataset = torchvision.datasets.ImageFolder(root='/content/data/train', transform=transform)
test_dataset = torchvision.datasets.ImageFolder(root='/content/data/test', transform=transform)
print('len(train_dataset): ', len(train_dataset))
print('len(test_dataset): ', len(test_dataset))
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size_train, shuffle=True, num_workers=2)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size_test, shuffle=True, num_workers=2)
print('len(train_loader): ', len(train_loader))
print('len(test_loader): ', len(test_loader))
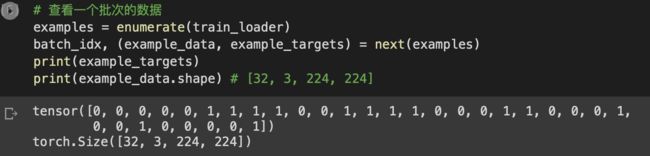
# 查看一个批次的数据
examples = enumerate(train_loader)
batch_idx, (example_data, example_targets) = next(examples)
print(example_targets)
print(example_data.shape) # [32, 3, 224, 224]
# 本小块展示的代码来自 https://blog.csdn.net/theVicTory/article/details/109230519
import matplotlib.pyplot as plt
import numpy as np
# 输出图像的函数
def imshow(img):
img = img / 2 + 0.5 # 反标准化
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# 获取一个批次的训练图片、标签并显示
images, labels = iter(train_loader).next()
imshow(torchvision.utils.make_grid(images))

模型定义
模型定义可参考原论文的表格。

这里我用Swin transformer的Tiny版本,它的参数量和ResNet50差不多。
swin_tiny_cfg = dict(patch_size=4, window_size=7, embed_dim=96, depths=(2, 2, 6, 2), num_heads=(3, 6, 12, 24))
swin_tiny = SwinTransformer(**swin_tiny_cfg)
下载权重
!wget https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_tiny_patch4_window7_224.pth
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.backbone = SwinTransformer(**swin_tiny_cfg)
self.backbone.load_state_dict(
torch.load('/content/swin_tiny_patch4_window7_224.pth',
map_location=torch.device(device))['model'], strict=True)
self.fc1 = nn.Linear(768, 256)
self.fc2 = nn.Linear(256, 2)
self.relu = nn.ReLU()
def forward(self, x):
"""
Swin Transformer https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/swin_transformer.py
def forward_features(self, x):
x = self.patch_embed(x)
if self.absolute_pos_embed is not None:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
x = self.layers(x)
x = self.norm(x) # B L C
x = self.avgpool(x.transpose(1, 2)) # B C 1
x = torch.flatten(x, 1)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
"""
x = self.backbone.forward_features(x) # [batch_size, 768]
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x) # [batch_size, 2]
return x
model = Net()
# output = model(example_data)
# print(output.shape)
model = model.to(device)
看看参数量
def get_parameter_number(model_analyse):
# 打印模型参数量
total_num = sum(p.numel() for p in model_analyse.parameters())
trainable_num = sum(p.numel() for p in model_analyse.parameters() if p.requires_grad)
return 'Total parameters: {}, Trainable parameters: {}'.format(total_num, trainable_num)
# 查看一下模型总的参数量和可学习参数量
get_parameter_number(model)

训练与预测
损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate,
momentum=momentum)
记录训练过程的损失变化
train_losses = []
train_counter = []
test_losses = []
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
data = data.to(device)
target = target.to(device)
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
train_losses.append(loss.item())
train_counter.append(
(batch_idx * batch_size_train) + ((epoch - 1) * len(train_loader.dataset)))
torch.save(model.state_dict(), './model.pth')
torch.save(optimizer.state_dict(), './optimizer.pth')
作为演示,只训练一个epoch,通常是几个。
train(epoch=1)

def test():
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data = data.to(device)
target = target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).sum()
test_loss /= len(test_loader.dataset)
test_losses.append(test_loss)
print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
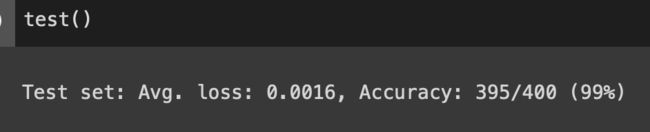
这准确率很惊人…虽然只是二分类问题…
test()
画出训练时损失下降趋势
fig = plt.figure()
plt.plot(train_counter, train_losses, color='blue')
plt.legend(['Train Loss'], loc='upper right')
plt.xlabel('number of training examples seen')
plt.ylabel('negative log likelihood loss')
plt.show()
