机器学习基础
目录
1、机器学习概念
1.1 简介
1.2 机器学习算法分类
2、监督学习
监督学习算法
3、无监督学习
无监督学习算法:
1、机器学习概念
1.1 简介
机器学习能够从无序的数据中提取出有用的信息,那么什么是机器学习呢?以垃圾邮件的检测为例,垃圾邮件的检测是指能够对邮件做出判断,判断其为垃圾邮件还是正常邮件。
机器学习是从数据中学习和提取有用的信息,不断提升机器的性能。那么,对于一个具体的机器学习的问题,很重要的一部分是对数据的收集,我们称这部分数据为训练数据。机器学习的基本工作是从这些数据中学习规则,利用学习到的规则来预测新的数据。
1.2 机器学习算法分类
在机器学习中,根据任务的不同,可以分为监督学习(Supervised Learning)、无监督学习(Unsupervised Learning )、半监督学习( Semi-Supervised Learning )和增强学习( Reinforcement Learning )
监督学习(Supervised Learning )的训练数据包含了类别信息,如在垃圾邮件检测中,其训练样本包含了邮件的类别信息:垃圾邮件和非垃圾邮件。在监督学习中,典型的问题是分类( Classification )和回归( Regression ),典型的算法有Logistic Regression、BP神经网络算法和线性回归算法。
无监督学习(Unsupervised Learning ),与监督学习不同的是,无监督学习的训练数据中不包含任何类别信息。在无监督学习中,其典型的问题为聚类(Clustering)问题,代表算法有K-Means算法、DBSCAN算法等。
半监督学习(Semi-Supervised Learning )的训练数据中有一部分数据包含类别信息,同时有一部分数据不包含类别信息,是监督学习和无监督学习的融合。在半监督学习中,其算法一般是在监督学习的算法上进行扩展,使之可以对未标注数据建模。监督学习和无监督学习是使用较多的两种学习方法,而半监督学习是监督学习和无监督学习的融合,在本书中,我们着重介绍监督学习和非监督学习。
2、监督学习
监督学习是机器学习算法中的一种重要的学习方法,在监督学习中,其训练样本中同时包含有特征和标签信息。在监督学习中,分类(Classification )算法和回归(Regression)算法是两类最重要的算法,两者之间最主要的区别是分类算法中的标签是离散的值
分类算法:如广告点击问题中的标签为(+1,-1),分别表示广告的点击和未点击;
回归算法:而回归算法中的标签值是连续的值,如通过人的身高、性别、体重等信息预测人的年龄,因为年龄是连续的正整数,因此标签为y∈N+,且y∈[1,80]。
 监督学习流程
监督学习流程
监督学习算法
分类问题(Classification)是指通过训练数据学习一个从观测样本到离散的标签的映射,分类问题是一个监督学习问题。典型的问题有:①垃圾邮件的分类(SpamClassification ):训练样本是邮件中的文本,标签是每个邮件是否是垃圾邮件({+1,-1},+1表示是垃圾邮件,-1表示不是垃圾邮件),目标是根据这些带标签的样本,预测个新的邮件是否是垃圾邮件;②点击率预测(Click-through Rate Prediction):训练样本是用户、广告和广告主的信息,标签是是否被点击([+1,-1),+1表示点击,-1表示未点击)。目标是在广告主发布广告后,预测指定的用户是否会点击,上述两种问题都是二分类的问题; ③手写字识别,即识别是(0,1,…,9)中的哪个数字,这是一个多分类的问题。
回归问题(Regression)是指通过训练数据学习一个从观测样本到连续的标签的映射,在回归问题中的标签是一系列连续的值。典型的回归问题有:①股票价格的预测,即利用股票的历史价格预测未来的股票价格;②房屋价格的预测,即利用房屋的数据,如房屋的面积、位置等信息预测房屋的价格。
3、无监督学习
无监督学习(Unsupervised Learning)是另一种机器学习算法,与监督学习不同的是,在无监督学习中,其样本中只含有特征,不包含标签信息。与监督学习( Supervised Learning)不同的是,由于无监督学习不包含标签信息,在学习时并不知道其分类结果是否正确。
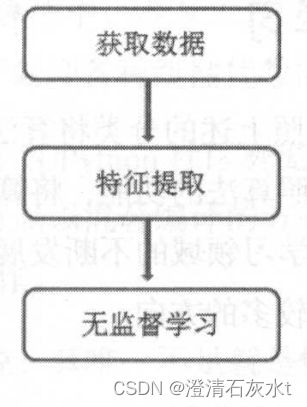 无监督学习流程
无监督学习流程
对于具体的无监督学习任务,首先是获取到带有特征值的样本,假设有m个训练数据{X(1),X(2),…,X(m)},对这m个样本进行处理,得到样本中有用的信息,这个过程称为特征处理或者特征提取,最后是通过无监督学习算法处理这些样本,如利用聚类算法对这些样本进行聚类。
无监督学习算法:
(1)聚类算法
聚类算法是无监督学习算法中最典型的一种学习算法。聚类算法利用样本的特征,将具有相似特征的样本划分到同一个类别中,而不关心这个类别具体是什么。
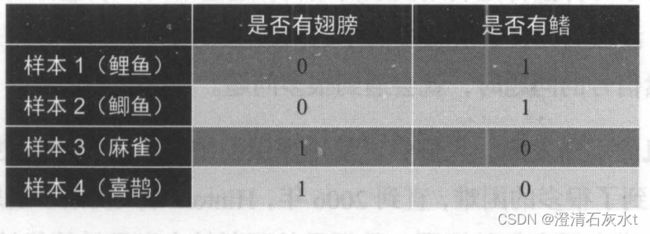 聚类算法
聚类算法
在表所示的聚类问题中,通过分别比较特征1(是否有翅膀)和特征2(是否有鳍),对上述的样本进行聚类。从表0-1中的数据可以看出,样本1和样本2较为相似,样本3和样本4较为相似,因此,可以将样本1和样本2划分到同一个类别中,将样本3和样本4划分到另一个类别中,而不用去关心样本1和样本2所属的类别具体是什么。
(2)降维算法
除了聚类算法,在无监督学习中,还有一类重要的算法是降维的算法,数据降维基本原理是将样本点从输入空间通过线性或非线性变换映射到一个低维空间,从而获得一个关于原数据集紧致的低维表示。
P28