一文带你入门机器学习中的树模型(附源码)
树模型
树模型在机器学习中至关重要,它不仅本身具有较好的性能,也可以用于优化其他的算法。
我们在本节将要介绍优化 K N N ~KNN~ KNN 算法的树模型以及决策树。
一、 K N N ~KNN~ KNN 的数据结构
在KNN算法中我们要找到测试点的最近的K个邻居,但是这需要我们求解所有点与测试点之间的距离(我们称这个过程为线性扫描),在数据集很大时这显然是不合理的,为此我们需要在此讨论以下KNN算法的数据结构。
1.1 时间复杂度
我们首先回顾一下 K N N ~KNN~ KNN 算法的时间复杂度,设数据集大小为 n ~n~ n ,特征向量维度为 d ~d~ d ,则对一个点进行分类的时间复杂度为: O ( n d ) ~O(nd)~ O(nd)
显然,随着数据集的增大,计算量将变得巨大,导致算法运行速度很慢,这并不是我们想看到的
我们希望找到一个较好的数据结构,使得对测试点进行分类时不再需要遍历每一个点。
1.2 K D ~KD~ KD 树
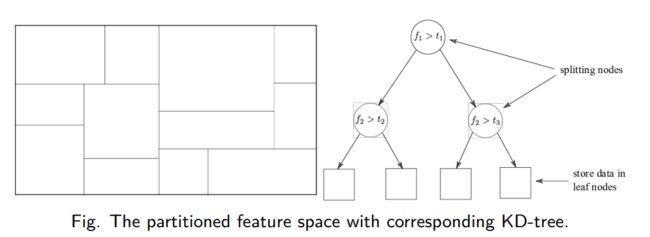
K D ~KD~ KD (K-Dimensional)树是一种对 k ~k~ k 维空间中的实例点进行存储以便对其进行快速检索的树形数据结构,它是一种二叉树,表示对 k ~k~ k 维空间的一个划分。
构造 K D ~KD~ KD 树相当于不断地用超平面将 k ~k~ k 维空间划分,构成一系列的 k ~k~ k 维超矩形区域, K D ~KD~ KD 树的每一个结点对应一个超矩形。
1.2.1 构造KD树
构造 K D ~KD~ KD 树的方法如下:
① 构造根节点,根节点对应特征空间中包含所有实例点的超矩形区域。
② 在超矩形区域选择一个坐标轴和在此坐标轴上的一个切分点,由此确定一个超平面,这个超平面通过选定的切分点并垂直于选定的坐标轴,将当前的超矩形区域分为左右两个子区域,这时该超矩形内的实例被分到了两个子区域,生成两个子节点。
③ 对每个结点重复执行②操作直到子区域内不再存在实例,由此得到的结点为叶子结点。
构造 K D ~KD~ KD 树的算法的形式化定义如下:
输入: k ~k k维空间数据集为:
D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) } D=\{(x_1,y_1),(x_2,y_2),...,(x_n,y_n)\} D={(x1,y1),(x2,y2),...,(xn,yn)}
其中我们将特征向量对应的数据集记为:
T = { x 1 , x 2 , . . . , x n } T=\{x_1,x_2,...,x_n\} T={x1,x2,...,xn}
其中的特征向量为 k ~k~ k 维向量:
x i = [ x i ( 1 ) , x i ( 2 ) , . . . , x i ( k ) ] T x_i=[~x_i^{(1)},x_i^{(2)},...,x_i^{(k)}~]^T xi=[ xi(1),xi(2),...,xi(k) ]T
(1)开始:构造根节点:根节点对应包含 T ~T~ T 的 k ~k~ k 维空间的超矩形区域。
选择 x ( 1 ) ~x^{(1)}~ x(1) 为坐标轴,以 T ~T~ T 中所有实例的 x ( 1 ) ~x^{(1)}~ x(1) 坐标的中位数为切分点,将根节点对应的超矩形区域分为两个子区域。
切分由通过切分点并与坐标轴 x ( 1 ) ~x^{(1)}~ x(1) 垂直的超平面实现,由根节点生成深度为1的左、右子节点:
切分点: x p = m e d i a n ( x ( 1 ) ) 左子节点中的实例: x ( 1 ) < x p 右子节点中的实例: x ( 1 ) > x p \begin{aligned} &切分点:x_p= {median}(x^{(1)})\\ &左子节点中的实例:x^{(1)}
将落在切分超平面上的实例点保存为根节点。
(2)重复:对深度为 j ~j~ j 的结点,选择 x ( l ) ~x^{(l)}~ x(l) 为切分的坐标轴, l = ( j m o d k ) + 1 ~l=(j\mod k)+1~ l=(jmodk)+1 ,以该节点区域中所有实例的 x ( l ) ~x^{(l)}~ x(l) 的中位数为切分点,将该节点对应的超矩形区域切分为两个子区域,切分由通过切分点并与坐标轴 x ( l ) ~x^{(l)}~ x(l) 垂直的超平面实现。
由该节点生成深度为 j + 1 ~j+1~ j+1 的左、右子节点:
切分点: x p = m e d i a n ( x ( l ) ) 左子节点中的实例: x ( l ) < x p 右子节点中的实例: x ( l ) > x p \begin{aligned} &切分点:x_p= {median}(x^{(l)})\\ &左子节点中的实例:x^{(l)}
将落在切分超平面上的实例点保存在该节点。
对于维度的选择还有另一个方法,即选择方差最大的维度去进行划分,这样可能会划分得更好。
(3)直到两个子区域没有实例存在时停止,从而形成 K D ~KD~ KD 树的区域划分。
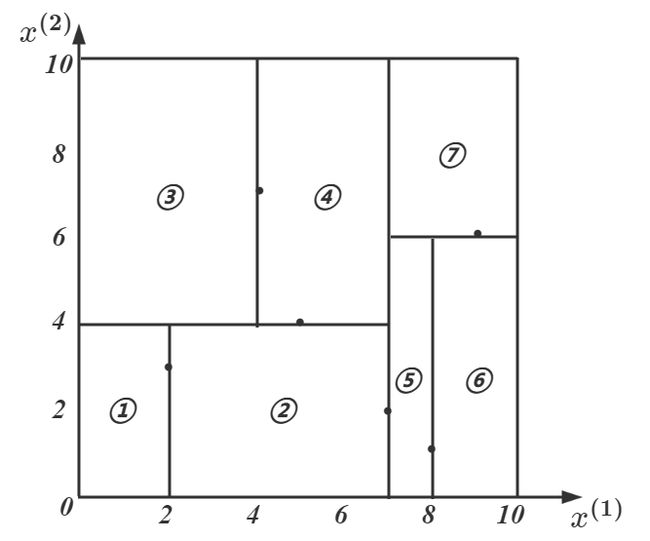
我们不妨在 2 ~2~ 2 维空间模拟一下 K D ~KD~ KD 树构造的过程:
T = { ( 2 , 3 ) T , ( 5 , 4 ) T , ( 9 , 6 ) T , ( 4 , 7 ) T , ( 8 , 1 ) T , ( 7 , 2 ) T } T=\{(2,3)^T,(5,4)^T,(9,6)^T,(4,7)^T,(8,1)^T,(7,2)^T\} T={(2,3)T,(5,4)T,(9,6)T,(4,7)T,(8,1)T,(7,2)T}
其构造过程如下:
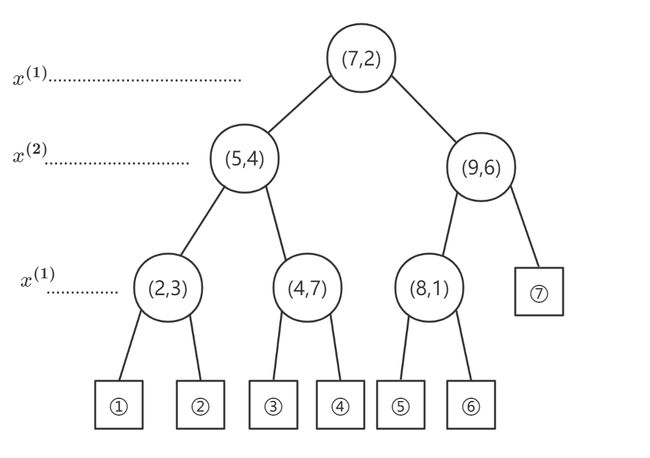
①选择根节点: x ( 1 ) ~x^{(1)}~ x(1) 所对应的切分点: ( 5 , 4 ) ~(5,4)~ (5,4) 或 ( 7 , 2 ) ~(7,2)~ (7,2) ,我们不妨选择 ( 7 , 2 ) ~(7,2)~ (7,2)
左子区域包含: ( 2 , 3 ) , ( 4 , 7 ) , ( 5 , 4 ) ~(2,3),(4,7),(5,4)~ (2,3),(4,7),(5,4) ,右子区域包含: ( 8 , 1 ) , ( 9 , 6 ) ~(8,1),(9,6)~ (8,1),(9,6)
②对深度为 1 ~1~ 1 的结点继续划分: l = ( 1 m o d 2 ) + 1 = 2 ~l=(1\mod 2)+1=2~ l=(1mod2)+1=2 ,以 x ( 2 ) ~x^{(2)}~ x(2) 为基准进行划分
左子区域切分点: ( 5 , 4 ) ~(5,4)~ (5,4) ,右子区域切分点: ( 9 , 6 ) ~(9,6)~ (9,6)
③对深度为 2 ~2~ 2 的结点继续划分: l = ( 2 m o d 2 ) + 1 = 1 ~l=(2\mod 2)+1=1~ l=(2mod2)+1=1 ,以 x ( 1 ) ~x^{(1)}~ x(1) 为基准进行划分
由此得到三个新的切分点: ( 2 , 3 ) , ( 4 , 7 ) , ( 8 , 1 ) ~(2,3),(4,7),(8,1)~ (2,3),(4,7),(8,1)
由此得到的划分如下图所示:
得到的 K D ~KD~ KD 树如下:
注意:我们在实际的算法中往往并不会使用全部的实例点去构造 K D ~KD~ KD 树,因为这样的时间复杂度很高,往往选取部分点对区域进行划分
1.2.2 搜索KD树
我们构造KD树的目的还是用于进行分类,因此我们需要思考如何搜索KD树来进行分类,k-近邻的搜索方式如下:
①对于给定的测试点 x t ~x_t~ xt ,我们首先在 K D ~KD~ KD 树中找到包含该测试点的叶子结点
②从该结点出发,依次退回到父节点,不断查找与目标点最邻近的结点
③当确定不可能存在更近的结点时中止,这样搜索区域便被限制在空间的局部区域上了
为了更加直观得理解该算法,我们进行详细的分析:以 1 − N N ~1-NN~ 1−NN 为例
输入:已构造的 K D ~KD~ KD 树,目标点 x t ~x_t~ xt
输出: x t ~x_t~ xt 的最近邻
(1)在 K D ~KD~ KD 树中找到包含目标点的叶子节点:寻找方法很容易,只需要从根节点开始递归得访问 K D ~KD~ KD 树,如果 x t ( l ) < x p ~x_t^{(l)}
(2)此叶子结点为“当前最近结点”,递归得向上回退,对每个结点进行如下操作:
① 如果该结点保存的实例点比“当前最近结点”离目标点 x t ~x_t~ xt 距离更近,则以当前结点为“当前最近结点”
② 当前最近点一定存在于该结点的一个子结点对应的区域,检查该子结点对应的父结点的另一子结点对应的区域中是否存在更近的点。
具体地,检查另一子结点对应地区域是否与以目标点为球心、以目标点与当前最近结点的距离为半径的超球体相交,如果相交则可能存在另一个子结点对应的区域内存在距离目标点更近的点,移动到另一个子结点,接着递归得进行搜索。
如果不相交则向上回退。
(3)当回退到根节点时,搜索结束。最后的“当前最近结点”记为 x t ~x_t~ xt 的最近邻点。
如果实例点是随机分布的,则 K D ~KD~ KD 树搜索的平均计算时间复杂度为 O ( log n ) ~O(\log n)~ O(logn) , K D ~KD~ KD 树更加适合训练实例数 n ~n~ n 远大于空间维数 k ~k~ k 时的 k ~k~ k 近邻搜索,当训练实例数接近特征空间维度数时它则接近于线性扫描。
我们以下图为例: A ~A~ A 为根节点,子结点为 B 、 C ~B、C~ B、C ,目标点为 S ~S~ S
得到的 K D ~KD~ KD 树如下:
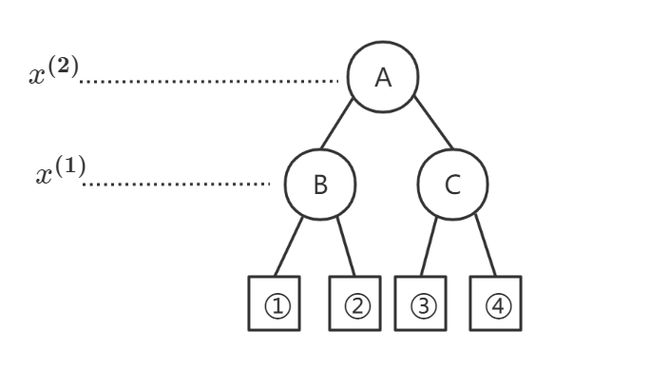
(1) 首先,我们找到了 S ~S~ S 位于区域②,因此得到“当前最近结点”为 D ~D~ D
(2) 然后,检查叶子节点②的父节点 B ~B~ B 的另一子结点①,发现①没有与超球体相交,则不需要检查
(3) 继续,返回父节点 A ~A~ A ,发现结点 C ~C~ C 对应的区域中④与超球体相交,对④进行搜索找到了更近的点 E ~E~ E
(4) 最终,我们得到了 S ~S~ S 的最近邻为 E ~E~ E
1.2.3 代码实现
手动实现的代码更加灵活,但鉴于笔者才疏学浅,我的选择往往是调库,手动实现是为了加强理解。
首先我们定义树节点类:代码实现参考了文章 k近邻算法之kd树优化
'''定义树节点'''
class TreeNode:
def __init__(self,x=None,y=None,dim=None,left=None,right=None,father=None):
'''
:param x: 该结点存储的特征向量
'''
self.vec = x #特征向量
self.label = y #样本标签
self.dim = dim #特征维度
self.left = left #左子节点
self.right = right #右子节点
self.father = father #父节点
接着我们定义用于构造和搜索Kd树的类:
'''定义KD树'''
class Kd_Tree(object):
'''初始化'''
def __init__(self,data,target):
self.n=len(data) #样本数量
self.d=len(data[0]) #特征维度数
self.X=data #存储特征向量数据集
self.Y=target #存储标签数据集
self.root=self.buildKdTree(data,target) #构造Kd树
'''构造Kd树'''
def buildKdTree(self,data,target,father=None):
'''
:param data: numpy数组,特征向量
:param target: numpy数组,标签向量
:return: Kd树
'''
dataNum=len(data) #样本数量
'''样本为空,返回空'''
if dataNum==0:
return None
'''选择切分的维度'''
varList=self.getVar(data)
maxVarDimIndex = varList.index(max(varList)) #找到方差最大的维度
sortIndex=data[:,maxVarDimIndex].argsort() #按照维度maxVarDimIndex从小到大排列的索引
'''找到中位数下标'''
mid=sortIndex[dataNum//2]
'''构造根节点'''
root=TreeNode(x=data[mid],y=target[mid],dim=maxVarDimIndex,father=father)
'''只有一个数据点时直接返回'''
if dataNum==1:
return root
'''划分左右子树并递归构造'''
leftdata=data[sortIndex[:dataNum//2]]
lefttatget=target[sortIndex[:dataNum//2]]
rightdata=data[sortIndex[dataNum//2+1:]]
righttarget=target[sortIndex[dataNum//2+1:]]
root.left=self.buildKdTree(leftdata,lefttatget,root)
root.right=self.buildKdTree(rightdata,righttarget,root)
return root
'''找到包含目标点的叶子节点'''
def findLeafNode(self,x,root):
if root==None: #树为空
return None
if root.left==None and root.right==None: #树只有一个结点
return root
node=root
while True: #找到叶子节点为止
dim=node.dim
if x[dim]<node.vec[dim]: #转到左子结点
if not node.left: #左子节点为空
return node
node=node.left
else: #转到右子节点
if not node.right: #右子节点为空
return node
node=node.right
'''搜索Kd树'''
def searchKdTree(self,x,k):
'''
:param x: 目标点的特征向量
:param k: k近邻的参数k
:return: 分类标签
'''
if self.n<=k: #所有的数据点都是近邻
'''找到出现次数最多的标签'''
labelNum={}
for label in self.Y:
if label not in labelNum.keys():
labelNum[label]=1
else:
labelNum[label]+=1
list=sorted(labelNum.items(),key=lambda x:x[1],reverse=True)
return list[0][0]
'''找到目标点x所属的叶子节点'''
node=self.findLeafNode(x,self.root)
if node==None: #空树情况
return None
'''计算叶子节点与目标点之间的欧式距离'''
eulerDistance=np.sqrt(sum((x-node.vec)**2)) #这是当前超球体半径
nodeList=[] #存储当前搜索到的k近邻
nodeList.append([eulerDistance,tuple(node.vec),node.label]) #[距离distance,特征向量vec,标签label]
'''向上递归搜索'''
while True:
if node==self.root: #回溯到根节点,停止回溯
break
'''检查父节点'''
father=node.father
fatherDistance=np.sqrt(sum((x-father.vec)**2))
'''
找到的近邻小于k个或者当前超球体半径与父节点对应的区域相交,则更新超球体半径
'''
if k>len(nodeList) or eulerDistance>fatherDistance:
nodeList.append([fatherDistance,tuple(father.vec),father.label])
nodeList.sort() #从小到大排序
eulerDistance= nodeList[-1][0] if k > len(nodeList) else nodeList[k-1][0] #更新超球体半径
'''找到的近邻仍小于k个或者目标点到切分超平面的距离小于超球体半径,即超球体与父节点的另一结点区域相交'''
if k>len(nodeList) or abs(x[father.dim]-father.vec[father.dim])<eulerDistance:
if x[father.dim]<father.vec[father.dim]: #目标点在父节点的左侧区域,则要检查右侧区域
otherChild=father.right
nodeList=self.search(nodeList,otherChild,x,k) #检查左侧区域对超球体进行更新
else: #目标点在父节点的右侧区域,则要检查左侧区域
otherChild=father.left
nodeList=self.search(nodeList,otherChild,x,k) #检查右侧区域对超球体进行更新
node=node.father #回溯到父节点
'''完成回溯,根据k近邻进行统计'''
nodeList = nodeList[:k] if k <= len(nodeList) else nodeList
labelNum={}
for node in nodeList:
if node[2] not in labelNum:
labelNum[node[2]]=0
else:
labelNum[node[2]]+=1
list=sorted(labelNum.items(),key=lambda x:x[1],reverse=True)
return list[0][0]
'''辅助搜索函数:搜索另一子结点区域'''
def search(self,nodeList,root,x,k):
'''
与 searchKdTree 几乎相同,只是减少了类别的统计与判断
对以另一子结点为根的子树进行搜索
'''
if root==None:
return nodeList
nodeList.sort()
dis = nodeList[-1][0] if k > len(nodeList) else nodeList[k-1][0] #当前超球体半径
node=self.findLeafNode(x,root) #找到目标点在另一结点区域中的最近点
distance = np.sqrt(sum((x - node.vec)**2))
'''更细超球体半径'''
if k>len(nodeList) or distance<dis:
nodeList.append([distance,tuple(node.vec),node.label])
nodeList.sort()
dis = nodeList[-1][0] if k > len(nodeList) else nodeList[k - 1][0]
'''向上递归搜索'''
while True:
if node==root:
break
'''检查父节点'''
father=node.father
fatherDistance=np.sqrt(sum((x-father.vec)**2))
'''
找到的近邻小于k个或者当前超球体半径与父节点对应的区域相交,则更新超球体半径
'''
if k>len(nodeList) or dis>fatherDistance:
nodeList.append([fatherDistance,tuple(father.vec),father.label])
nodeList.sort() #从小到大排序
dis= nodeList[-1][0] if k > len(nodeList) else nodeList[k-1][0] #更新超球体半径
'''找到的近邻仍小于k个或者目标点到切分超平面的距离小于超球体半径,即超球体与父节点的另一结点区域相交'''
if k>len(nodeList) or abs(x[father.dim]-father.vec[father.dim])<dis:
if x[father.dim]<father.vec[father.dim]: #目标点在父节点的左侧区域,则要检查右侧区域
otherChild=father.right
nodeList=self.search(nodeList,otherChild,x,k) #检查左侧区域对超球体进行更新
else: #目标点在父节点的右侧区域,则要检查左侧区域
otherChild=father.left
nodeList=self.search(nodeList,otherChild,x,k) #检查右侧区域对超球体进行更新
node=node.father #回溯到父节点
return nodeList
'''计算各维度方差'''
def getVar(self,data):
return list(np.var(data,axis=0))
由此我们可以定义以 K d ~Kd~ Kd 树为数据结构的优化后的 K N N ~KNN~ KNN 模型:
'''定义KNN分类器'''
class KnnClassifier(object):
'''初始化k参数'''
def __init__(self,k):
self.k=k
'''构造Kd树'''
def fit(self,data,target):
self.KdTree=Kd_Tree(data,target)
'''进行预测'''
def predict(self,X_test):
result=[]
for x_t in X_test:
result.append(self.KdTree.searchKdTree(x_t,self.k))
return np.array(result)
注意,我们上述实现的代码与我们的举例存在不同,一方面我们选择切分维度的方法是选择方差最大的那个维度,另外我们搜索 K D ~KD~ KD 树时不再是寻找最近邻,而是寻找 k ~k~ k 近邻,区别在于我们添加了一个数组存储当前寻找到的 k ~k~ k 个近邻,超球体半径是第 k ~k~ k 小的数据点与目标点之间的距离,这样实现的代码更具有普适性。
我们可以用鸢尾花数据集对上述模型进行验证:
'''使用鸢尾花数据集进行验证'''
iris=load_iris()
data=iris.data
target=iris.target
'''数据集划分'''
X_train,X_test,y_train,y_test=train_test_split(data,target,test_size=0.2,random_state=10)#选取20%的数据作为测试集
'''初始化模型'''
knn=KnnClassifier(3)
knn.fit(X_train,y_train)
y_pred=knn.predict(X_test)
print(accuracy_score(y_test,y_pred)) #0.9666666666666667
可以发现正确率为0.967,模型效果良好,上述手动实现过程还是比较复杂的,在算法竞赛过程中为了提高编码效率,还是调库效率较高,不过如果涉及到算法的优化的话,面向手动实现的代码进行分析更有优势。
1.2.4 总结
① KD树是一种二叉树,其中每个节点都是一个k维点。
② 可以将每个非叶节点视为隐式生成一个拆分超平面,该超平面将空间拆分为两部分,称为半空间。
③ 此超平面左侧的点由该节点的左子树表示,而超平面右侧的点由右子树表示。
④ 超平面方向的选择方式如下:树中的每个节点都与k维度中的一个维度相关联,超平面垂直于该维度的轴。
1.3 球树
球树类似于KD树,但是不用超平面对特征空间进行分割,而是用超球面进行分割
ball结构允许我们沿着点所在的底层流形对数据进行分区,而不是重复剖析整个特征空间(如KD树)
1.3.1 伪码实现
球树的构造伪码如下图所示,因为其构造过程类似于 K D ~KD~ KD 树,所以在此不再手动实现(笔者此刻不愿意coding了 TAT)

1.3.2 球树应用
球树的作用与 K D ~KD~ KD 树相同,都是对 K N N ~KNN~ KNN 的数据结构进行优化, K D ~KD~ KD 树适用于低维空间,球树适用于高维空间。
① K N N ~KNN~ KNN 在测试过程中很慢,因为它做了很多不必要的工作。
② K D ~KD~ KD 树对特征空间进行分区,这样我们就可以排除距离最近的 k ~k~ k 个邻居更远的整个分区。
但是,拆分是轴对齐的,无法很好地延伸到更高的维度。
③ 球树划分了点所在的流形,而不是整个空间。这使得它在更高的维度上表现得更好。
二、决策树
2.1 核心思想
假设我们进行一个二分类问题,如果我们知道一个测试点属于一个100万个点的集群,所有这些点的标签都为正值,那么在我们计算测试点到这100万个距离中的每一个点的距离之前,我们也会知道它的邻居将为正值,由此就有了决策树的思想。
决策树的构建过程,我们不存储训练数据,而是使用训练数据来构建一个树结构,该结构递归地将空间划分为具有类似标签的区域。

决策树特点:
① 首先,决策树的根节点对应整个训练集
② 然后,通过一个简单的阈值 t ~t~ t ,将该集合沿一个维度 l ~l~ l 大致分成两半。
③ x ( l ) ≥ t ~x^{(l)}≥ t~ x(l)≥t 的数据点落在右子节点中,其他所有节点落在左子节点中。
④ 选择阈值 t ~t~ t 和维度 l ~l~ l ,以便生成的子节点在类成员方面更纯粹。
⑤ 理想情况下,所有的正节点都属于一个子节点,所有的负节点都属于另一个子节点。
⑥ 满足上述条件后,则完成决策的构建,否则要继续对叶子结点进行分割,直到所有叶子结点都属于一个类或不再可分
决策树在KNN之上的优点:
① 决策树构建之后我们便不再需要存储各个训练数据,只需要存储所有叶子结点的标签
② 决策树在测试期间速度非常快,因为测试输入只需遍历树到一片叶子,预测是叶子的主要标签
③ 决策树不需要度量,因为分割基于特征阈值而不是距离。
2.2 构造决策树
我们所要构建的决策树的目标是:
① 使得决策树最大紧凑化
② 使得叶子结点都只包含一种标签的结点
要找到一棵最小化的树是一个NP完全问题,但是我们可以用贪婪策略非常有效地近似它。
我们不断拆分数据,以最小化杂质函数,该函数用于测量子对象中的标签纯度。
我们首先了解一下构造决策树用到的一些重要概念。
2.2.1 基尼系数
首先我们假设数据集 S ~S~ S 为:
S = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) } y i ∈ { 1 , 2 , . . . , c } S=\{(x_1,y_1),(x_2,y_2),...,(x_n,y_n)\}\\ y_i\in\{1,2,...,c\} S={(x1,y1),(x2,y2),...,(xn,yn)}yi∈{1,2,...,c}
接着定义数据集的子集 S k ~S_k~ Sk :
S k = { ( x , y ) ∣ y = k } S = S 1 ∪ S 2 ∪ . . . ∪ S c S_k=\{(x,y)|y=k\}\\ S=S_1\cup S_2\cup...\cup S_c Sk={(x,y)∣y=k}S=S1∪S2∪...∪Sc
然后我们可以定义输入分数 p k ~p_k~ pk :
p k = ∣ S k ∣ ∣ S ∣ p_k=\frac{|S_k|}{|S|} pk=∣S∣∣Sk∣
基尼不纯度:表示在样本集合中一个随机选中的样本被分错的概率,则整个数据集的基尼不纯度为:
G i n i ( S ) = ∑ k = 1 c p k ( 1 − p k ) {Gini}(S)=\sum_{k=1}^cp_k(1-p_k) Gini(S)=k=1∑cpk(1−pk)
显然当数据集 S ~S~ S 中的标签只有一个时, G ( S ) = 0 ~G(S)=0~ G(S)=0 ,同时我们也可以定义决策树的基尼不纯度:
G i n i T ( S ) = ∣ S L ∣ ∣ S ∣ G i n i T ( S L ) + ∣ S R ∣ ∣ S ∣ G i n i T ( S R ) {Gini}^T(S)=\frac{|S_L|}{|S|} {Gini}^T(S_L)+\frac{|S_R|}{|S|} {Gini}^T(S_R) GiniT(S)=∣S∣∣SL∣GiniT(SL)+∣S∣∣SR∣GiniT(SR)
2.2.2 信息熵
信息是个很抽象的概念。人们常常说信息很多,或者信息较少,但却很难说清楚信息到底有多少。比如一本五十万字的中文书到底有多少信息量。直到1948年,香农提出了**“信息熵”**的概念,才解决了对信息的量化度量问题。信息熵这个词是香农从热力学中借用过来的。热力学中的热熵是表示分子状态混乱程度的物理量。香农用信息熵的概念来描述信源的不确定度。信源的不确定性越大,信息熵也越大。
从机器学习的角度来看,信息熵表示的是信息量的期望值,我们的假设与杂质函数的假设相同,则信息量的定义如下:
I k = log p k I_k=\log p_k Ik=logpk
由于信息熵是信息量的期望值,所以信息熵 H ( S ) ~H(S)~ H(S) 的定义如下:信息熵反映的是不确定性
H ( S ) = − ∑ k = 1 c p k log p k H(S)=-\sum_{k=1}^cp_k\log p_k H(S)=−k=1∑cpklogpk
同理我们可以定义决策树的熵:
H T ( S ) = ∣ S L ∣ ∣ S ∣ H T ( S L ) + ∣ S R ∣ ∣ S ∣ H T ( S R ) H^T(S)=\frac{|S_L|}{|S|}H^T(S_L)+\frac{|S_R|}{|S|}H^T(S_R) HT(S)=∣S∣∣SL∣HT(SL)+∣S∣∣SR∣HT(SR)
在实际的场景中,我们可能需要研究数据集中某个特征等于某个值时的信息熵等于多少,这个时候就需要用到条件熵。条件熵 H ( Y ∣ X ) ~H(Y|X)~ H(Y∣X) 表示特征 X ~X~ X 为某个值的条件下,标签集为 Y ~Y~ Y 的熵。条件熵的计算公式如下:
H ( D , X ) = H ( Y ∣ X ) = ∑ x ∈ X p ( x ) H ( Y ∣ X = x ) = − ∑ x ∈ X p ( x ) ∑ y ∈ Y p ( y ∣ x ) log p ( y ∣ x ) \begin{aligned} &H(D,X)=H(Y|X)=\sum_{x\in X}p(x)H(Y|X=x)=-\sum_{x\in X}p(x)\sum_{y\in Y}p(y|x)\log p(y|x) \end{aligned} H(D,X)=H(Y∣X)=x∈X∑p(x)H(Y∣X=x)=−x∈X∑p(x)y∈Y∑p(y∣x)logp(y∣x)
现在已经知道了什么是熵,什么是条件熵,接下来就可以看看什么是信息增益了。
所谓的信息增益就是表示我已知条件X后能得到信息Y的不确定性的减少程度。
就好比,我在玩读心术。你心里想一件东西,我来猜。我已开始什么都没问你,我要猜的话,肯定是瞎猜。这个时候我的熵就非常高。然后我接下来我会去试着问你是非题,当我问了是非题之后,我就能减小猜测你心中想到的东西的范围,这样其实就是减小了我的熵。那么我熵的减小程度就是我的信息增益。
所以信息增益如果套上机器学习的话就是,如果把特征A对训练集S的信息增益记为g(D, A)的话,那么g(D, A)的计算公式就是:
g ( D , A ) = H ( D ) − H ( D , A ) g(D,A)=H(D)-H(D,A) g(D,A)=H(D)−H(D,A)
我们不妨通过一个例子理解上述与熵相关的概念:我们有如下"客户流失数据集",0代表未流失,1代表流失
| 编号 | 性别 | 活跃度 | 是否流失 |
|---|---|---|---|
| 1 | 男 | 高 | 0 |
| 2 | 女 | 中 | 0 |
| 3 | 男 | 低 | 1 |
| 4 | 女 | 高 | 0 |
| 5 | 男 | 高 | 0 |
| 6 | 男 | 中 | 0 |
| 7 | 男 | 中 | 1 |
| 8 | 女 | 中 | 0 |
| 9 | 女 | 低 | 1 |
| 10 | 女 | 中 | 0 |
| 11 | 女 | 高 | 0 |
| 12 | 男 | 低 | 1 |
| 13 | 女 | 低 | 1 |
| 14 | 男 | 高 | 0 |
| 15 | 男 | 高 | 0 |
假如要算性别和活跃度这两个特征的信息增益的话,首先要先算总的信息熵和条件熵。
计算总的信息熵很简单:15条数据中标签为0的有10个,标签为1的有5个
y i ∈ { 0 , 1 } p 0 = ∣ S 0 ∣ ∣ S ∣ = 10 15 = 2 3 p 1 = ∣ S 1 ∣ ∣ S ∣ = 5 15 = 1 3 y_i\in\{0,1\}\\ p_0=\frac{|S_0|}{|S|}=\frac{10}{15}=\frac23\\ p_1=\frac{|S_1|}{|S|}=\frac{5}{15}=\frac13 yi∈{0,1}p0=∣S∣∣S0∣=1510=32p1=∣S∣∣S1∣=155=31
则可得总信息熵为:
H ( S ) = − ∑ k = 0 1 p k log p k = − 2 3 log 2 3 − 1 3 log 1 3 ≈ 0.9182 H(S)=-\sum_{k=0}^1p_k\log p_k=-\frac23\log\frac23-\frac13\log\frac13\approx0.9182 H(S)=−k=0∑1pklogpk=−32log32−31log31≈0.9182
接下来就是条件熵的计算,以性别为男的熵为例。表格中性别为男的数据有8条,这8条数据中有3条数据的标签为1,有5条数据的标签为0。所以根据条件熵的计算公式能够得出该条件熵为:
H ( Y ∣ g e n d e r = m a n ) = − 3 8 log 3 8 − 5 8 log 5 8 ≈ 0.9543 H(Y| {gender=man})=-\frac38\log\frac38-\frac58\log\frac58\approx0.9543 H(Y∣gender=man)=−83log83−85log85≈0.9543
同理,我们也可以计算出性别为女时的条件熵:
H ( Y ∣ g e n d e r = w o m a n ) = − 2 7 log 2 7 − 5 7 log 5 7 ≈ 0.8631 H(Y| {gender=woman})=-\frac27\log\frac27-\frac57\log\frac57\approx0.8631 H(Y∣gender=woman)=−72log72−75log75≈0.8631
由此可得总的条件熵为:
H ( Y ∣ g e n d e r ) = p ( g e n d e r = m a x ) H ( Y ∣ g e n d e r = m a n ) + p ( g e n d e r = w o m a n ) H ( Y ∣ g e n d e r = w o m a n ) = 8 15 × 0.9543 + 7 15 × 0.8631 ≈ 0.9117 \begin{aligned} &H(Y| {gender})=p( {gender=max})H(Y| {gender=man})+p( {gender=woman})H(Y| {gender=woman})\\ &~~~~~~~~~~~~~~~~~~~~~~~~=\frac8{15}\times0.9543+\frac7{15}\times0.8631\approx0.9117 \end{aligned} H(Y∣gender)=p(gender=max)H(Y∣gender=man)+p(gender=woman)H(Y∣gender=woman) =158×0.9543+157×0.8631≈0.9117
接着我们可以按照相同的方法计算活跃度的条件熵:
H ( Y ∣ a c t i v a t i o n = l o w ) = − 4 4 log 4 4 − 0 = 0 H ( Y ∣ a c t i v a t i o n = m i d ) = − 4 5 log 4 5 − 1 5 log 1 5 ≈ 0.7219 H ( Y ∣ a c t i v a t i o n = h i g h ) = − 6 6 log 6 6 − 0 = 0 H ( Y ∣ a c t i v a t i o n ) = 5 15 H ( Y ∣ a c t i v a t i o n = m i d ) ≈ 0.2406 \begin{aligned} &H(Y| {activation=low})=-\frac44\log\frac44-0=0\\ &H(Y| {activation=mid})=-\frac45\log\frac45-\frac15\log\frac15\approx0.7219\\ &H(Y| {activation=high})=-\frac66\log\frac66-0=0\\ &H(Y| {activation})=\frac5{15} H(Y| {activation=mid})\approx0.2406 \end{aligned} H(Y∣activation=low)=−44log44−0=0H(Y∣activation=mid)=−54log54−51log51≈0.7219H(Y∣activation=high)=−66log66−0=0H(Y∣activation)=155H(Y∣activation=mid)≈0.2406
由此可得性别和活跃度两个特征的信息增益:
g ( S , g e n d e r ) = H ( S ) − H ( Y ∣ g e n d e r ) = 0.9182 − 0.9117 = 0.0065 g ( S , a c t i v a t i o n ) = H ( S ) − H ( Y ∣ a c t i v a t i o n ) = 0.9182 − 0.2406 = 0.6776 \begin{aligned} &g(S, {gender})=H(S)-H(Y| {gender})=0.9182-0.9117=0.0065\\ &g(S, {activation})=H(S)-H(Y| {activation})=0.9182-0.2406=0.6776 \end{aligned} g(S,gender)=H(S)−H(Y∣gender)=0.9182−0.9117=0.0065g(S,activation)=H(S)−H(Y∣activation)=0.9182−0.2406=0.6776
那信息增益算出来之后有什么意义呢?回到读心术的问题,为了我能更加准确的猜出你心中所想,我肯定是问的问题越好就能猜得越准!换句话来说我肯定是要想出一个信息增益最大(减少不确定性程度最高)的问题来问你,显然上述两个特征中活跃度的信息增益最高,而这也是 I D 3 ~ID3~ ID3 算法的基本思想。
同时支持 I D 3 ~ID3~ ID3 算法的的一个定理为:信息增益一定非负,相关证明可以参考 如何证明信息增益一定大于0?
2.2.3 I D 3 ~ID3~ ID3 算法
(1)中止条件: I D 3 ~ID3~ ID3 算法的终止条件为:
①子集中的所有数据点具有相同的标签 y ~y~ y ,停止拆分,并创建一个标签为 y ~y~ y 的叶子节点
②没有更多的特征用于切分子集,比如两个数据点的特征向量相同但是标签不同,停止拆分,并创建一个标签为最常见标签的叶子节点

(2)算法过程:
#假设数据集为D,标签集为A,需要构造的决策树为tree
def ID3(D, A):
if 'D中所有的标签都相同':
return '标签'
if '样本中只有一个特征或者所有样本的特征都一样':
'对D中所有的标签进行计数'
return '计数最高的标签'
'计算所有特征的信息增益'
'选出增益最大的特征作为最佳特征(best_feature)'
'将best_feature作为tree的根结点'
'得到best_feature在数据集中所有出现过的值的集合(value_set)'
for value in value_set:
'从D中筛选出best_feature=value的子数据集(sub_feature)'
'从A中筛选出best_feature=value的子标签集(sub_label)'
#递归构造tree
tree[best_feature][value] = ID3(sub_feature, sub_label)
return tree
比如我们辨别西瓜好坏的决策树如下:
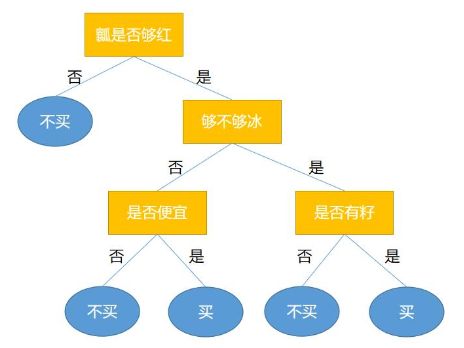
很明显上述的 I D 3 ~ID3~ ID3 算法是比较适合具有多项式特征的数据集的,而对于具有连续型的特征数据并不推荐该算法。
算法实现如下:首先我们用到的库为:
'''屏蔽warning'''
import warnings
warnings.filterwarnings("ignore")
'''导入重要的库'''
import numpy as np
import pandas as pd
import copy
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
决策树模型为:
'''定义决策树模型'''
class DecisionTree(object):
def __init__(self,data,target):
'''初始化一个用于统计标签数量的模板'''
self.dictLabel={}
for y in target:
if y not in self.dictLabel.keys():
self.dictLabel[y]=0
'''决策树模型'''
self.tree=self.buildTree_ID3(data,target)
'''构造决策树'''
def buildTree_ID3(self,data,target):
if self.is_same_label(target): #D中所有的标签都相同
return target[0] #返回相同的标签
if len(data)==1 or self.is_same_vector(data): #样本中只有一个特征或者所有样本的特征都一样
return np.argmax(np.bincount(target)) #返回数量最多的标签
'''计算所有特征的信息增益'''
Gain=self.calcInfoGain(data,target)
'''选出增益最大的特征'''
Gain.sort(key=lambda x:x[1]) #按照信息增益进行排序
best_feature=Gain[-1][0]
# print(Gain)
# print("best_feature:",best_feature)
# print("信息增益:",Gain[-1][1])
'''将best_feature作为根节点'''
tree={}
tree[best_feature]={}
'''得到best_feature的取值集合'''
value_set=[]
for v in data[:,best_feature]:
if v not in value_set:
value_set.append(v)
'''递归得构造树'''
'''首先整合数据集'''
dataset=[] #整合特征向量与标签,便于得到子数据集
for i in range(len(data)):
dataset.append((data[i],target[i]))
for value in value_set:
subset=np.array(list(filter(lambda x:x[0][best_feature]==value,dataset))) #首先对dataset进行过滤
'''从D中筛选出best_feature=value的子数据集(sub_feature)'''
sub_feature=np.array(list(np.array(subset)[:,0]))
'''从A中筛选出best_feature=value的子标签集(sub_label)'''
sub_label=np.array(list(np.array(subset)[:,1]))
#上述数据集不需要再删去特征A,因为特征A在子树的信息增益一定为0
tree[best_feature][value]=self.buildTree_ID3(sub_feature,sub_label)
return tree
'''计算信息增益'''
def calcInfoGain(self,data,target):
'''
:param data: 特征向量集,numpy数组
:param target: 标签集,numpy数组
:return: Gain,Gain[i]=(index,g(D,A)),index为特征索引,g(D,A)为信息增益
'''
'''计算总信息熵HD'''
labelNum=copy.deepcopy(self.dictLabel)#统计各类标签数量
for y in target:
labelNum[y]+=1
HD=0.0 #总信息熵
dataNum=len(data)
for y in labelNum.keys():
p=labelNum[y]/dataNum
if not p==0:
HD+=-p*np.log2(p) #规避log(0)的情况
'''计算各个特征的条件熵'''
HDA=[] #存储各个特征的条件熵
for A in range(len(data[0])):
'''首先统计特征A的取值数量'''
valueNum={}
'''
valueNum[v]=(num,labelNum)
(num,labelNum)为特征A取值为v的数据信息
num表示特征A取值为v的样本数量
labelNum记录了特征A取值为v的样本中各类标签的数量
'''
for i in range(dataNum):
value=data[i][A]
label=target[i]
if value not in valueNum:
labelNum=copy.deepcopy(self.dictLabel)
labelNum[label]+=1
valueNum[value]=[1,labelNum]
else:
valueNum[value][0]+=1 #取值为value的数量+1
valueNum[value][1][label]+=1
'''统计结束,计算总条件熵'''
ConEntropy=0.0 #特征A的条件熵
for v in valueNum.keys():
p_v=valueNum[v][0]/dataNum
InfoEntropy=0.0 #特征A取值为v的信息熵
for y in valueNum[v][1].keys():
p=valueNum[v][1][y]/valueNum[v][0]
if not p==0:
InfoEntropy+=-p*np.log2(p)
ConEntropy+=p_v*InfoEntropy
HDA.append((A,ConEntropy))
'''信息熵与各个特征的条件熵计算完毕,统计信息增益'''
Gain=[]
for i in range(len(HDA)):
A=HDA[i][0]
G=HD-HDA[i][1]
Gain.append((A,G))
return Gain
'''判断数据集中标签是否都相同'''
def is_same_label(self,target):
y=target[0]
for i in range(1,len(target)):
if not target[i]==y:
return False
return True
'''判断数据集中向量是否都相同'''
def is_same_vector(self,data):
x=data[0]
for i in range(1,len(data)):
if not (data[i]==x).all():
return False
return True
决策树分类器为:
'''定义决策树分类器'''
class Classifiter(object):
'''无重要参数'''
def __init__(self):
pass
'''训练模型'''
def fit(self,data,target):
self.decisionTree=DecisionTree(data,target) #构造决策树
'''模型预测'''
def predict(self,X_test):
result=[]
for x_t in X_test:
node=self.decisionTree.tree #node初始化为根节点
while isinstance(node,dict): #只要node不是叶子节点,那么它一定是字典
feature=list(node.keys())[0] #当前决策树分支特征
node=node[feature][x_t[feature]]
result.append(node)
return np.array(result)
验证模型时,我们用到的数据集为西瓜好坏数据集:watermelon20.xlsx
'''验证模型效果'''
'''加载数据'''
df=pd.read_excel("data/watermelon_data.xlsx",sheet_name="Sheet1",header=0,index_col=0)
target=np.array(df["好瓜"])
target=np.where(target=="是",1,0) #修正标签
df.drop("好瓜",axis=1,inplace=True)
data=df.values
'''数据集划分'''
X_train,X_test,y_train,y_test=train_test_split(data,target,test_size=0.2,random_state=99)#选取20%的数据作为测试集
'''初始化模型'''
classifiter=Classifiter()
'''模型训练与预测'''
classifiter.fit(data,target) #鉴于数据集太小,我们用全部数据进行训练
print(classifiter.decisionTree.tree) #决策树
#{3: {'清晰': {5: {'硬滑': 1, '软粘': {4: {'稍凹': {0: {'青绿': 1, '乌黑': 0}}, '平坦': 0}}}}, '稍糊': {5: {'软粘': 1, '硬滑': 0}}, '模糊': 0}}
y_pred=classifiter.predict(X_test)
print(accuracy_score(y_test,y_pred)) #1.0
最终我们得到的决策树如下图所示:

算法一个明显的弊端是无法处理包含在训练集中未出现过的特征取值的测试点,这种情况经常出现在具有连续型特征的数据集上,这要求我们的训练集要足够大,保证对各种取值的覆盖,我们后面的 C A R T ~CART~ CART 算法会应对这个问题。
2.2.4 C 4.5 ~C4.5~ C4.5 算法
C 4.5 ~C4.5~ C4.5 算法是对 I D 3 ~ID3~ ID3 算法的扩展,它们的区别在于 I D 3 ~ID3~ ID3 每次选择信息增益最大的特征进行划分,而 C 4.5 ~C4.5~ C4.5 每次选择信息增益率最大的特征进行划分,实现 C 4.5 ~C4.5~ C4.5 算法只需要修改上述代码中的计算部分。
由于在使用信息增益这一指标进行划分时,更喜欢可取值数量较多的特征。为了减少这种偏好可能带来的不利影响,Ross Quinlan使用了信息增益率这一指标来选择最优划分属性,信息增益率的定义如下:
设数据集为 D ~D~ D ,某一特征为 A ~A~ A , G a i n ( D , A ) ~ {Gain}(D,A)~ Gain(D,A) 为信息增益, V ~V~ V 表示特征 A ~A~ A 取值的集合,则信息增益率定义如下:
G a i n r a t i o ( D , A ) = G a i n ( D , A ) − ∑ v ∈ V ∣ D v ∣ ∣ D ∣ log ∣ D v ∣ ∣ D ∣ {Gain ratio}(D,A)=\frac{ {Gain}(D,A)}{-\sum_{v\in V}\frac{|D^v|}{|D|}\log\frac{|D^v|}{|D|}} Gainratio(D,A)=−∑v∈V∣D∣∣Dv∣log∣D∣∣Dv∣Gain(D,A)
还记得我们刚刚举的例子吗,我们回到客户流失数据集中,可以很容易得计算信息增益率:
G a i n ( D , g e n d e r ) = 0.0065 G a i n ( D , a c t i v a t i o n ) = 0.6776 \begin{aligned} & {Gain}(D, {gender})=0.0065\\ & {Gain}(D, {activation})=0.6776\\ \end{aligned} Gain(D,gender)=0.0065Gain(D,activation)=0.6776
15条数据中8条是男性,7条是女性;4条低活跃度,5条中活跃度,6条高活跃度:
G a i n r a t i o ( D , g e n d e r ) = G a i n ( D , g e n d e r ) − 8 15 log 8 15 − 7 15 log 7 15 ≈ 0.0065 G a i n r a t i o ( D , a c t i v a t i o n ) = G a i n ( D , a c t i v a t i o n ) − 4 15 log 4 15 − 5 15 log 5 15 − 6 15 log 6 15 ≈ 0.4238 \begin{aligned} & {Gain ratio}(D, {gender})=\frac{ {Gain}(D, {gender})}{-\frac8{15}\log\frac8{15}-\frac7{15}\log\frac7{15}}\approx0.0065\\ & {Gain ratio}(D, {activation})=\frac{ {Gain}(D, {activation})}{-\frac4{15}\log\frac4{15}-\frac5{15}\log\frac5{15}-\frac6{15}\log\frac6{15}}\approx 0.4238 \end{aligned} Gainratio(D,gender)=−158log158−157log157Gain(D,gender)≈0.0065Gainratio(D,activation)=−154log154−155log155−156log156Gain(D,activation)≈0.4238
我们可以发现活跃度的信息增益率要比信息增益小很多,这就是 C 4.5 ~C4.5~ C4.5 算法的特点。
实现 C 4.5 ~C4.5~ C4.5 算法仅需要修改 I D 3 ~ID3~ ID3 算法的 calcInfoGain 函数:
'''计算信息增益率'''
def calcInfoGain(self,data,target):
'''
:param data: 特征向量集,numpy数组
:param target: 标签集,numpy数组
:return: Gain,Gain[i]=(index,g(D,A)),index为特征索引,g(D,A)为信息增益
'''
'''计算总信息熵HD'''
labelNum=copy.deepcopy(self.dictLabel)#统计各类标签数量
for y in target:
labelNum[y]+=1
HD=0.0 #总信息熵
dataNum=len(data)
for y in labelNum.keys():
p=labelNum[y]/dataNum
if not p==0:
HD+=-p*np.log2(p) #规避log(0)的情况
'''计算各个特征的条件熵'''
HDA=[] #存储各个特征的条件熵
Ratio_base=[] #存储计算信息增益率的底数
for A in range(len(data[0])):
'''首先统计特征A的取值数量'''
valueNum={}
'''
valueNum[v]=(num,labelNum)
(num,labelNum)为特征A取值为v的数据信息
num表示特征A取值为v的样本数量
labelNum记录了特征A取值为v的样本中各类标签的数量
'''
for i in range(dataNum):
value=data[i][A]
label=target[i]
if value not in valueNum:
labelNum=copy.deepcopy(self.dictLabel)
labelNum[label]+=1
valueNum[value]=[1,labelNum]
else:
valueNum[value][0]+=1 #取值为value的数量+1
valueNum[value][1][label]+=1
'''统计结束,计算总条件熵'''
ConEntropy=0.0 #特征A的条件熵
base=0.0
for v in valueNum.keys():
p_v=valueNum[v][0]/dataNum
if not p_v==0:
base+=-p_v*np.log2(p_v)
InfoEntropy=0.0 #特征A取值为v的信息熵
for y in valueNum[v][1].keys():
p=valueNum[v][1][y]/valueNum[v][0]
if not p==0:
InfoEntropy+=-p*np.log2(p)
ConEntropy+=p_v*InfoEntropy
HDA.append((A,ConEntropy))
Ratio_base.append(base)
'''信息熵与各个特征的条件熵计算完毕,统计信息增益'''
Gain=[]
for i in range(len(HDA)):
A=HDA[i][0]
G=(HD-HDA[i][1])
if not G==0.0:
G/=Ratio_base[i]
Gain.append((A,G))
return Gain
值得一提的是:当信息增益为0时,对应的信息增益率的底数也为0,在编写函数时需要注意避免分母为0的情况,同时上述两个算法都可以优化成可以处理具有连续型特征的数据集的算法,只需要将划分不同取值分支的过程改为选择阈值的过程,这也是 C A R T ~CART~ CART 算法的思想,所以我们不再过多赘述,该思想将会在 C A R T ~CART~ CART 算法中实现。
最终我们得到的决策树如下字典所示:可以发现对于我们的西瓜数据集来说两个算法得到的决策树相同
#{3: {'清晰': {5: {'硬滑': 1, '软粘': {4: {'稍凹': {0: {'青绿': 1, '乌黑': 0}}, '平坦': 0}}}}, '稍糊': {5: {'软粘': 1, '硬滑': 0}}, '模糊': 0}}
2.2.5 C A R T ~CART~ CART 算法
C A R T ~CART~ CART 即 Classification and Regression Trees,它既可以作为分类树也可以作为回归树,并且它只能是二叉树。
在ID3算法中我们使用了信息增益来选择特征,信息增益大的优先选择。在C4.5算法中,采用了信息增益率来选择特征,以减少信息增益容易选择特征值多的特征的问题。但是无论是ID3还是C4.5,都是基于信息论的熵模型的,这里面会涉及大量的对数运算。能不能简化模型同时也不至于完全丢失熵模型的优点呢?当然有!那就是基尼系数!
CART算法使用基尼系数来代替信息增益率,基尼系数代表了模型的不纯度,基尼系数越小,则不纯度越低,特征越好。这和信息增益与信息增益率是相反的(它们都是越大越好)。
基尼系数的计算方式如下:数据集为 D ~D~ D , p k ~p_k~ pk 表示第 k ~k~ k 个类别在数据集中所占的比例
G i n i ( D ) = ∑ k = 1 c p k ( 1 − p k ) = 1 − ∑ k = 1 c p k 2 {Gini}(D)=\sum_{k=1}^cp_k(1-p_k)=1-\sum_{k=1}^cp_k^2 Gini(D)=k=1∑cpk(1−pk)=1−k=1∑cpk2
我们还是以客户流失数据集为例:15条数据中,10条标签为0,5条标签为1,则有:
G i n i ( D ) = 1 − ( p 0 2 + p 1 2 ) = 1 − [ ( 2 3 ) 2 + ( 1 3 ) 2 ] ≈ 0.4444 {Gini}(D)=1-(p_0^2+p_1^2)=1-\big[(\frac23)^2+(\frac13)^2\big]\approx0.4444 Gini(D)=1−(p02+p12)=1−[(32)2+(31)2]≈0.4444
同时还有基于数据集 D ~D~ D 和特征 A ~A~ A 的 G i n i ~ {Gini}~ Gini 系数, V ~V~ V 表示特征 A ~A~ A 取值的集合,则定义如下:计算过程类似于条件熵的计算
G i n i ( D , A ) = ∑ v ∈ V ∣ D v ∣ ∣ D ∣ G i n i ( D v ) {Gini}(D,A)=\sum_{v\in V}\frac{|D^v|}{|D|} {Gini}(D^v) Gini(D,A)=v∈V∑∣D∣∣Dv∣Gini(Dv)
我们以客户流失数据集为例:
① 性别特征:15条数据中,8条男性,7条女性;男性数据中,5条标签0,3条标签1;女性数据中,5条标签0,2条标签1
∣ D ∣ = 15 , ∣ D m a n ∣ = 8 , ∣ D w o m a n ∣ = 7 G i n i ( D m a n ) = 1 − [ ( 5 8 ) 2 + ( 3 8 ) 2 ] ≈ 0.46875 G i n i ( D w o m a n ) = 1 − [ ( 5 7 ) 2 + ( 2 7 ) 2 ] ≈ 0.40816 G i n i ( D , g e n d e r ) = 8 15 × 0.46875 + 7 15 × 0.40816 ≈ 0.44048 \begin{aligned} &|D|=15,|D^{ {man}}|=8,|D^{ {woman}}|=7\\ & {Gini}(D^{ {man}})=1-\big[(\frac58)^2+(\frac38)^2\big]\approx0.46875\\ & {Gini}(D^{ {woman}})=1-\big[(\frac57)^2+(\frac27)^2\big]\approx0.40816\\ & {Gini}(D, {gender})=\frac8{15}\times 0.46875+\frac7{15}\times 0.40816\approx0.44048 \end{aligned} ∣D∣=15,∣Dman∣=8,∣Dwoman∣=7Gini(Dman)=1−[(85)2+(83)2]≈0.46875Gini(Dwoman)=1−[(75)2+(72)2]≈0.40816Gini(D,gender)=158×0.46875+157×0.40816≈0.44048
② 活跃度特征计算同理:
∣ D ∣ = 15 , ∣ D l o w ∣ = 4 , ∣ D m i d ∣ = 5 , ∣ D h i g h ∣ = 6 G i n i ( D l o w ) = 1 − [ ( 4 4 ) 2 + ( 0 4 ) 2 ] = 0 G i n i ( D m i d ) = 1 − [ ( 4 5 ) 2 + ( 1 5 ) 2 ] = 0.32 G i n i ( D h i g h ) = 1 − [ ( 6 6 ) 2 + ( 0 6 ) 2 ] = 0 G i n i ( D , a c t i v a t i o n ) = 5 15 × 0.32 = 0.10667 \begin{aligned} &|D|=15,|D^{ {low}}|=4,|D^{ {mid}}|=5,|D^{ {high}}|=6\\ & {Gini}(D^{ {low}})=1-\big[(\frac44)^2+(\frac04)^2\big]=0\\ & {Gini}(D^{ {mid}})=1-\big[(\frac45)^2+(\frac15)^2\big]=0.32\\ & {Gini}(D^{ {high}})=1-\big[(\frac66)^2+(\frac06)^2\big]=0\\ & {Gini}(D, {activation})=\frac5{15}\times 0.32=0.10667 \end{aligned} ∣D∣=15,∣Dlow∣=4,∣Dmid∣=5,∣Dhigh∣=6Gini(Dlow)=1−[(44)2+(40)2]=0Gini(Dmid)=1−[(54)2+(51)2]=0.32Gini(Dhigh)=1−[(66)2+(60)2]=0Gini(D,activation)=155×0.32=0.10667
显然我们要选择活跃度特征,因为它的基尼系数小,不纯度更低。
当我们知道如何选择用于切分的特征后,应该思考如何在该特征上选择一个切分点,即如何寻找一个合适的阈值,在此我们面向连续型特征进行分析,而对于离散型的数据类比即可。
① 首先,将数据集按照最优特征从大到小排列
② 对于大小为 n ~n~ n 的样本,共有 n − 1 ~n-1~ n−1 种切分方式,即有 n − 1 ~n-1~ n−1 个切分点,但是这样切分计算量是很大的并且决策树不佳,我们将注意力放在切分的特征 A ~A~ A 上,设 A ~A~ A 有 m ~m~ m 种不同的取值,则我们只需要关注这 m − 1 ~m-1~ m−1 个不同取值分界点处的切分即可,同时这样可以规避掉一个问题,即切分的阈值一定不属于所提供的数据集中的一个取值,不需要再考虑特征的取值等于阈值时,数据点划分到左子集还是右子集的问题,而在预测的时候如果出现特征取值等于阈值的情况可以考虑固定好搜索走向或者随机走到左右子树。

③ 每个切分点将数据集划分为左右两部分: D L , D R ~D_L,D_R~ DL,DR ,则该切分对应着一个基尼系数:
G i n i ( D L , D R ) = ∣ D L ∣ ∣ D ∣ G i n i ( D L ) + ∣ D R ∣ ∣ D ∣ G i n i ( D R ) \begin{aligned} & {Gini}(D_L,D_R)=\frac{|D_L|}{|D|} {Gini}(D_L)+\frac{|D_R|}{|D|} {Gini}(D_R) \end{aligned} Gini(DL,DR)=∣D∣∣DL∣Gini(DL)+∣D∣∣DR∣Gini(DR)
找到基尼系数最小的切分方式,选择切分左右两个数据点特征的均值作为阈值。
我们通过代码实现基于 C A R T ~CART~ CART 算法的决策树模型:首先我们用到的库有:
'''屏蔽warning'''
import warnings
warnings.filterwarnings("ignore")
'''导入重要的库'''
import numpy as np
import pandas as pd
import copy
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
C A R T ~CART~ CART 树模型定义如下:
'''定义CART决策树'''
class CART(object):
'''初始化树模型'''
def __init__(self,data,target):
'''初始化一个用于统计标签数量的模板'''
self.dictLabel={}
for y in target:
if y not in self.dictLabel.keys():
self.dictLabel[y]=0
'''决策树模型'''
self.tree=self.buildTree(data,target)
'''构造决策树'''
def buildTree(self,data,target):
if self.is_same_label(target): #D中所有的标签都相同
return target[0] #返回相同的标签
if len(data)==1 or self.is_same_vector(data): #样本中只有一个特征或者所有样本的特征都一样
return np.argmax(np.bincount(target)) #返回数量最多的标签
'''选出基尼系数最小的特征'''
bestFeature=self.findBestFeature(data,target)
'''选出该特征最优的划分'''
threshold=self.findBestSplit(bestFeature,data,target)
'''整合数据集'''
D=[] #整合特征向量与标签,便于得到子数据集
for i in range(len(data)):
D.append((data[i],target[i]))
'''划分数据集'''
dataL,targetL,dataR,targetR=self.splitDataset(bestFeature,threshold,D)
'''构造二叉树'''
tree={} #初始化树
tree[(bestFeature,threshold)]={}
'''构造左右子树'''
tree[(bestFeature,threshold)]["left"]=self.buildTree(dataL,targetL)
tree[(bestFeature,threshold)]["right"]=self.buildTree(dataR,targetR)
return tree
'''计算数据集D的基尼系数'''
def Gini_D(self,target): #我们仅需要target即可计算数据集D的基尼系数
dataNum=len(target) #样本大小
labelNum=copy.deepcopy(self.dictLabel) #统计各类标签数量
for y in target:
labelNum[y]+=1
G=1.0 #基尼系数
for y in labelNum.keys():
G-=(labelNum[y]/dataNum)**2
return G
'''计算特征A的基尼系数'''
def Gini_D_A(self,A,data,target):
dataNum=len(data)
valueNum={} #统计特征A不同取值信息
'''
valueNum[v]=(num,labelNum)
(num,labelNum)为特征A取值为v的数据信息
num表示特征A取值为v的样本数量
labelNum记录了特征A取值为v的样本中各类标签
'''
for i in range(dataNum):
value=data[i][A]
label=target[i]
if value not in valueNum:
labelNum=np.array([label])
valueNum[value]=[1,labelNum]
else:
valueNum[value][0]+=1 #取值为value的数量+1
valueNum[value][1]=np.append(valueNum[value][1],label)
'''统计结束,计算特征A的基尼系数'''
G=0.0 #特征A的基尼系数
for v in valueNum.keys():
p=valueNum[v][0]/dataNum
G+=p*self.Gini_D(valueNum[v][1])
return G
'''选择基尼系数最小的特征'''
def findBestFeature(self,data,target):
featureNum=len(data[0])
Ginis=[] #存储各个维度的基尼系数
for A in range(featureNum):
Ginis.append((A,self.Gini_D_A(A,data,target)))
Ginis.sort(key=lambda x:x[1]) #按照基尼系数排序
bestFeature=Ginis[0][0]
return bestFeature
'''根据阈值划分数据集'''
def splitDataset(self,A,threshold,D):
'''
:param A: 用于划分的特征
:param threshold: 特征阈值
:param D: D[i]=(data[i],target[i]),整合后的数据集
:return: 划分后的左右两个数据集
'''
'''获得两个划分后的子集'''
DL=np.array(list(filter(lambda x:x[0][A]<threshold,D)))
DR=np.array(list(filter(lambda x:x[0][A]>threshold,D)))
'''分离出data和target'''
dataL=np.array(list(np.array(DL)[:,0]))
targetL=np.array(list(np.array(DL)[:,1]))
dataR=np.array(list(np.array(DR)[:,0]))
targetR=np.array(list(np.array(DR)[:,1]))
return dataL,targetL,dataR,targetR
'''找到最优的划分'''
def findBestSplit(self,A,data,target):
'''
:param A: 切分点所在的维度
:param data: 特征向量集
:param target: 标签集
:return: 该特征的切分阈值 threshold
'''
dataNum=len(data) #样本大小
'''首先整合数据'''
D=[] #整合特征向量与标签,便于得到子数据集
for i in range(len(data)):
D.append((data[i],target[i]))
'''集合按照特征A的大小排序'''
D.sort(key=lambda x:x[0][A])
'''遍历dataNum-1个切分'''
split=[] #存储各种划分的基尼系数和阈值,split[i]=(threshold,Gini)
for i in range(dataNum-1):
if D[i][0][A]==D[i+1][0][A]: #取值相同,不进行切分
continue
threshold=(D[i][0][A]+D[i+1][0][A])/2
dataL,targetL,dataR,targetR=self.splitDataset(A,threshold,D)
Gini=(len(dataL)/dataNum)*self.Gini_D(targetL)+(len(dataR)/dataNum)*self.Gini_D(targetR)
split.append((threshold,Gini))
'''选择基尼系数最小的划分'''
split.sort(key=lambda x:x[1])
threshold=split[0][0]
return threshold
'''判断数据集中标签是否都相同'''
def is_same_label(self,target):
y=target[0]
for i in range(1,len(target)):
if not target[i]==y:
return False
return True
'''判断数据集中向量是否都相同'''
def is_same_vector(self,data):
x=data[0]
for i in range(1,len(data)):
if not (data[i]==x).all():
return False
return True
利用该分类树的分类器为:
'''定义决策树分类器'''
class Classifiter(object):
'''无重要参数'''
def __init__(self):
pass
'''训练模型'''
def fit(self,data,target):
self.decisionTree=CART(data,target) #构造决策树
'''模型预测'''
def predict(self,X_test):
result=[]
for x_t in X_test:
node=self.decisionTree.tree #node初始化为根节点
while isinstance(node,dict): #只要node不是叶子节点,那么它一定是字典
feature=list(node.keys())[0][0] #当前决策树分支特征
threshold=list(node.keys())[0][1] #当前决策树分支阈值
if x_t[feature]<threshold:
node=node[(feature,threshold)]["left"]
else:
node=node[(feature,threshold)]["right"]
result.append(node)
return np.array(result)
我们可以利用鸢尾花数据集进行模型效果的验证:可以发现准确率很高,达到了0.96
'''验证模型效果'''
'''加载鸢尾花数据集'''
iris=load_iris()
data=iris.data
target=iris.target
'''划分数据集'''
X_train,X_test,y_train,y_test=train_test_split(data,target,test_size=0.2,random_state=10)#选取20%的数据作为测试集
'''初始化模型'''
classifiter=Classifiter()
'''模型训练与预测'''
classifiter.fit(X_train,y_train)
y_pred=classifiter.predict(X_test)
print(accuracy_score(y_test,y_pred)) #0.9666666666666667
可以发现 C A R T ~CART~ CART 算法的大体思想与 I D 3 ~ID3~ ID3 和 C 4.5 ~C4.5~ C4.5 算法相同,模型的实现也比较类似。
C A R T ~CART~ CART 是一个构造简单并且测试速度很快的树,但是它本身在准确性上并没竞争力,一些诸如 LightGBM 和 XGBoost 等高性能的第三方库提供的树模型具有更强大的性能,适用于机器学习竞赛中。
获取更多与机器相关的算法与原码可以关注我的个人博客 My Brain