UIE:Unified Structure Generation for Universal Information Extraction
论文:https://arxiv.org/pdf/2203.12277.pdf
作者采用生成式text to structure结构统一了信息抽取的四个任务,并且在13个数据集上采用有监督、低资源和少样本设置下均取得了SOTA。
0 摘要
本文提出了一个统一的文本到结构生成框架,即UIE,它可以通用地为不同的IE任务建模,自适应地生成目标结构,并从不同的知识来源协同学习通用的IE能力。
具体来说,UIE通过一种结构化的提取语言对不同的提取结构进行统一编码,通过一种基于模式的prompt机制——结构化模式自适应地生成目标提取,并通过一个大规模的预训练的文本-结构模型来捕获常见的IE能力。
实验表明,UIE在4个IE任务、13个数据集和所有的有监督的、低资源的、少样本的设置上,对于广泛的实体、关系、事件和情感提取任务及其统一,都达到了SOTA的性能。这些结果验证了UIE的有效性、通用性和可移植性。
1 引言
信息提取(IE)旨在从非结构化文本中识别和构建用户指定的信息。 因为不同的任务识别的实体、事件类型等等都不一样,所以针对特定的任务要训练特定的模型,定制化较高,不具有通用性。针对这种问题,本文从生成模型的角度去考虑信息抽取的问题,使得这几种子任务可以通过一个模型去完成。
信息抽取通常包含常见的四个子任务: 实体抽取、关系抽取、事件抽取以及情感分析等。
- 命名实体识别任务一般是采用span及其实体类别表示
- 关系抽取任务一般采用三元组(triplet)结构表示
- 事件抽取任务一般采用记录(record)表示
- 情感分析任务采用三元组(triplet)来表示
IE将文本到结构的转换可以进一步分解为几个原子转换操作:
- 第一步是做定位(Spotting)。在输入的原句中定位到目标信息片段。例如在给定Entity PER的时候,要定位到“Steve”定位,给定sentiment expression要定位到“excited”;
- 第二步是做关联(Associating)。指找出Spotting输出的信息片段之间的关系。例如,把“Steve”和“Apple”分配为关系“work for”的参数1和参数2,也就头实体和尾实体。
通过这种方式,不同的IE任务可以分解为一系列原子文本到结构的转换,所有IE模型共享相同的底层发现和关联能力。

- 为了对异构IE结构进行建模,论文设计了一种结构提取语言(SEL),该语言可以有效地将不同的IE结构编码为统一的表示,从而可以在相同的文本到结构生成框架中对各种IE任务进行通用建模。
- 为了自适应地为不同的IE任务生成目标结构,论文提出了结构模式指导器(SSI),这是一种基于模式的prompt机制,用于控制UIE中要发现的内容、要关联的内容以及要生成的内容。
经过转化,上图a中的各个任务就可以结构化为下图b中的格式。

本文创新点:
- 提出了一个统一的text-to-structure生成架构,可以对不同的信息抽取(IE)任务进行建模,自适应地生成目标结构,并从不同的知识资源学习通用的信息抽取能力。是第一个text-to-structure预训练抽取模型。
- 设计了一个统一的结构生成网络,通过结构抽取语言(structural extraction language)将异构的信息抽取结构编码成统一的表示,并通过结构模式(structural schema instructor)指导机制控制UIE模型的识别、关联和生成。
2 方法
在本节中,将描述如何在统一的文本中共同制定、学习和执行各种IE任务,以构建生成架构UIE。
- 设计结构化提取语言(SEL):将实体、关系、事件编码为统一表示。
- 结构模式指导器(SSI):基于模式的prompt机制,用于控制UIE模型,以便为不同的提取设置发现、关联和生成哪个模型。
- 预训练:作者从web源挖掘大规模异构数据集对UIE进行预训练(实际是就是用远程监督生成了一个大规模关系抽取预训练数据集),令模型可以学习通用IE能力,并显著提高了IE在 supervised, low-resource, 以及 few-shot settings这类情况下的性能。
2.1 如何结构化提取的信息
IE将文本到结构的转换可以进一步分解为几个原子转换操作:
- 第一步是做定位(Spotting)。在输入的原句中定位到目标信息片段。
- 第二步是做关联(Associating)。指找出Spotting输出的信息片段之间的关系。
structured extraction language (SEL)将异构IE结构编码为统一的表示,每个SEL表达式包含三种类型的语义单元,示例如下图:

- Spot Name: 指目标信息片段的类别,在实体抽取中指实体类别,在事件抽取中可以指事件类型和论元类别。
- Info Span: Spotting操作(原句中定位到目标信息片段)的输出,即原句子中的目标信息片段。
- Asso Name: 指两个信息片段之间的关系类型,也就是Associating操作(Spotting输出的信息片段之间的关系)的输出。
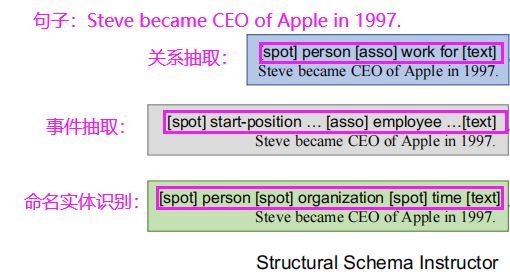
对于句子:Steve became CEO of Apple in 1997.
进行关系抽取、事件抽取、命名实体识别就可以统一的生成如下结构:

SEL的优点:
- 统一编码不同的IE结构,因此不同的IE任务可以建模为相同的text-to-structure生成过程;
- 高效地表示同一结构中句子的所有提取结果,可以自然地进行联合提取;
- 生成的输出结构非常紧凑,大大降低了解码的复杂度。
2.2 如何自适应地得到想要生成的信息
使用SEL, UIE(本文提出的模型)可以均匀地生成不同的IE结构。然而,由于不同的IE任务有不同的模式,在提取过程中,如何自适应地控制我们想要生成的信息?
本文提出了结构模式指导器(SSI),这是一种基于模式(schema)的提示(prompt)机制,用于控制不同的生成需求:在Text前拼接上相应的Schema Prompt,输出相应的SEL结构语言。
如下图:
不同任务的的形式是:
- 实体抽取:[spot] 实体类别 [text]
- 关系抽取:[spot] 实体类别 [asso] 关系类别 [text]
- 事件抽取:[spot] 事件类别 [asso] 论元类别 [text]
- 观点抽取:[spot] 评价维度 [asso] 观点类别 [text]
UIE的整体框架为:

形式上,UIE将给定的结构模式指导器SSI(s)和文本序列(x)作为输入,并生成采用SEL语法描述的结构化数据(y),其中包含基于模式s从x中提取的信息:

2.2.1 结构模式指导器(SSI,Structural Schema Instructor )
为了描述任务的提取目标,Structural Schema Instructor(SSI)构建了一个基于模式的提示(schema-based prompt),并在生成过程中将其用作前缀。包含三种类型的token:
- SPOTNAME:信息提取任务中的目标定位名称。如NER任务中的“person”
- ASSONAME:目标关联名称。如关系提取任务中的“work for”;
- Special Symbols([spot], [asso],[text]):分别添加在每个spot name、association name和文本序列前面添加。
SSI中的所有标记都被连接起来,并放在原始文本序列之前。![s\bigoplus x=[{\color{Red} s_{1},s_{2},...,s_{|s|}},x_{1},x_{2},...,x_{x}] =[{\color{Red} [spot],..[spot]...,[asso],...,[asso]...,[text]},x_{1},x_{2},...,x_{x}]](http://img.e-com-net.com/image/info8/0bb6f80ef0284314b1bf564929bafd29.gif)
2.2.2 使用UIE生成结构
so,模型到底是什么呢?其实就是一个标准的Transformer,包含了Encoder和Decoder。首先将SSI信息和句子拼接(其中  是SSI信息,
是SSI信息, 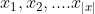 是句子),输入至Encoder,得到每一个token的隐层表示:
是句子),输入至Encoder,得到每一个token的隐层表示:

接下来使用隐层表示在Decoder端生成目标结构化信息,表示如式 (4) 所示:
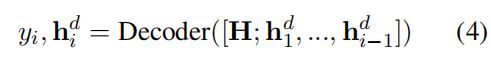
(在解码的步骤 i中 ,UIE生成SEL序列中的第 i 个token  和解码器状态
和解码器状态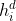 )
)
3 预训练和微调
在本节中,论文将描述:
- 1)Pre-train:如何预训练一个大规模的UIE模型,来捕获不同IE任务间的通用IE能力?
- 2)Finetune:如何通过快速的Finetune使UIE适应不同设置下的不同 IE 任务。
3.1 预训练
生成任务是不可控,如果生成的信息结构不符合前面定义的结构,那怎样抽取信息呢?作者通过了定义不同的损失避免的这种情况。
UIE预训练语料主要来自Wikipedia、Wikidata和ConceptNet,构建了3种预训练数据,并分别构造3种预训练任务,将大规模异构数据整合到一起进行预训练:
D_pair: 通过Wikipedia对齐Wikidata,构建text-to-struct的平行语料,数据表示为(s,x,y)
Text-to-Structure Pre-training:每个实例都是一个并行对(token序列x,结构化记录y),用于预训练UIE的文本到结构映射能力。预训练时随机取样一些负例(spots、association)作为噪声训练(引入negative schema)。
首先,定义 。具体x输入为:[spot] person [asso] work for [text]Steve became CEO of Apple in 1997.,y则为:((person: Steve(work for: Apple)))。可以发现在生成的过程中,person和work for在输出时是肯定要出现的。这两个东西就是我们此前定义的spotting、associating。
作者发现如果在生成的token中,加个损失,用来判断当前token是不是spotting或者是不是associating效果会变好。
这里的正样本就是spotting或者assocating,负样本则是随机抽取的token。损失如下:
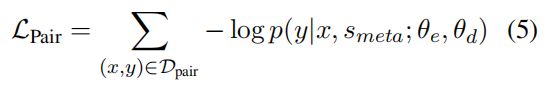
D_record: 结构数据集,其中每个实例都是结构化记录 y(None,None,y)
Structure Generation Pre-training:为了具备SEL语言的结构化能力,这部分输入只有结构化数据record,输入前面的部分,使其生成剩余部分,并且只训练UIE的decoder部分,使其学会SEL语法。
这个损失就是生成任务中,自回归的一个损失。用于预训练UIE的结构解码能力,损失如下所示:
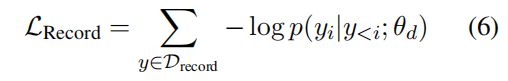
D_text: 无结构化的原始文本数据集。论文使用英文维基百科中的所有纯文本,构造无结构的原始文本数据:(None,x'(破坏过的源文本),x''(破坏的目标spans))
Retrofitting Semantic Representation:为了具备基础的语义编码能力,对D_text数据进行 span corruption训练。这部分做的是无监督的masked language model任务,和T5中的预训练任务一样,在原始句子中MASK掉15%的tokens,然后生成MASK的部分,输入中已经呈现的部分输出MASK
为了提高UIE的语义表示,作者还加了MLM(Masked Language Model)任务。用于预训练UIE的语义编码能力,可以有效地缓解token语义的灾难性遗忘,尤其是在SPOTNAME和ASSONAME token上。。损失如下:

这里的MASK是针对目标文本的。跟bert有点区别。
作者采用的模型是T5-v1.1-base和T5-v1.1-large作为UIE-base和UIE-large,模型的参数初始化直接使用了T5-v1.1的参数,也就是说直接基于其进行了二次预训练。
最后将这三种损失相加,进行大规模的预训练:
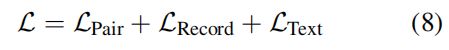
值得注意的是,作者并不是分开做这三个预训练任务的,而是将其统一化,全部表示为三元组 (s,x,y),其中 s 是加在输入句子前面的prompt,x 是输入的原始句子,y 是需要生成的目标句子,在每一个batch中随机抽取每一个任务的数据去训练。Dpair 数据表示为 (s,x,y),Drecord 数据表示为 (None,None,y),Dtext 数据表示为 (None,x′,x″),这样无论是哪种任务都是输入一个三元组,即可统一训练。
3.2 微调
微调部分和预训练任务的 Dpair 类似,数据形式是 (s,x,y),微调的Loss计算方式如式 (9) 所示。
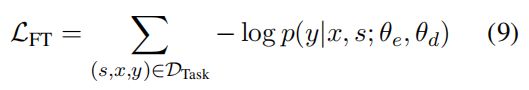
如下表所示,微调部分依然加入了负样本,下部分第二行加入了负样本,随机插入一些原标签中没有的信息,输入句子中并没有facility的实体,而标签中插入了 (facility: [NULL])。

拒绝机制(RM)的一个示例,此处“(facility:[NULL])是学习阶段注入的拒绝噪声,推理阶段将忽略[NULL]值范围。
4 实验
本文在13个IE基准上进行了实验,涉及4个很有代表性的IE任务(包括实体提取、关系提取、事件提取、结构化情感提取)及其组合(例如,联合实体-关系提取)。结果如下:
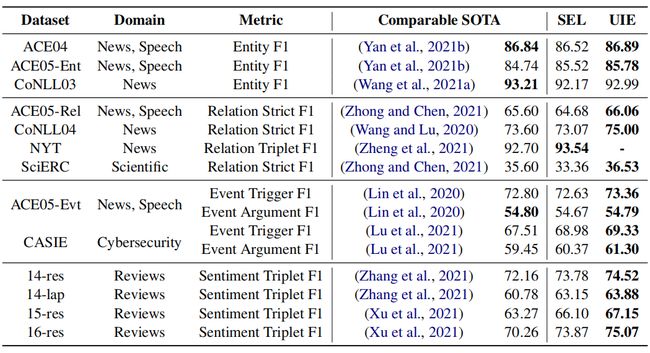
最右边的SEL列是指基于T5-v1.1-large进行微调得到的结果(没有预训练的UIE模型),UIE是指基于UIE-large进行微调的结果,可以看到几乎在全部数据集上都取得了SOTA的结果,但是通过对比SEL和UIE发现预训练部分对结果的提升并不大,通过这个可以看出作者设计的SEL语法和SSI还是很强大的,另一方面也说明T5本身的生成能力就很强大。
另外,作者也给除了few-shot的效果,如下:

UIE真正强大的地方是小样本情况下,泛化能力非常强,远超基于T5的微调结果,在全监督设置下预训练部分的能力没有体现出来,但在低资源下针对性的预训练可以非常好的提升泛化能力。
参考:
UIE: 信息抽取的大一统模型 - mdnice 墨滴
开箱即用:UIE-通用信息抽取(2022) - 知乎
通用信息提取的统一结构生成-信息检索研究室
信息抽取大一统:百度中科院发布通用抽取模型UIE,刷新13个IE数据集SOTA! - 知乎
信息抽取新SOTA!首个结构化生成式信息抽取预训练模型,一统信息抽取四大任务 - 知乎
《Unified Structure Generation for Universal Information Extraction》论文阅读笔记_KekeLoveNLP的博客-CSDN博客
论文笔记 ACL 2022|Unified Structure Generation for Universal Information Extraction_hlee-top的博客-CSDN博客